




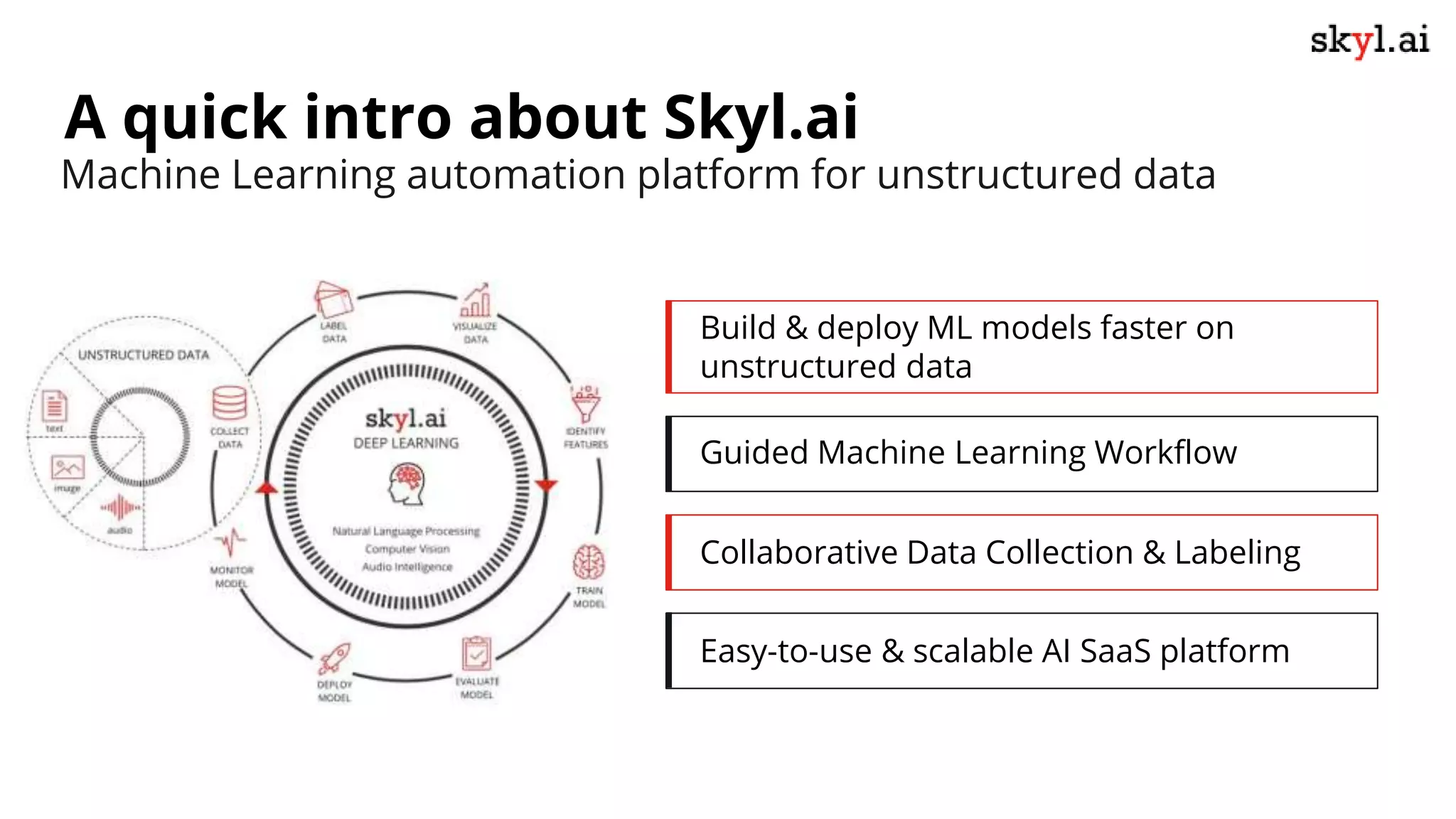


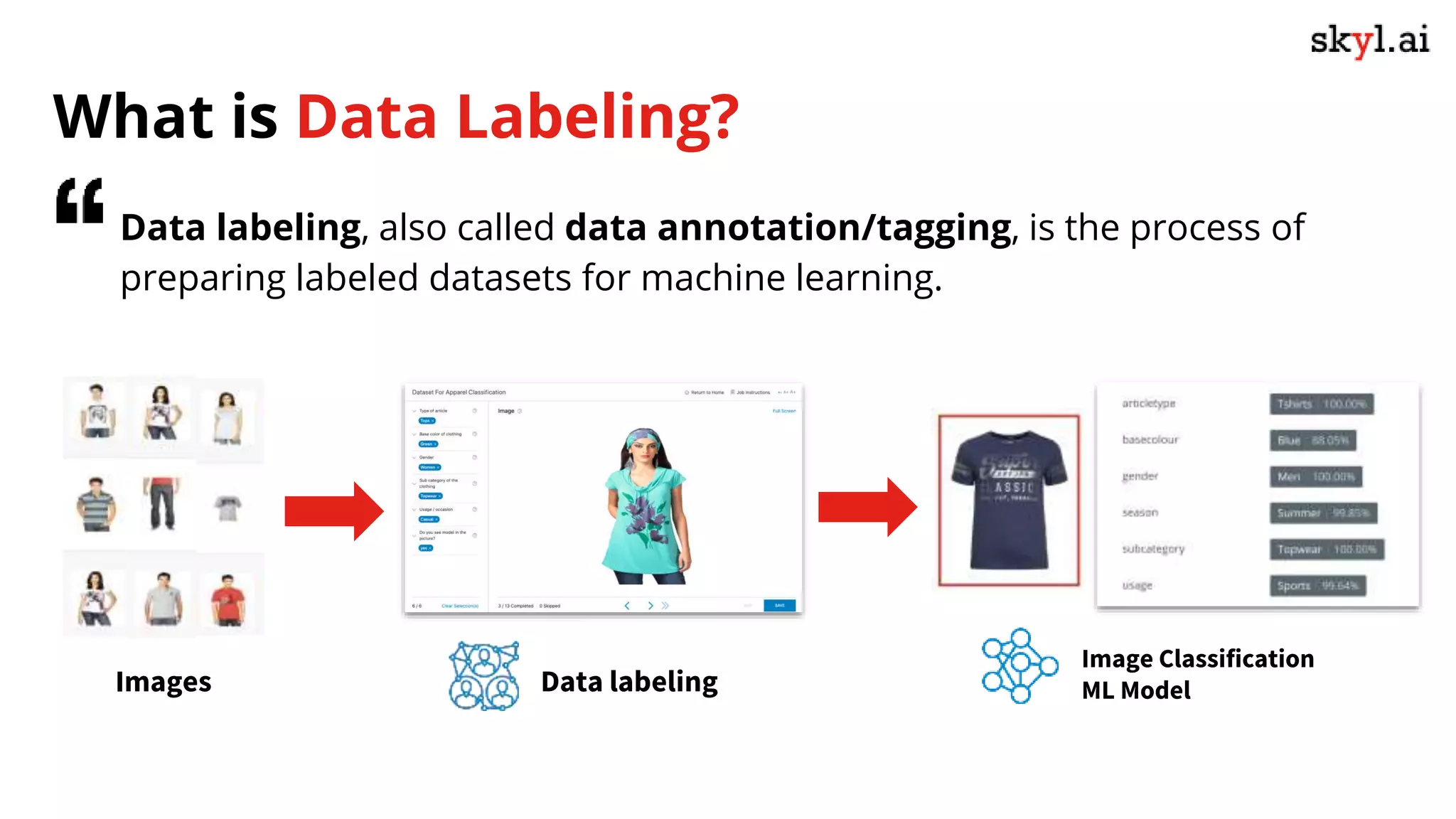

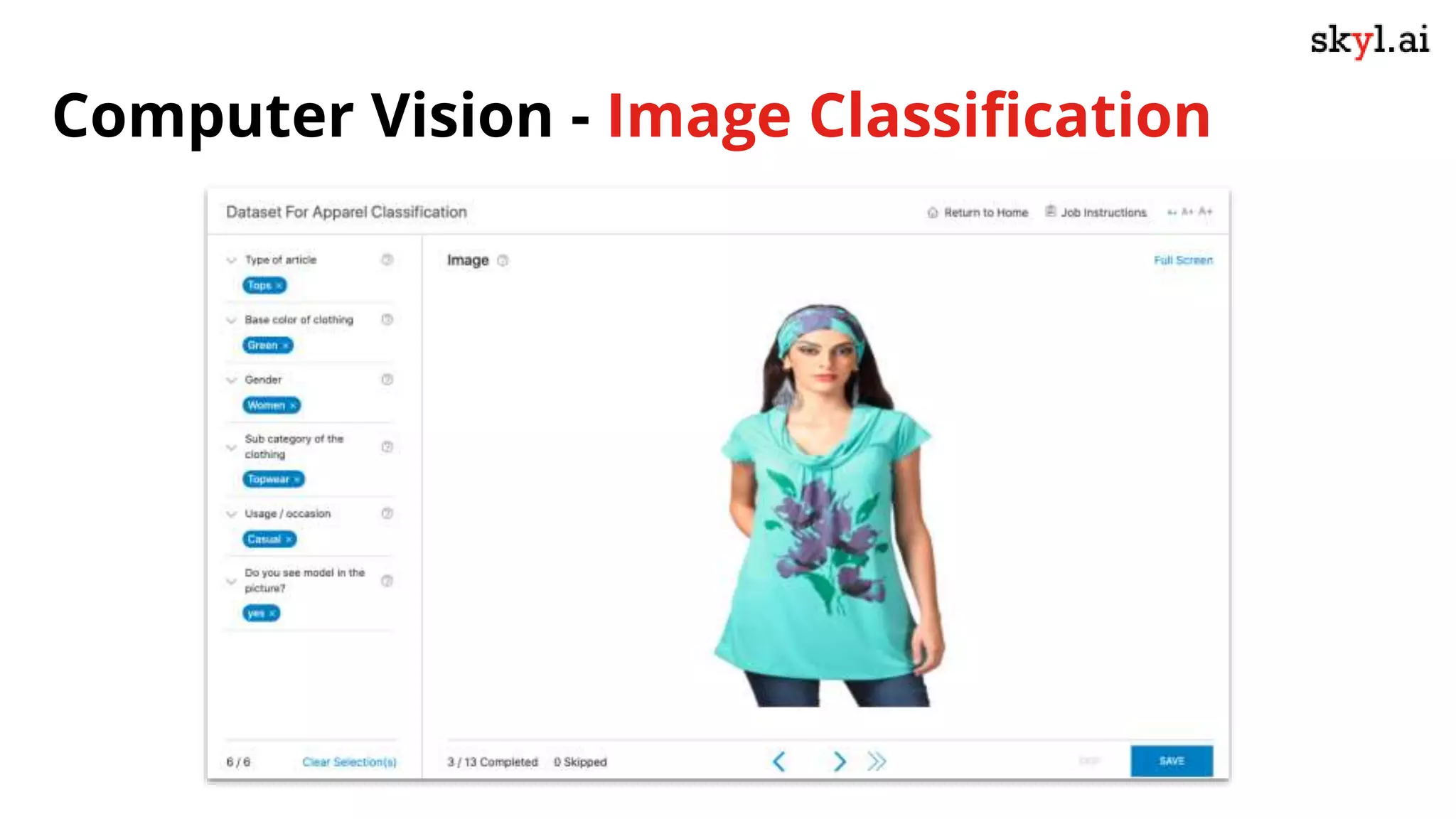
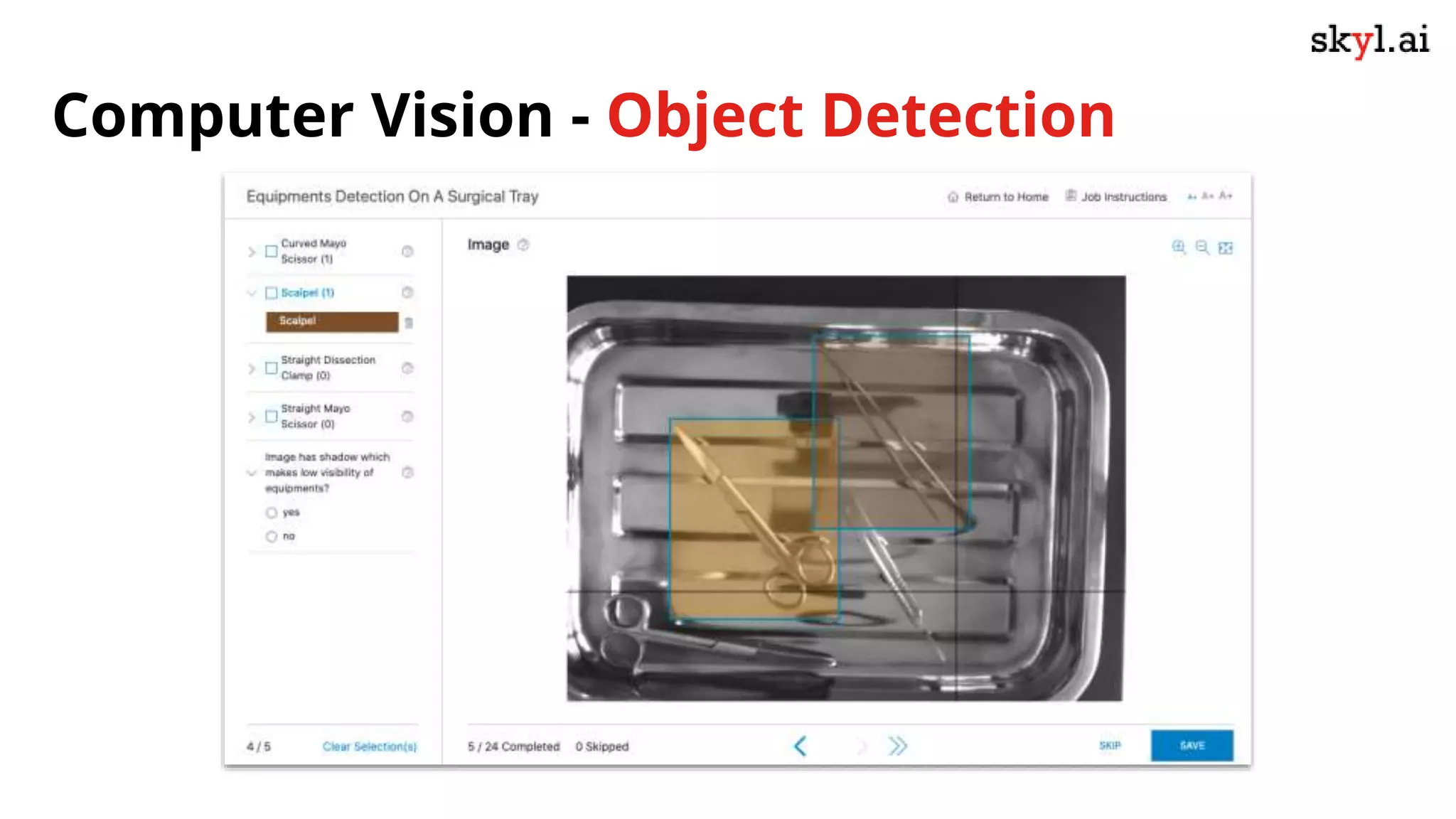
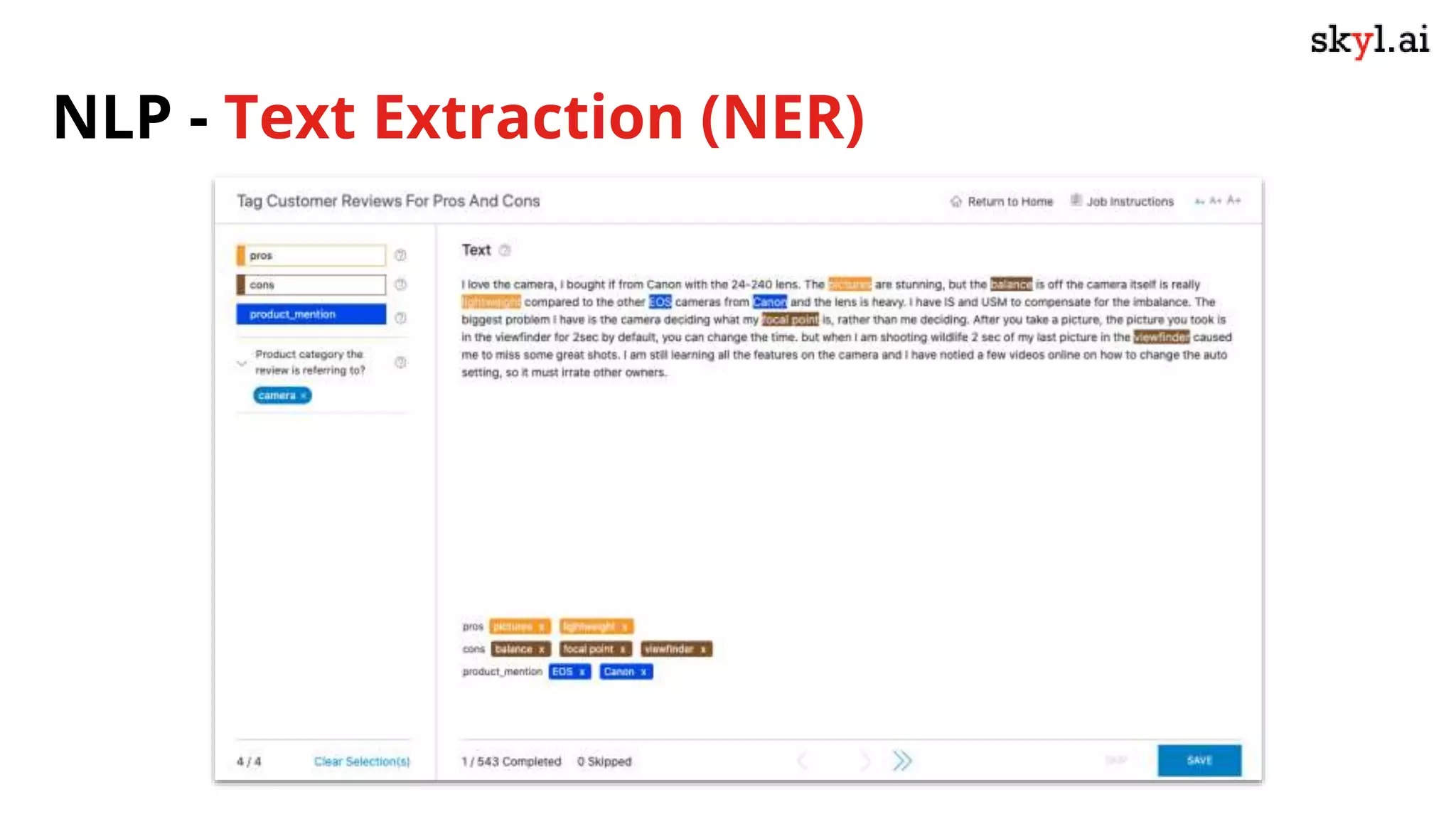

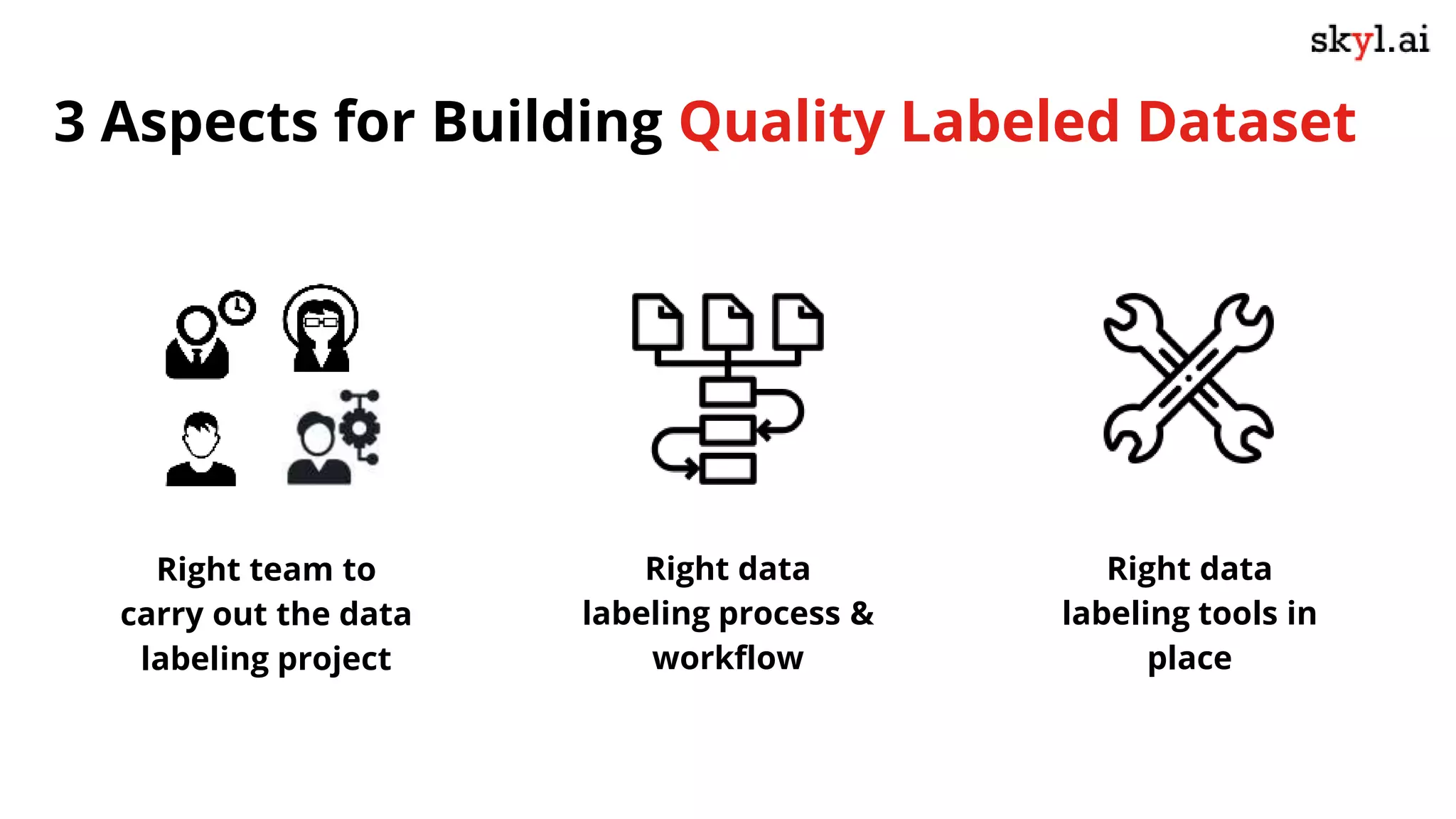





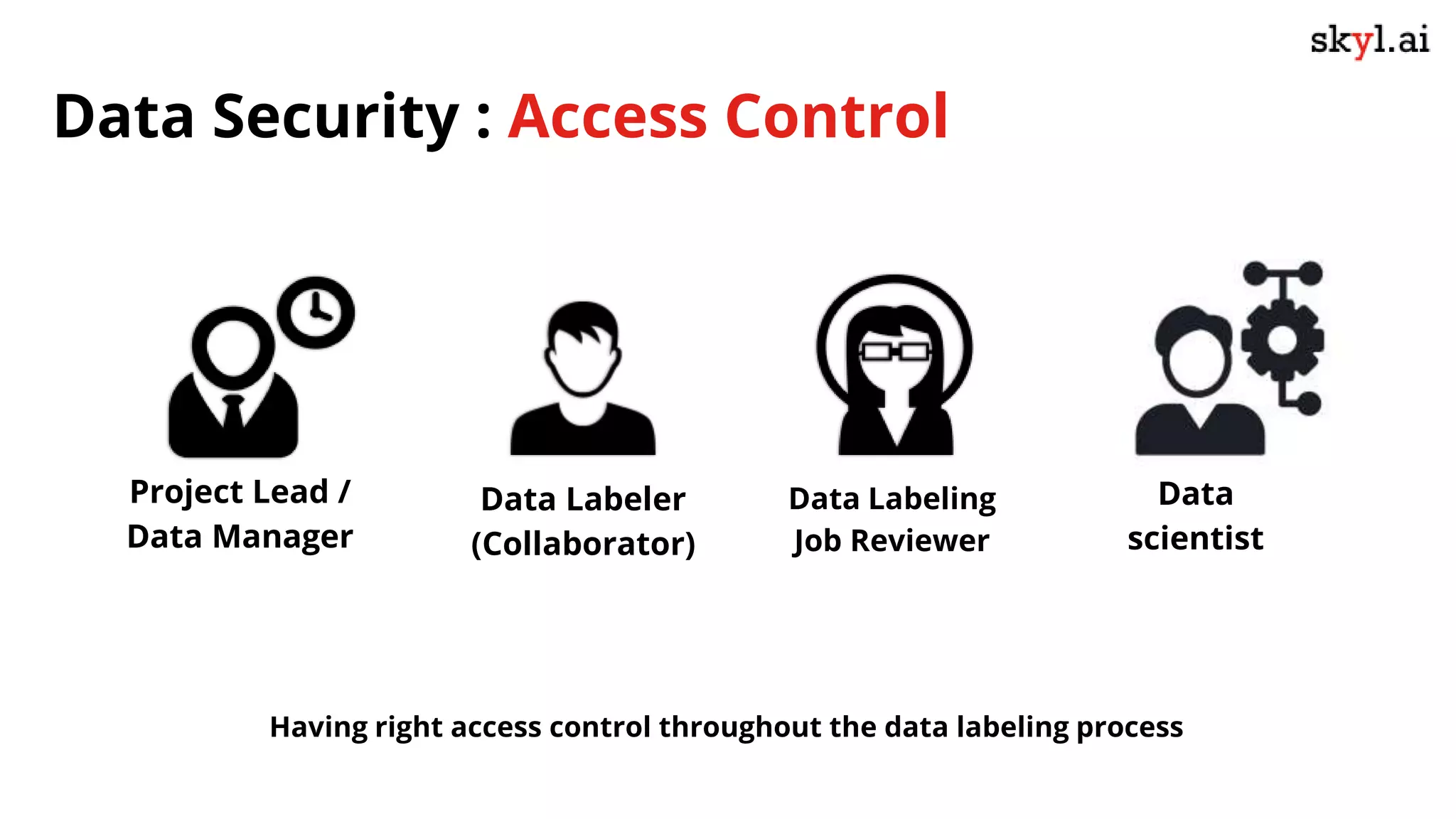
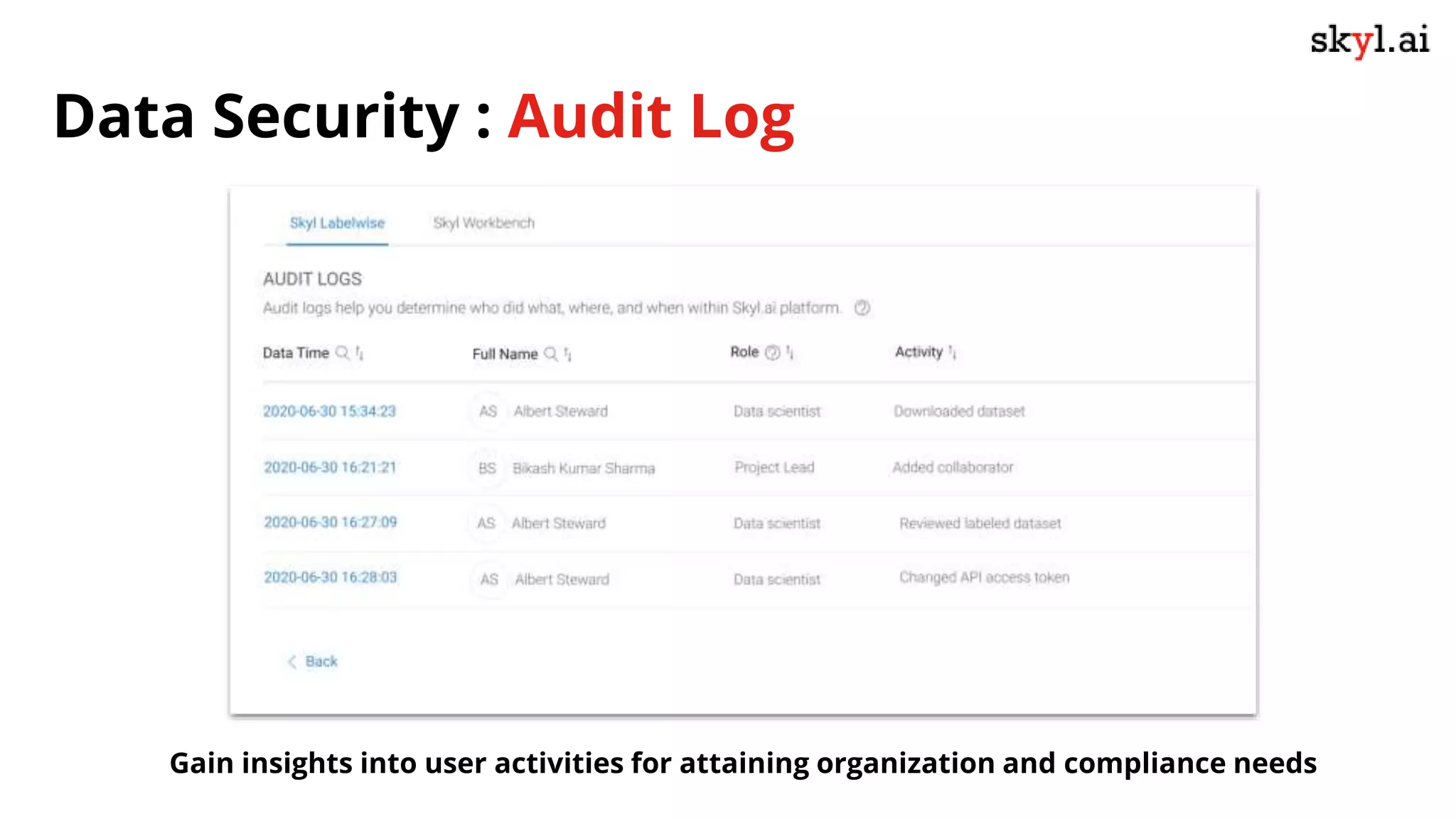
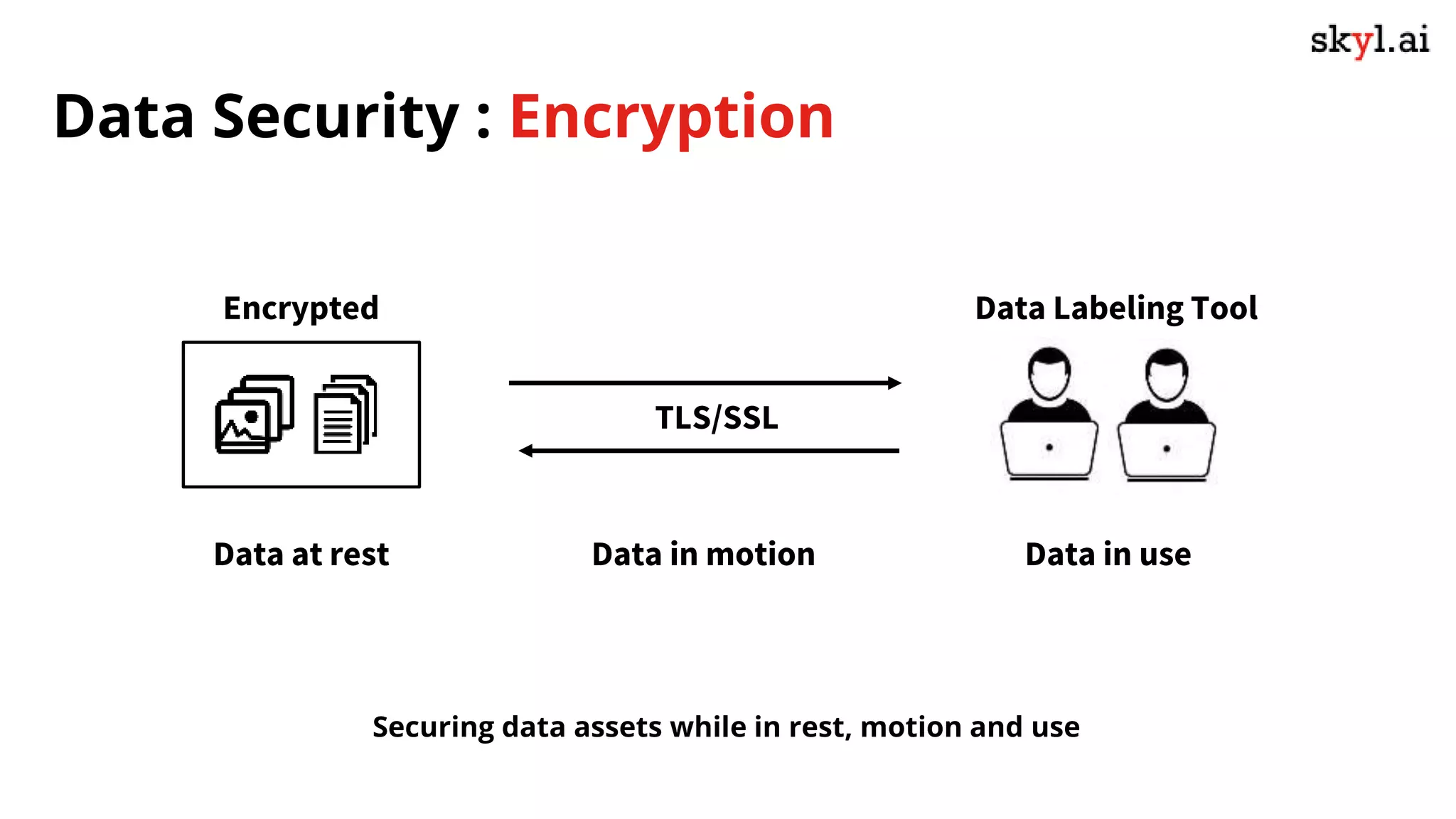
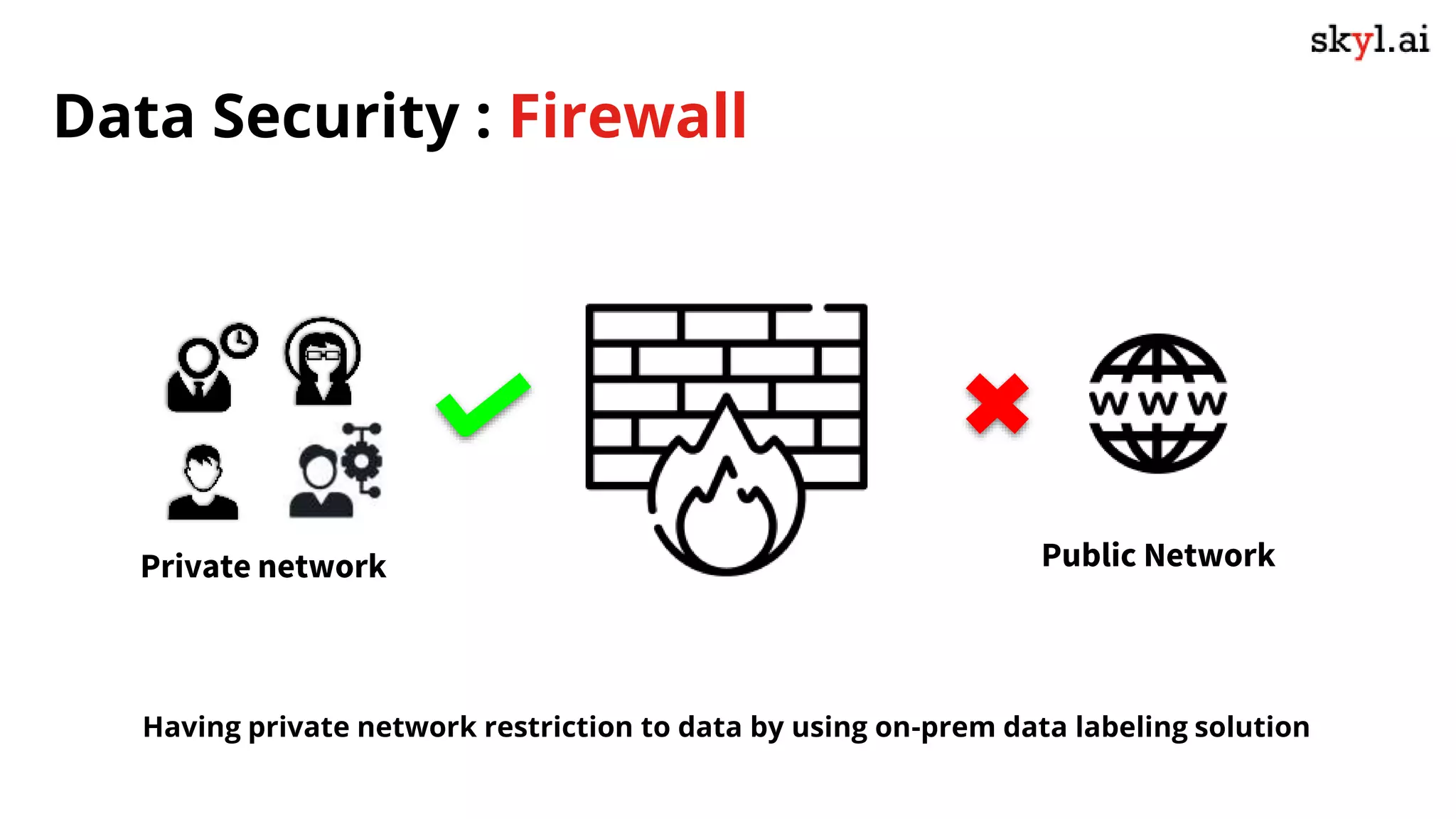

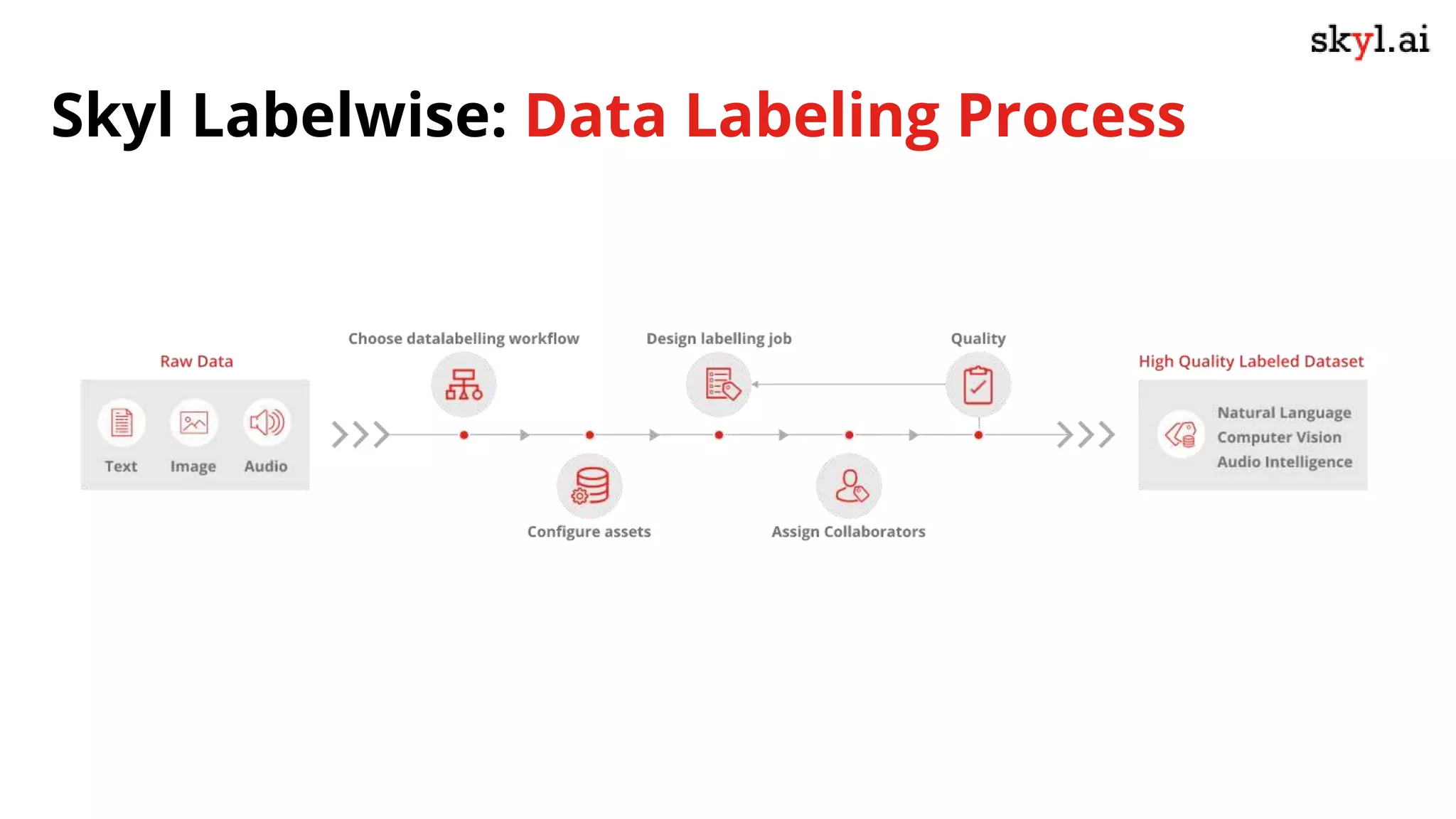








































The document discusses secure data labeling for machine learning, featuring experts in the field sharing their experiences and insights. It covers the data labeling process, best practices, and the importance of quality datasets while outlining the capabilities of skyl.ai's data labeling solution. The webinar also includes a live demo and offers consulting services for AI adoption and implementation.























































































