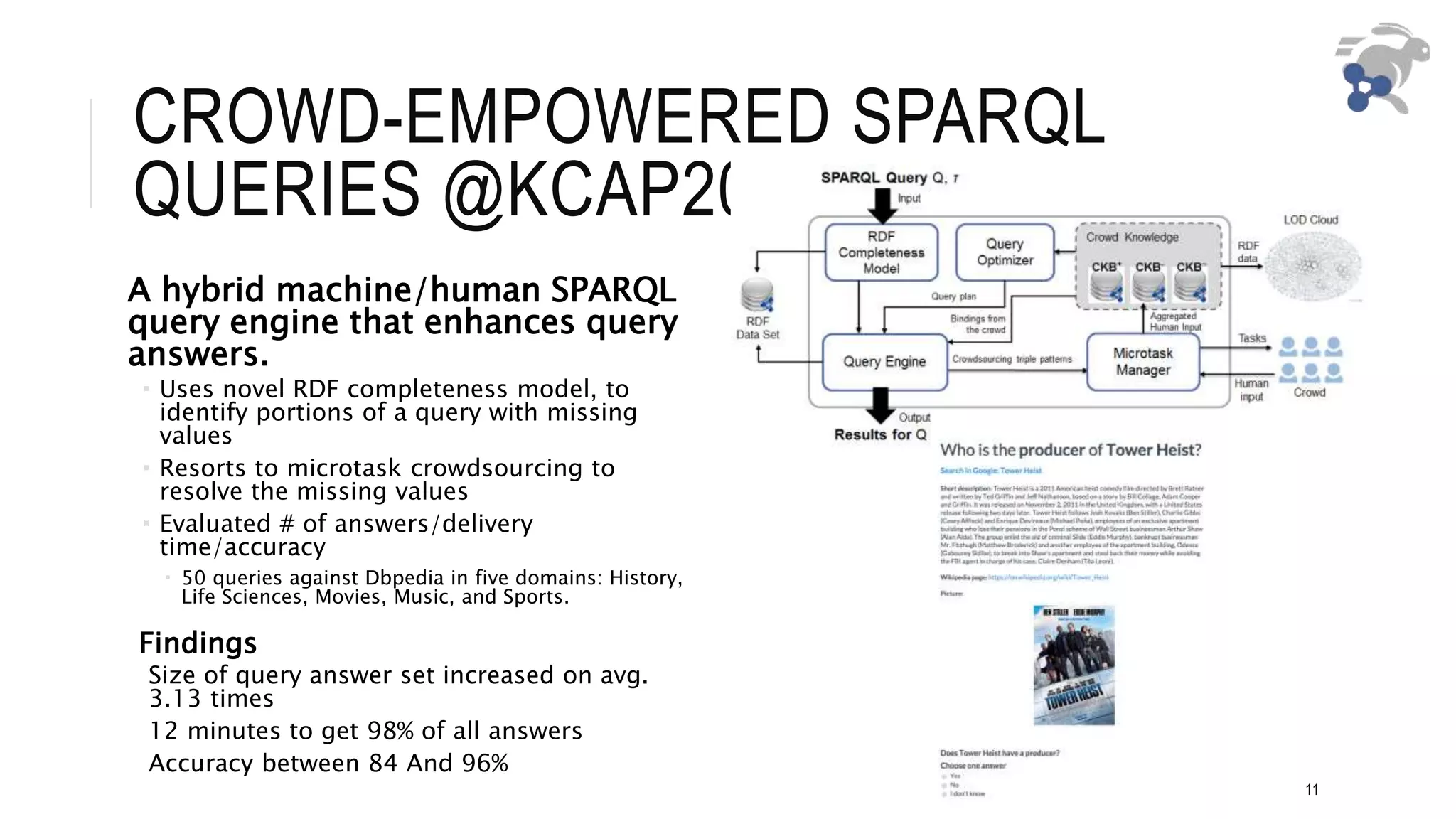
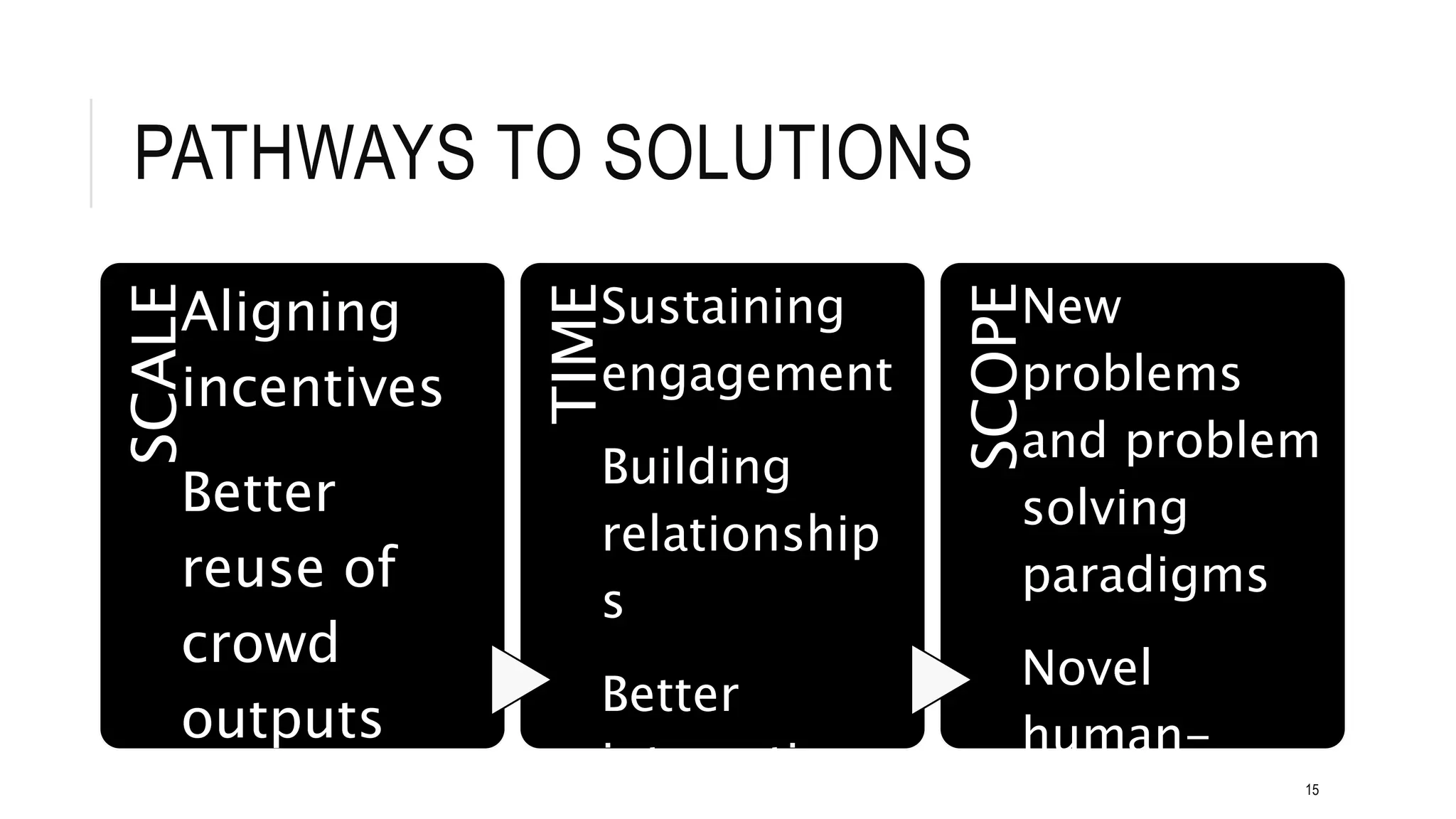
This document discusses crowdsourcing approaches for solving problems in semantic web technology. It defines crowdsourcing and the semantic web. There are many challenges to using crowdsourcing effectively for semantic web tasks, such as determining the appropriate form of crowdsourcing for different tasks, how to combine crowd and machine intelligence, and how to encourage participation. The document reviews different forms of crowdsourcing projects and discusses factors to consider in task design, quality assurance, and incentives. It also summarizes some research on improving paid microtasks and hybrid crowd-machine approaches. Several open questions are raised about the fundamental challenges of using crowdsourcing at the necessary scale, scope and sustainability for knowledge-intensive semantic web problems.

![CROWDSOURCING
PROBLEM SOLVING VIA OPEN CALLS
“Crowdsourcing represents the act of a company or
institution taking a function once performed by
employees and outsourcing it to an undefined (and
generally large) network of people in the form of an
open call. “
[Howe, 2006]
2](https://image.slidesharecdn.com/crowdsourcingsheffield2016-161118180749/75/One-does-not-simply-crowdsource-the-Semantic-Web-2-2048.jpg)
![THE SEMANTIC WEB
WEB OF DATA THAT CAN BE
PROCESSED BY MACHINES
3
“The Semantic Web provides a common framework
that allows data to be shared and reused across
application, enterprise, and community boundaries “
[W3C, 2011]](https://image.slidesharecdn.com/crowdsourcingsheffield2016-161118180749/75/One-does-not-simply-crowdsource-the-Semantic-Web-3-2048.jpg)


![DIFFERENT FORMS AND
PLATFORMS TO CHOOSE FROM
6
Macrotasks
Microtasks
Challenges
Self-organized crowds
Crowdfunding
Source:
[Prpić et al.,
2015]](https://image.slidesharecdn.com/crowdsourcingsheffield2016-161118180749/75/One-does-not-simply-crowdsource-the-Semantic-Web-6-2048.jpg)









![CROWDSOURCING
PROBLEM SOLVING VIA OPEN CALLS
“Crowdsourcing represents the act of a company or
institution taking a function once performed by
employees and outsourcing it to an undefined (and
generally large) network of people in the form of an
open call. “
[Howe, 2006]
2](https://crownmelresort.com/image.slidesharecdn.com/crowdsourcingsheffield2016-161118180749/75/One-does-not-simply-crowdsource-the-Semantic-Web-2-2048.jpg)
![THE SEMANTIC WEB
WEB OF DATA THAT CAN BE
PROCESSED BY MACHINES
3
“The Semantic Web provides a common framework
that allows data to be shared and reused across
application, enterprise, and community boundaries “
[W3C, 2011]](https://crownmelresort.com/image.slidesharecdn.com/crowdsourcingsheffield2016-161118180749/75/One-does-not-simply-crowdsource-the-Semantic-Web-3-2048.jpg)


![DIFFERENT FORMS AND
PLATFORMS TO CHOOSE FROM
6
Macrotasks
Microtasks
Challenges
Self-organized crowds
Crowdfunding
Source:
[Prpić et al.,
2015]](https://crownmelresort.com/image.slidesharecdn.com/crowdsourcingsheffield2016-161118180749/75/One-does-not-simply-crowdsource-the-Semantic-Web-6-2048.jpg)



































![Digital and networks handout [smua june 2017]](https://cdn.slidesharecdn.com/ss_thumbnails/digitalandnetworkshandoutsmuajune2017-170629150834-thumbnail.jpg?width=640&height=640&fit=bounds)



























































![SHS_Core_CAE_Q3_LE1 FOR THIRD [FINAL].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/shscorecaeq3le1final-251116055110-e3081055-thumbnail.jpg?width=640&height=640&fit=bounds)
















