Downloaded 149 times





























![Kafka Streams
valbuilder=newKStreamBuilder()
valstream:KStream[K,V]=builder.stream(des,des,"raw.data.topic")
.flatMapValues(value->Arrays.asList(value.toLowerCase.split("")
.map((k,v)->newKeyValue(k,v))
.countByKey(ser,ser,des,des,"kTable")
.toStream()
stream.to("results.topic",...)
valstreams=newKafkaStreams(builder,props)
streams.start()
https://github.com/con uentinc/demos](https://image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/75/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-35-2048.jpg)


.where("wsid=?ANDyear=?ANDmonth=?",e.wsid,e.year,e.month)
.collectAsync()
.map(MonthlyTemperature(_,e.wsid,e.year,e.month))pipeTorequester
}](https://image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/75/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-37-2048.jpg)

.map(LabeledPoint.parse)
valtrainingStream=KafkaUtils.createDirectStream[_,_,_,_](..)
.map(transformFunc)
.map(LabeledPoint.parse)
trainingStream.saveToCassandra("ml_training_keyspace","raw_training_data")
valmodel=newStreamingLinearRegressionWithSGD()
.setInitialWeights(Vectors.dense(weights))
.trainOn(trainingStream)
model
.predictOnValues(testData.map(lp=>(lp.label,lp.features)))
.saveToCassandra("ml_predictions_keyspace","predictions")](https://image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/75/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-38-2048.jpg)





















.map(transformFunc)
.map(LabeledPoint.parse)
dataStream.foreachRDD(_.toDF.write.format("filodb.spark")
.option("dataset","training").save())
if(trainNow){
varmodel=newStreamingLinearRegressionWithSGD()
.setInitialWeights(Vectors.dense(weights))
.trainOn(dataStream.join(historicalEvents))
}
model.predictOnValues(dataStream.map(lp=>(lp.label,lp.features)))
.insertIntoFilo("predictions")](https://image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/75/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-61-2048.jpg)
















![Spark Streaming -> FiloDB
valratingsStream=KafkaUtils.createDirectStream[String,String,StringDecoder,Strin
ratingsStream.foreachRDD{
(message:RDD[(String,String)],batchTime:Time)=>{
valdf=message.map(_._2.split(",")).map(rating=>Rating(rating(0).trim.toInt,r
toDF("fromuserid","touserid","rating")
//addthebatchtimetotheDataFrame
valdfWithBatchTime=df.withColumn("batch_time",org.apache.spark.sql.functions.l
//savetheDataFrametoFiloDB
dfWithBatchTime.write.format("filodb.spark")
.option("dataset","ratings")
.save()
}
}
One-line change to write to FiloDB vs Cassandra](https://image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/75/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-81-2048.jpg)









































![Kafka Streams
valbuilder=newKStreamBuilder()
valstream:KStream[K,V]=builder.stream(des,des,"raw.data.topic")
.flatMapValues(value->Arrays.asList(value.toLowerCase.split("")
.map((k,v)->newKeyValue(k,v))
.countByKey(ser,ser,des,des,"kTable")
.toStream()
stream.to("results.topic",...)
valstreams=newKafkaStreams(builder,props)
streams.start()
https://github.com/con uentinc/demos](https://crownmelresort.com/image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/75/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-35-2048.jpg)


.where("wsid=?ANDyear=?ANDmonth=?",e.wsid,e.year,e.month)
.collectAsync()
.map(MonthlyTemperature(_,e.wsid,e.year,e.month))pipeTorequester
}](https://crownmelresort.com/image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/75/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-37-2048.jpg)

.map(LabeledPoint.parse)
valtrainingStream=KafkaUtils.createDirectStream[_,_,_,_](..)
.map(transformFunc)
.map(LabeledPoint.parse)
trainingStream.saveToCassandra("ml_training_keyspace","raw_training_data")
valmodel=newStreamingLinearRegressionWithSGD()
.setInitialWeights(Vectors.dense(weights))
.trainOn(trainingStream)
model
.predictOnValues(testData.map(lp=>(lp.label,lp.features)))
.saveToCassandra("ml_predictions_keyspace","predictions")](https://crownmelresort.com/image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/75/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-38-2048.jpg)























.map(transformFunc)
.map(LabeledPoint.parse)
dataStream.foreachRDD(_.toDF.write.format("filodb.spark")
.option("dataset","training").save())
if(trainNow){
varmodel=newStreamingLinearRegressionWithSGD()
.setInitialWeights(Vectors.dense(weights))
.trainOn(dataStream.join(historicalEvents))
}
model.predictOnValues(dataStream.map(lp=>(lp.label,lp.features)))
.insertIntoFilo("predictions")](https://crownmelresort.com/image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/75/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-61-2048.jpg)



















![Spark Streaming -> FiloDB
valratingsStream=KafkaUtils.createDirectStream[String,String,StringDecoder,Strin
ratingsStream.foreachRDD{
(message:RDD[(String,String)],batchTime:Time)=>{
valdf=message.map(_._2.split(",")).map(rating=>Rating(rating(0).trim.toInt,r
toDF("fromuserid","touserid","rating")
//addthebatchtimetotheDataFrame
valdfWithBatchTime=df.withColumn("batch_time",org.apache.spark.sql.functions.l
//savetheDataFrametoFiloDB
dfWithBatchTime.write.format("filodb.spark")
.option("dataset","ratings")
.save()
}
}
One-line change to write to FiloDB vs Cassandra](https://crownmelresort.com/image.slidesharecdn.com/stratasjstreamingadhocmachinelearninganalysis-160331160231/75/NoLambda-Combining-Streaming-Ad-Hoc-Machine-Learning-and-Batch-Analysis-81-2048.jpg)










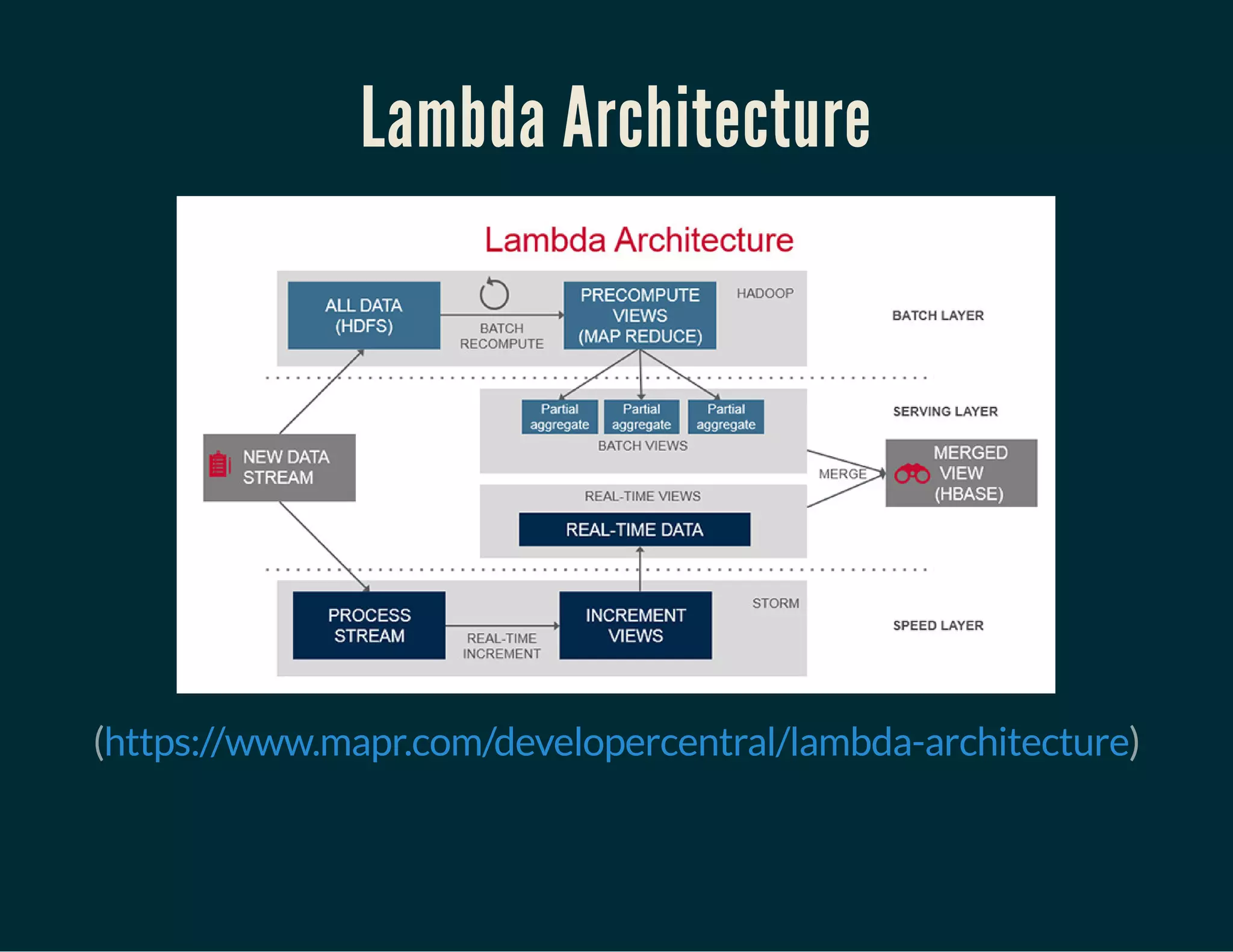
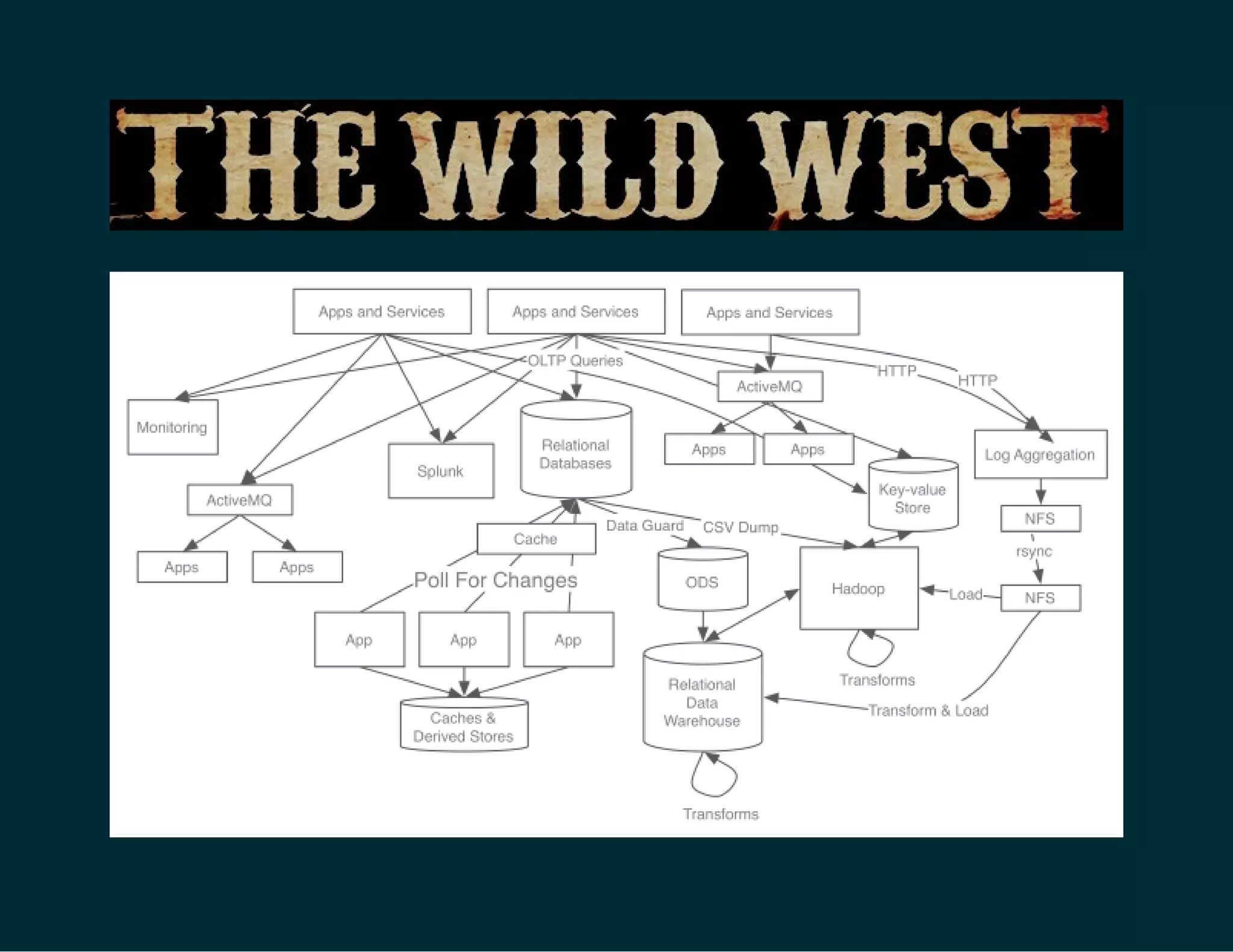
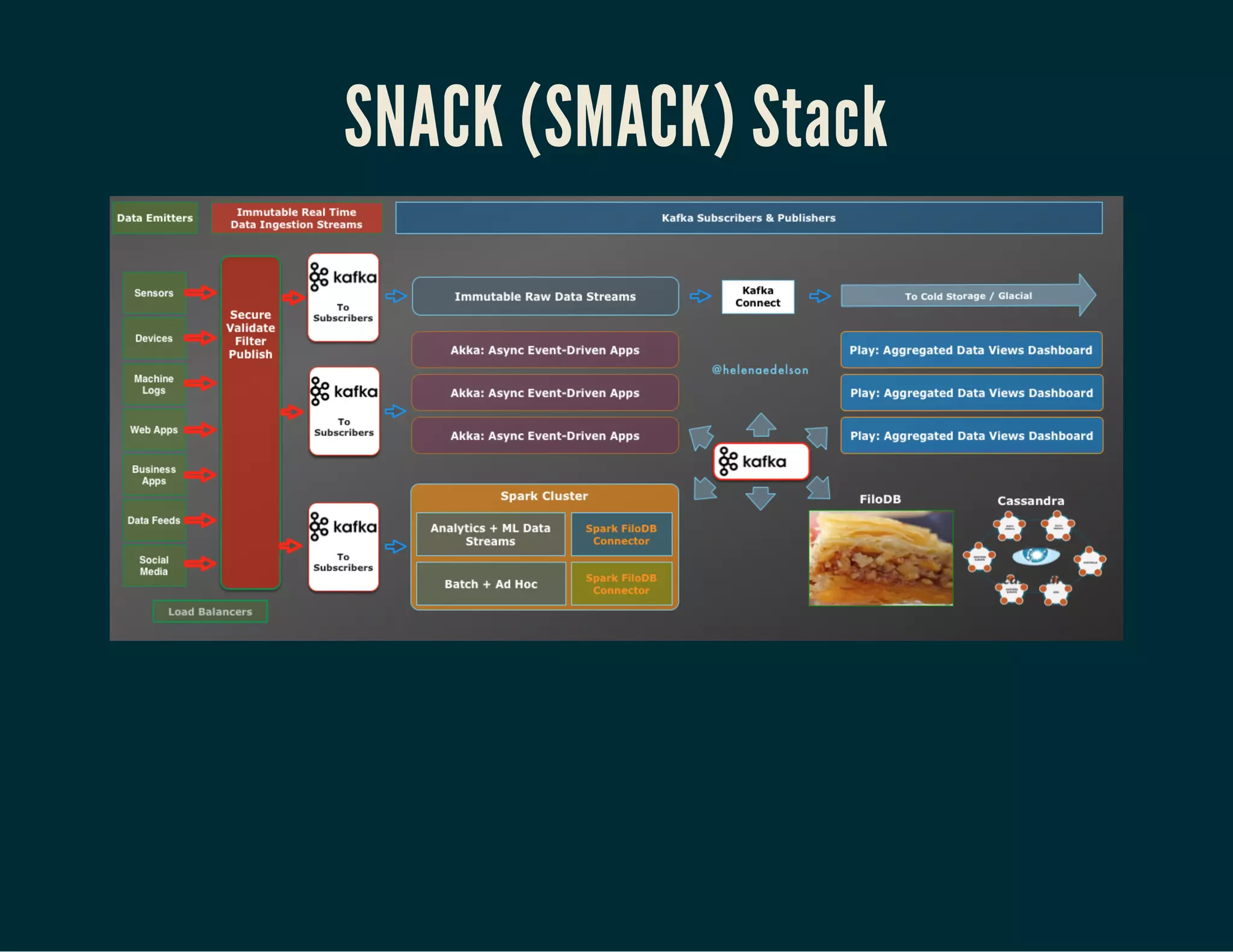
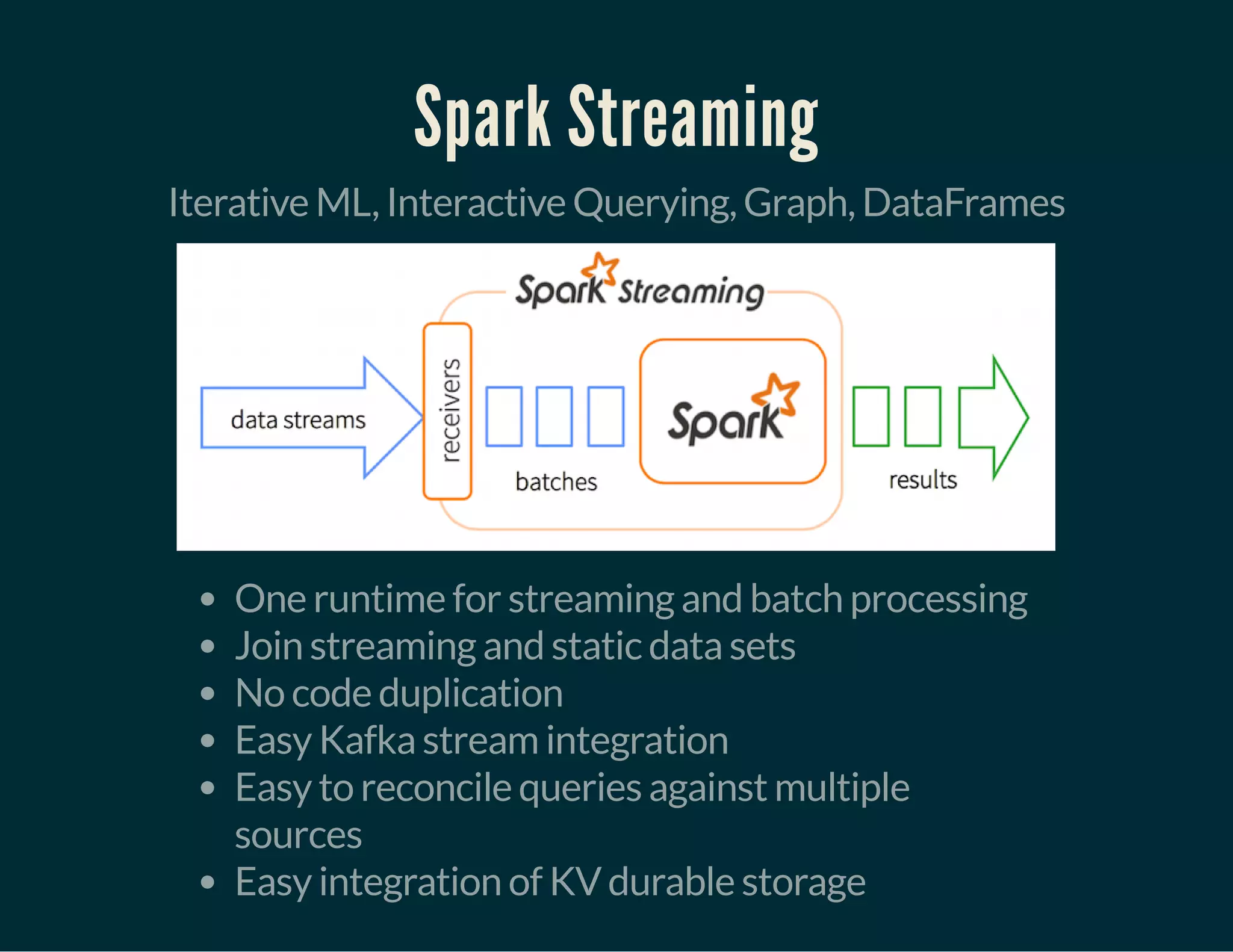
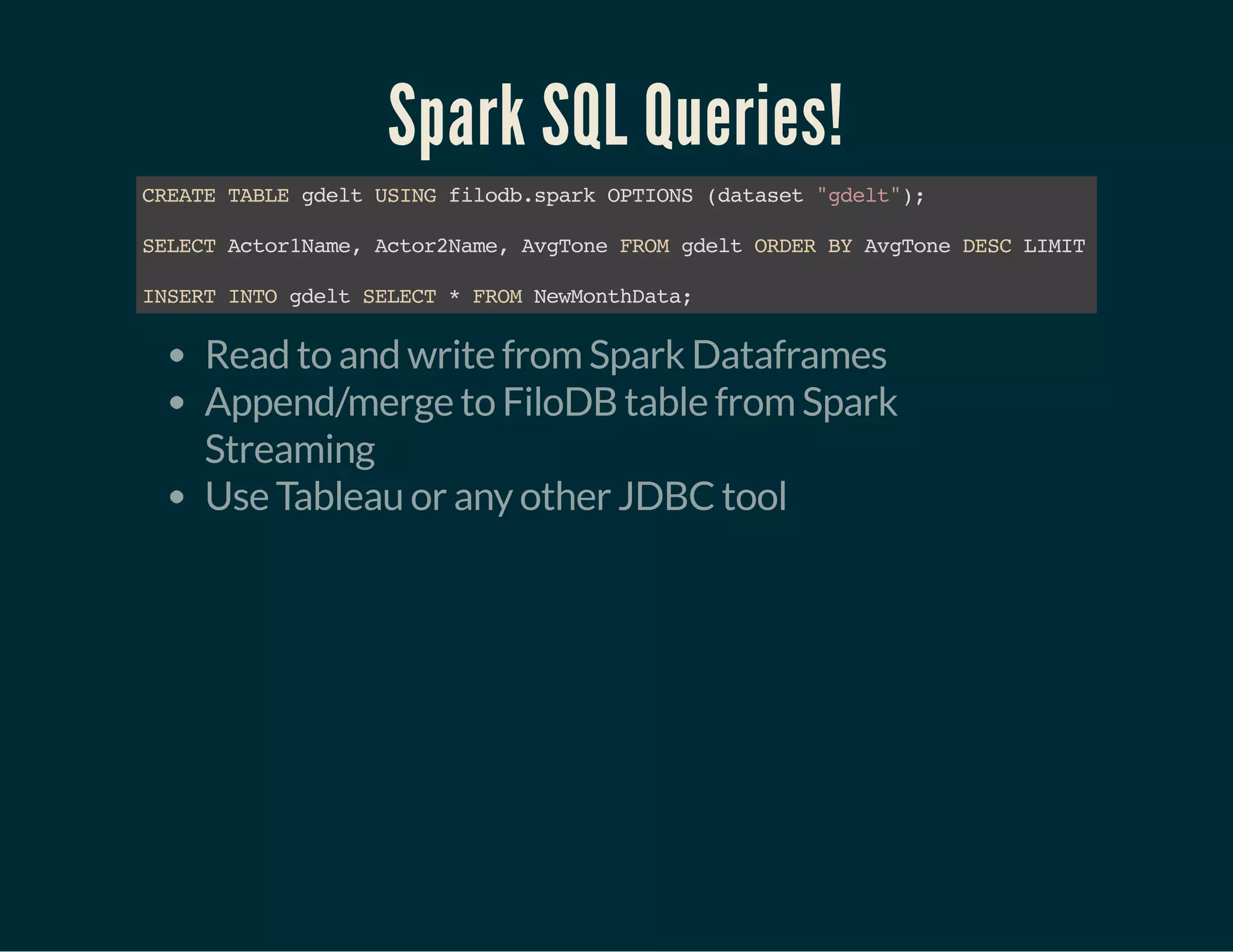
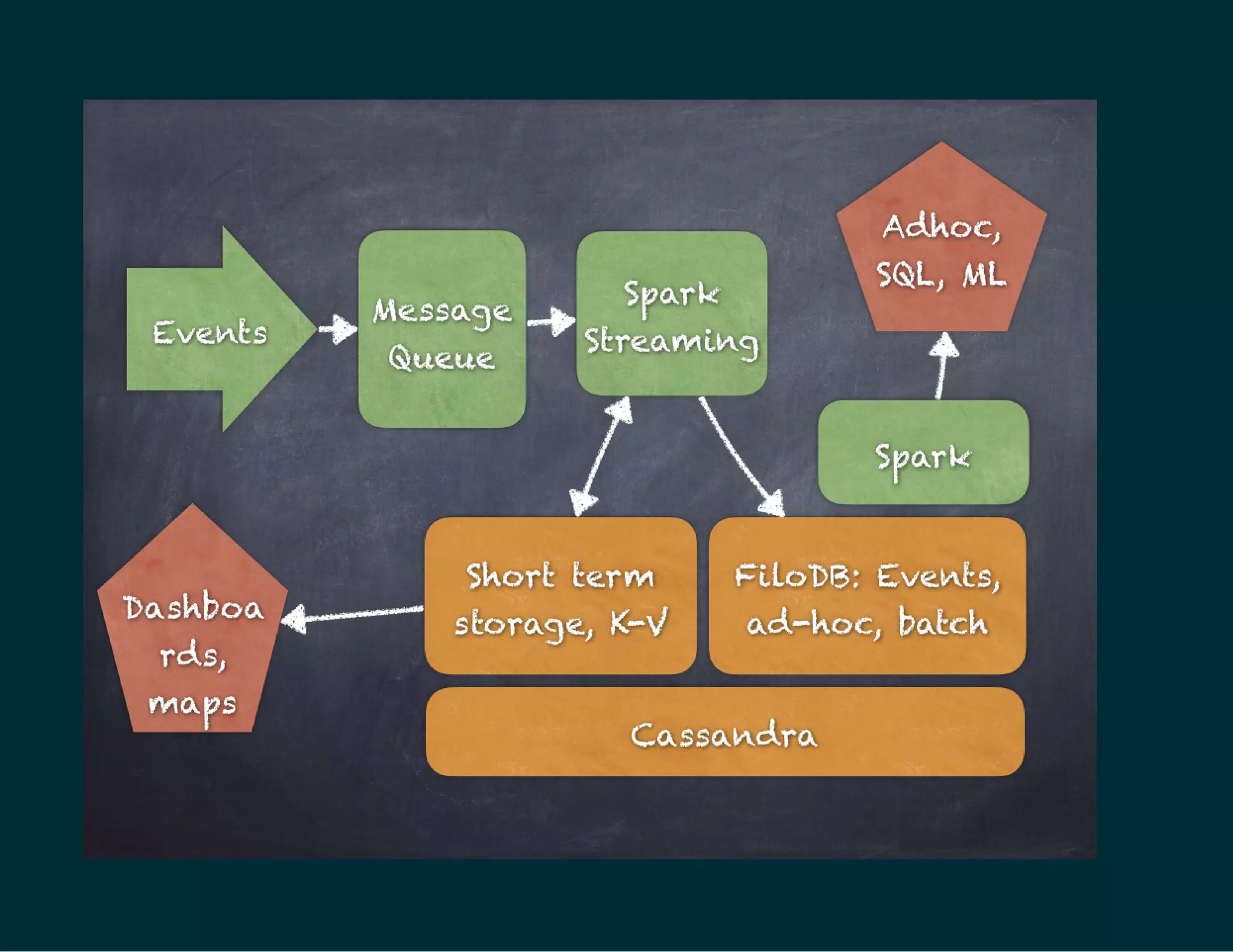
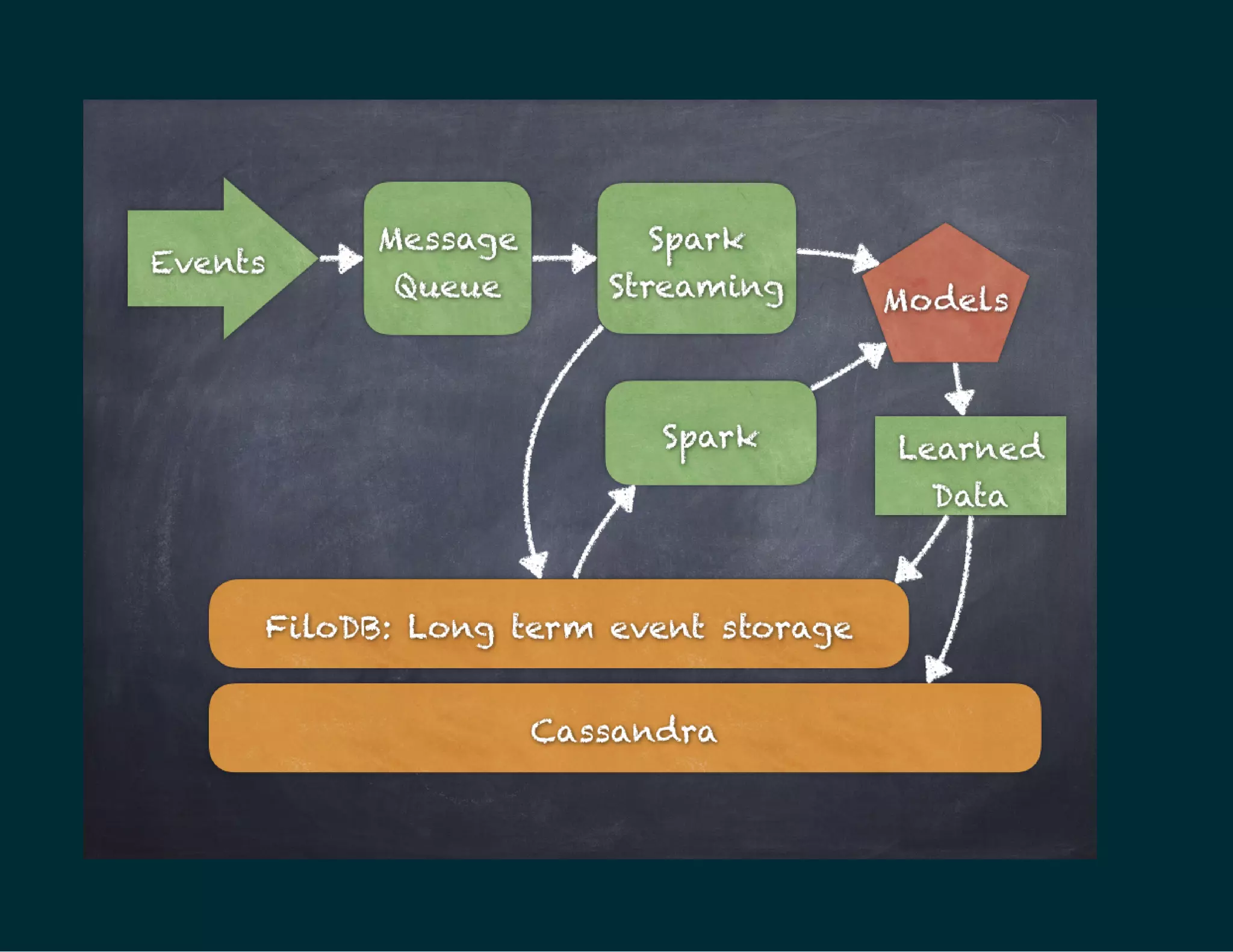
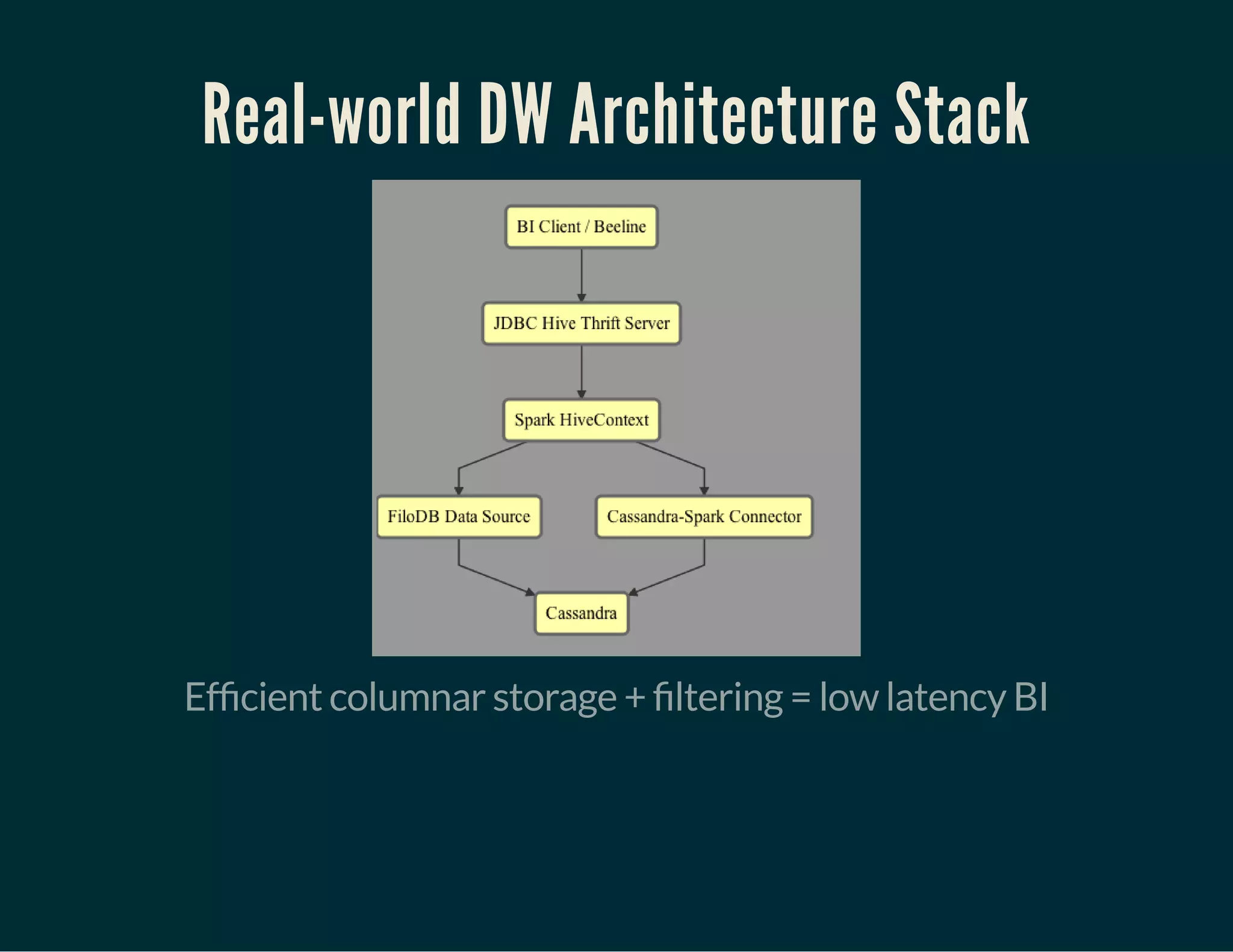
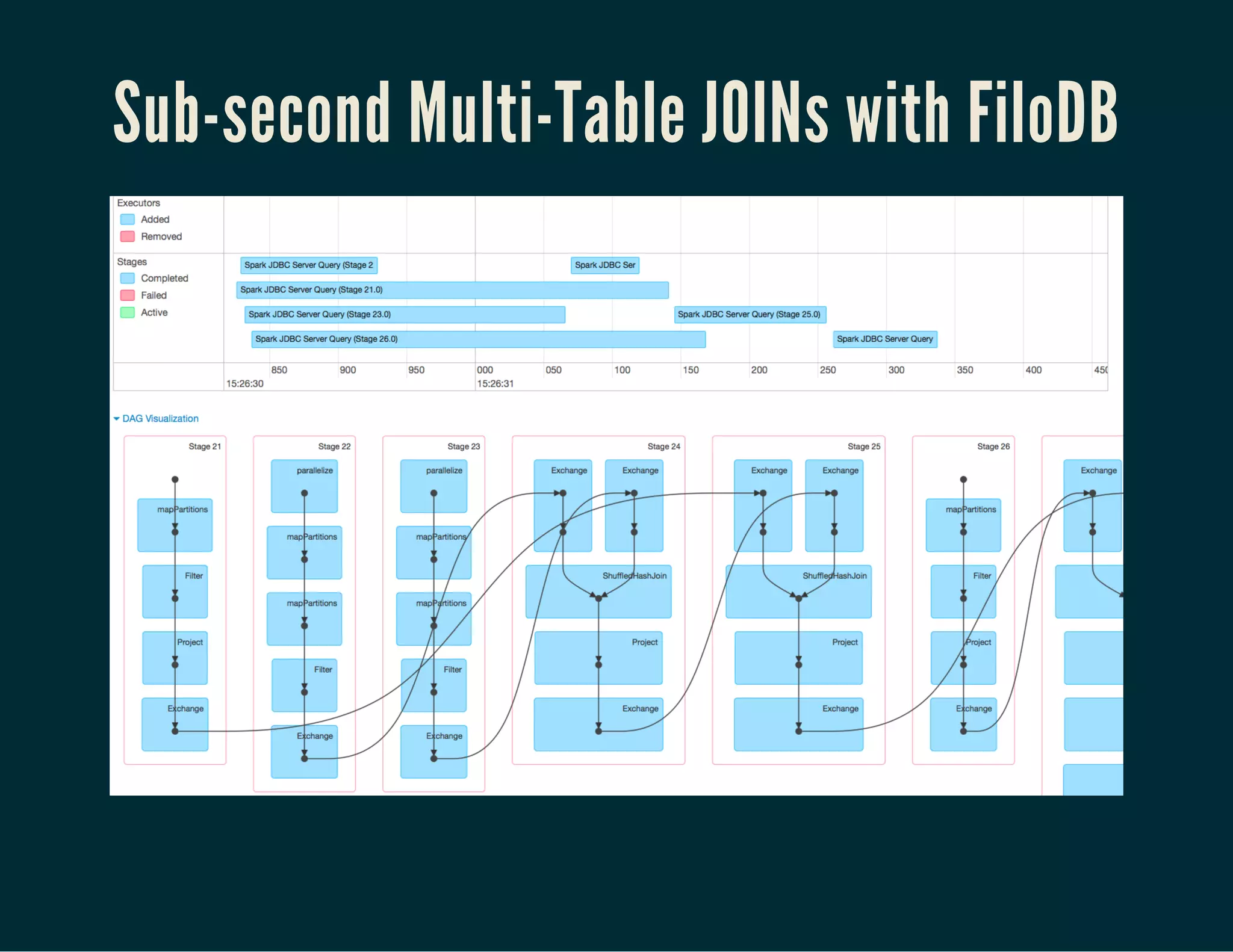
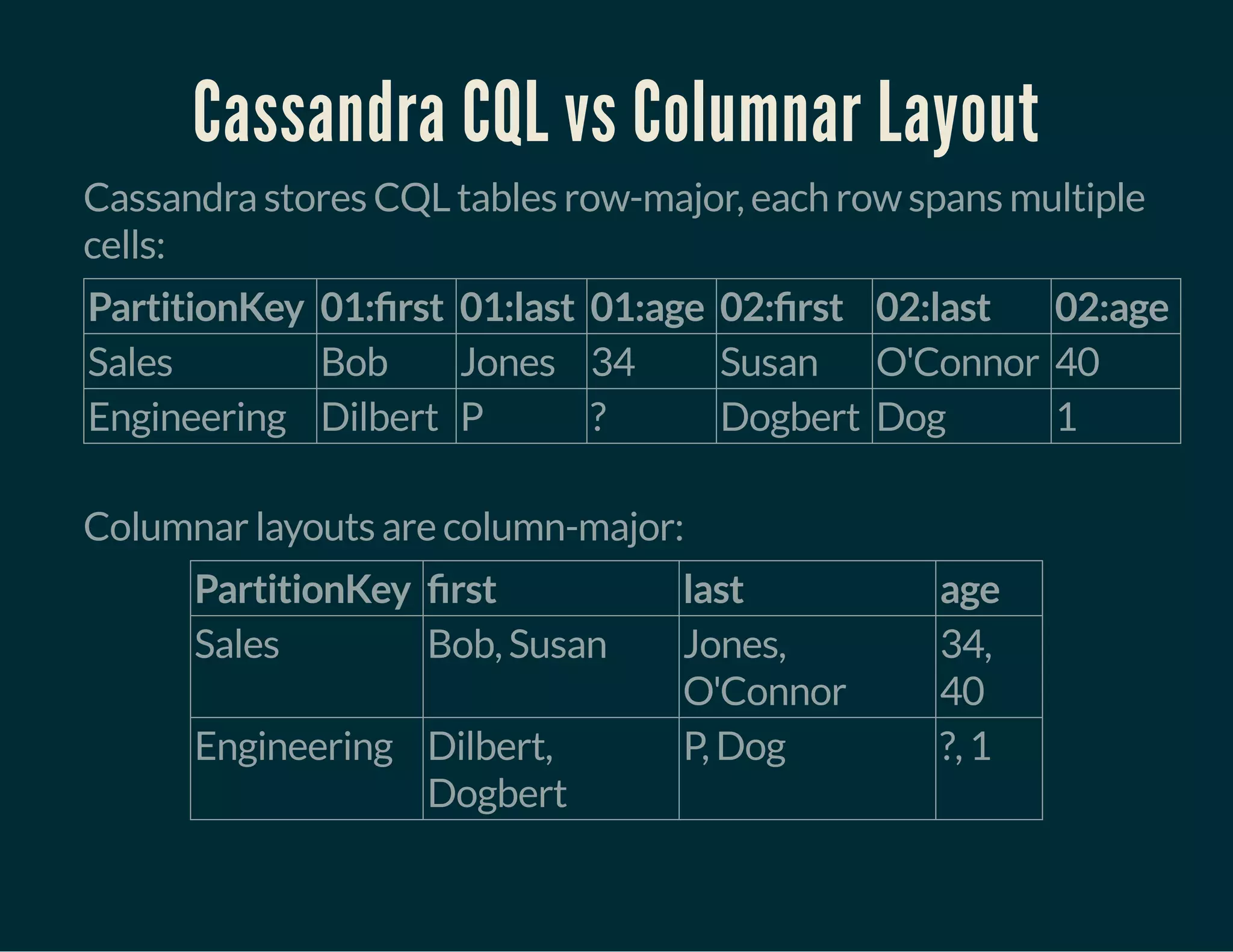
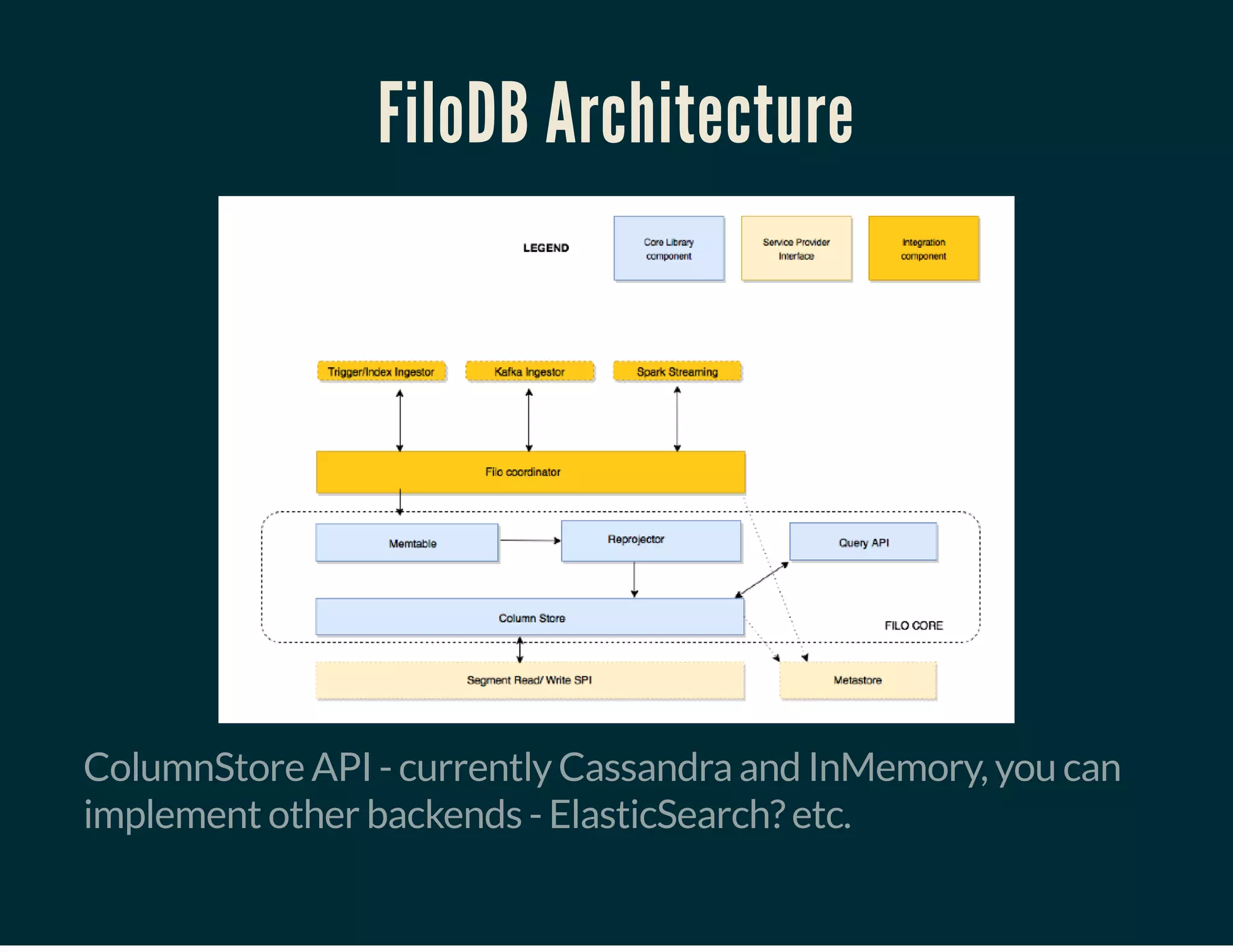
The document discusses Tuplejump's integration of streaming, ad-hoc, machine learning, and batch analytics through their technologies, particularly in the context of using Apache Spark and Cassandra. It highlights the challenges of building scalable, fault-tolerant systems capable of handling massive data and emphasizes the advantages of their Filodb database for optimizing analytics and storage solutions. Key use cases include real-time processing and the benefits of a unified streaming architecture over traditional Lambda architectures, addressing issues of performance, complexity, and data consistency.










































































