Downloaded 10 times



![Data Processing (MapReduce)
Input
Data
Map()
Map()
Map()
Reduce()
Reduce()
Output
Data
Split
[k1, v1]
Sort by
k1
Merge
[k1, [v1, v2, v3…]]](https://image.slidesharecdn.com/mapreduceintroduction-151026131037-lva1-app6891/75/Introducing-MapReduce-Programming-Framework-4-2048.jpg)


![Outputs of Mappers
Process 1
[Hello, 1]
[Hadoop, 1]
[Goodbye, 1]
[Hadoop, 1]
Process 2
[Hello, 1]
[World, 1]
[Bye, 1]
[World, 1]](https://image.slidesharecdn.com/mapreduceintroduction-151026131037-lva1-app6891/75/Introducing-MapReduce-Programming-Framework-8-2048.jpg)
![Consolidated Result of Reducers
[Bye, 1]
[Goodbye, 1]
[Hadoop, 2]
[Hello, 2]
[World, 2]](https://image.slidesharecdn.com/mapreduceintroduction-151026131037-lva1-app6891/75/Introducing-MapReduce-Programming-Framework-9-2048.jpg)





![Data Processing (MapReduce)
Input
Data
Map()
Map()
Map()
Reduce()
Reduce()
Output
Data
Split
[k1, v1]
Sort by
k1
Merge
[k1, [v1, v2, v3…]]](https://crownmelresort.com/image.slidesharecdn.com/mapreduceintroduction-151026131037-lva1-app6891/75/Introducing-MapReduce-Programming-Framework-4-2048.jpg)



![Outputs of Mappers
Process 1
[Hello, 1]
[Hadoop, 1]
[Goodbye, 1]
[Hadoop, 1]
Process 2
[Hello, 1]
[World, 1]
[Bye, 1]
[World, 1]](https://crownmelresort.com/image.slidesharecdn.com/mapreduceintroduction-151026131037-lva1-app6891/75/Introducing-MapReduce-Programming-Framework-8-2048.jpg)
![Consolidated Result of Reducers
[Bye, 1]
[Goodbye, 1]
[Hadoop, 2]
[Hello, 2]
[World, 2]](https://crownmelresort.com/image.slidesharecdn.com/mapreduceintroduction-151026131037-lva1-app6891/75/Introducing-MapReduce-Programming-Framework-9-2048.jpg)



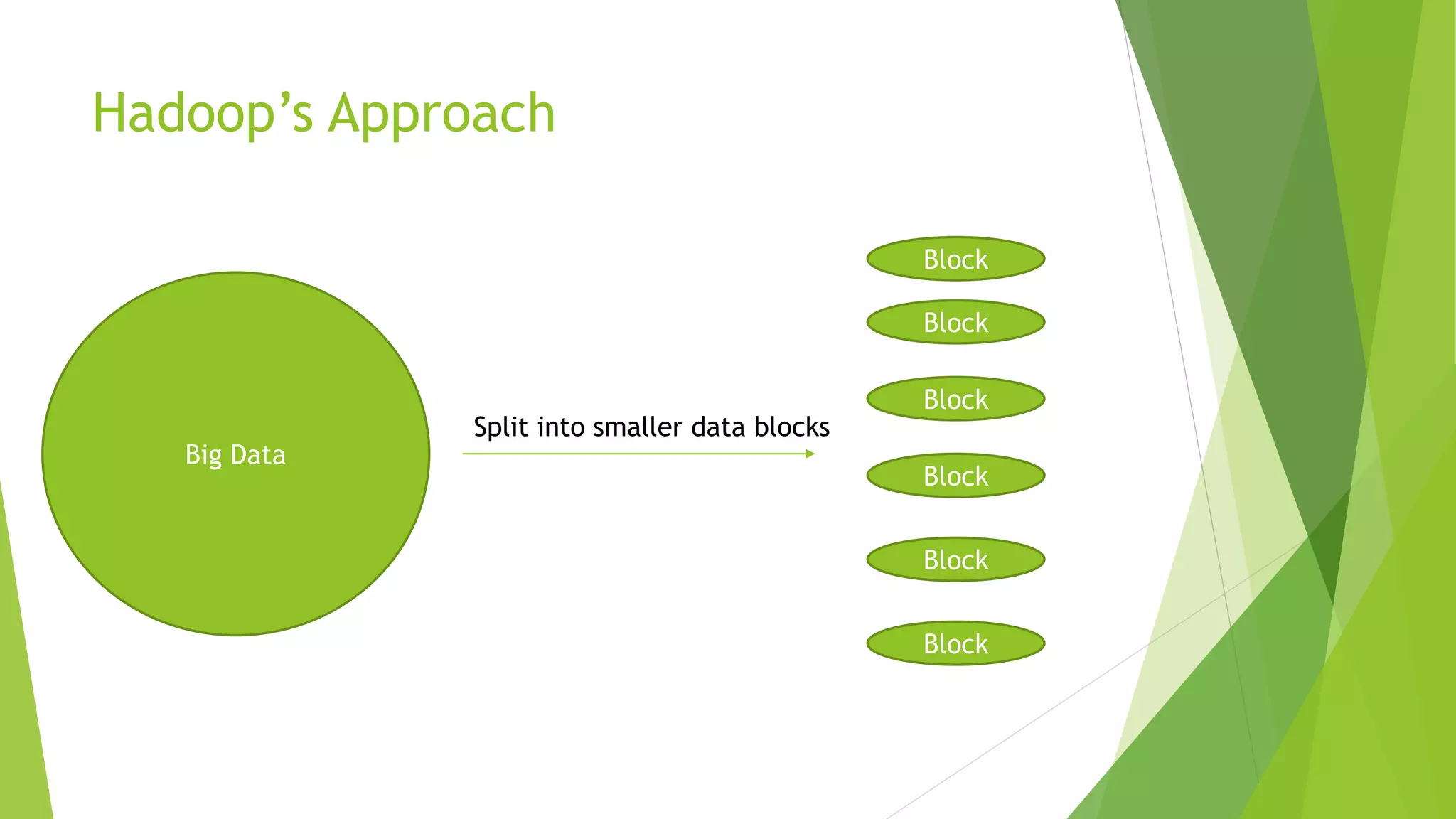
The document introduces the MapReduce programming model. It explains that MapReduce handles parallelization and distributed computing tasks like multi-threading, failure handling, and I/O behind the scenes. Developers focus on defining two functions: the mapper which splits input into key-value pairs, and the reducer which aggregates the output of mappers by keys. MapReduce processes large datasets by splitting input files into blocks, running the mapper function on each block in parallel, shuffling and sorting the outputs, and running the reducer to aggregate the results.






























































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)












