Download to read offline



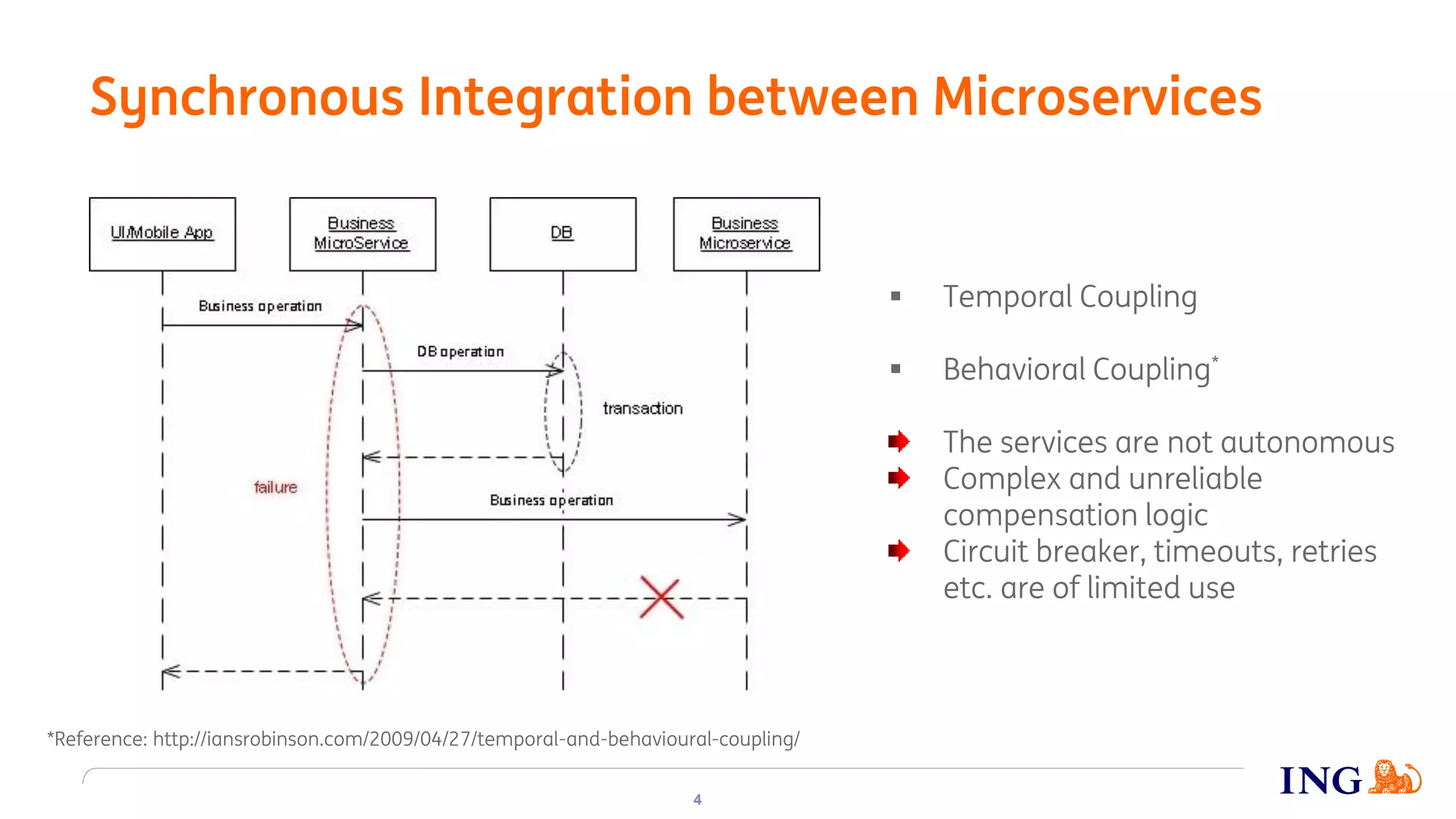
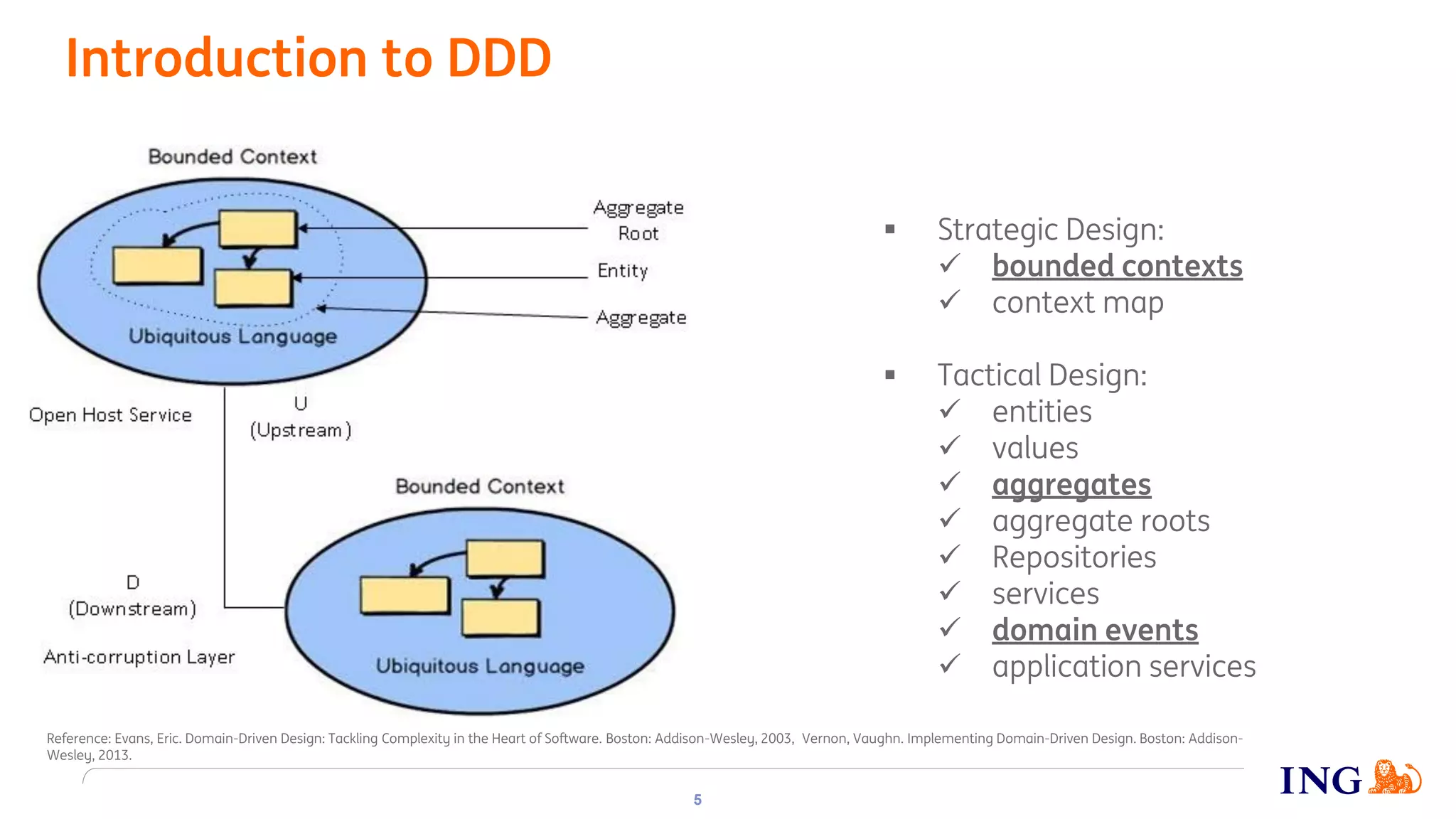



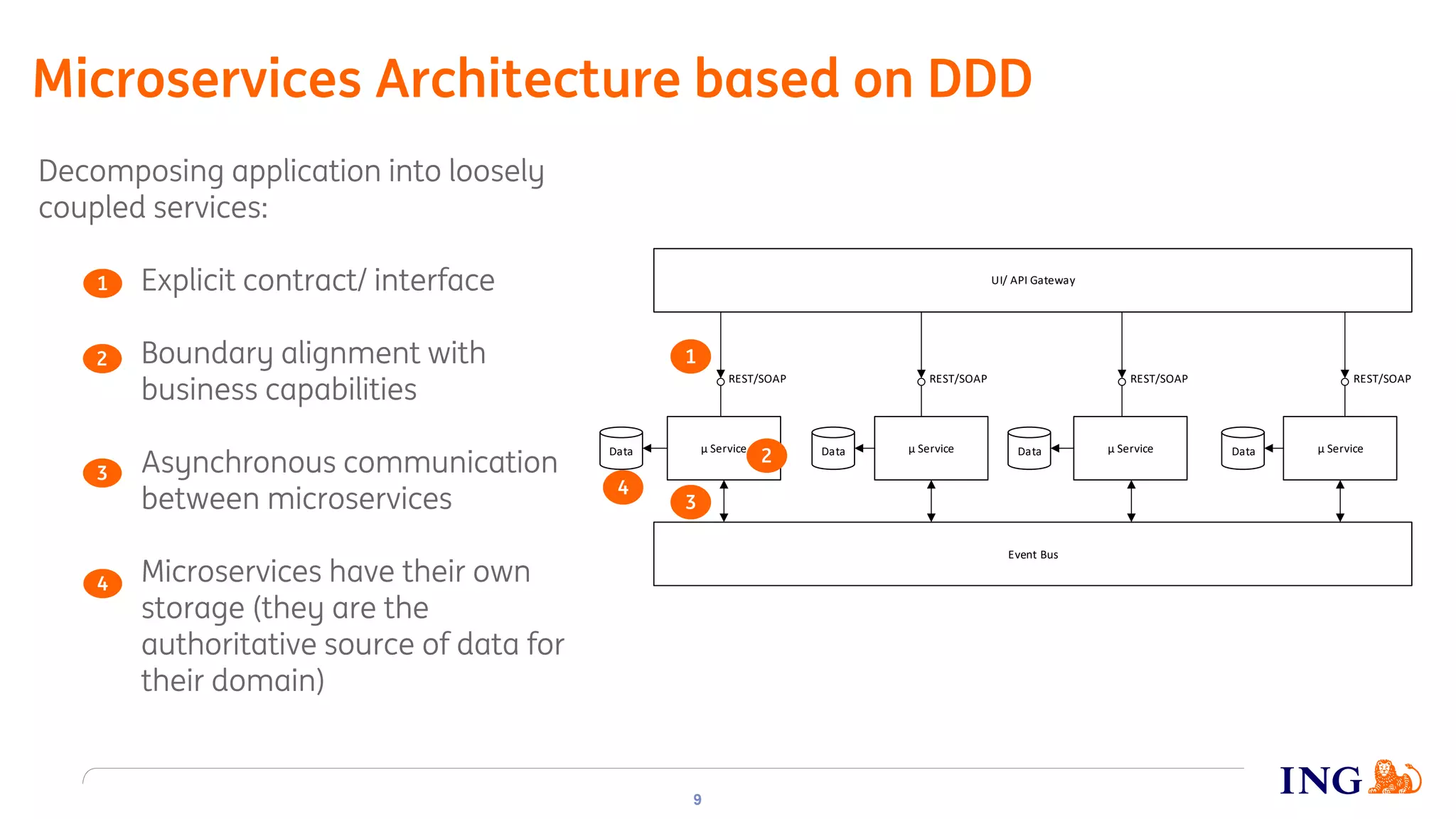
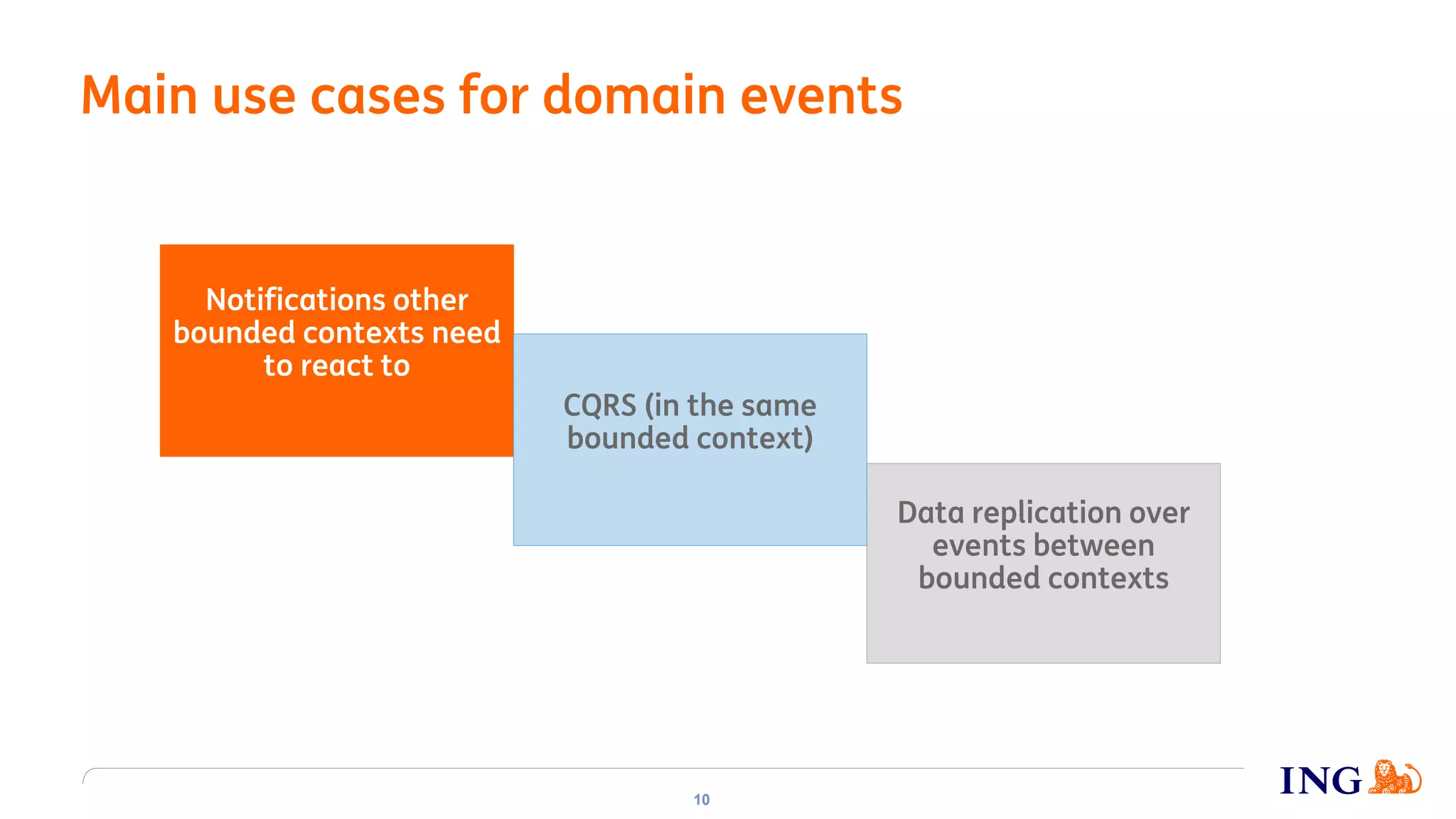

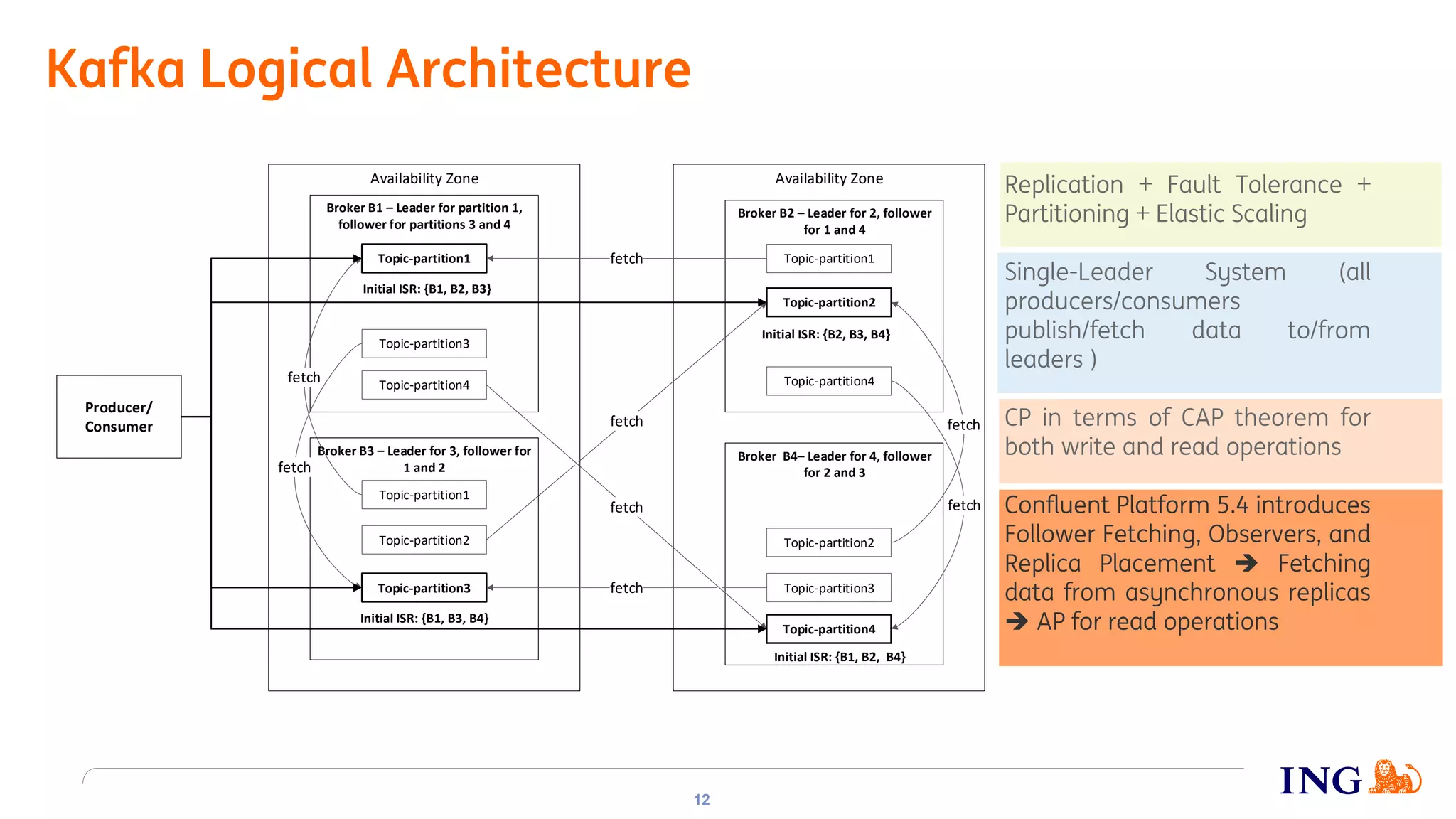

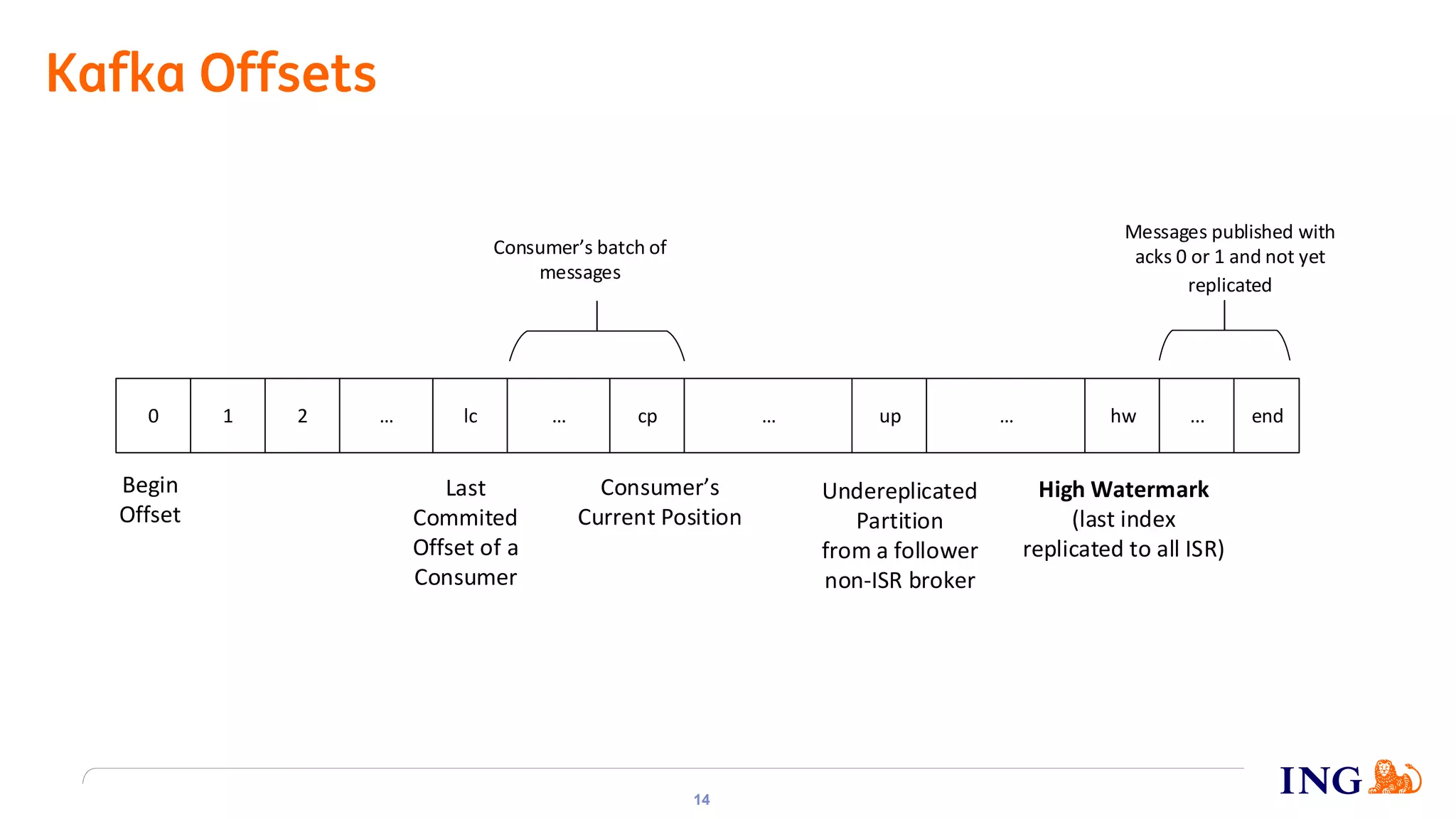



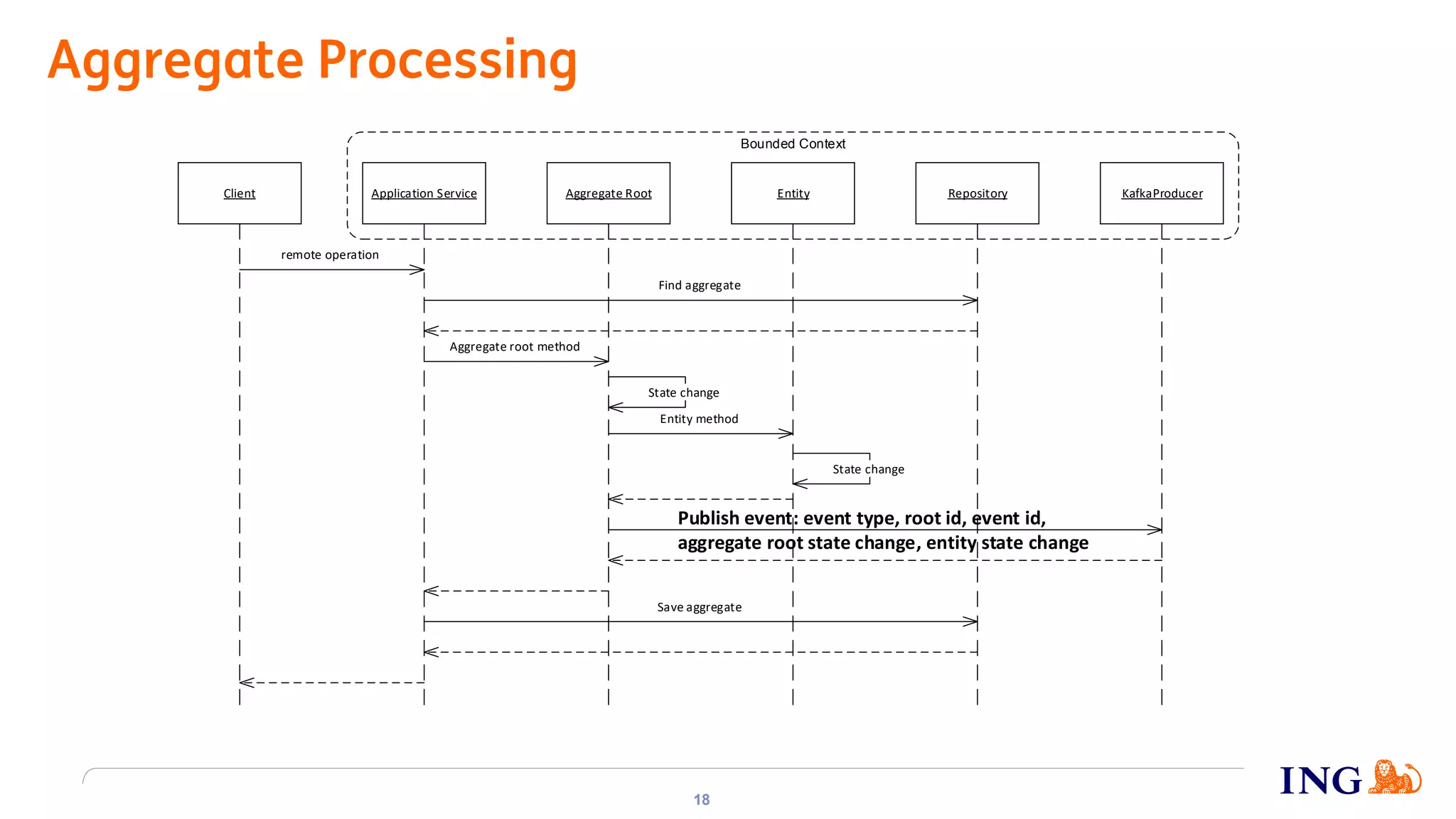
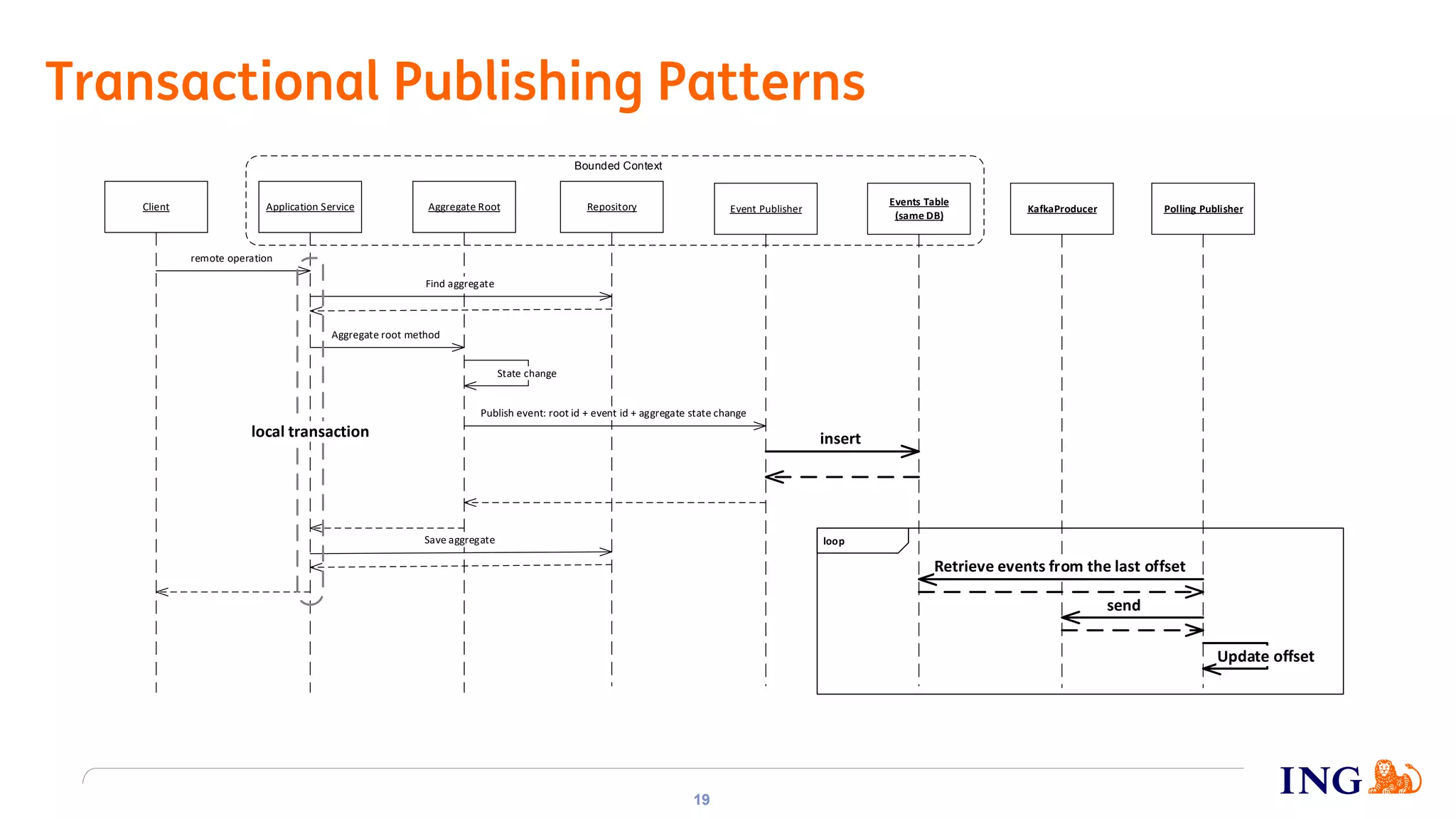




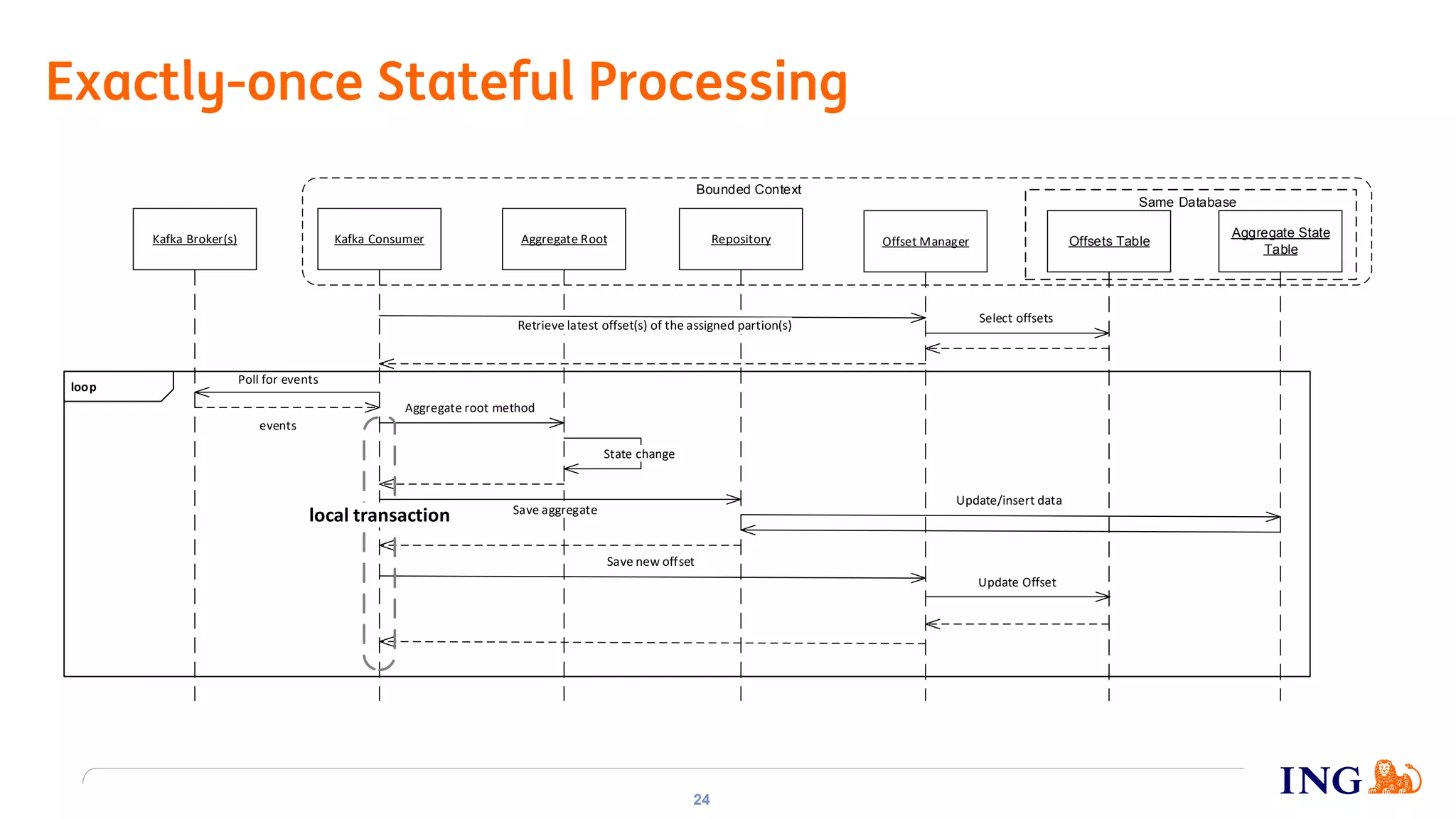
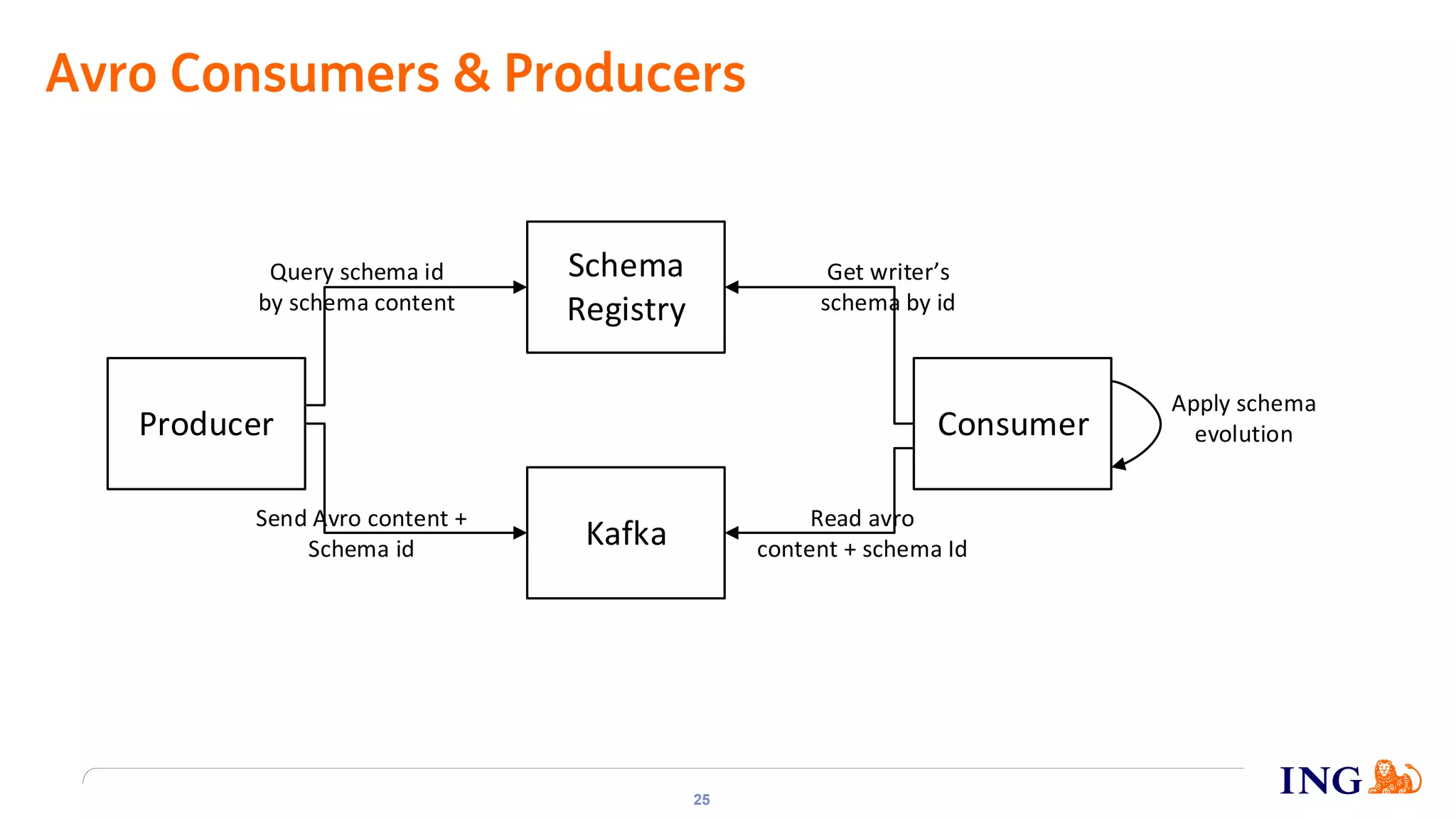
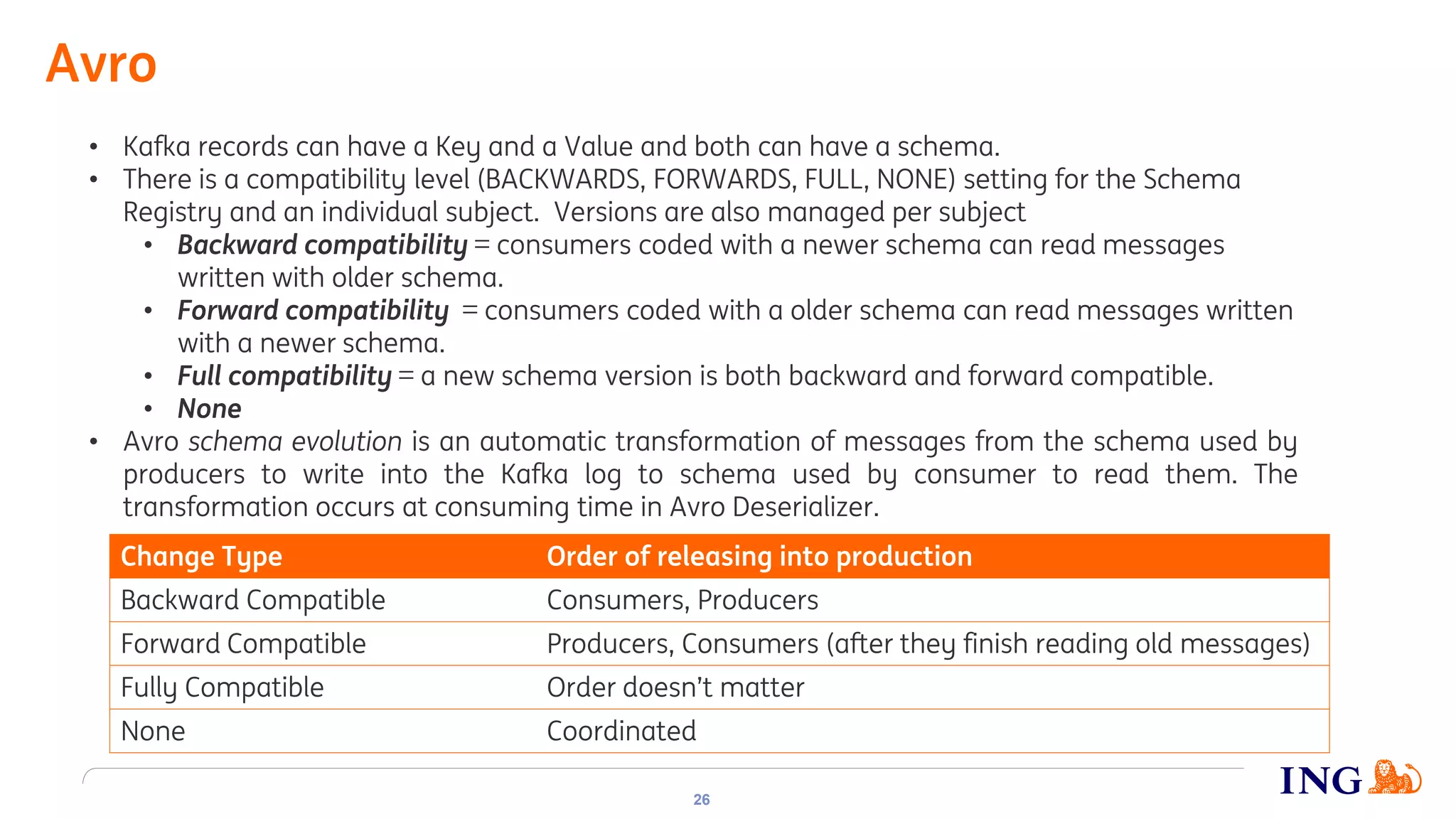

































The document discusses the implementation of domain events using Kafka in microservices integration, highlighting challenges and benefits such as agility, resilience, and fault tolerance. It covers key concepts like domain-driven design (DDD), microservices architecture, and Kafka's messaging capabilities including event publishing, delivery guarantees, and consumer configurations. The conclusion emphasizes how DDD aids in decomposing systems for microservices while ensuring resilience and scalability.



































































