Download as PDF, PPTX


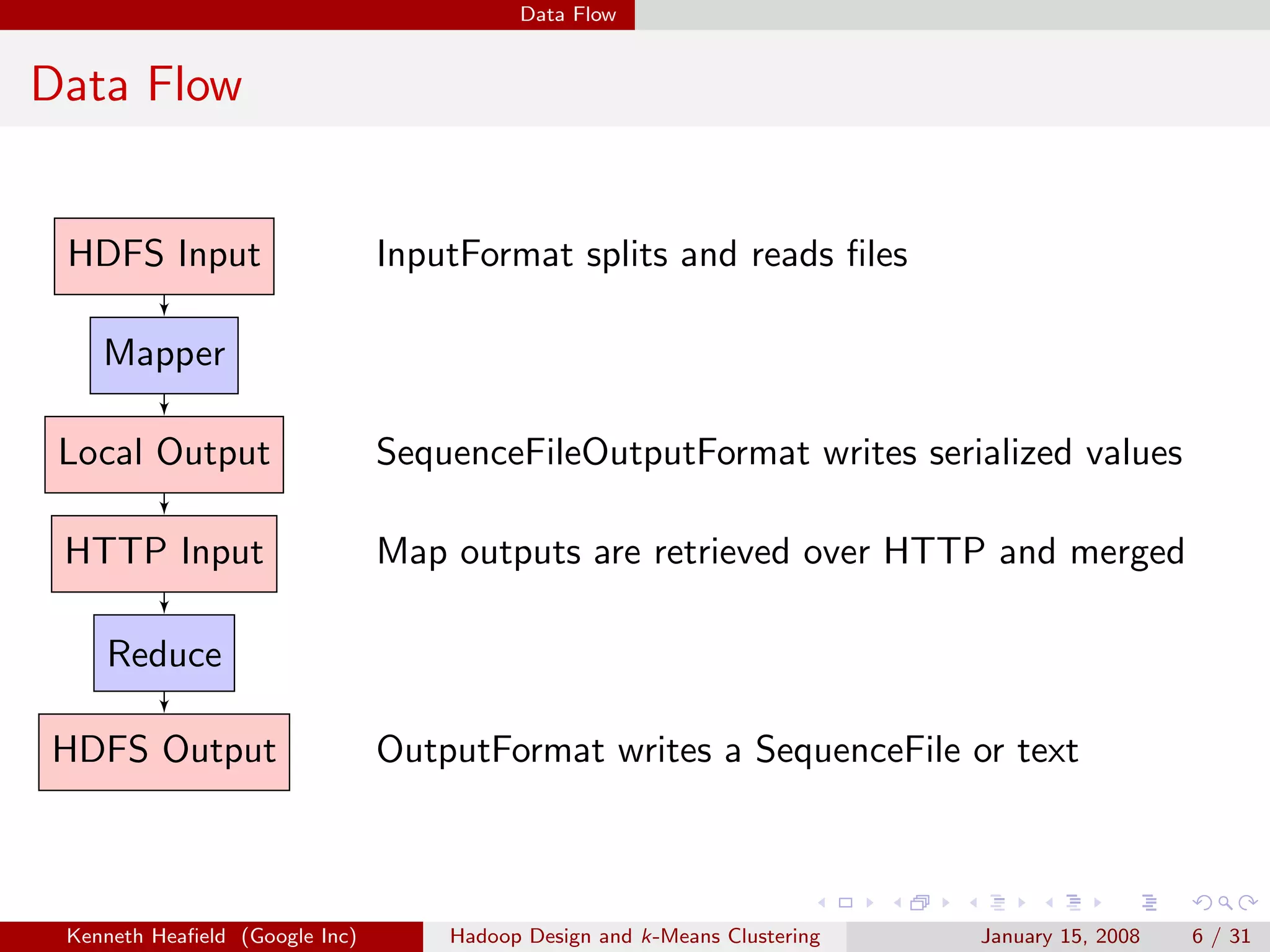
![Data Flow Input
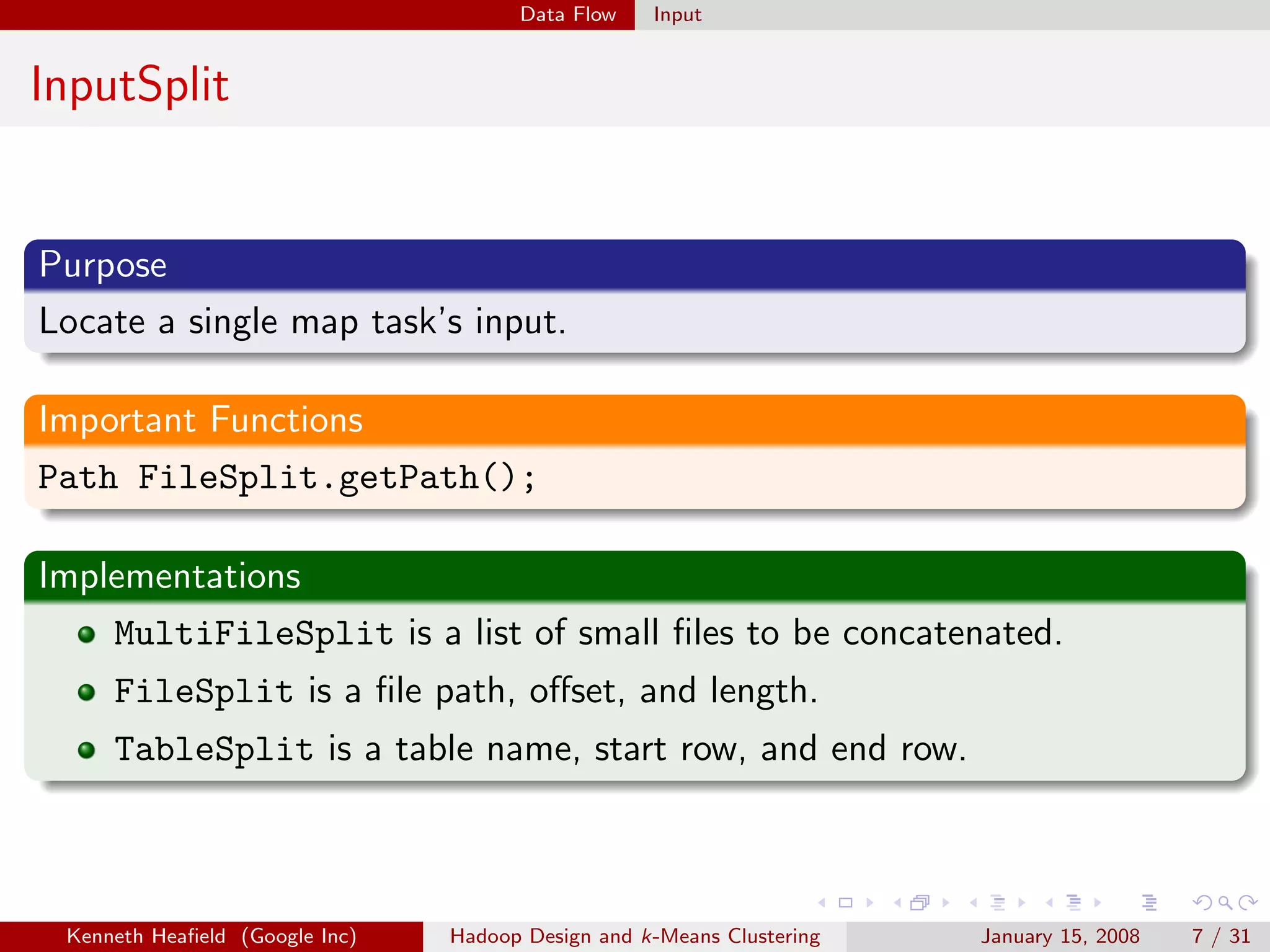
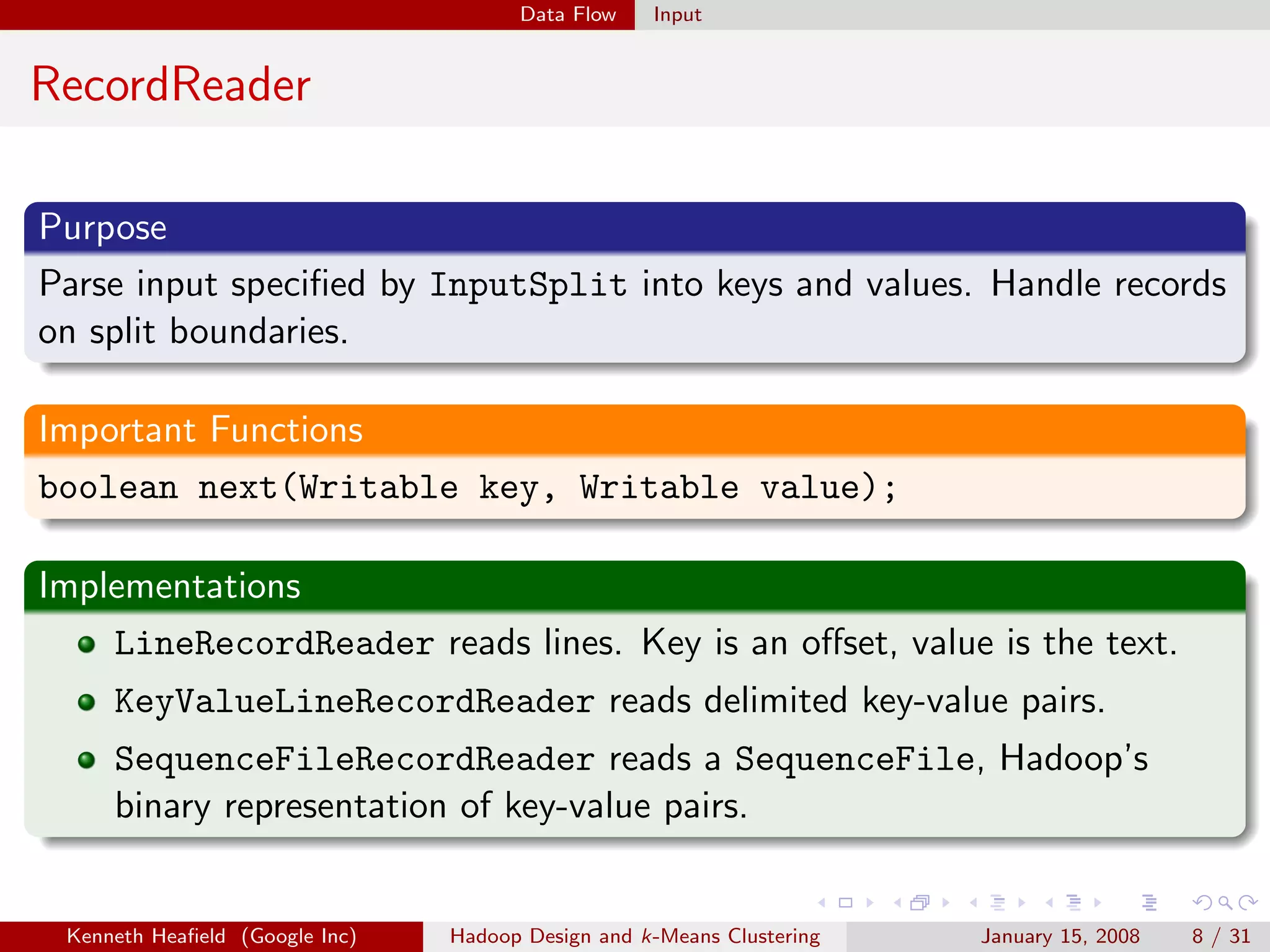
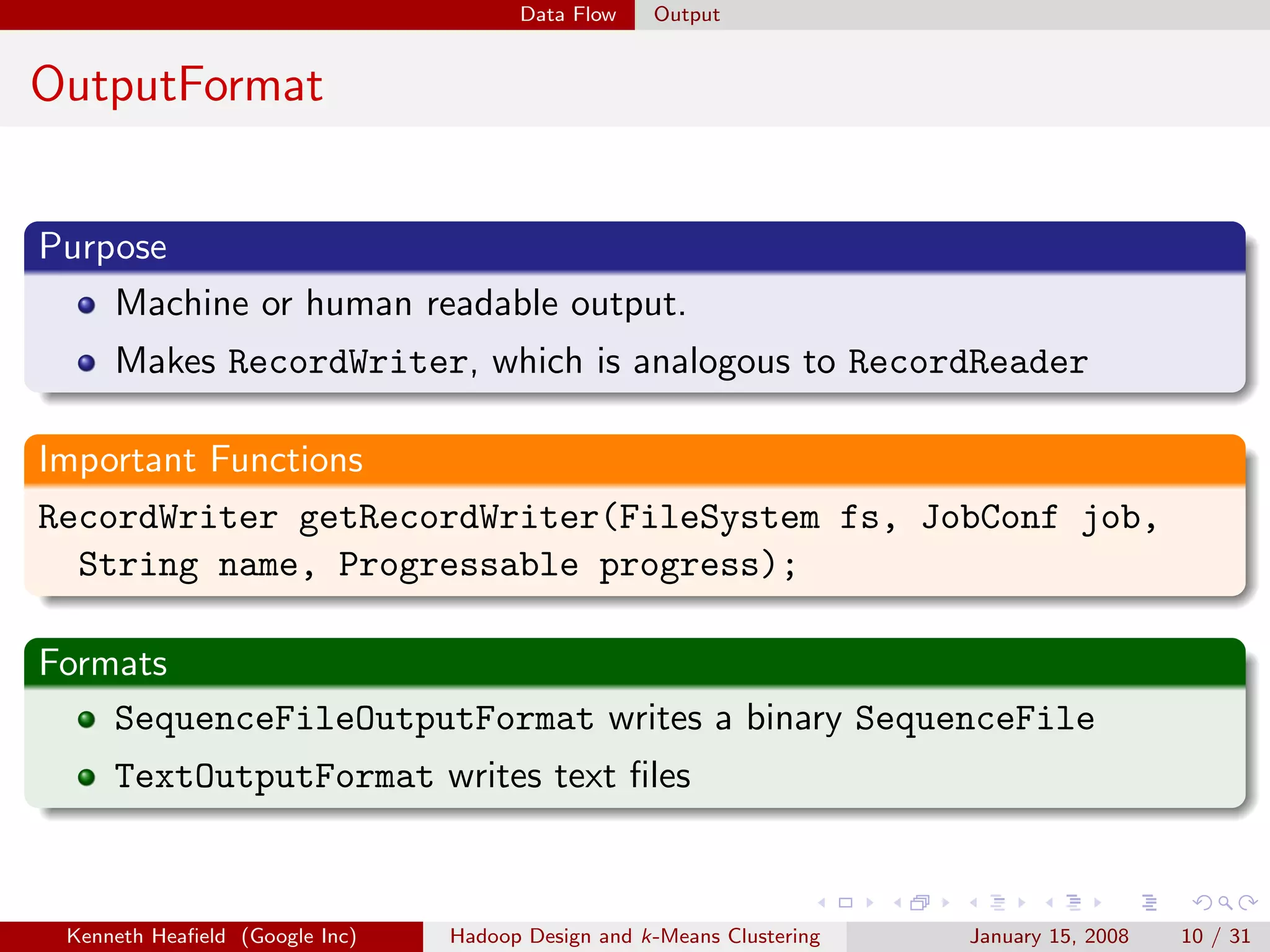
InputFormat
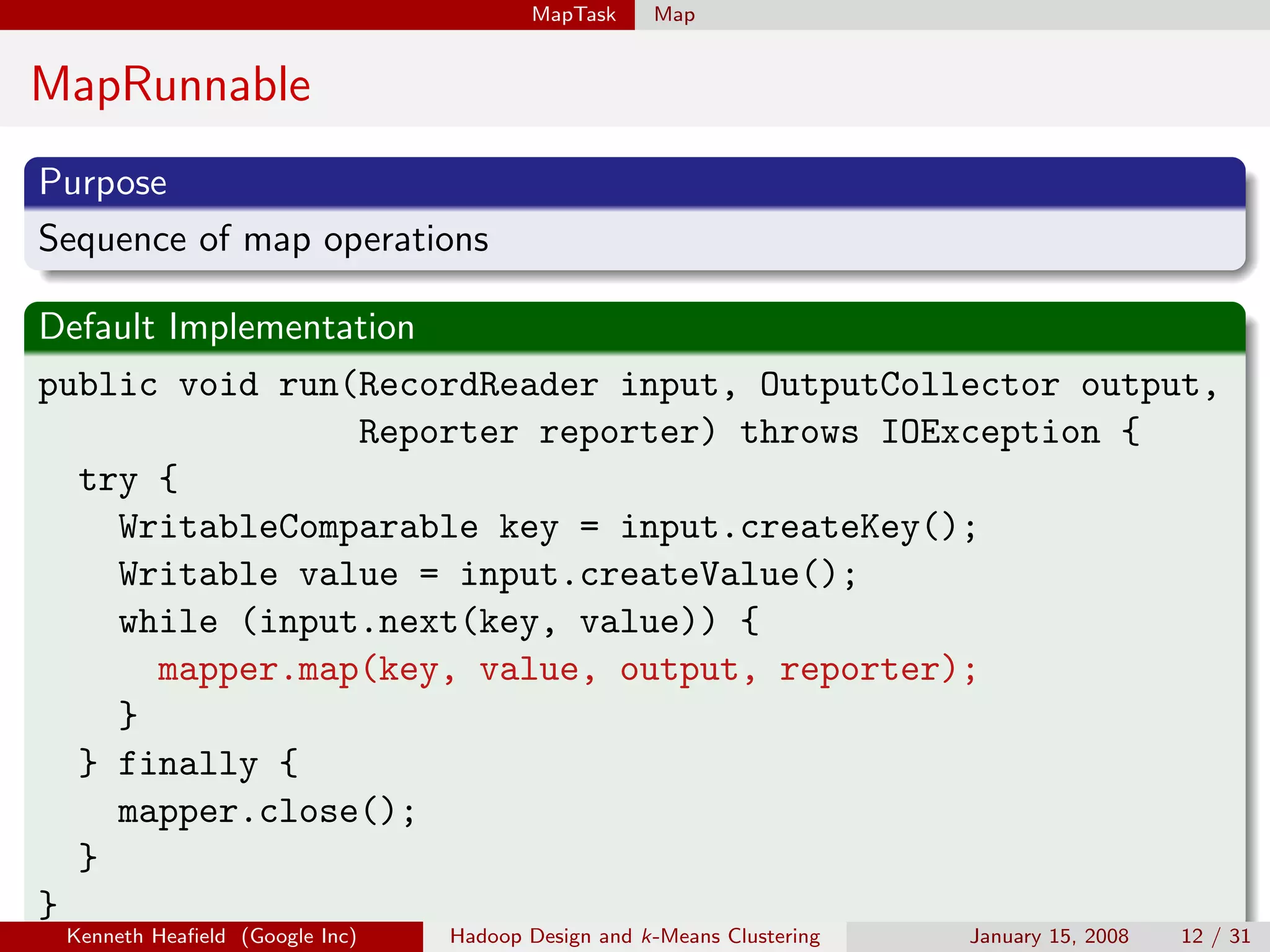
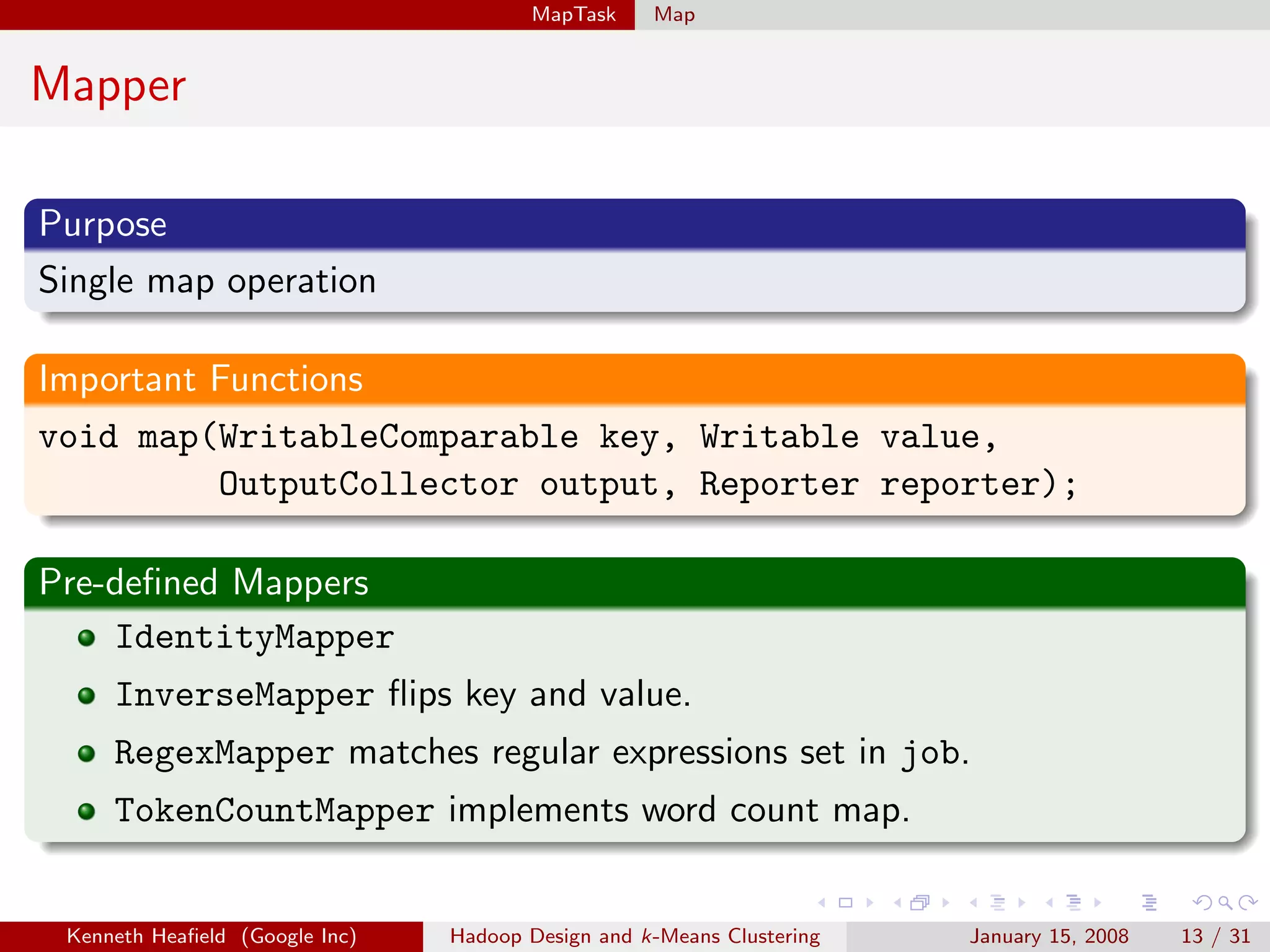
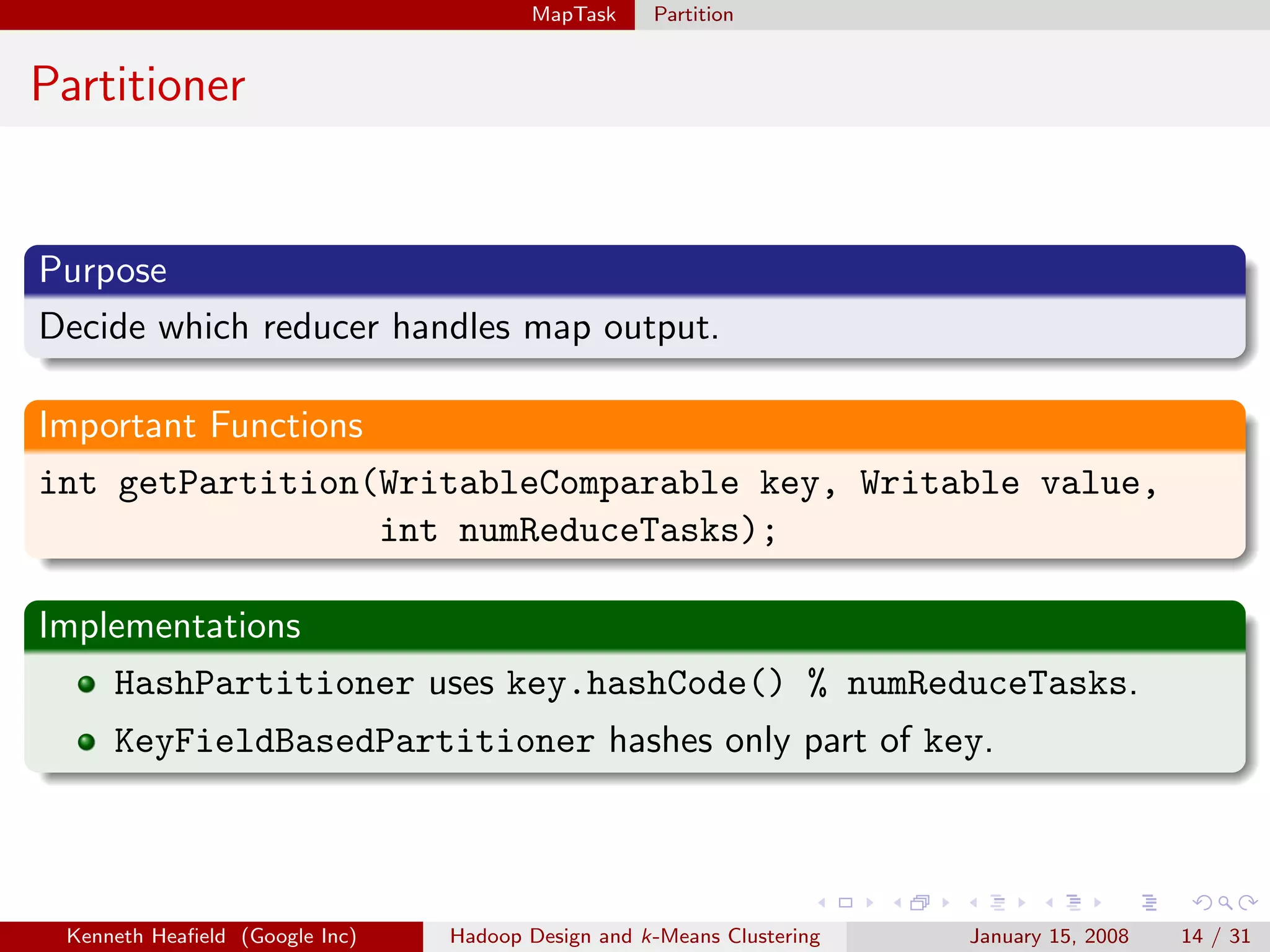
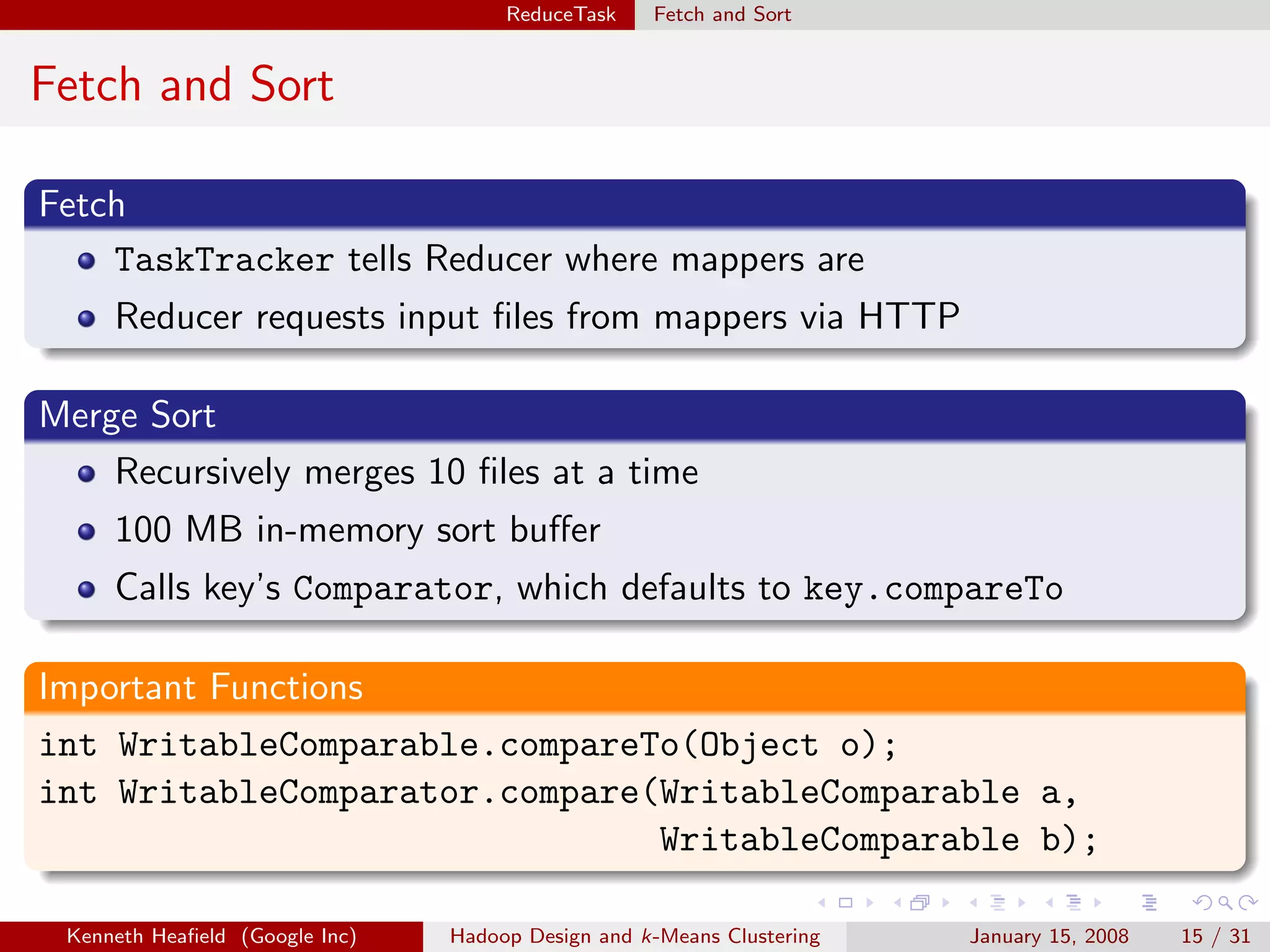
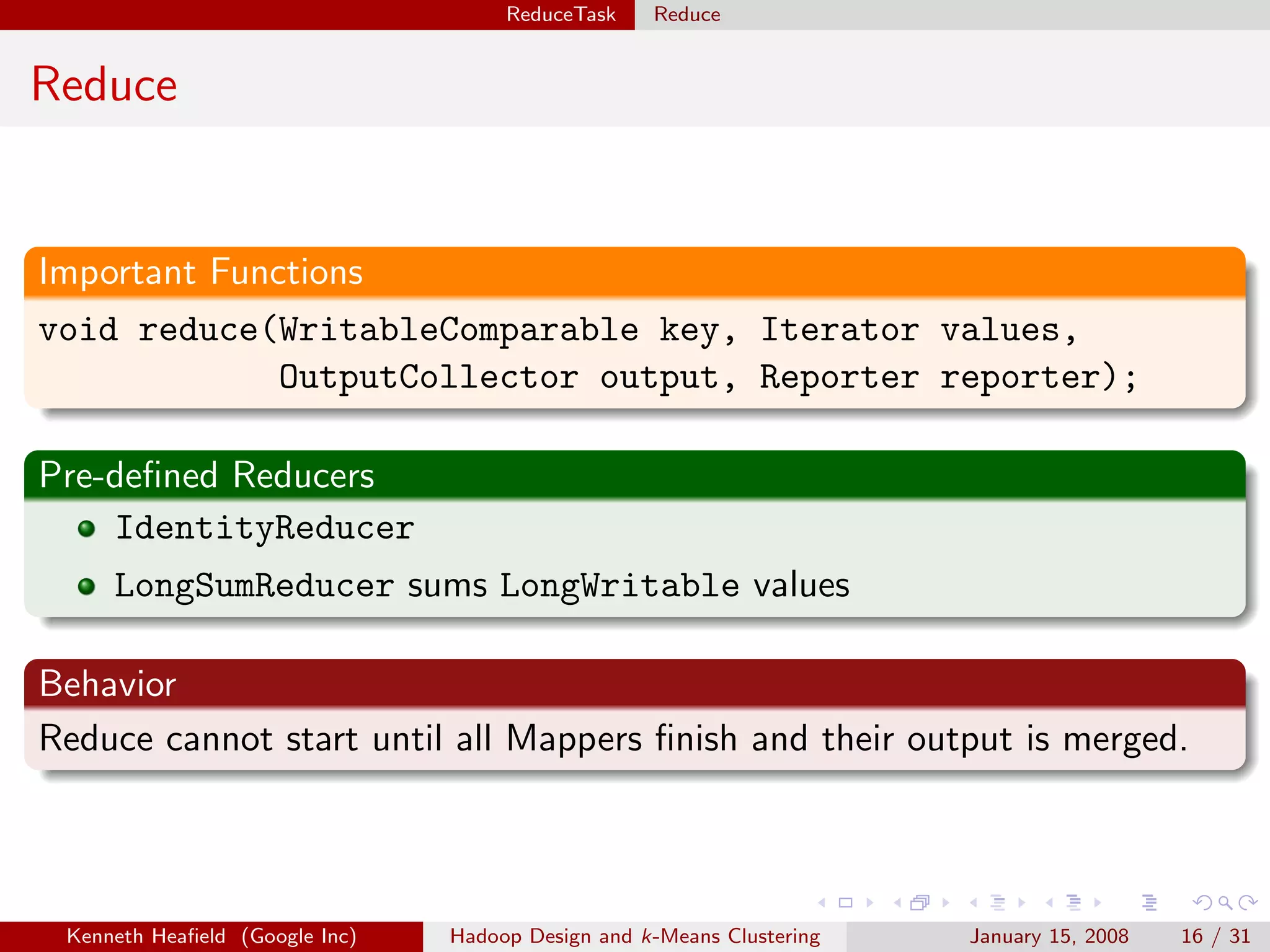
Purpose
Specifies input file format by constructing InputSplit and
RecordReader.
Important Functions
RecordReader getRecordReader(InputSplit split, JobConf job,
Reporter reporter);
InputSplit[] getSplits(JobConf job, int numSplits);
Implementations
TextInputFormat reads text files.
TableInputFormat reads from a table.
Kenneth Heafield (Google Inc) Hadoop Design and k-Means Clustering January 15, 2008 9 / 31](https://image.slidesharecdn.com/more-090927094956-phpapp02/75/Hadoop-Design-and-k-Means-Clustering-9-2048.jpg)




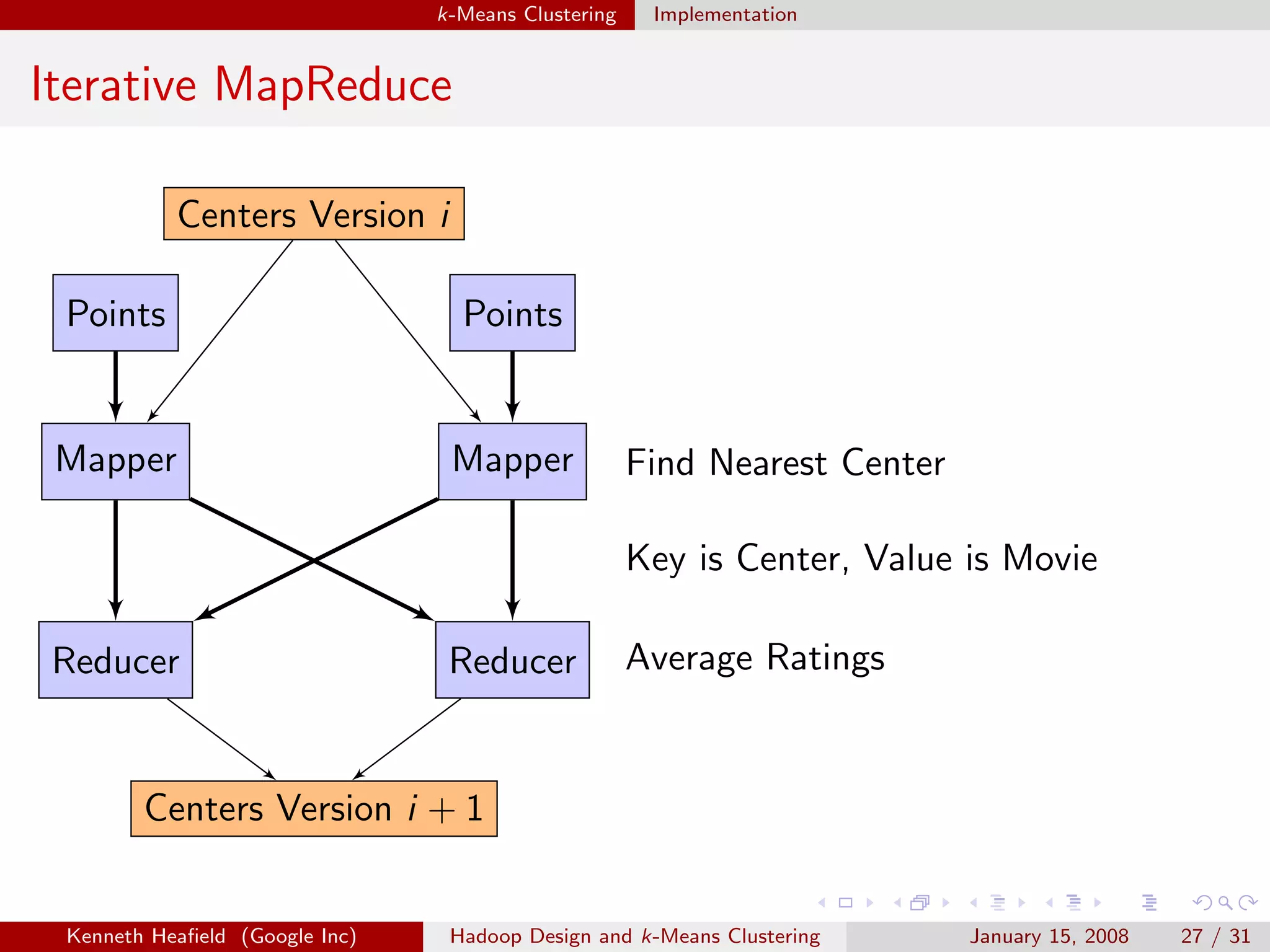
![k-Means Clustering Algorithm
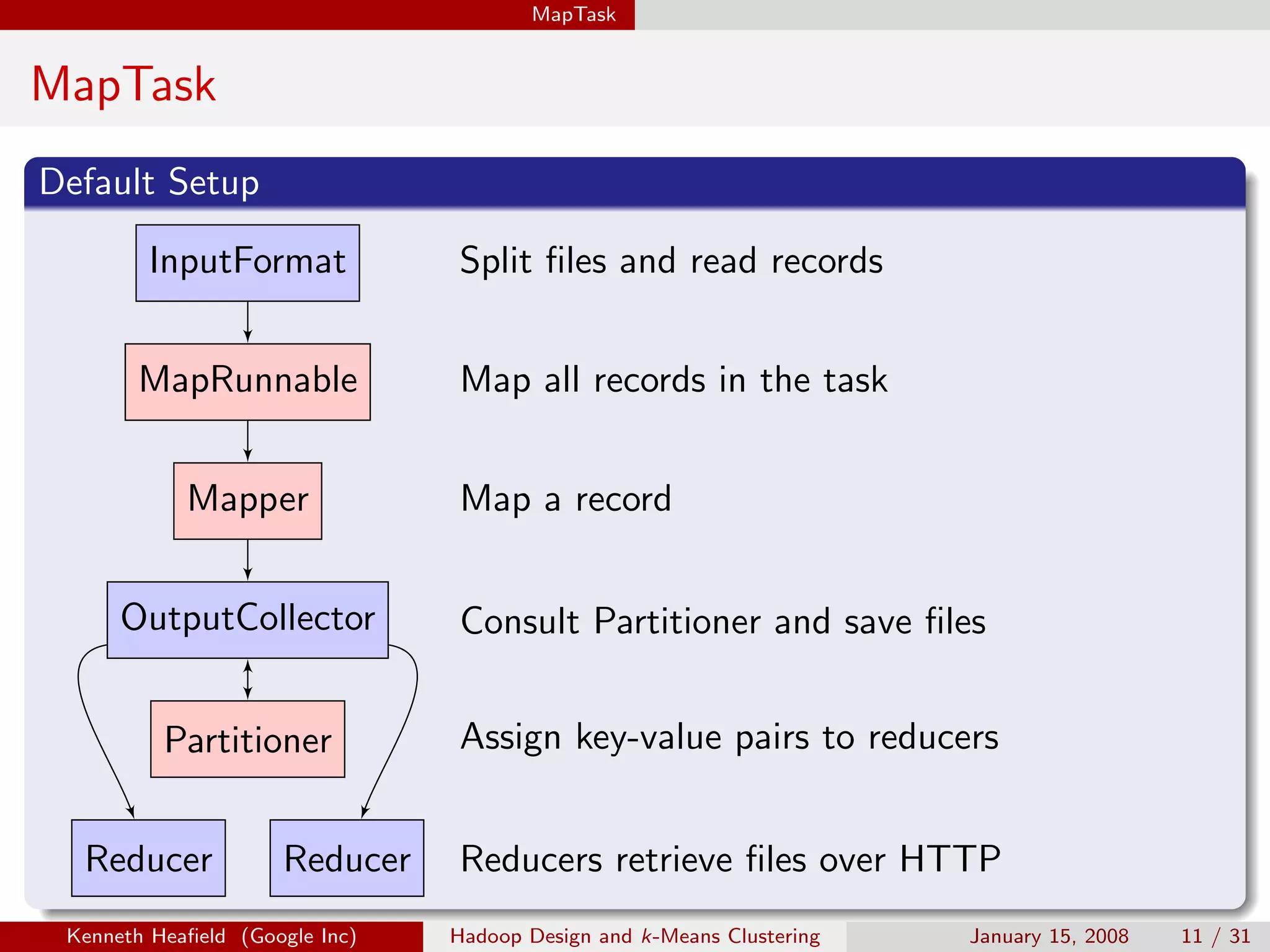
k-Means Clustering
Two Dimensional Clusters
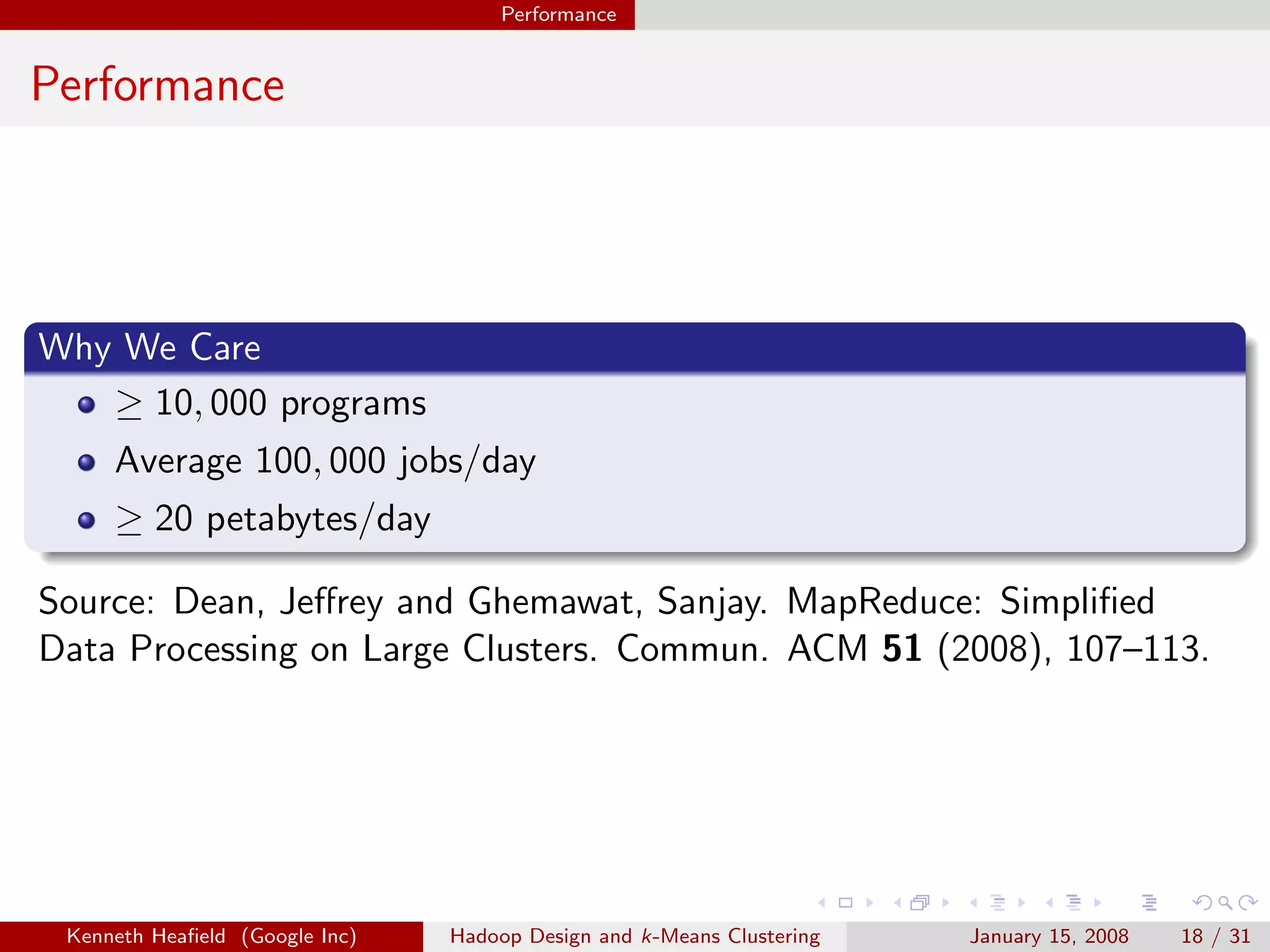
Goal
Cluster similar data points
Approach
Given data points x[i] and distance d:
Select k centers c
Assign x[i] to closest center c[i]
Minimize i d(x[i], c[i])
d is sum of squares
Kenneth Heafield (Google Inc) Hadoop Design and k-Means Clustering January 15, 2008 24 / 31](https://image.slidesharecdn.com/more-090927094956-phpapp02/75/Hadoop-Design-and-k-Means-Clustering-24-2048.jpg)













![Data Flow Input
InputFormat
Purpose
Specifies input file format by constructing InputSplit and
RecordReader.
Important Functions
RecordReader getRecordReader(InputSplit split, JobConf job,
Reporter reporter);
InputSplit[] getSplits(JobConf job, int numSplits);
Implementations
TextInputFormat reads text files.
TableInputFormat reads from a table.
Kenneth Heafield (Google Inc) Hadoop Design and k-Means Clustering January 15, 2008 9 / 31](https://crownmelresort.com/image.slidesharecdn.com/more-090927094956-phpapp02/75/Hadoop-Design-and-k-Means-Clustering-9-2048.jpg)














![k-Means Clustering Algorithm
k-Means Clustering
Two Dimensional Clusters
Goal
Cluster similar data points
Approach
Given data points x[i] and distance d:
Select k centers c
Assign x[i] to closest center c[i]
Minimize i d(x[i], c[i])
d is sum of squares
Kenneth Heafield (Google Inc) Hadoop Design and k-Means Clustering January 15, 2008 24 / 31](https://crownmelresort.com/image.slidesharecdn.com/more-090927094956-phpapp02/75/Hadoop-Design-and-k-Means-Clustering-24-2048.jpg)








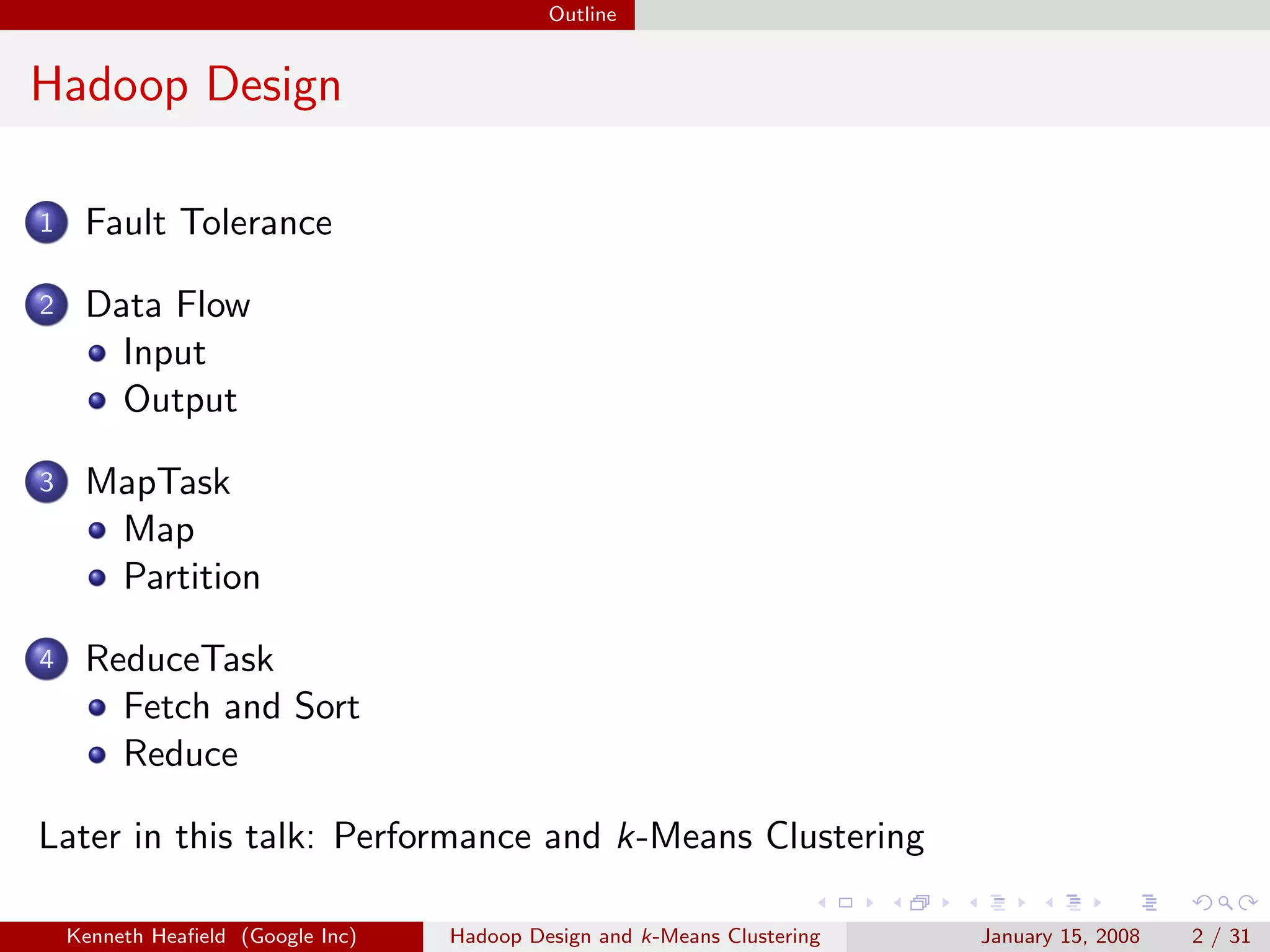
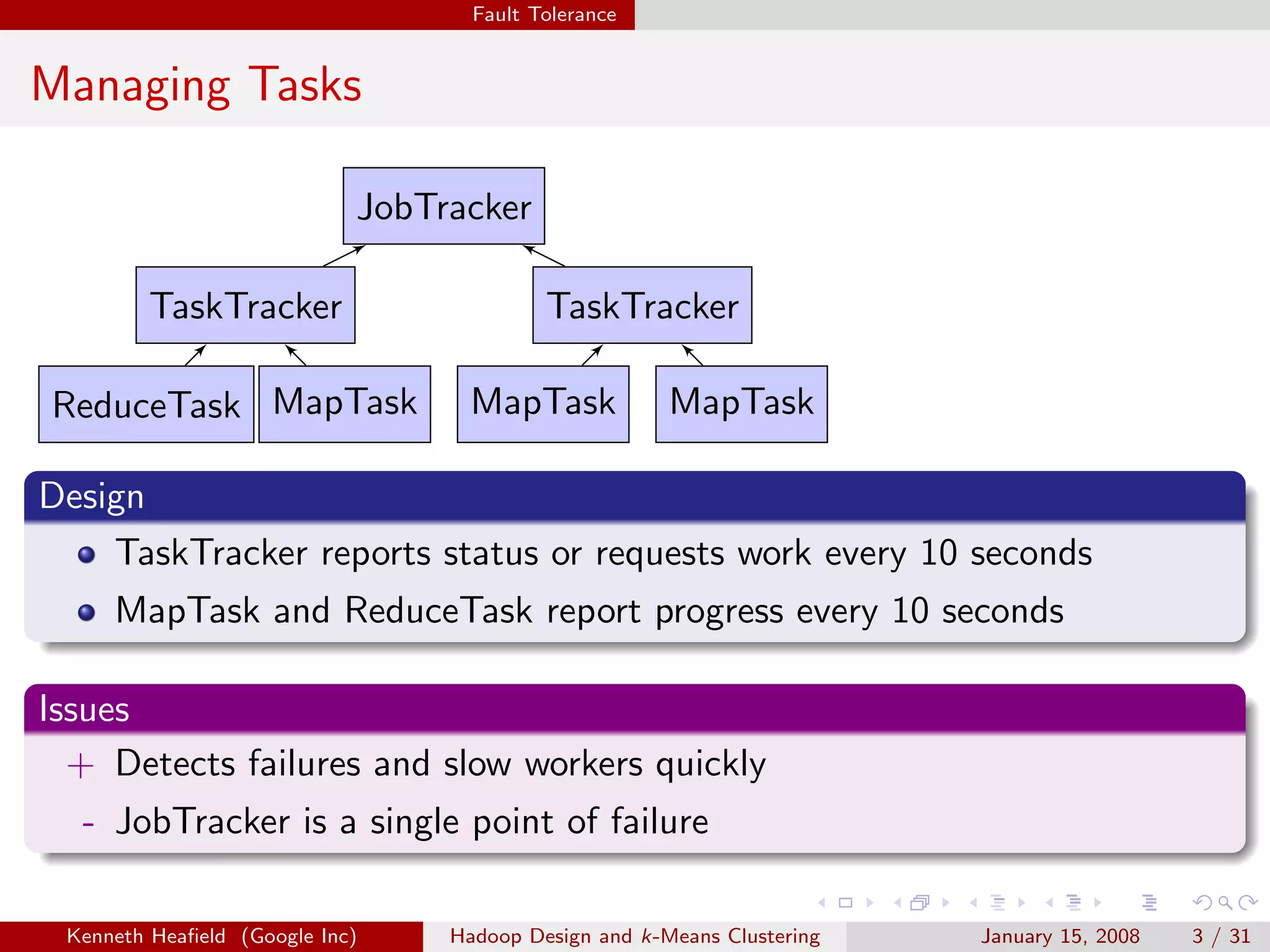
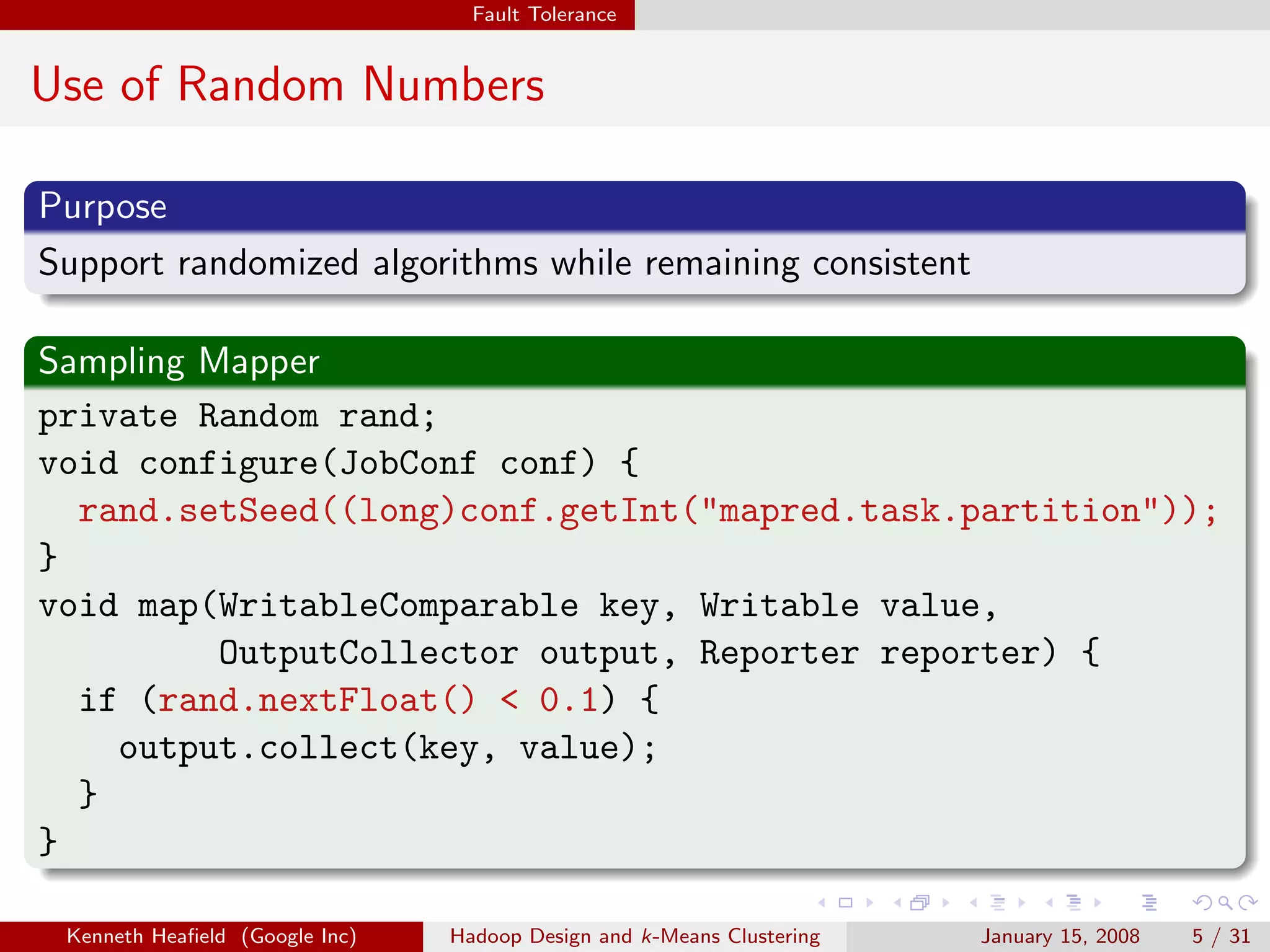
This document discusses Hadoop design and k-means clustering. It outlines Hadoop's fault tolerance through task tracking and task replication. It describes Hadoop's data flow including input splitting, mapping and reducing. It also discusses optimizations like combiners. Finally it explains the k-means clustering algorithm and different approaches to implementing it in Hadoop including iterative MapReduce and partitioning large numbers of clusters.








































































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)

