Download as PDF, PPTX


















![KSQL - SELECT
Selects rows from a KSQL stream or table
Result of this statement will not be persisted in a Kafka topic and will only be printed out
in the console
from_item is one of the following: stream_name, table_name
SELECT select_expr [, ...]
FROM from_item
[ LEFT JOIN join_table ON join_criteria ]
[ WINDOW window_expression ]
[ WHERE condition ]
[ GROUP BY grouping_expression ]
[ HAVING having_expression ]
[ LIMIT count ];](https://image.slidesharecdn.com/07guidoschmutz-181022185952/75/Ingesting-and-Processing-IoT-Data-Using-MQTT-Kafka-Connect-and-Kafka-Streams-KSQL-35-2048.jpg)

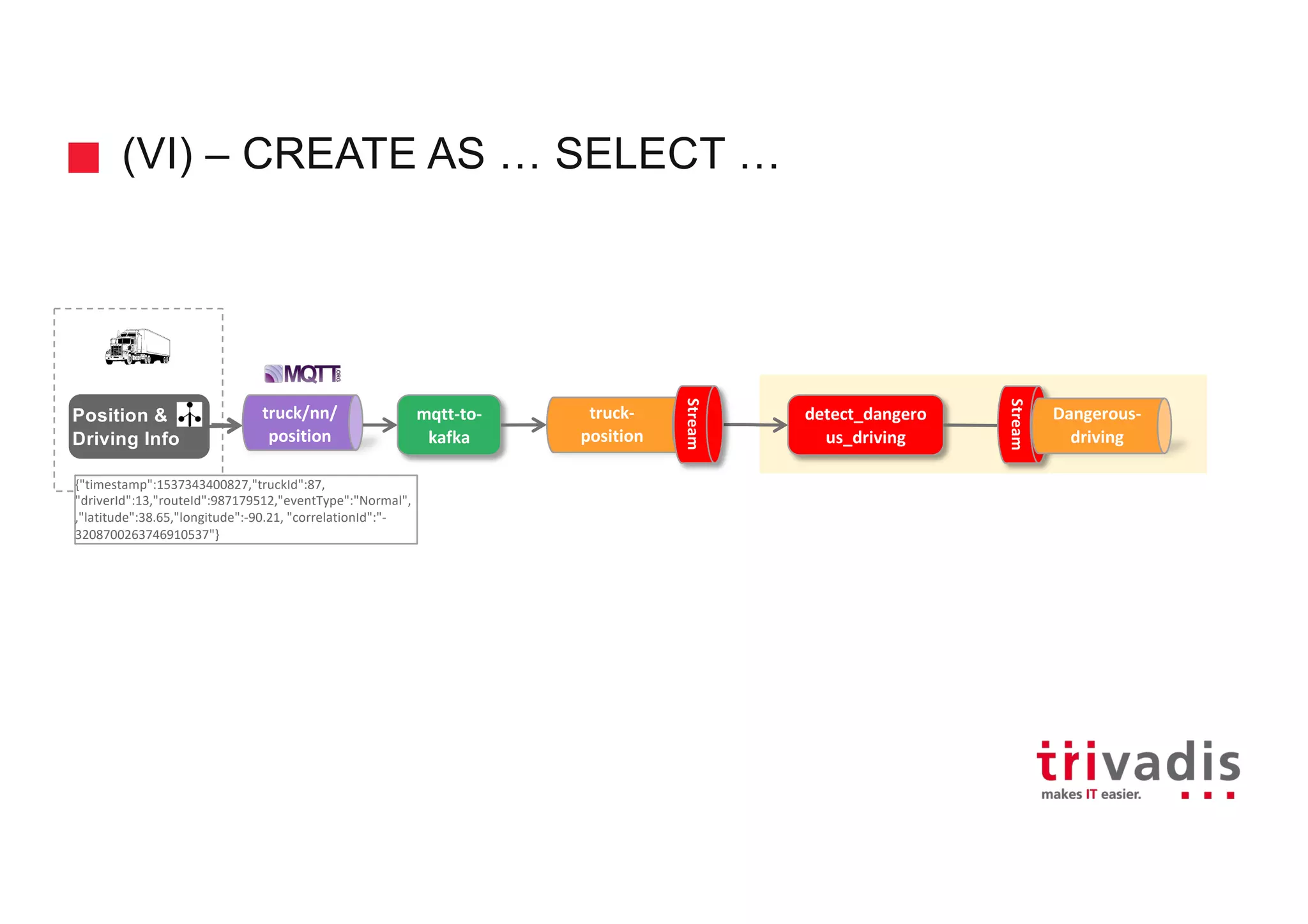
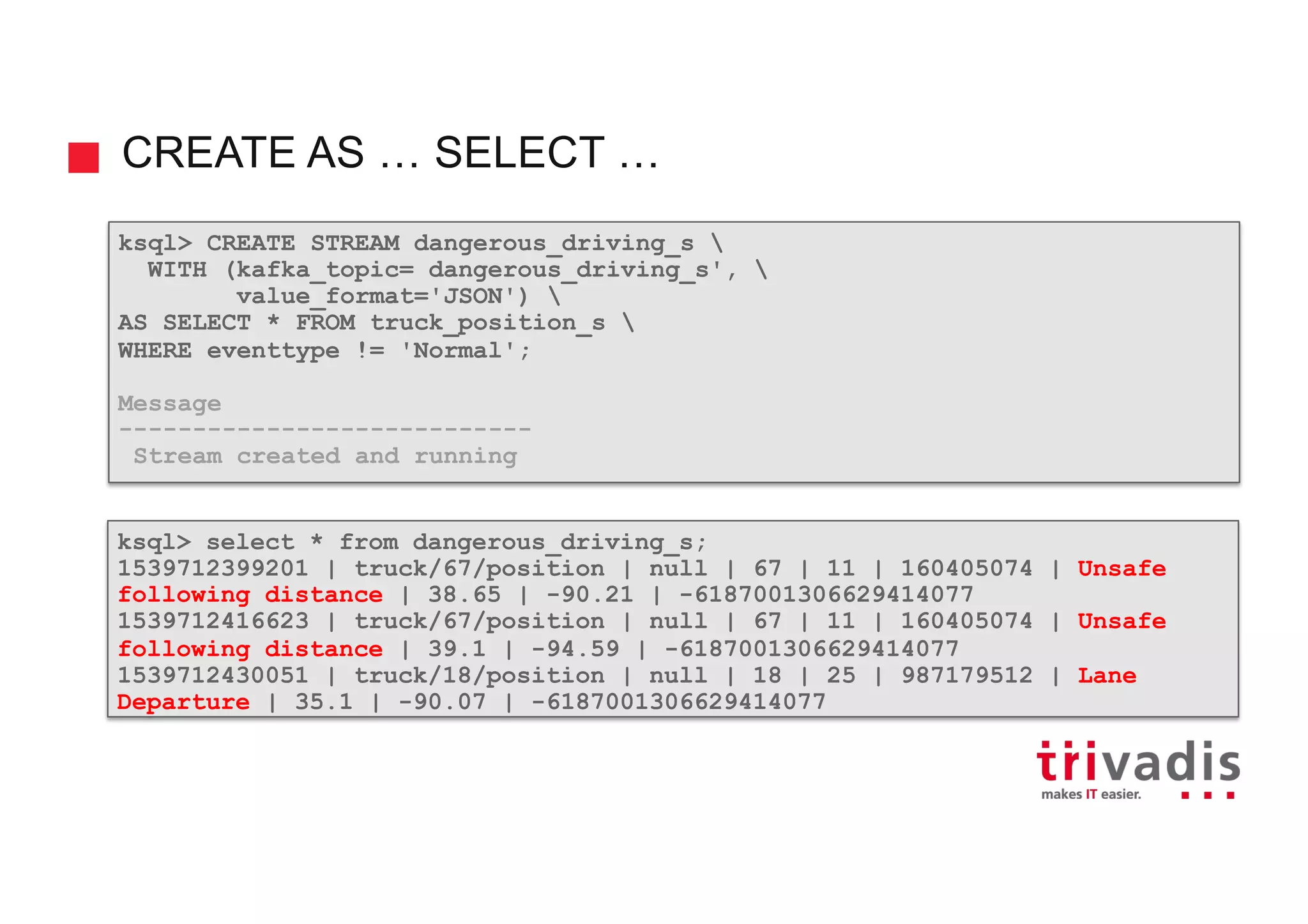
![CREATE STREAM … AS SELECT …
Create a new KSQL table along with the corresponding Kafka topic and stream the
result of the SELECT query as a changelog into the topic
WINDOW clause can only be used if the from_item is a stream
CREATE STREAM stream_name
[WITH ( property_name = expression [, ...] )]
AS SELECT select_expr [, ...]
FROM from_stream [ LEFT | FULL | INNER ]
JOIN [join_table | join_stream]
[ WITHIN [(before TIMEUNIT, after TIMEUNIT) | N TIMEUNIT] ] ON join_criteria
[ WHERE condition ]
[PARTITION BY column_name];](https://image.slidesharecdn.com/07guidoschmutz-181022185952/75/Ingesting-and-Processing-IoT-Data-Using-MQTT-Kafka-Connect-and-Kafka-Streams-KSQL-38-2048.jpg)
![INSERT INTO … AS SELECT …
Stream the result of the SELECT query into an existing stream and its underlying topic
schema and partitioning column produced by the query must match the stream’s
schema and key
If the schema and partitioning column are incompatible with the stream, then the
statement will return an error
stream_name and from_item must both
refer to a Stream. Tables are not supported!
CREATE STREAM stream_name ...;
INSERT INTO stream_name
SELECT select_expr [., ...]
FROM from_stream
[ WHERE condition ]
[ PARTITION BY column_name ];](https://image.slidesharecdn.com/07guidoschmutz-181022185952/75/Ingesting-and-Processing-IoT-Data-Using-MQTT-Kafka-Connect-and-Kafka-Streams-KSQL-39-2048.jpg)











































![KSQL - SELECT
Selects rows from a KSQL stream or table
Result of this statement will not be persisted in a Kafka topic and will only be printed out
in the console
from_item is one of the following: stream_name, table_name
SELECT select_expr [, ...]
FROM from_item
[ LEFT JOIN join_table ON join_criteria ]
[ WINDOW window_expression ]
[ WHERE condition ]
[ GROUP BY grouping_expression ]
[ HAVING having_expression ]
[ LIMIT count ];](https://crownmelresort.com/image.slidesharecdn.com/07guidoschmutz-181022185952/75/Ingesting-and-Processing-IoT-Data-Using-MQTT-Kafka-Connect-and-Kafka-Streams-KSQL-35-2048.jpg)


![CREATE STREAM … AS SELECT …
Create a new KSQL table along with the corresponding Kafka topic and stream the
result of the SELECT query as a changelog into the topic
WINDOW clause can only be used if the from_item is a stream
CREATE STREAM stream_name
[WITH ( property_name = expression [, ...] )]
AS SELECT select_expr [, ...]
FROM from_stream [ LEFT | FULL | INNER ]
JOIN [join_table | join_stream]
[ WITHIN [(before TIMEUNIT, after TIMEUNIT) | N TIMEUNIT] ] ON join_criteria
[ WHERE condition ]
[PARTITION BY column_name];](https://crownmelresort.com/image.slidesharecdn.com/07guidoschmutz-181022185952/75/Ingesting-and-Processing-IoT-Data-Using-MQTT-Kafka-Connect-and-Kafka-Streams-KSQL-38-2048.jpg)
![INSERT INTO … AS SELECT …
Stream the result of the SELECT query into an existing stream and its underlying topic
schema and partitioning column produced by the query must match the stream’s
schema and key
If the schema and partitioning column are incompatible with the stream, then the
statement will return an error
stream_name and from_item must both
refer to a Stream. Tables are not supported!
CREATE STREAM stream_name ...;
INSERT INTO stream_name
SELECT select_expr [., ...]
FROM from_stream
[ WHERE condition ]
[ PARTITION BY column_name ];](https://crownmelresort.com/image.slidesharecdn.com/07guidoschmutz-181022185952/75/Ingesting-and-Processing-IoT-Data-Using-MQTT-Kafka-Connect-and-Kafka-Streams-KSQL-39-2048.jpg)

















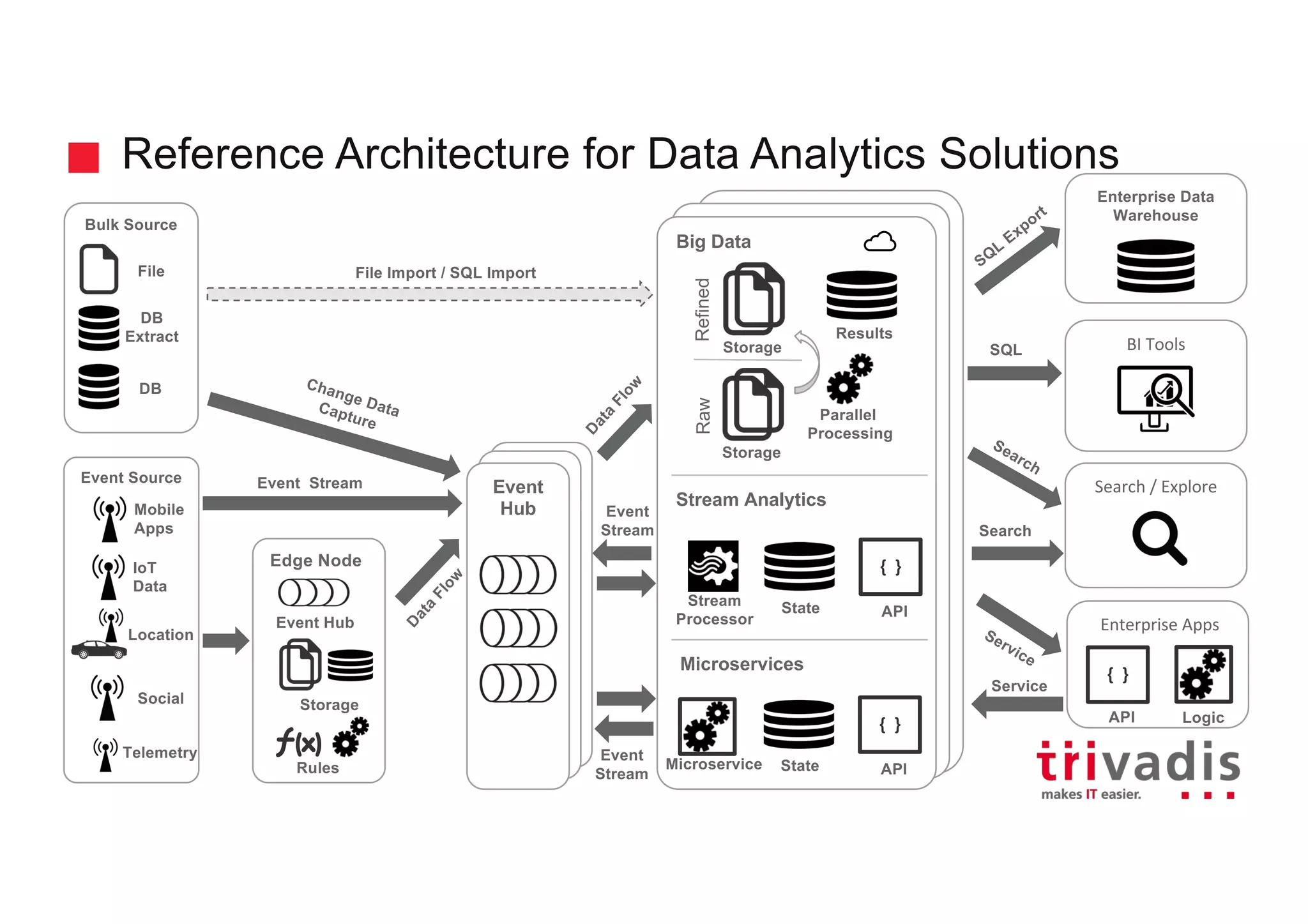
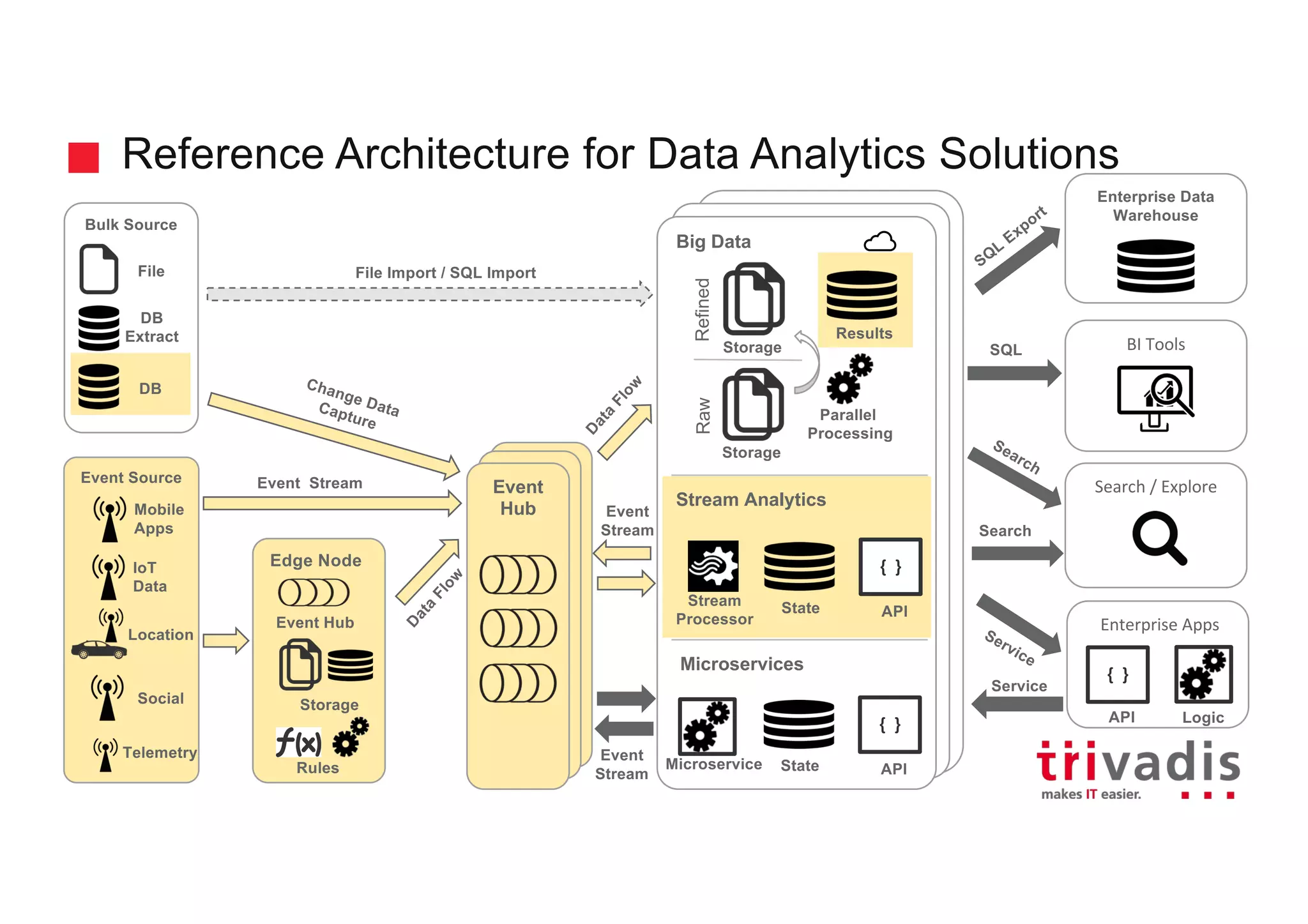
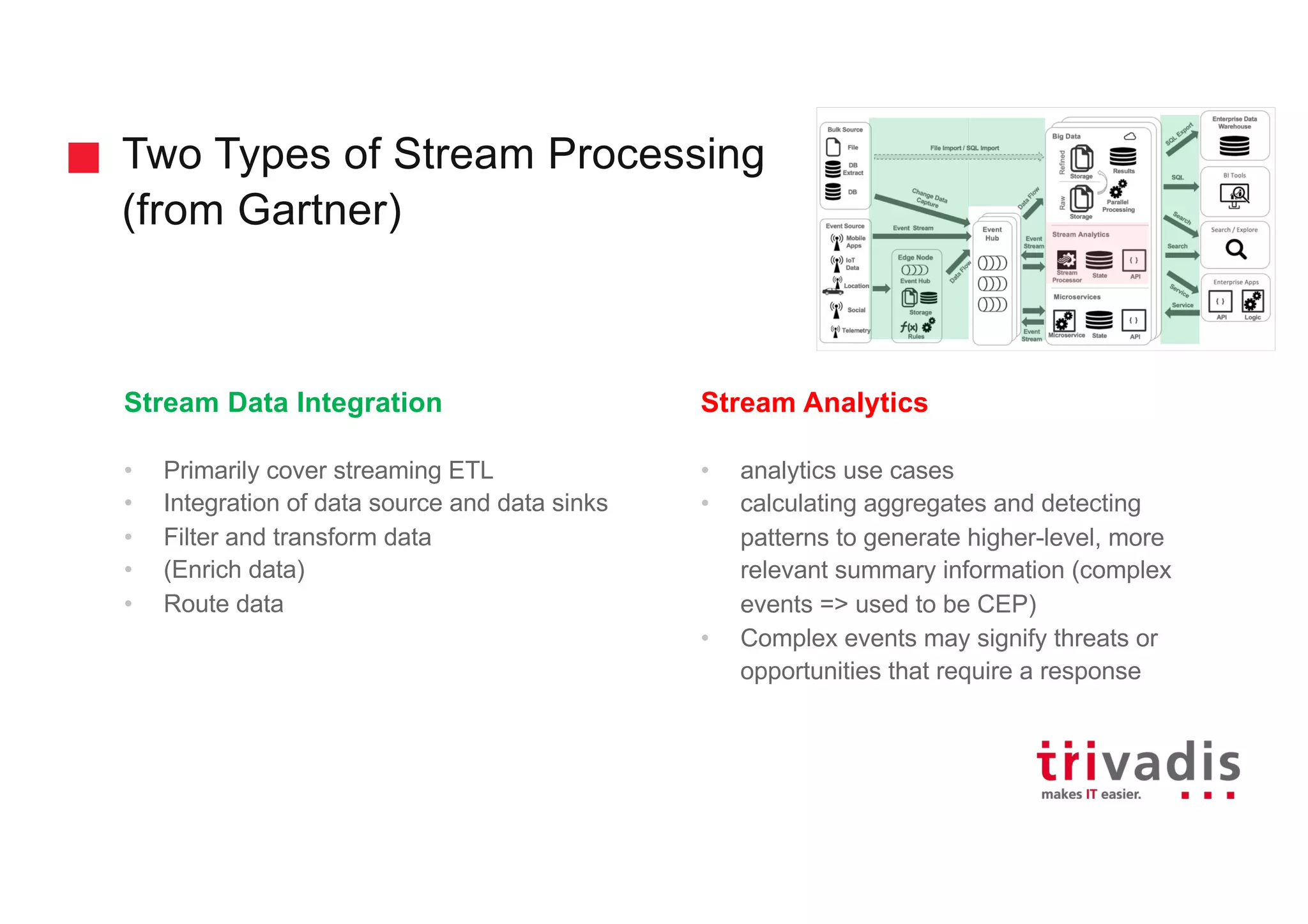
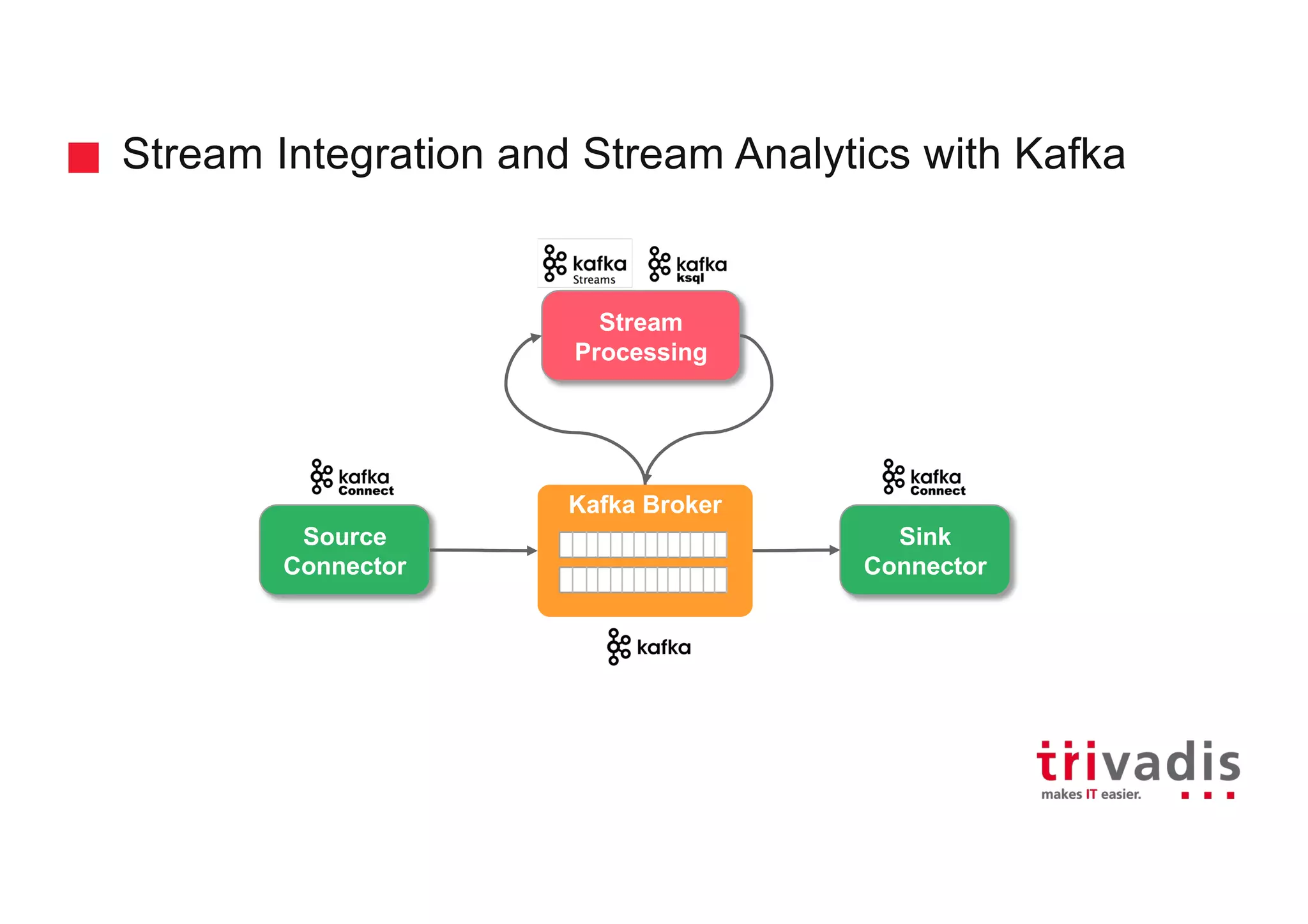
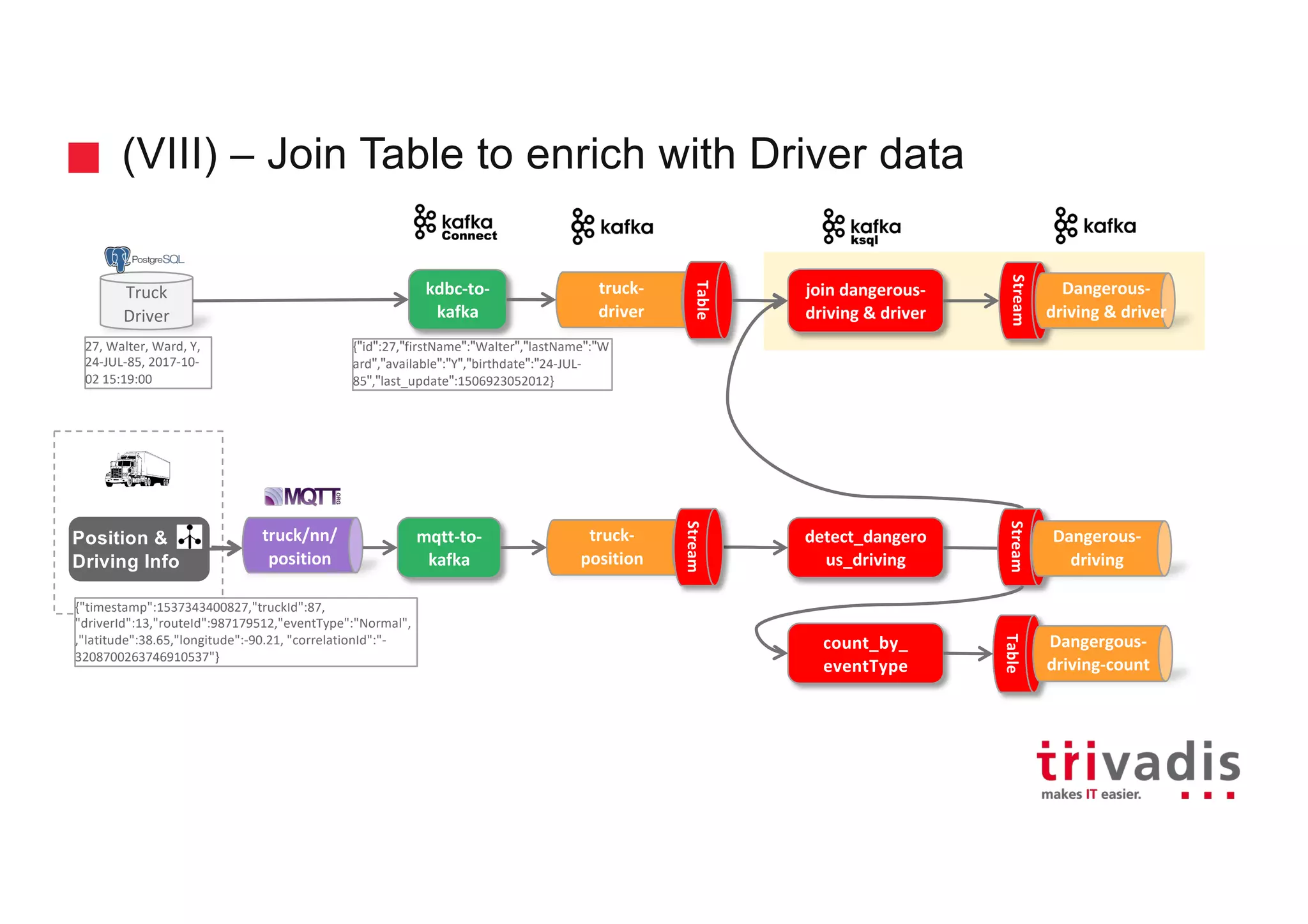
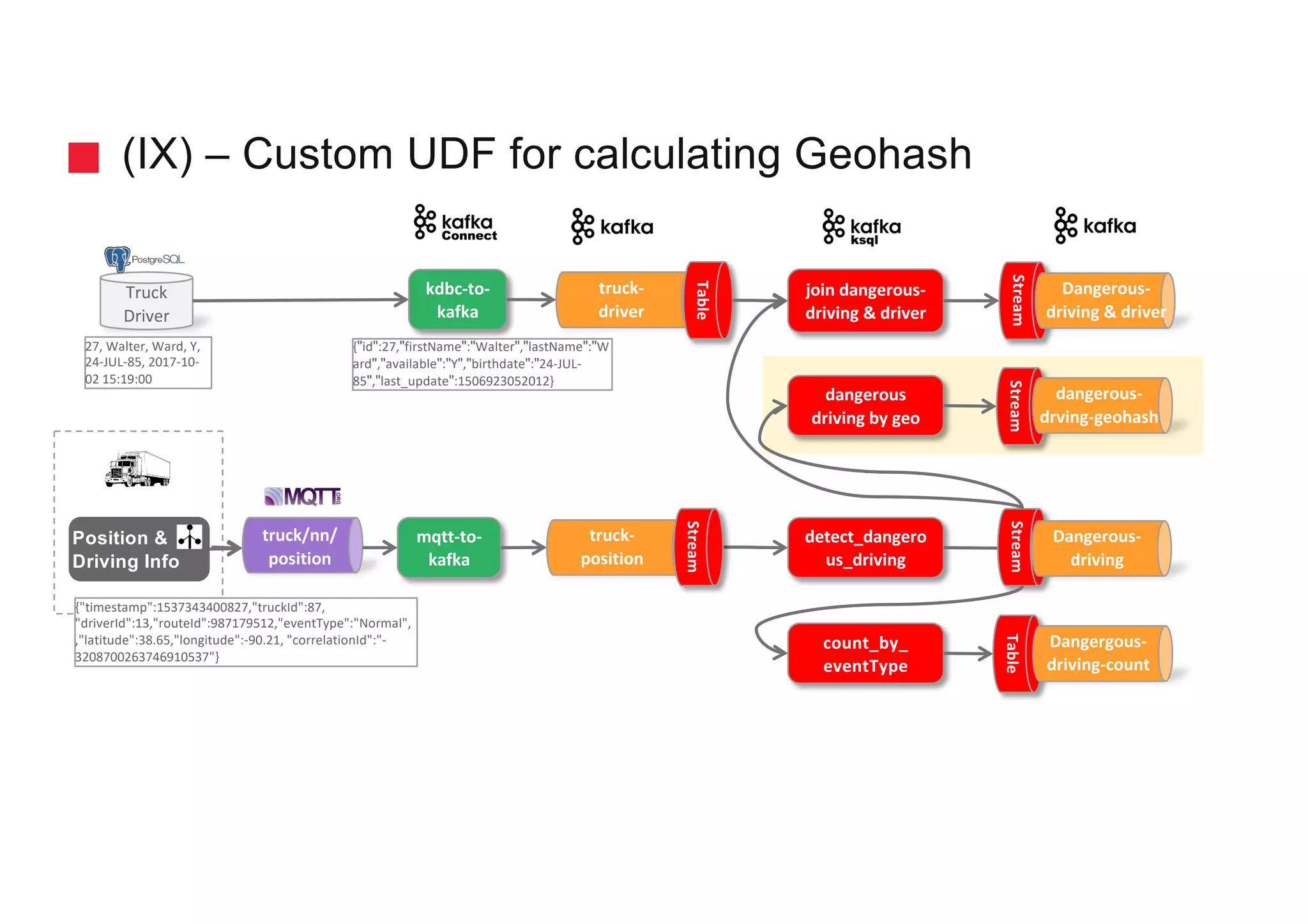
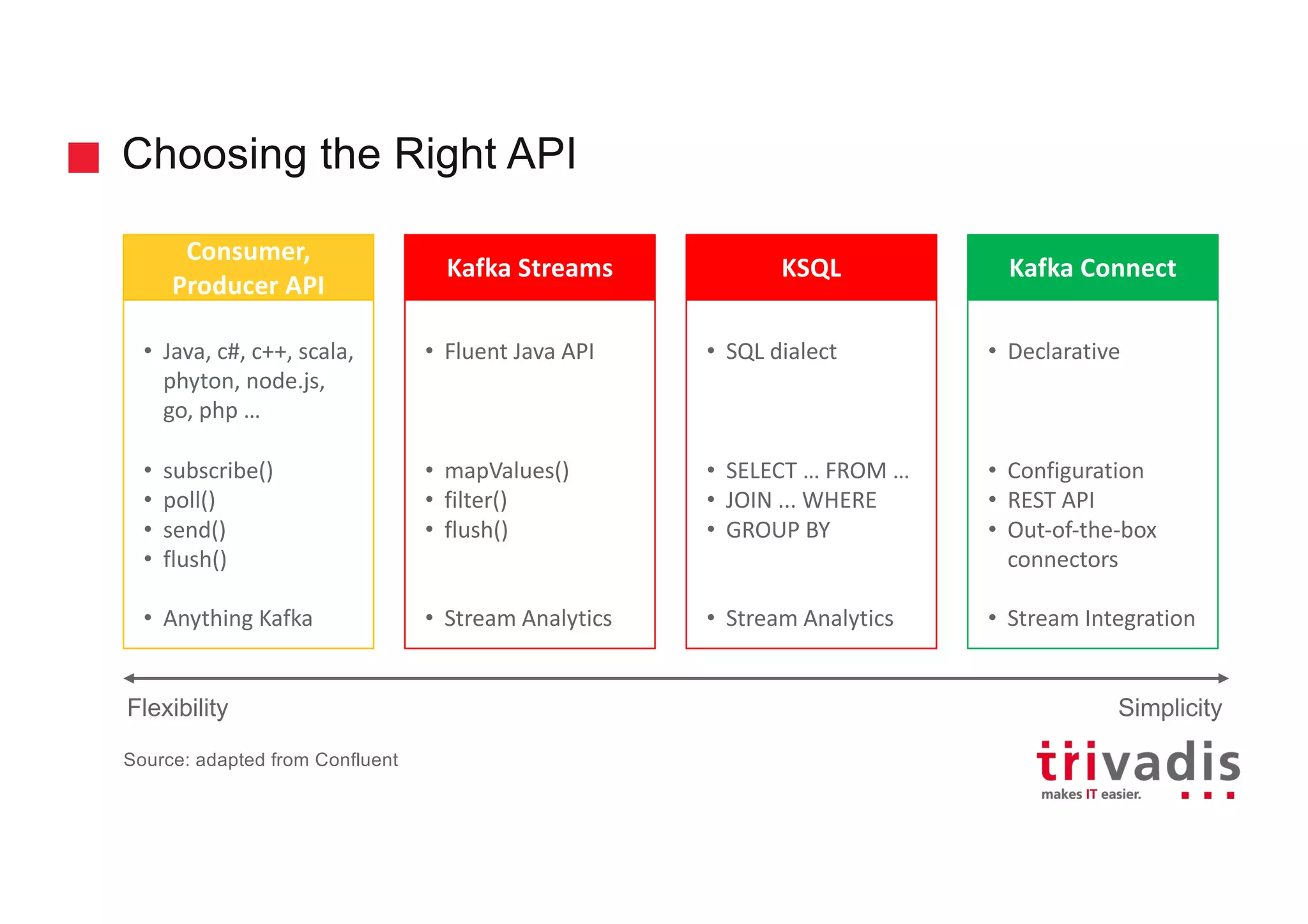
The document discusses the ingestion and processing of IoT data using MQTT, Kafka Connect, and KSQL, focusing on a logistics use case involving trucks. It outlines the architecture for data integration and analytics, detailing how to connect IoT devices to Kafka and process streaming data in real-time. Key components include MQTT protocols, Kafka source connectors, and KSQL for stream analytics, offering methods for data manipulation and insights generation.























































































