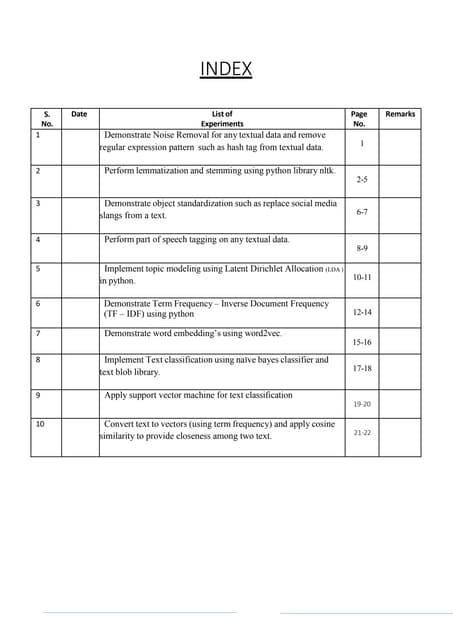
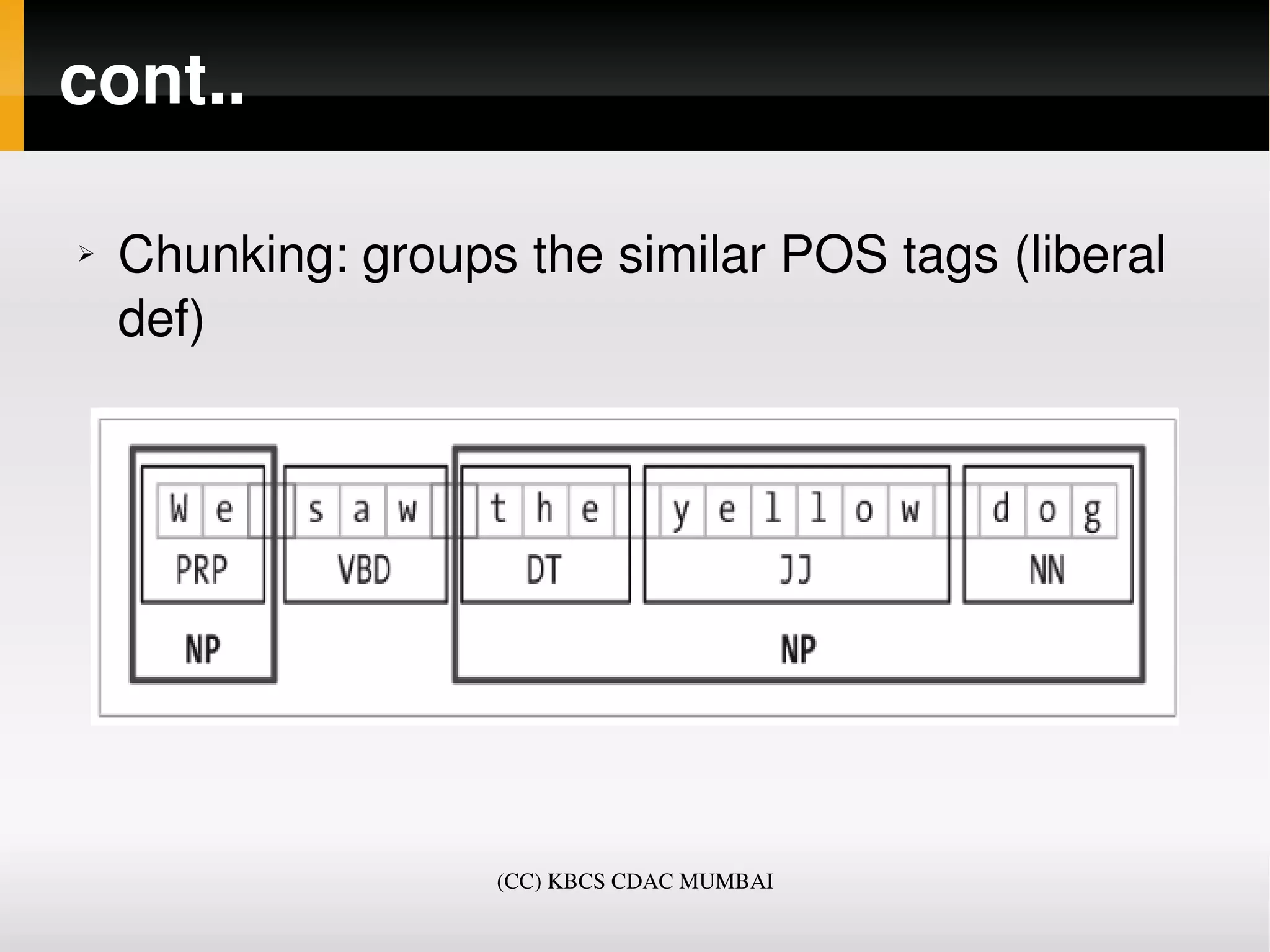
The document provides an overview of the Natural Language Toolkit (NLTK), an open-source Python library for processing human language data. It covers installation, basic operations such as tokenization and stemming, and applications of NLTK in various NLP tasks including machine translation and text classification. Additionally, it discusses challenges in NLP and offers practical examples for using NLTK functionalities in Python.
![Natural Language Toolkit [NLTK]
Prakash B Pimpale
pbpimpale@gmail.com
@
FOSS(From the Open Source Shelf)
An open source softwares seminar series
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-1-2048.jpg)








![Installing NLTK
Windows
➢ Install Python: Version 2.4.*, 2.5.*, or 2.6.* and
not 3.0
available http://www.nltk.org/download
[great instructions!]
➢ Install PyYAML:
➢ Install Numpy
➢ Install Matplotlib
➢ Install NLTK (CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-11-2048.jpg)



![cont..
Test installation
( set path if needed: as
export NLTK_DATA = '/home/....../nltk_data')
>>> from nltk.corpus import brown
>>> brown.words()[0:20]
['The', 'Fulton', 'County', 'Grand', 'Jury']
All set!
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-16-2048.jpg)


![cont..
Find common context
>>>text2.common_contexts(["monstrous", "very"])
Find position of the word in entire text
>>>text4.dispersion_plot(["citizens", "democracy",
"freedom", "duties", "America"])
Counting vocab
>>>len(text4) #gives tokens(words and
punctuations)
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-19-2048.jpg)


![cont..
Writing our own text
>>>textown =['a','text','is','a','list','of','words']
adding texts(lists, can contain anything)
>>>sent = ['pqr']
>>>sent2 = ['xyz']
>>>sent+sent2
append to text
>>>sent.append('abc')
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-22-2048.jpg)
![cont..
Indexing text
>>> text4[173]
or
>>>text4.index('awaken')
slicing
text1[3:4], text[:5], text[10:] try it! (notice ending
index one less than specified)
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-23-2048.jpg)
![cont..
Strings in python
>>>name = 'astring'
>>>name[0]
what's more
>>>name*2
>>>'SPACE '.join(['let us','join'])
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-24-2048.jpg)
![cont..
Statistics to text
Frequency Distribution
>>> fdist1 = FreqDist(text1)
>>> fdist1
>>> vocabulary1 = fdist1.keys()
>>>vocabulary1[:25]
let's plot it...
>>>fdist1.plot(50, cumulative=True)
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-25-2048.jpg)
![cont..
*what the text1 is about?
*are all the words meaningful?
Let's find long words i.e.
Words from text1 with length more than 10
in python
>>>longw=[word for word in text1 if len(word)>10]
let's see it...
>>>sorted(longw)
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-26-2048.jpg)
![cont..
*most long words have small freq and are not
major topic of text many times
*words with long length and certain freq may
help to identify text topic
>>>sorted([w for w in set(text5) if len(w) > 7 and
fdist5[w] > 7])
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-27-2048.jpg)
![cont..
Bigrams and collocations:
*Bigrams
>>>sent=['near','river', 'bank']
>>>bigrams(sent)
basic to many NLP apps; transliteration,
translation
*collocations: frequent bigrams of rare words
>>>text4.collocations()
basic to some WSD approaches
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-28-2048.jpg)



![cont..
Playing with text corpora
Available corporas: Gutenberg, Web and chat
text, Brown, Reuters, inaugural address, etc.
>>> from nltk.corpus import inaugural
>>> inaugural.fileids()
>>>fileid[:4] for fileid in
inaugural.fileids()]
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-32-2048.jpg)
![cont..
>>> cfd = nltk.ConditionalFreqDist(
(target, file[:4])
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['america', 'citizen']
if w.lower().startswith(target))
>>> cfd.plot()
Conditional Freq distribution of words 'america' and
'citizen' with different years
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-33-2048.jpg)
![cont..
Generating text (applying bigrams)
>>> def generate_model(cfdist, word, num=15):
for i in range(num):
print word,
word = cfdist[word].max()
>>>text = nltk.corpus.genesis.words('englishkjv.txt')
>>>bigrams = nltk.bigrams(text)
>>>cfd = nltk.ConditionalFreqDist(bigrams)
>>print cfd['living']
>>generate_model(cfd, 'living')
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-34-2048.jpg)

![cont..
Stop words:
>>> from nltk.corpus import stopwords
>>> stopwords.words('english')
Percentage of content
>>> def content_fraction(text):
stopwords = nltk.corpus.stopwords.words('english')
content = [w for w in text if w.lower() not in stopwords]
return len(content) / len(text)
>>> content_fraction(nltk.corpus.reuters.words())
is the useful fraction of useful words!
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-36-2048.jpg)



![cont..
Tokenization:
>>> tokens = nltk.word_tokenize(raw)
>>> type(tokens)
>>> len(tokens)
>>> tokens[:15]
convert to Text
>>> text = nltk.Text(tokens)
>>> type(text)
Now you can do all above things with this!
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-40-2048.jpg)
![cont..
What about HTML?
>>> url =
"http://news.bbc.co.uk/2/hi/health/2284783.stm"
>>> html = urlopen(url).read()
>>> html[:60]
It's HTML; Clean the tags...
>>> raw = nltk.clean_html(html)
>>> tokens = nltk.word_tokenize(raw)
>>> tokens[:60]
>>> text = nltk.Text(tokens)
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-41-2048.jpg)


![cont..
Stemming : NLTK has inbuilt stemmers
>>>text =['apples','called','indians','applying']
>>> porter = nltk.PorterStemmer()
>>> lancaster = nltk.LancasterStemmer()
>>>[porter.stem(p) for p in text]
>>>[lancaster.stem(p) for p in text]
Lemmatization: WordNet lemmetizer, removes
affixes only if the new word exist in dictionary
>>> wnl = nltk.WordNetLemmatizer()
>>> [wnl.lemmatize(t) for t in text]
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-44-2048.jpg)

![cont..
Classifying with NLTK:
Problem: Gender identification from name
Feature last letter
>>> def gender_features(word):
return {'last_letter': word[1]}
Get data
>>> from nltk.corpus import names
>>> import random
(CC) KBCS CDAC MUMBAI](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-46-2048.jpg)
![cont..
>>> names = ([(name, 'male') for name in
names.words('male.txt')] +
[(name, 'female') for name in
names.words('female.txt')])
>>> random.shuffle(names)
Get Feature set
>>> featuresets = [(gender_features(n), g) for (n,g) in
names]
>>> train_set, test_set = featuresets[500:], featuresets[:500]
Train
>>> classifier = nltk.NaiveBayesClassifier.train(train_set)
Test (CC) KBCS CDAC MUMBAI
>>> classifier.classify(gender_features('Neo'))](https://image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-47-2048.jpg)


![Natural Language Toolkit [NLTK]
Prakash B Pimpale
pbpimpale@gmail.com
@
FOSS(From the Open Source Shelf)
An open source softwares seminar series
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-1-2048.jpg)









![Installing NLTK
Windows
➢ Install Python: Version 2.4.*, 2.5.*, or 2.6.* and
not 3.0
available http://www.nltk.org/download
[great instructions!]
➢ Install PyYAML:
➢ Install Numpy
➢ Install Matplotlib
➢ Install NLTK (CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-11-2048.jpg)




![cont..
Test installation
( set path if needed: as
export NLTK_DATA = '/home/....../nltk_data')
>>> from nltk.corpus import brown
>>> brown.words()[0:20]
['The', 'Fulton', 'County', 'Grand', 'Jury']
All set!
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-16-2048.jpg)


![cont..
Find common context
>>>text2.common_contexts(["monstrous", "very"])
Find position of the word in entire text
>>>text4.dispersion_plot(["citizens", "democracy",
"freedom", "duties", "America"])
Counting vocab
>>>len(text4) #gives tokens(words and
punctuations)
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-19-2048.jpg)


![cont..
Writing our own text
>>>textown =['a','text','is','a','list','of','words']
adding texts(lists, can contain anything)
>>>sent = ['pqr']
>>>sent2 = ['xyz']
>>>sent+sent2
append to text
>>>sent.append('abc')
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-22-2048.jpg)
![cont..
Indexing text
>>> text4[173]
or
>>>text4.index('awaken')
slicing
text1[3:4], text[:5], text[10:] try it! (notice ending
index one less than specified)
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-23-2048.jpg)
![cont..
Strings in python
>>>name = 'astring'
>>>name[0]
what's more
>>>name*2
>>>'SPACE '.join(['let us','join'])
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-24-2048.jpg)
![cont..
Statistics to text
Frequency Distribution
>>> fdist1 = FreqDist(text1)
>>> fdist1
>>> vocabulary1 = fdist1.keys()
>>>vocabulary1[:25]
let's plot it...
>>>fdist1.plot(50, cumulative=True)
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-25-2048.jpg)
![cont..
*what the text1 is about?
*are all the words meaningful?
Let's find long words i.e.
Words from text1 with length more than 10
in python
>>>longw=[word for word in text1 if len(word)>10]
let's see it...
>>>sorted(longw)
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-26-2048.jpg)
![cont..
*most long words have small freq and are not
major topic of text many times
*words with long length and certain freq may
help to identify text topic
>>>sorted([w for w in set(text5) if len(w) > 7 and
fdist5[w] > 7])
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-27-2048.jpg)
![cont..
Bigrams and collocations:
*Bigrams
>>>sent=['near','river', 'bank']
>>>bigrams(sent)
basic to many NLP apps; transliteration,
translation
*collocations: frequent bigrams of rare words
>>>text4.collocations()
basic to some WSD approaches
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-28-2048.jpg)



![cont..
Playing with text corpora
Available corporas: Gutenberg, Web and chat
text, Brown, Reuters, inaugural address, etc.
>>> from nltk.corpus import inaugural
>>> inaugural.fileids()
>>>fileid[:4] for fileid in
inaugural.fileids()]
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-32-2048.jpg)
![cont..
>>> cfd = nltk.ConditionalFreqDist(
(target, file[:4])
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['america', 'citizen']
if w.lower().startswith(target))
>>> cfd.plot()
Conditional Freq distribution of words 'america' and
'citizen' with different years
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-33-2048.jpg)
![cont..
Generating text (applying bigrams)
>>> def generate_model(cfdist, word, num=15):
for i in range(num):
print word,
word = cfdist[word].max()
>>>text = nltk.corpus.genesis.words('englishkjv.txt')
>>>bigrams = nltk.bigrams(text)
>>>cfd = nltk.ConditionalFreqDist(bigrams)
>>print cfd['living']
>>generate_model(cfd, 'living')
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-34-2048.jpg)

![cont..
Stop words:
>>> from nltk.corpus import stopwords
>>> stopwords.words('english')
Percentage of content
>>> def content_fraction(text):
stopwords = nltk.corpus.stopwords.words('english')
content = [w for w in text if w.lower() not in stopwords]
return len(content) / len(text)
>>> content_fraction(nltk.corpus.reuters.words())
is the useful fraction of useful words!
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-36-2048.jpg)



![cont..
Tokenization:
>>> tokens = nltk.word_tokenize(raw)
>>> type(tokens)
>>> len(tokens)
>>> tokens[:15]
convert to Text
>>> text = nltk.Text(tokens)
>>> type(text)
Now you can do all above things with this!
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-40-2048.jpg)
![cont..
What about HTML?
>>> url =
"http://news.bbc.co.uk/2/hi/health/2284783.stm"
>>> html = urlopen(url).read()
>>> html[:60]
It's HTML; Clean the tags...
>>> raw = nltk.clean_html(html)
>>> tokens = nltk.word_tokenize(raw)
>>> tokens[:60]
>>> text = nltk.Text(tokens)
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-41-2048.jpg)


![cont..
Stemming : NLTK has inbuilt stemmers
>>>text =['apples','called','indians','applying']
>>> porter = nltk.PorterStemmer()
>>> lancaster = nltk.LancasterStemmer()
>>>[porter.stem(p) for p in text]
>>>[lancaster.stem(p) for p in text]
Lemmatization: WordNet lemmetizer, removes
affixes only if the new word exist in dictionary
>>> wnl = nltk.WordNetLemmatizer()
>>> [wnl.lemmatize(t) for t in text]
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-44-2048.jpg)

![cont..
Classifying with NLTK:
Problem: Gender identification from name
Feature last letter
>>> def gender_features(word):
return {'last_letter': word[1]}
Get data
>>> from nltk.corpus import names
>>> import random
(CC) KBCS CDAC MUMBAI](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-46-2048.jpg)
![cont..
>>> names = ([(name, 'male') for name in
names.words('male.txt')] +
[(name, 'female') for name in
names.words('female.txt')])
>>> random.shuffle(names)
Get Feature set
>>> featuresets = [(gender_features(n), g) for (n,g) in
names]
>>> train_set, test_set = featuresets[500:], featuresets[:500]
Train
>>> classifier = nltk.NaiveBayesClassifier.train(train_set)
Test (CC) KBCS CDAC MUMBAI
>>> classifier.classify(gender_features('Neo'))](https://crownmelresort.com/image.slidesharecdn.com/nltkfoss-100818001605-phpapp01/75/Natural-Language-Toolkit-NLTK-Basics-47-2048.jpg)