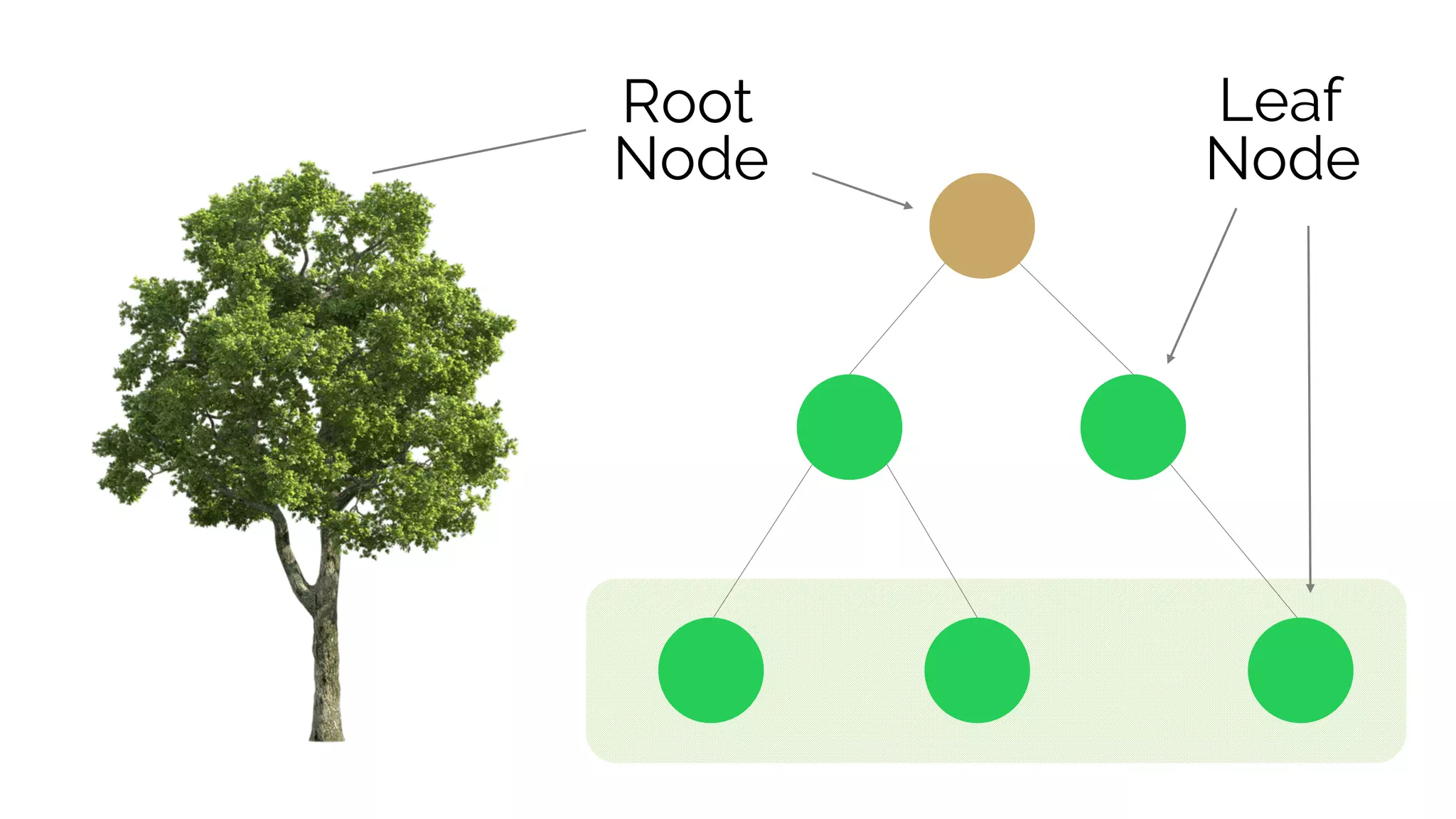
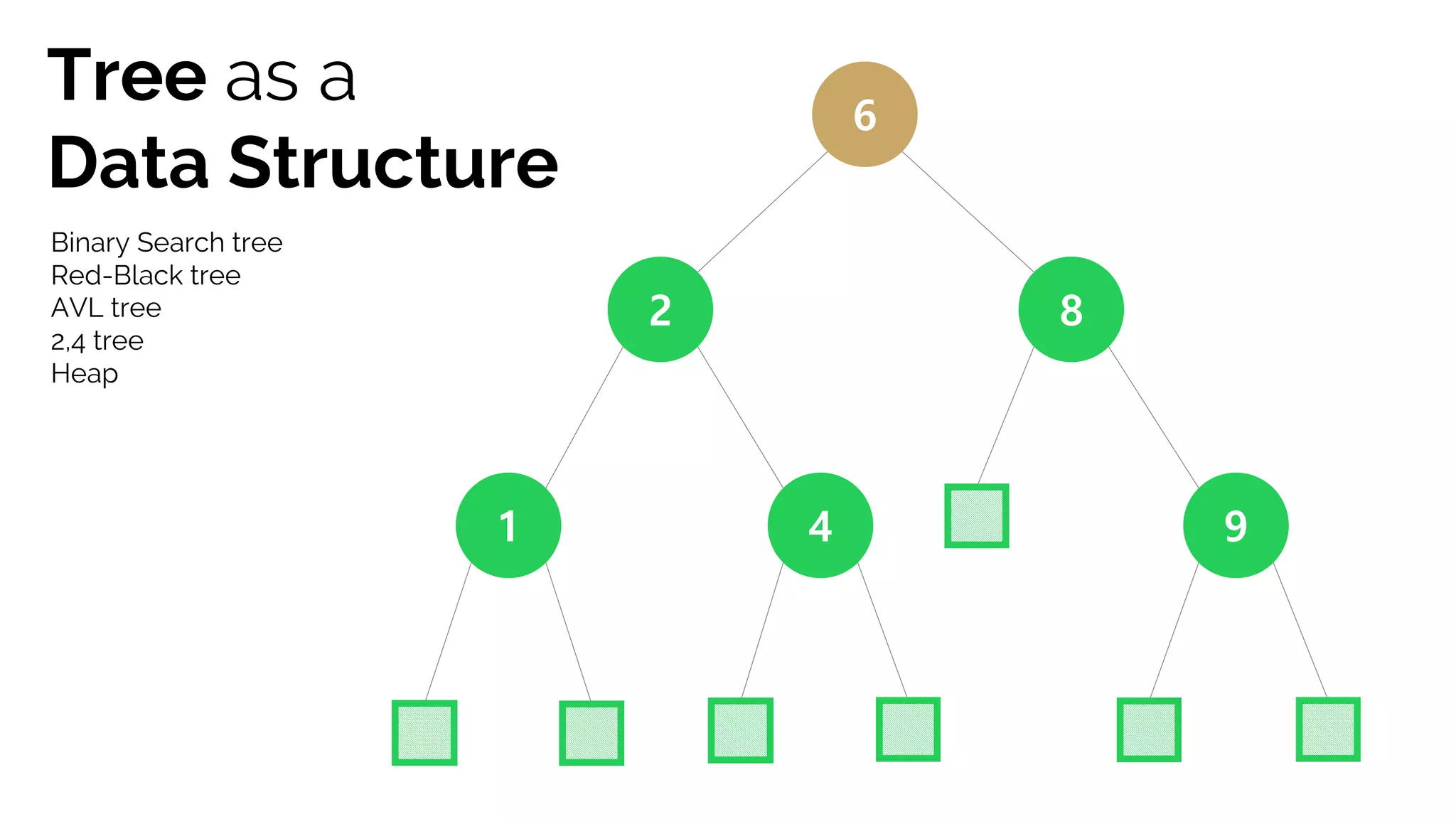
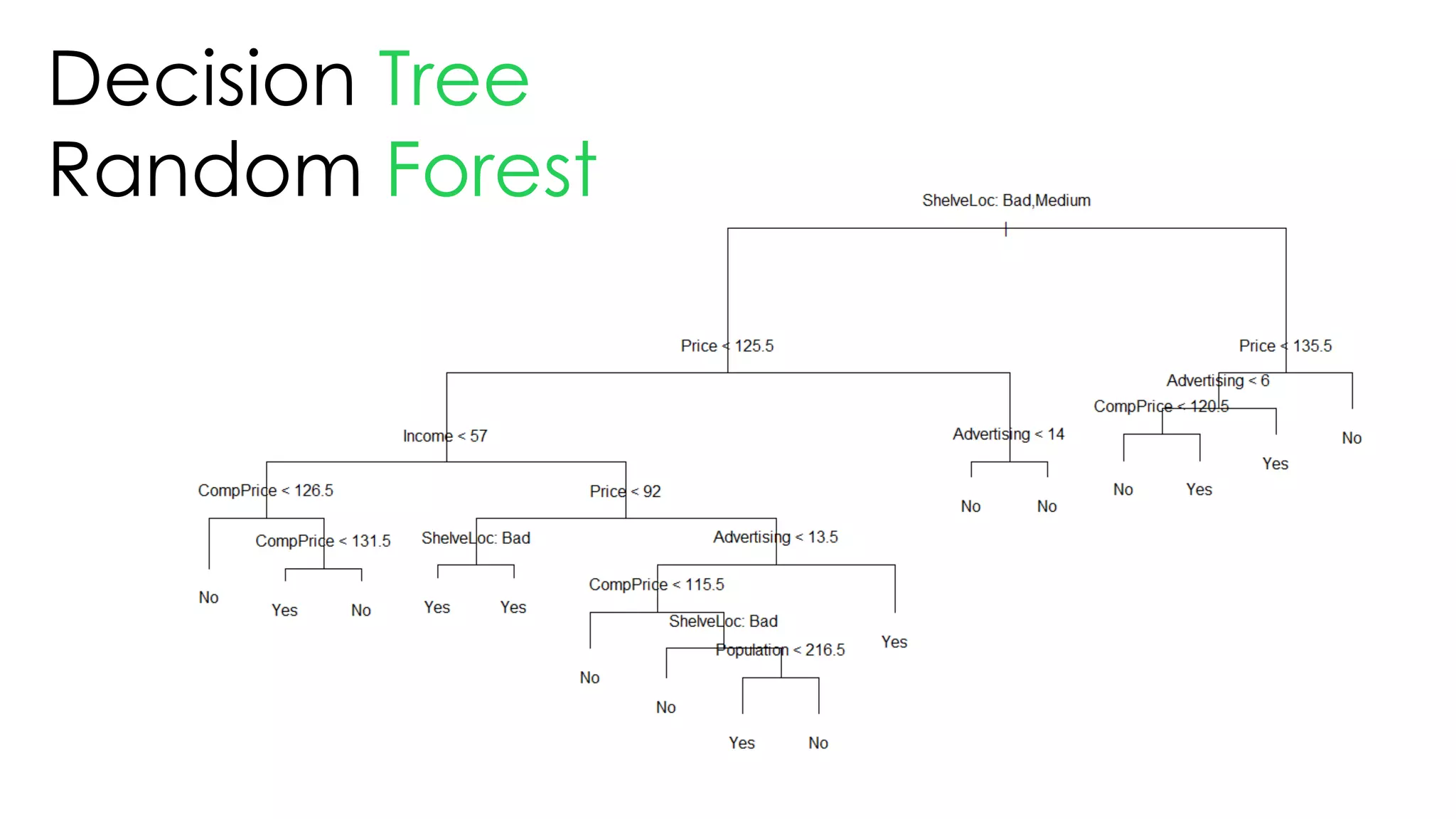
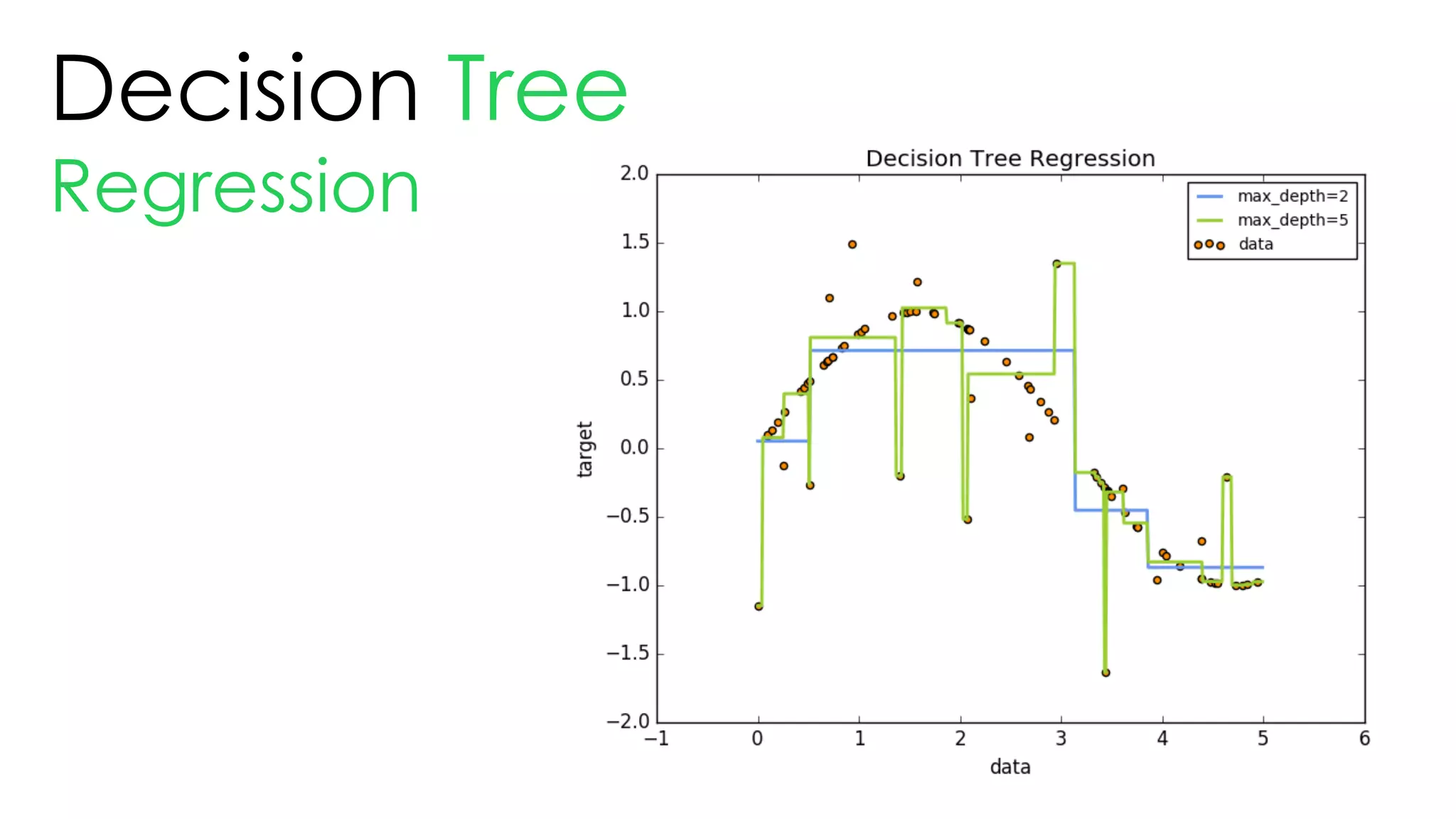
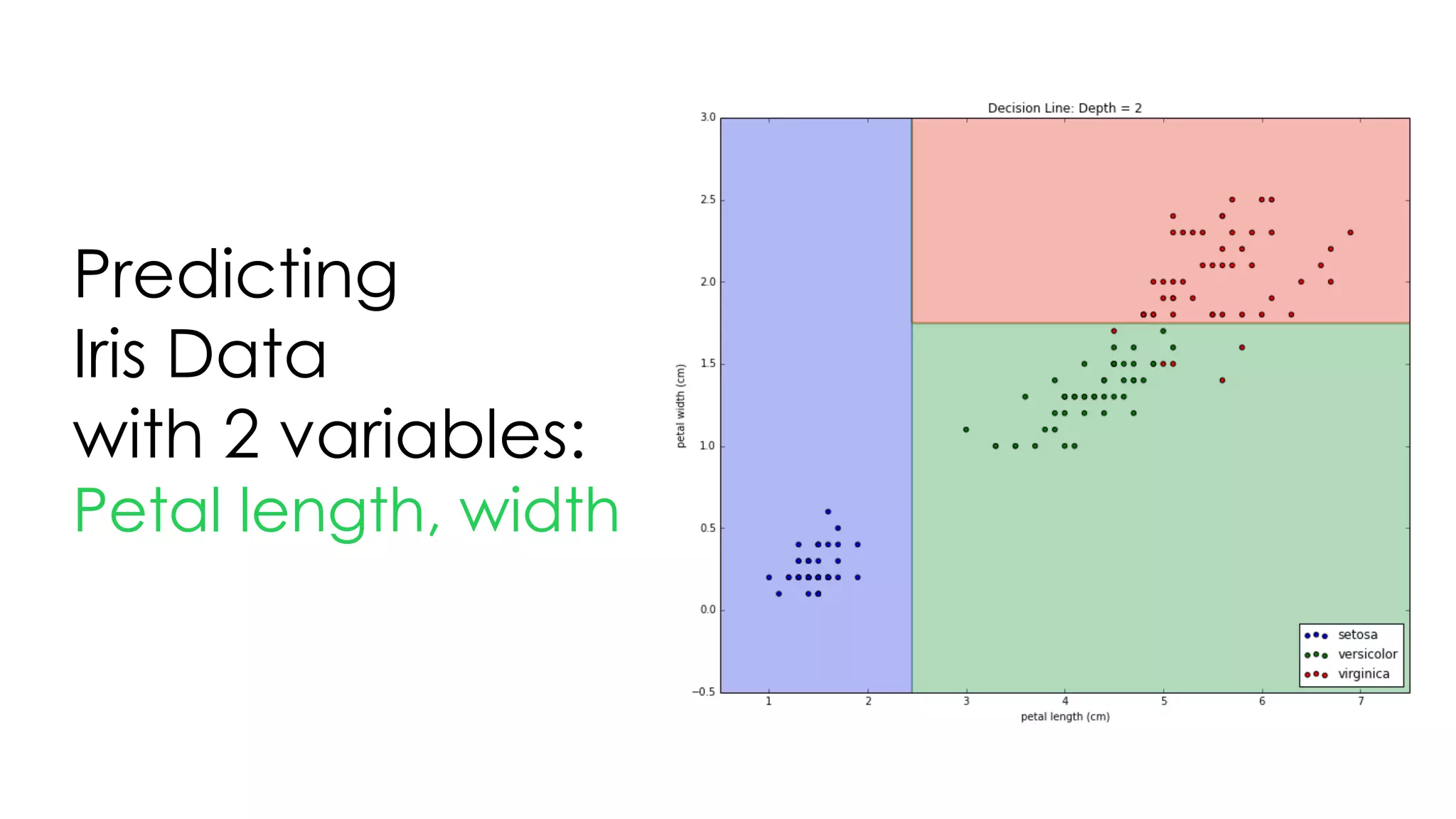
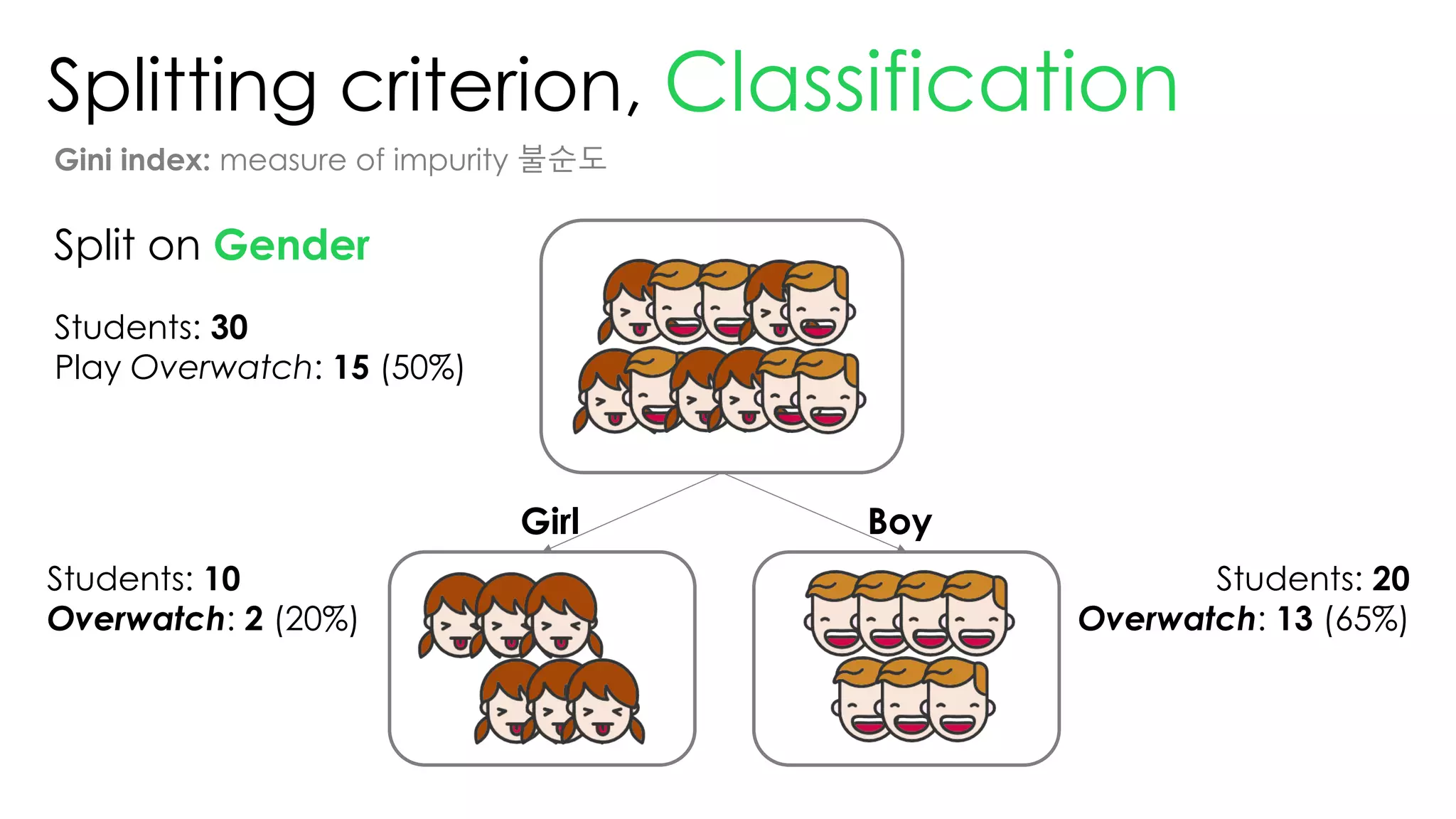
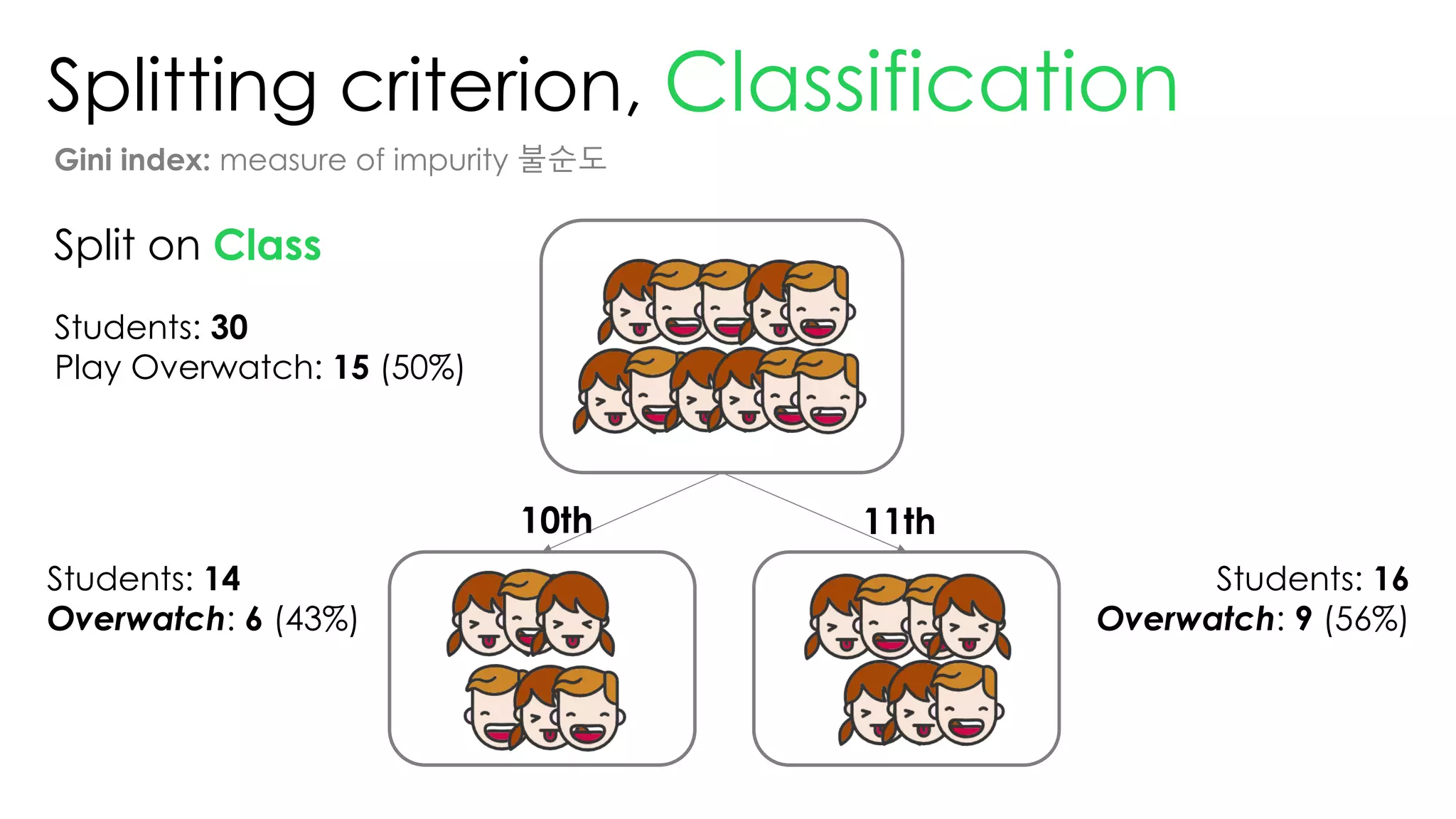
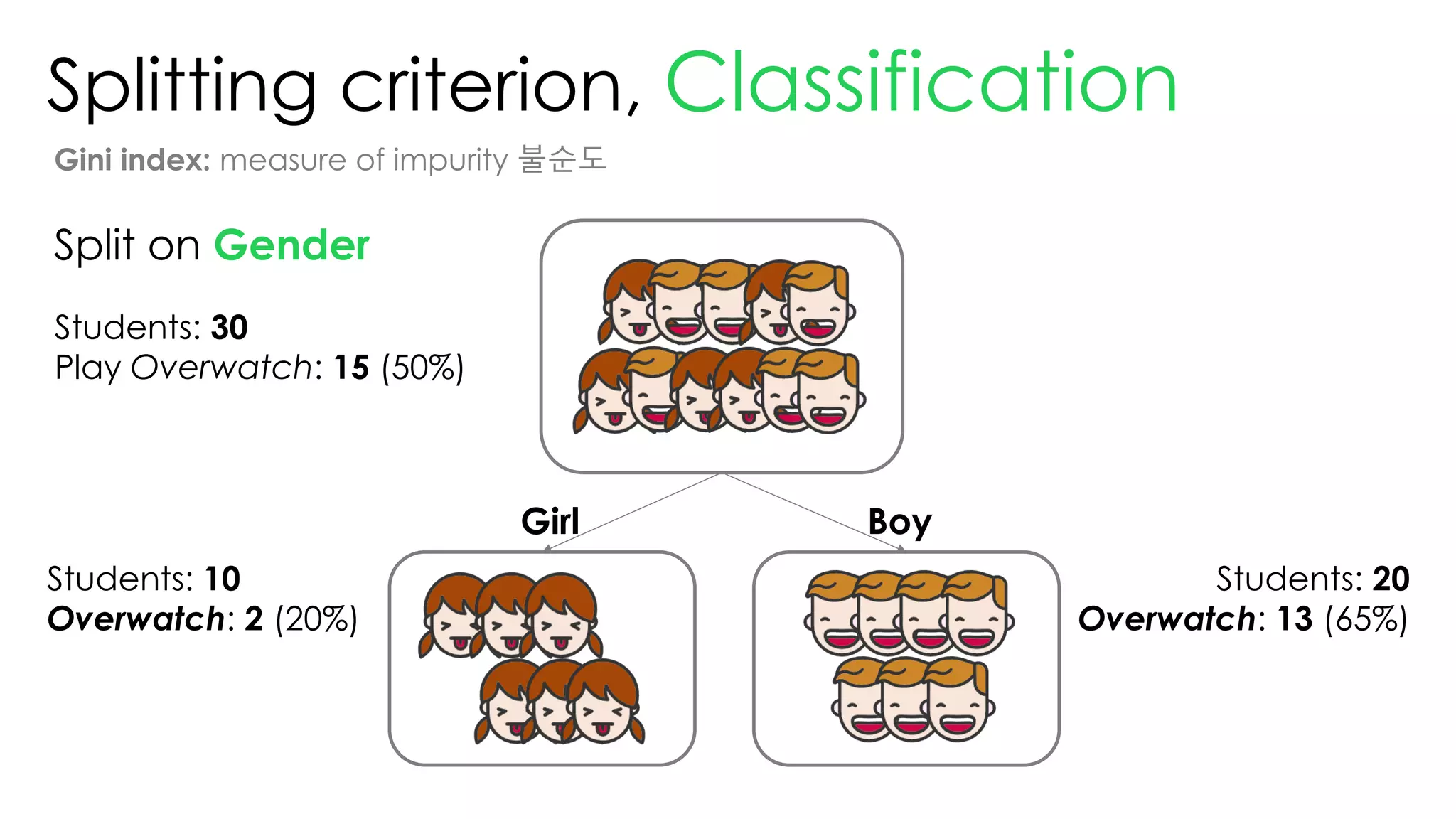
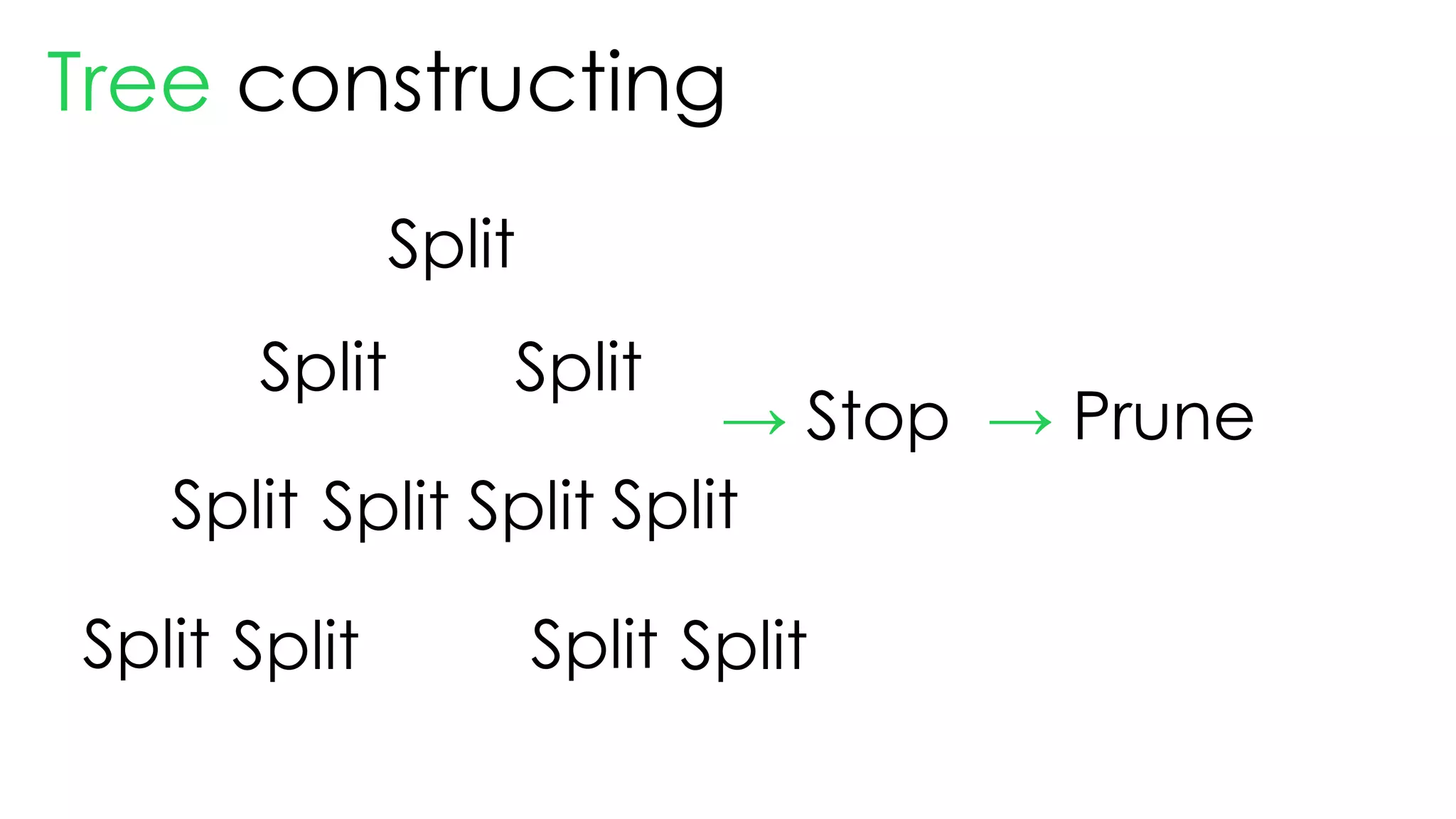
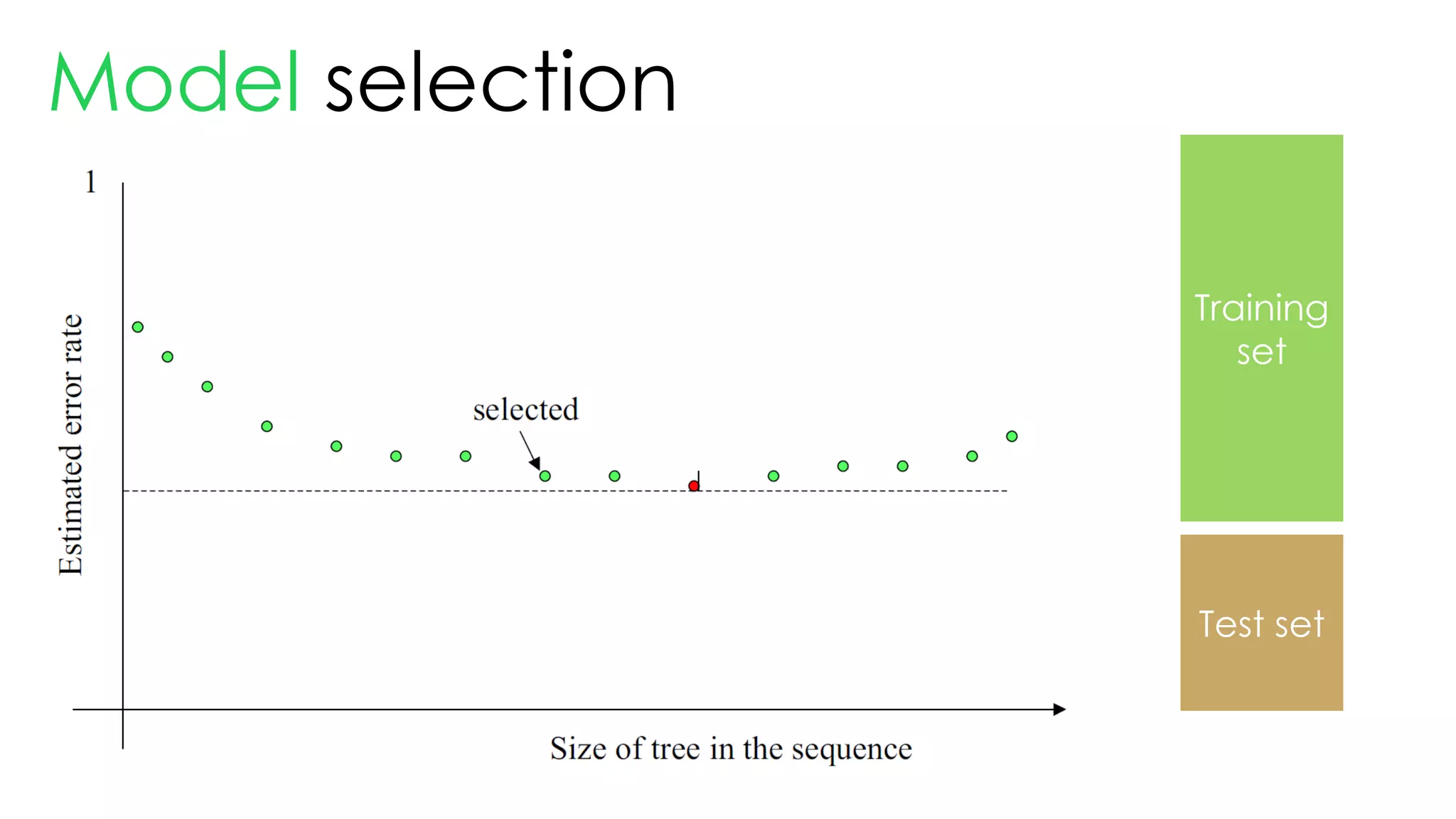
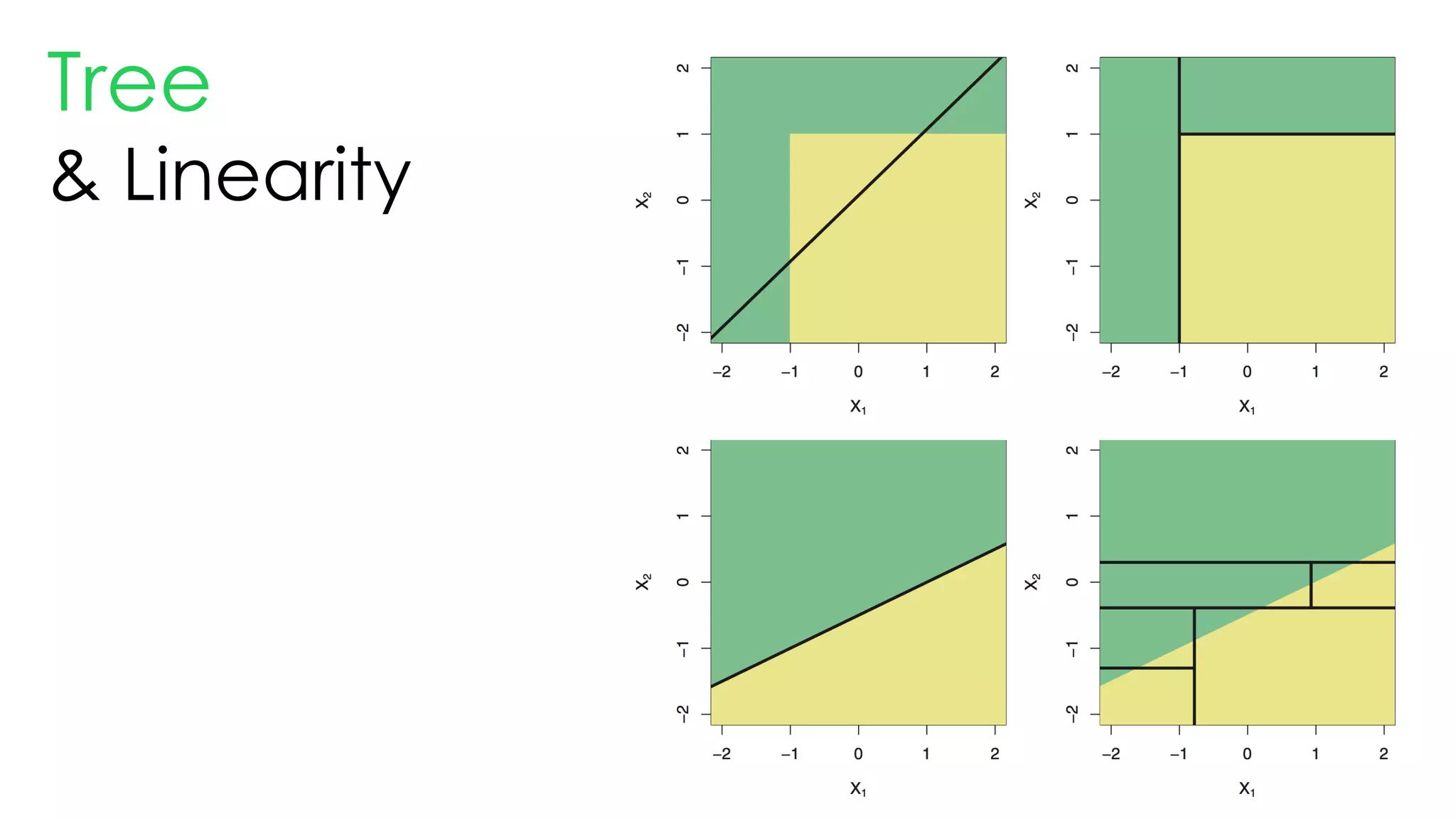
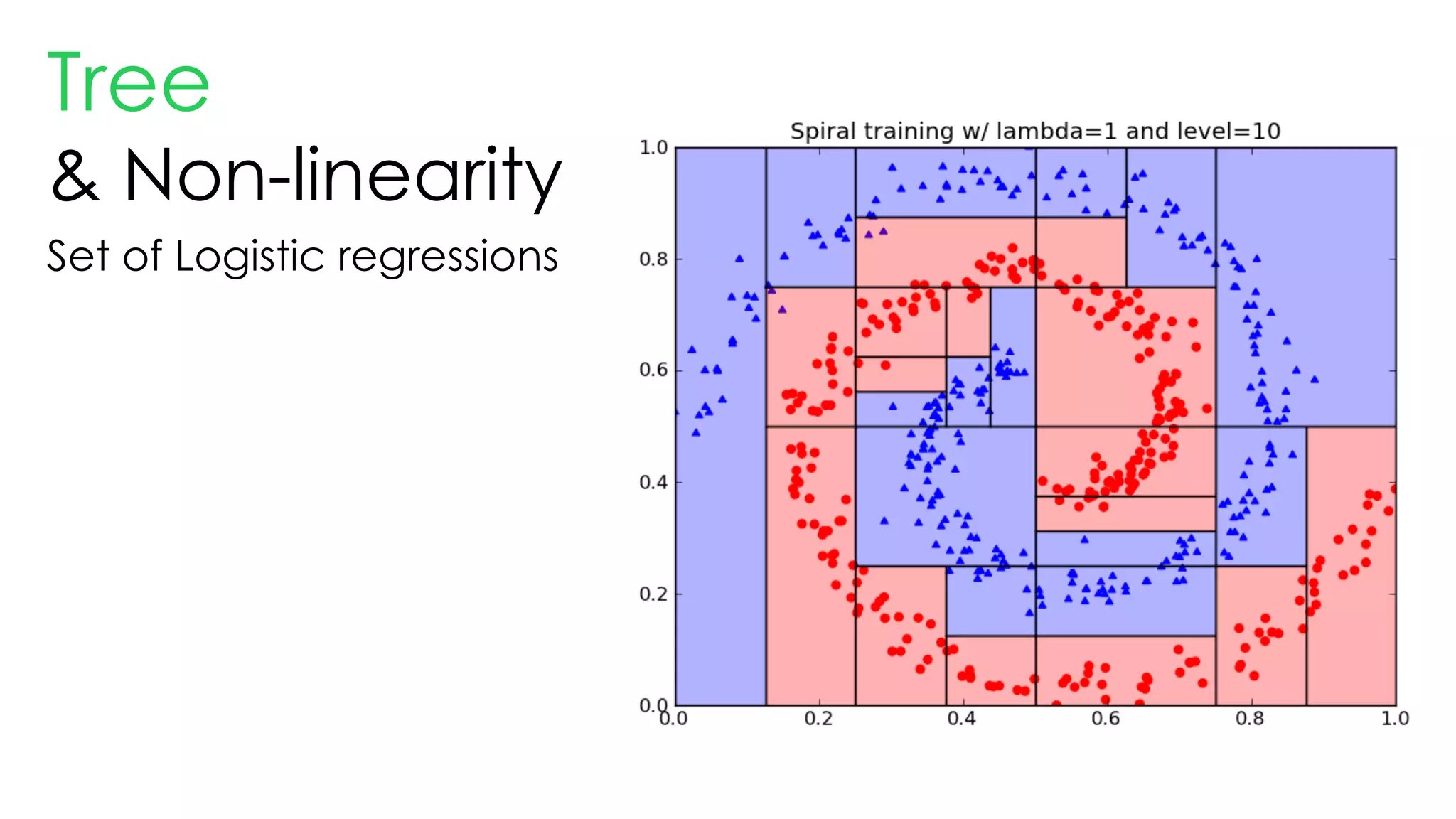
This document discusses decision trees and their use in machine learning for classification and regression problems. It covers key concepts like splitting criteria, overfitting, and pruning methods. Decision trees are explained as a top-down greedy algorithm that recursively splits the data space and builds nested partitions. Methods like calculating Gini impurity and residual sum of squares are presented for selecting the best data splits in classification and regression trees. The document also notes advantages of decision trees in modeling nonlinear relationships and disadvantages like potential overfitting issues.










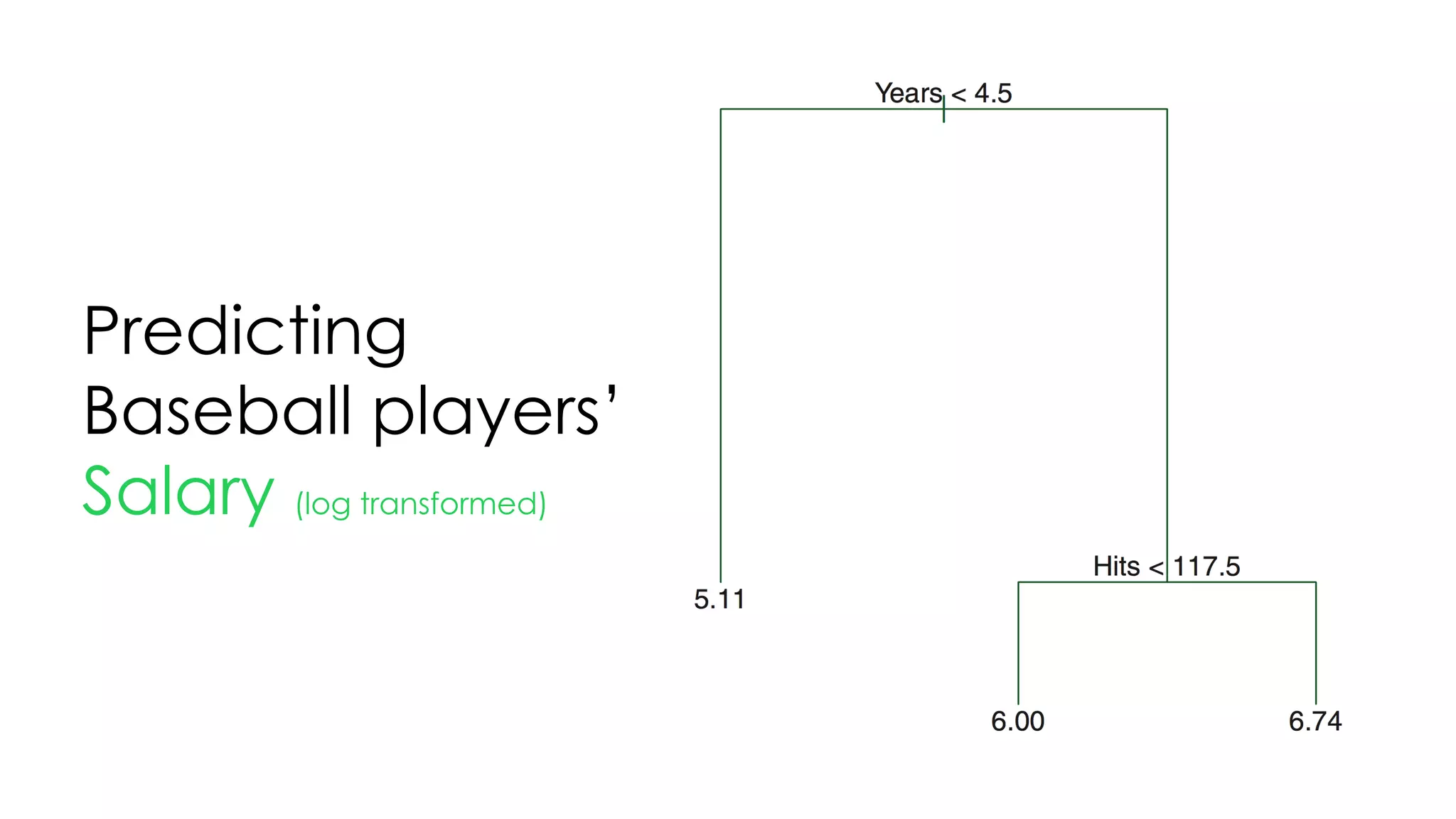
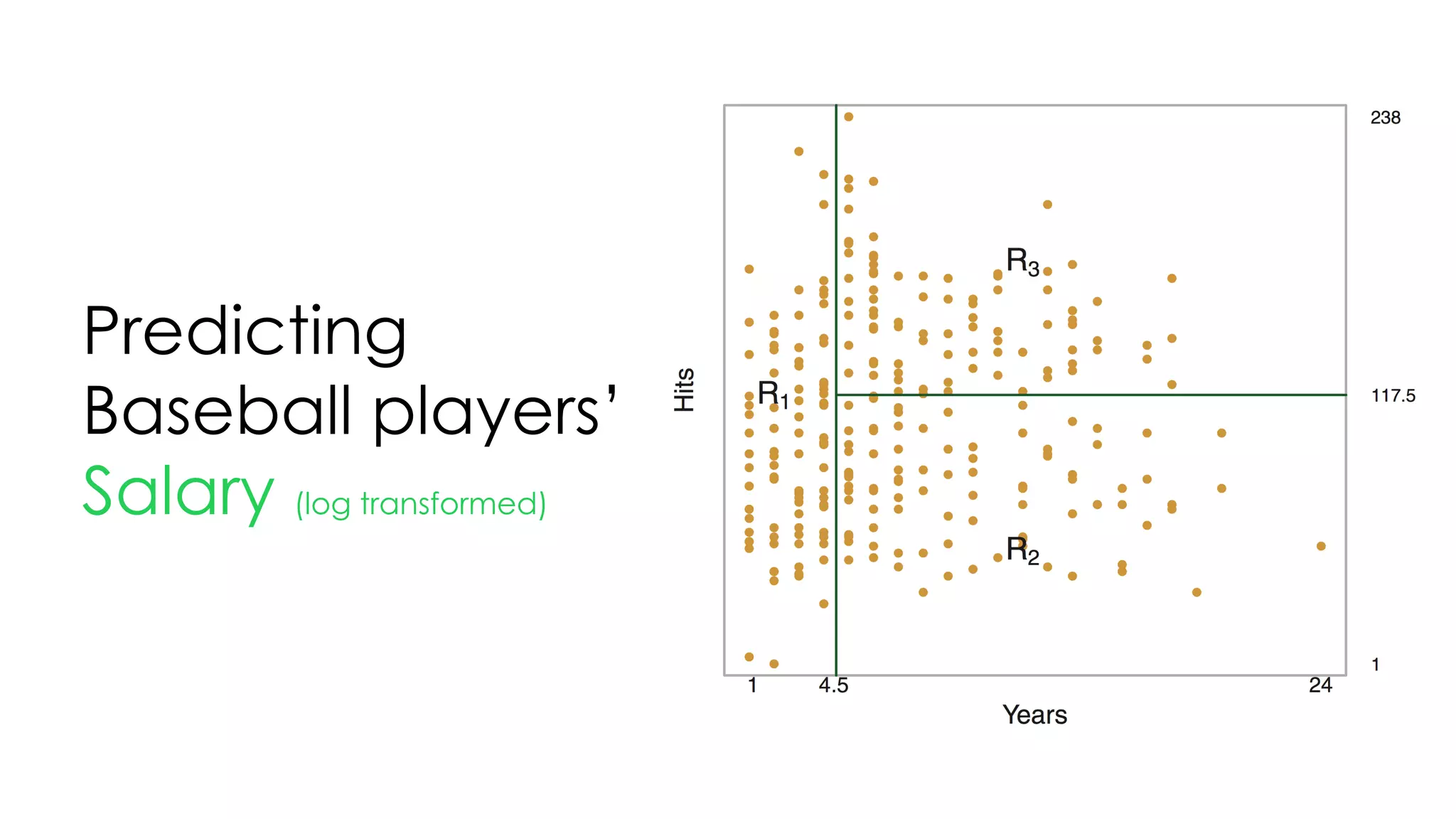






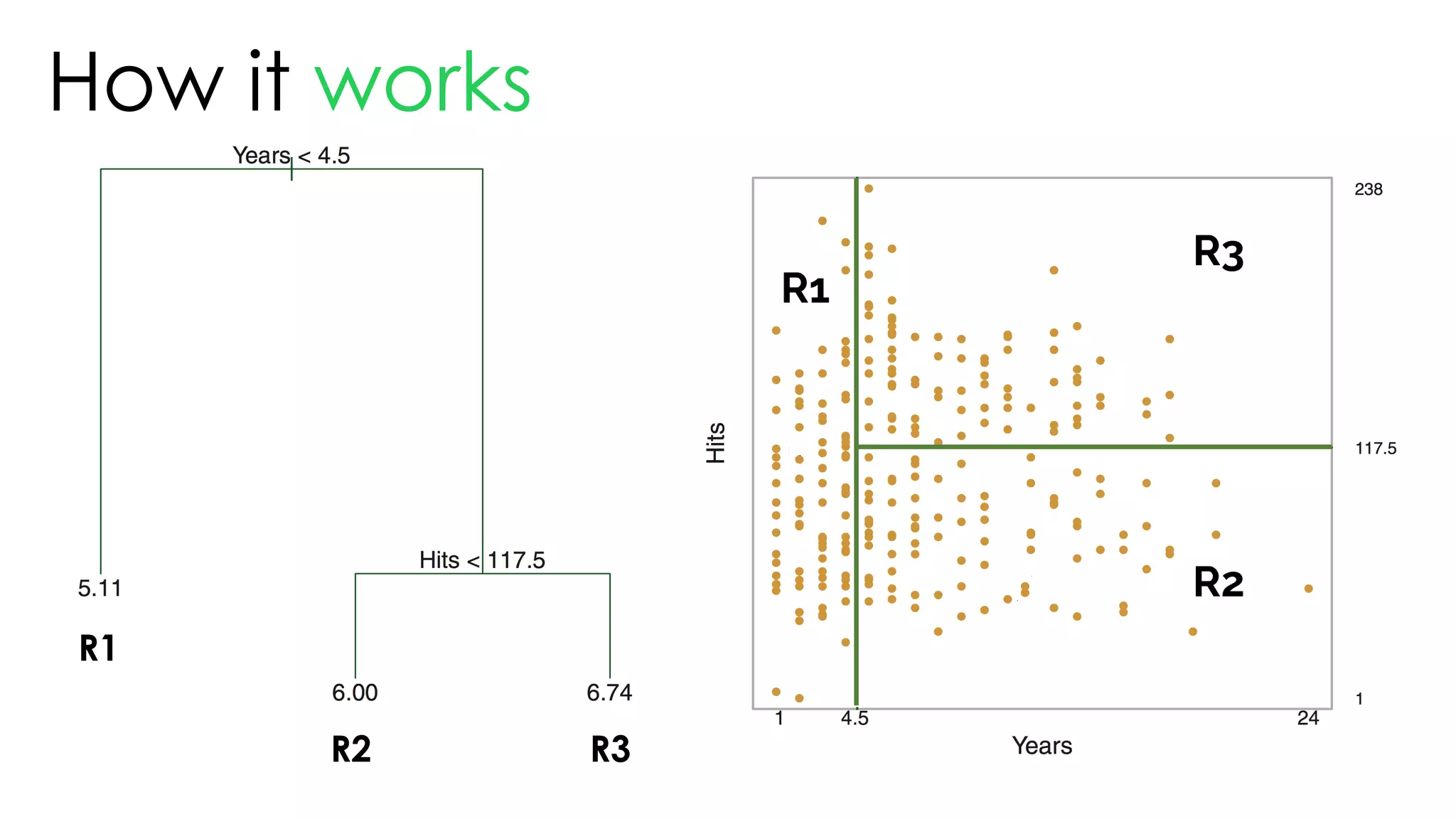



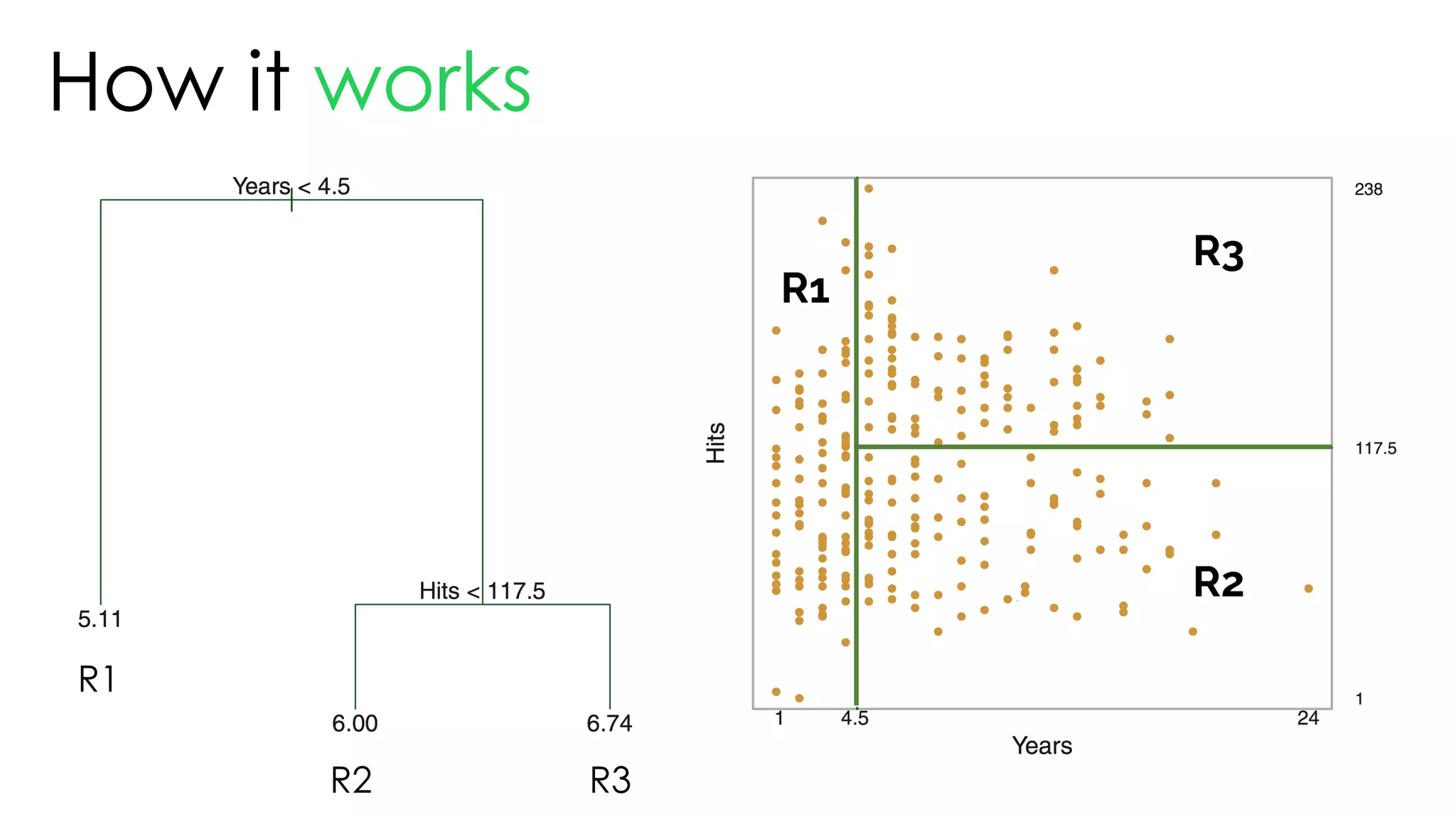


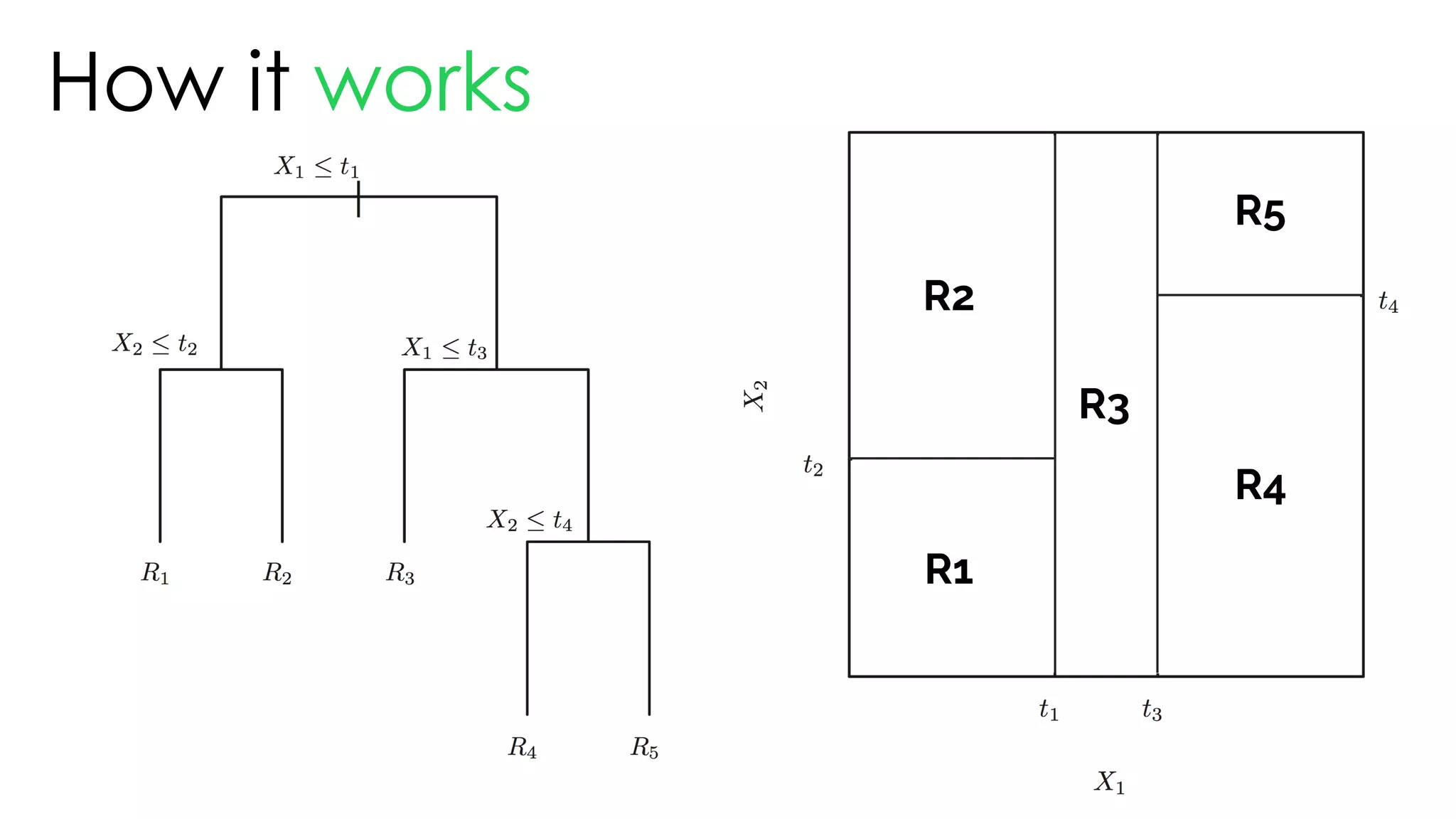
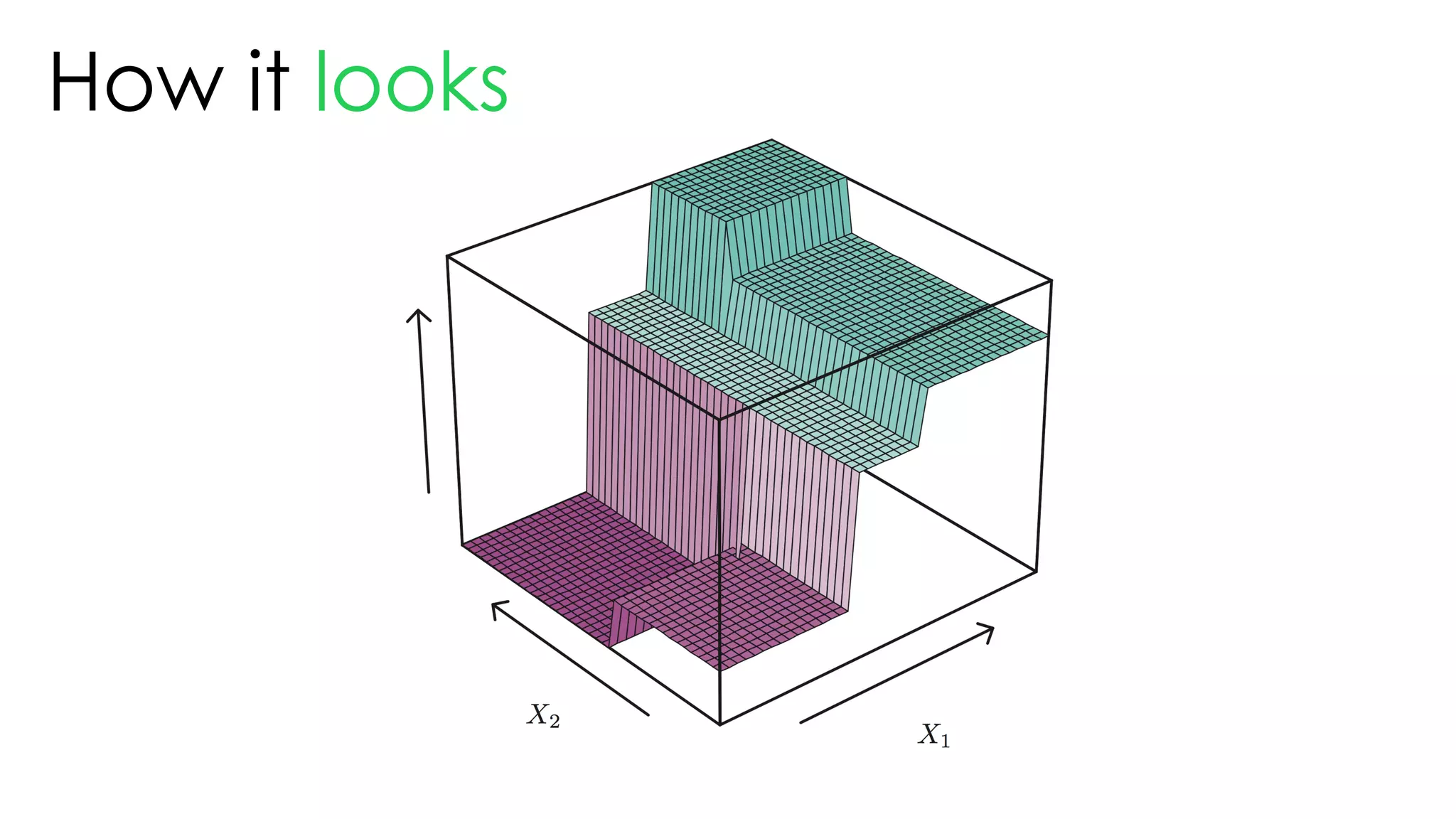
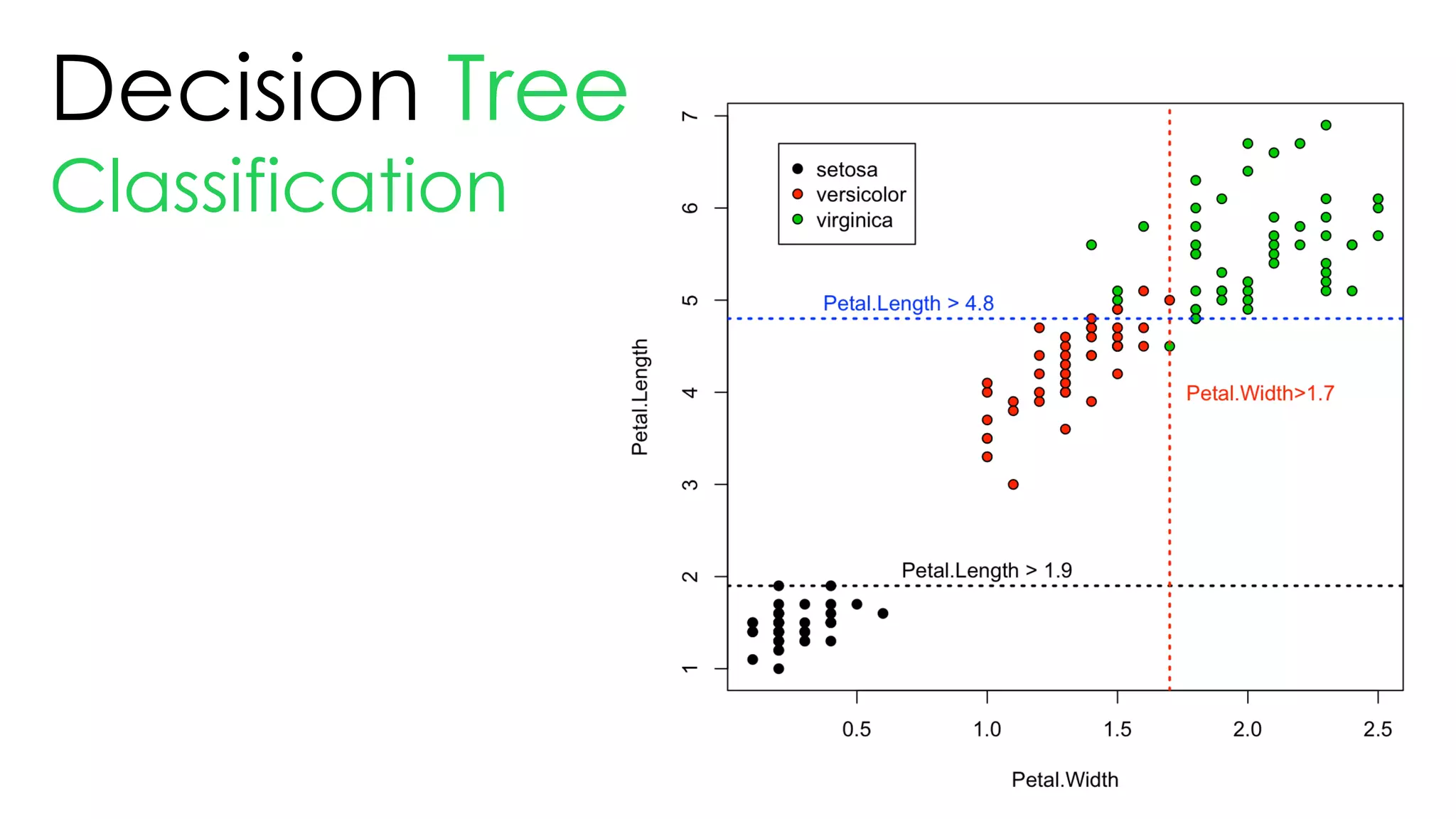
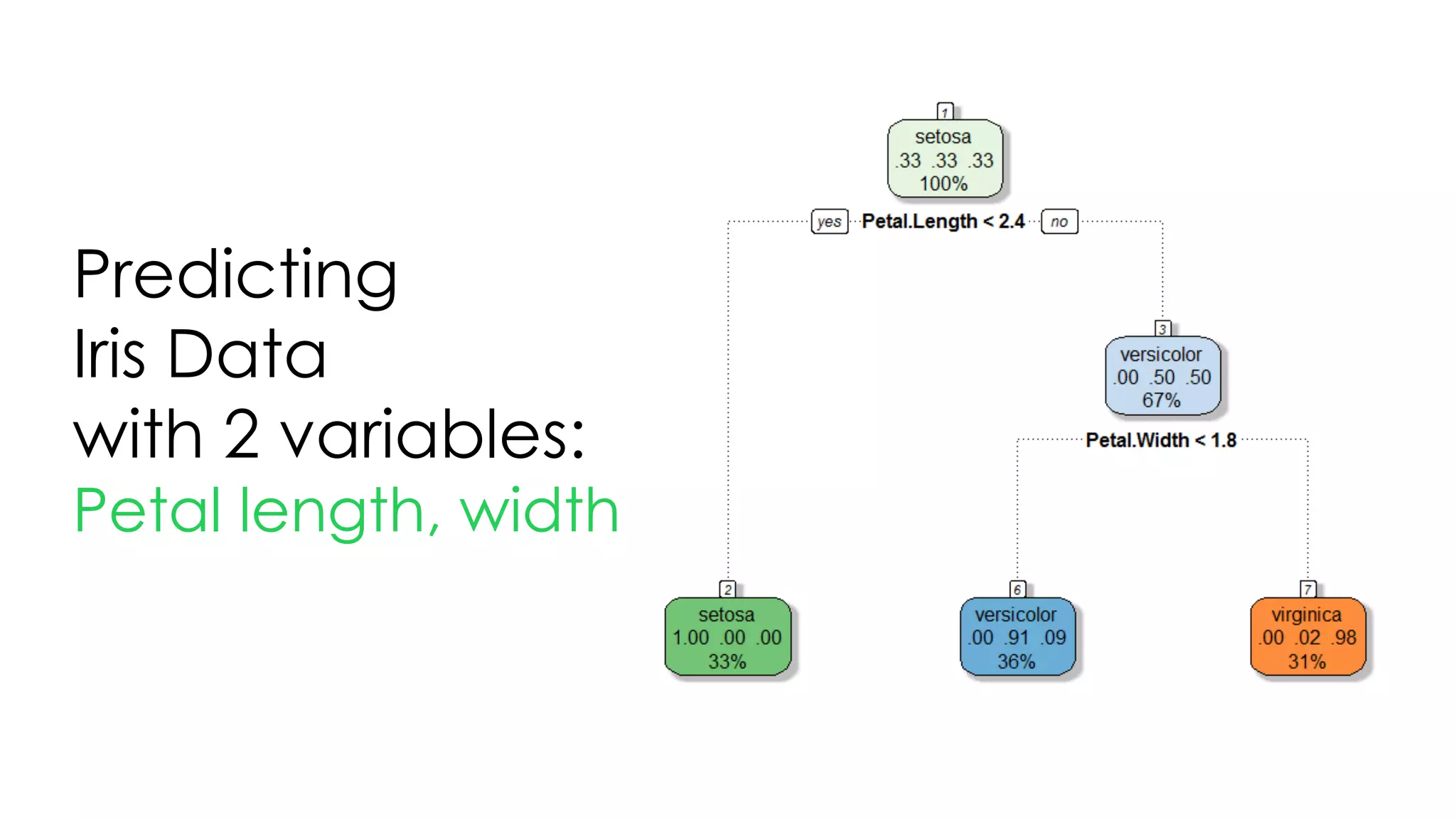


























![Tree
& advantages
1. 이해하기 쉽다: 씹고 뜯고 맛보고 즐기고 [White box]
2. 데이터 정제가 크게 필요하지 않다: 바로 넣자
3. numerical, categorical 가리지 않는다: 그냥 넣자
4. 데이터가 어떤 패턴인지 볼 때 편하다: 넣어봐](https://image.slidesharecdn.com/thetreeslideshare-170922160319/75/Decision-Tree-Intro-72-2048.jpg)











































































![Tree
& advantages
1. 이해하기 쉽다: 씹고 뜯고 맛보고 즐기고 [White box]
2. 데이터 정제가 크게 필요하지 않다: 바로 넣자
3. numerical, categorical 가리지 않는다: 그냥 넣자
4. 데이터가 어떤 패턴인지 볼 때 편하다: 넣어봐](https://crownmelresort.com/image.slidesharecdn.com/thetreeslideshare-170922160319/75/Decision-Tree-Intro-72-2048.jpg)




![[211] 네이버 검색과 데이터마이닝](https://cdn.slidesharecdn.com/ss_thumbnails/211-150915001301-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SOPT] 데이터 구조 및 알고리즘 스터디 - #04 : 트리 기초, 이진 트리, 우선순위 큐](https://cdn.slidesharecdn.com/ss_thumbnails/4-151013103145-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


![[분석]텔레마틱스를 이용한 자동차 운전자 프로필 생성](https://cdn.slidesharecdn.com/ss_thumbnails/random-151119122606-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
























![Random Forest Intro [랜덤포레스트 설명]](https://cdn.slidesharecdn.com/ss_thumbnails/theforestslideshare-170924111713-thumbnail.jpg?width=640&height=640&fit=bounds)





![Neural Network Intro [인공신경망 설명]](https://cdn.slidesharecdn.com/ss_thumbnails/neuralnetworkfinale-170924112506-thumbnail.jpg?width=640&height=640&fit=bounds)



























