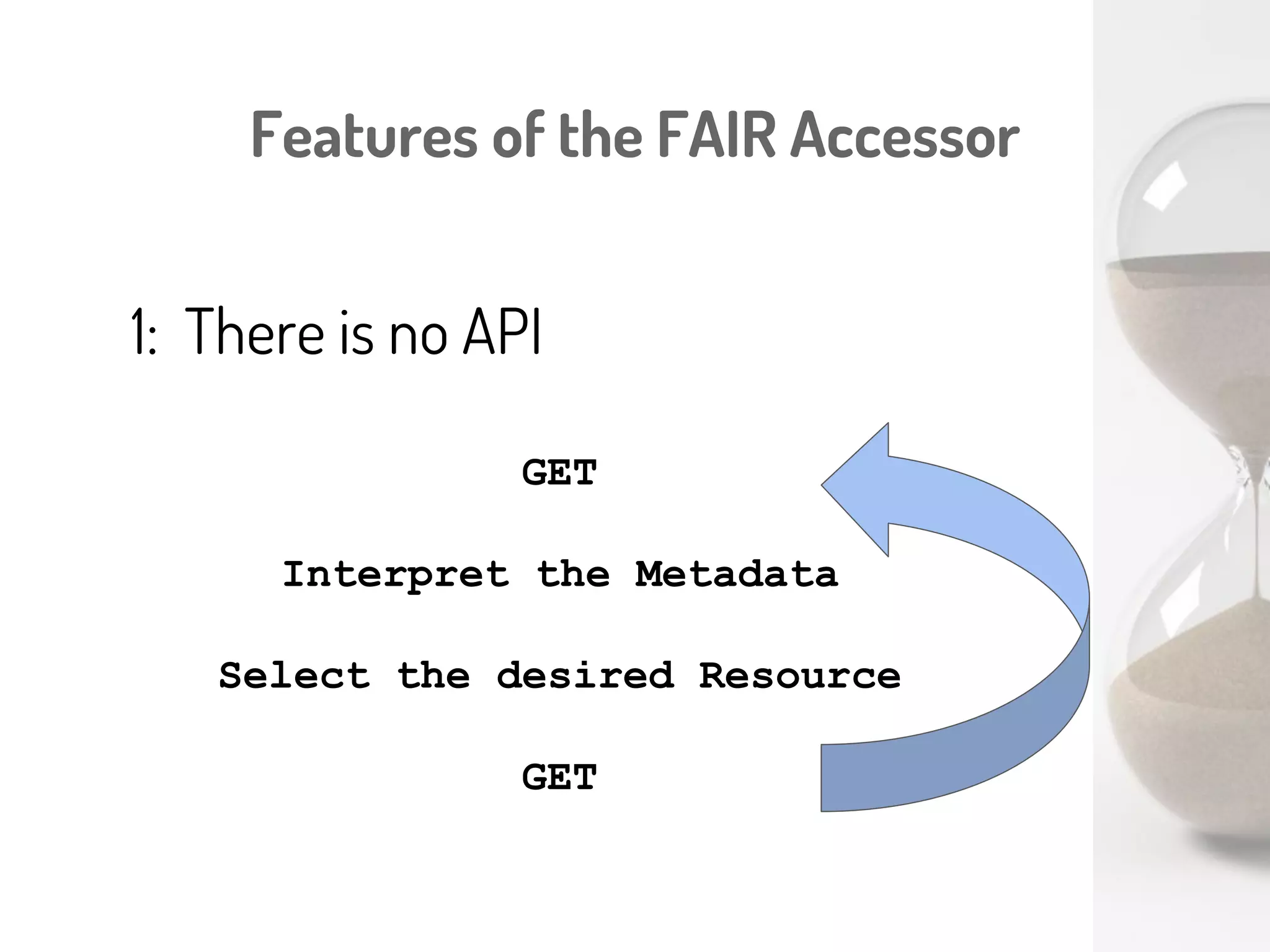
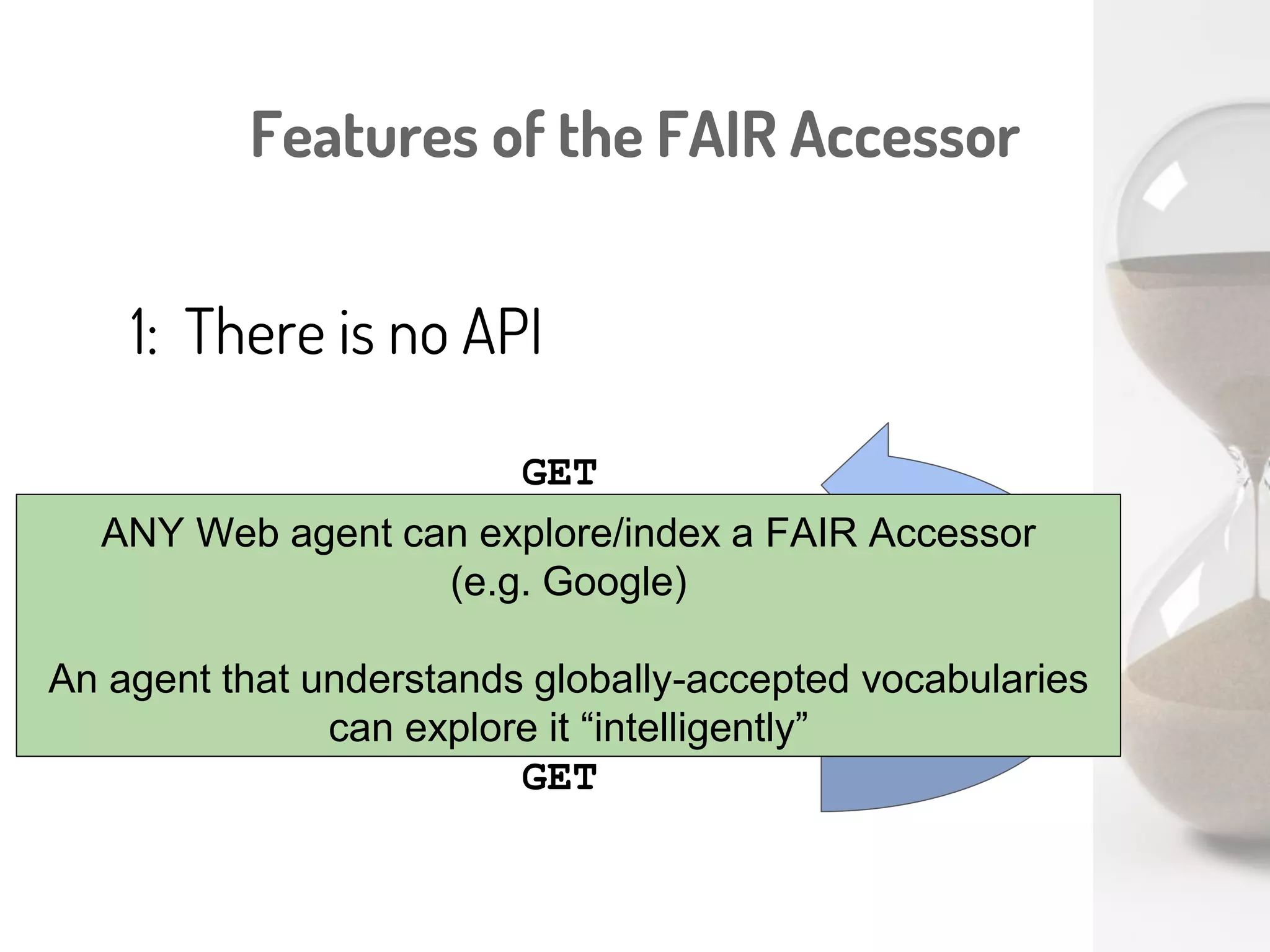
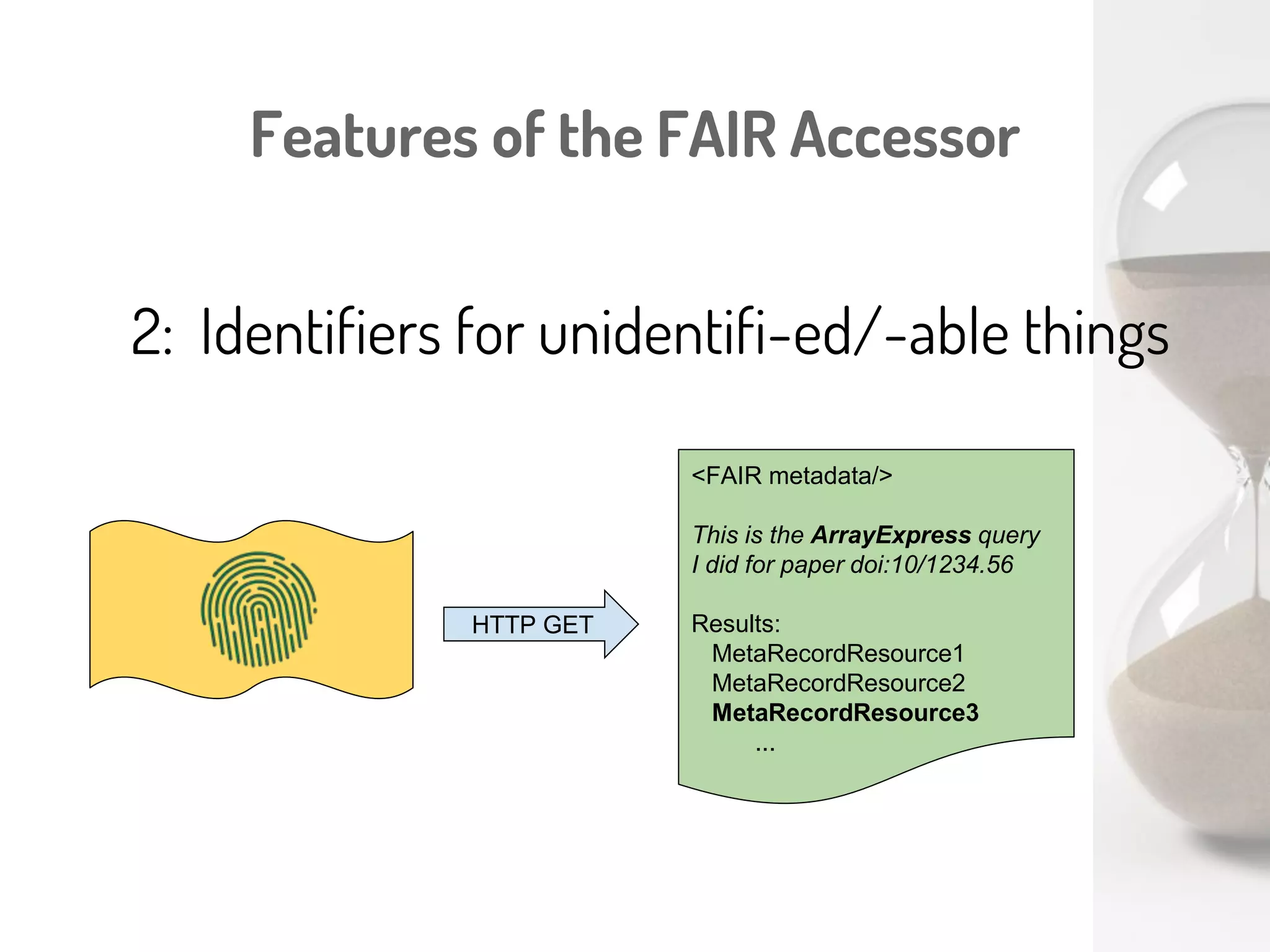
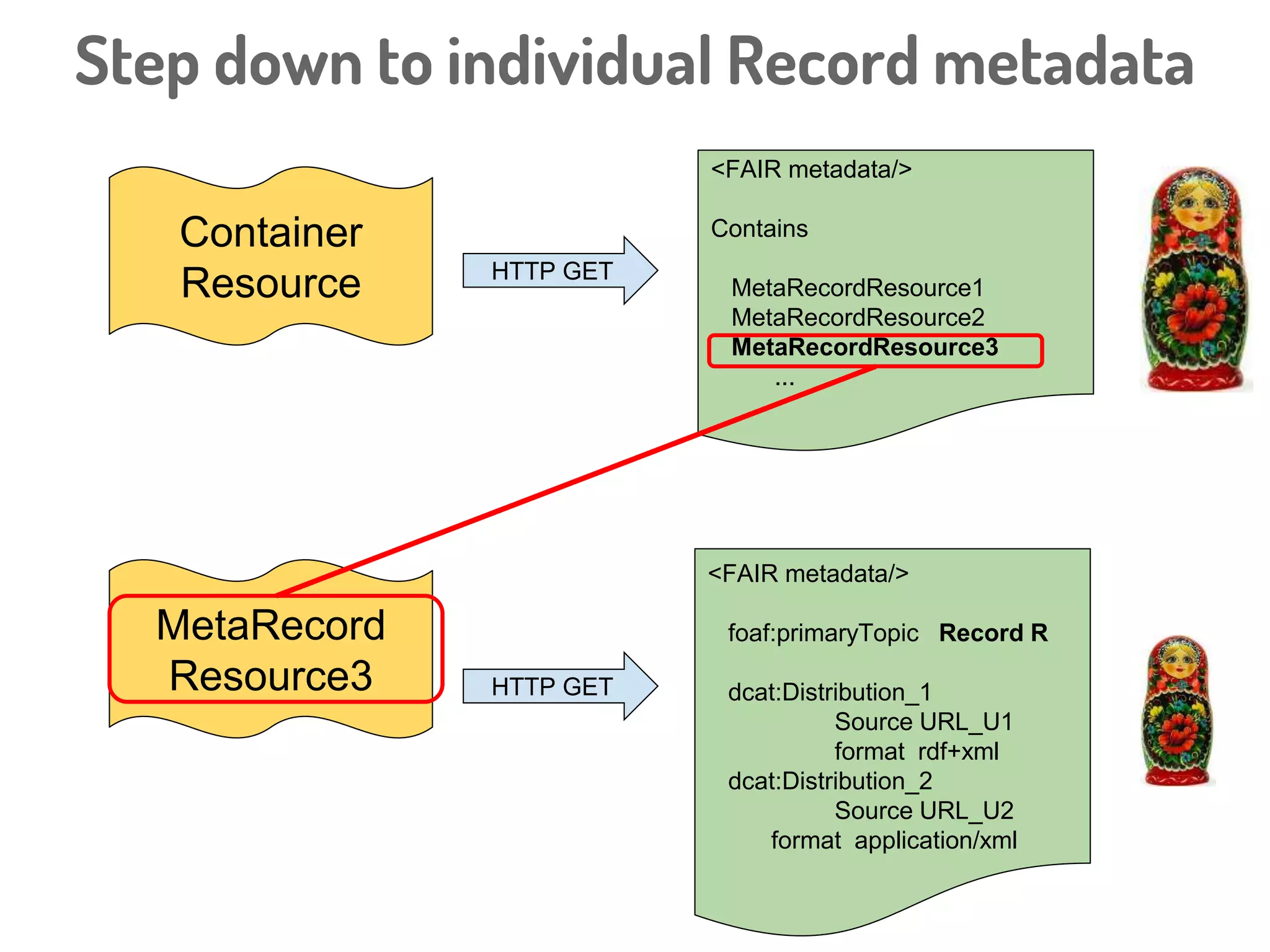
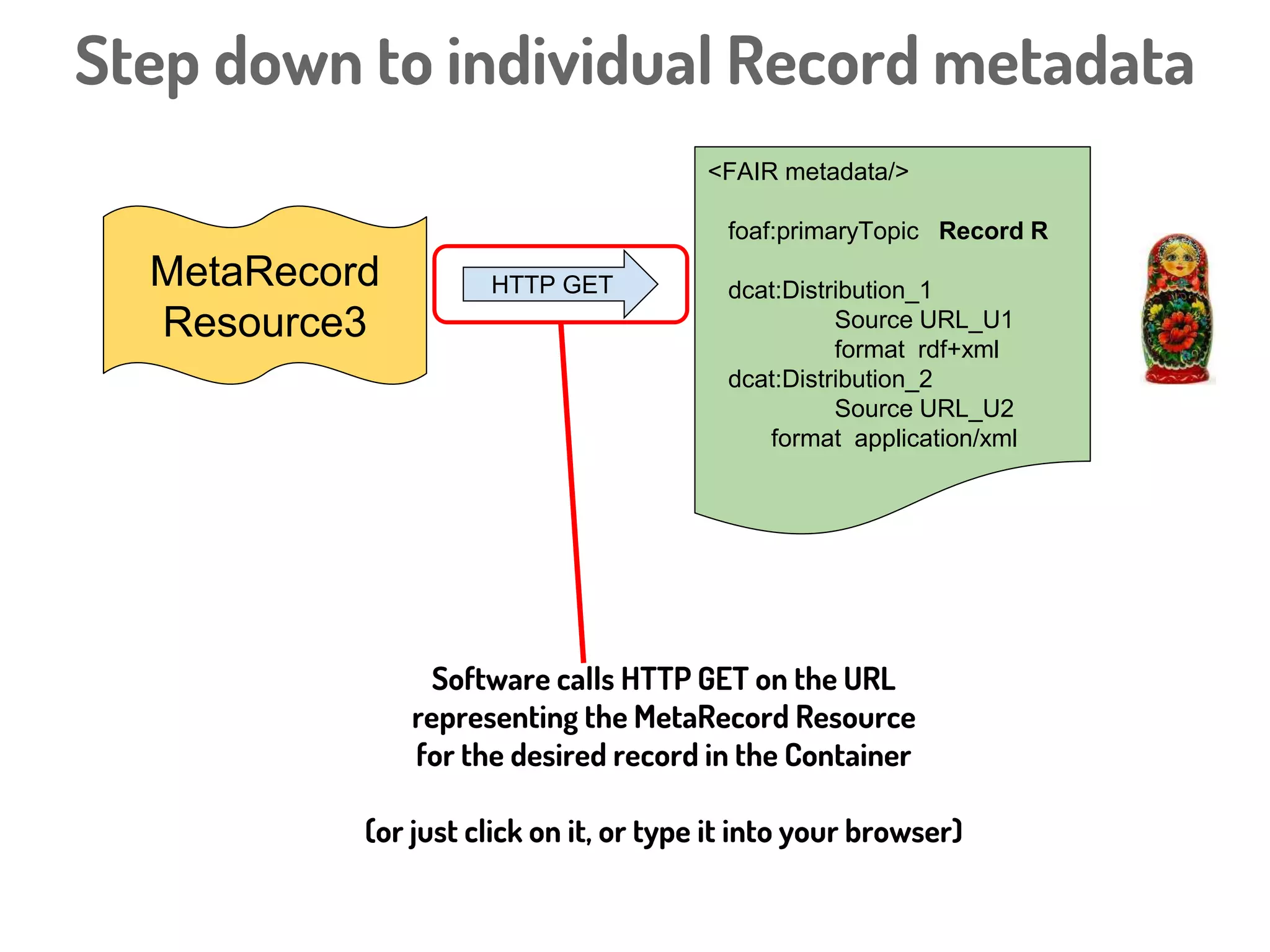
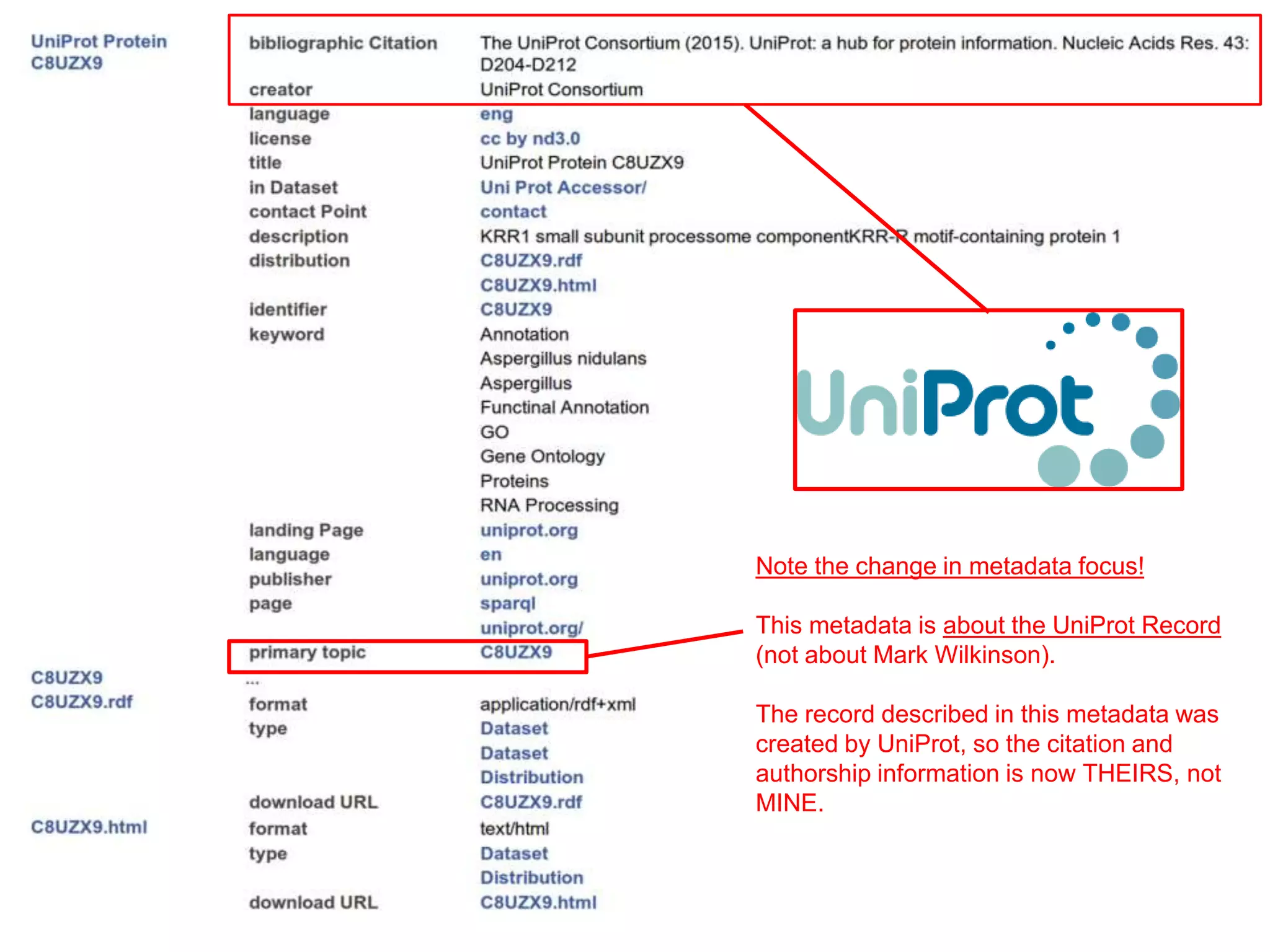
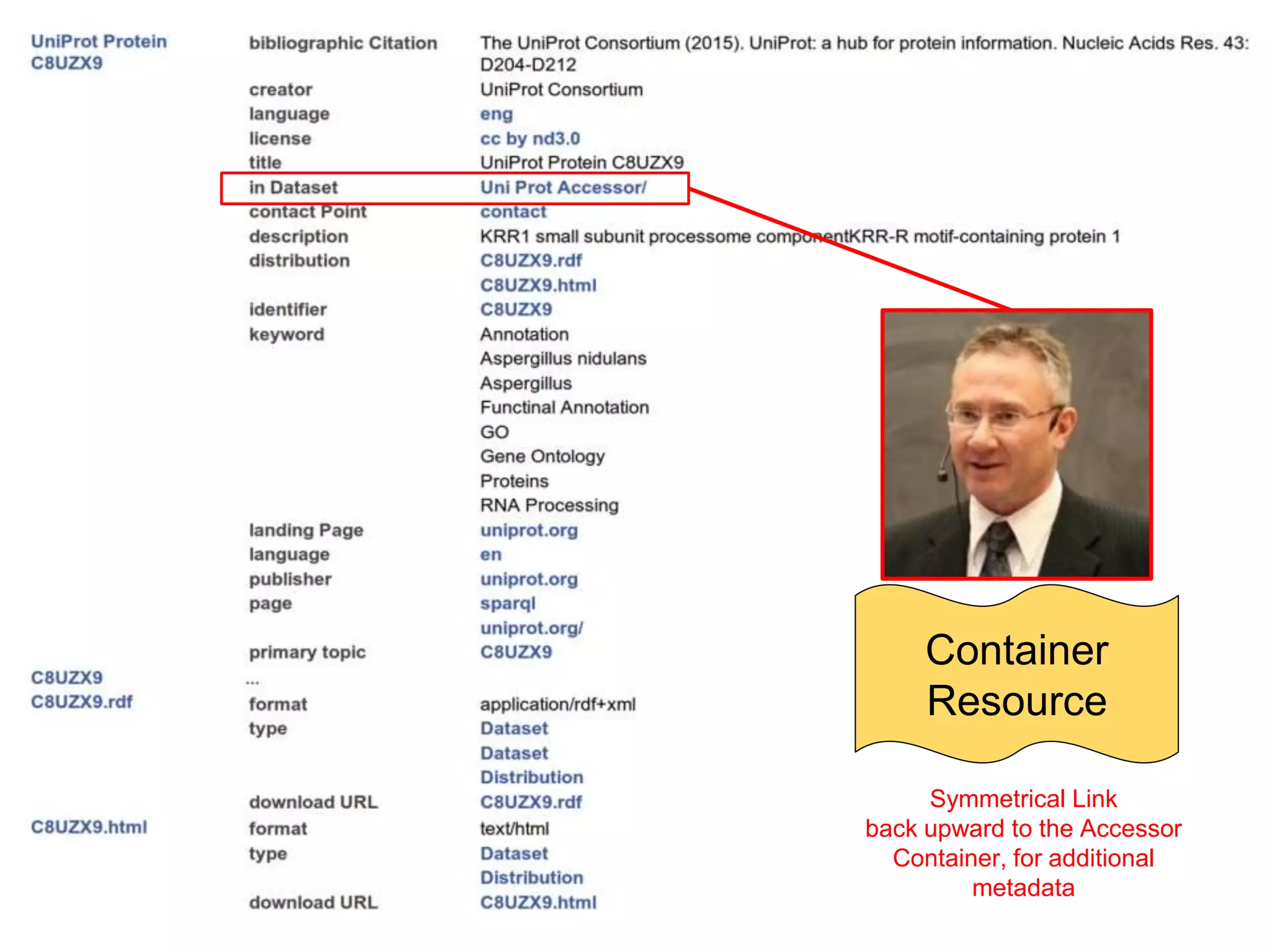
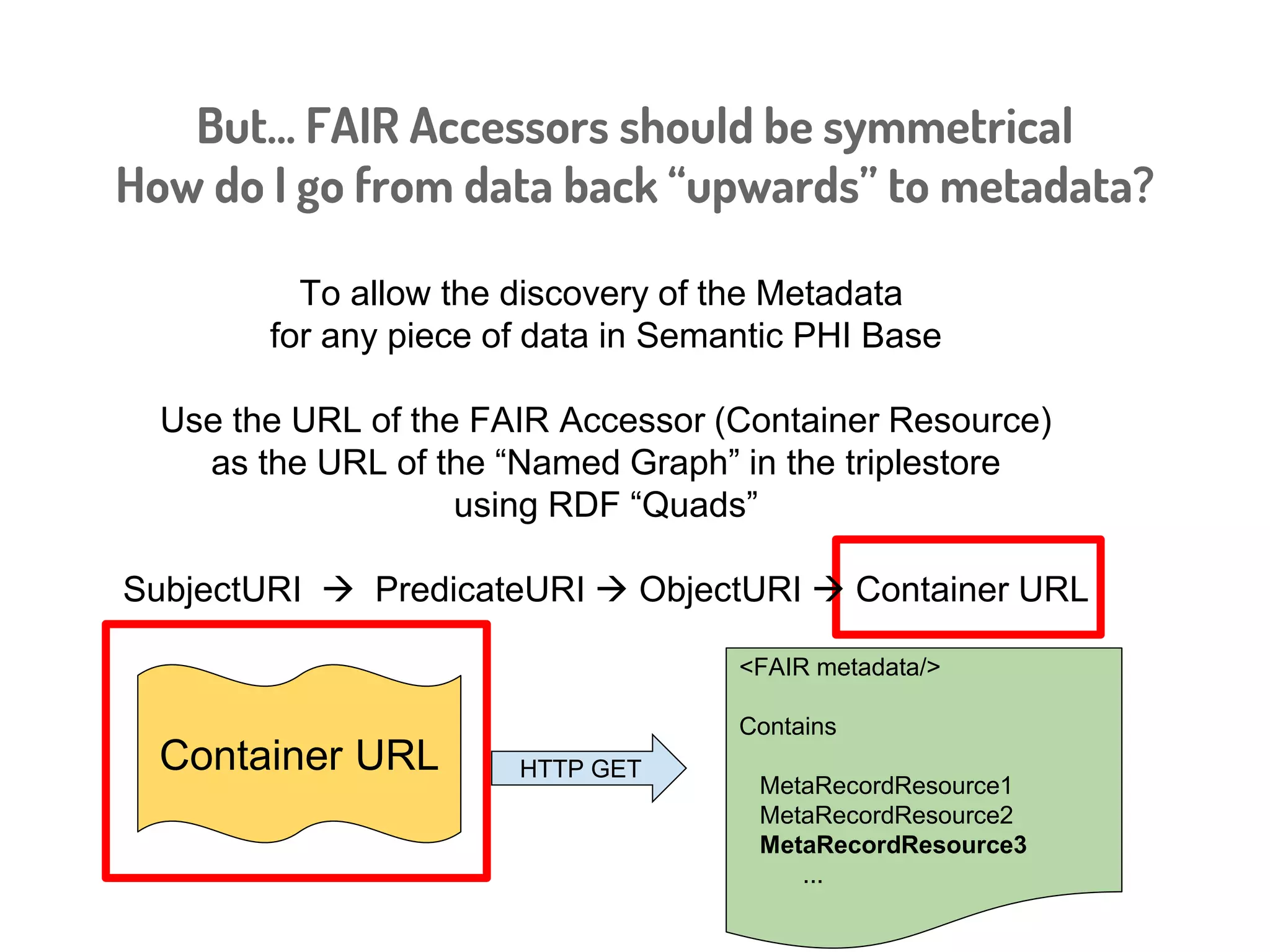
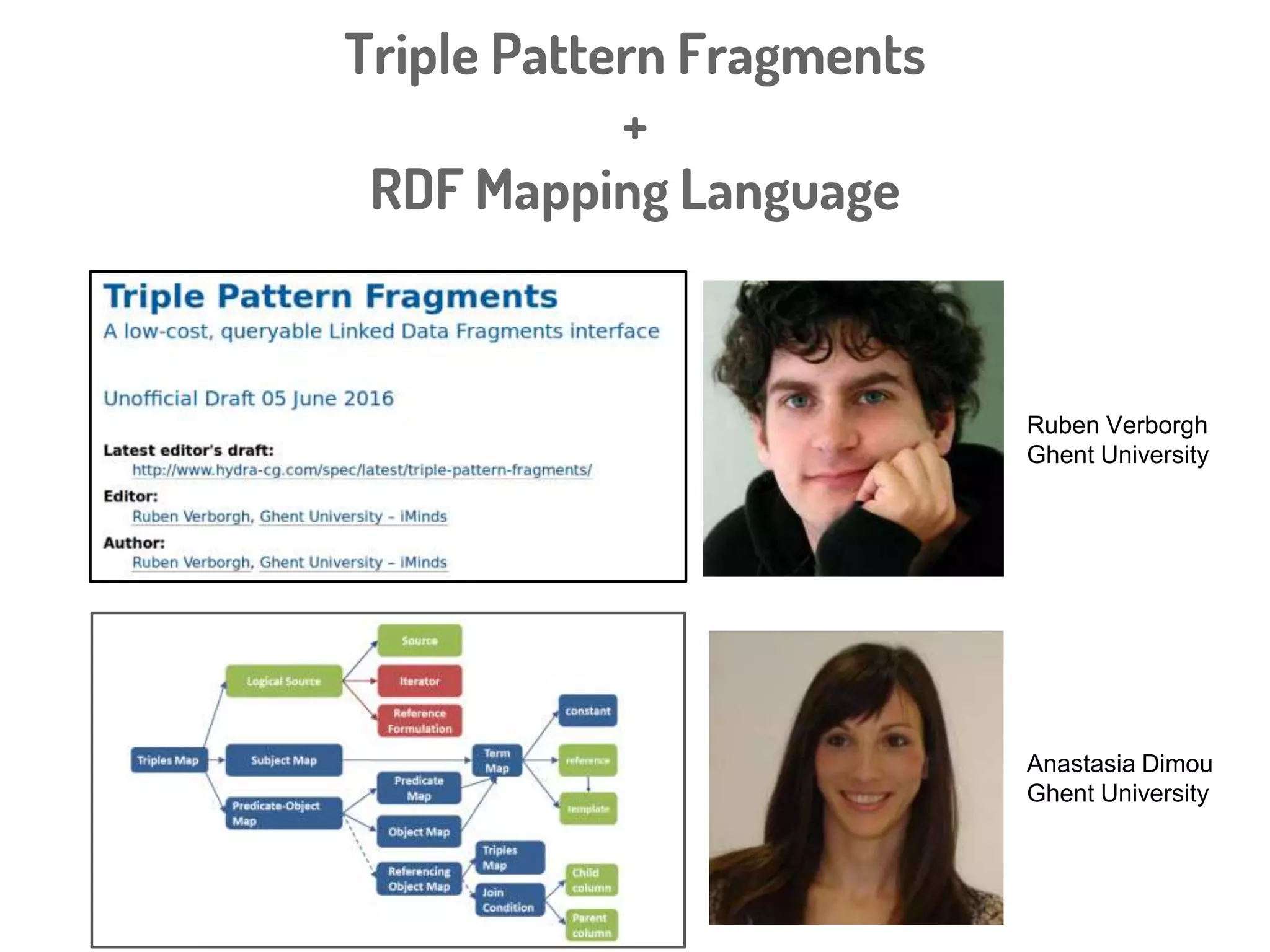
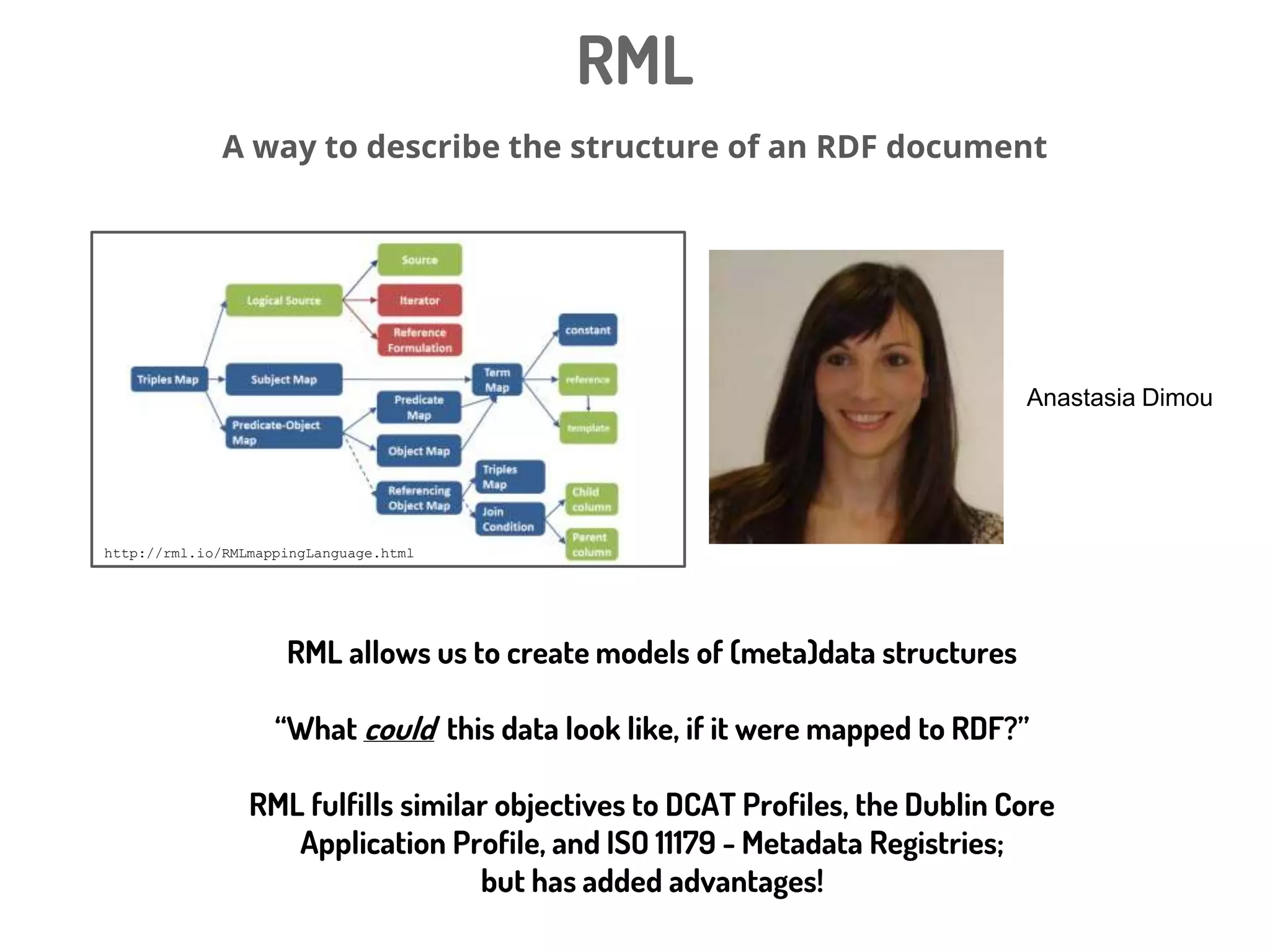
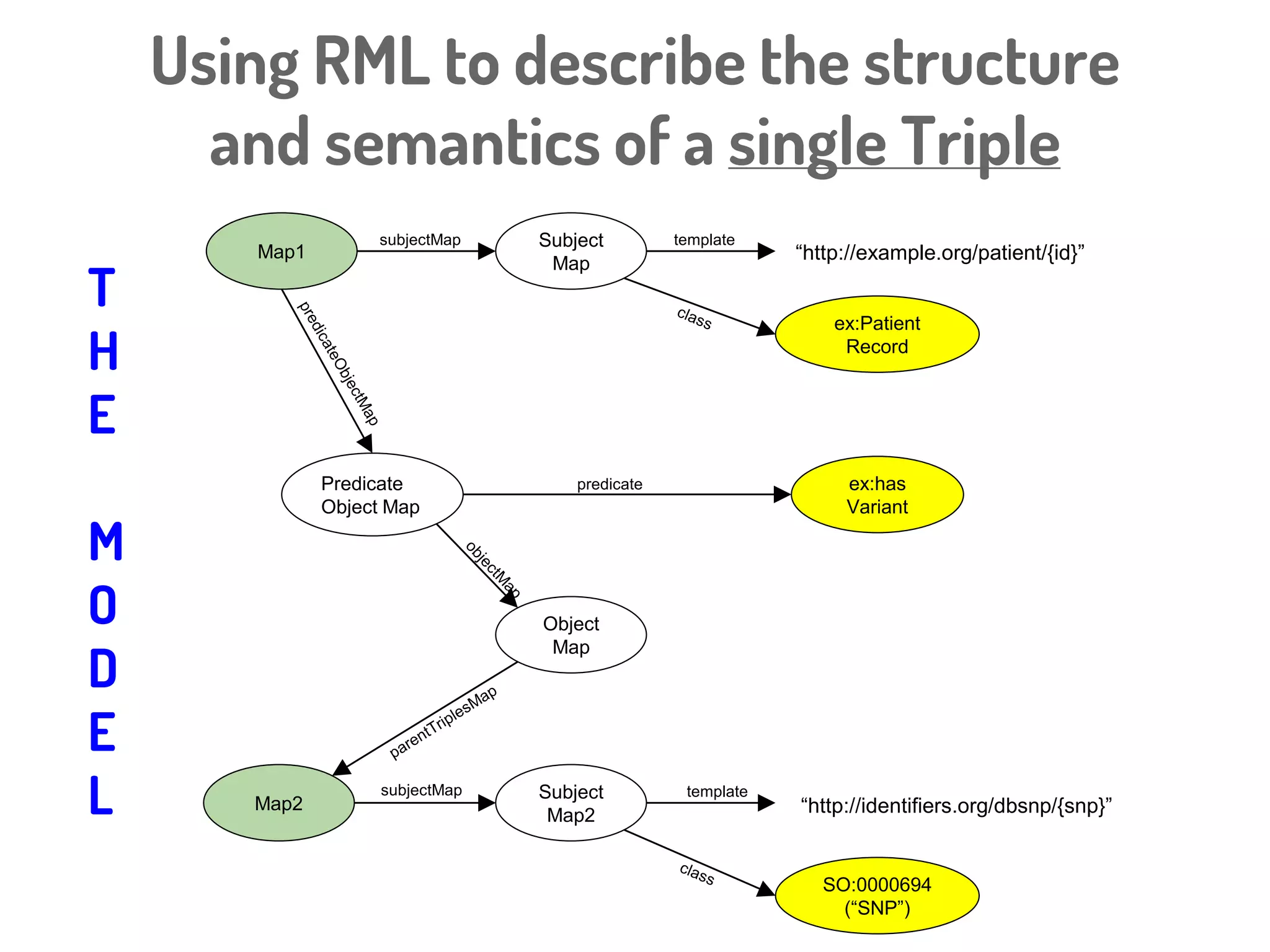
Download to read offline


























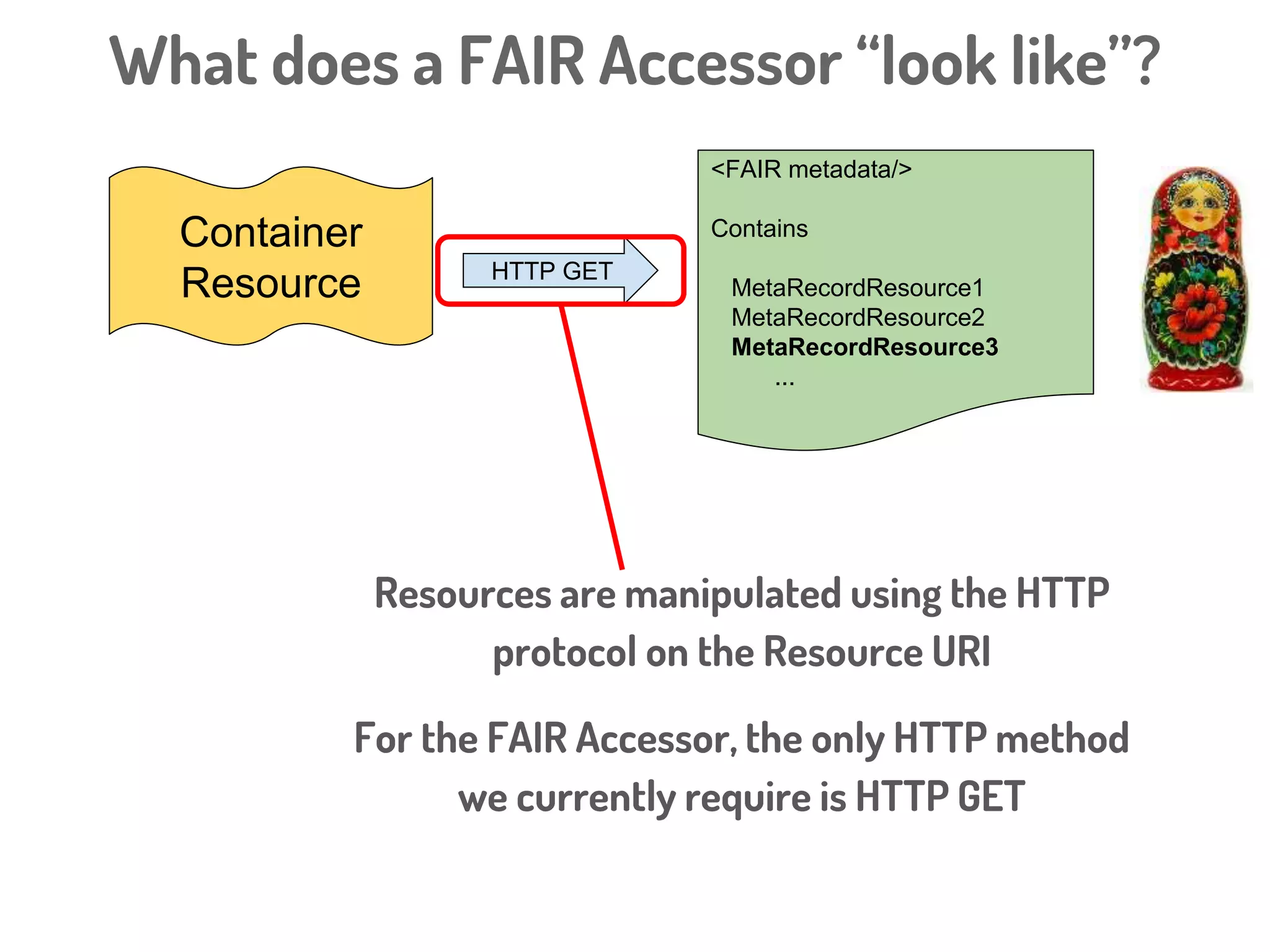



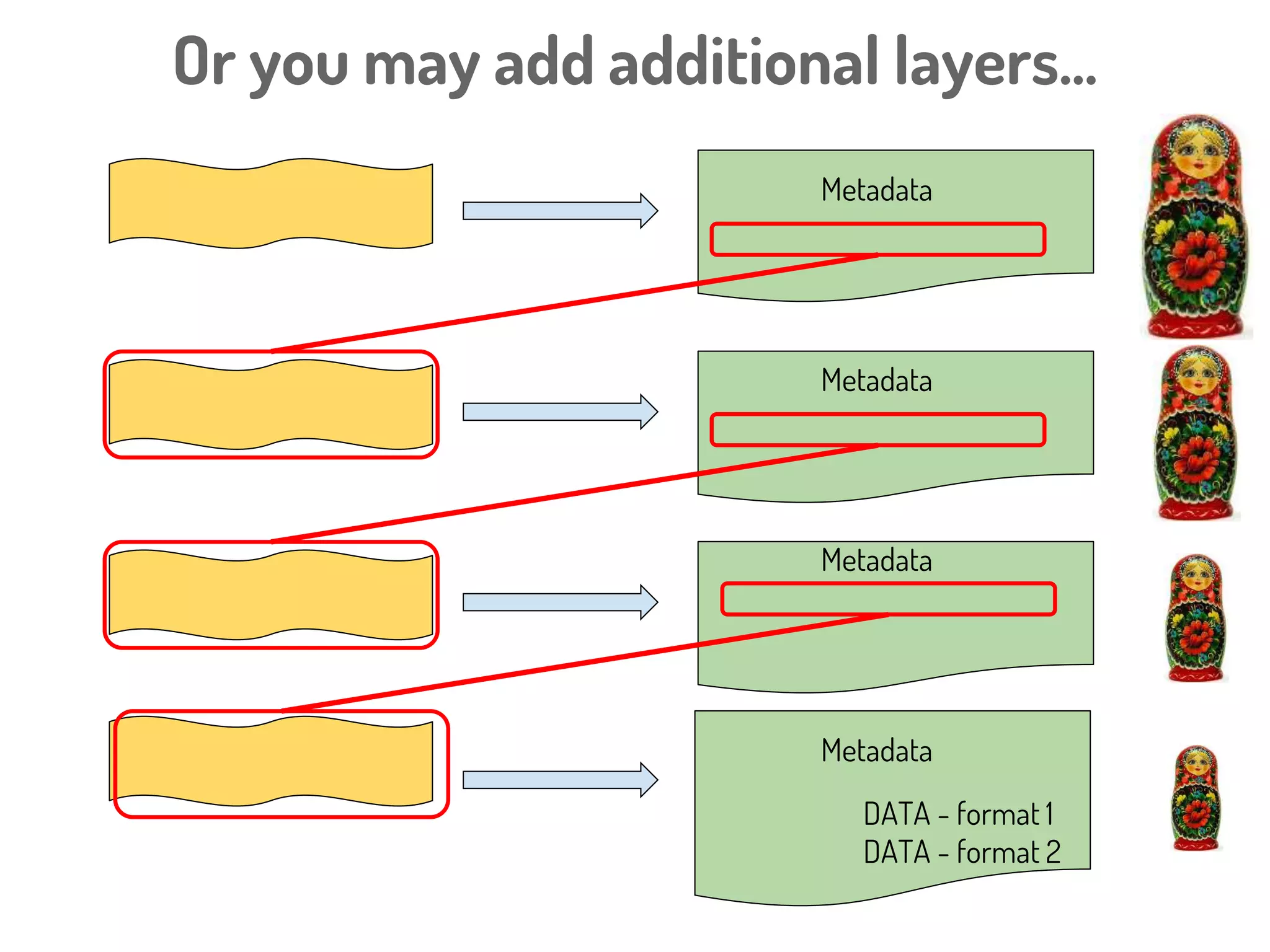
























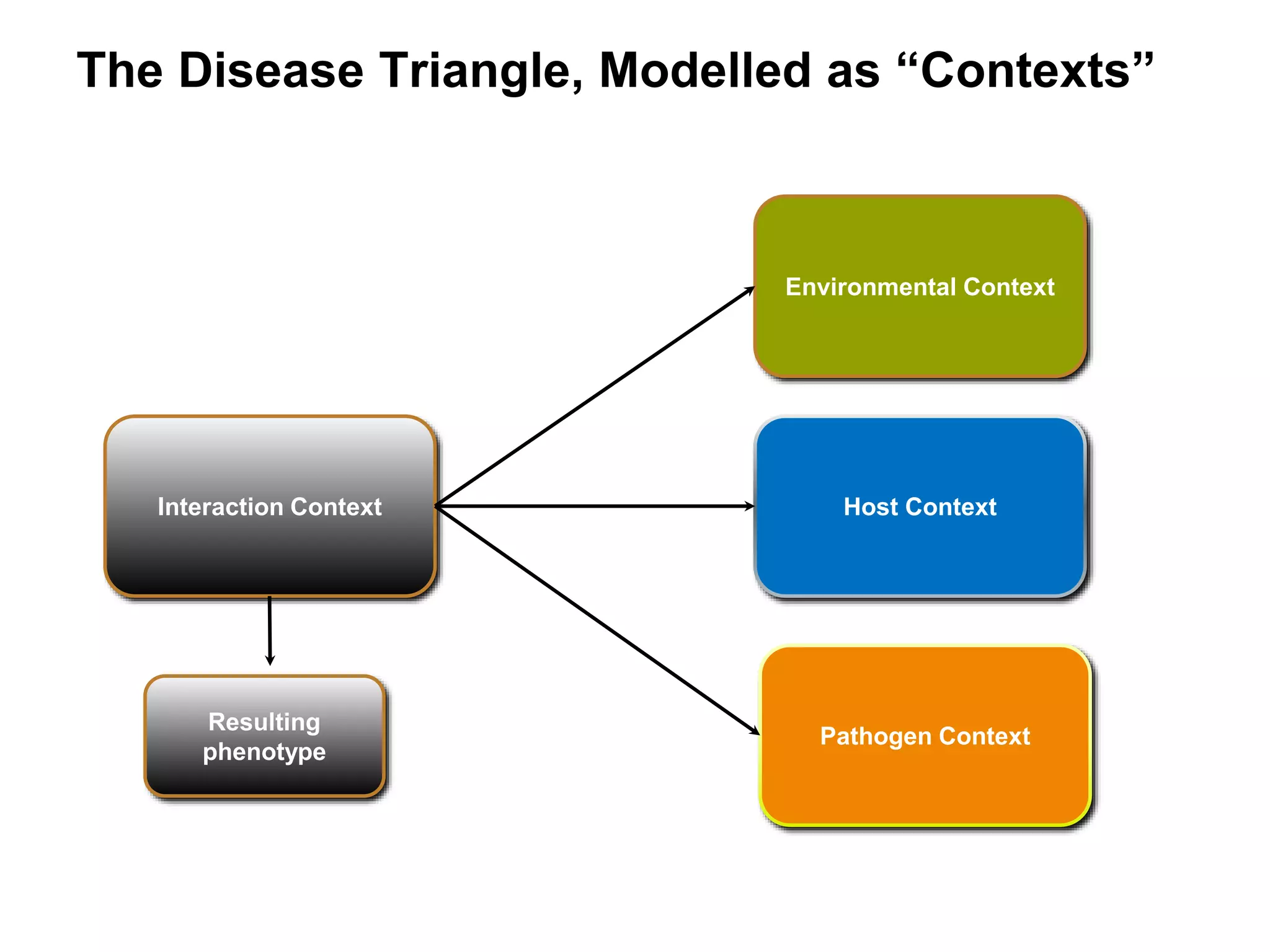







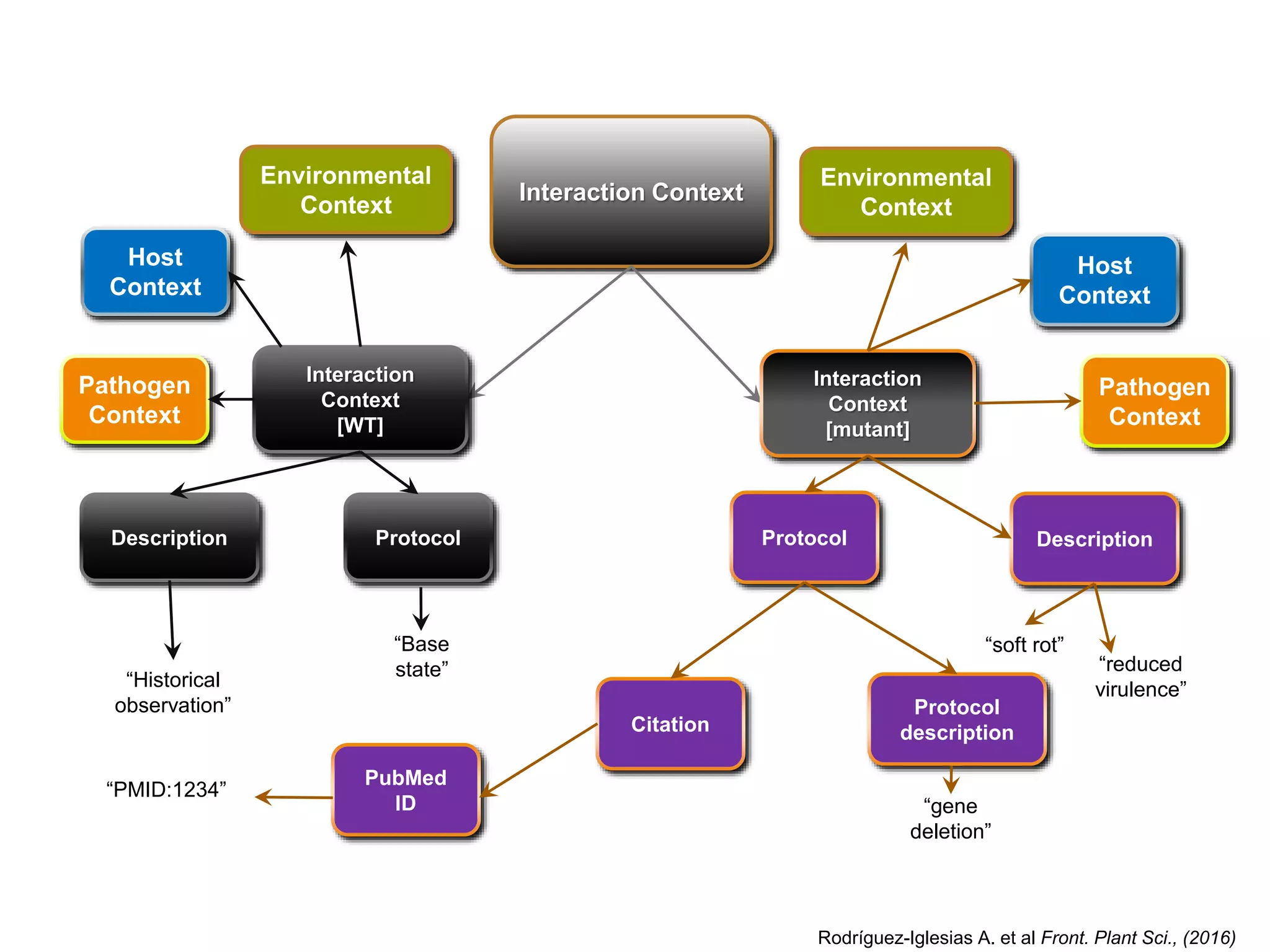
![Interaction Context
Interaction
Context
[WT]
Interaction
Context
[mutant]
Host
Context
Host
Context
Pathogen
Context
Pathogen
Context
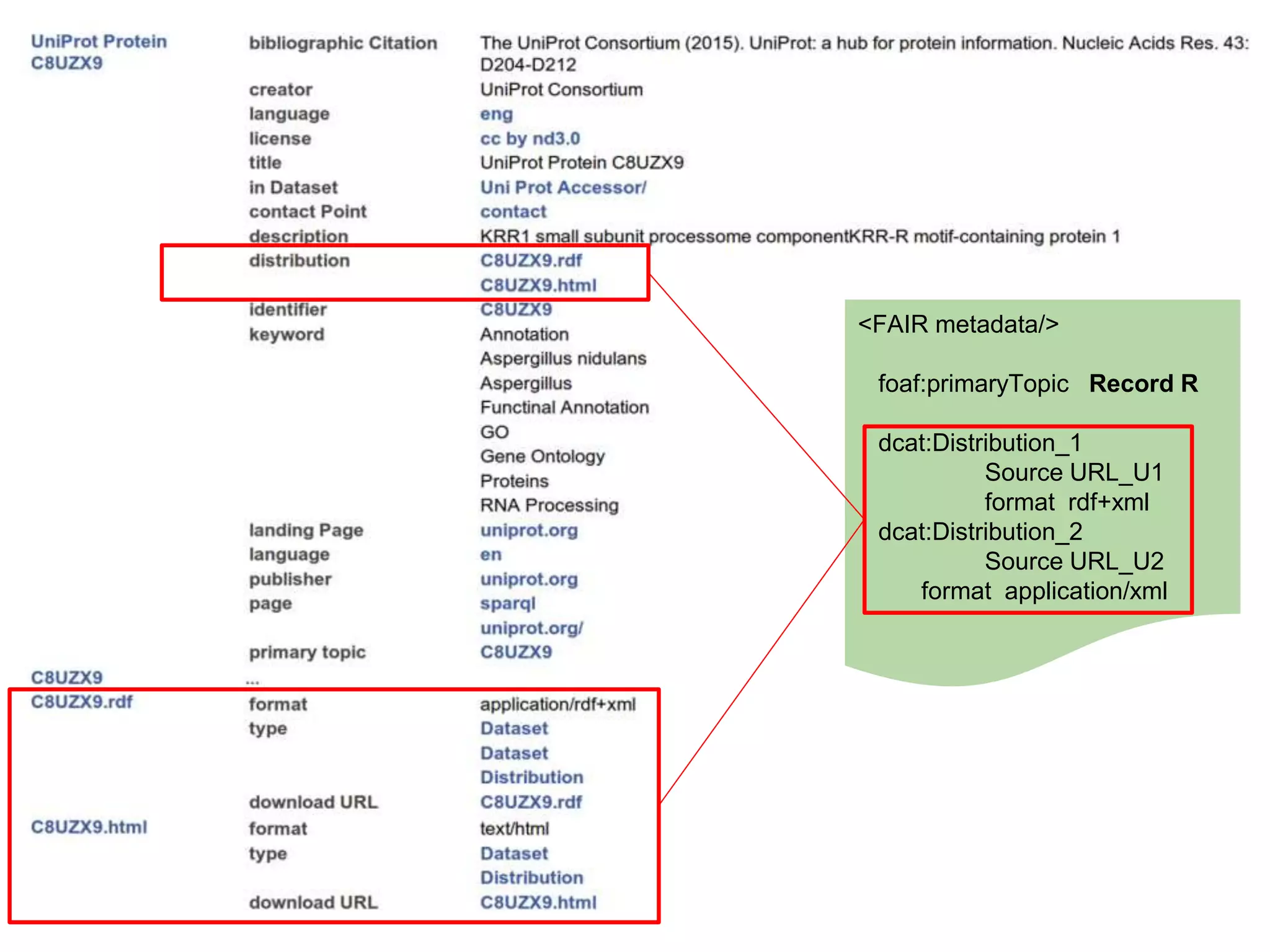
Description DescriptionProtocol Protocol
“Historical
observation”
“Base
state” “reduced
virulence”
“soft rot”
Protocol
descriptionCitation
PubMed
ID
“PMID:1234”
“gene
deletion”
Environmental
Context
Environmental
Context
Rodríguez-Iglesias A. et al Front. Plant Sci., (2016)](https://image.slidesharecdn.com/ibcfairprototypeimplementationslideshow-170118085918/75/IBC-FAIR-Data-Prototype-Implementation-slideshow-108-2048.jpg)
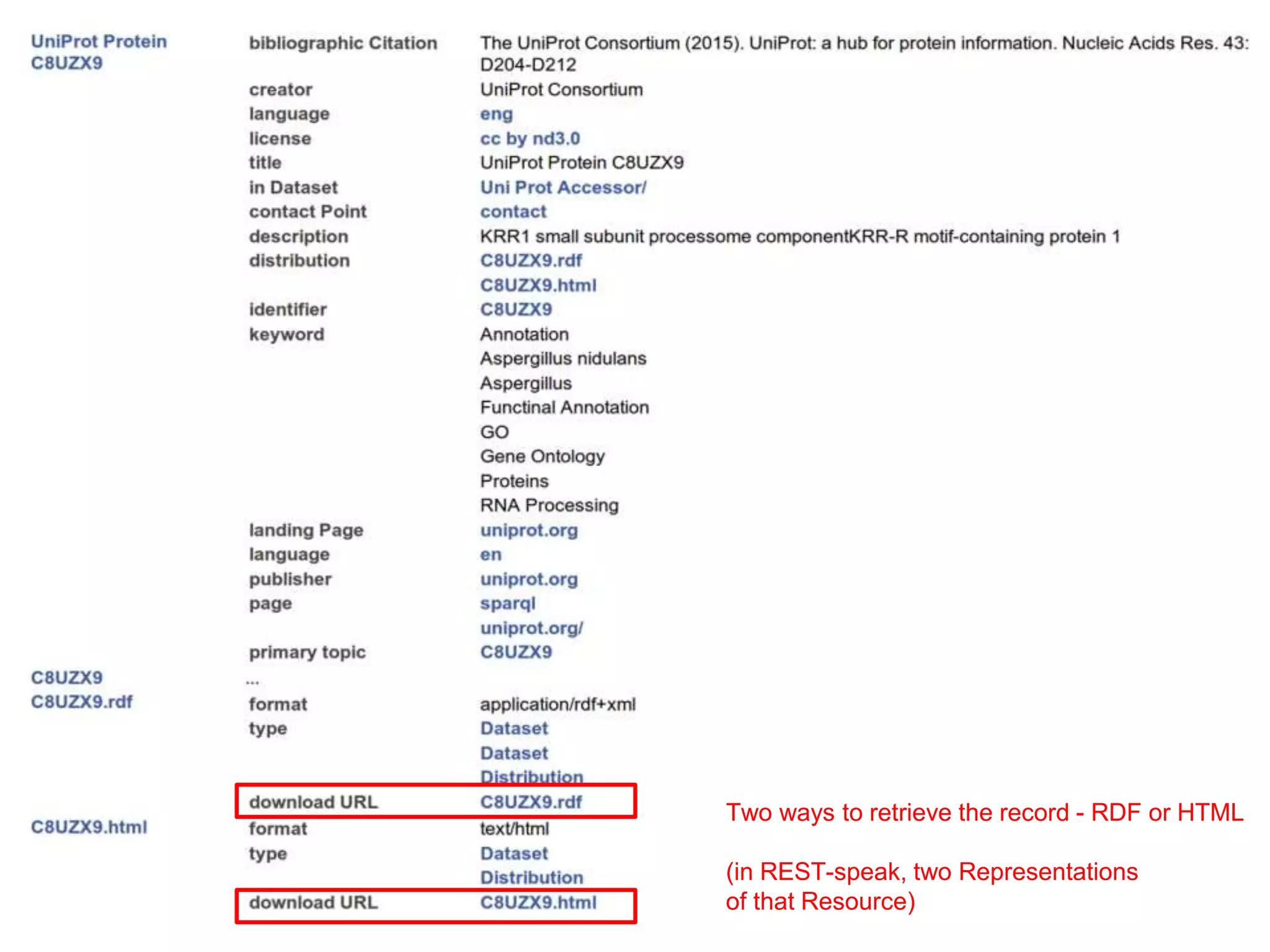
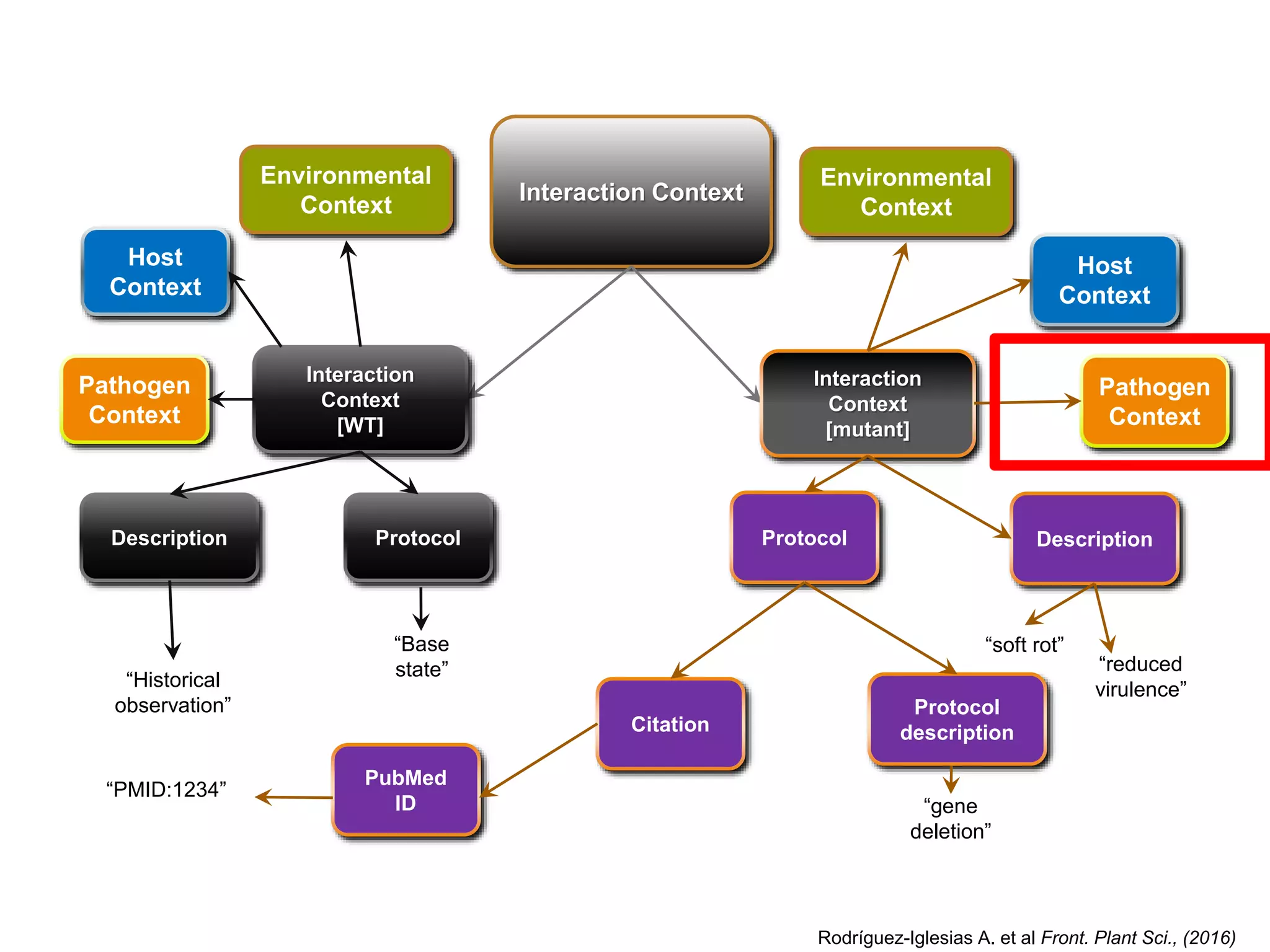
![Interaction Context
Interaction
Context
[WT]
Interaction
Context
[mutant]
Host
Context
Host
Context
Pathogen
Context
Pathogen
Context
Description DescriptionProtocol Protocol
“Historical
observation”
“Base
state” “reduced
virulence”
“soft rot”
Protocol
descriptionCitation
PubMed
ID
“PMID:1234”
“gene
deletion”
Environmental
Context
Environmental
Context
Rodríguez-Iglesias A. et al Front. Plant Sci., (2016)](https://image.slidesharecdn.com/ibcfairprototypeimplementationslideshow-170118085918/75/IBC-FAIR-Data-Prototype-Implementation-slideshow-109-2048.jpg)





















































































































































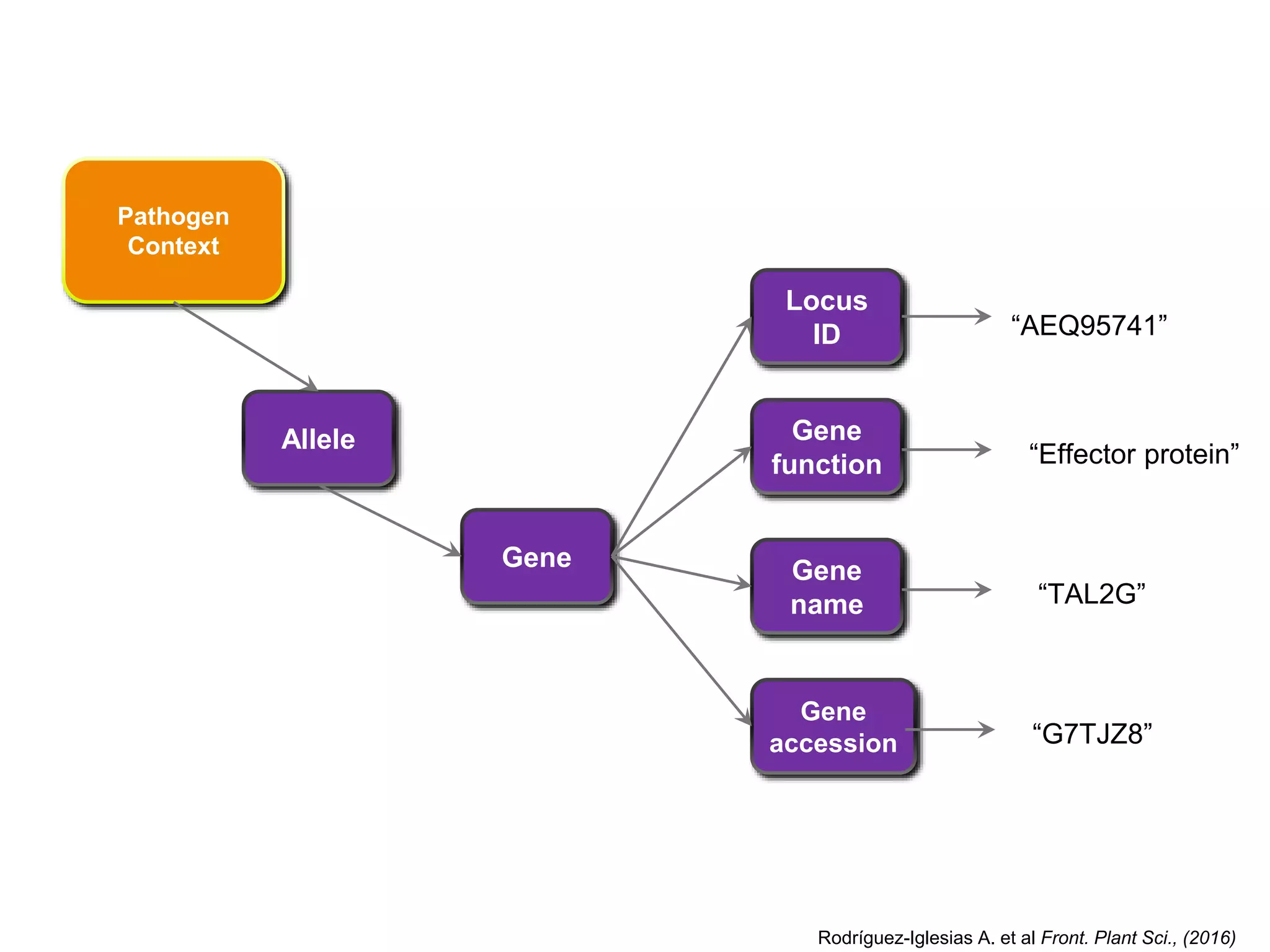
![Interaction Context
Interaction
Context
[WT]
Interaction
Context
[mutant]
Host
Context
Host
Context
Pathogen
Context
Pathogen
Context
Description DescriptionProtocol Protocol
“Historical
observation”
“Base
state” “reduced
virulence”
“soft rot”
Protocol
descriptionCitation
PubMed
ID
“PMID:1234”
“gene
deletion”
Environmental
Context
Environmental
Context
Rodríguez-Iglesias A. et al Front. Plant Sci., (2016)](https://crownmelresort.com/image.slidesharecdn.com/ibcfairprototypeimplementationslideshow-170118085918/75/IBC-FAIR-Data-Prototype-Implementation-slideshow-108-2048.jpg)
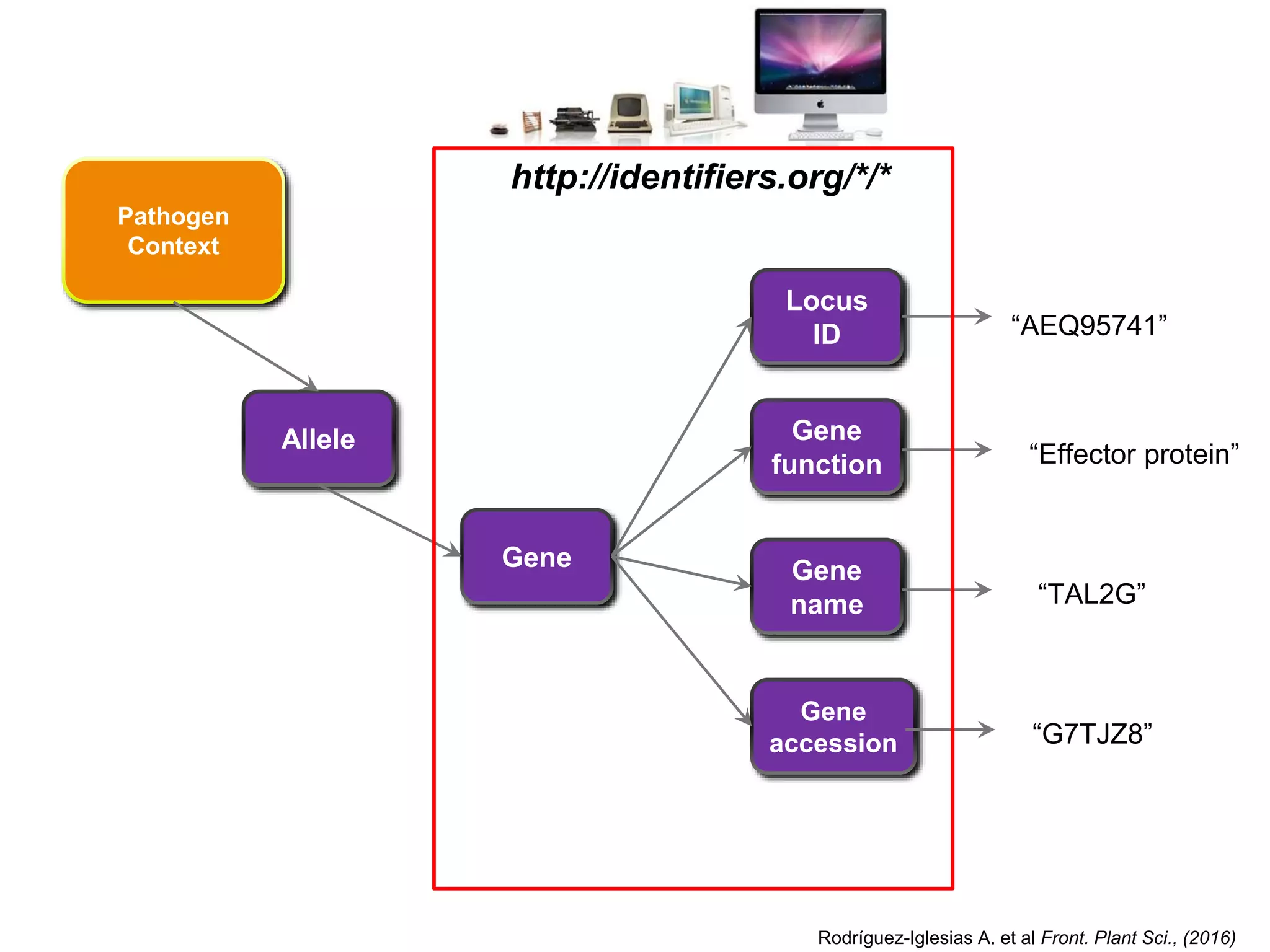
![Interaction Context
Interaction
Context
[WT]
Interaction
Context
[mutant]
Host
Context
Host
Context
Pathogen
Context
Pathogen
Context
Description DescriptionProtocol Protocol
“Historical
observation”
“Base
state” “reduced
virulence”
“soft rot”
Protocol
descriptionCitation
PubMed
ID
“PMID:1234”
“gene
deletion”
Environmental
Context
Environmental
Context
Rodríguez-Iglesias A. et al Front. Plant Sci., (2016)](https://crownmelresort.com/image.slidesharecdn.com/ibcfairprototypeimplementationslideshow-170118085918/75/IBC-FAIR-Data-Prototype-Implementation-slideshow-109-2048.jpg)



























































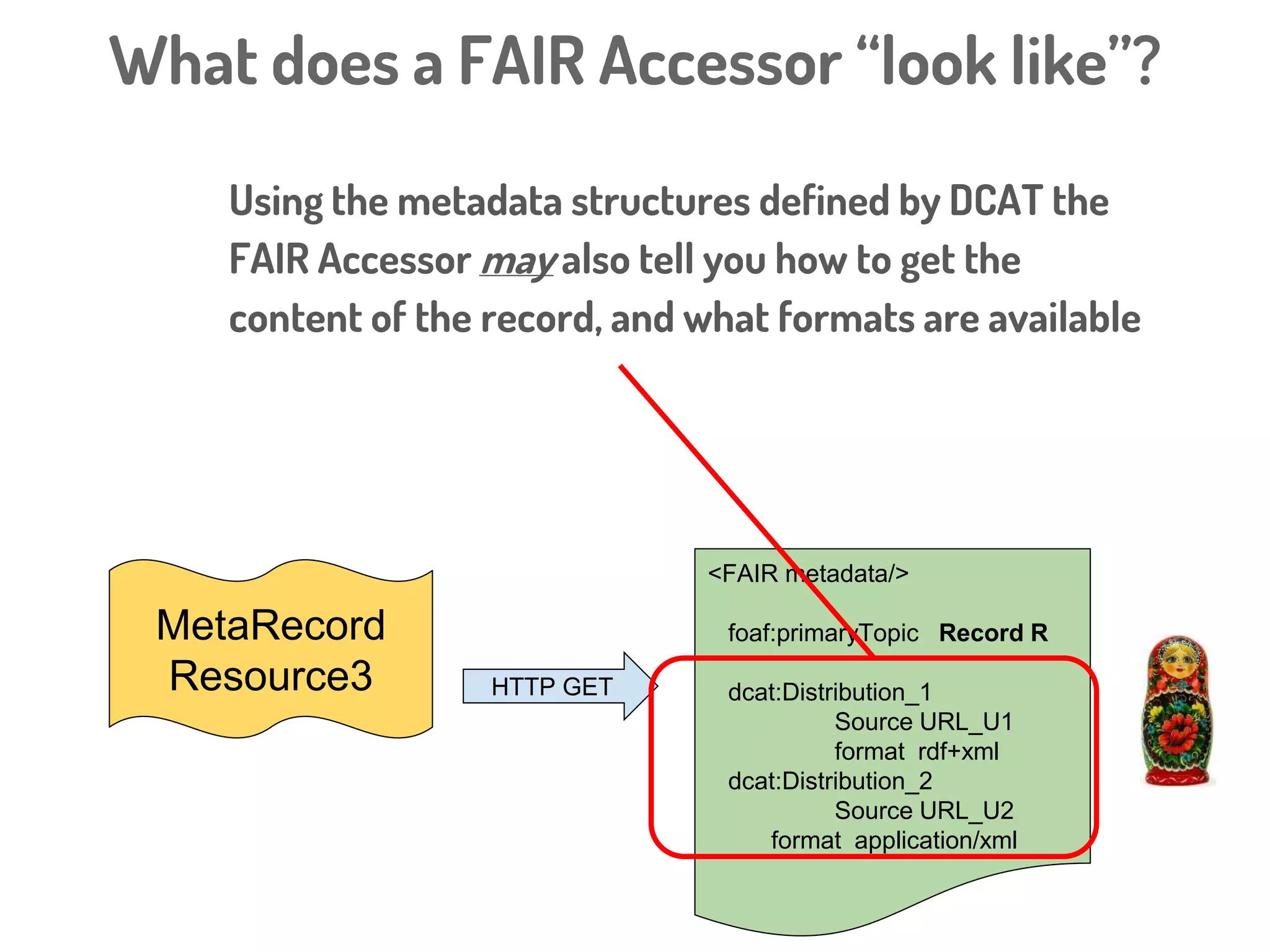
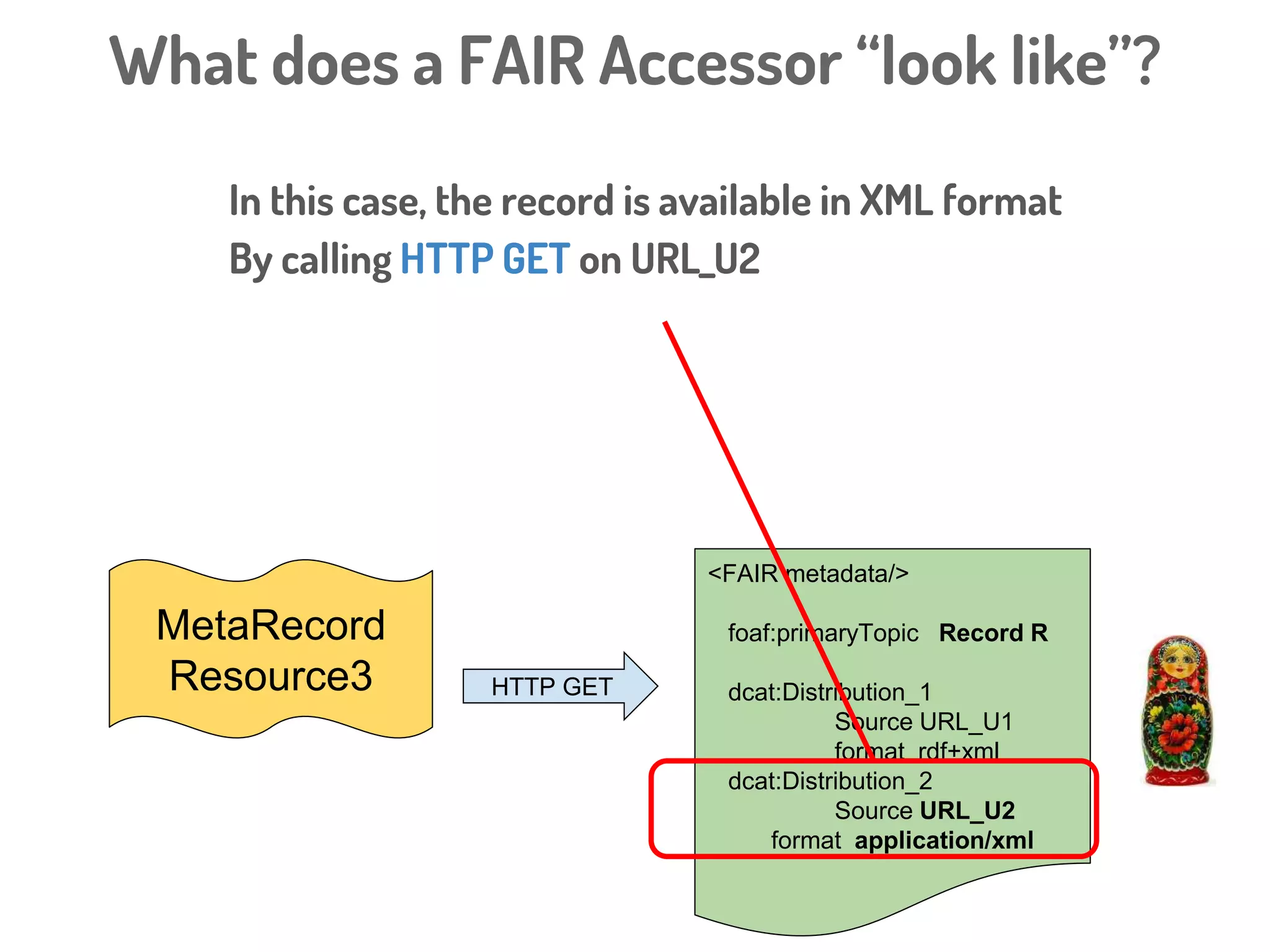
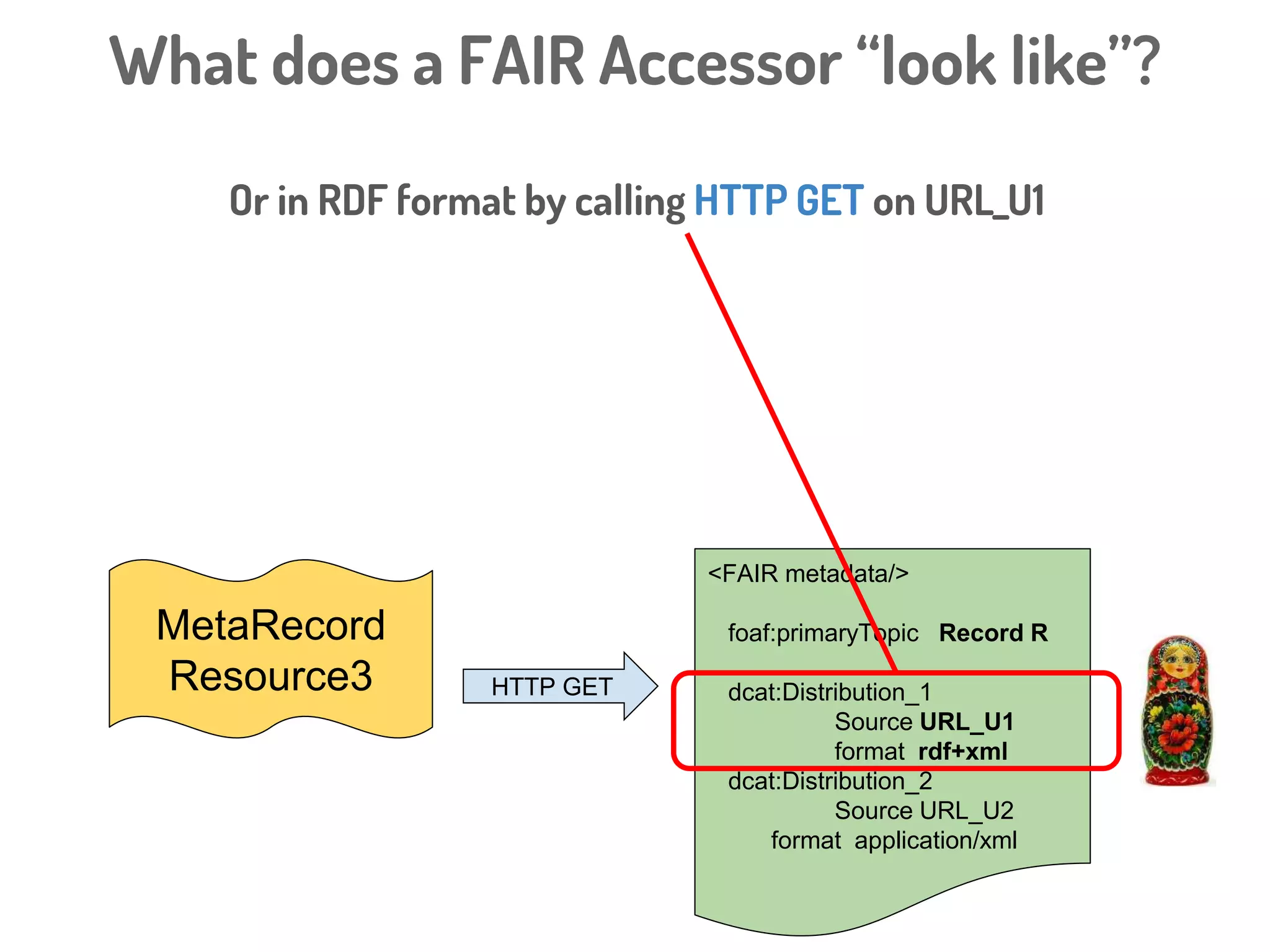
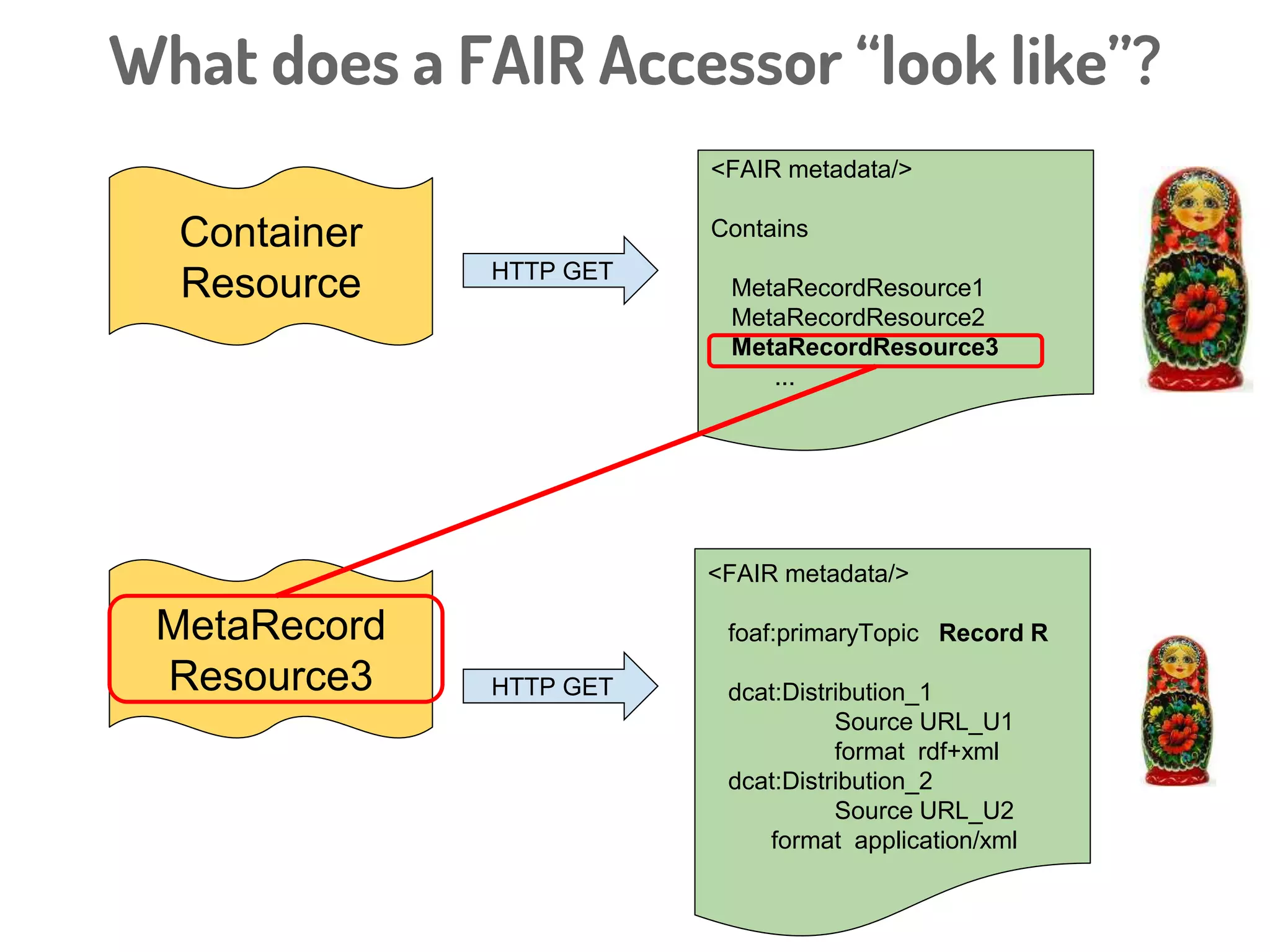
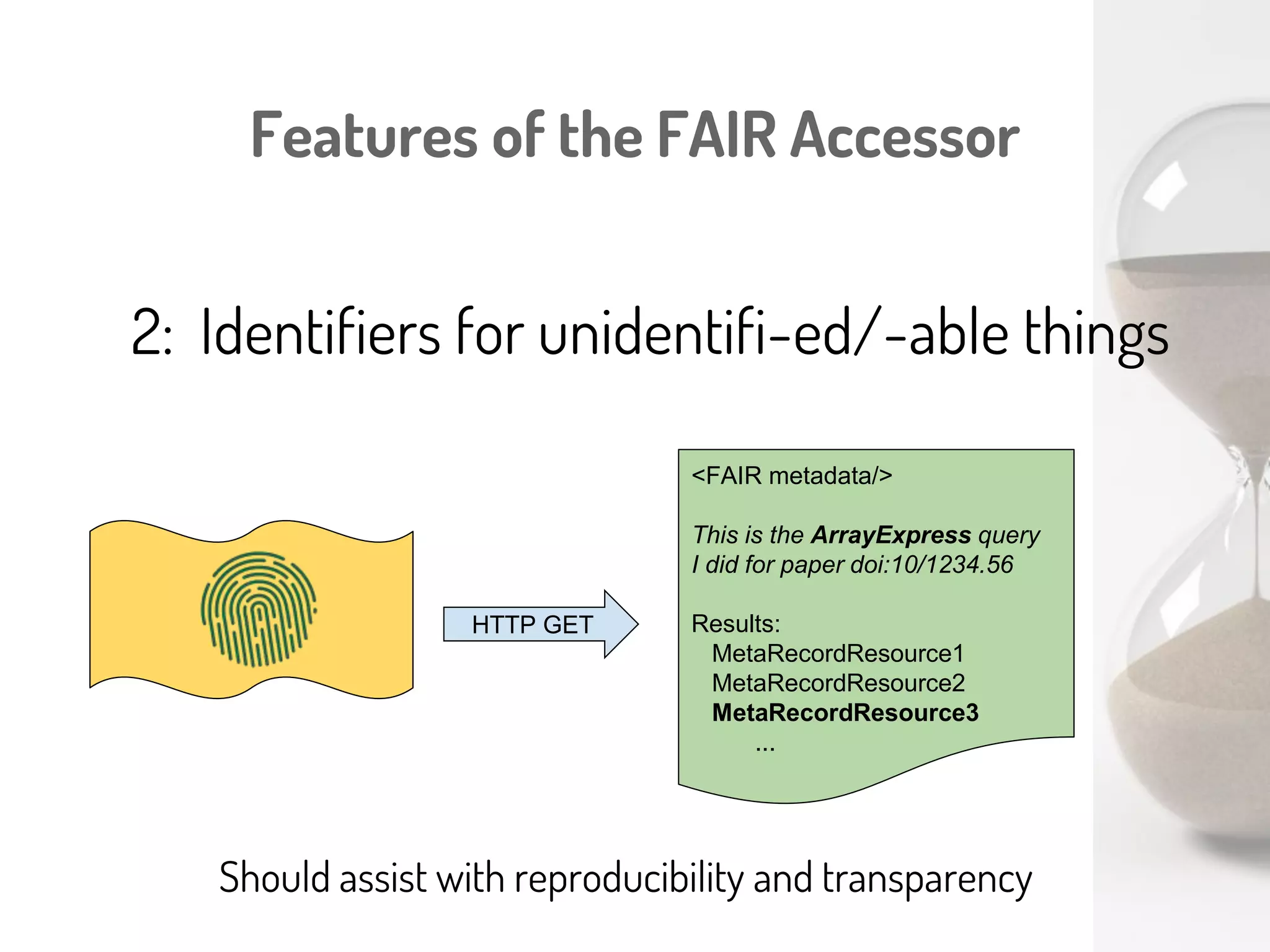
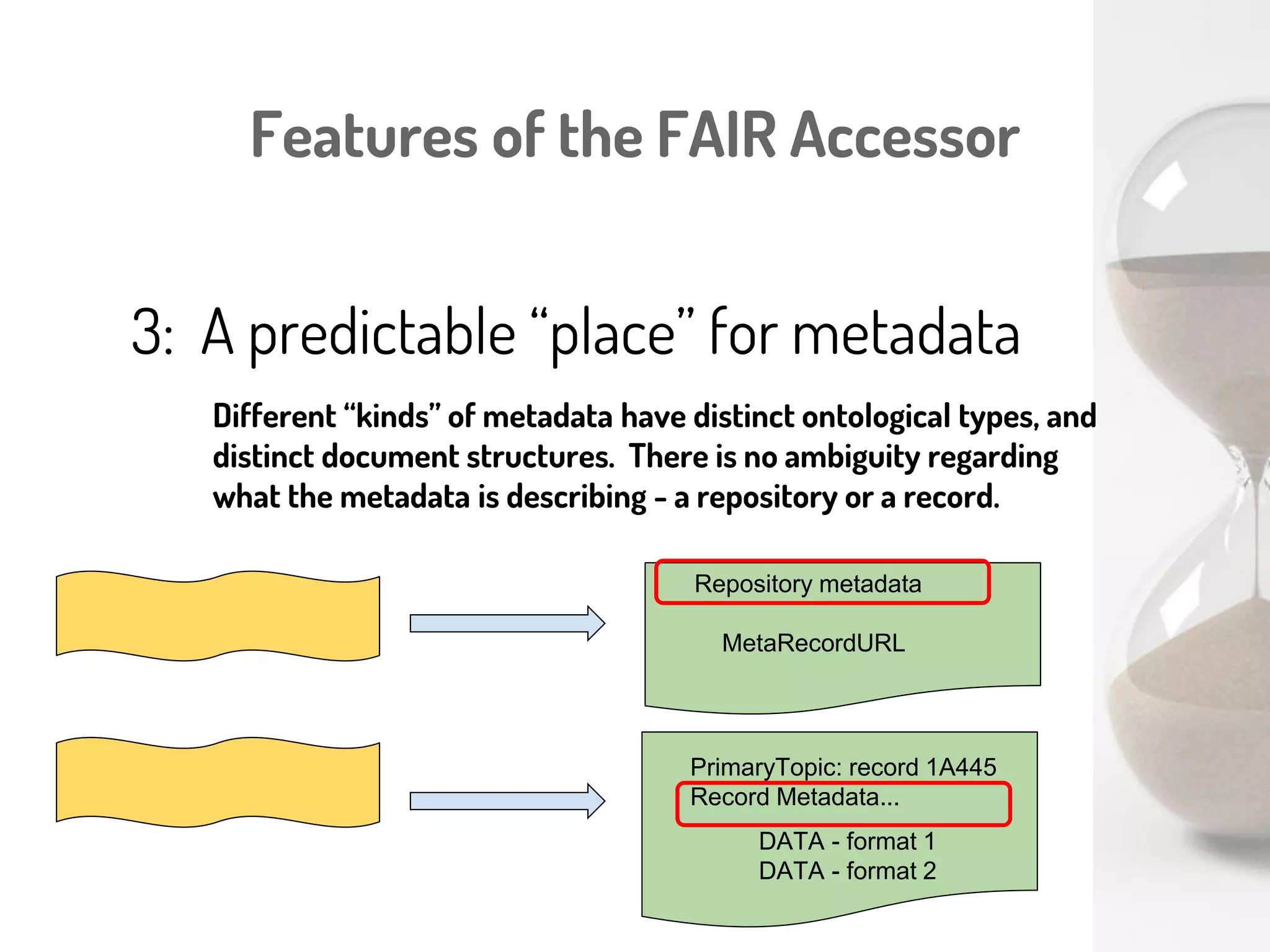
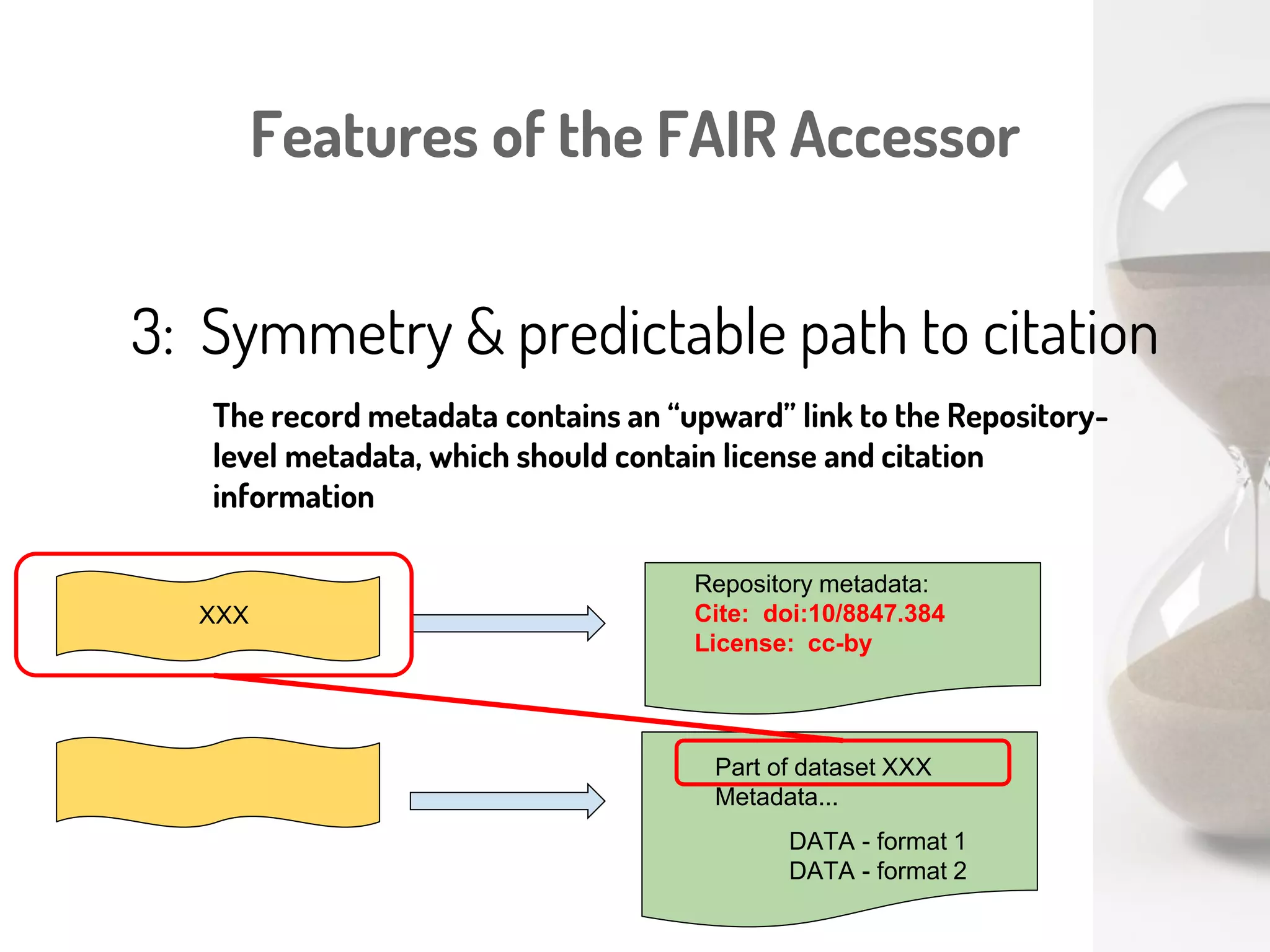
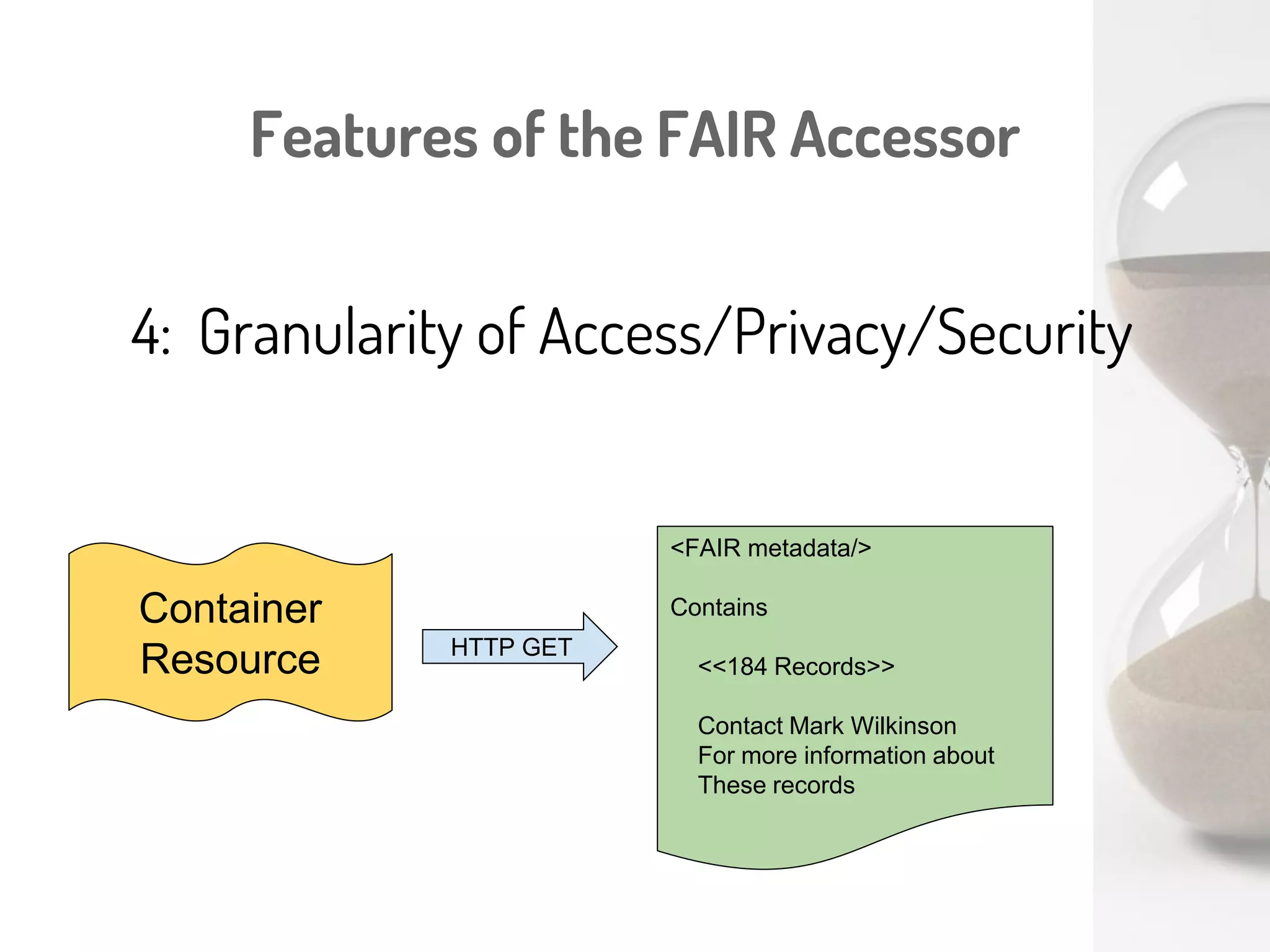
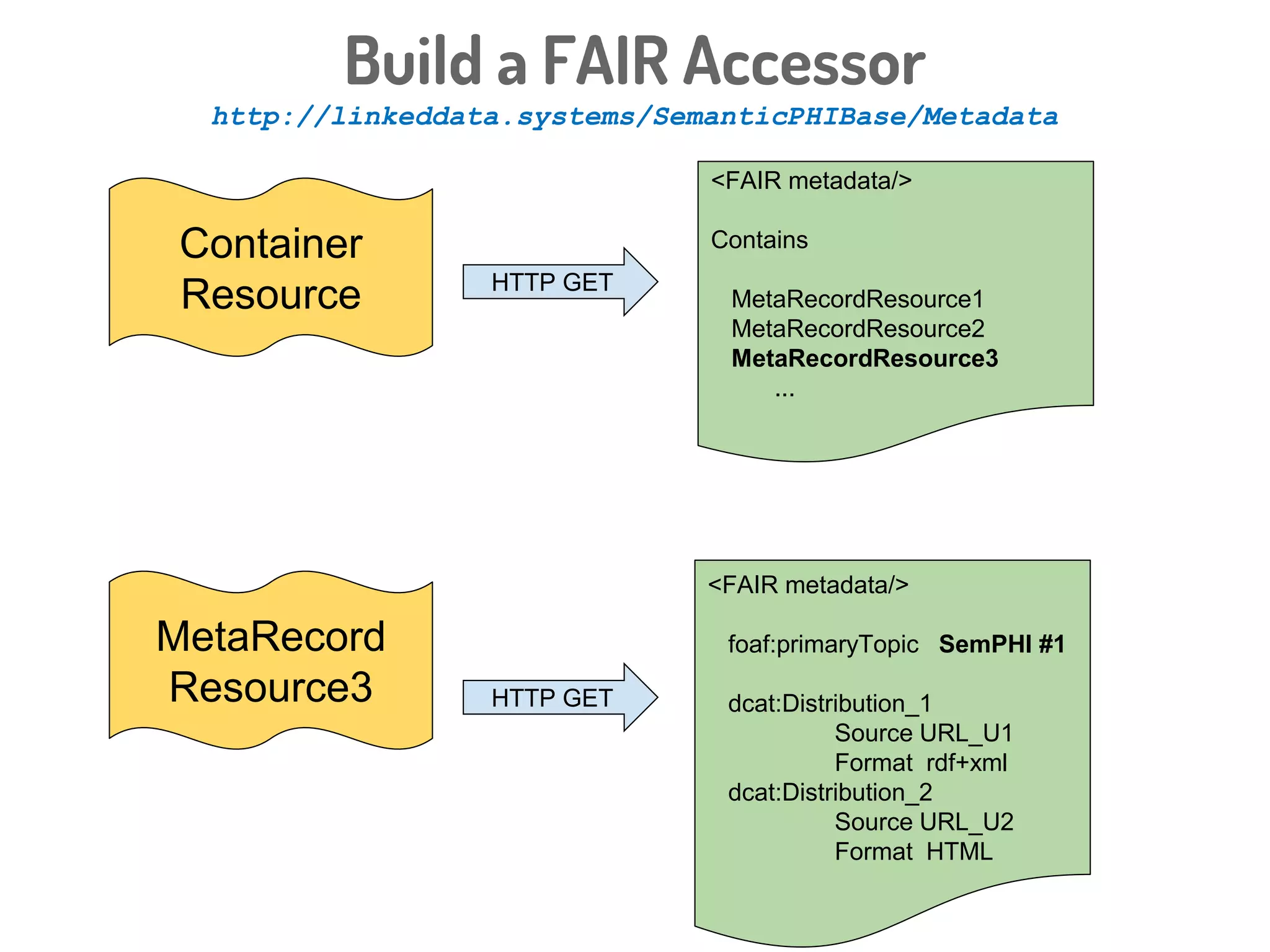
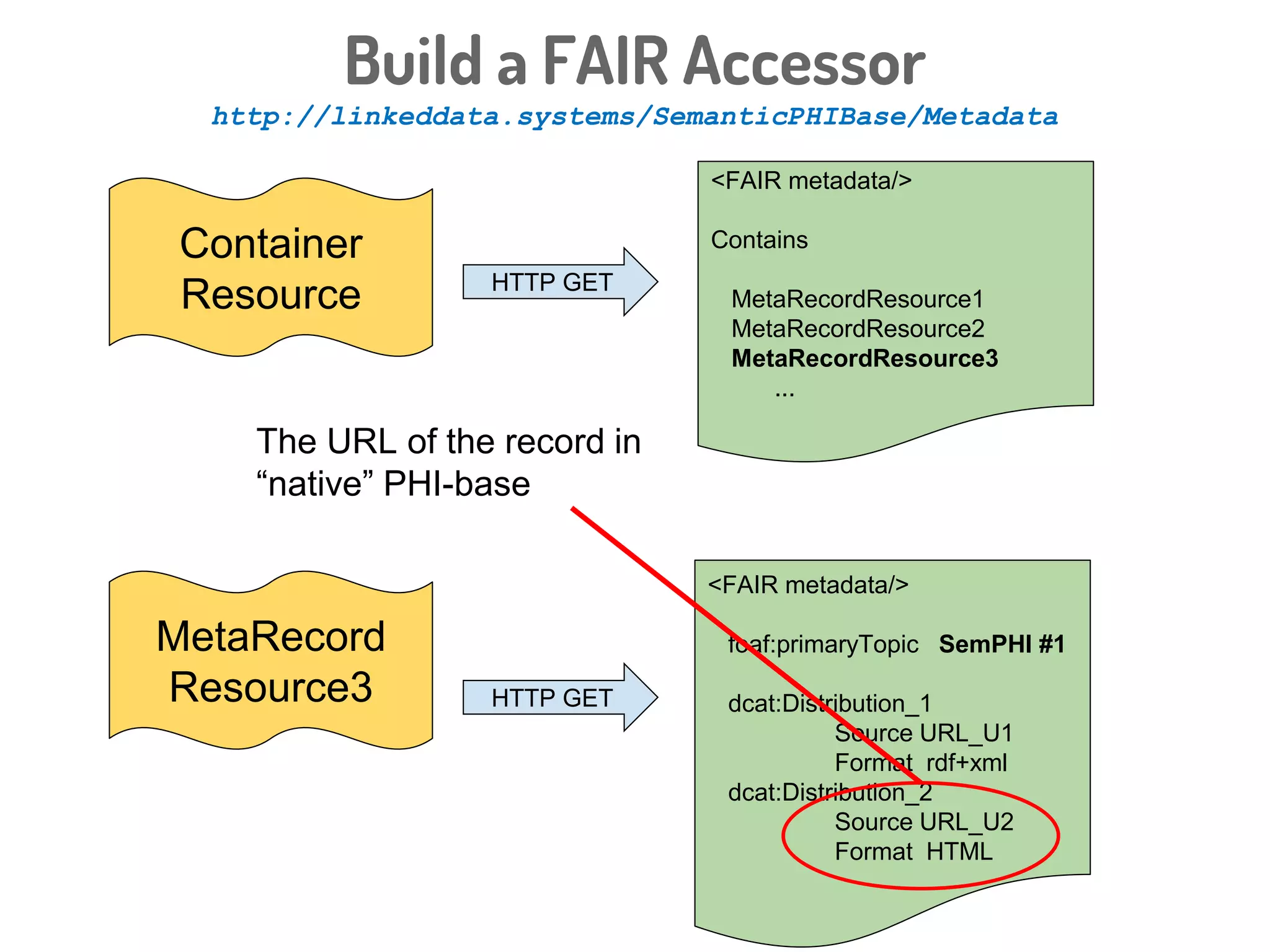
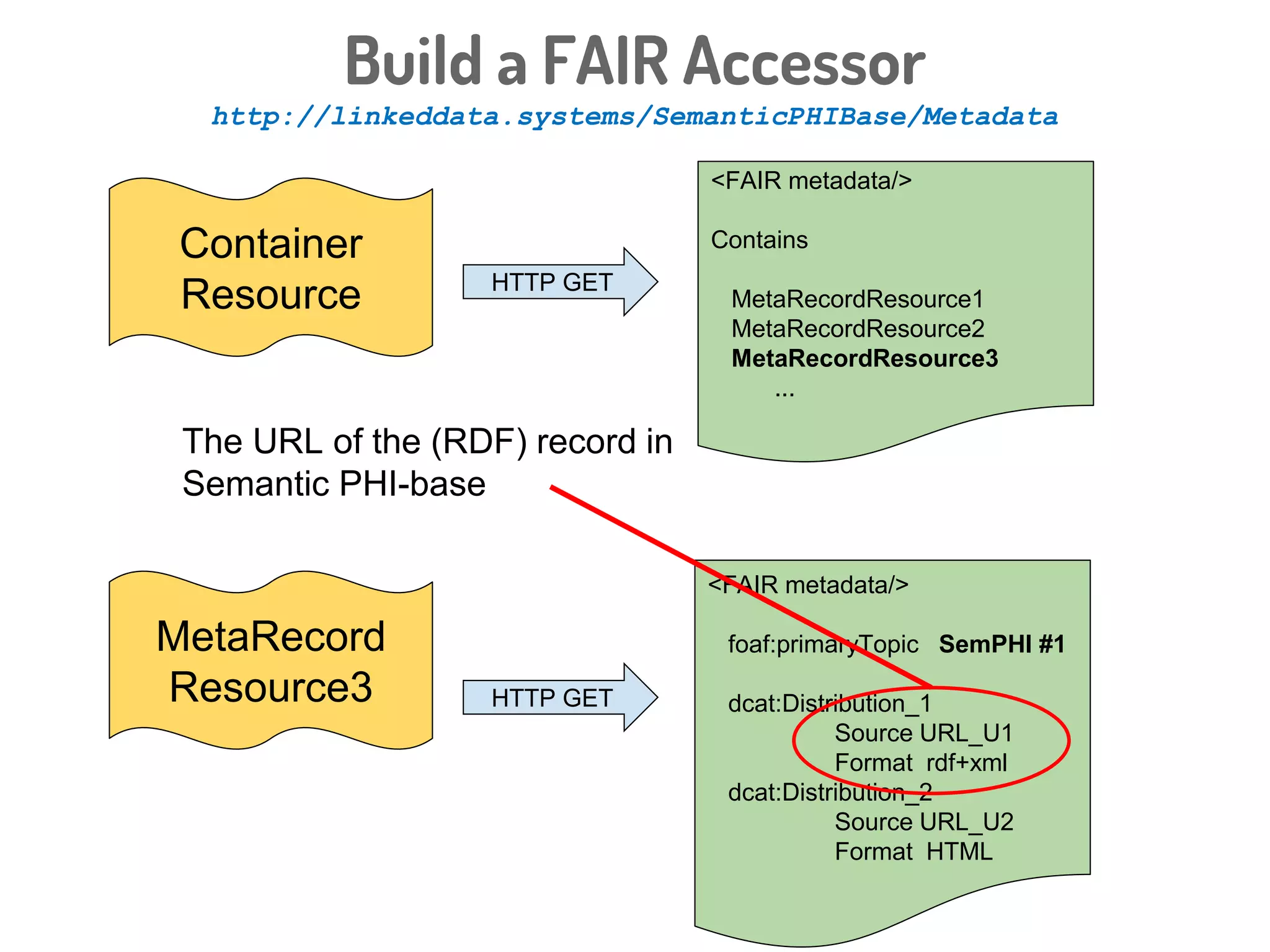
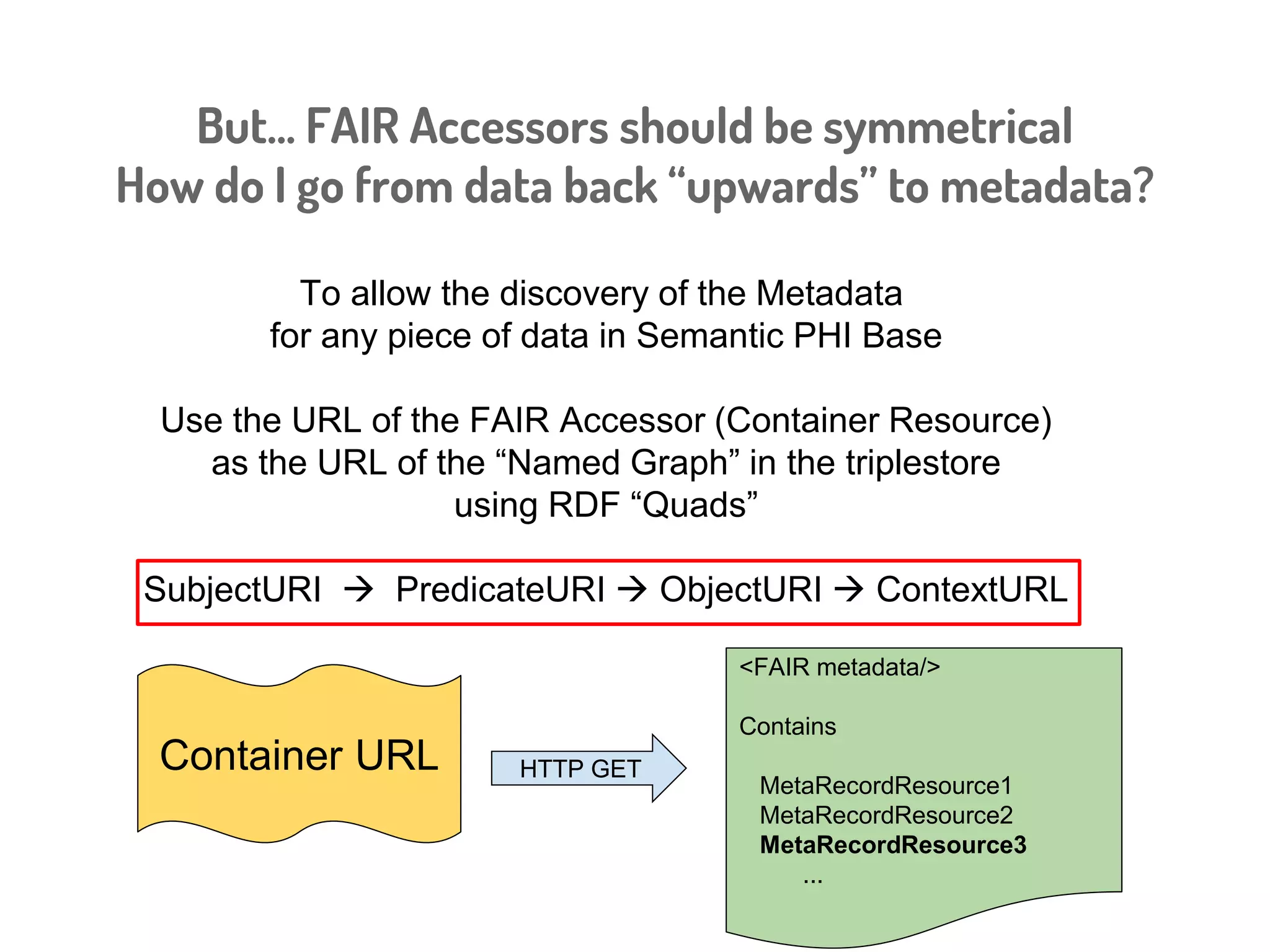
The document discusses a novel, API-free approach to improving data interoperability within legacy and prospective datasets, emphasizing the importance of FAIR principles: Findable, Accessible, Interoperable, and Reusable. It highlights the problems of data reproducibility and completeness in ecological and evolutionary research and outlines a concept for creating 'fair accessors' to facilitate publishing and accessing metadata about various scholarly entities without relying on APIs. The discussion involves collaborative efforts and proposed solutions aimed at enhancing data quality for better research transparency and reproducibility.











































































































