Downloaded 35 times

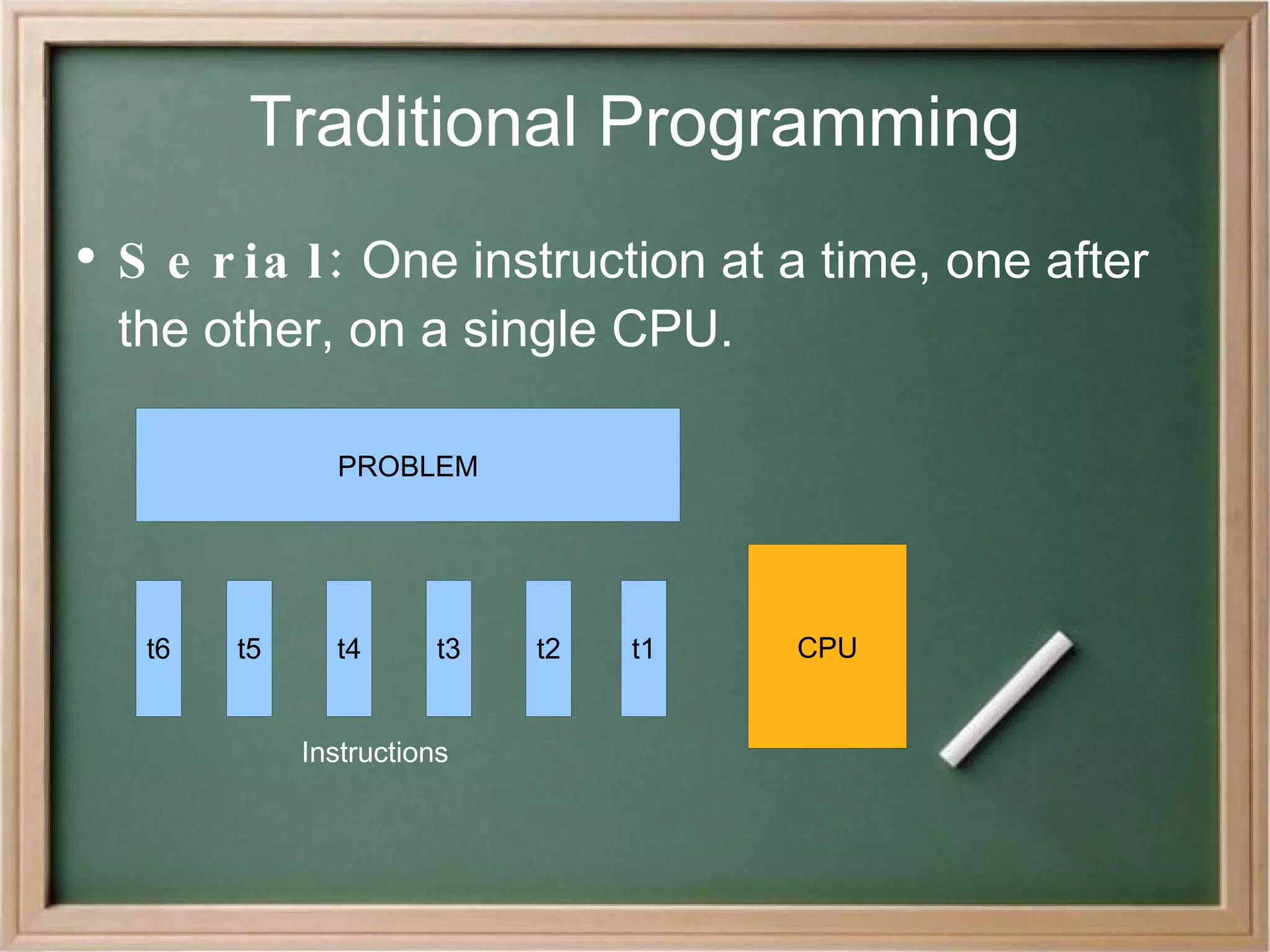
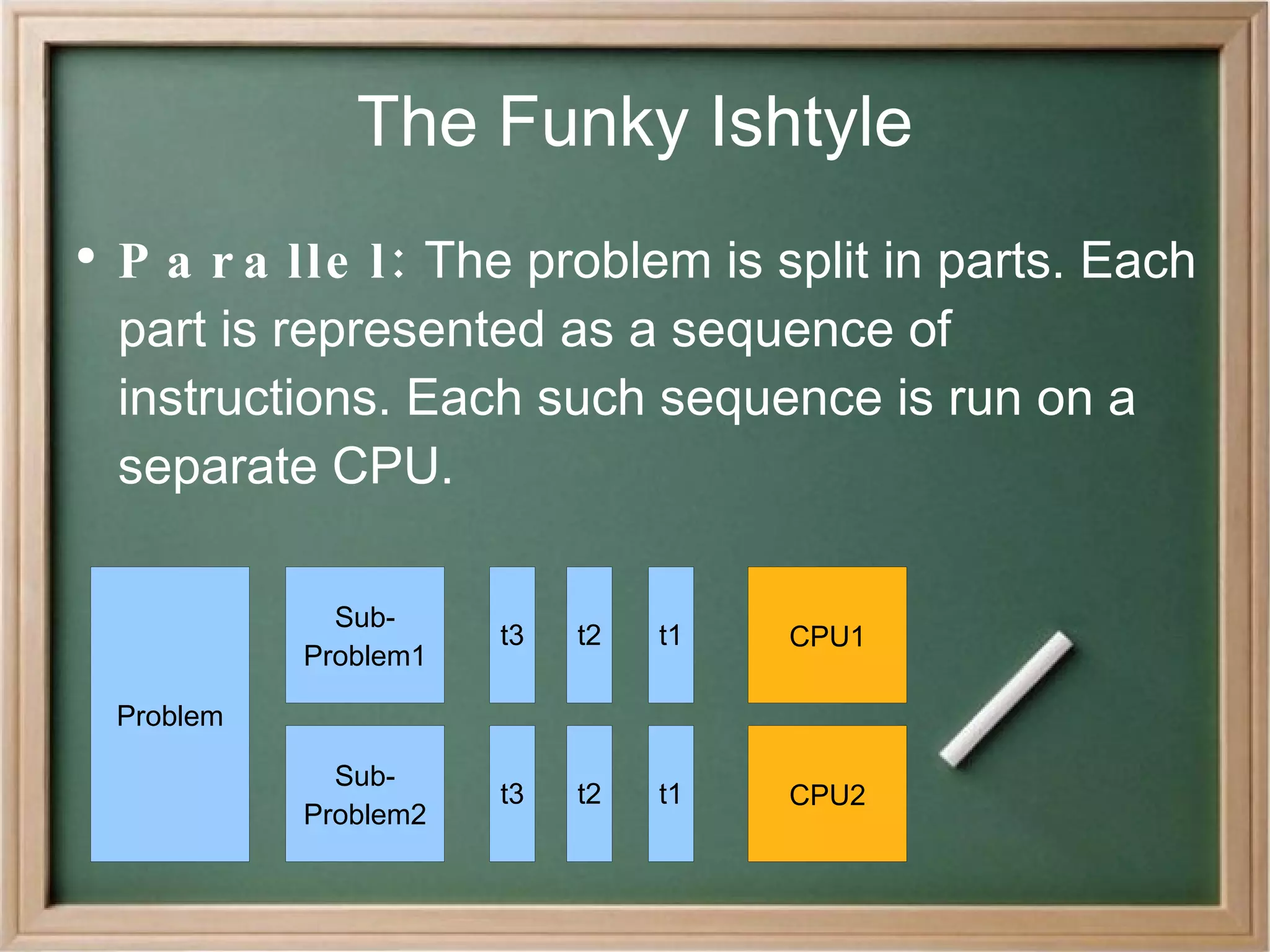
































































The document discusses parallel programming and message passing as a parallel programming model. It provides examples of using MPI (Message Passing Interface) and MapReduce frameworks for parallel programming. Some key applications discussed are financial risk assessment, molecular dynamics simulations, rendering animation, and web indexing. Challenges with parallel programming include potential slowdown due to overhead and limitations of parallel speedup based on sequential fractions of programs.














































![SHS_Core_CAE_Q3_LE1 FOR THIRD [FINAL].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/shscorecaeq3le1final-251116055110-e3081055-thumbnail.jpg?width=640&height=640&fit=bounds)


















