Downloaded 36 times





![Filtered Index – Allowed Syntax
◦ WHERE <filter_predicate>[from BOL: CREATE INDEX]
<filter_predicate> ::= <conjunct> [ AND <conjunct> ]
<conjunct> ::= <disjunct> | <comparison>
<disjunct> ::= column_name IN (constant ,…)
<comparison> ::= column_name <comparison_op> constant
<comparison_op> ::= { IS | IS NOT | = | <> | != | > | >= | !> | < | <= | !< }
◦ No BETWEEN, no LIKE, no subquery, no variables
◦ So must be simple and deterministic](https://image.slidesharecdn.com/microsoftsqlserverfilteredindexessparsecolumns2011-110308021923-phpapp02/75/Microsoft-SQL-Server-Filtered-Indexes-Sparse-Columns-Feb-2011-6-2048.jpg)




























![Filtered Index – Allowed Syntax
◦ WHERE <filter_predicate>[from BOL: CREATE INDEX]
<filter_predicate> ::= <conjunct> [ AND <conjunct> ]
<conjunct> ::= <disjunct> | <comparison>
<disjunct> ::= column_name IN (constant ,…)
<comparison> ::= column_name <comparison_op> constant
<comparison_op> ::= { IS | IS NOT | = | <> | != | > | >= | !> | < | <= | !< }
◦ No BETWEEN, no LIKE, no subquery, no variables
◦ So must be simple and deterministic](https://crownmelresort.com/image.slidesharecdn.com/microsoftsqlserverfilteredindexessparsecolumns2011-110308021923-phpapp02/75/Microsoft-SQL-Server-Filtered-Indexes-Sparse-Columns-Feb-2011-6-2048.jpg)


























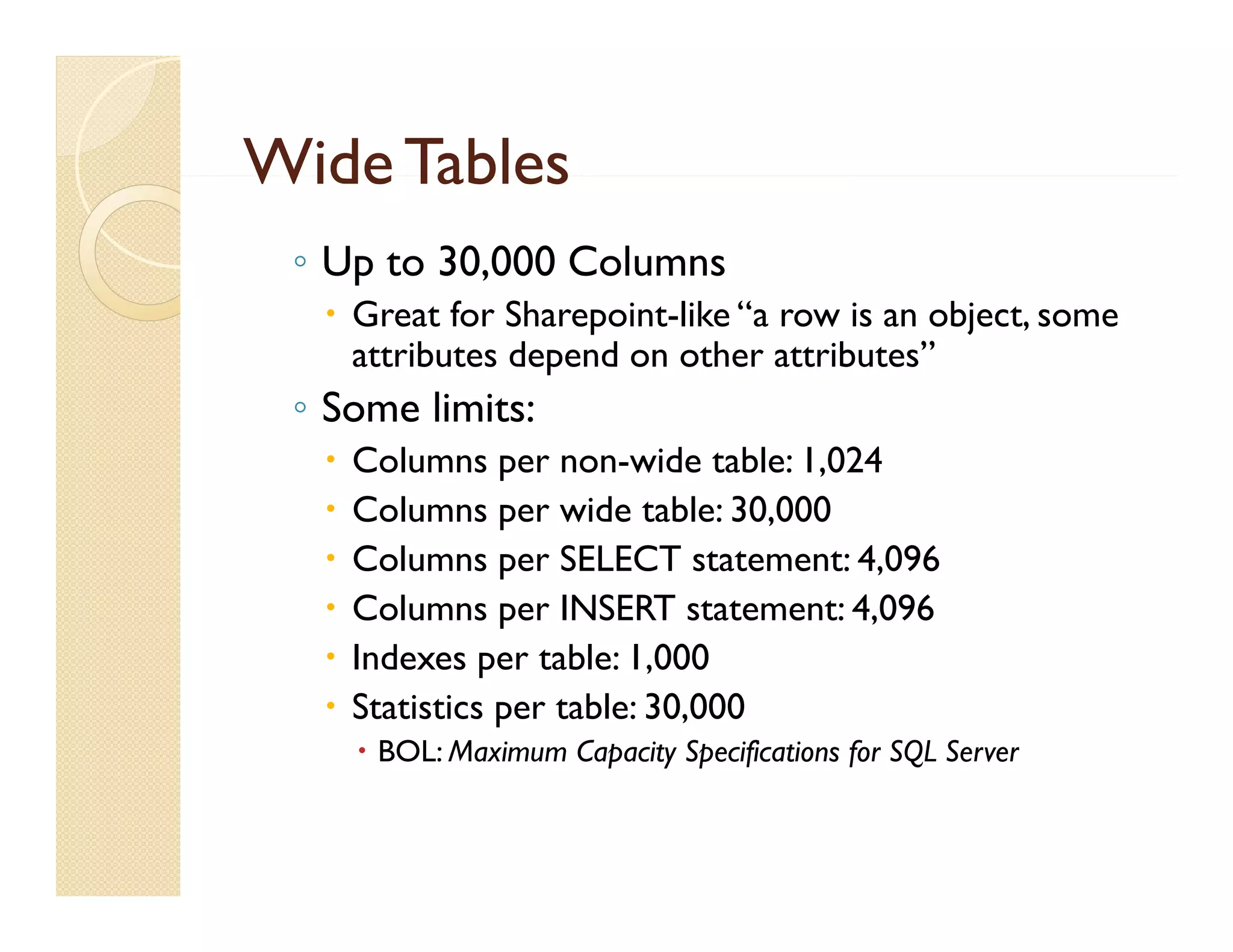
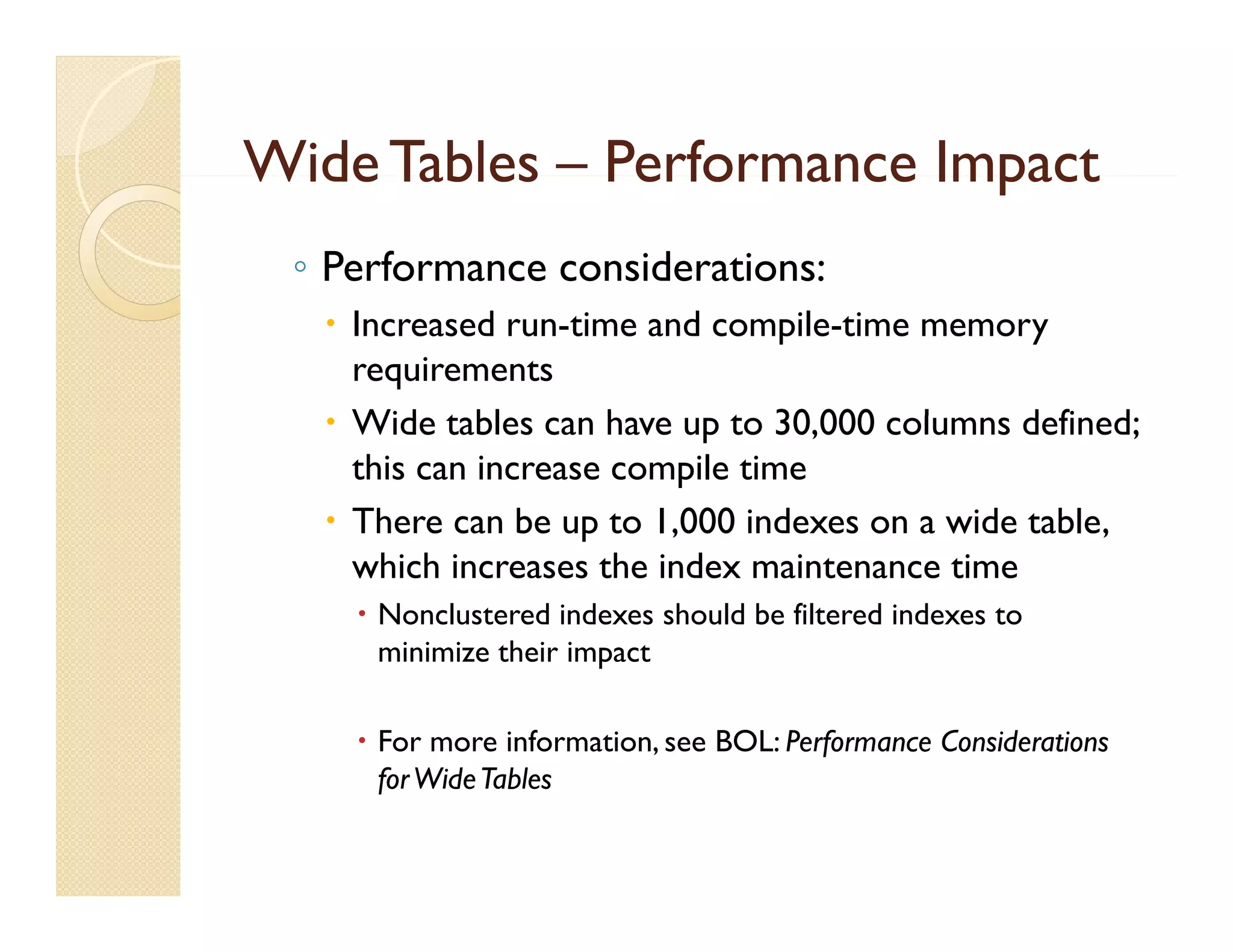
The document discusses Microsoft SQL Server's filtered indexes and sparse columns, detailing their functionalities and benefits, such as reduced storage costs and improved query performance. It highlights the implementation of filtered indexes to optimize queries for specific data subsets while addressing their requirements and limitations. Additionally, it covers wide tables and the use of sparse columns for flexible data storage, along with considerations for performance and maintenance.

























![[Www.pkbulk.blogspot.com]dbms10](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms10-130615034621-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





























































