Download as PDF, PPTX










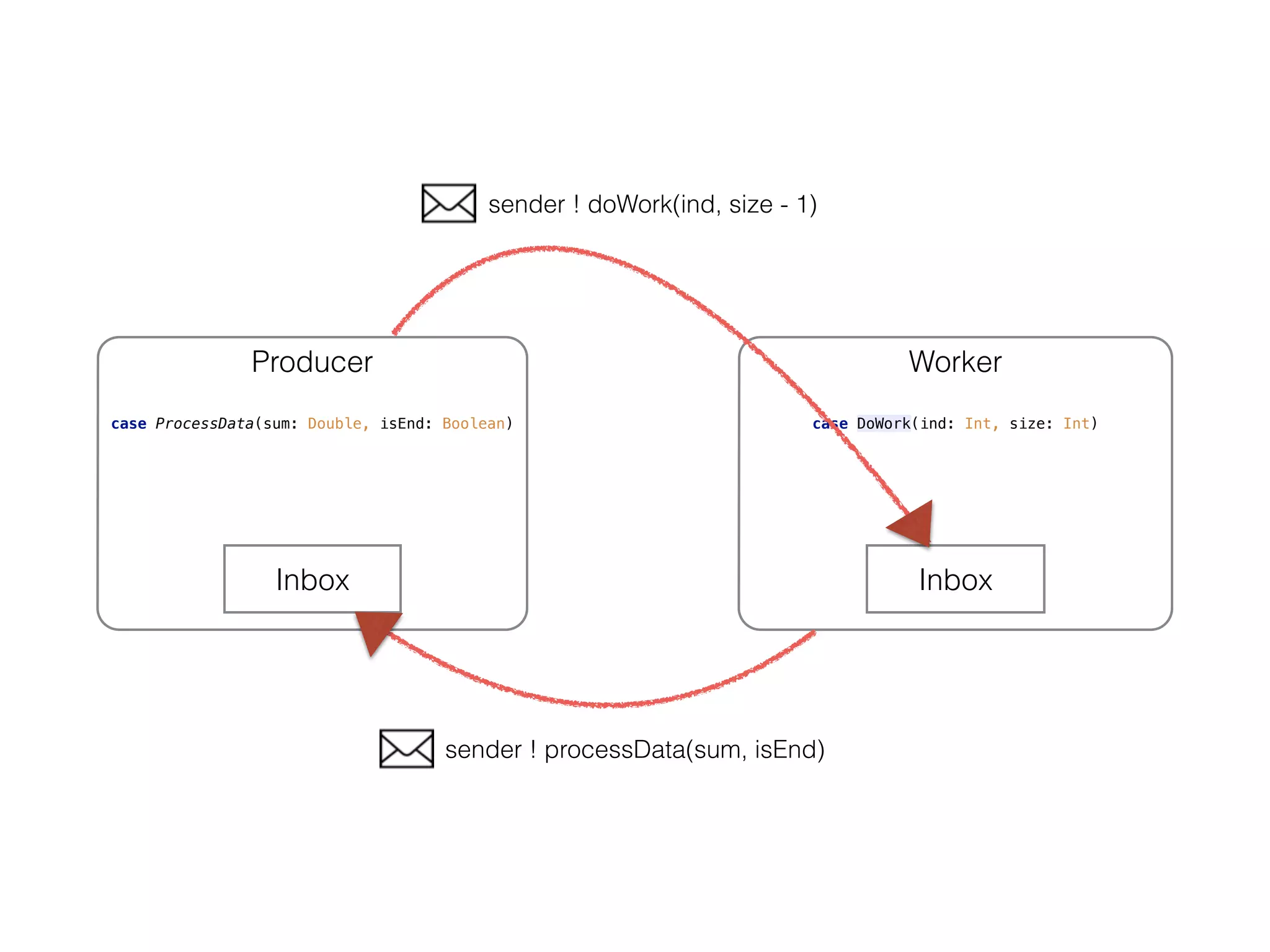


![Main
object Application extends App{
override def main(arg: Array[String]){
val system = ActorSystem("ClusterSystem")
system.actorOf(Props[Producer], name = "producer")
}
}
object ClusterMessageProtocol {
sealed trait Message
// Producer side
case class InitiateWorker(worker: ActorRef) extends Message
case class ProcessData(sum: Double) extends Message
// Actor side
case class DoWork(iter: List[String]) extends Message
}](https://image.slidesharecdn.com/meetuprandscala-150506003234-conversion-gate01/75/Seattle-useR-Group-R-Scala-15-2048.jpg)
![…
Worker Actor[akka://ClusterSystem/user/producer/workerRouter/$h#504275836] is alive!!!
Worker Actor[akka://ClusterSystem/user/producer/workerRouter/$e#1071584906] is alive!!!
Producer Actor[akka://ClusterSystem/user/producer#1272599354] is alive
Actor[akka://ClusterSystem/user/producer/workerRouter/$h#1269880699] => Partial Sum: -964.3282348781046, Size: 1000000
Actor[akka://ClusterSystem/user/producer/workerRouter/$f#500982456] => Partial Sum: -177.85266733478048, Size: 1000000
…
Actor[akka://ClusterSystem/user/producer/workerRouter/$e#1850062035] => Partial Sum: -547.8233029081448, Size: 1000000
Actor[akka://ClusterSystem/user/producer/workerRouter/$h#1269880699] => Partial Sum: -660.0674912837135, Size: 1000000
Producer Actor[akka://ClusterSystem/user/producer#1420020857] is dead. The sum is -13615.40143829277
> sum(vector)
[1] -13615.4](https://image.slidesharecdn.com/meetuprandscala-150506003234-conversion-gate01/75/Seattle-useR-Group-R-Scala-16-2048.jpg)
















![Main
object Application extends App{
override def main(arg: Array[String]){
val system = ActorSystem("ClusterSystem")
system.actorOf(Props[Producer], name = "producer")
}
}
object ClusterMessageProtocol {
sealed trait Message
// Producer side
case class InitiateWorker(worker: ActorRef) extends Message
case class ProcessData(sum: Double) extends Message
// Actor side
case class DoWork(iter: List[String]) extends Message
}](https://crownmelresort.com/image.slidesharecdn.com/meetuprandscala-150506003234-conversion-gate01/75/Seattle-useR-Group-R-Scala-15-2048.jpg)
![…
Worker Actor[akka://ClusterSystem/user/producer/workerRouter/$h#504275836] is alive!!!
Worker Actor[akka://ClusterSystem/user/producer/workerRouter/$e#1071584906] is alive!!!
Producer Actor[akka://ClusterSystem/user/producer#1272599354] is alive
Actor[akka://ClusterSystem/user/producer/workerRouter/$h#1269880699] => Partial Sum: -964.3282348781046, Size: 1000000
Actor[akka://ClusterSystem/user/producer/workerRouter/$f#500982456] => Partial Sum: -177.85266733478048, Size: 1000000
…
Actor[akka://ClusterSystem/user/producer/workerRouter/$e#1850062035] => Partial Sum: -547.8233029081448, Size: 1000000
Actor[akka://ClusterSystem/user/producer/workerRouter/$h#1269880699] => Partial Sum: -660.0674912837135, Size: 1000000
Producer Actor[akka://ClusterSystem/user/producer#1420020857] is dead. The sum is -13615.40143829277
> sum(vector)
[1] -13615.4](https://crownmelresort.com/image.slidesharecdn.com/meetuprandscala-150506003234-conversion-gate01/75/Seattle-useR-Group-R-Scala-16-2048.jpg)



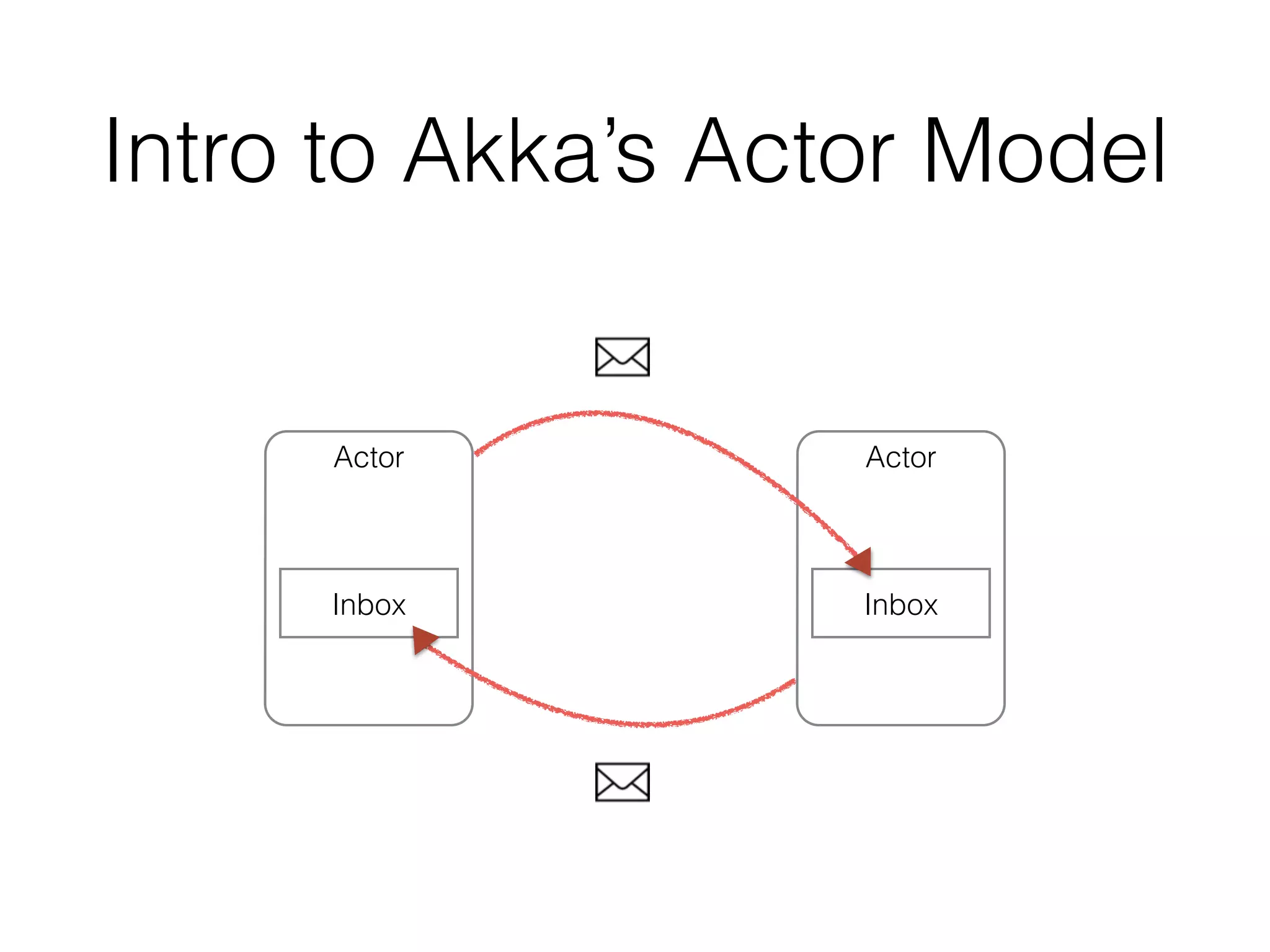
This document discusses scaling R to large datasets using Scala and Akka. It describes how R has limitations for parallelism and handling large data in memory. The author demonstrates reading a large CSV file of 100 million doubles (1.7GB) in parallel using Scala, Akka actors and Rserve. Producer and Worker actors divide the file and sum parts in Rserve. This allows scaling R computations to large data beyond a single machine's memory. Potential applications mentioned include optimization, distributed linear algebra, machine learning and statistics.






![[PyCon 2014 APAC] How to integrate python into a scala stack to build realtim...](https://cdn.slidesharecdn.com/ss_thumbnails/howtointegratepythonintoascalastacktobuildrealtimepredictivemodelsv2nomanuscript-140518005621-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





































































