Downloaded 243 times







![HBase Tables
• An HBase cluster is made up of any number of user-
defined tables
• Table schema only defines it’s column families
– Each family consists of any number of columns
– Each column consists of any number of versions
– Columns only exist when inserted, NULLs are free
– Everything except table/family names are byte[]
– Rows in a table are sorted and stored sequentially
– Columns in a family are sorted and stored sequentially
(Table, Row, Family, Column, Timestamp) Value](https://image.slidesharecdn.com/nychadoopmeetup-introductiontohbase-100928233306-phpapp02/75/Nyc-hadoop-meetup-introduction-to-h-base-8-2048.jpg)






















![HBase Tables
• An HBase cluster is made up of any number of user-
defined tables
• Table schema only defines it’s column families
– Each family consists of any number of columns
– Each column consists of any number of versions
– Columns only exist when inserted, NULLs are free
– Everything except table/family names are byte[]
– Rows in a table are sorted and stored sequentially
– Columns in a family are sorted and stored sequentially
(Table, Row, Family, Column, Timestamp) Value](https://crownmelresort.com/image.slidesharecdn.com/nychadoopmeetup-introductiontohbase-100928233306-phpapp02/75/Nyc-hadoop-meetup-introduction-to-h-base-8-2048.jpg)


















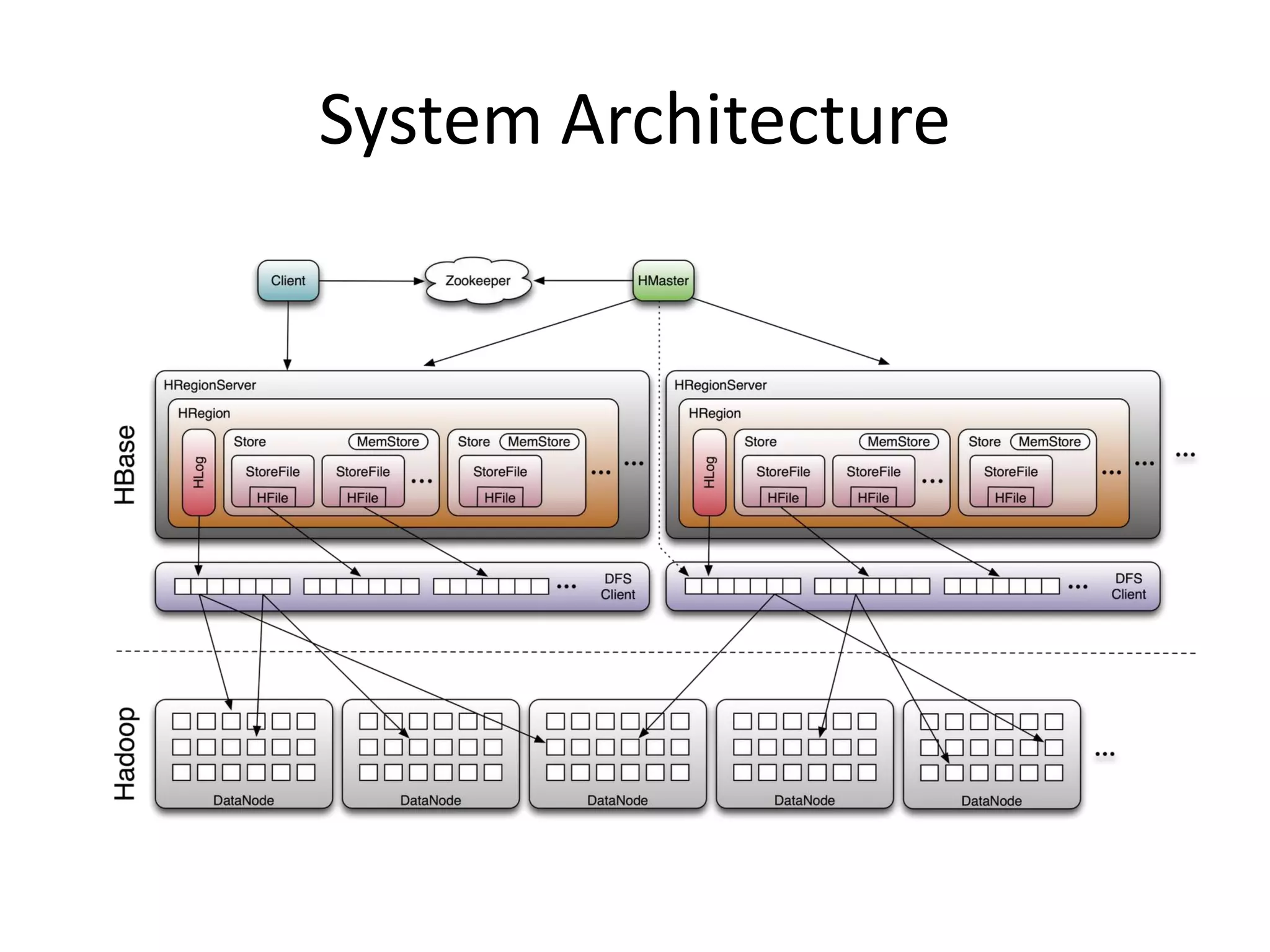
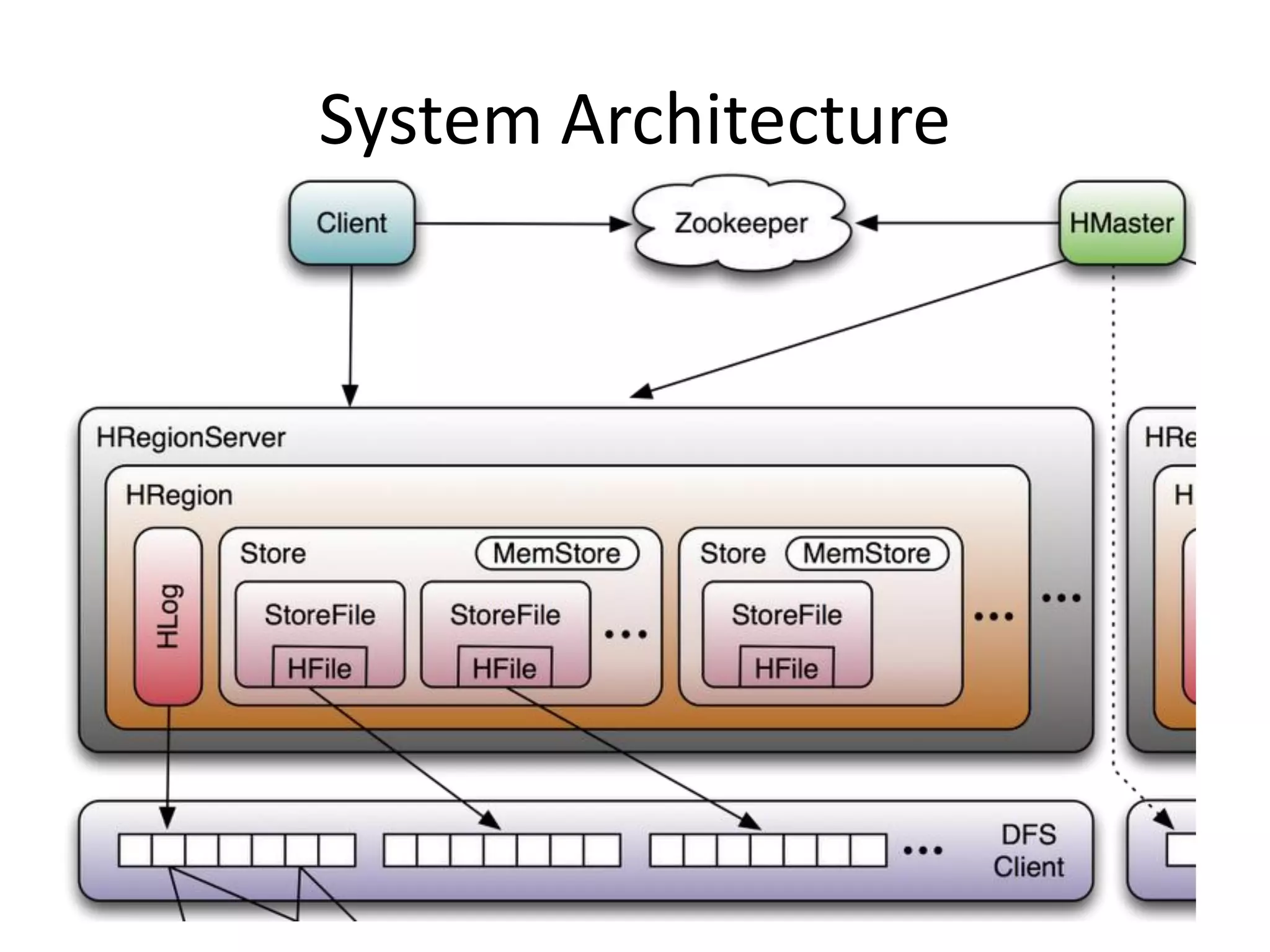
Jonathan Gray gave an introduction to HBase at the NYC Hadoop Meetup. He began with an overview of HBase and why it was created to handle large datasets beyond what Hadoop could support alone. He then described what HBase is, as a distributed, column-oriented database management system. Gray explained how HBase works with its master and regionserver nodes and how it partitions data across tables and regions. He highlighted some key features of HBase and examples of companies using it in production. Gray concluded with what is planned for the future of HBase and contrasted it with relational database examples.















































