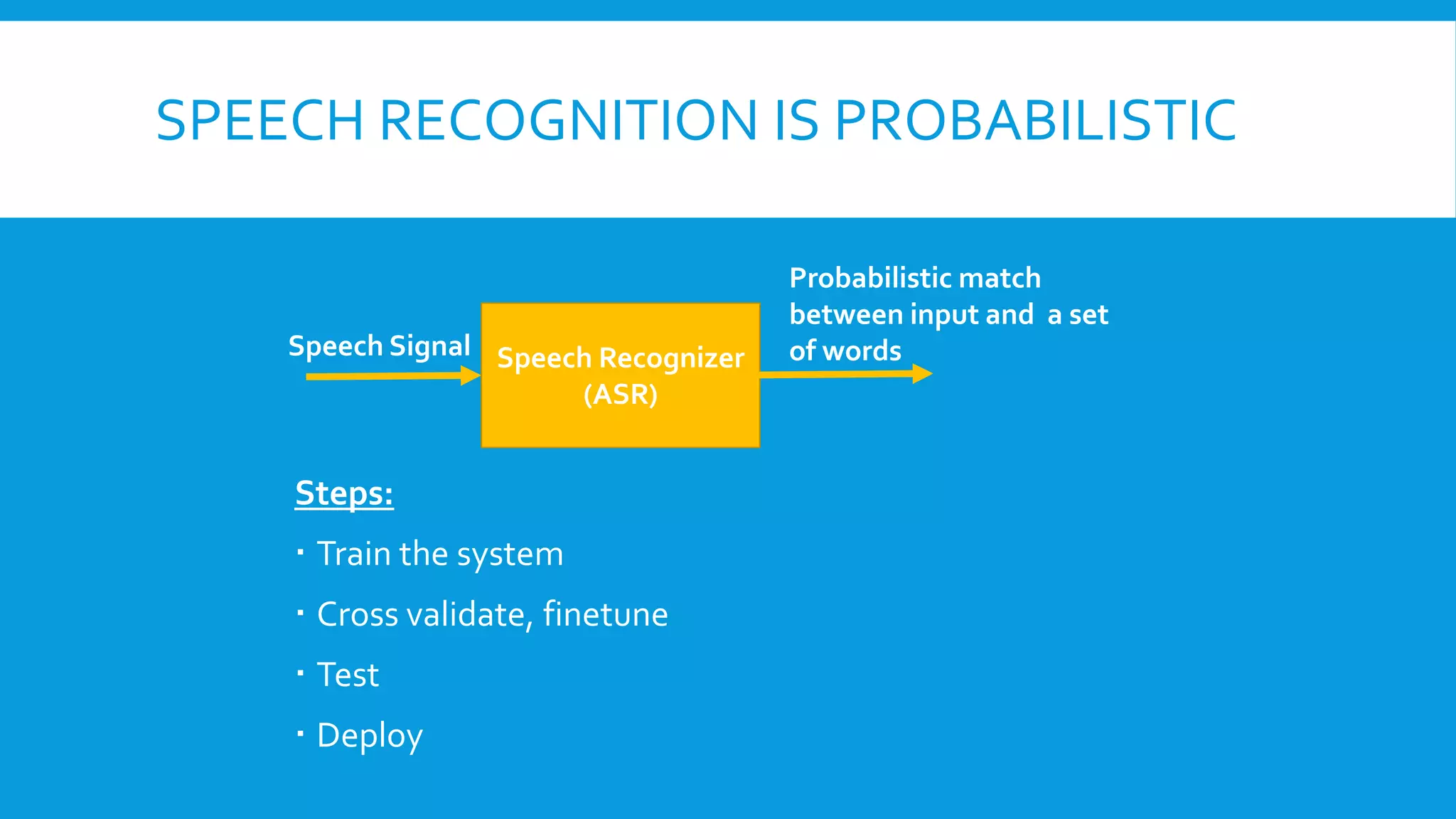
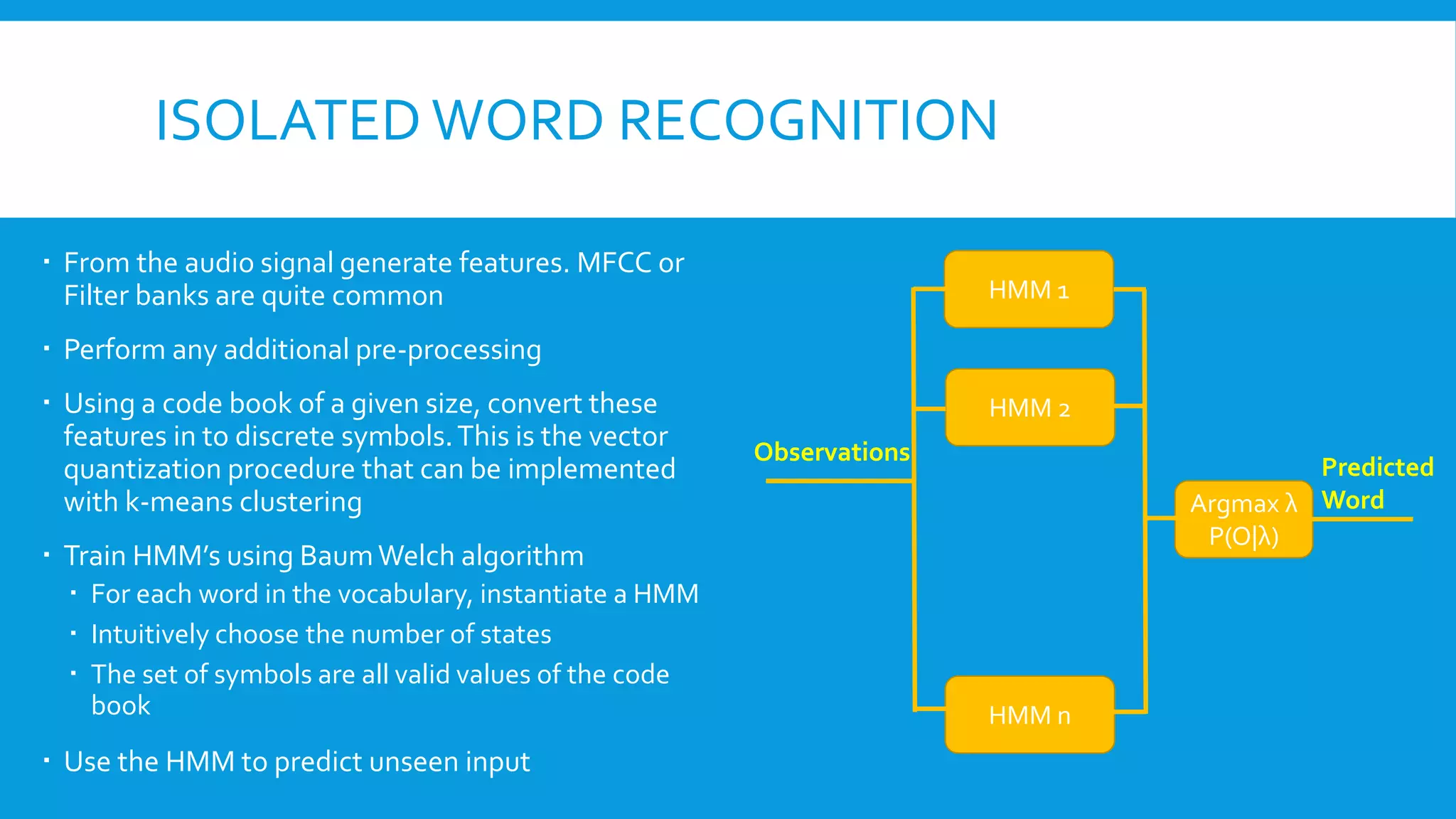
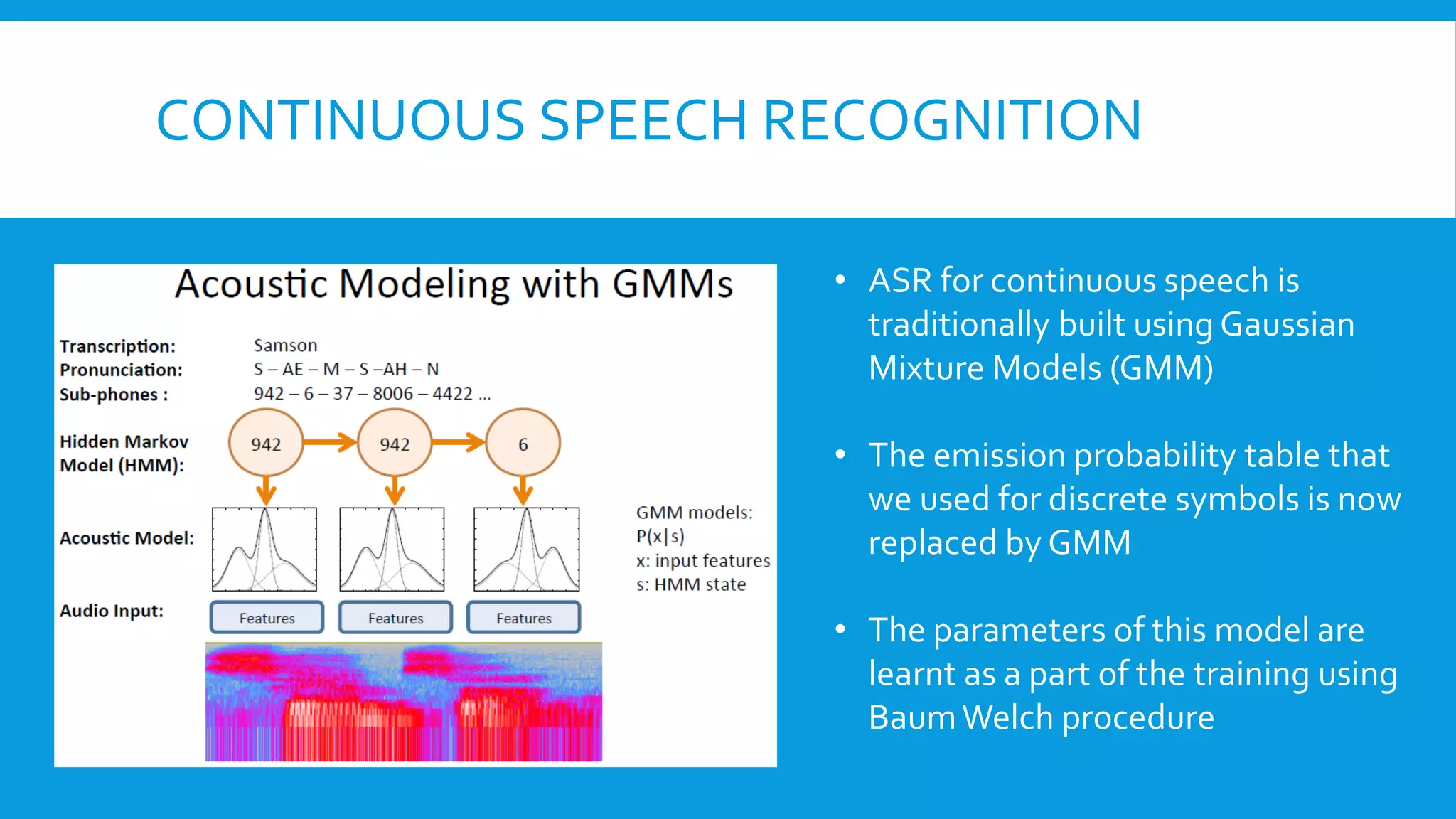
The document discusses the evolution of speech recognition technologies, highlighting traditional methods and the integration of deep learning techniques. It covers various applications, types of speech recognition tasks, and the probabilistic approach to Automatic Speech Recognition (ASR). Future directions indicate a shift towards fully neural network-based systems, moving away from Hidden Markov Models (HMMs).