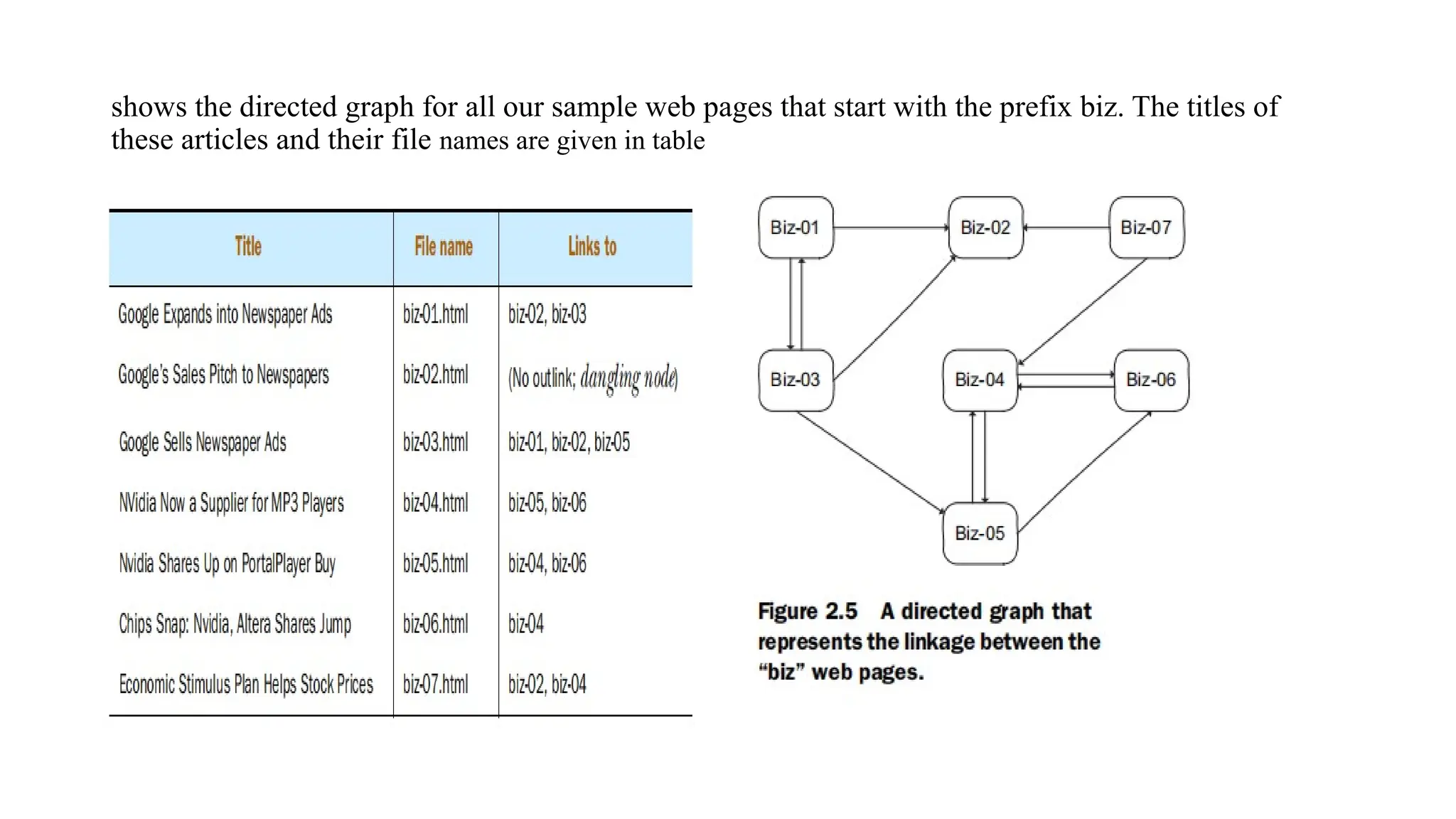
Information retrieval (IR) is a process of accessing relevant information from data collections, utilizing key components like indexing, query processing, ranking, and user interfaces. Tools like Lucene are instrumental in indexing documents and enhancing search efficiency, employing methods such as link analysis and classification algorithms like Naive Bayes to improve search results. The document also discusses the Pagerank algorithm, its calculations, and its applications in search engine optimization.

































































































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)
