Download as PDF, PPTX

























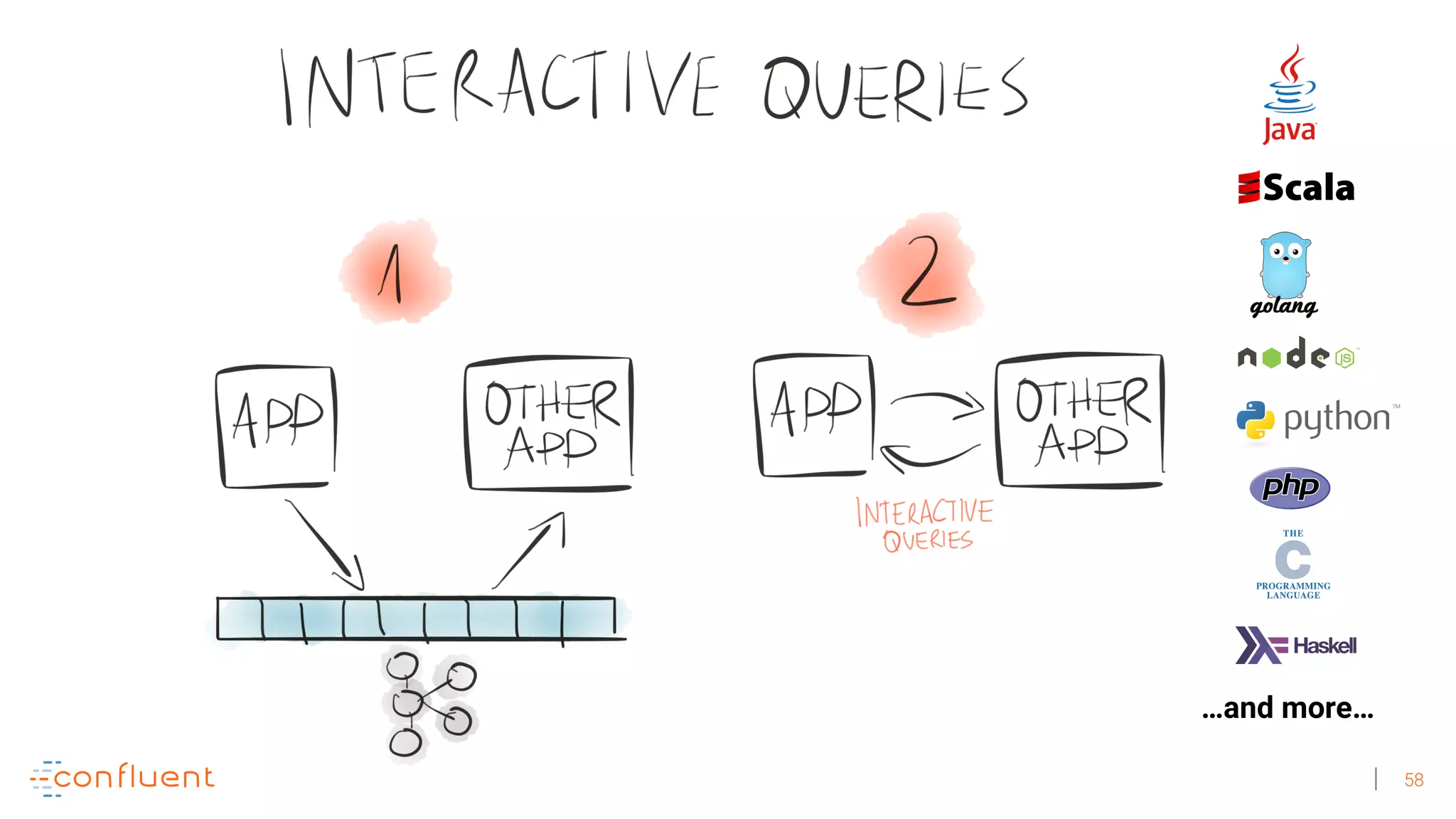
![60
$ curl -sXGET http://localhost:7070/kafka-music/charts/top-five
[
{
"artist": "Subhumans",
"album": "Live In A Dive",
"name": "All Gone Dead",
"plays": 126
},
{
"artist": "Wheres The Pope?",
"album": "PSI",
"name": "Fear Of God",
"plays": 115
},
...
]](https://image.slidesharecdn.com/rethinkingstreamprocessingwithapachekafka-googledevfestswitzerland-michaelnoll-2017-10-28-v1-171030094944/75/Rethinking-Stream-Processing-with-Apache-Kafka-Applications-vs-Clusters-Streams-vs-Databases-Google-DevFest-Switzerland-2017-60-2048.jpg)






























































![60
$ curl -sXGET http://localhost:7070/kafka-music/charts/top-five
[
{
"artist": "Subhumans",
"album": "Live In A Dive",
"name": "All Gone Dead",
"plays": 126
},
{
"artist": "Wheres The Pope?",
"album": "PSI",
"name": "Fear Of God",
"plays": 115
},
...
]](https://crownmelresort.com/image.slidesharecdn.com/rethinkingstreamprocessingwithapachekafka-googledevfestswitzerland-michaelnoll-2017-10-28-v1-171030094944/75/Rethinking-Stream-Processing-with-Apache-Kafka-Applications-vs-Clusters-Streams-vs-Databases-Google-DevFest-Switzerland-2017-60-2048.jpg)






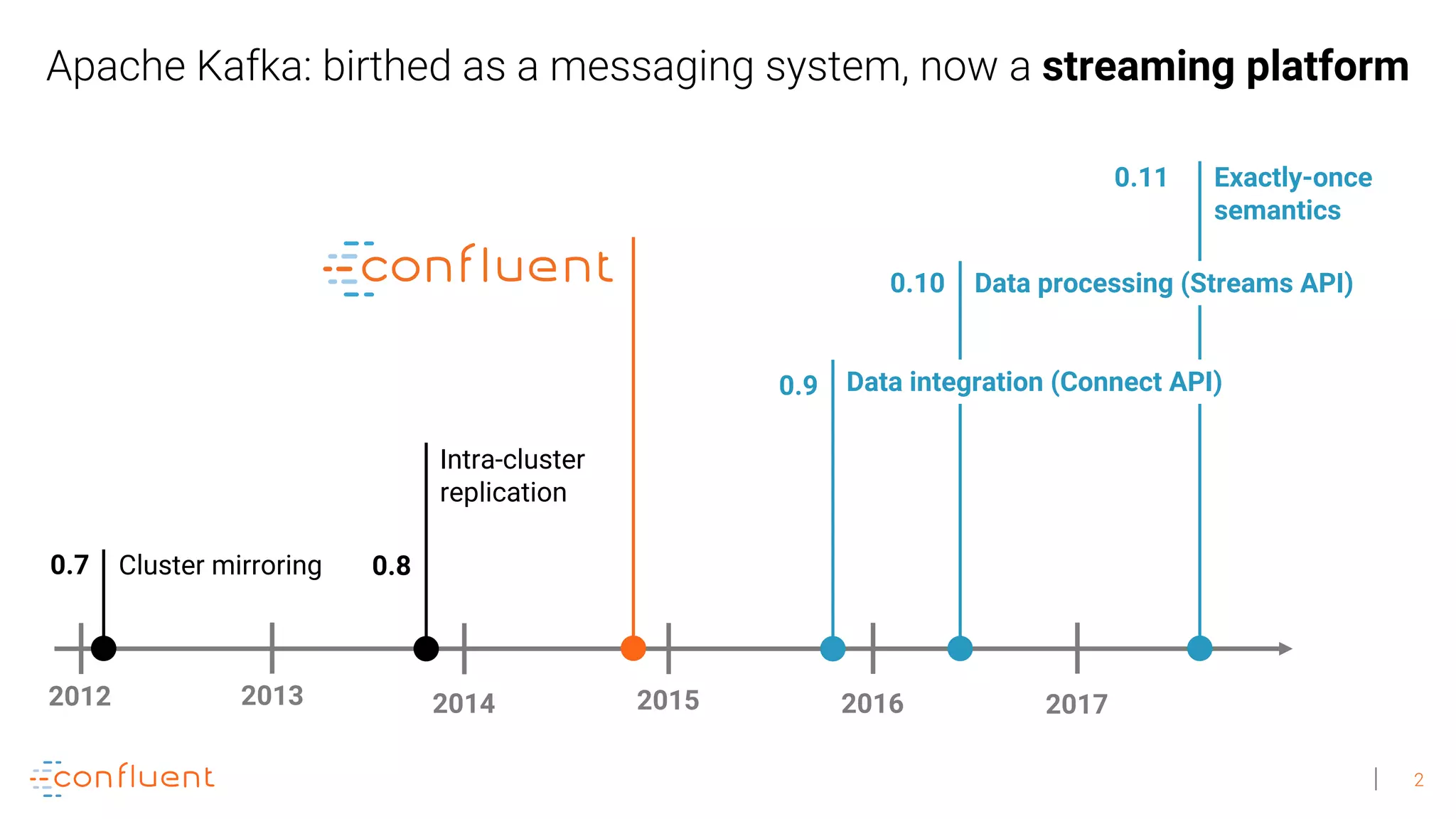
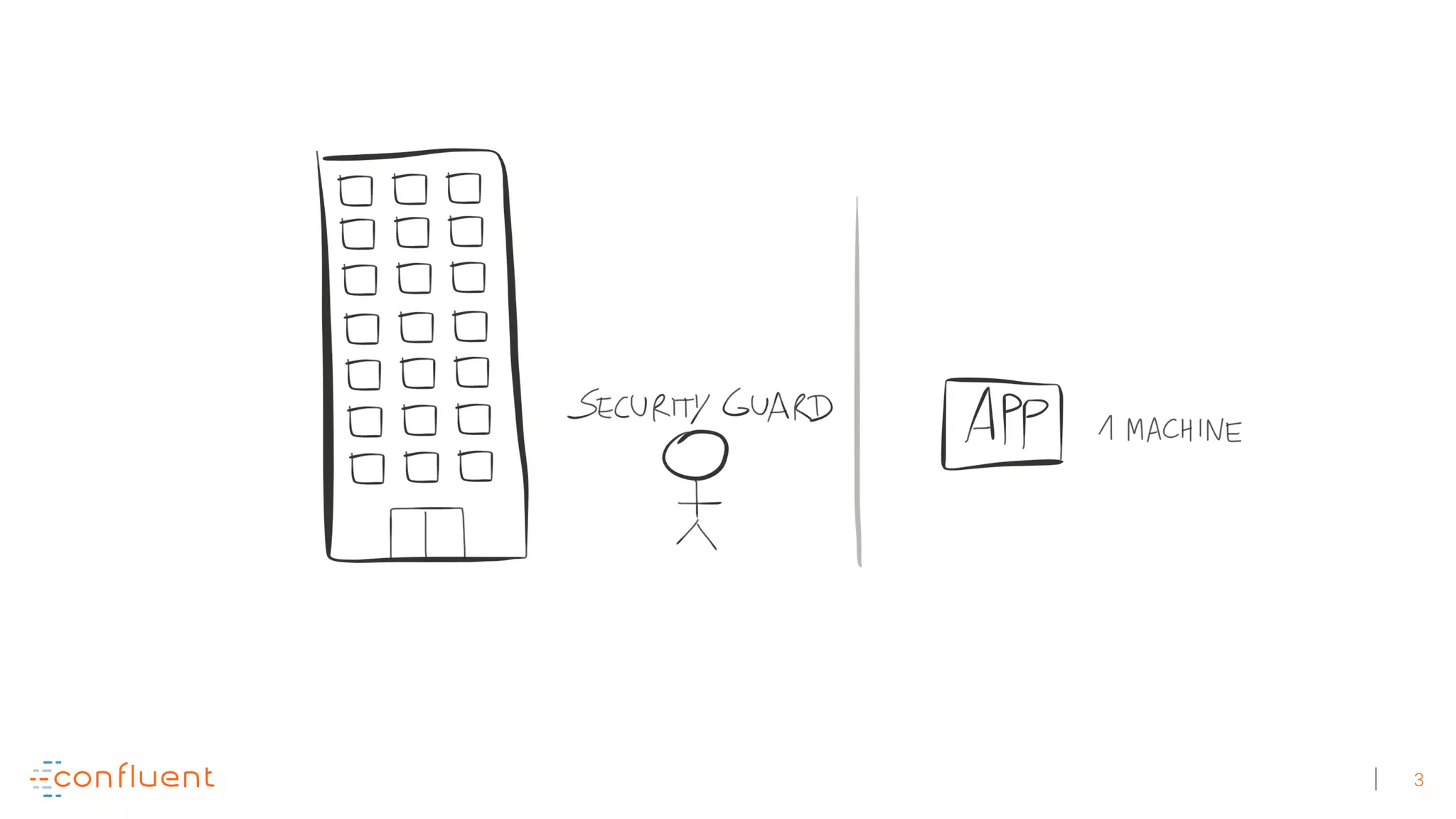
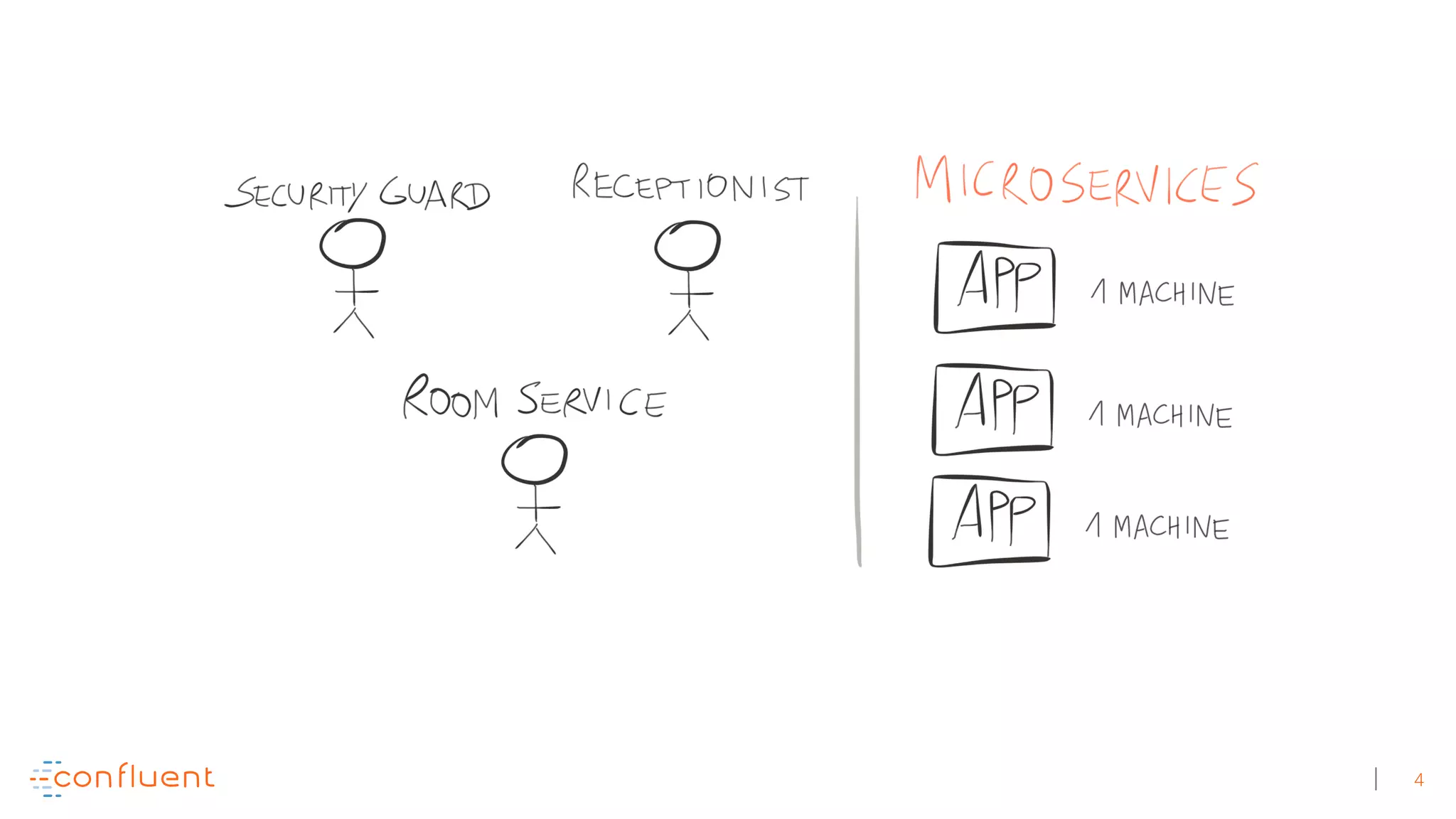
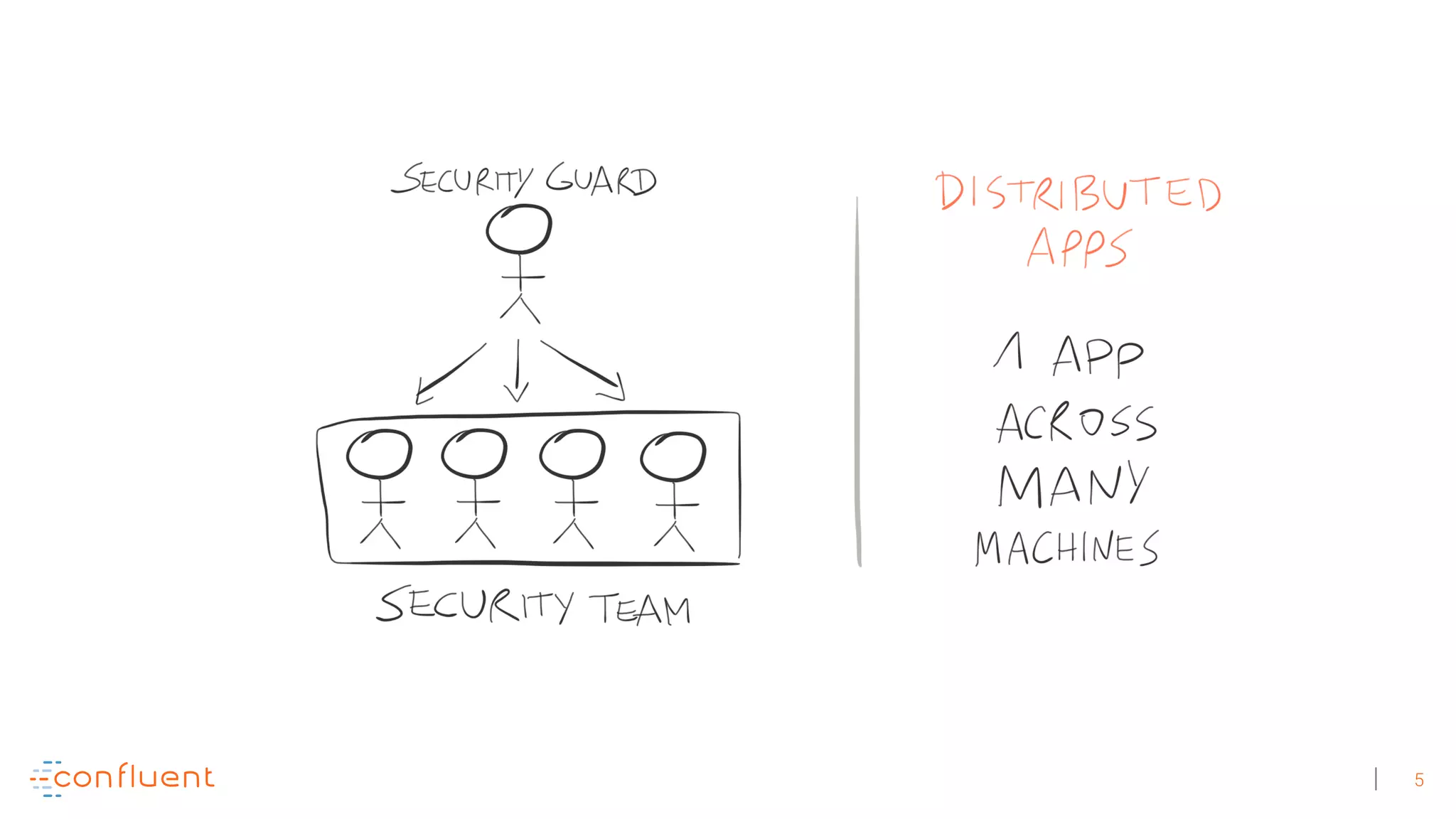
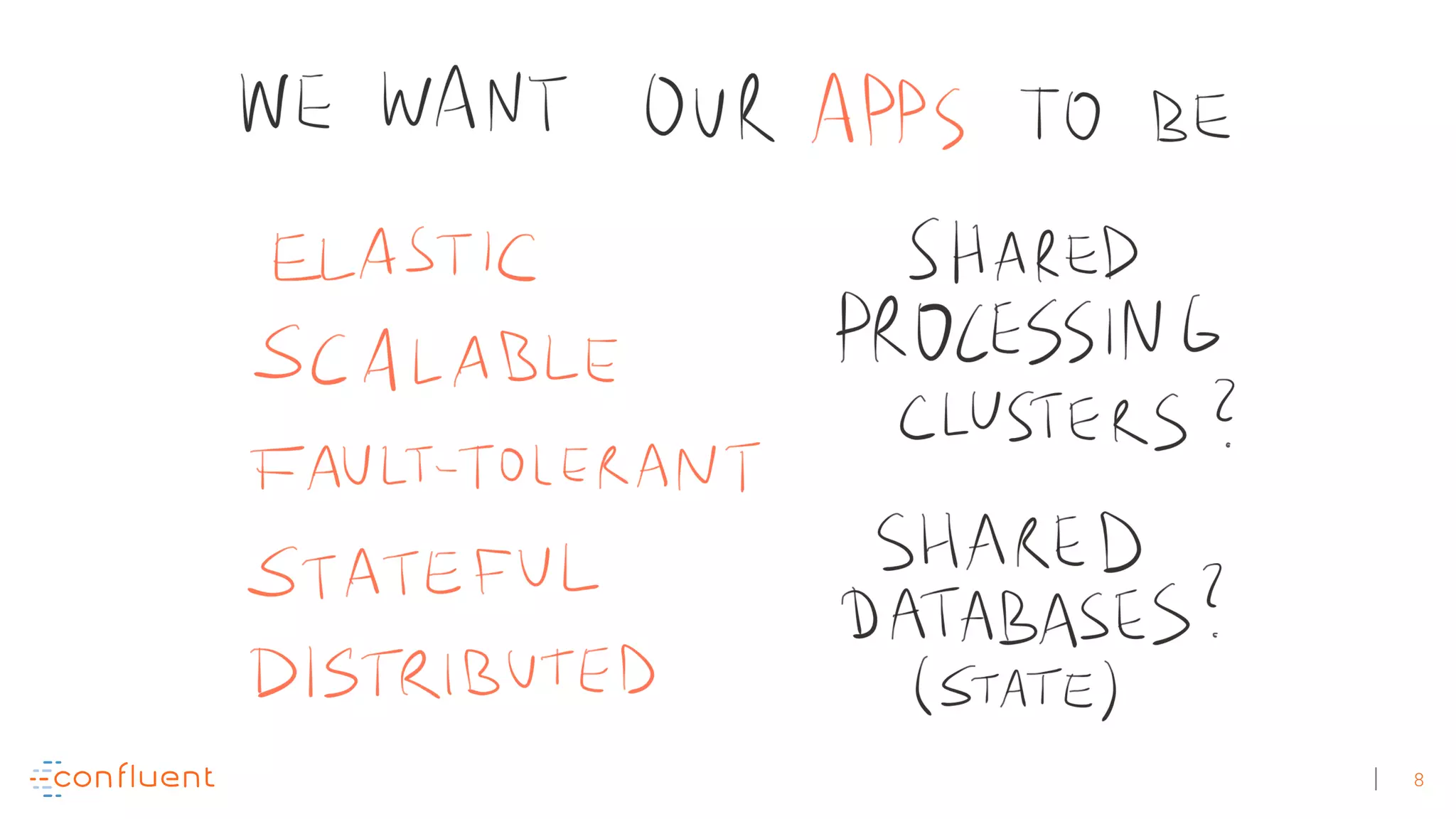
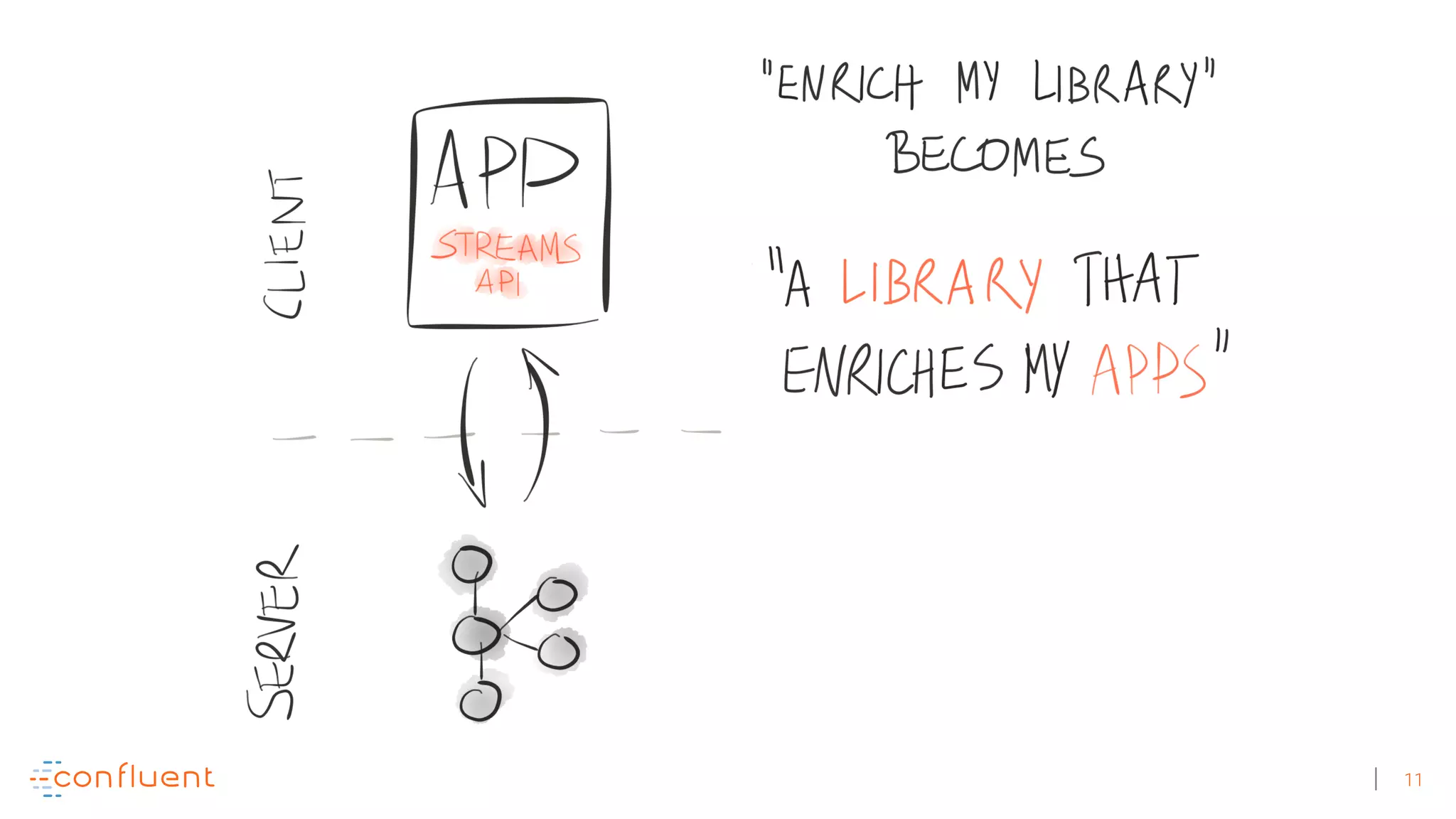
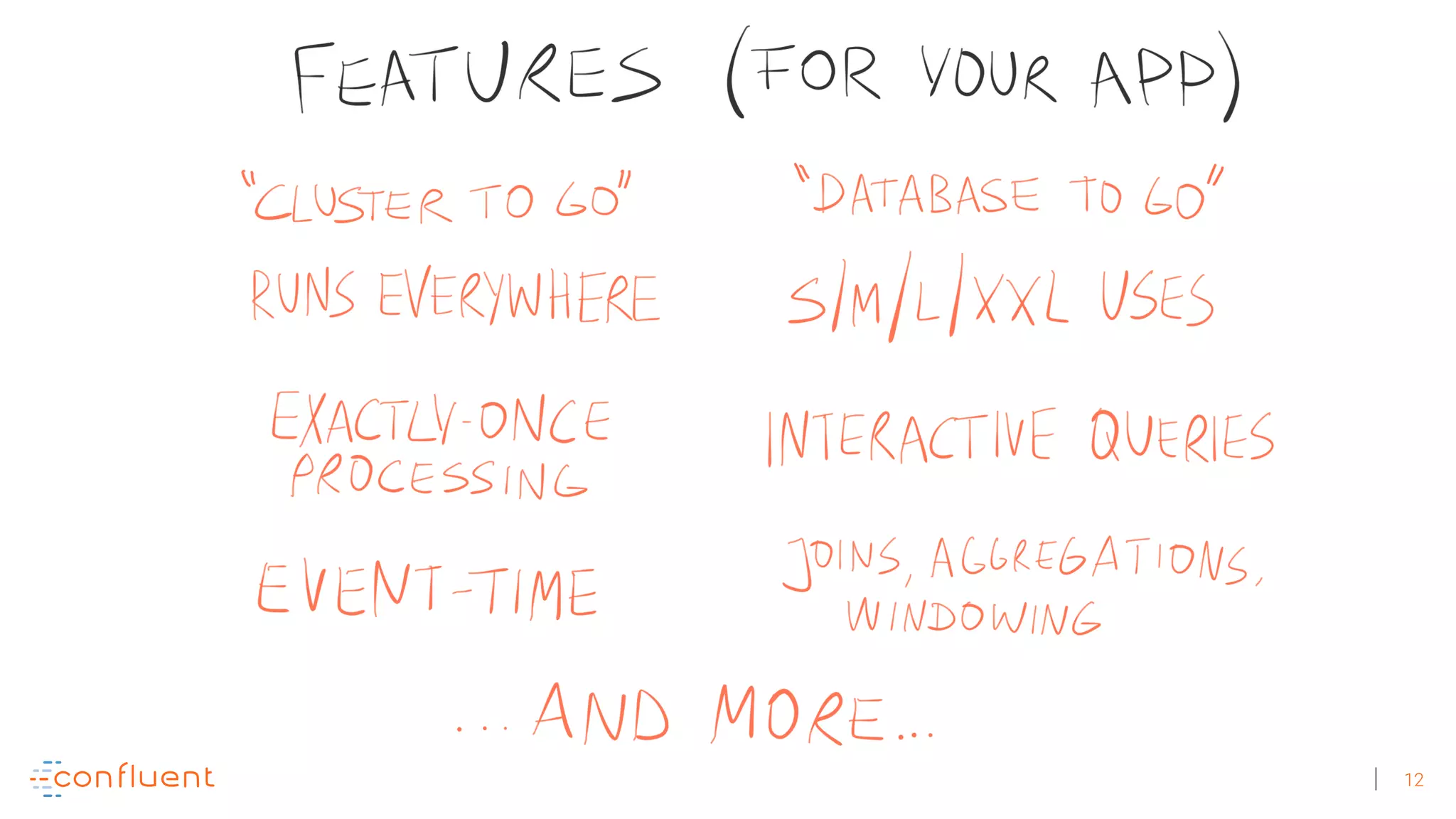
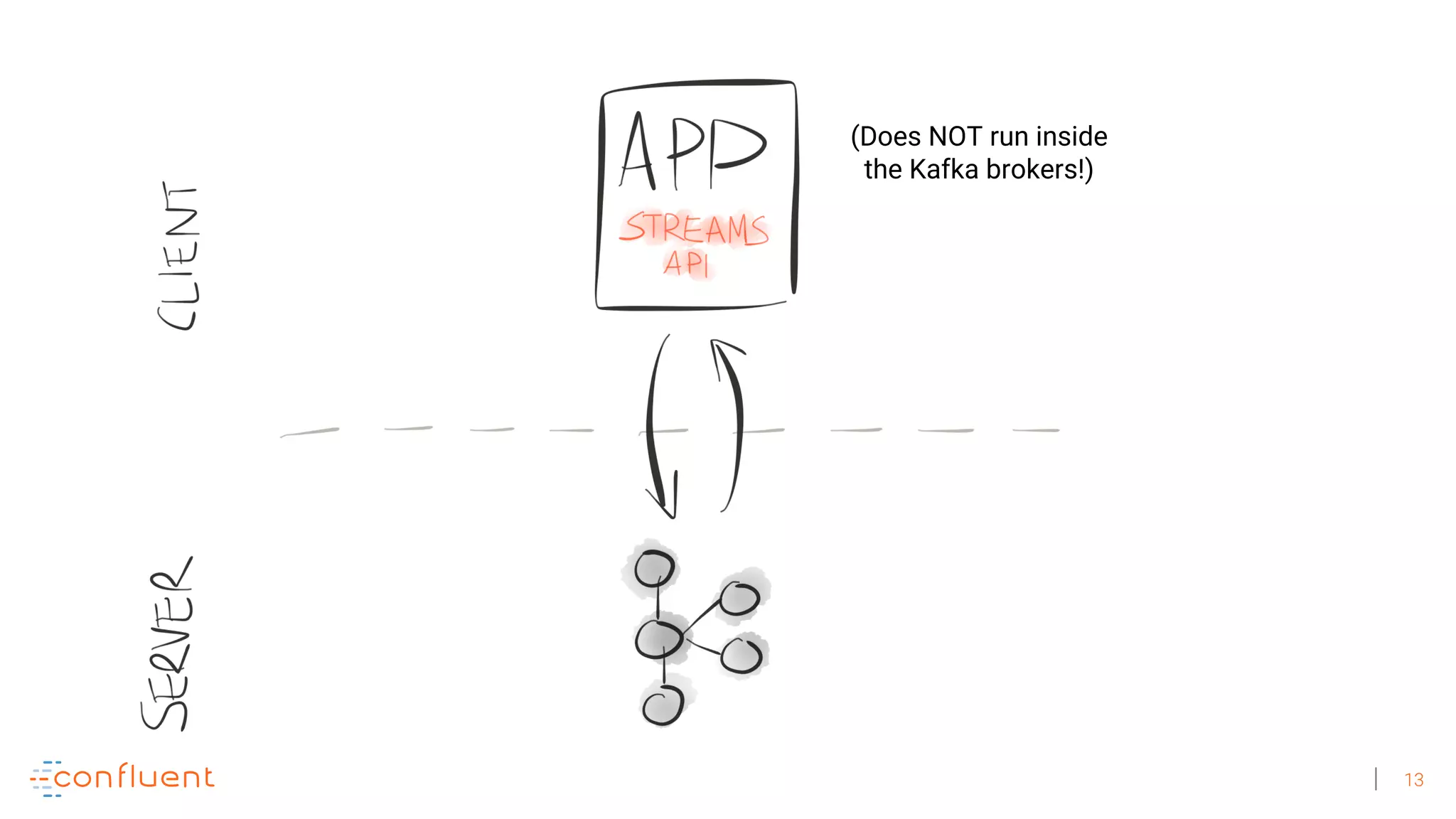
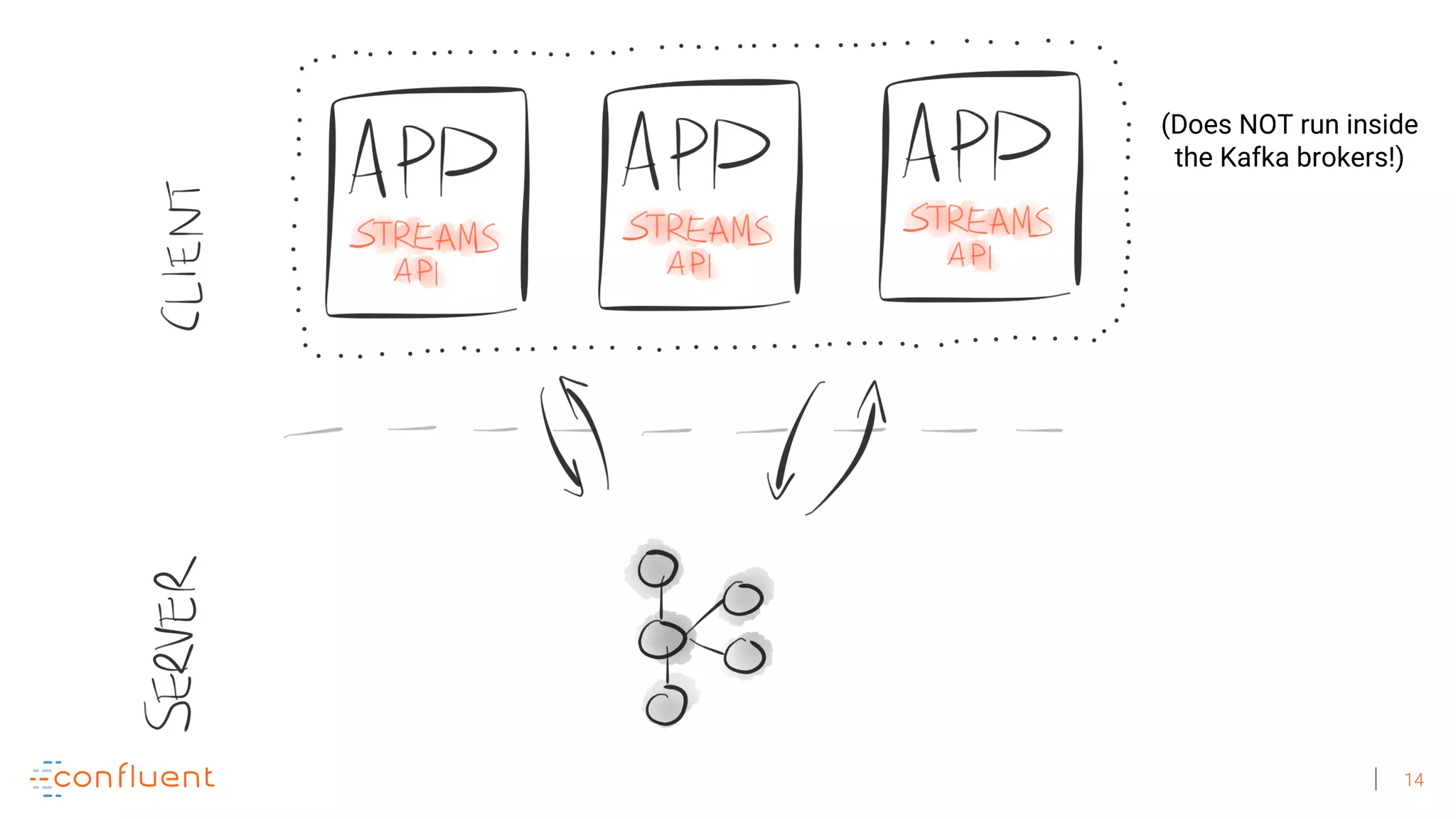
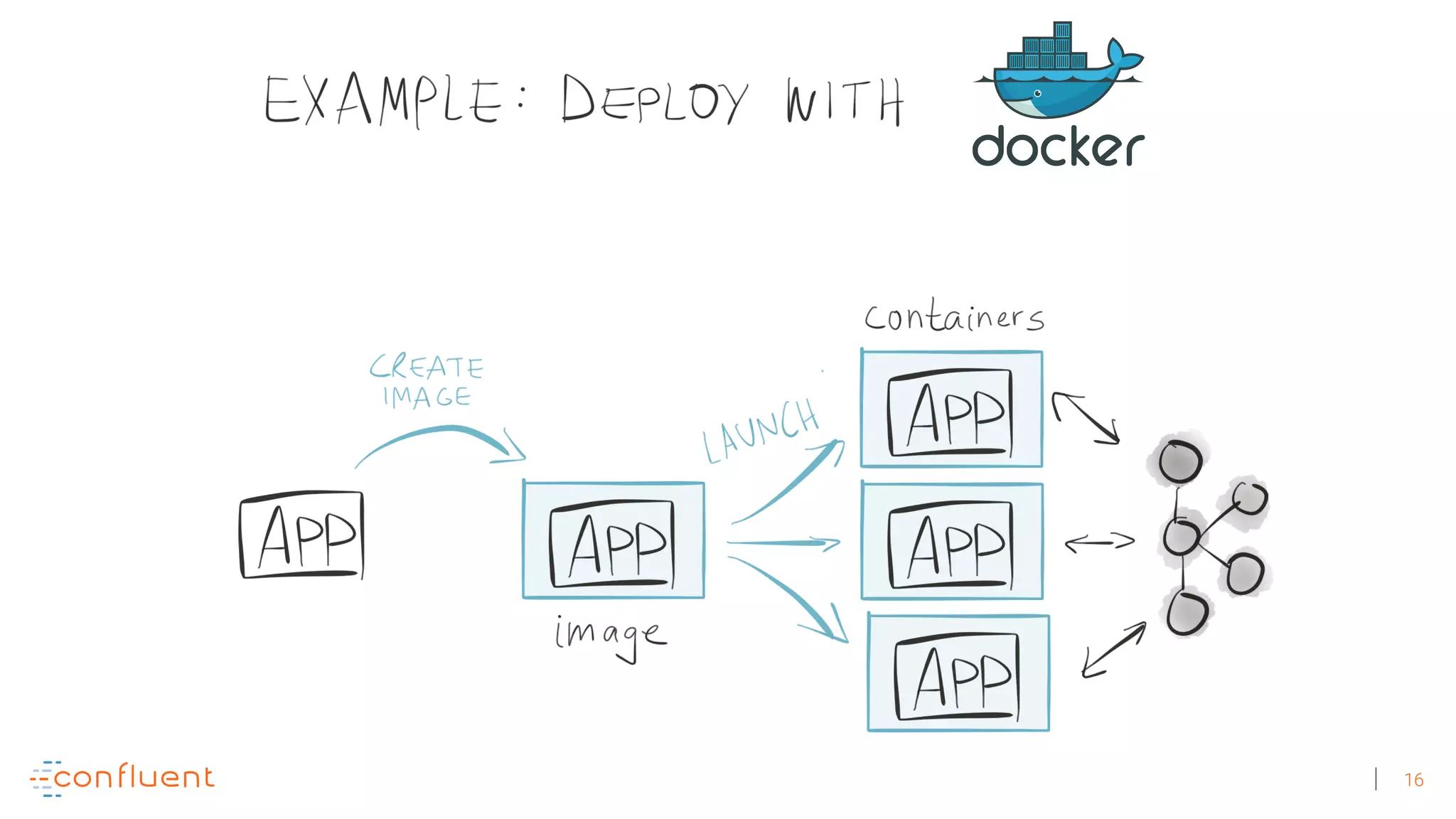
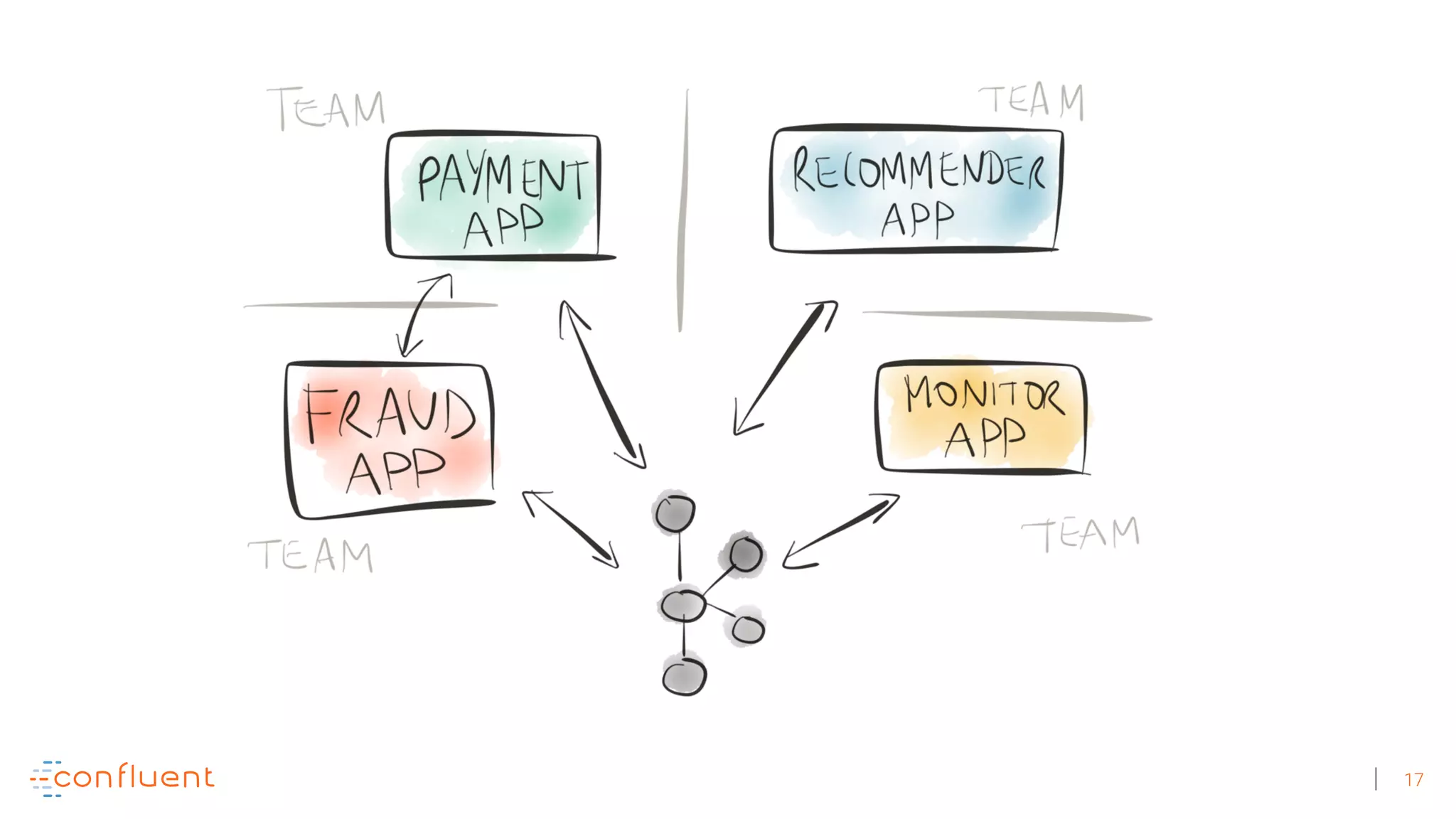
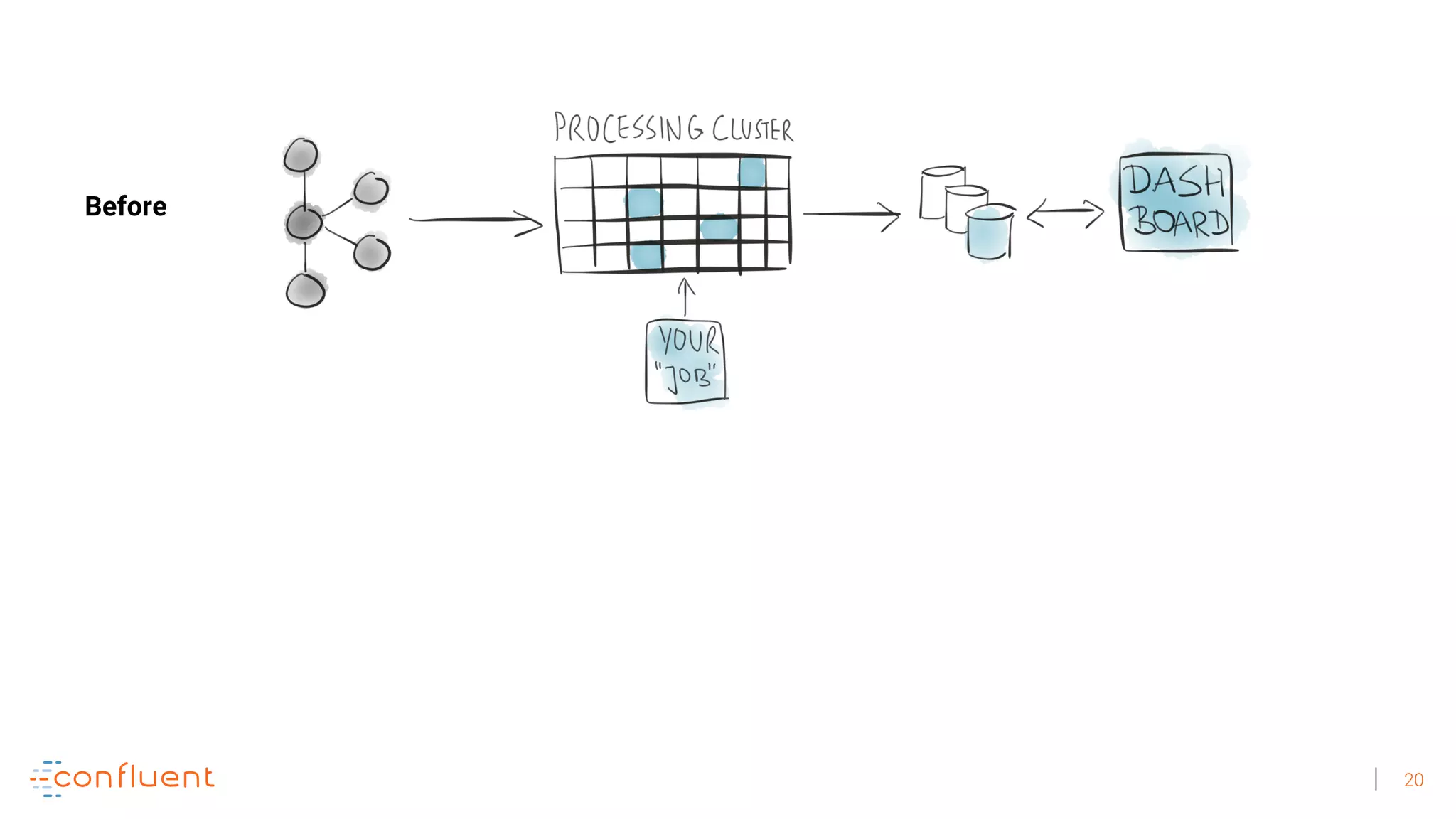
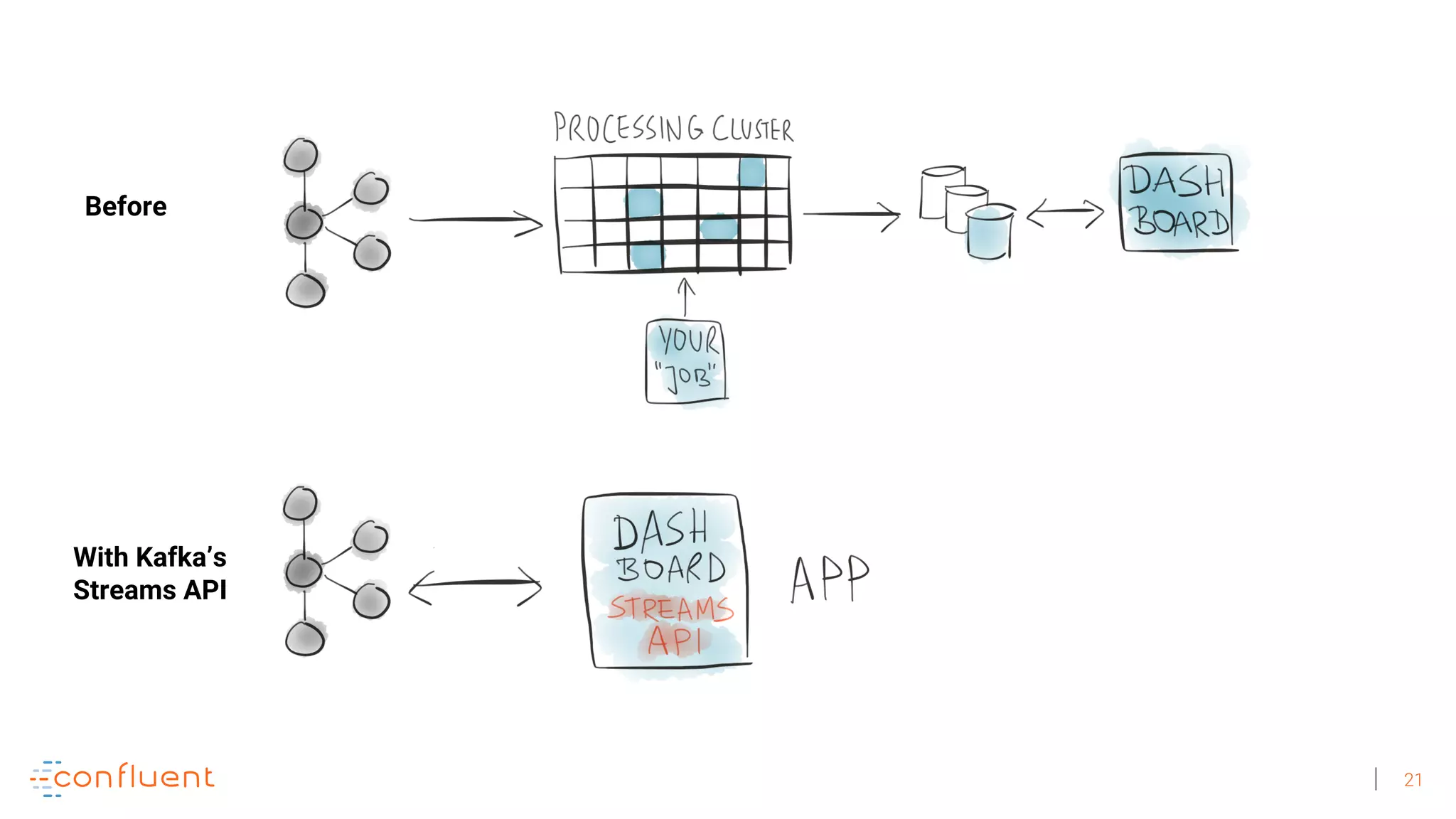
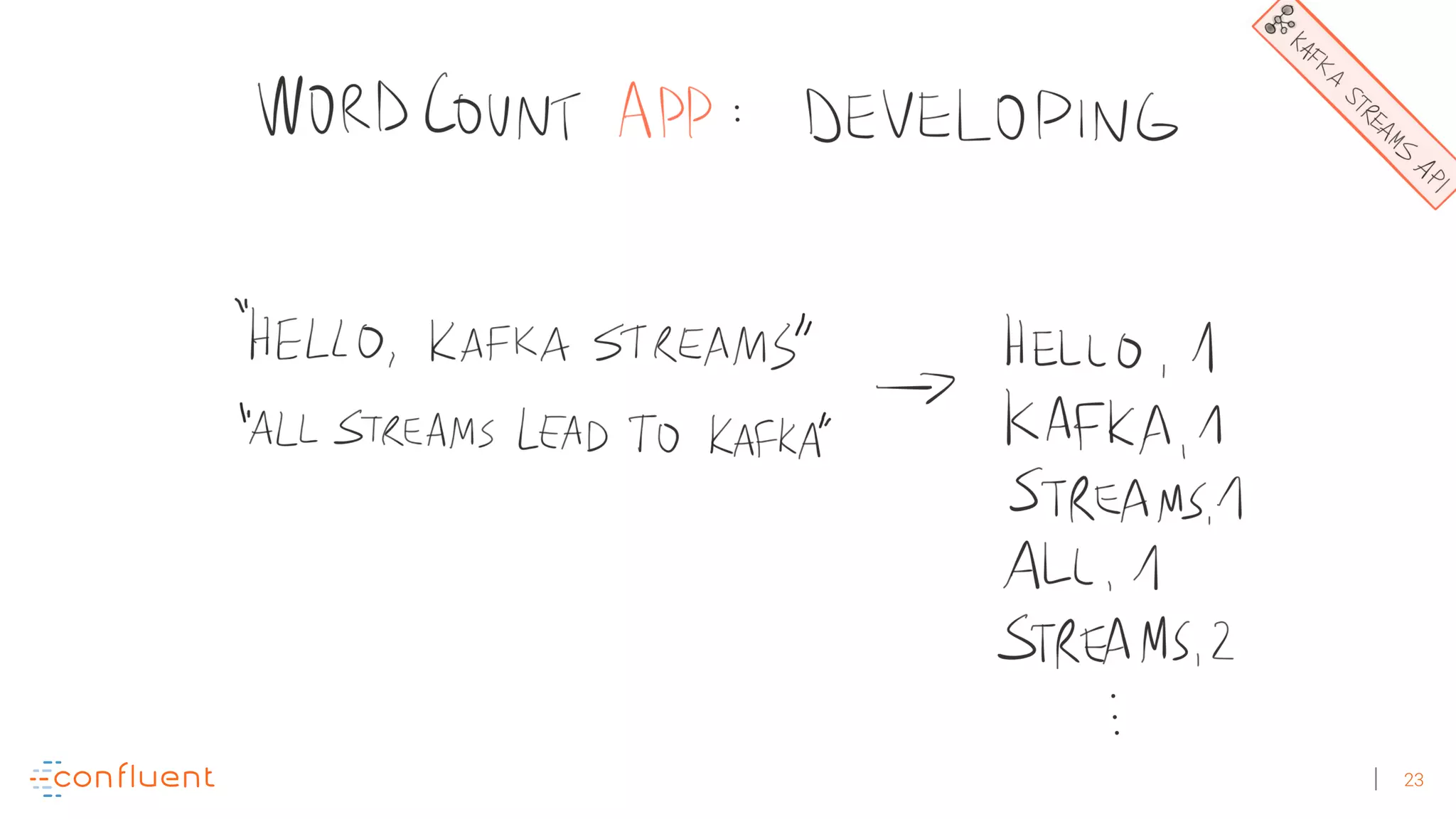
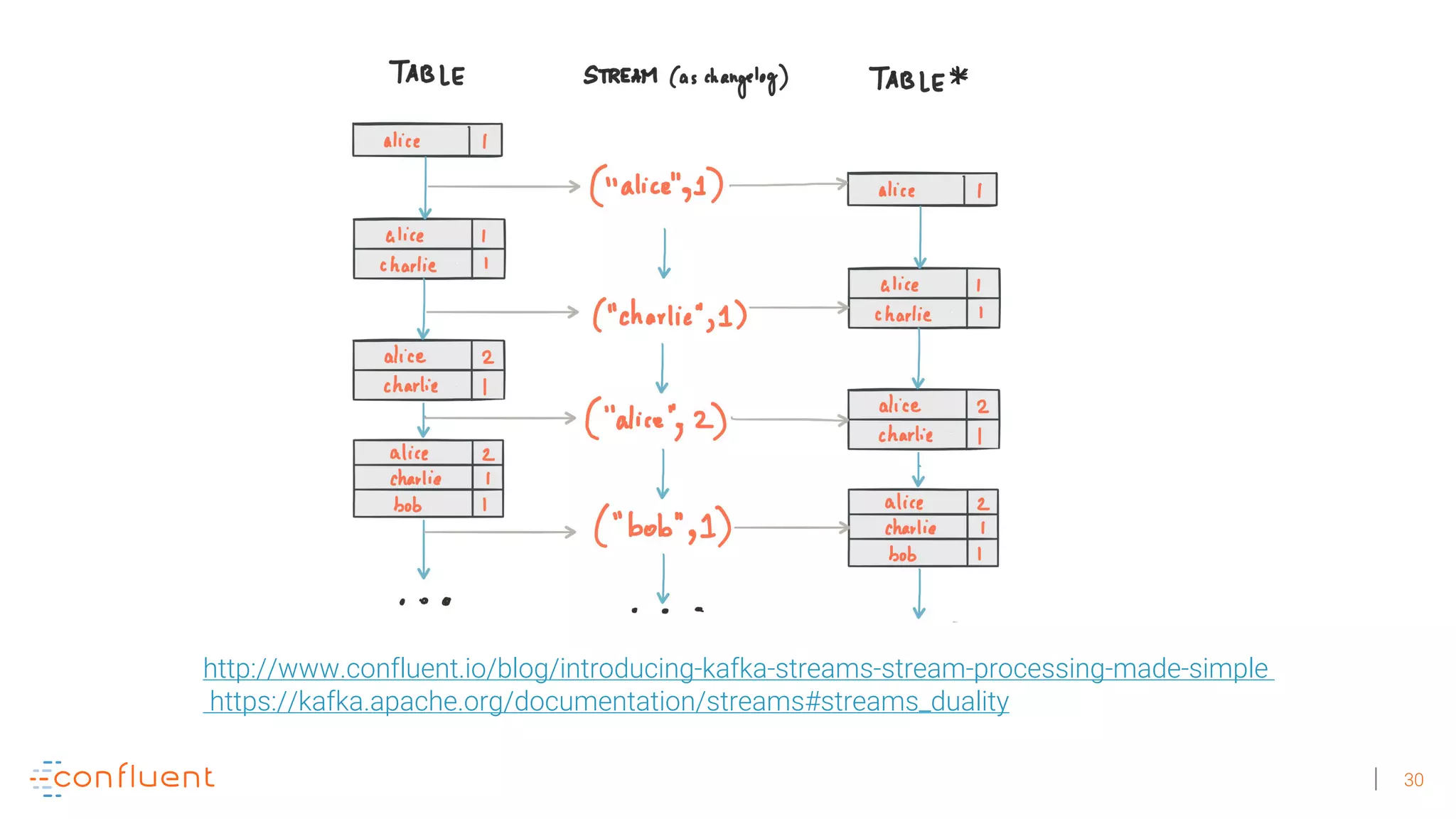
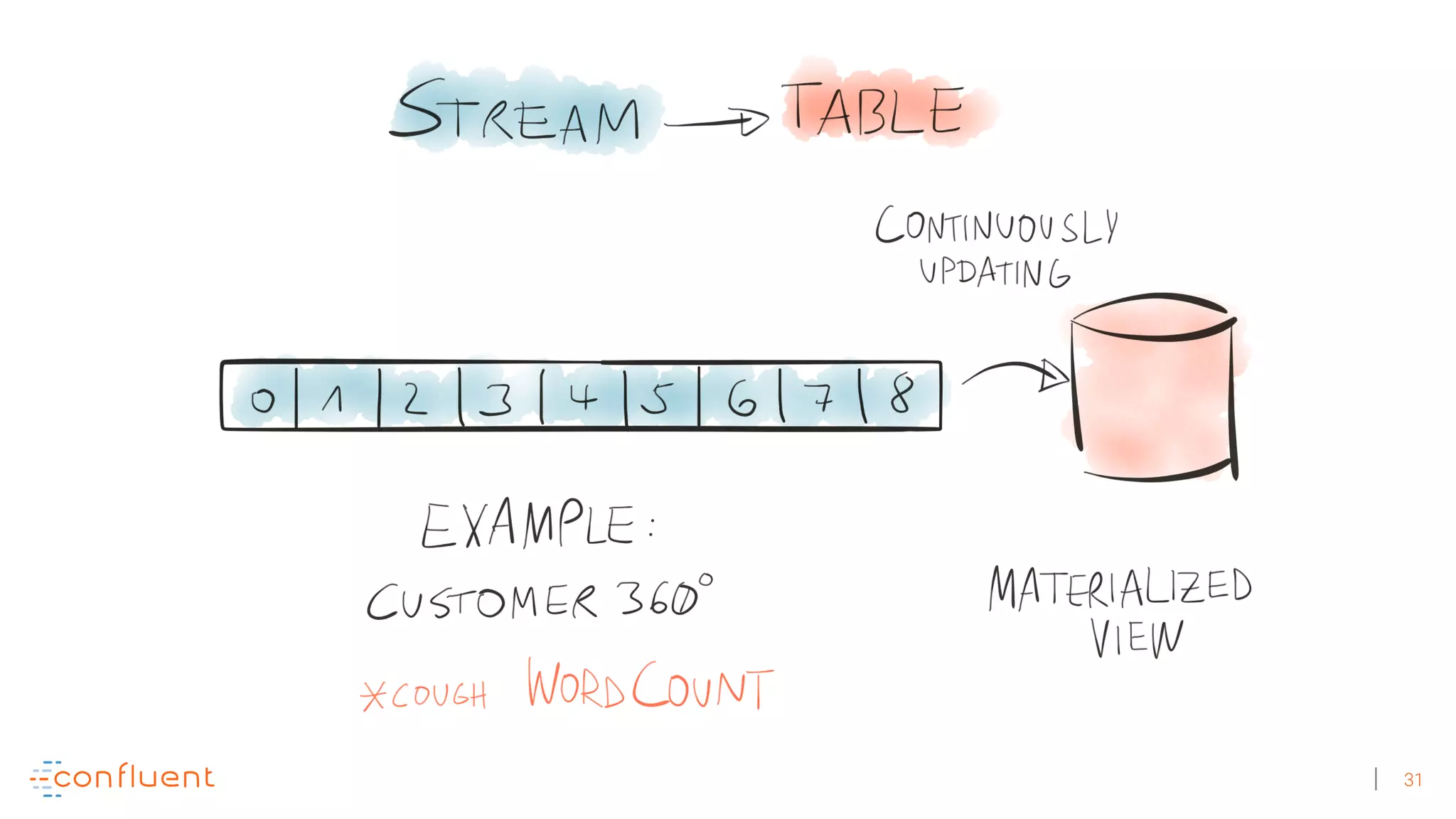
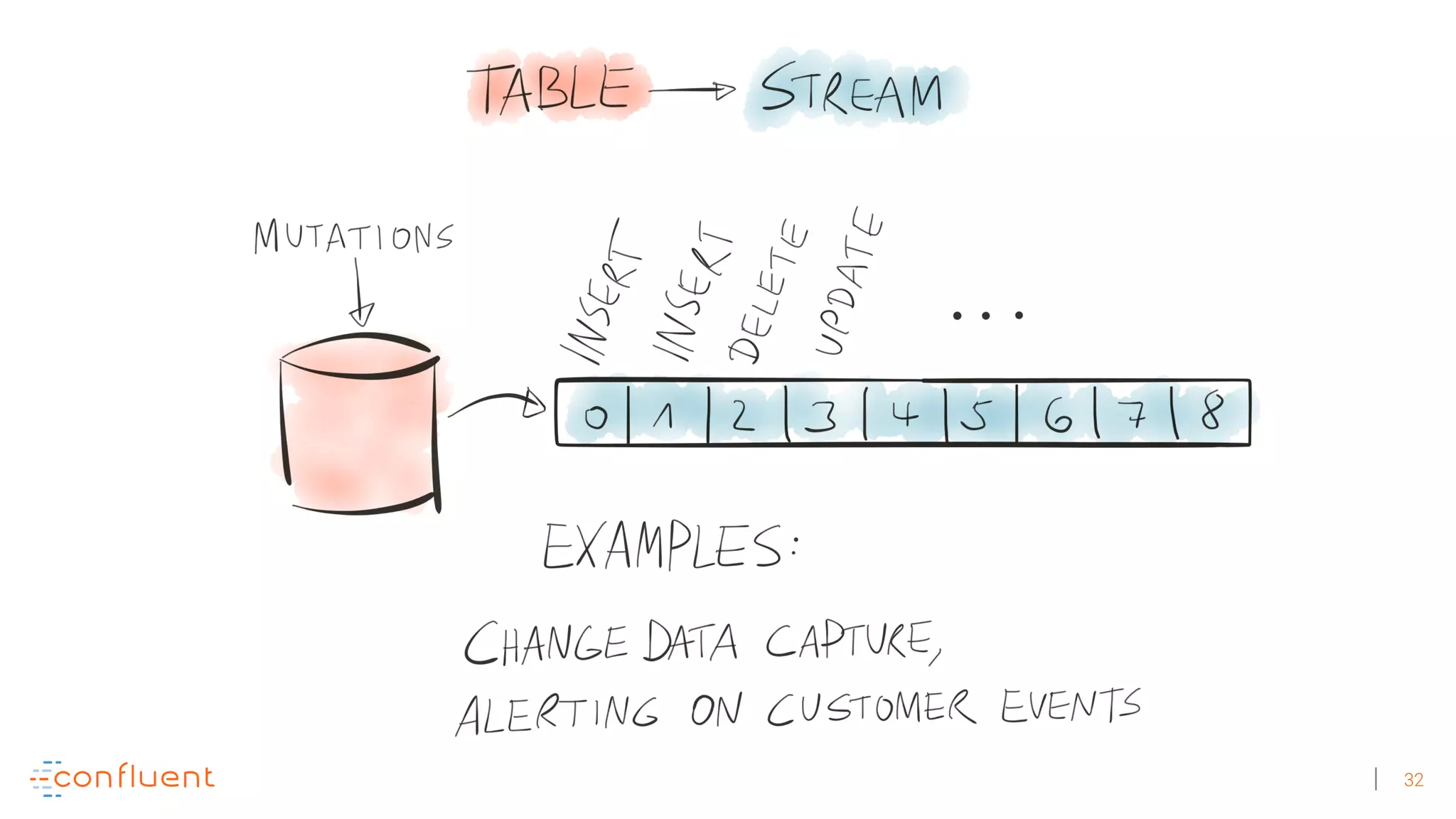
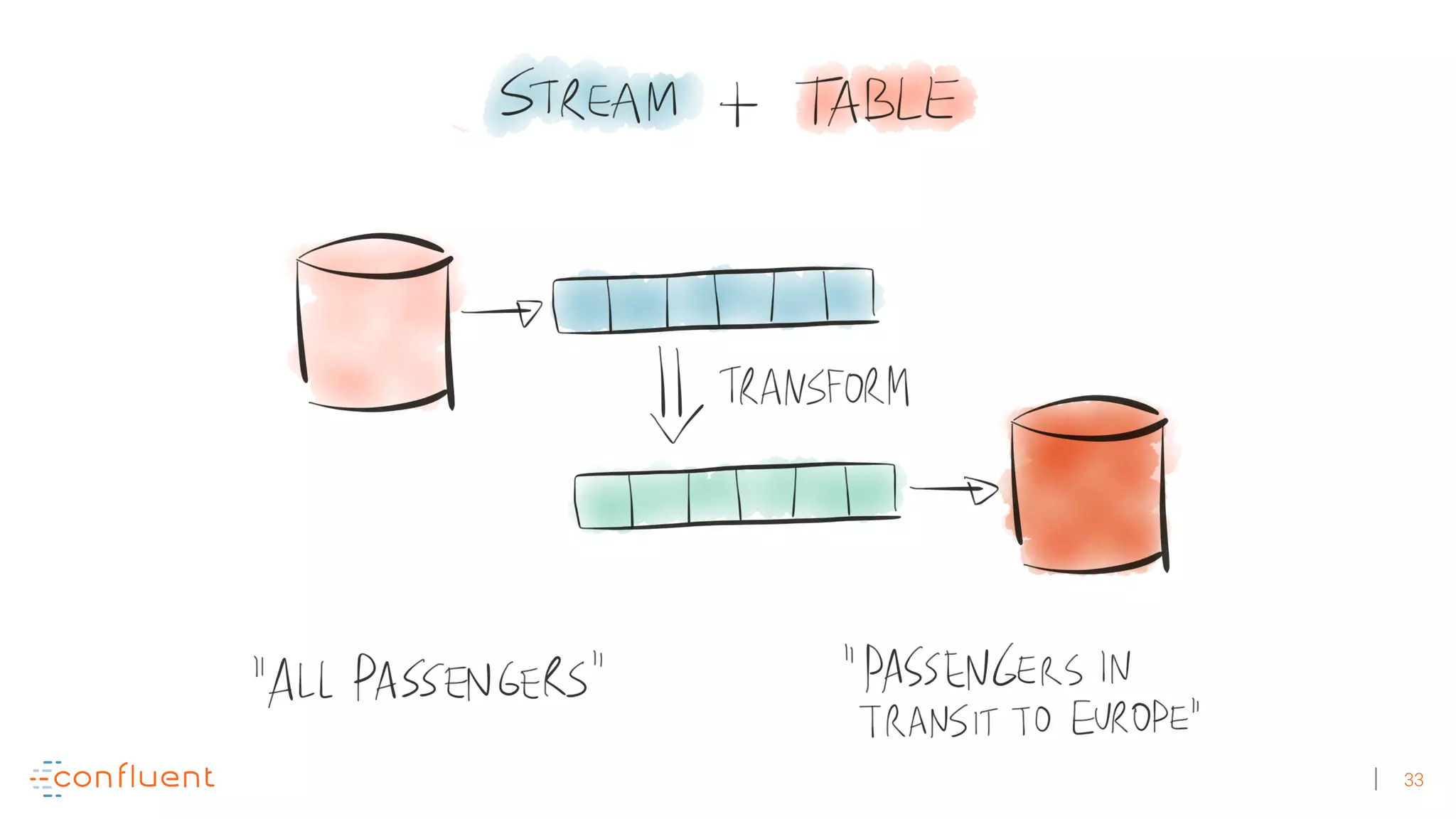
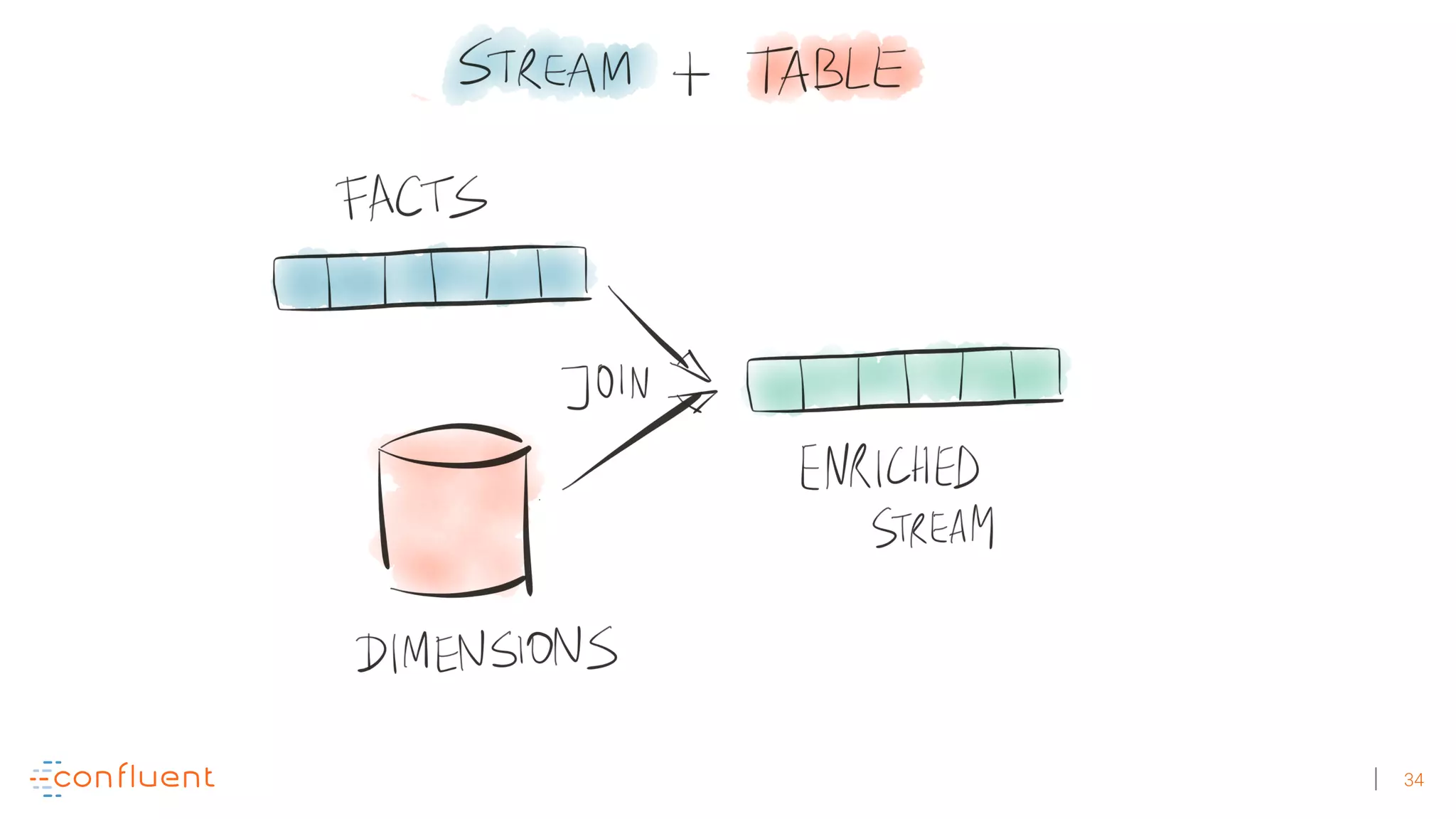
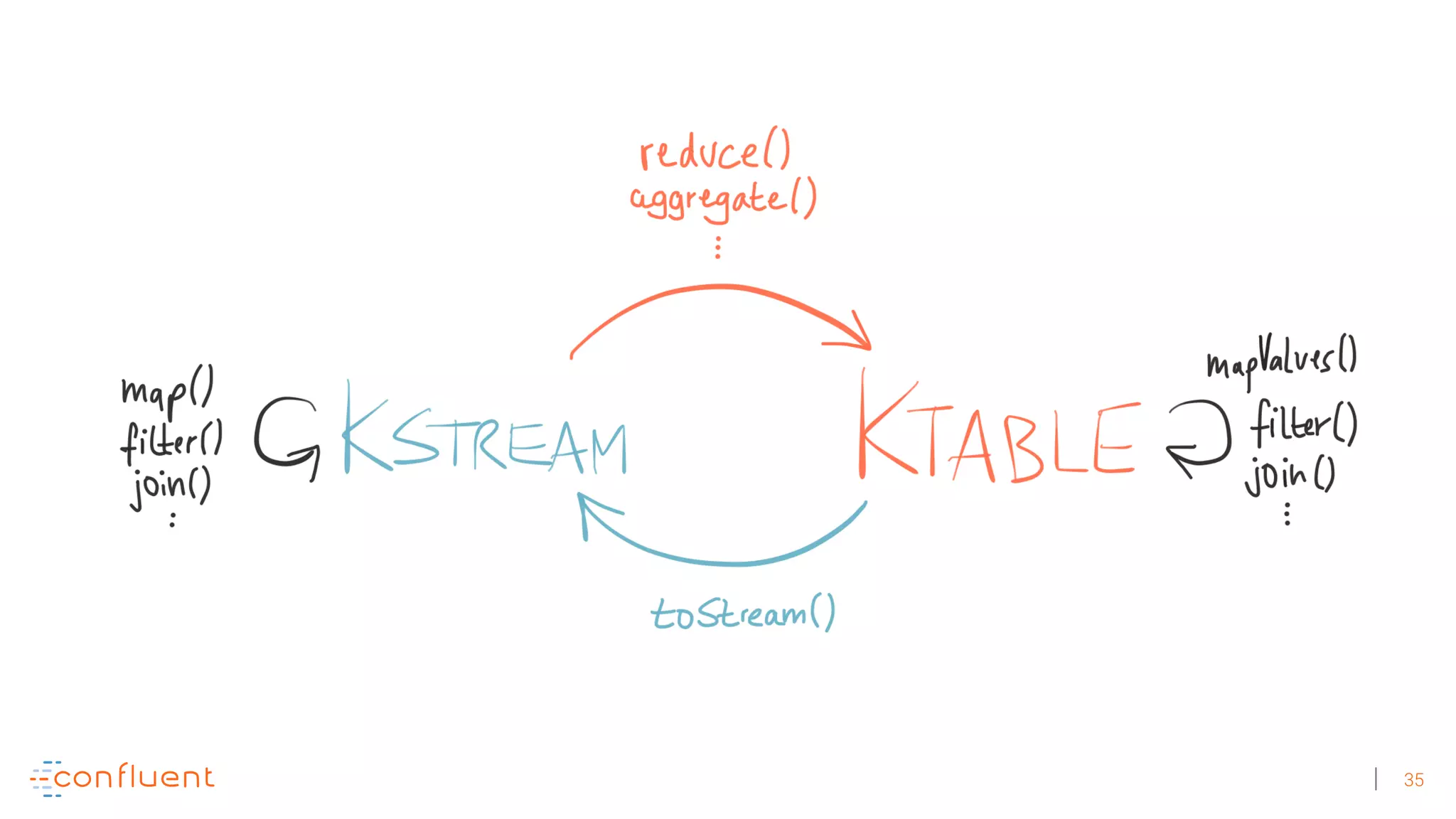
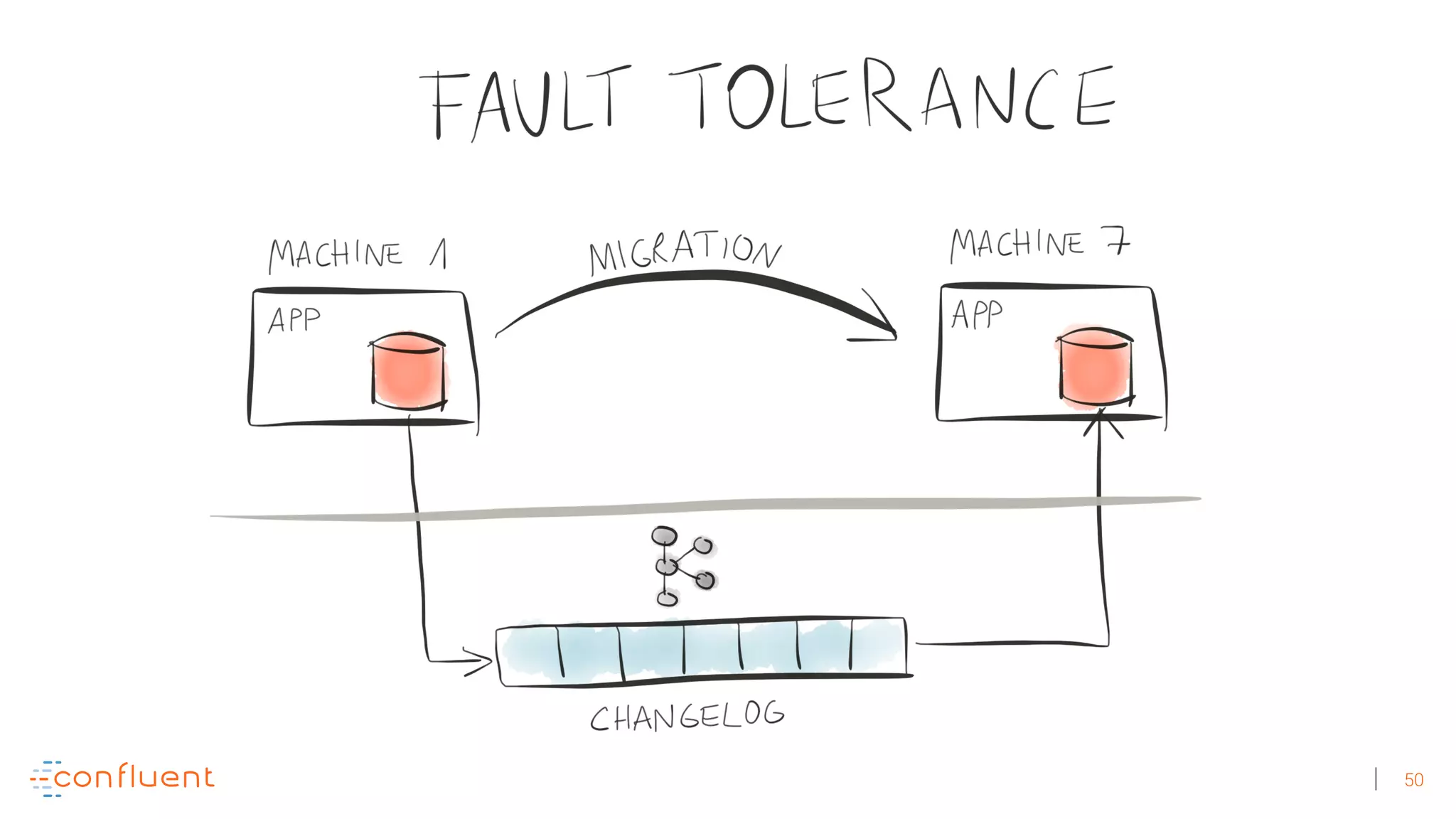
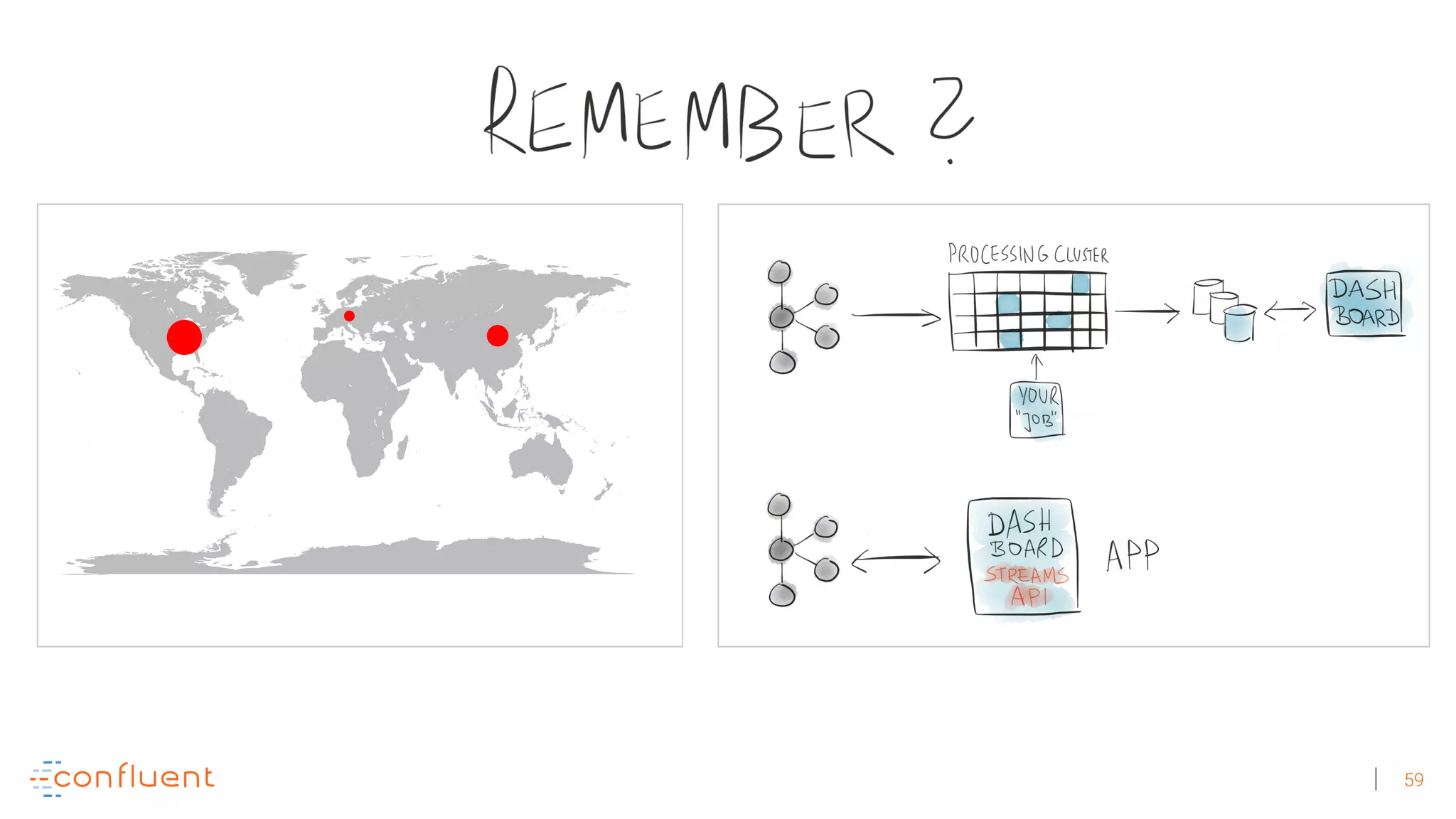
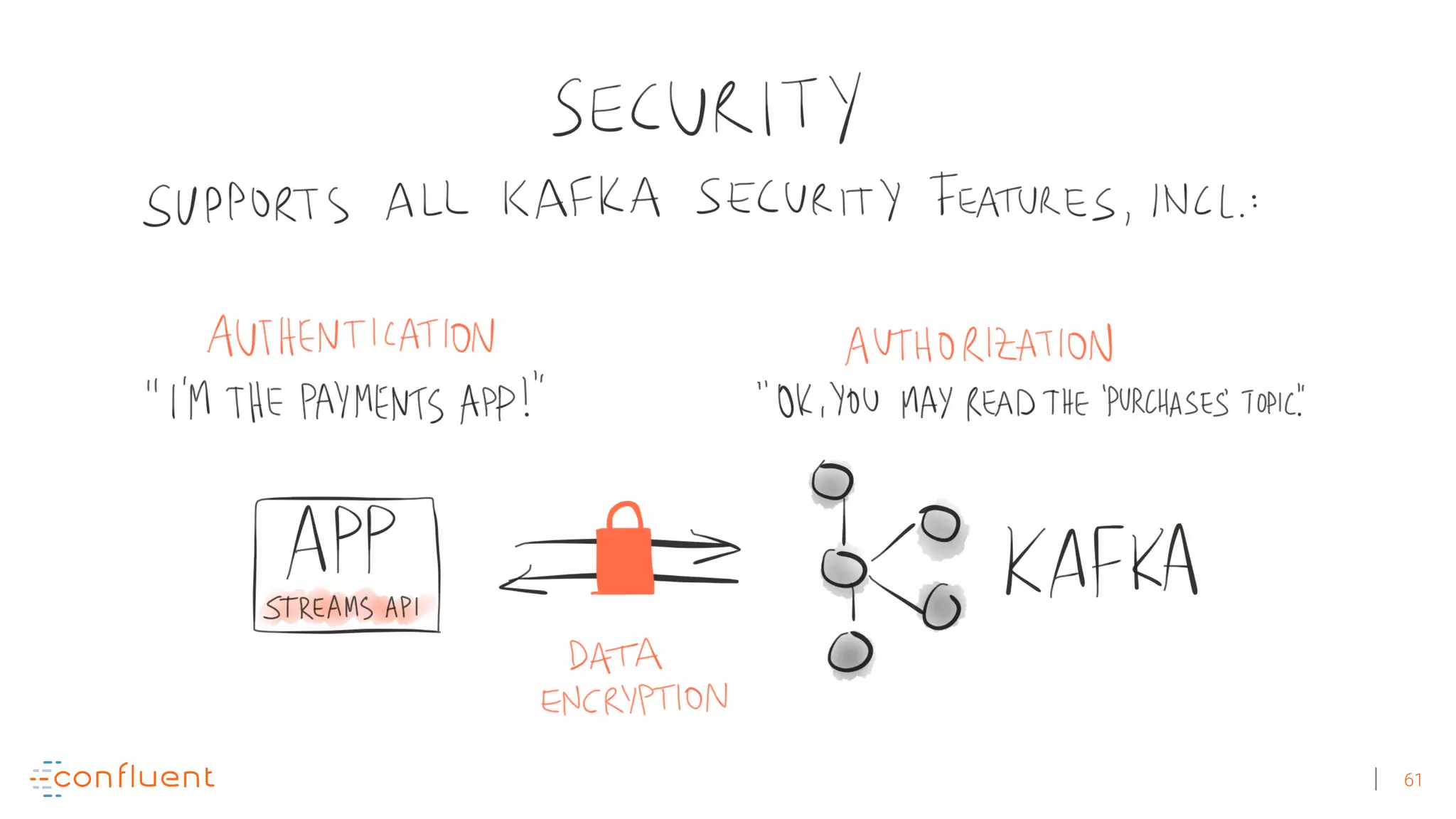
The document discusses the evolution of Apache Kafka from a messaging system to a comprehensive streaming platform, highlighting its capabilities such as exactly-once semantics and various APIs. It emphasizes the use of Kafka Streams for real-time data processing and provides examples of stream processing with code snippets. Additionally, it introduces KSQL, a streaming SQL engine that allows users to process data using SQL without needing separate processing clusters.


















































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)















