Downloaded 20 times































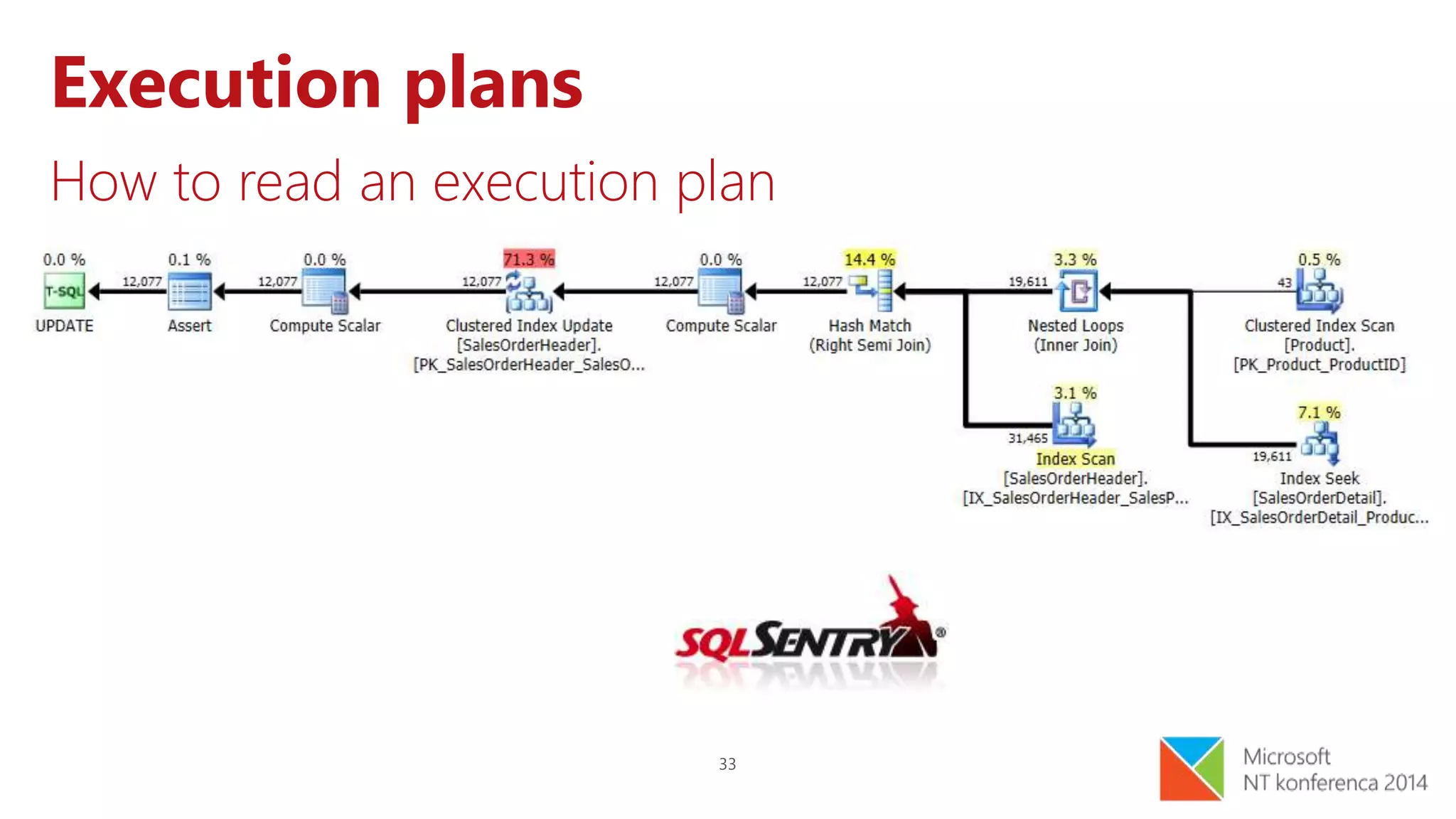
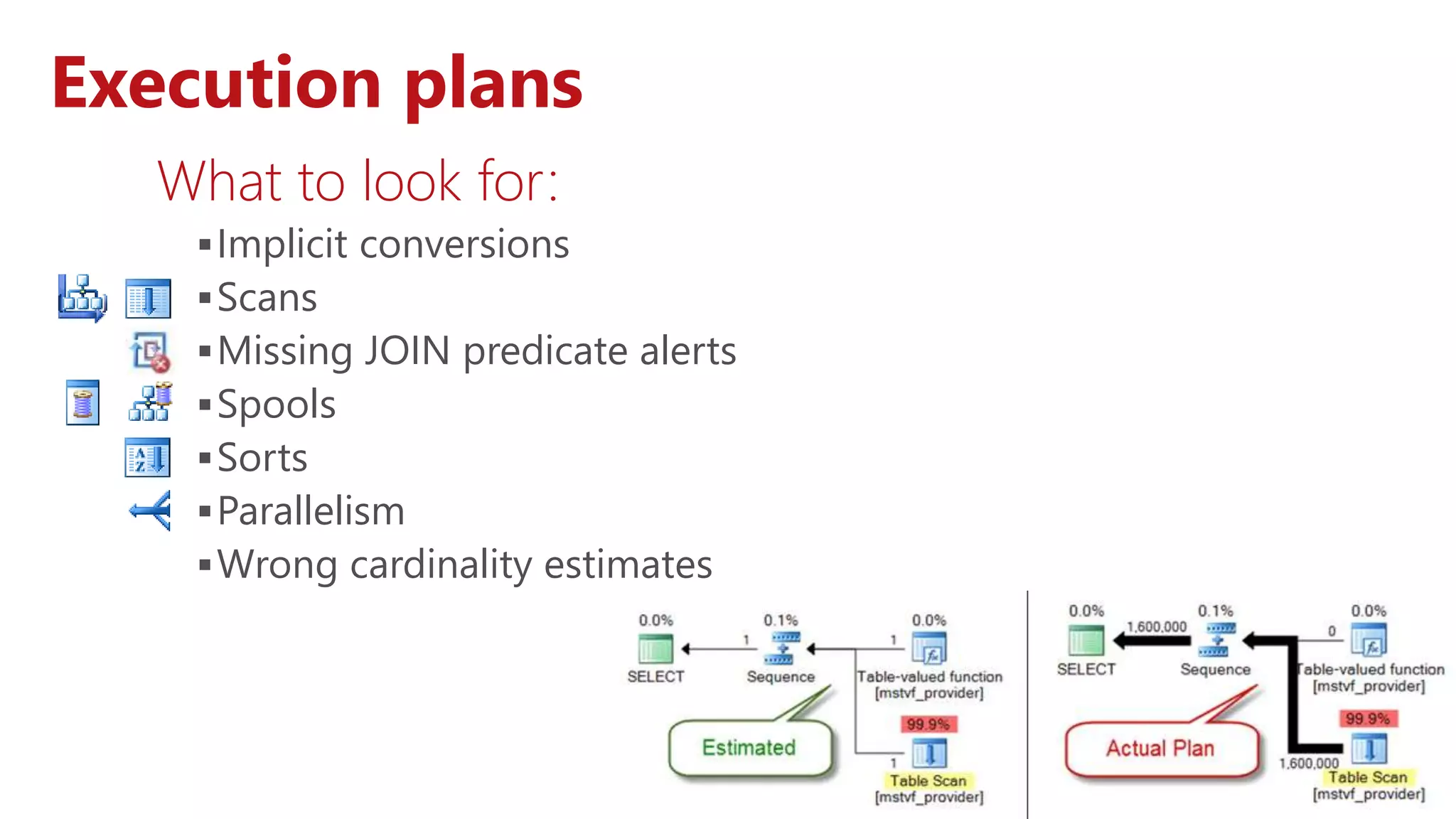









































The document addresses issues related to slow SQL queries, outlining various performance tuning strategies including schema design, query optimization, and indexing. Key points include the importance of normalization, avoidance of cursors, and the concept of sargability to enhance query performance. It also emphasizes the need for careful index creation and execution plan analysis to improve overall database efficiency.

































































