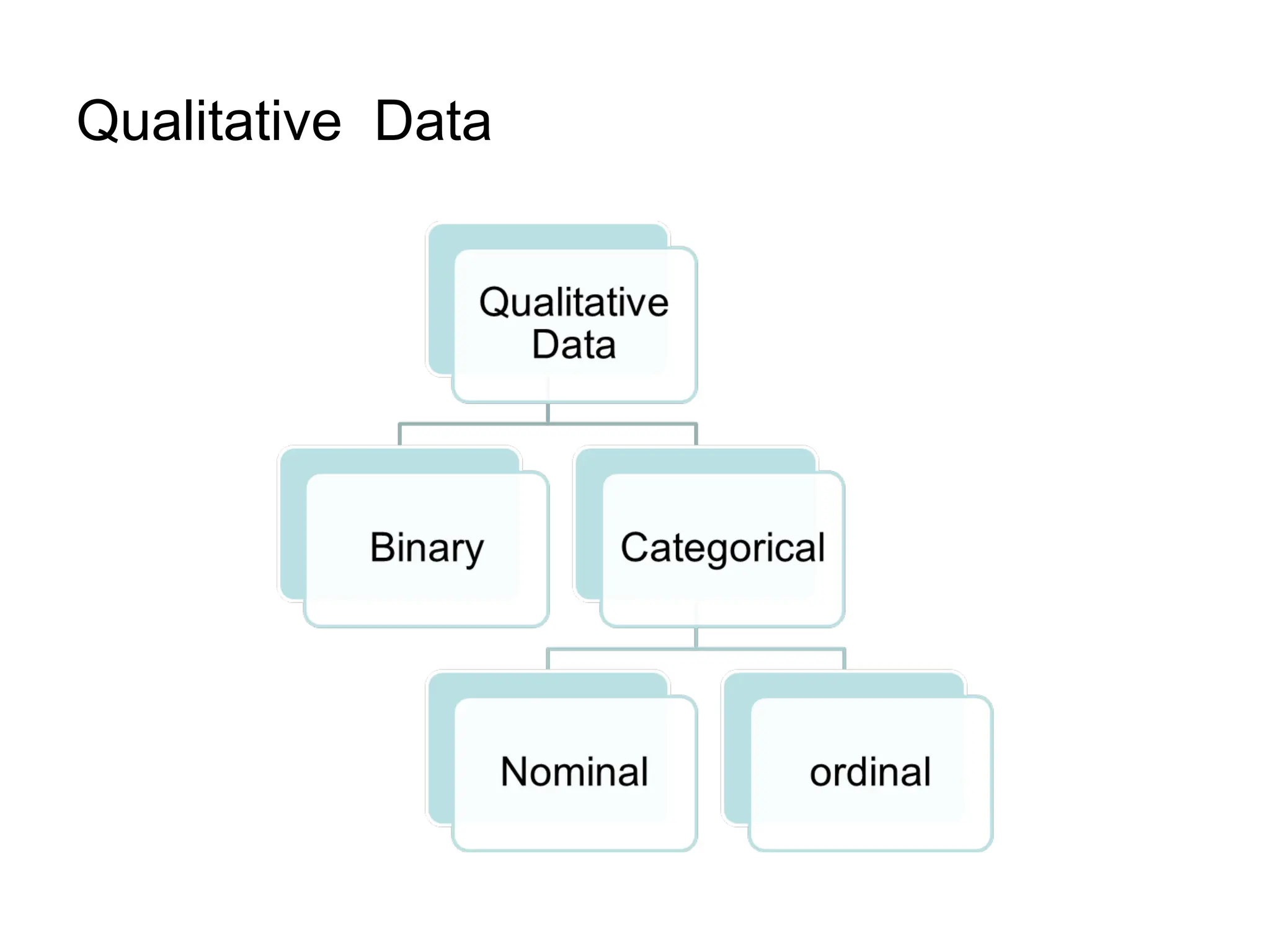
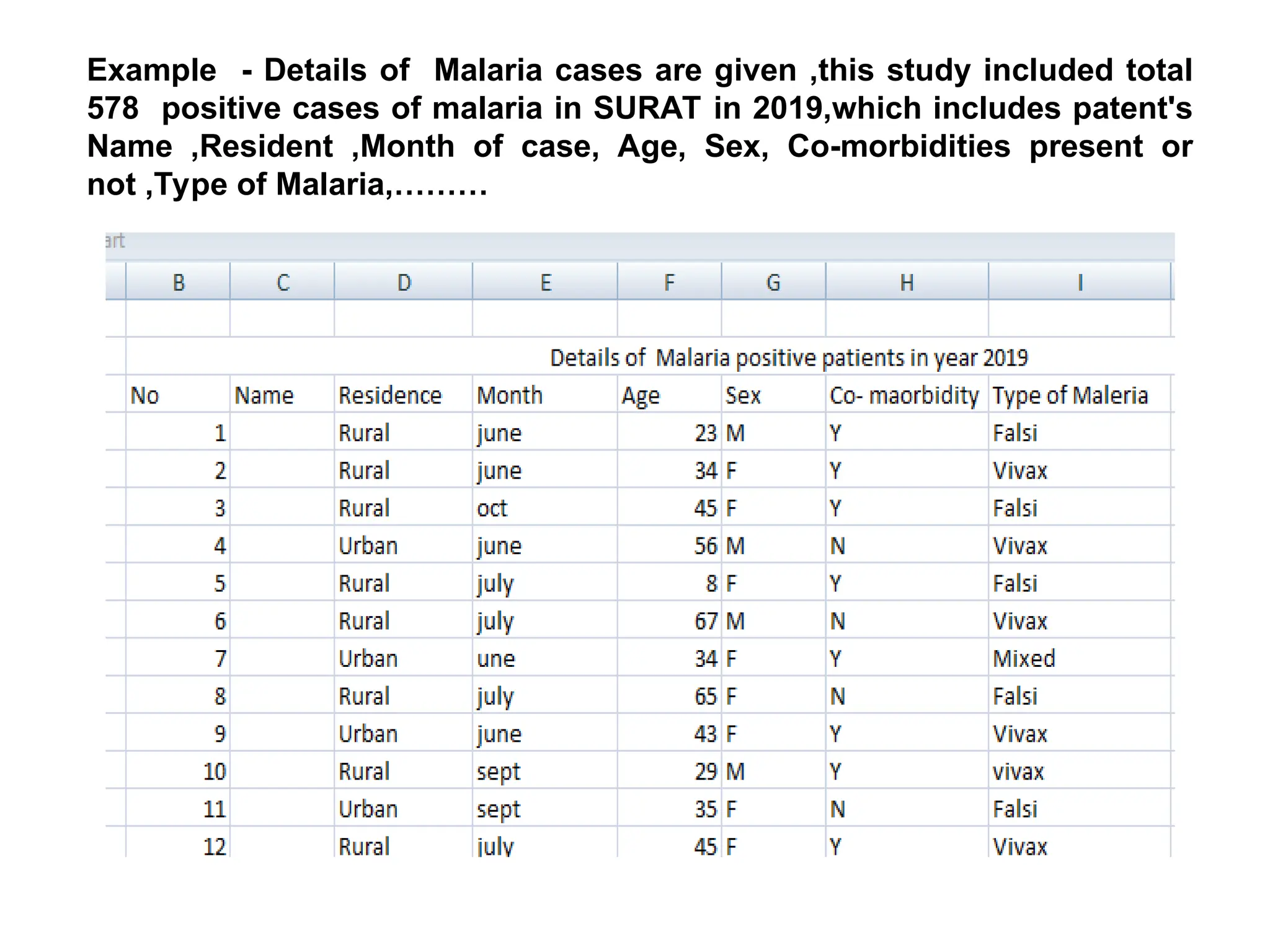
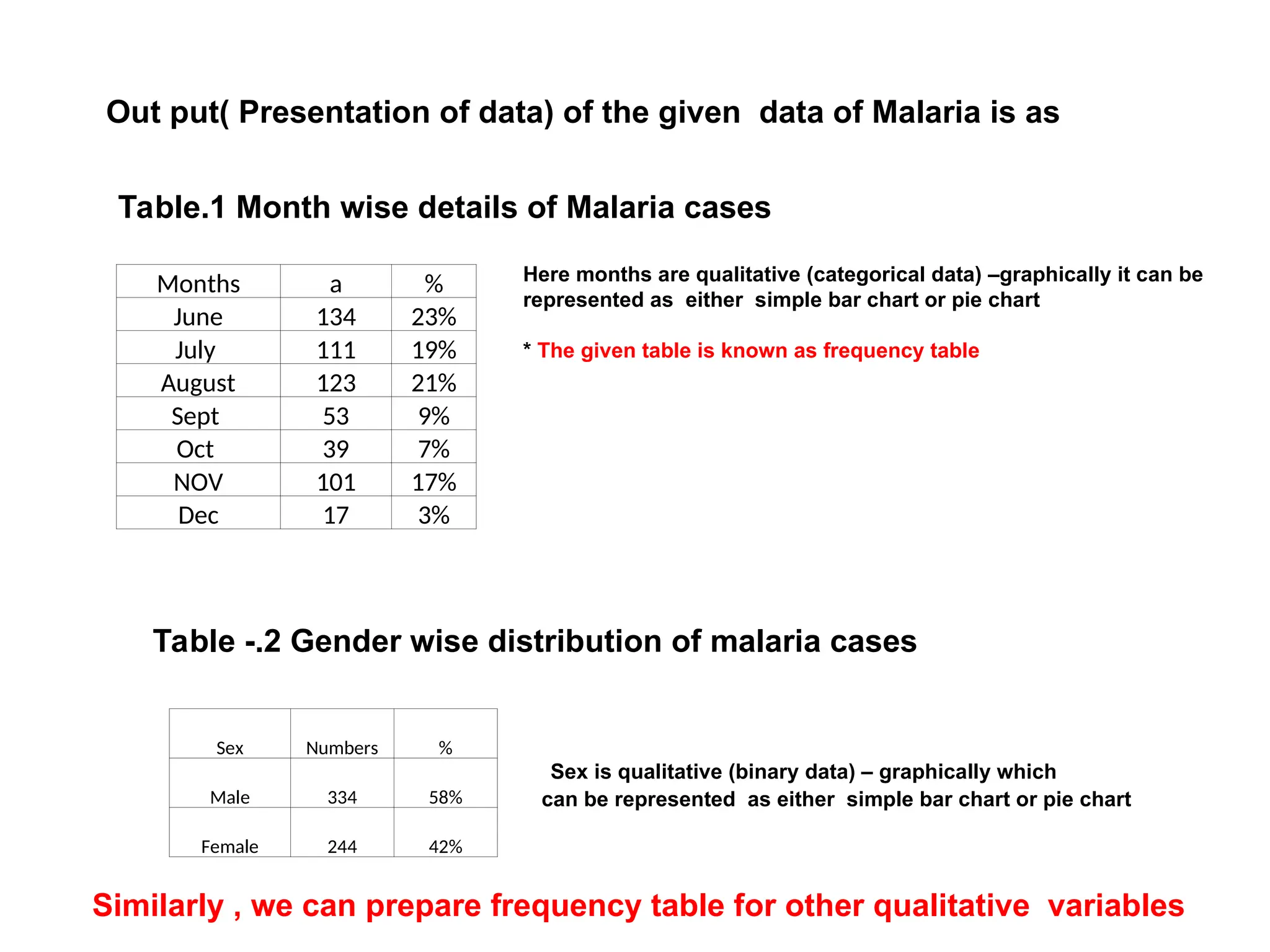
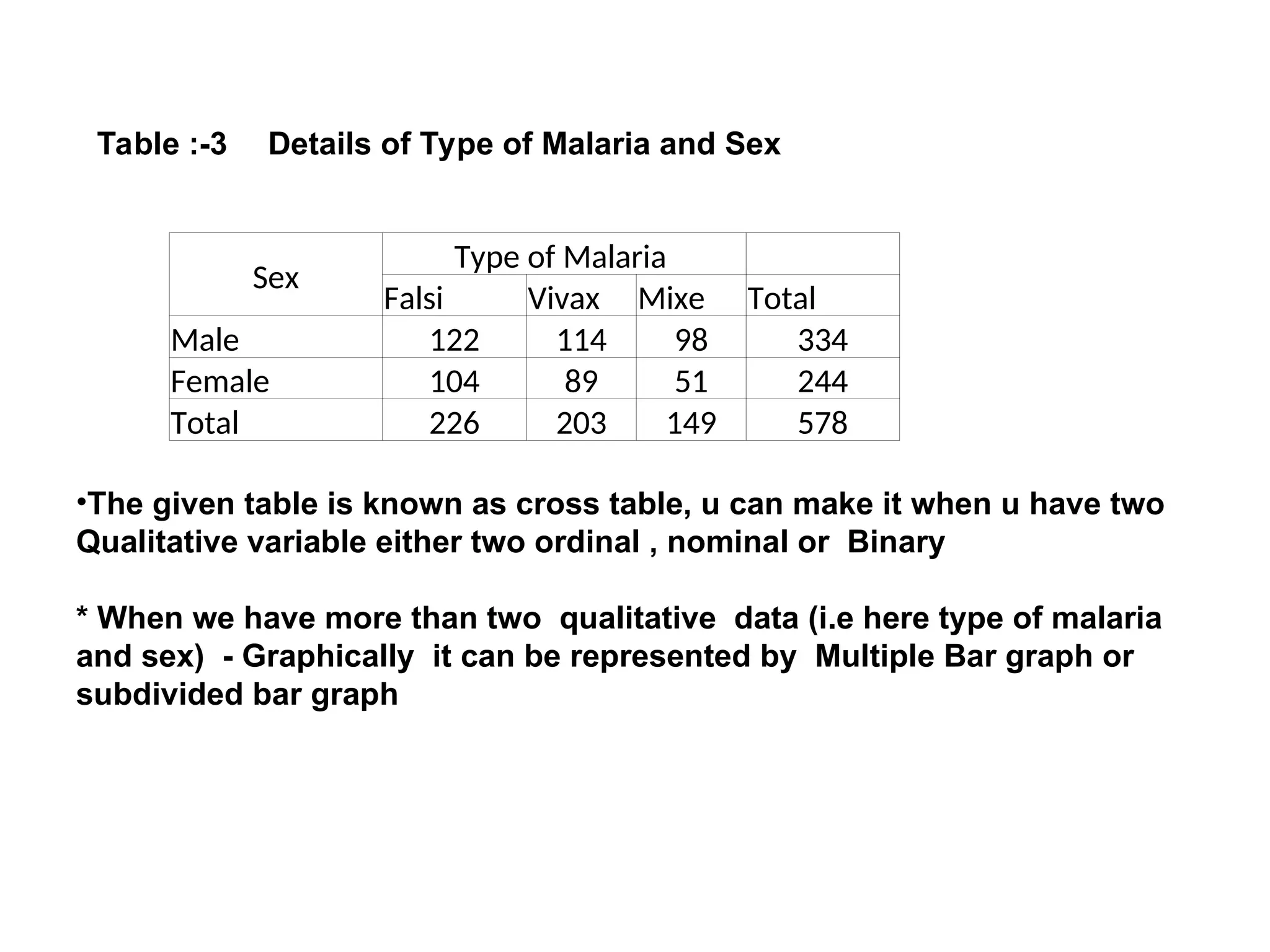
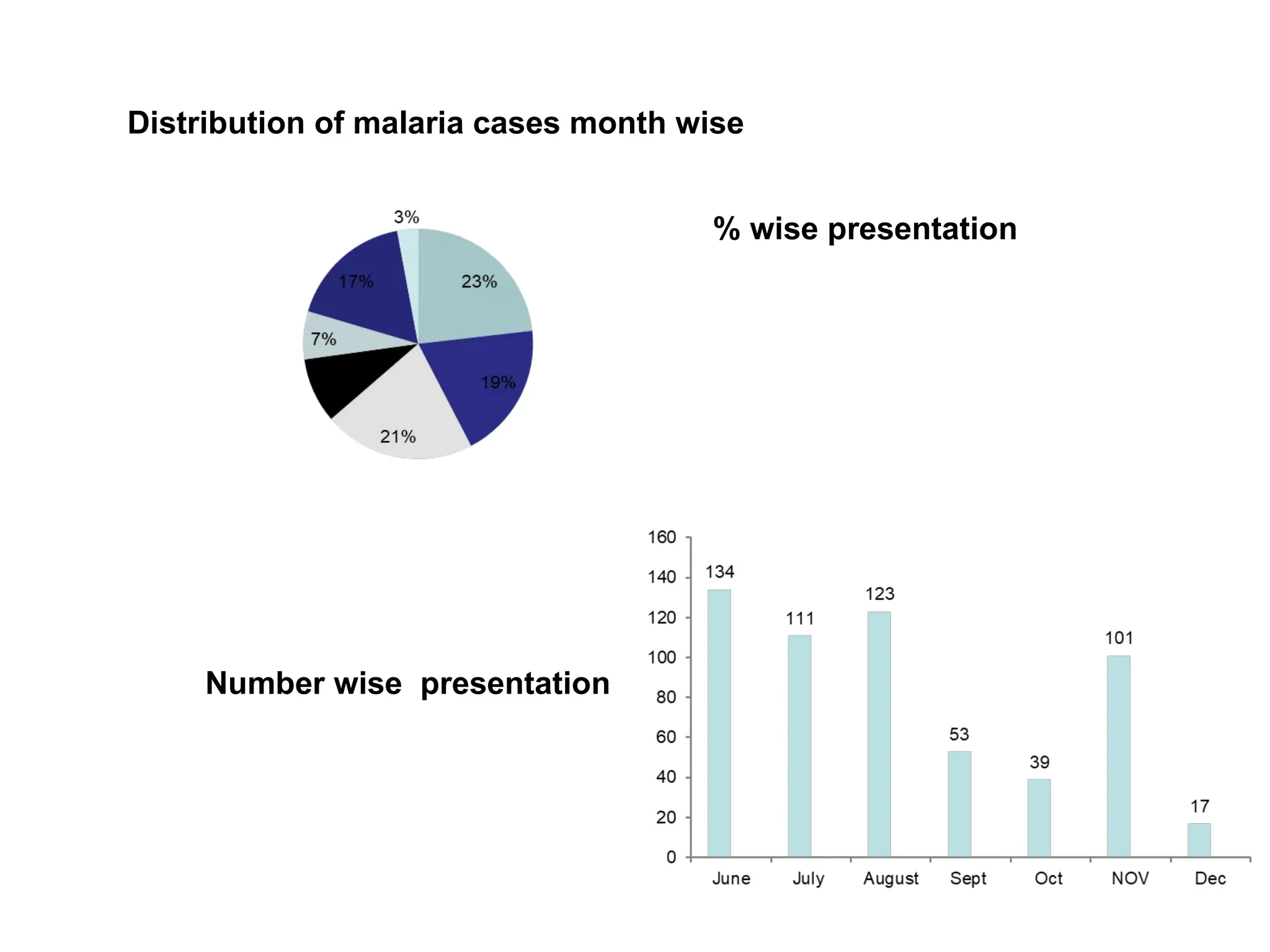
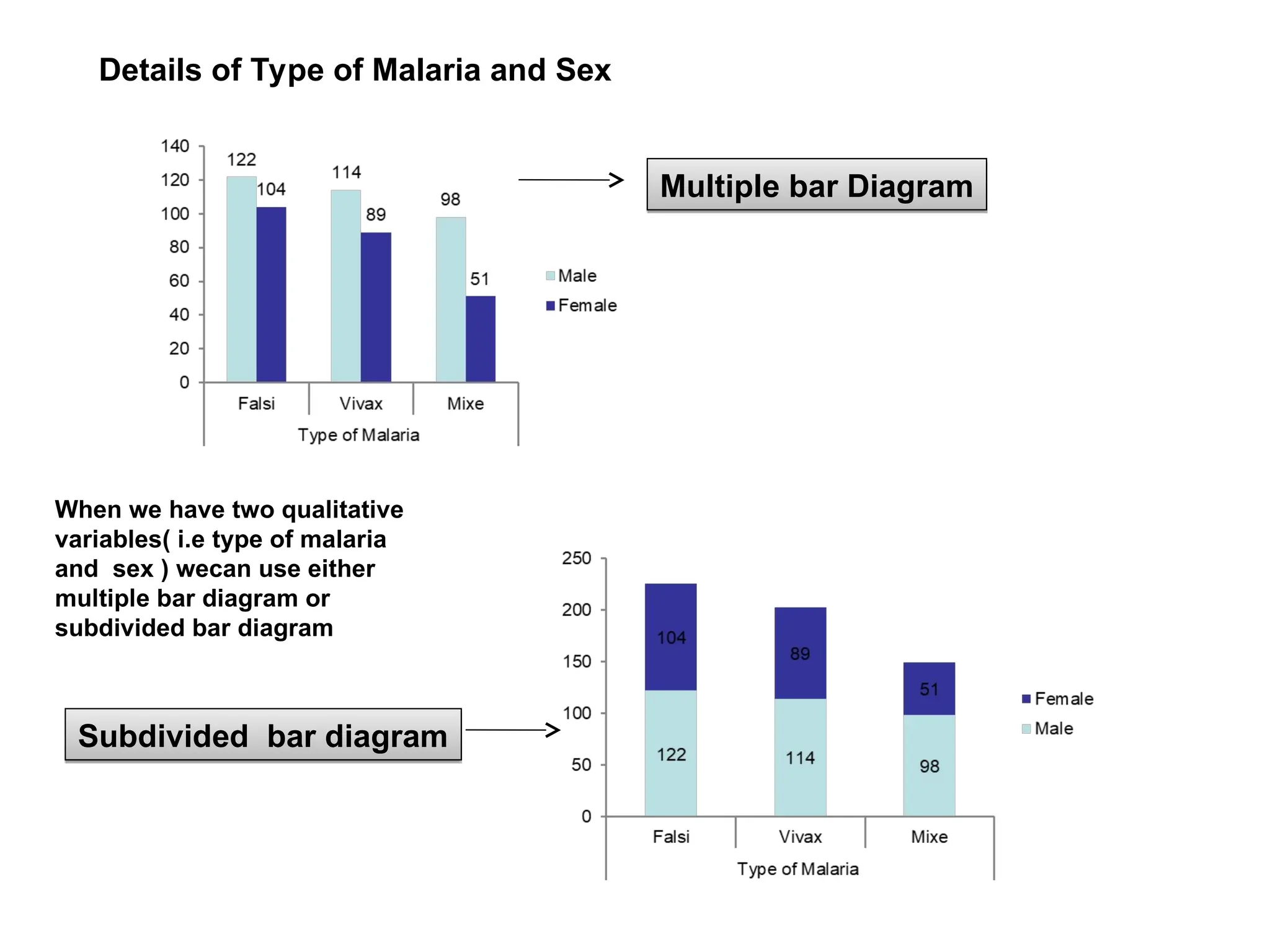
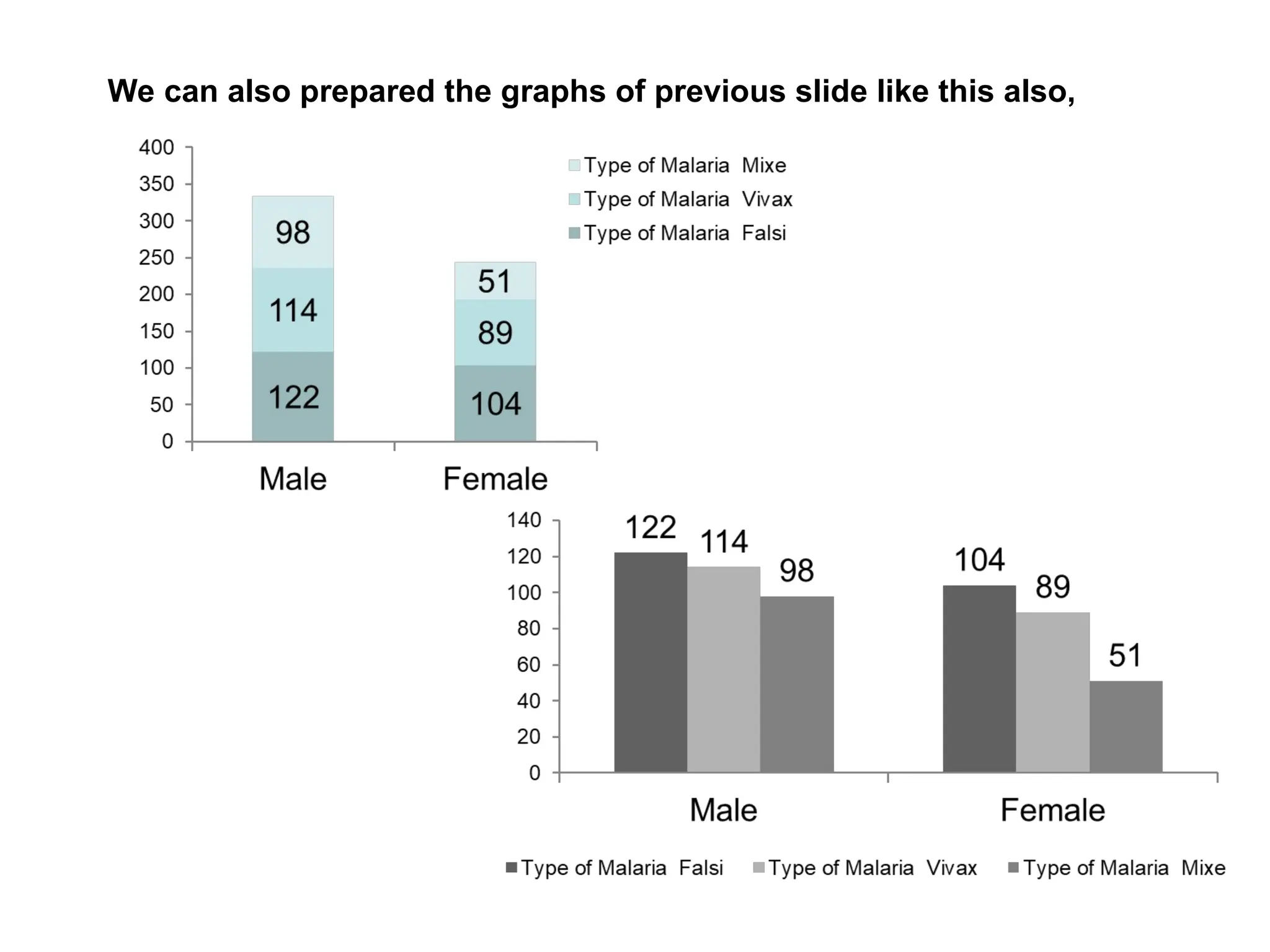
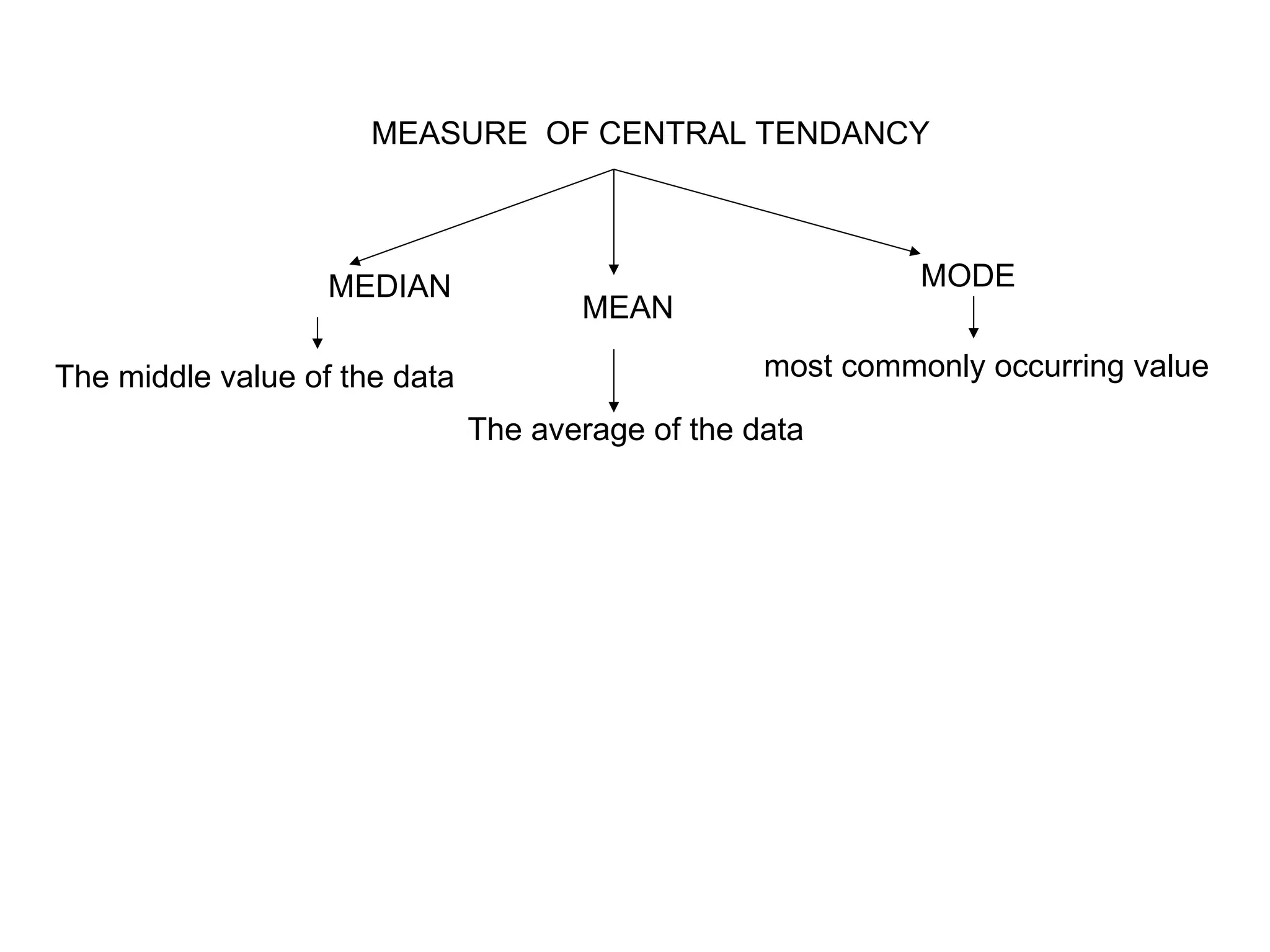
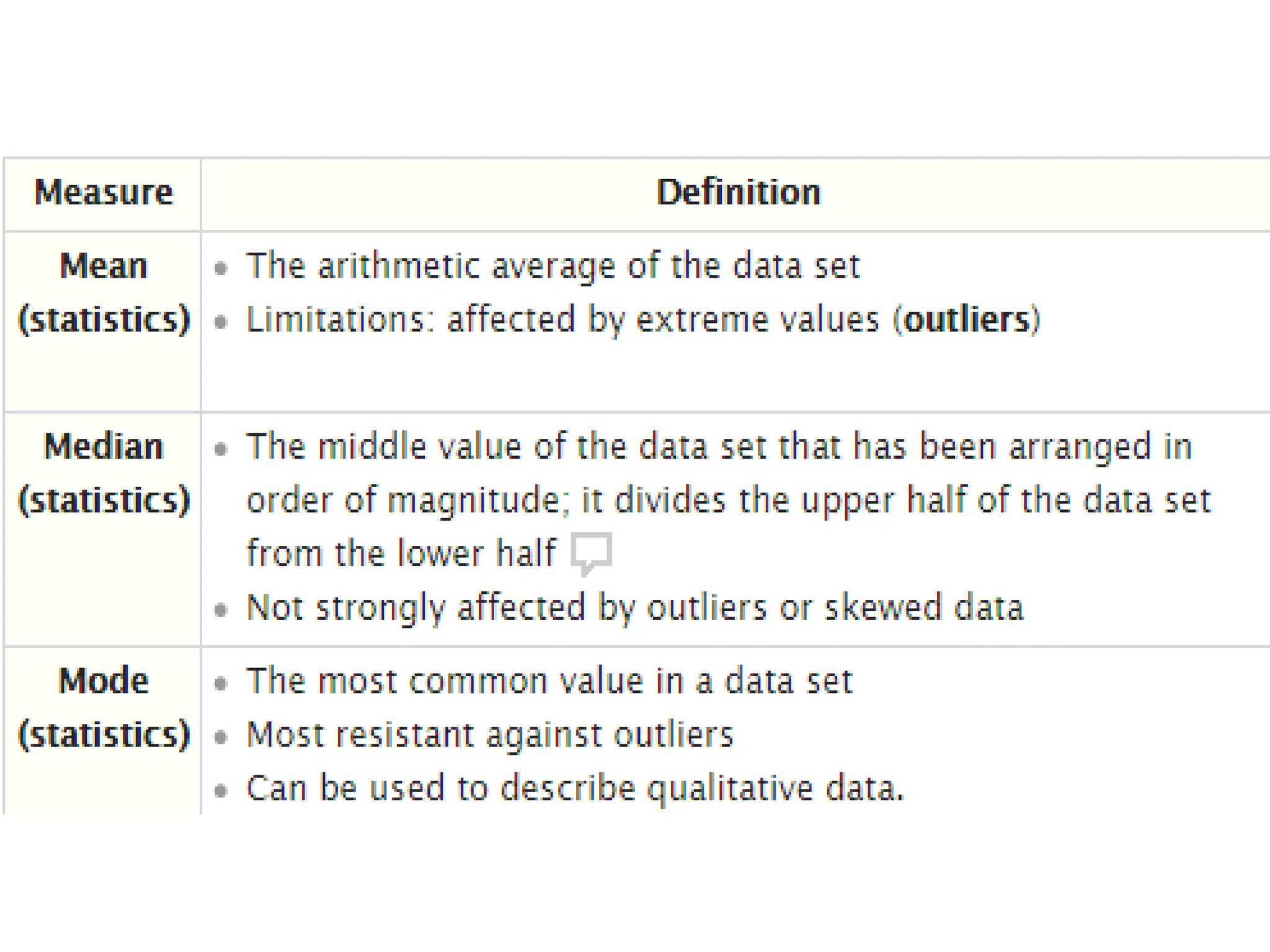
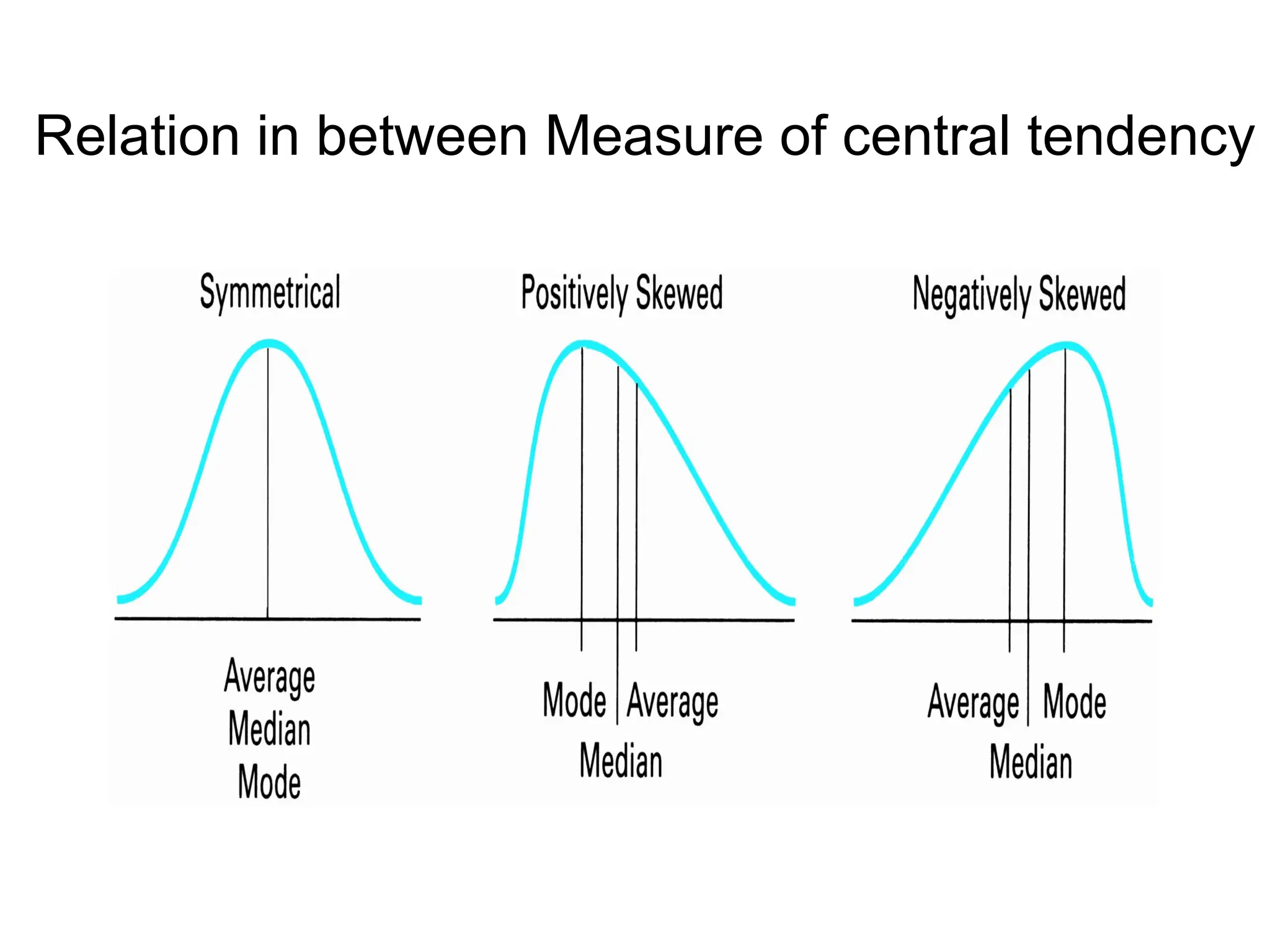
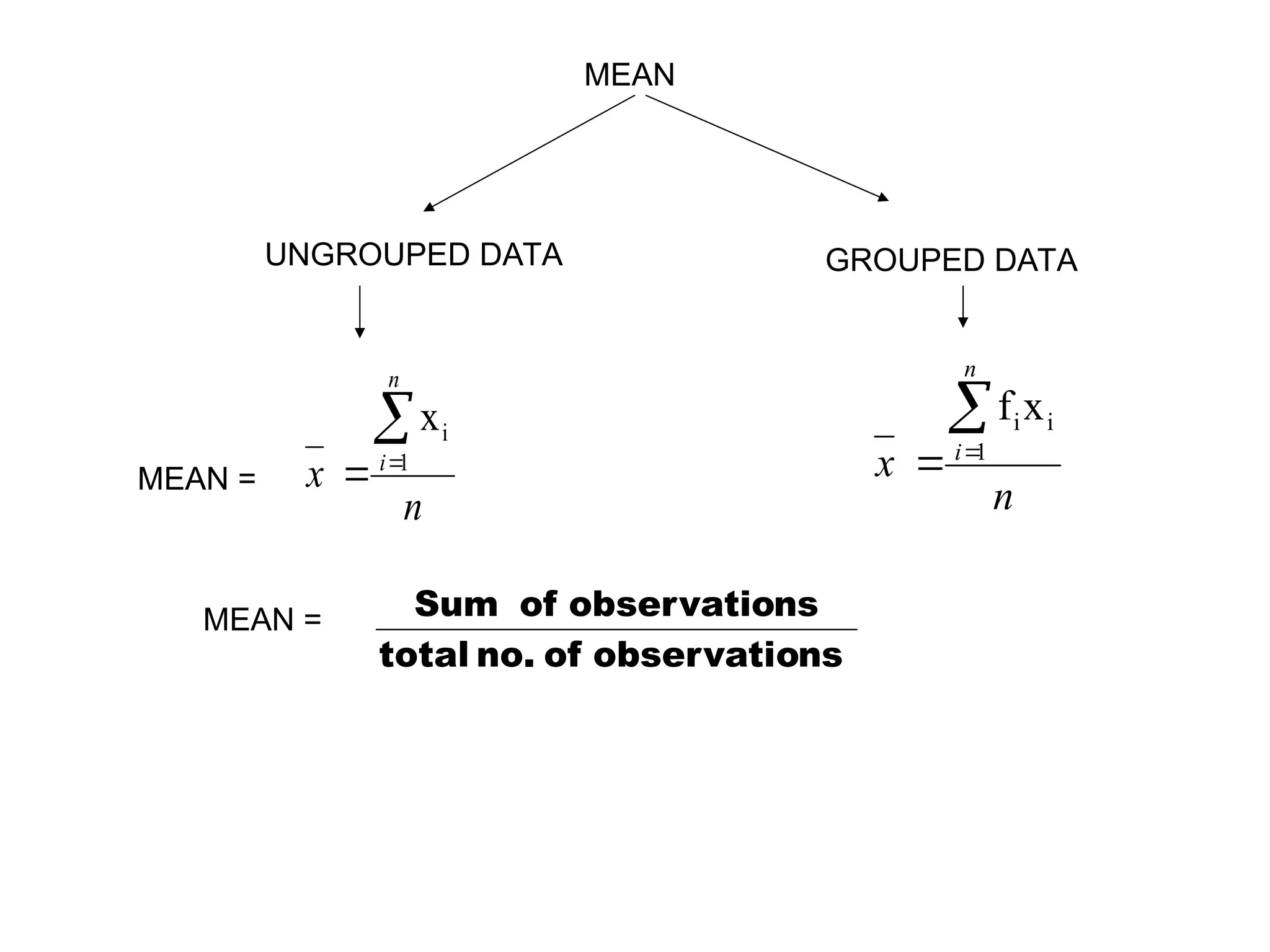
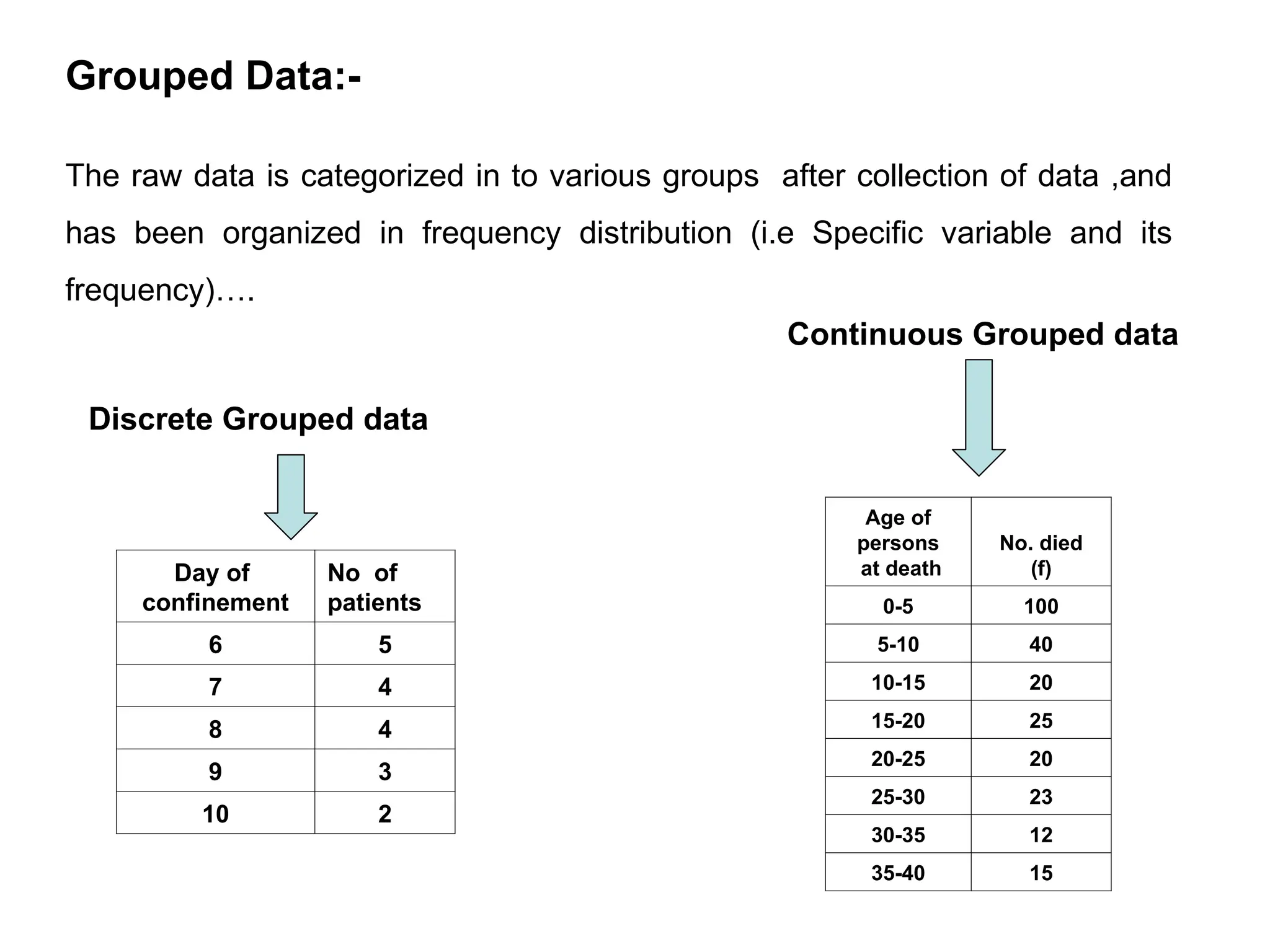
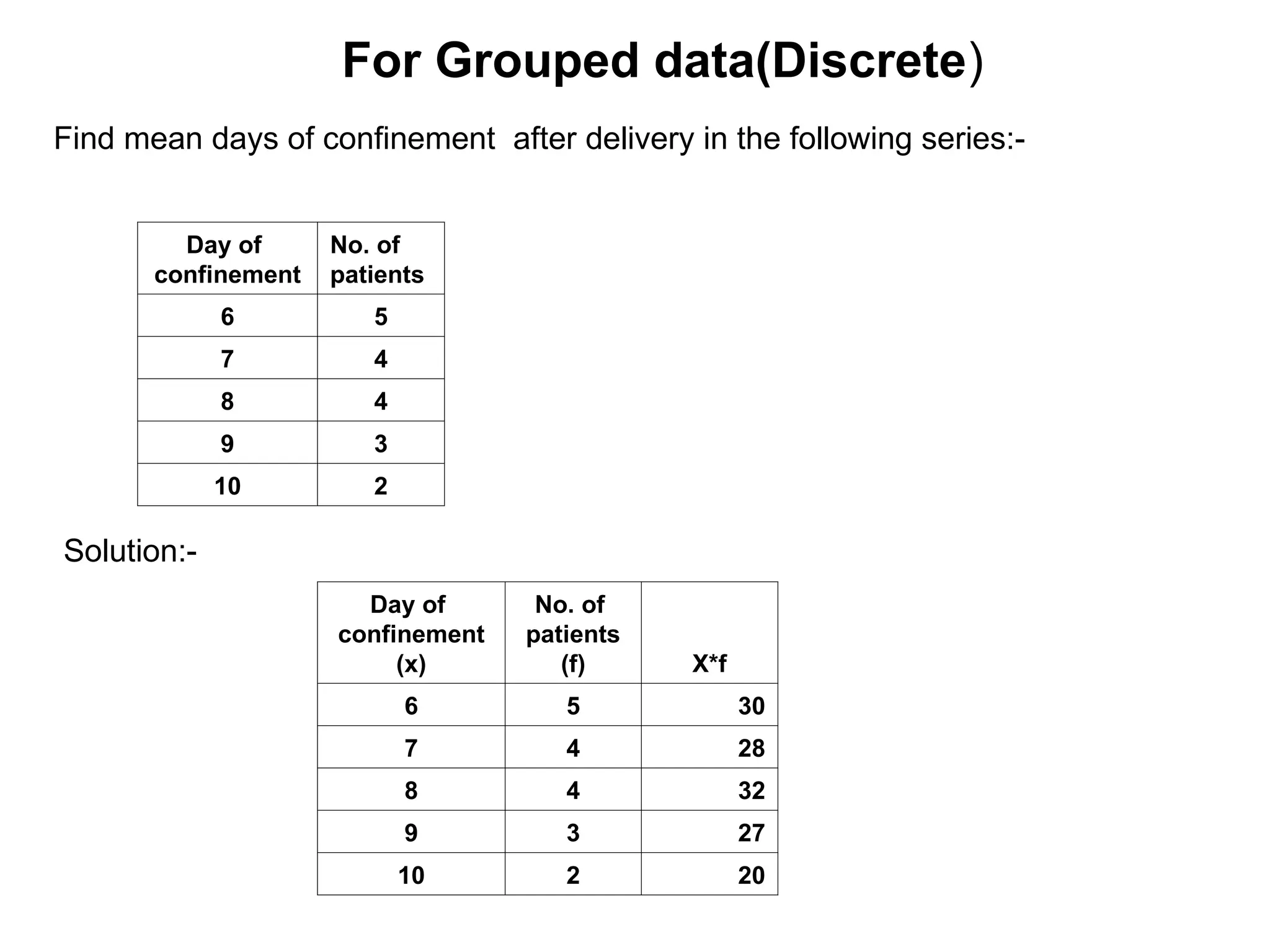
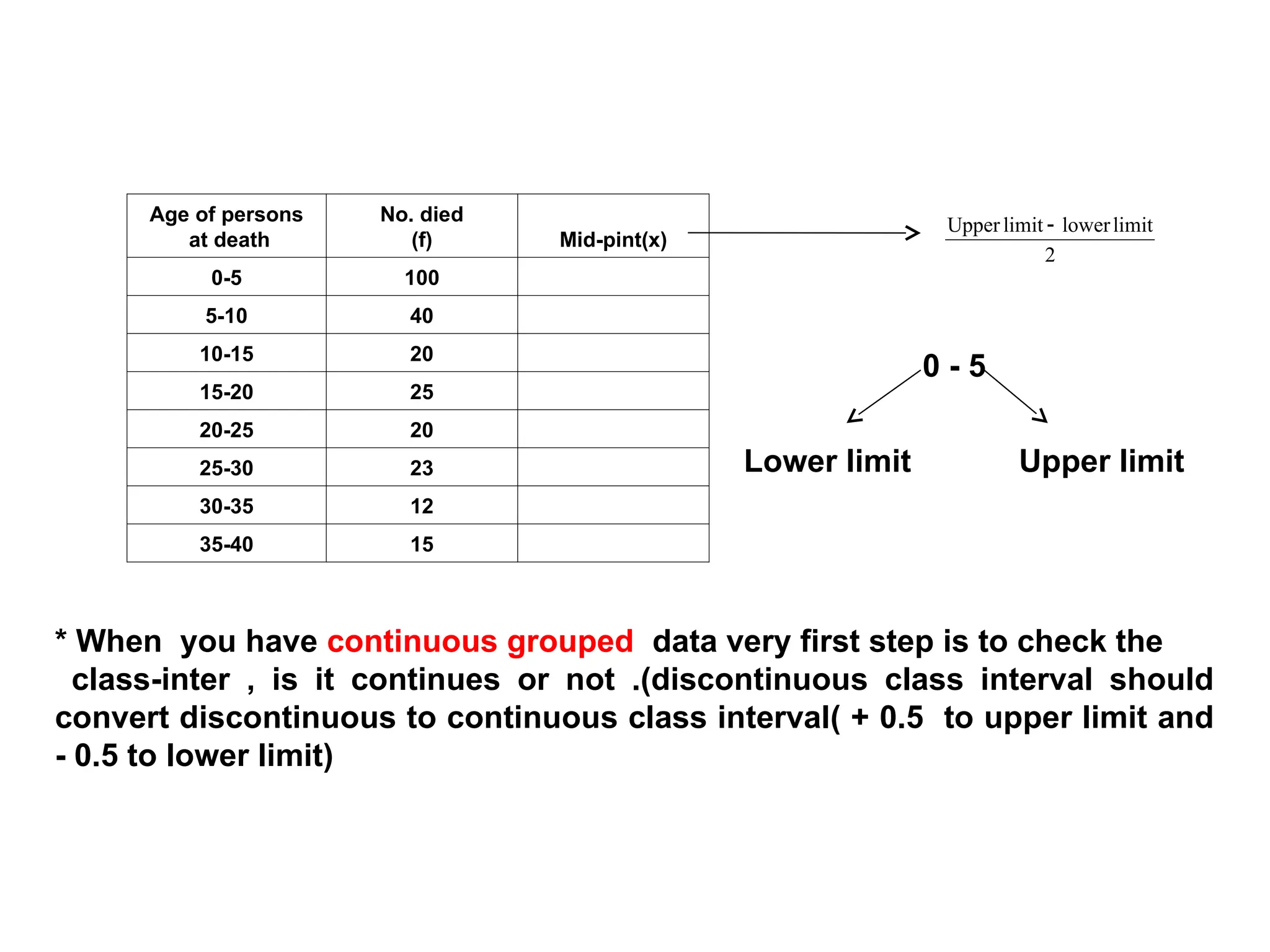
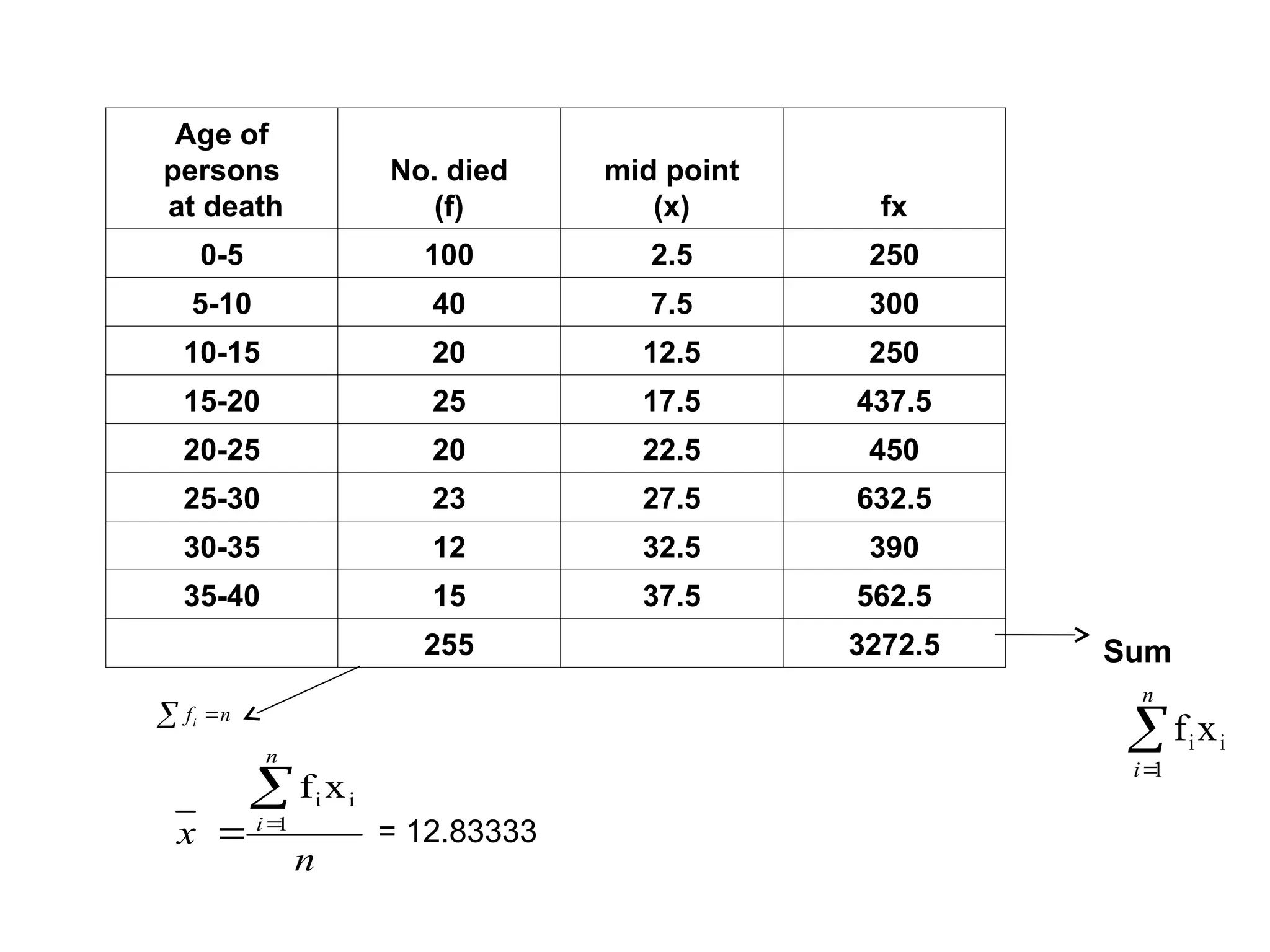
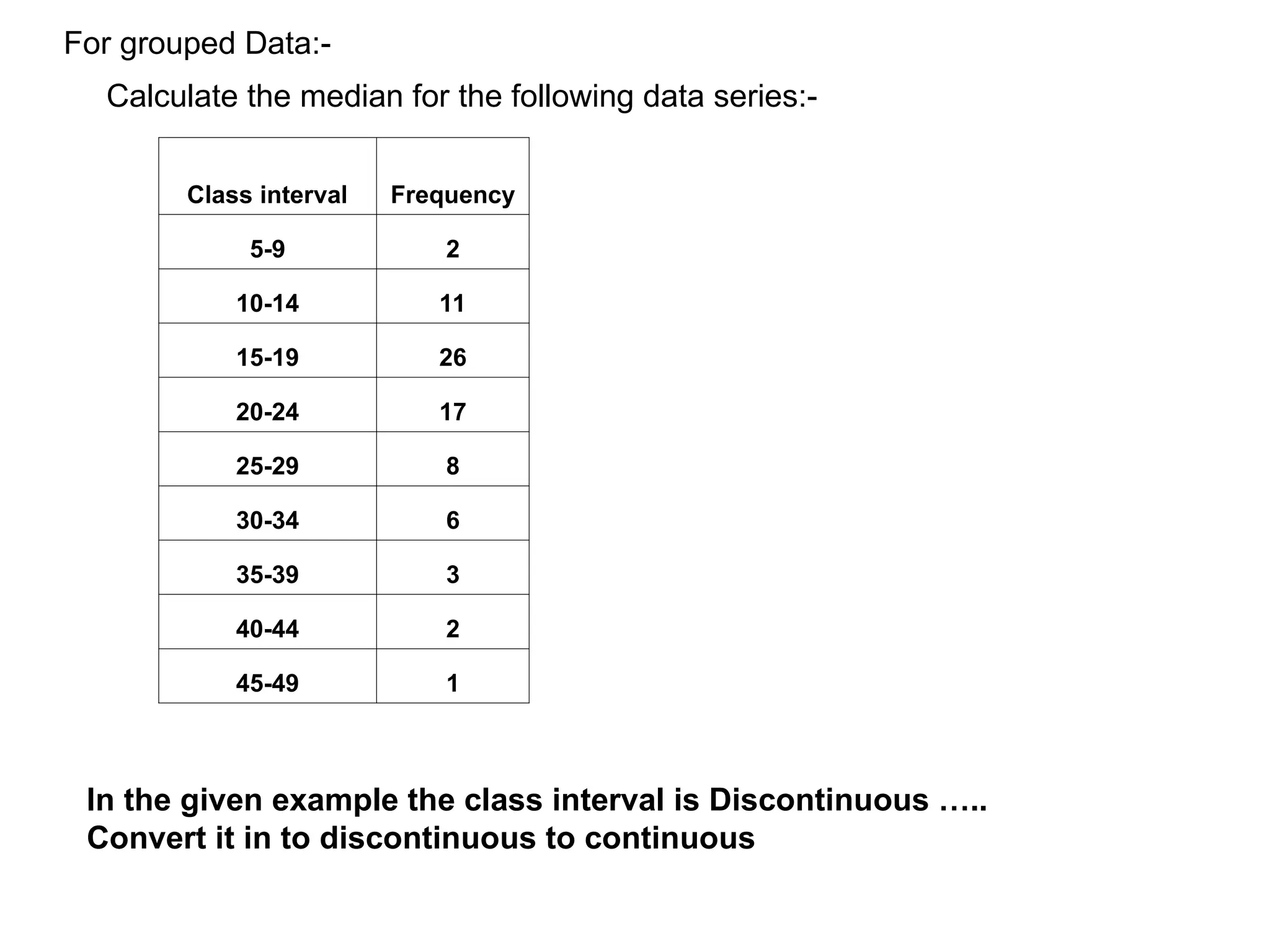
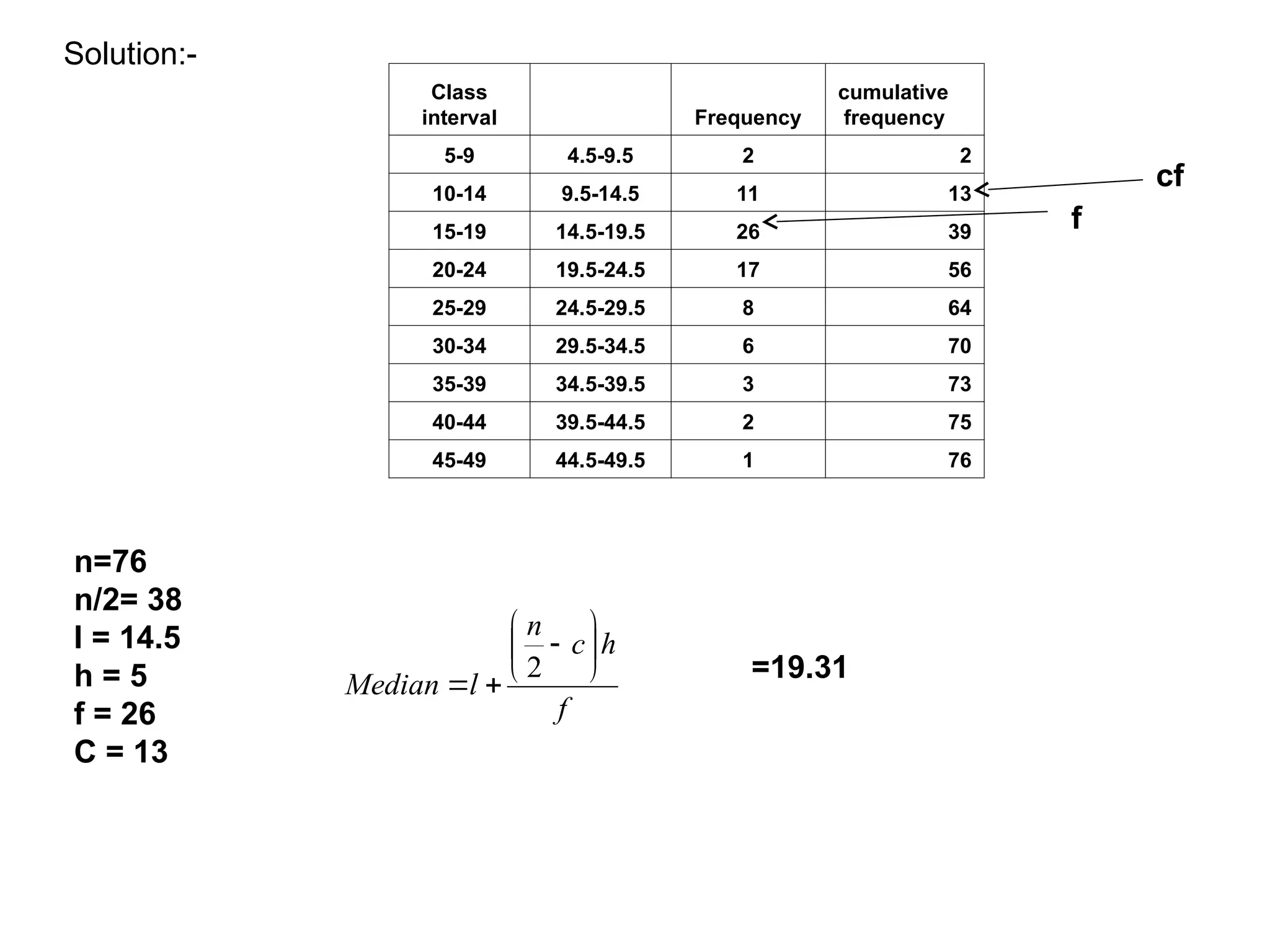
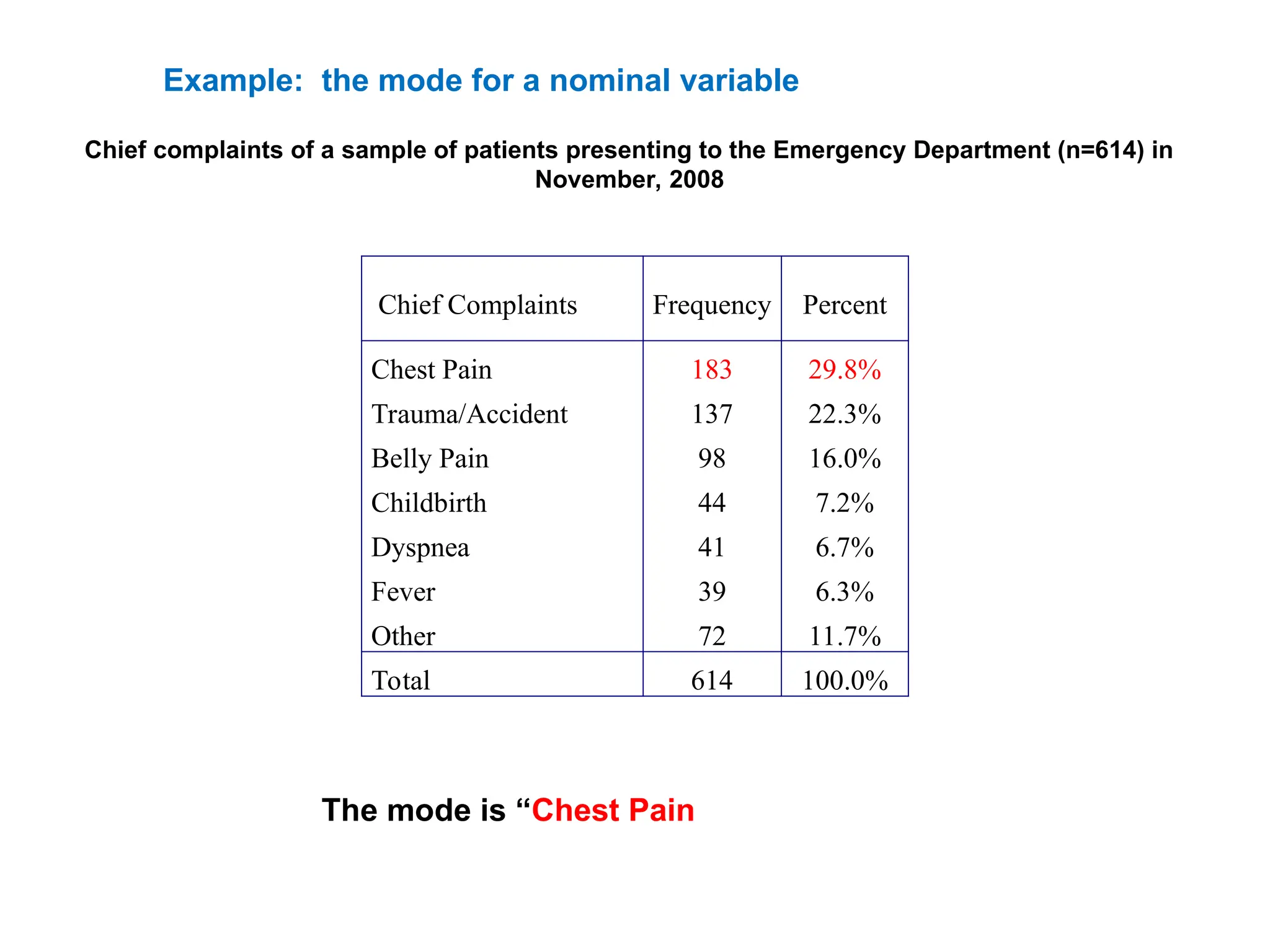
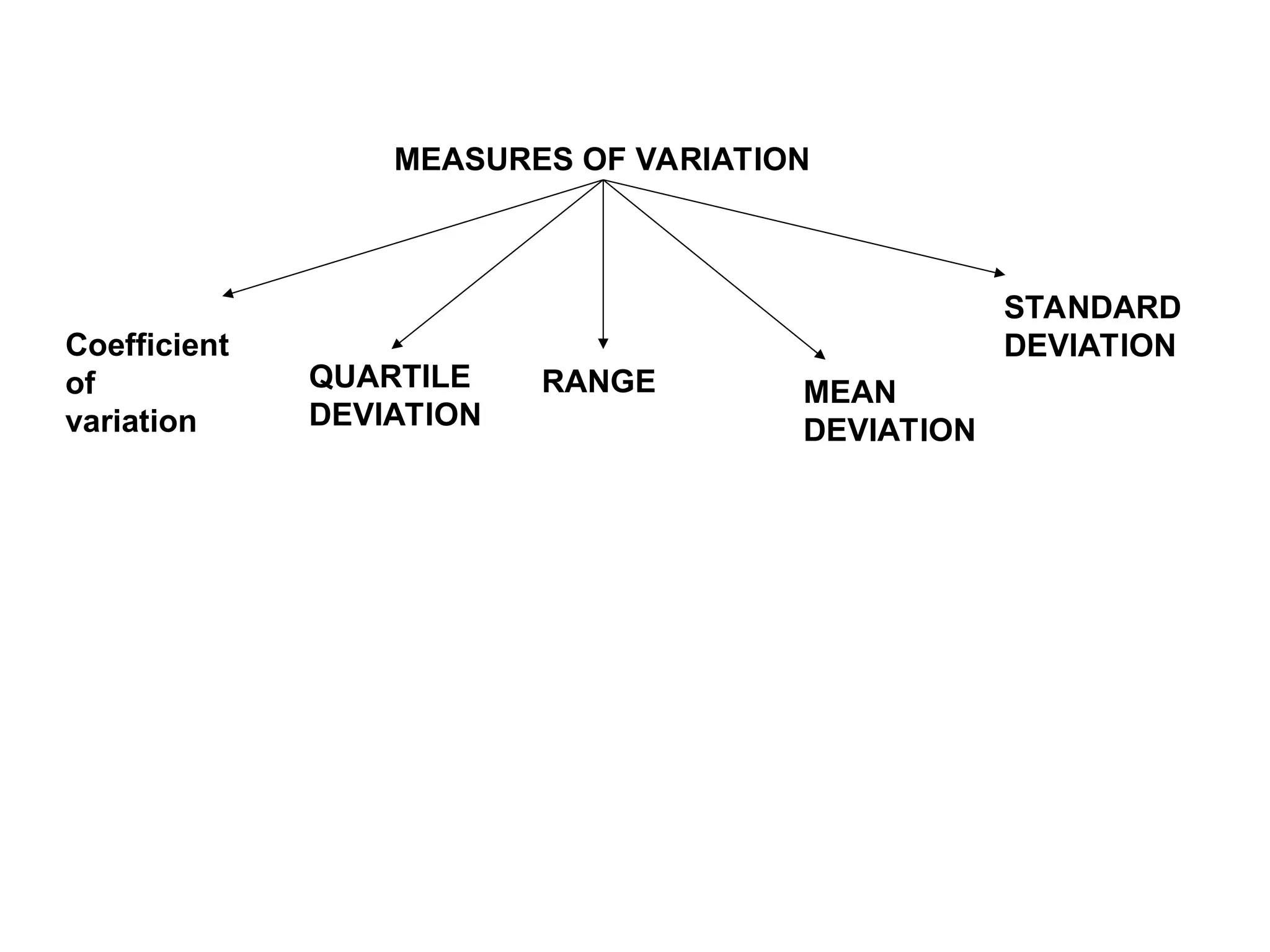
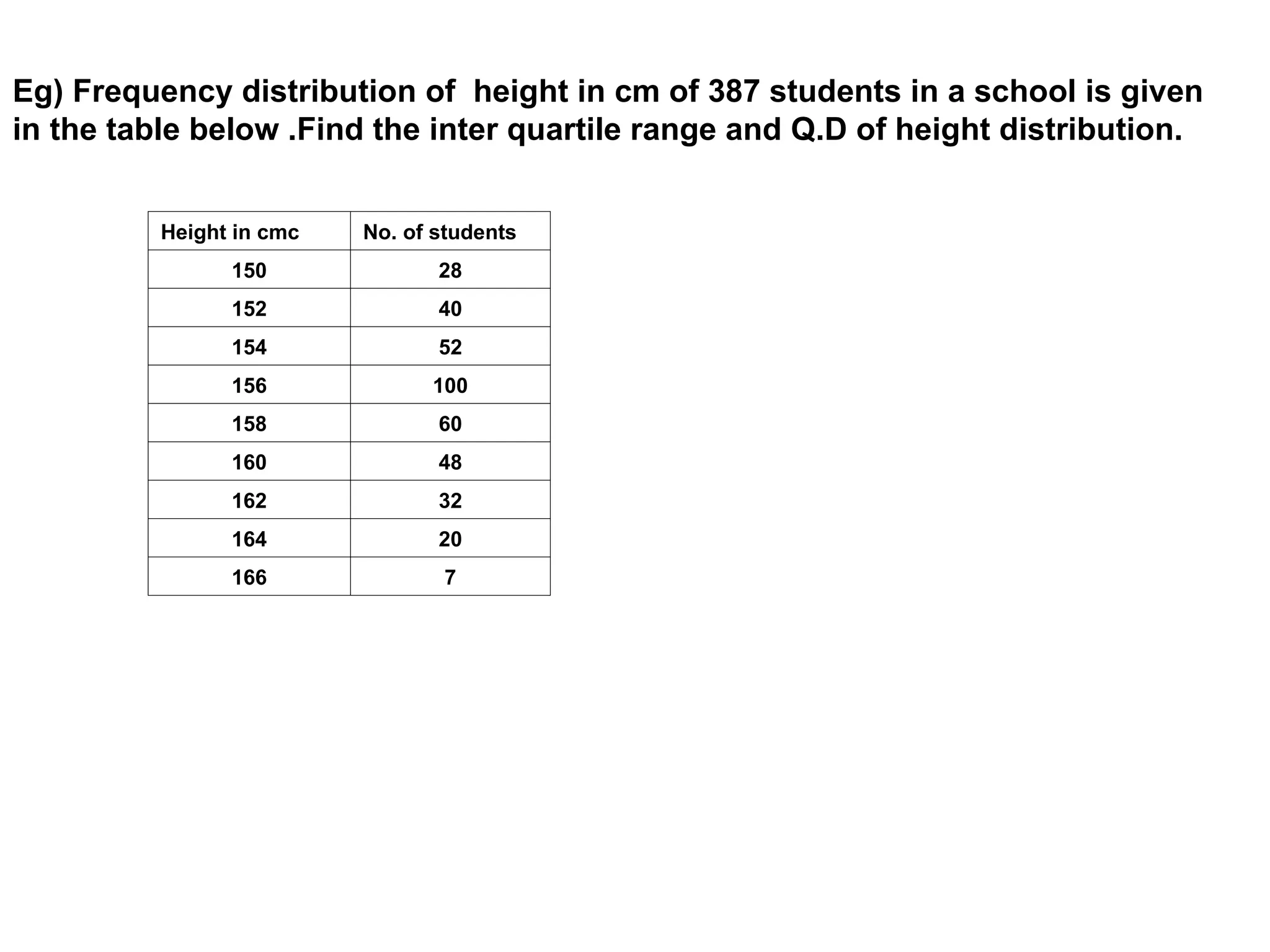
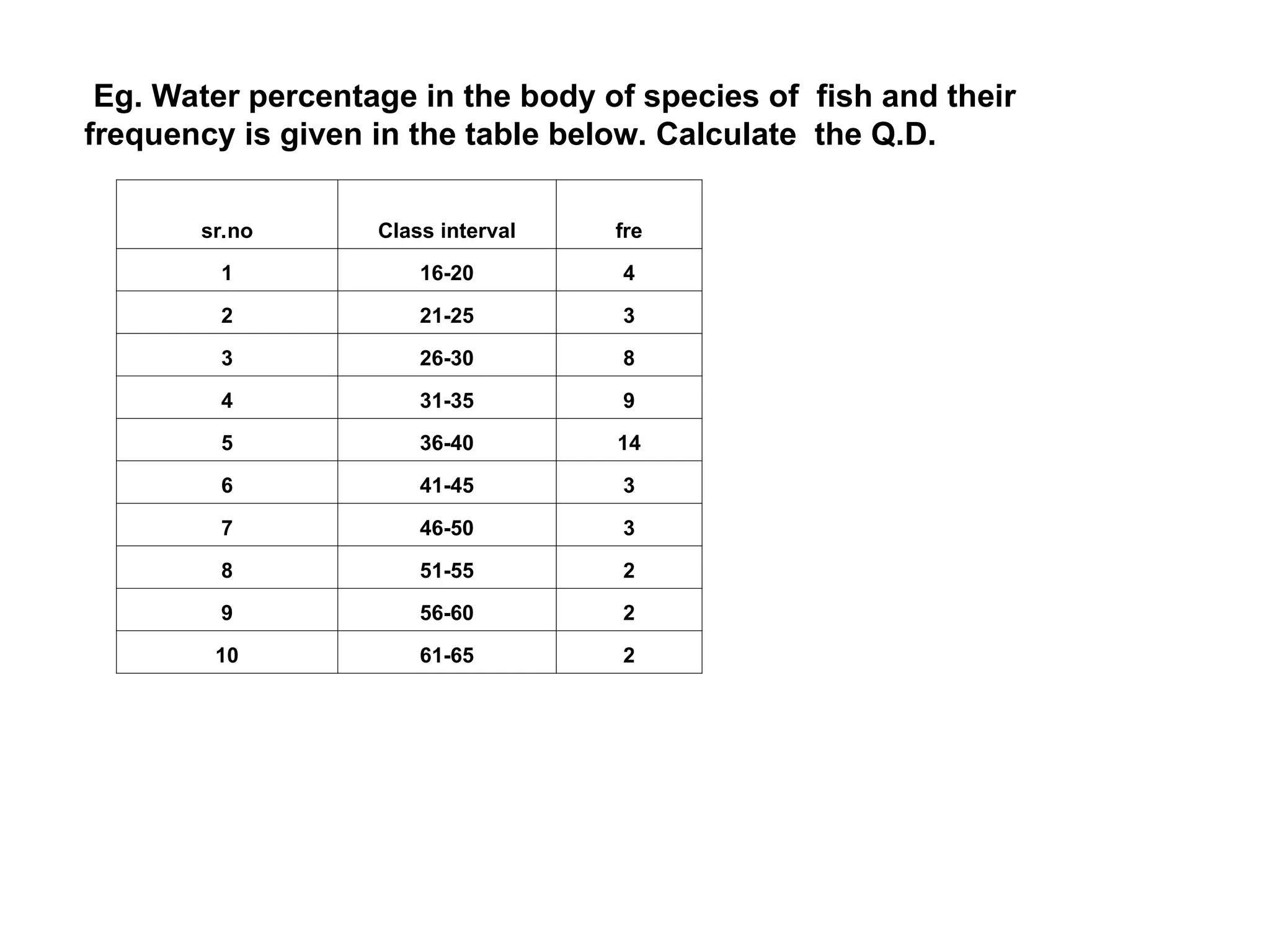
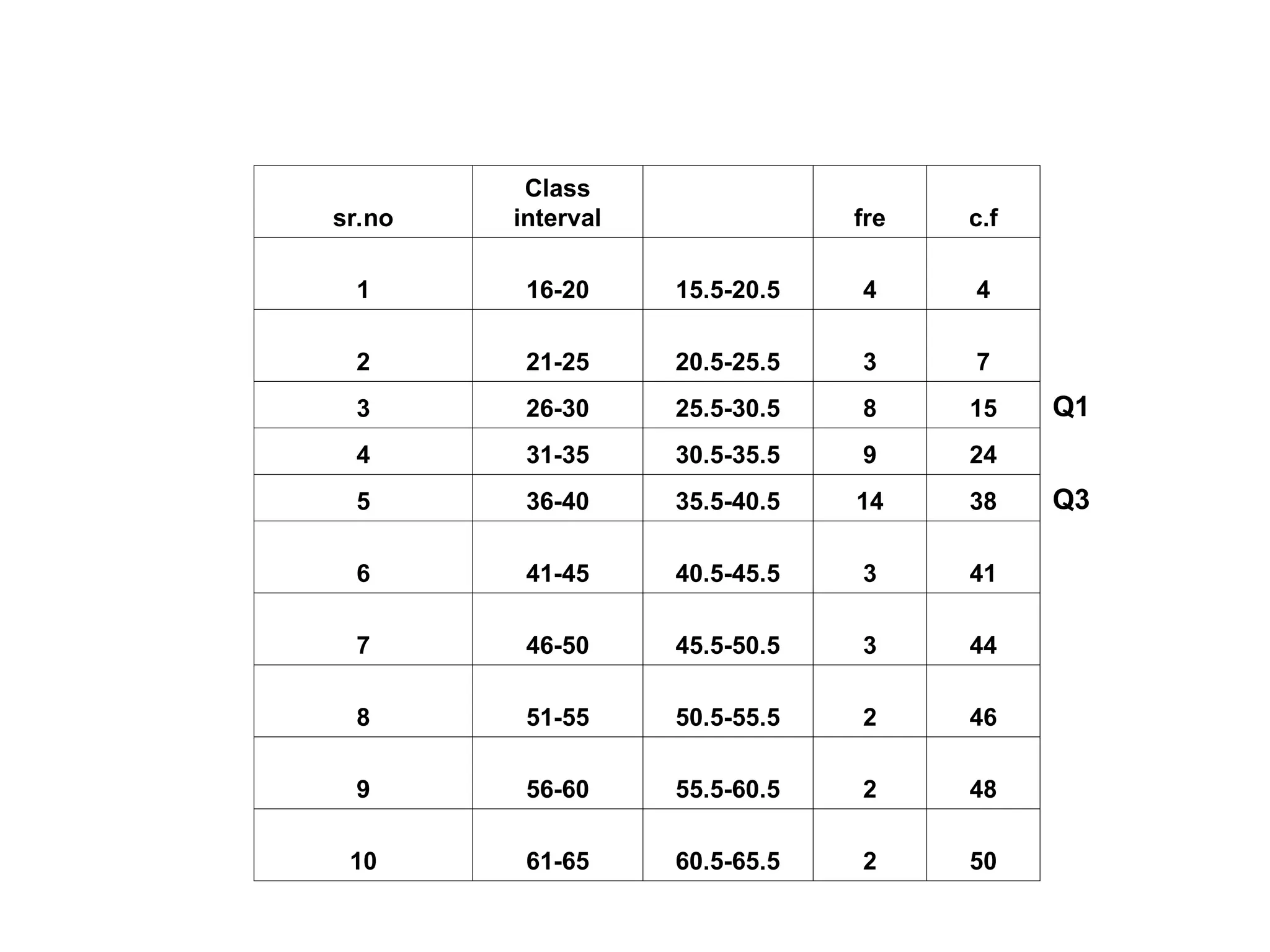
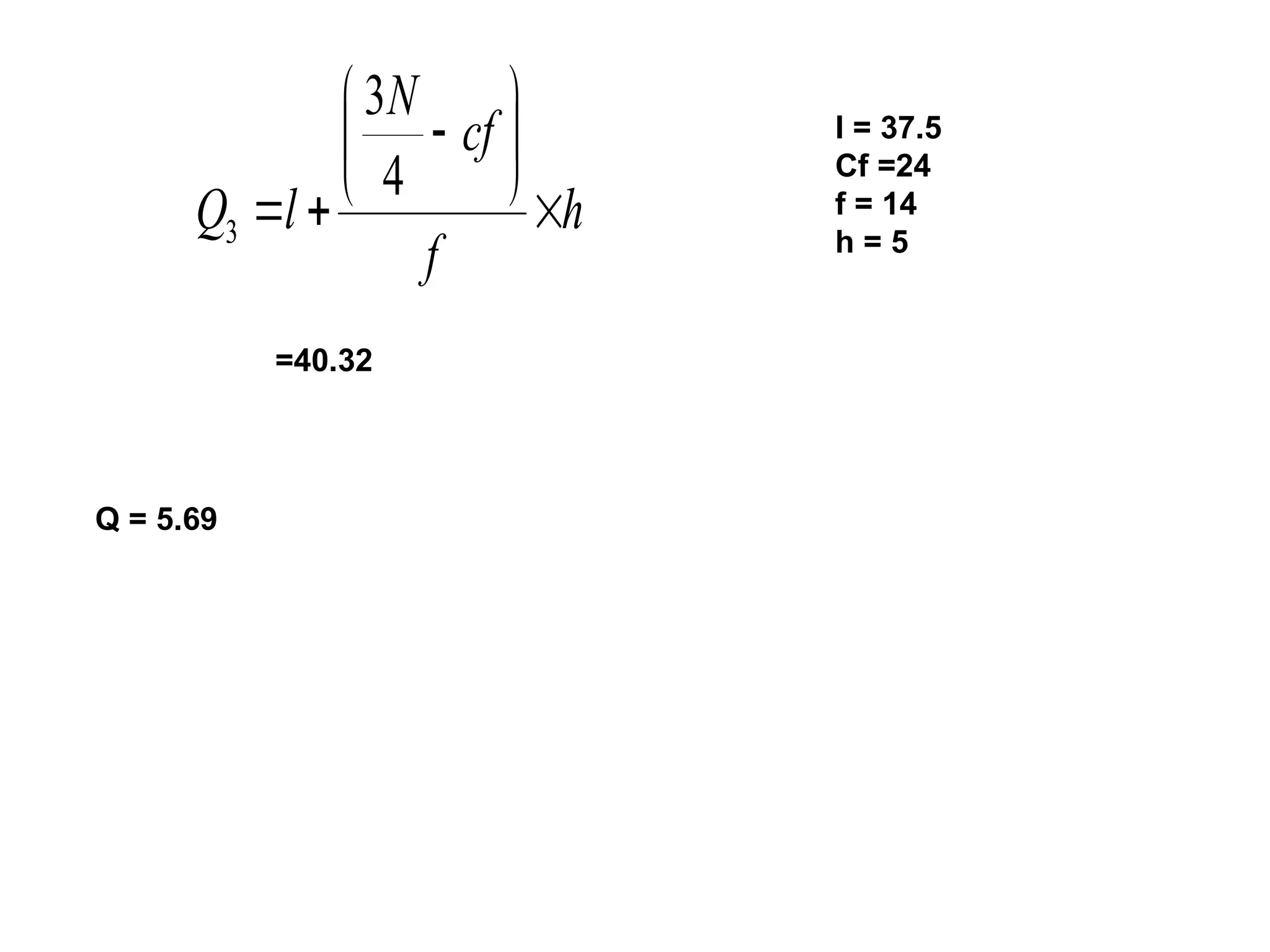
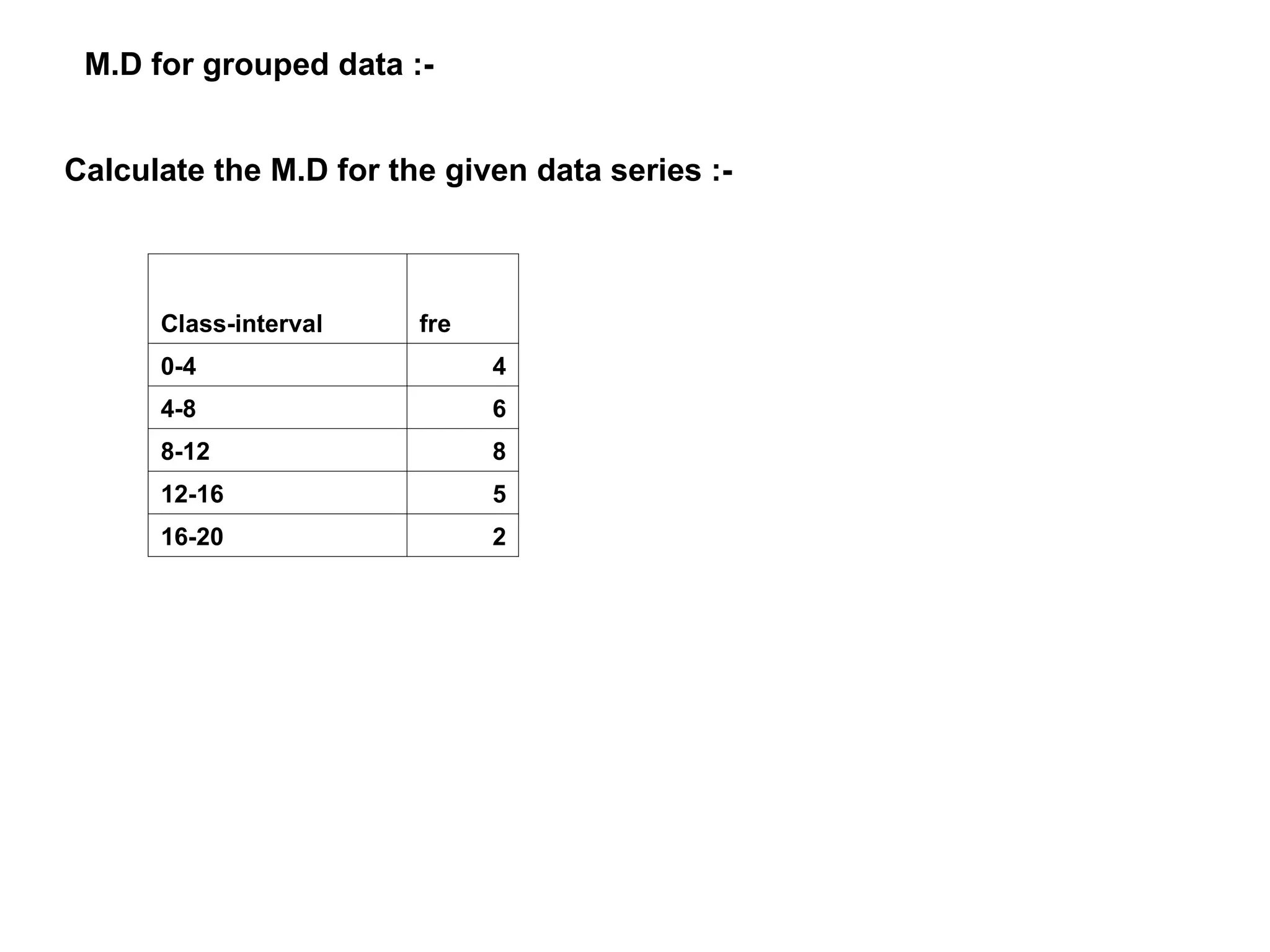
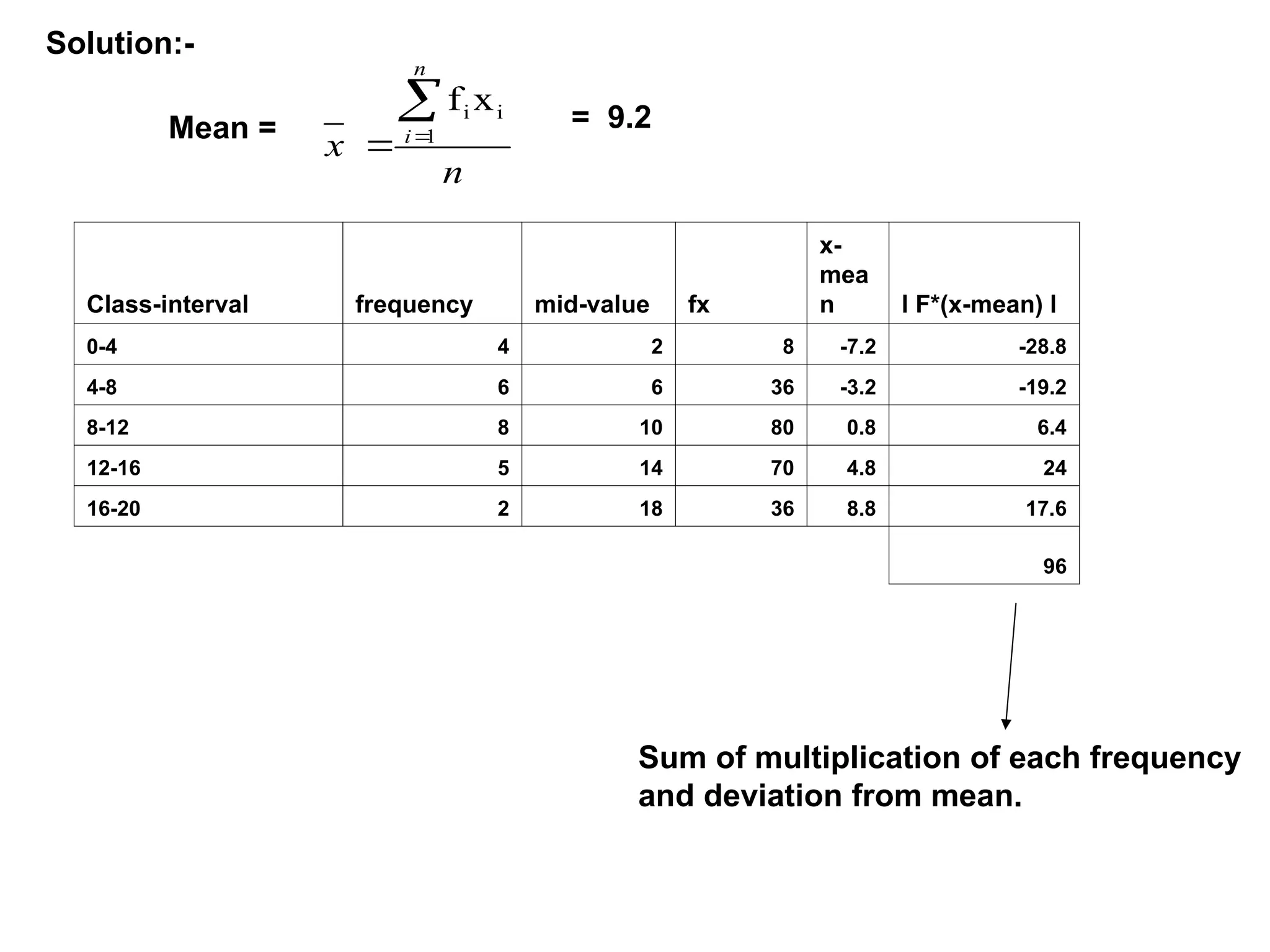
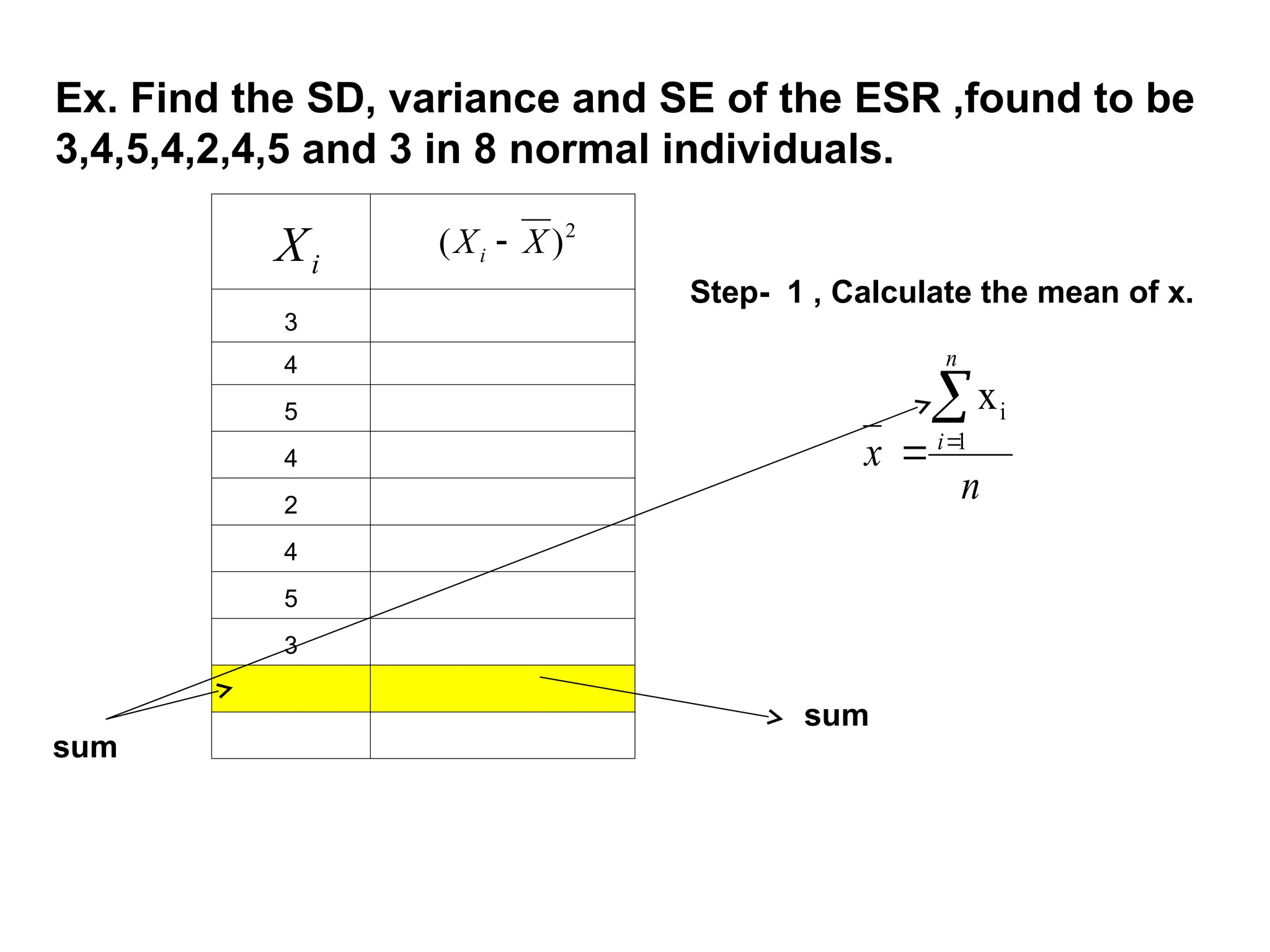
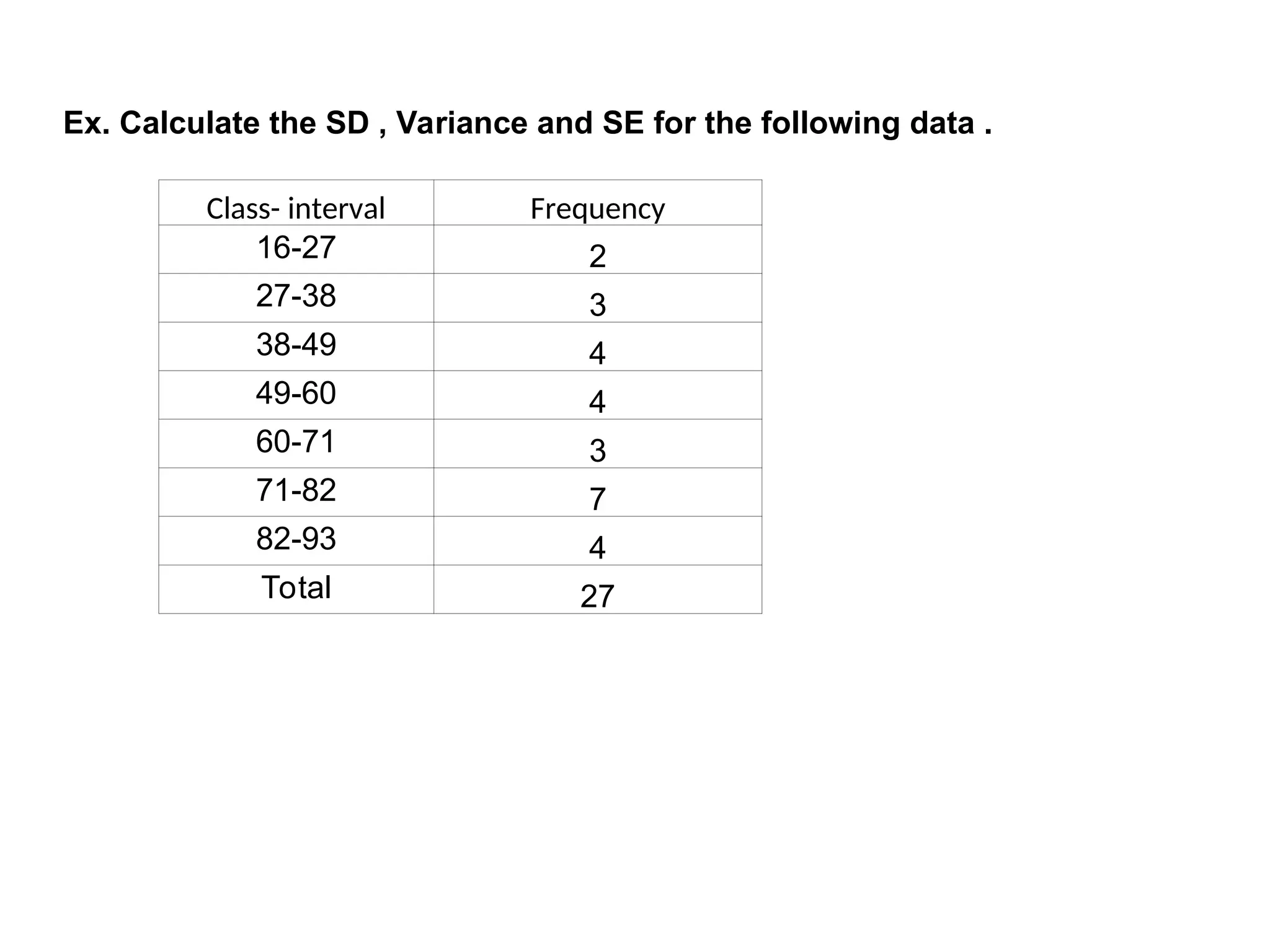
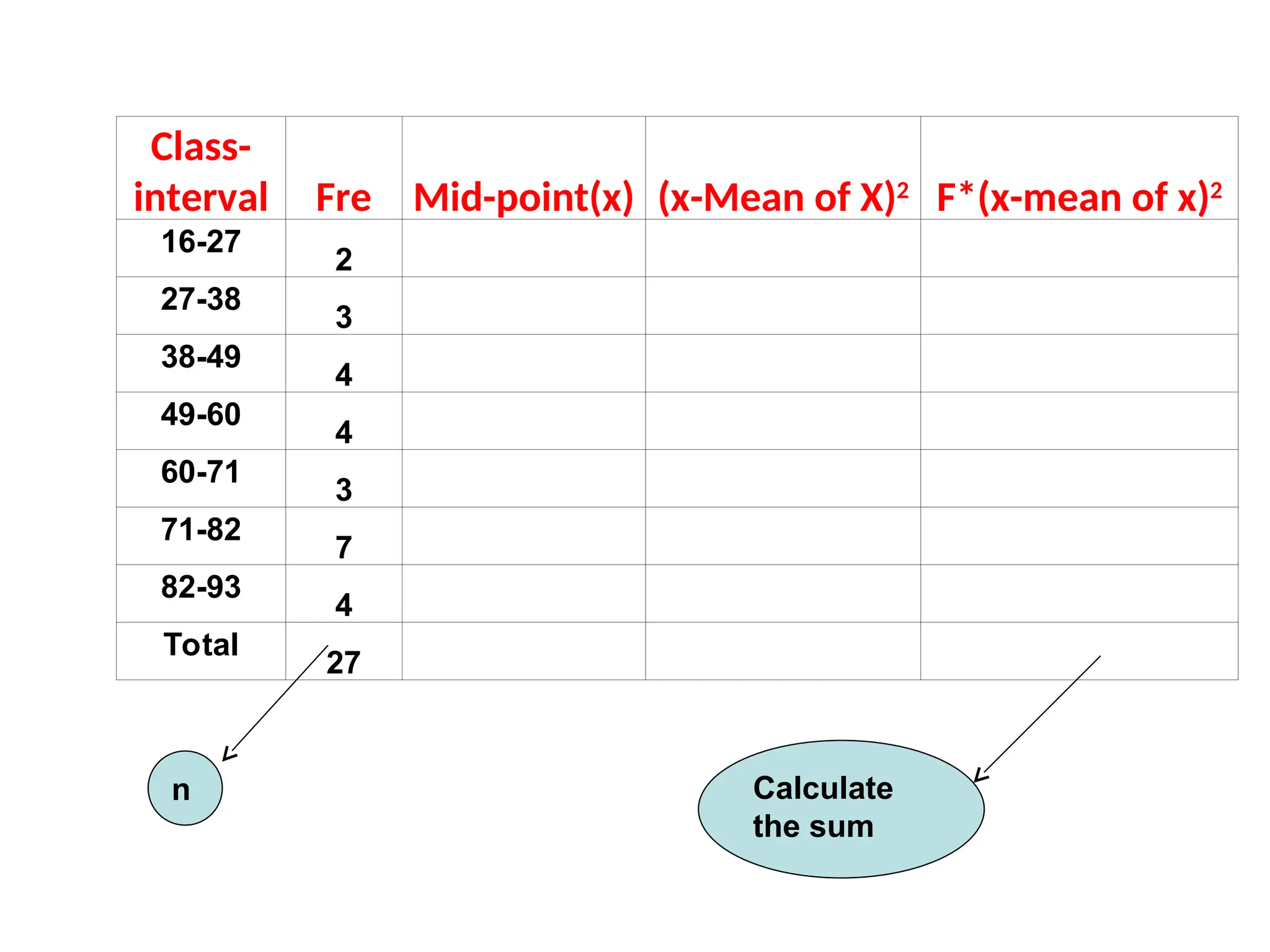
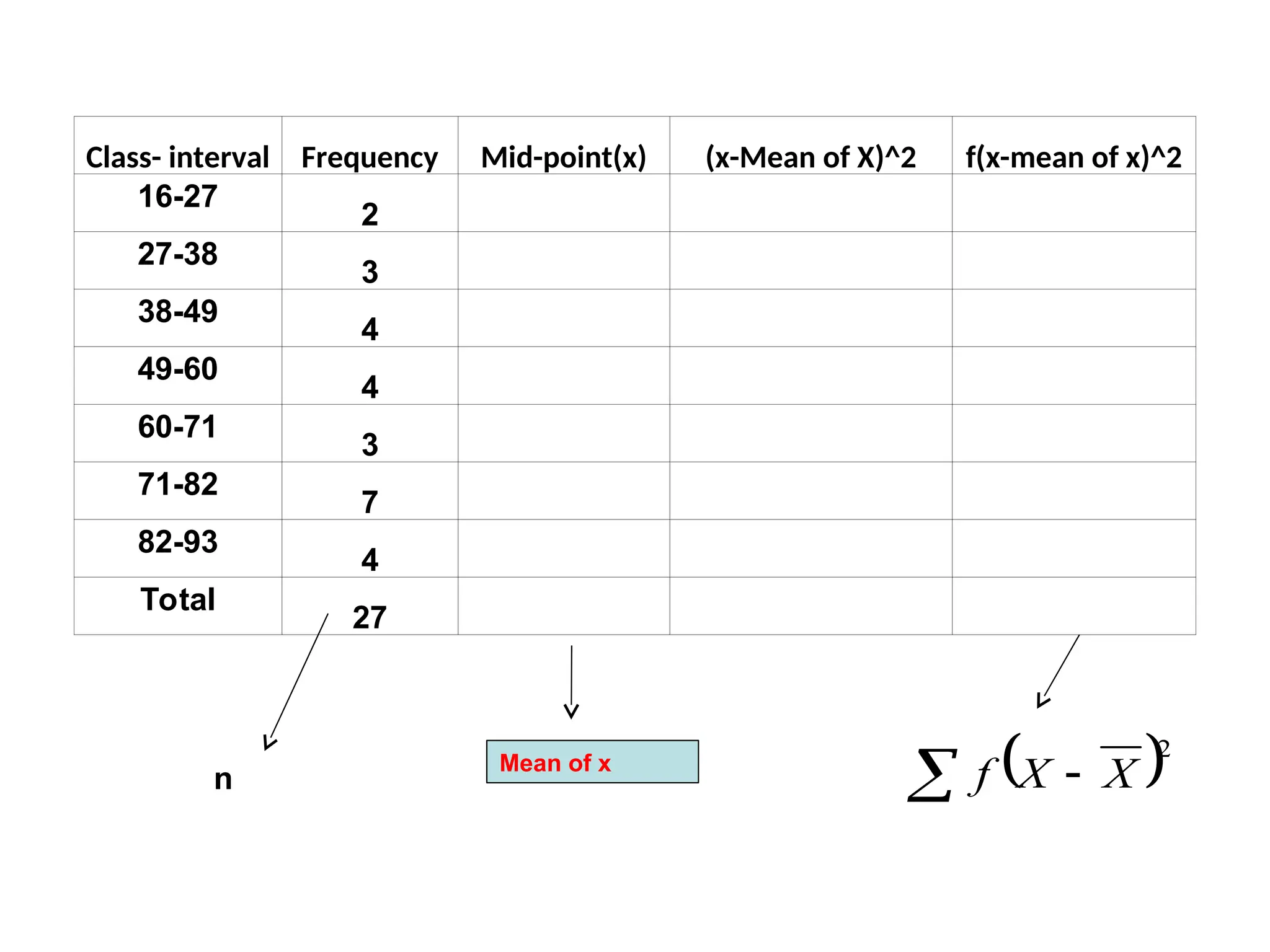
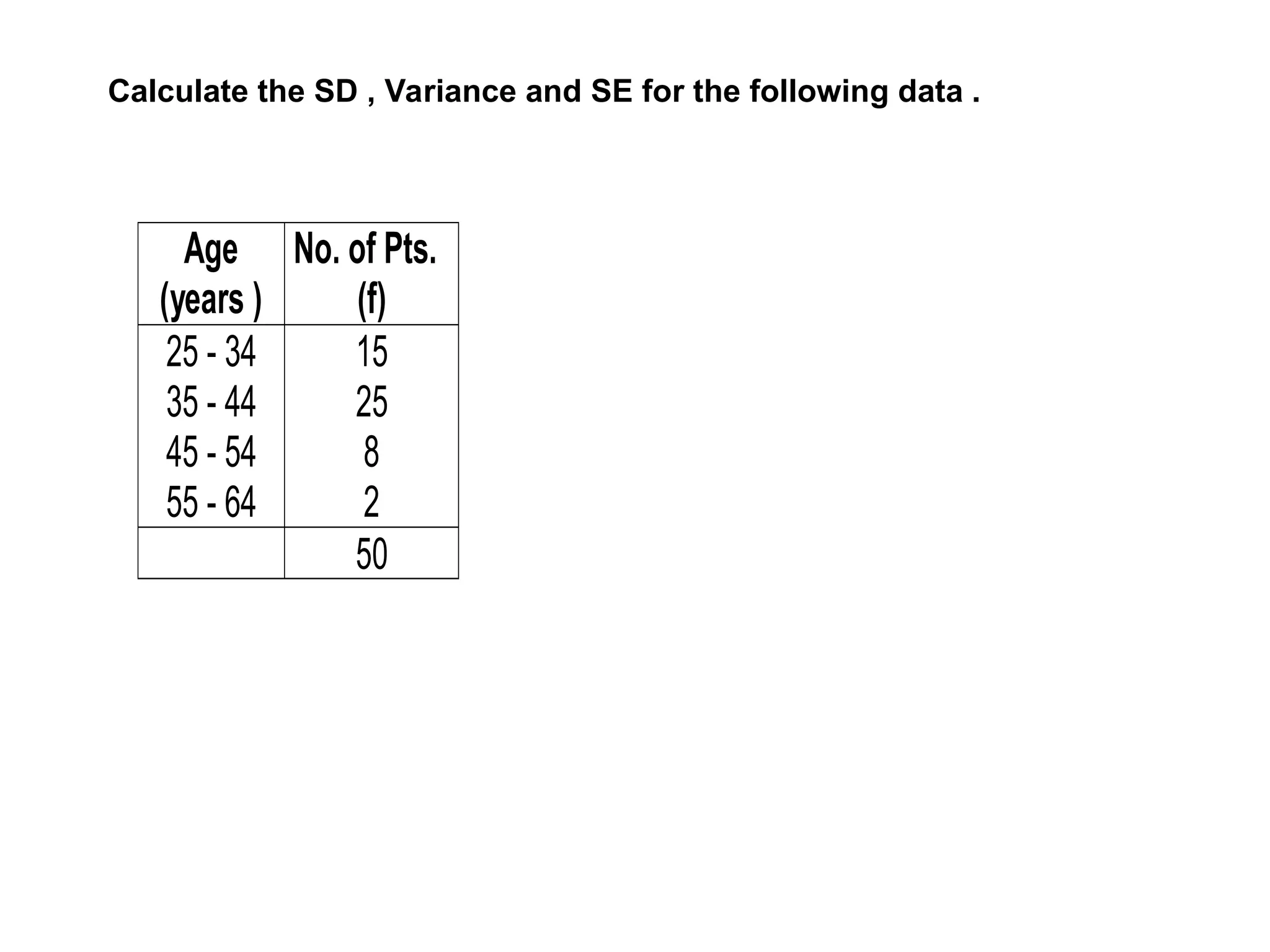
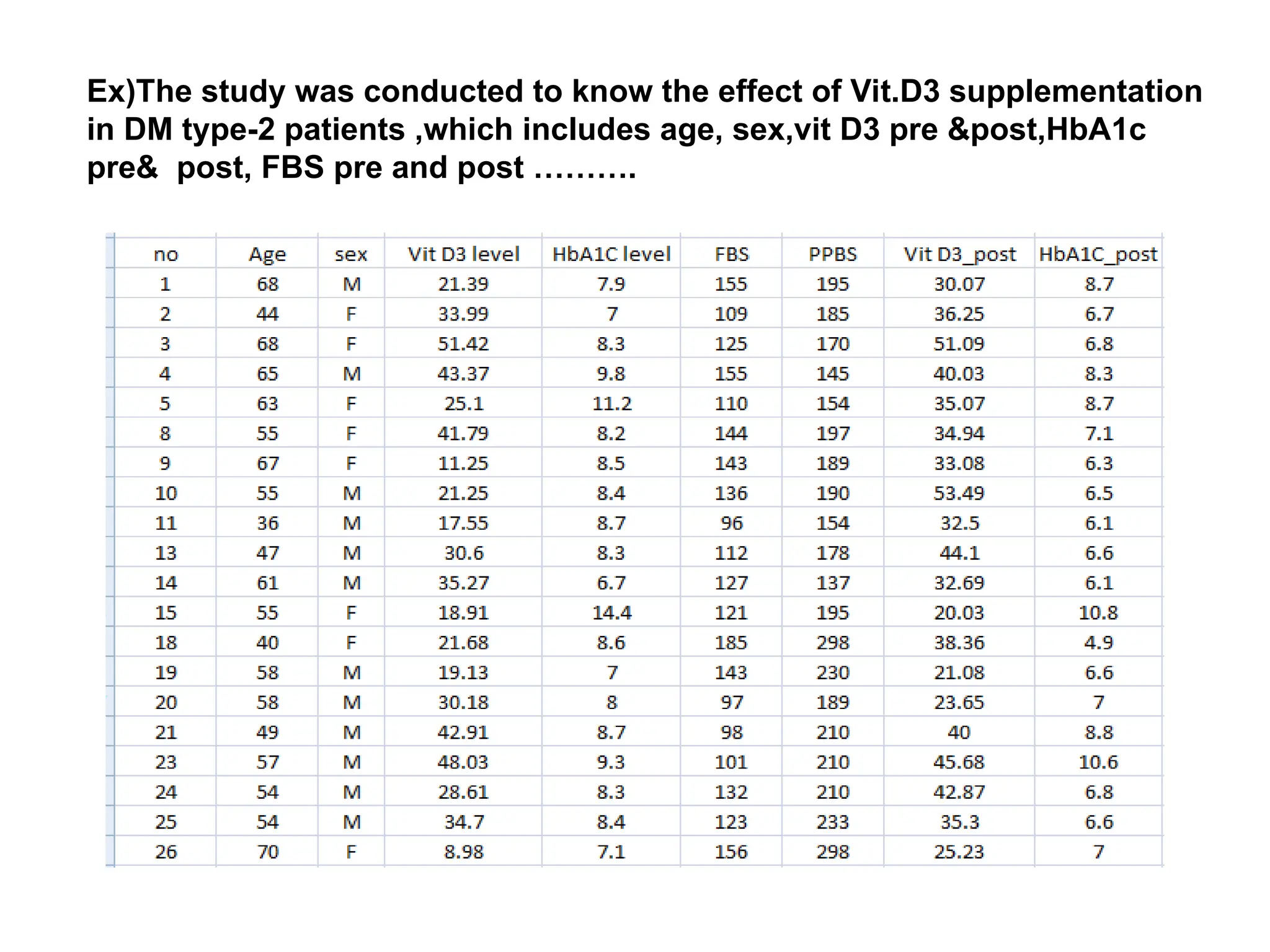
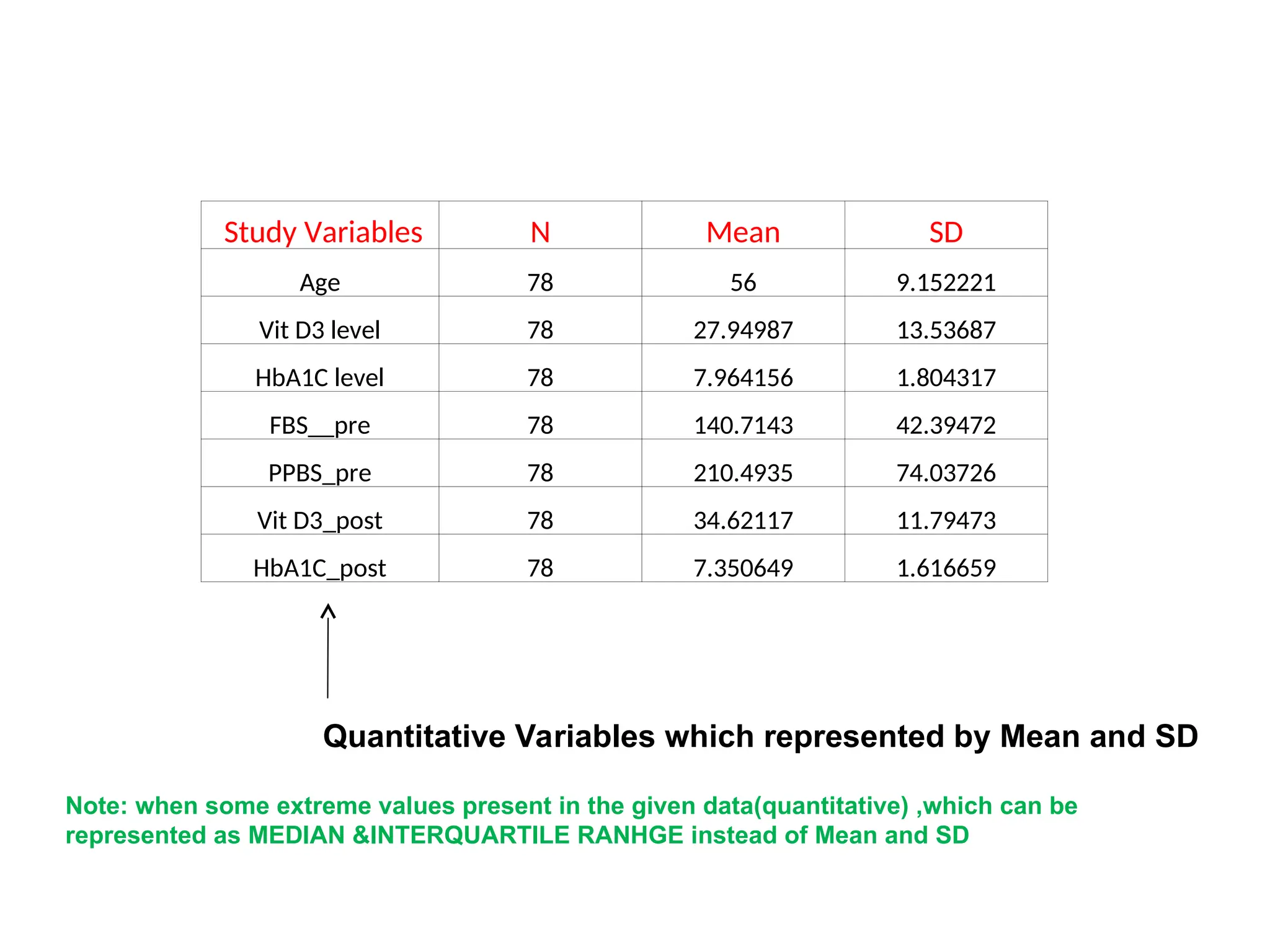
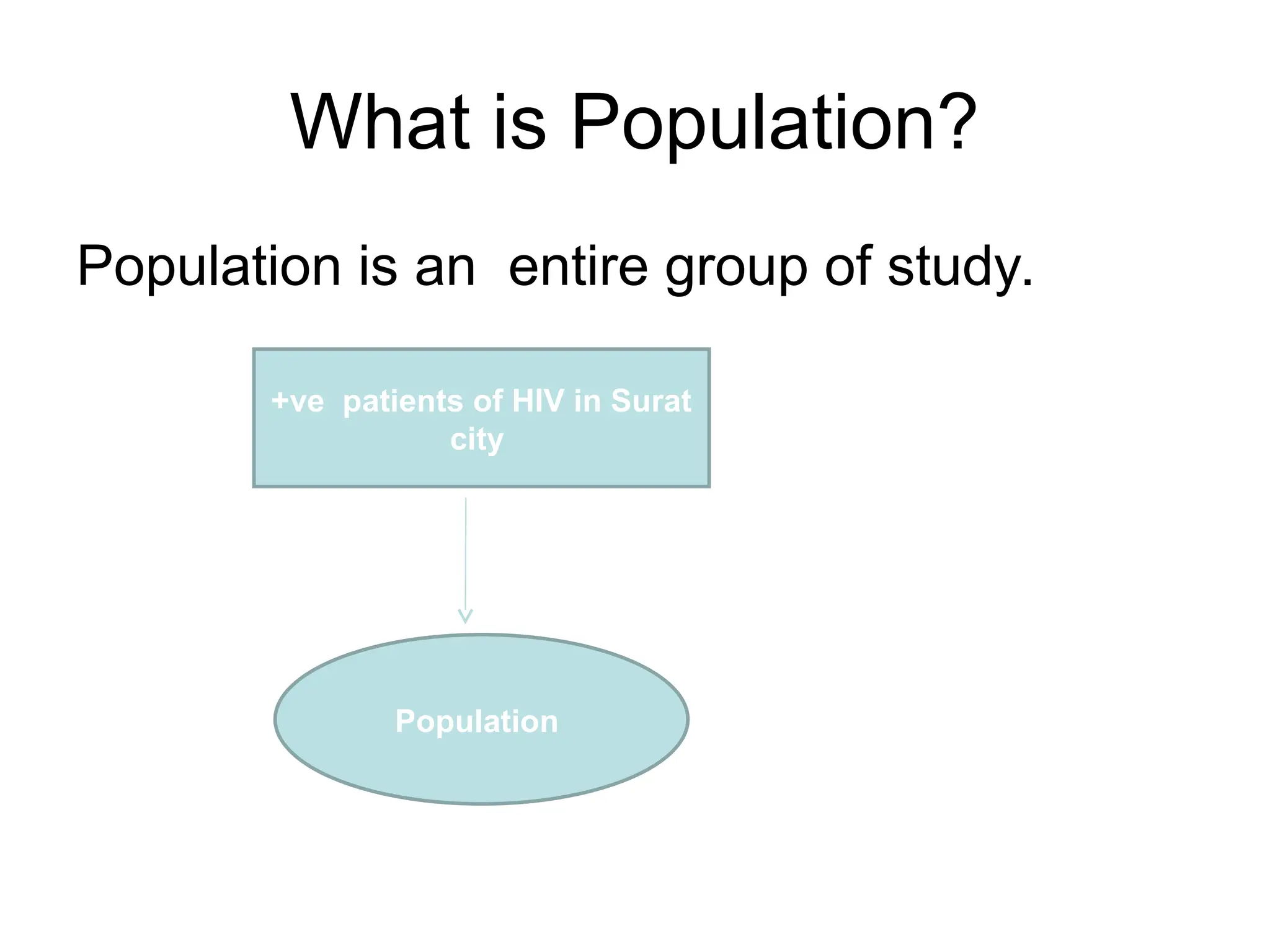
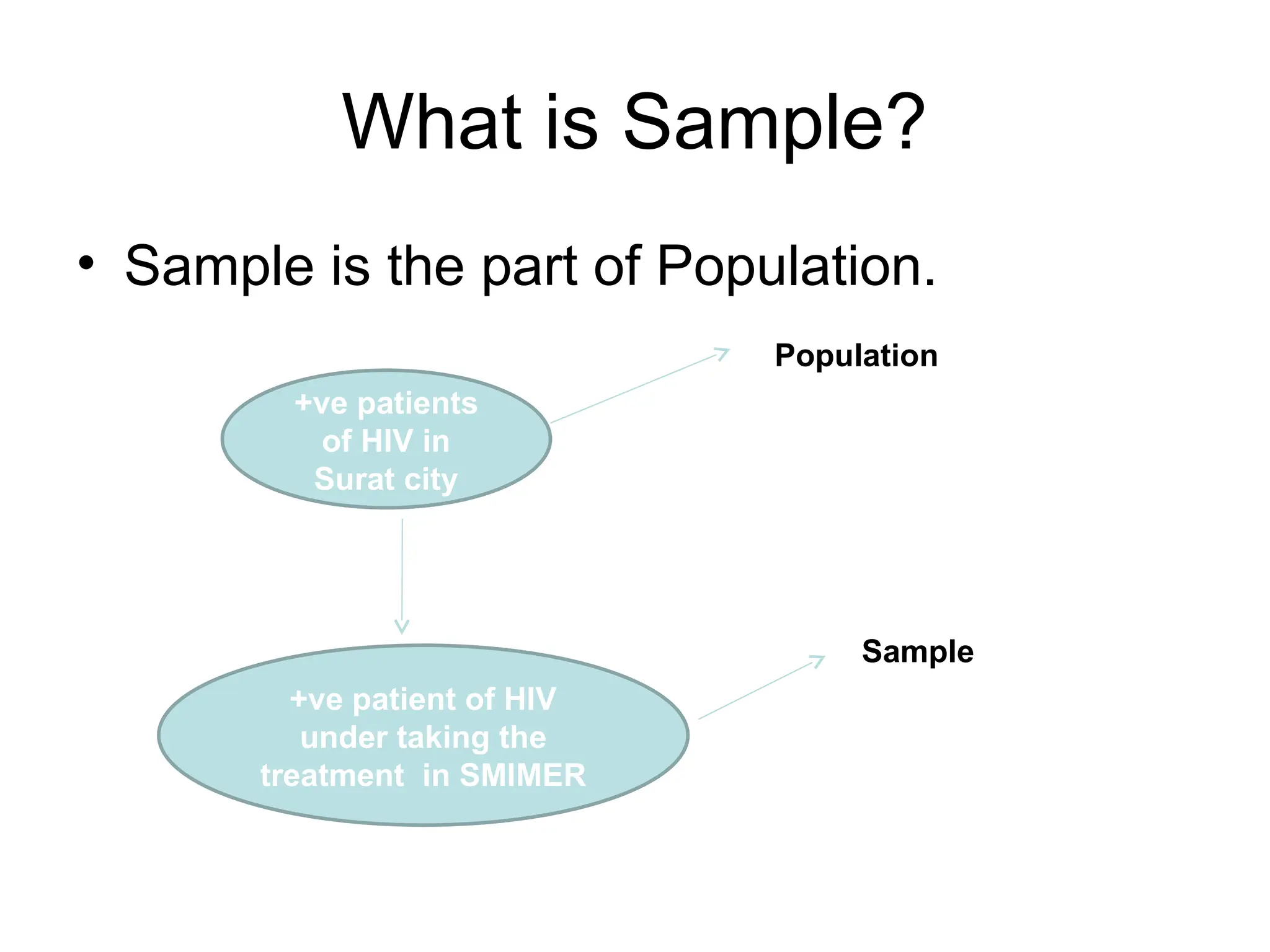
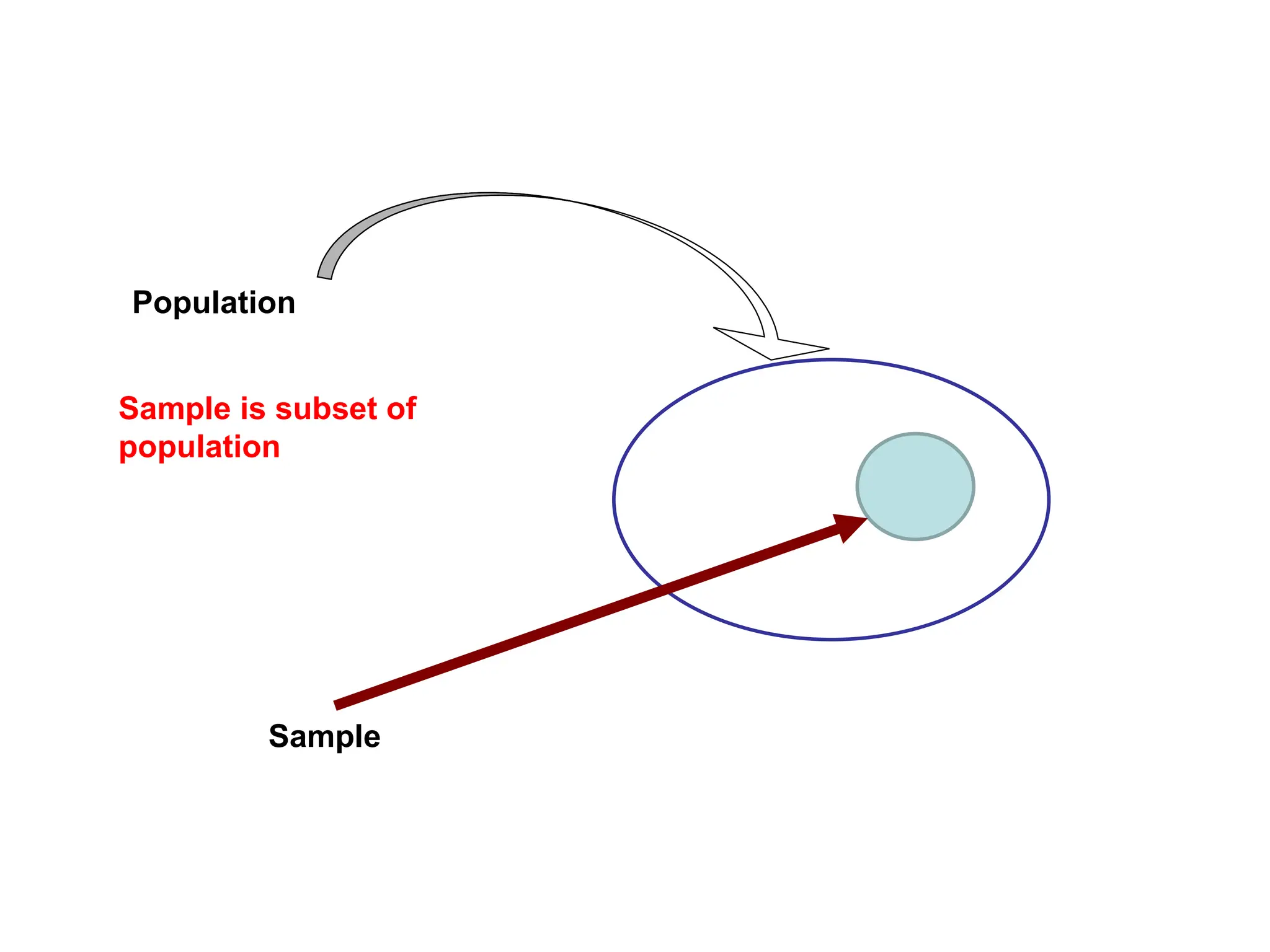
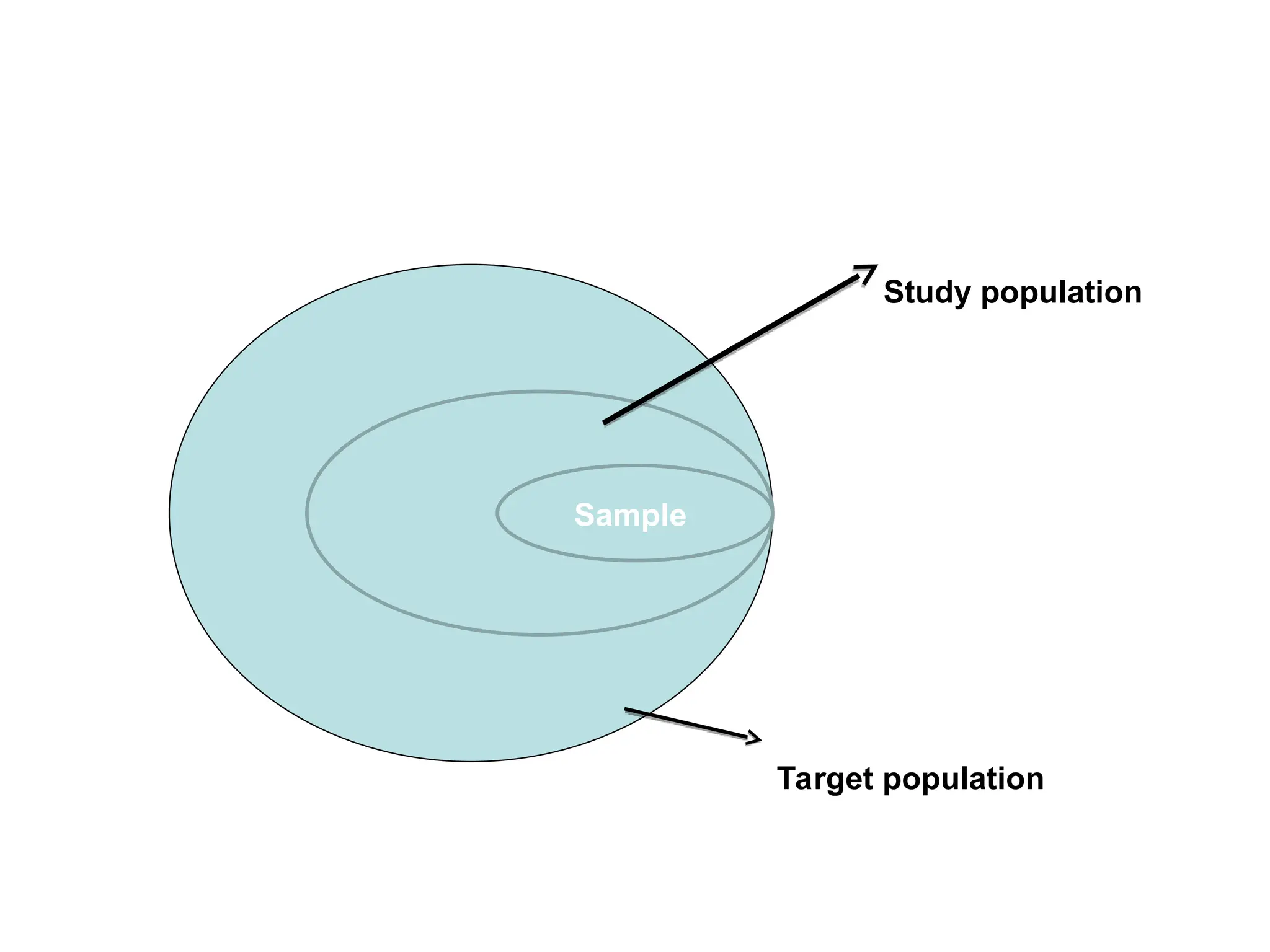
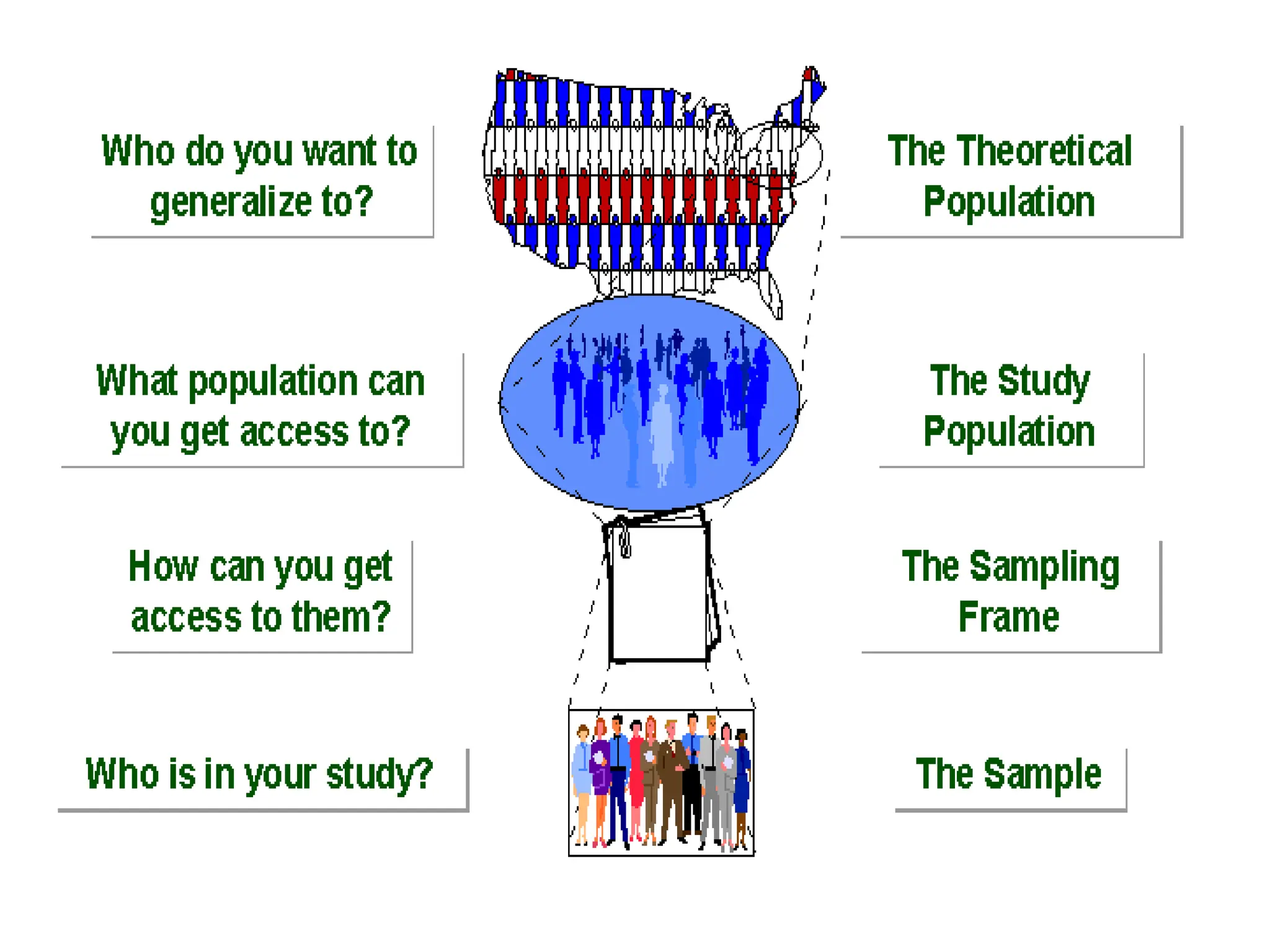
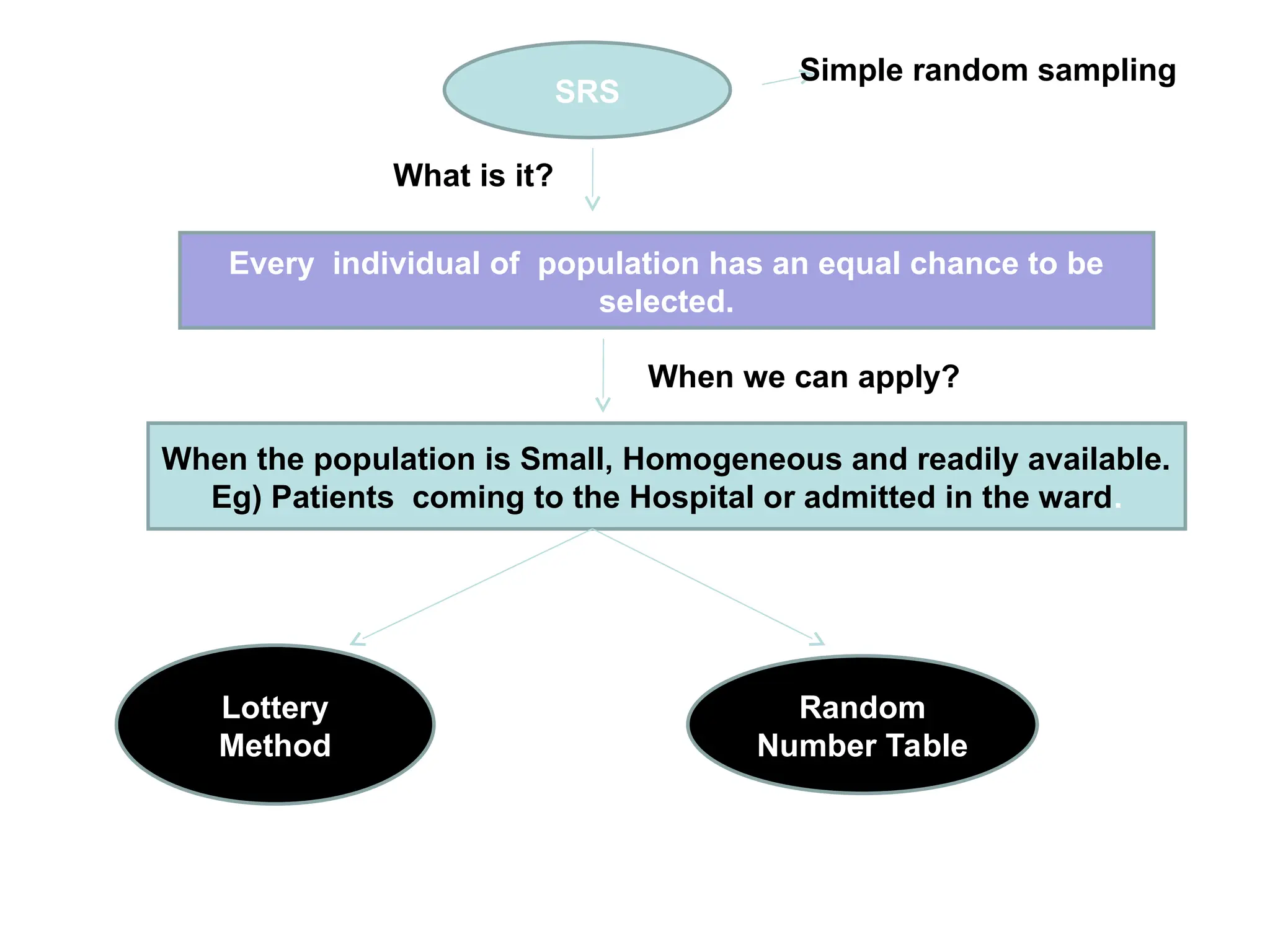
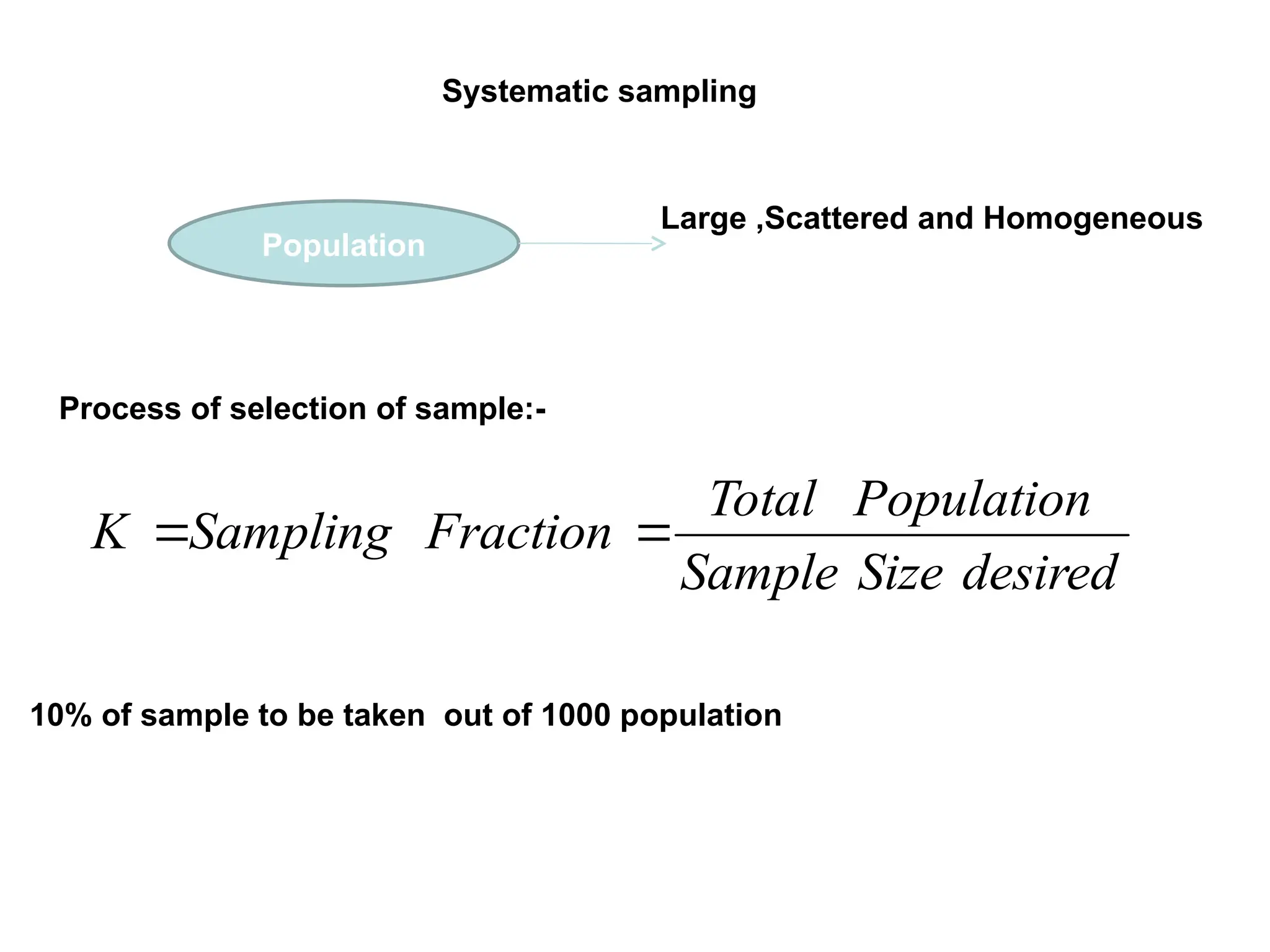
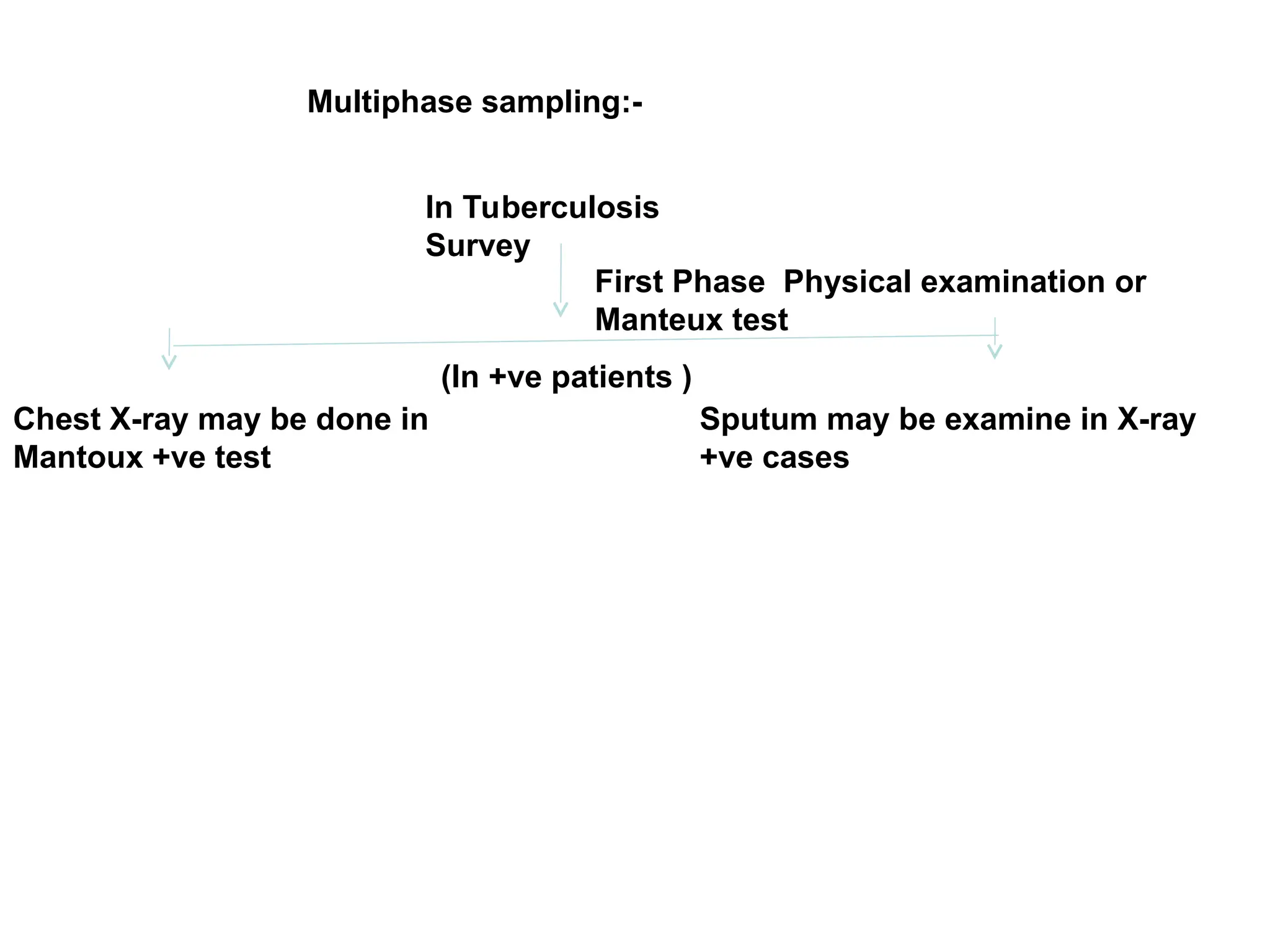
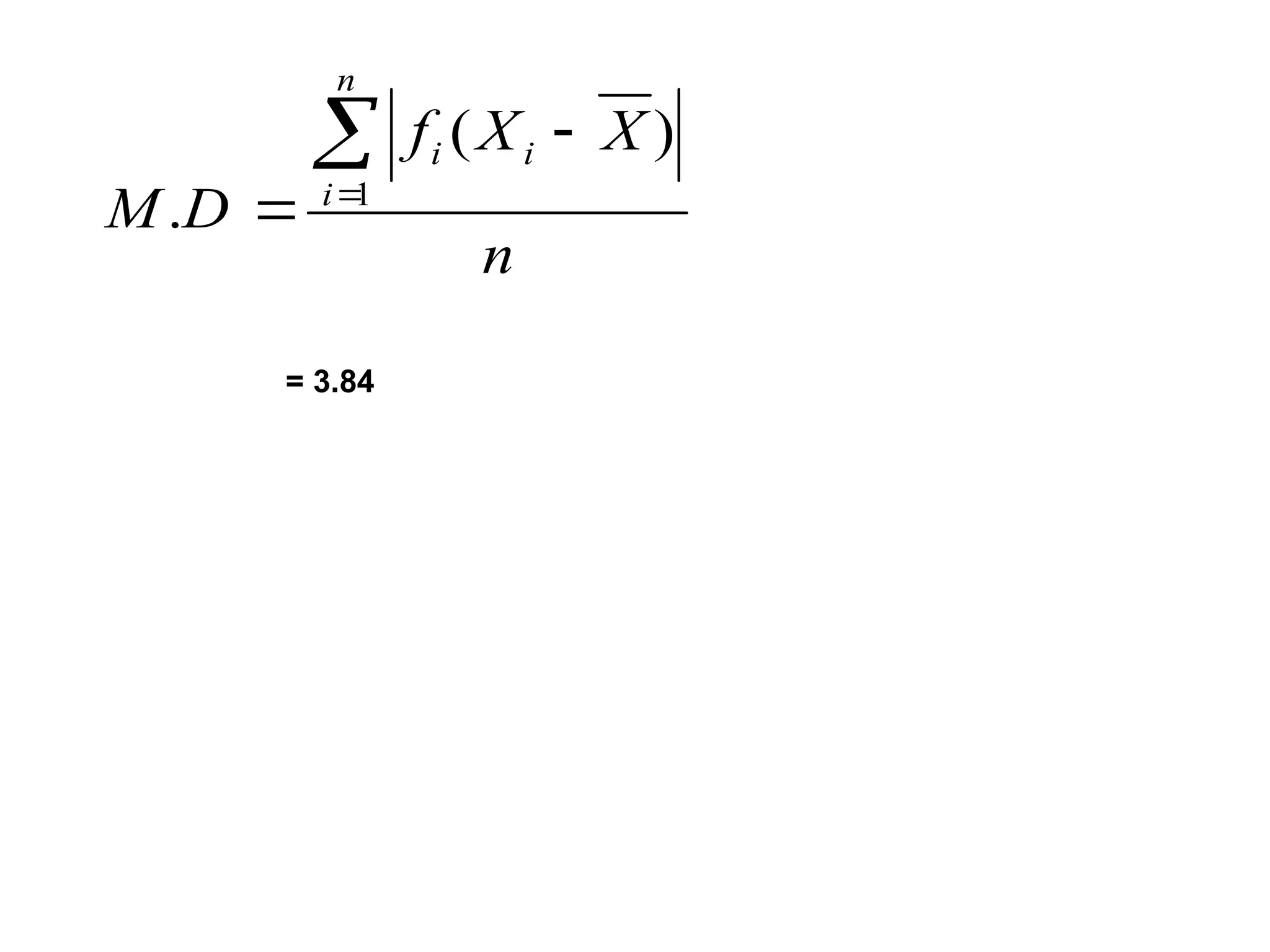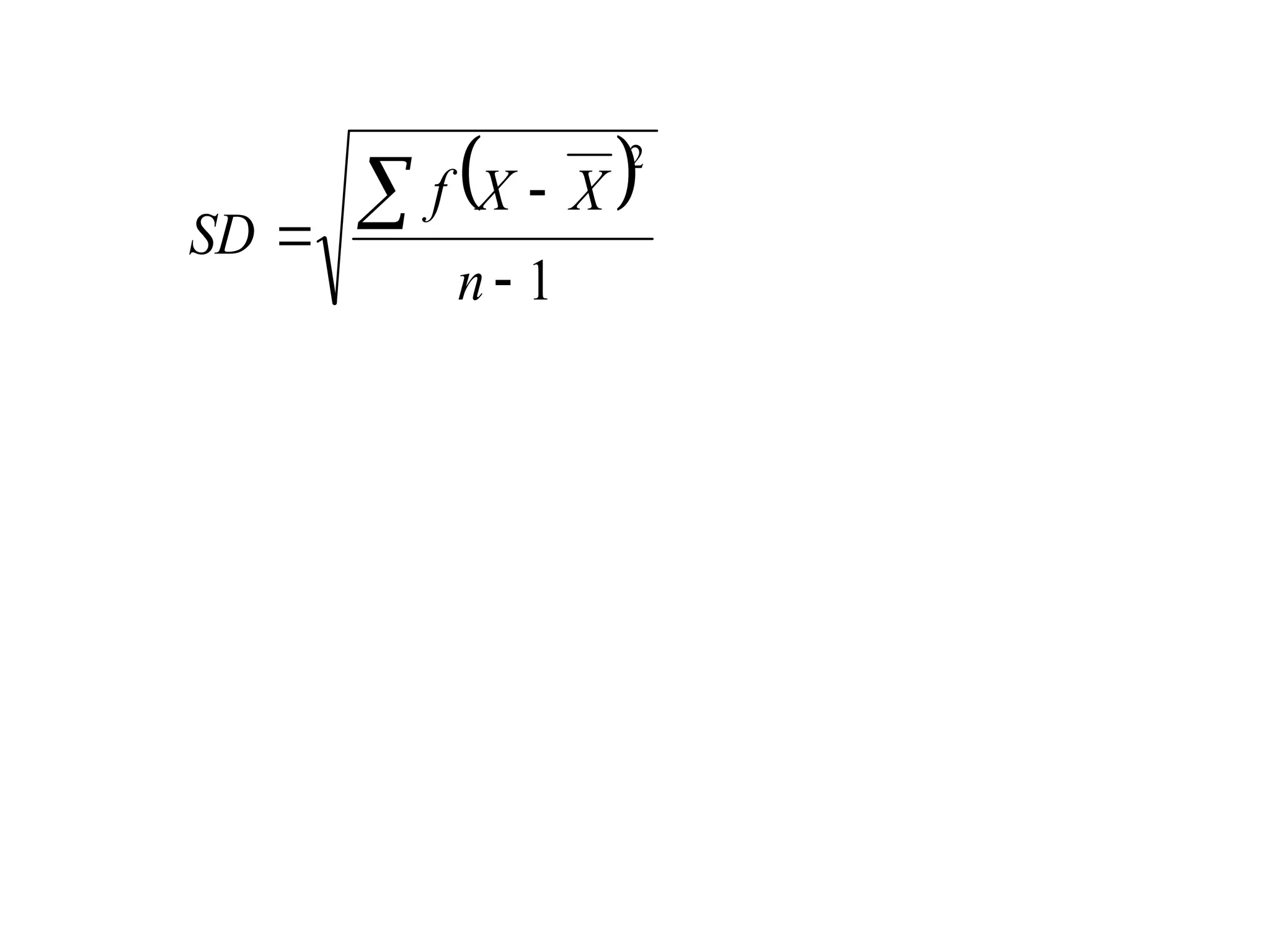The document outlines descriptive statistics and sampling methods, focusing on data presentation techniques for both qualitative and quantitative data. It explains measures of central tendency (mean, median, and mode) and dispersion, along with methods for summarizing ungrouped and grouped data. Examples are provided for calculating and interpreting these statistical measures, particularly in the context of malaria case studies.