Download as PDF, PPTX
















![Fitting Into 249 Cycles: Bursts
Process few packets at a time (a burst), not one-by-one:
1. Amortize slow memory reads per burst
2. Increase cache hit ratio: do the same for few packets at once
void lcore_loop()
{
struct rte_mbuf *burst[32];
while (1) {
nb_rx = rte_eth_rx_burst(0, 0, burst, 32);
...
rte_eth_tx_burst(1, 0, burst, nb_rx);
}
}
17
Pros/cons?](https://image.slidesharecdn.com/networkprogrammingdpdk-180621090830/75/Network-Programming-Data-Plane-Development-Kit-DPDK-17-2048.jpg)










![DPDK
Kernel
So, Let’s Make a Simple Hub!
28
void lcore_loop()
{
struct rte_mbuf *burst[32];
uint16_t id = rte_lcore_id();
while (1) {
nb_rx = rte_eth_rx_burst(0, id, burst, 32);
rte_eth_tx_burst(1, id, burst, nb_rx);
nb_rx = rte_eth_rx_burst(1, id, burst, 32);
rte_eth_tx_burst(0, id, burst, nb_rx);
}
}
PMD
App
PMD
while (1) {
rx(...); tx(...);
}
mmap()](https://image.slidesharecdn.com/networkprogrammingdpdk-180621090830/75/Network-Programming-Data-Plane-Development-Kit-DPDK-28-2048.jpg)


![DPDK Command Line Arguments
31
1. Number of workers:
-c COREMASK, i.e. -c 0xf
better: -l CORELIST, i.e. -l 0-3
best: --lcores COREMAP, i.e. --lcores 0-3@0
2. Number of memory channels (optional):
-n NUM, i.e. -n 4
3. Allocate memory using hugepages (optional):
-m MB, i.e. -m 512
--socket-mem SOCKET_MB,SOCKET_MB,..., i.e. --socket-mem 384,128
4. Add virtual devices (optional):
--vdev <driver><id>[,key=val, ...], i.e. --vdev net_pcap0,iface=eth0
More command-line options: http://dpdk.org/doc/guides/testpmd_app_ug/run_app.html](https://image.slidesharecdn.com/networkprogrammingdpdk-180621090830/75/Network-Programming-Data-Plane-Development-Kit-DPDK-31-2048.jpg)
![DPDK Main Loop
1. Receive burst of packets:
nb_rx = rte_eth_rx_burst(port_id, queue_id, burst, BURST_SZ);
2. Process packets (app logic)
3. Send burst of packets:
nb_tx = rte_eth_tx_burst(port_id, queue_id, burst, nb_rx);
4. Free unsent buffers:
for (; nb_tx < nb_rx; nb_tx++)
rte_pktmbuf_free(burst[nb_tx]);
32](https://image.slidesharecdn.com/networkprogrammingdpdk-180621090830/75/Network-Programming-Data-Plane-Development-Kit-DPDK-32-2048.jpg)
















![Cuckoo Hash Structures
50
B
Bucket
Numberofbuckets
Bucket entries
S
Ki
A
Key signatures []
Entry
K
Key indexes []
Alt. signatures []
Numberofslots
D
KeyData
Ring of free
slots](https://image.slidesharecdn.com/networkprogrammingdpdk-180621090830/75/Network-Programming-Data-Plane-Development-Kit-DPDK-50-2048.jpg)





























![Fitting Into 249 Cycles: Bursts
Process few packets at a time (a burst), not one-by-one:
1. Amortize slow memory reads per burst
2. Increase cache hit ratio: do the same for few packets at once
void lcore_loop()
{
struct rte_mbuf *burst[32];
while (1) {
nb_rx = rte_eth_rx_burst(0, 0, burst, 32);
...
rte_eth_tx_burst(1, 0, burst, nb_rx);
}
}
17
Pros/cons?](https://crownmelresort.com/image.slidesharecdn.com/networkprogrammingdpdk-180621090830/75/Network-Programming-Data-Plane-Development-Kit-DPDK-17-2048.jpg)










![DPDK
Kernel
So, Let’s Make a Simple Hub!
28
void lcore_loop()
{
struct rte_mbuf *burst[32];
uint16_t id = rte_lcore_id();
while (1) {
nb_rx = rte_eth_rx_burst(0, id, burst, 32);
rte_eth_tx_burst(1, id, burst, nb_rx);
nb_rx = rte_eth_rx_burst(1, id, burst, 32);
rte_eth_tx_burst(0, id, burst, nb_rx);
}
}
PMD
App
PMD
while (1) {
rx(...); tx(...);
}
mmap()](https://crownmelresort.com/image.slidesharecdn.com/networkprogrammingdpdk-180621090830/75/Network-Programming-Data-Plane-Development-Kit-DPDK-28-2048.jpg)


![DPDK Command Line Arguments
31
1. Number of workers:
-c COREMASK, i.e. -c 0xf
better: -l CORELIST, i.e. -l 0-3
best: --lcores COREMAP, i.e. --lcores 0-3@0
2. Number of memory channels (optional):
-n NUM, i.e. -n 4
3. Allocate memory using hugepages (optional):
-m MB, i.e. -m 512
--socket-mem SOCKET_MB,SOCKET_MB,..., i.e. --socket-mem 384,128
4. Add virtual devices (optional):
--vdev <driver><id>[,key=val, ...], i.e. --vdev net_pcap0,iface=eth0
More command-line options: http://dpdk.org/doc/guides/testpmd_app_ug/run_app.html](https://crownmelresort.com/image.slidesharecdn.com/networkprogrammingdpdk-180621090830/75/Network-Programming-Data-Plane-Development-Kit-DPDK-31-2048.jpg)
![DPDK Main Loop
1. Receive burst of packets:
nb_rx = rte_eth_rx_burst(port_id, queue_id, burst, BURST_SZ);
2. Process packets (app logic)
3. Send burst of packets:
nb_tx = rte_eth_tx_burst(port_id, queue_id, burst, nb_rx);
4. Free unsent buffers:
for (; nb_tx < nb_rx; nb_tx++)
rte_pktmbuf_free(burst[nb_tx]);
32](https://crownmelresort.com/image.slidesharecdn.com/networkprogrammingdpdk-180621090830/75/Network-Programming-Data-Plane-Development-Kit-DPDK-32-2048.jpg)

















![Cuckoo Hash Structures
50
B
Bucket
Numberofbuckets
Bucket entries
S
Ki
A
Key signatures []
Entry
K
Key indexes []
Alt. signatures []
Numberofslots
D
KeyData
Ring of free
slots](https://crownmelresort.com/image.slidesharecdn.com/networkprogrammingdpdk-180621090830/75/Network-Programming-Data-Plane-Development-Kit-DPDK-50-2048.jpg)
















The document outlines the architecture and implementation of high-performance networking using Data Plane Development Kit (DPDK), emphasizing efficient packet processing and management. It discusses networking protocols, memory management, and the benefits of user space libraries for reducing latency in packet handling. Additionally, it explains the operational mechanics of data planes, including mechanisms for packet reception and transmission in a multi-core environment.
Presenting key networking terms and protocols, including TCP, UDP, NAT, IPsec, and IPv4/IPv6.
Introduction to Network Programming with series including Berkeley Sockets and DPDK.
Steps to implement a 10Gbit/s switch, including handling Ethernet frames and MAC tables.
Process for making a simple hub switch, incorporating frame checks and MAC table updates.
Breakdown of Ethernet frame format and size specifications, with payload and header details.
Calculating minimum Ethernet frame size and maximum frames for 1 and 10 Gbps links.
Analysis of CPU budget per packet for Ethernet communication, measured in cycles.
Overview of Xeon processor memory structure including L1, L2, and LLC cache.
Comparison of CPU cycles needed for Ethernet packet processing regarding memory levels.
Challenges in kernel development including interrupts and context switching.
DPDK introduction with its purpose, advantages, and definitions of dataplane architecture.
Detailed explanation of DPDK libraries, drivers, and functionalities available.
Techniques for optimizing packet processing within CPU cycle constraints, including polling and multicore usage.
Key benefits of using DPDK for high performance in networking, including efficient management.
Different models for dataplane applications, focusing on synchronization and processing.
Utilization of RSS and Flow Affinity for efficient packet processing across cores.
Overview of DPDK's architecture including user space, hardware access, and app deployment.
Code example to build a simple hub using DPDK components and structures.
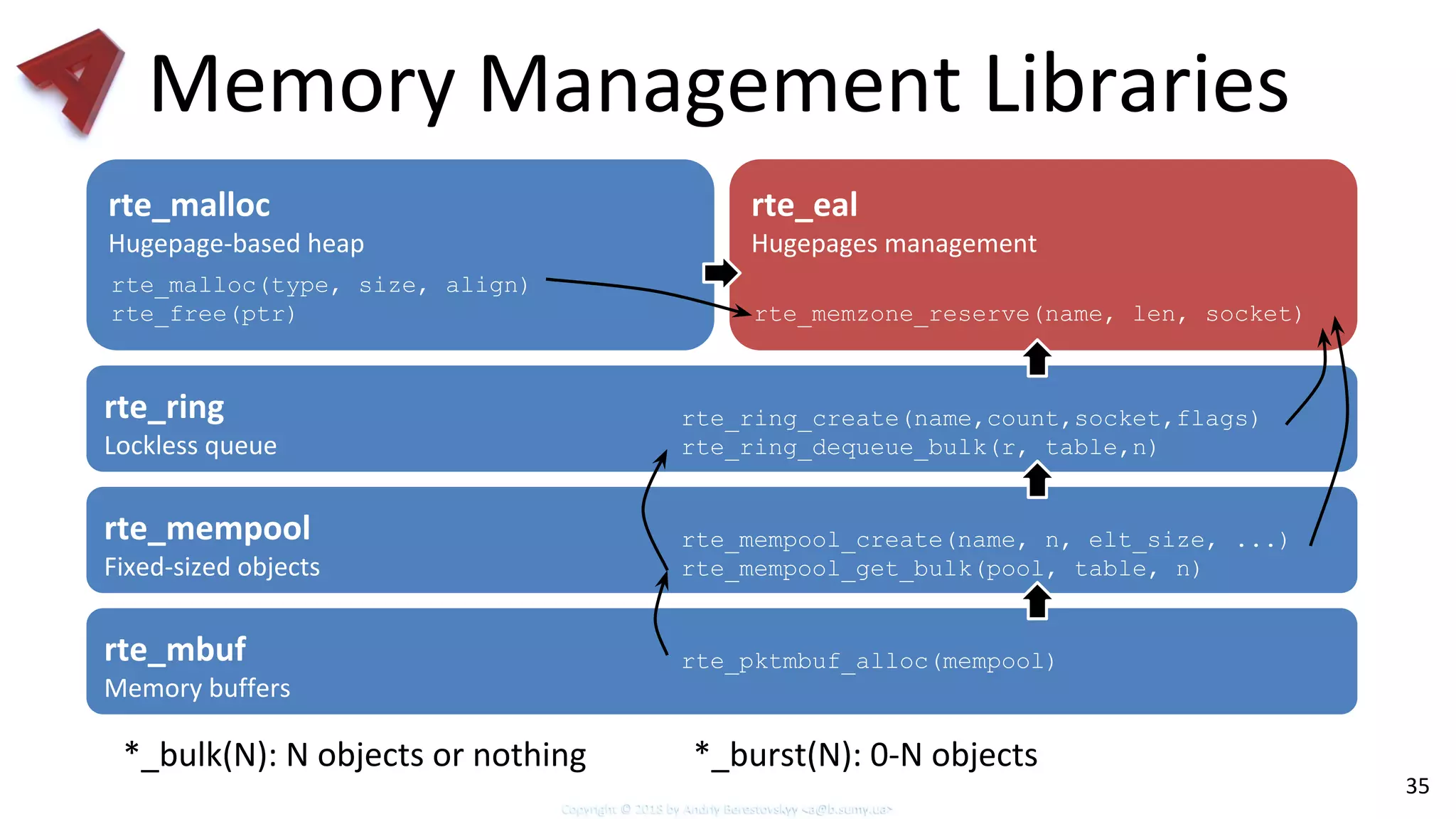
Overview of essential DPDK libraries and their roles in memory allocation and queue management.
Key command line arguments for configuring DPDK applications and managing packet loops.
Memory management strategies including usage of huge pages and memory zones for efficiency.
Discussion of various memory management techniques including lockless queues and non-blocking algorithms.
Focus on DPDK's hashing libraries and cuckoo hashing for managing data efficiently.
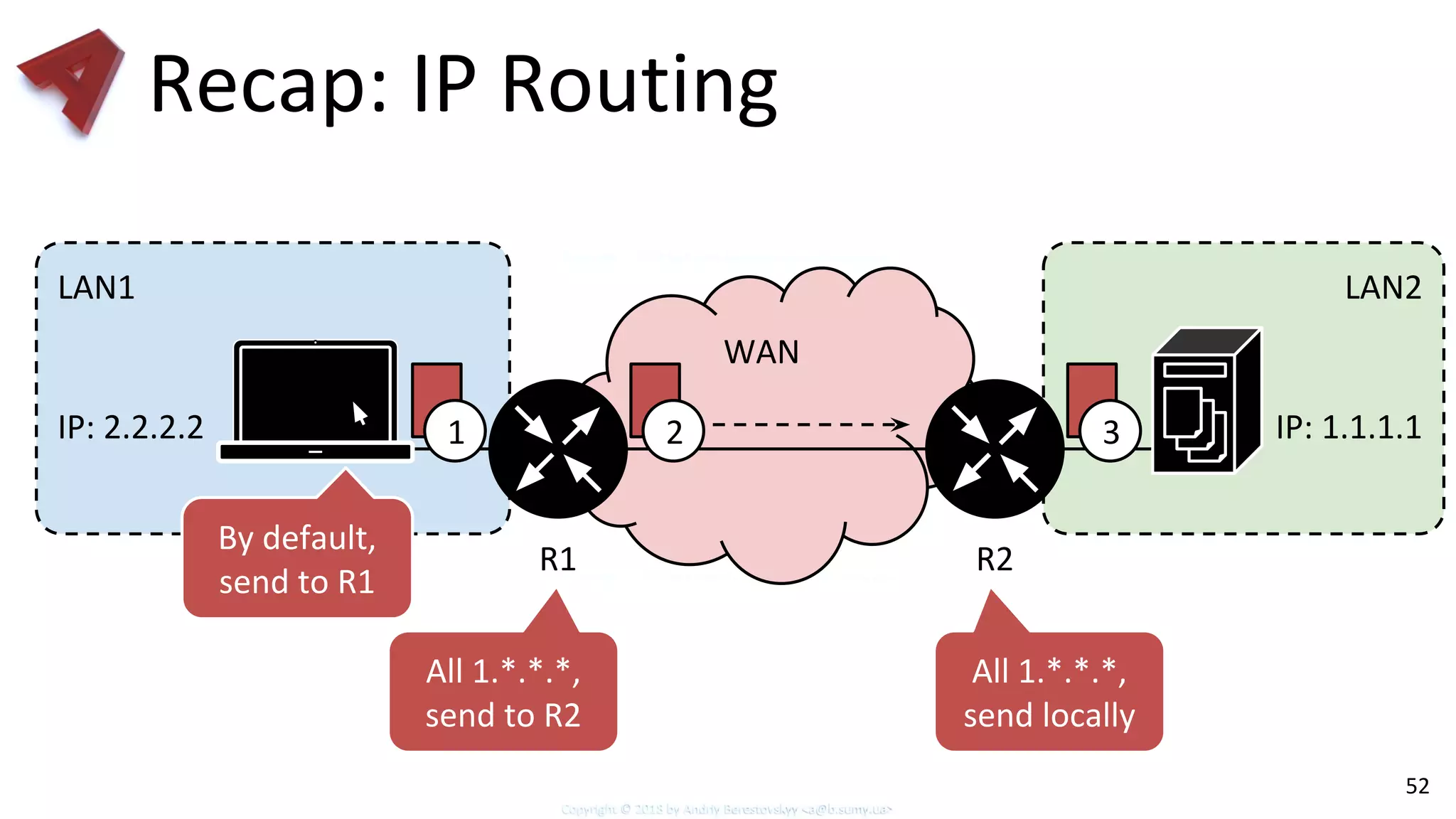
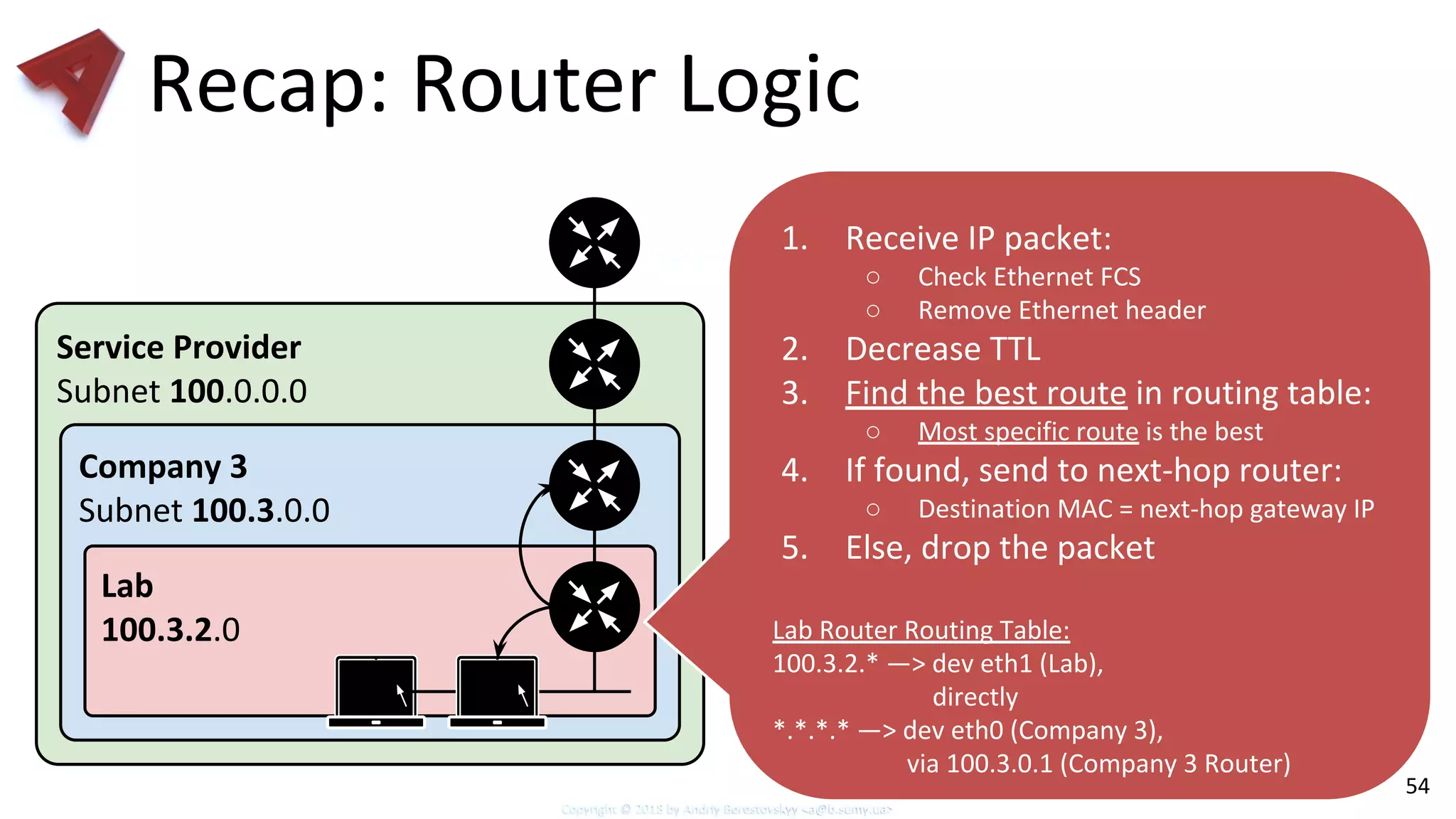
Review of IP routing basics, subnetting concepts, and longest prefix matching.
Insight into how DPDK implements longest prefix matching for IP addresses efficiently.
Overview of DPDK’s poll mode and kernel NIC interface for effective packet management.
Best practices for improving DPDK applications, including memory allocation and threading strategies.
Source links for further reference on DPDK programming and related research material.










































































