



















































The document discusses association rules and how they are used for discovering relationships between variables in databases, particularly through methodologies like the apriori algorithm. It explains key concepts such as support, confidence, and lift, which help in identifying useful product associations for marketing and recommendation engines. Practical applications are highlighted, including insights into grocery shopping patterns and analysis of voting behaviors in politics.
Presented by Derek Kane.
Key concepts of Association Rules including Support, Confidence, Lift, the Apriori Algorithm, examples like Grocery Shopping.
Methodologies for finding relationships in data, explained with an example: buying combinations like Peanut Butter and Jelly.
Applications in various fields such as recommendations in retail, politics, medical diagnosis, etc.
Using association rules for store layout, marketing and cross-selling based on purchasing patterns.
Netflix improved predictions by 10%, increasing revenue from $5 million to $3.2 billion due to analytics.
Format of association rules, LHS and RHS explained with an example of buying coffee leading to milk.
Importance of support, confidence, and lift as essential measures prior to analyzing association rules.
Support definition with an example. High support rules indicate significant purchasing relationships.
Definition of confidence with an example calculation of the likelihood of a rule based on transaction data.
Definition of lift, calculations, and interpretations. A lift greater than 1 indicates positive associations.
Introduction to the Apriori algorithm, its theorem, and its two-step process for mining association rules.
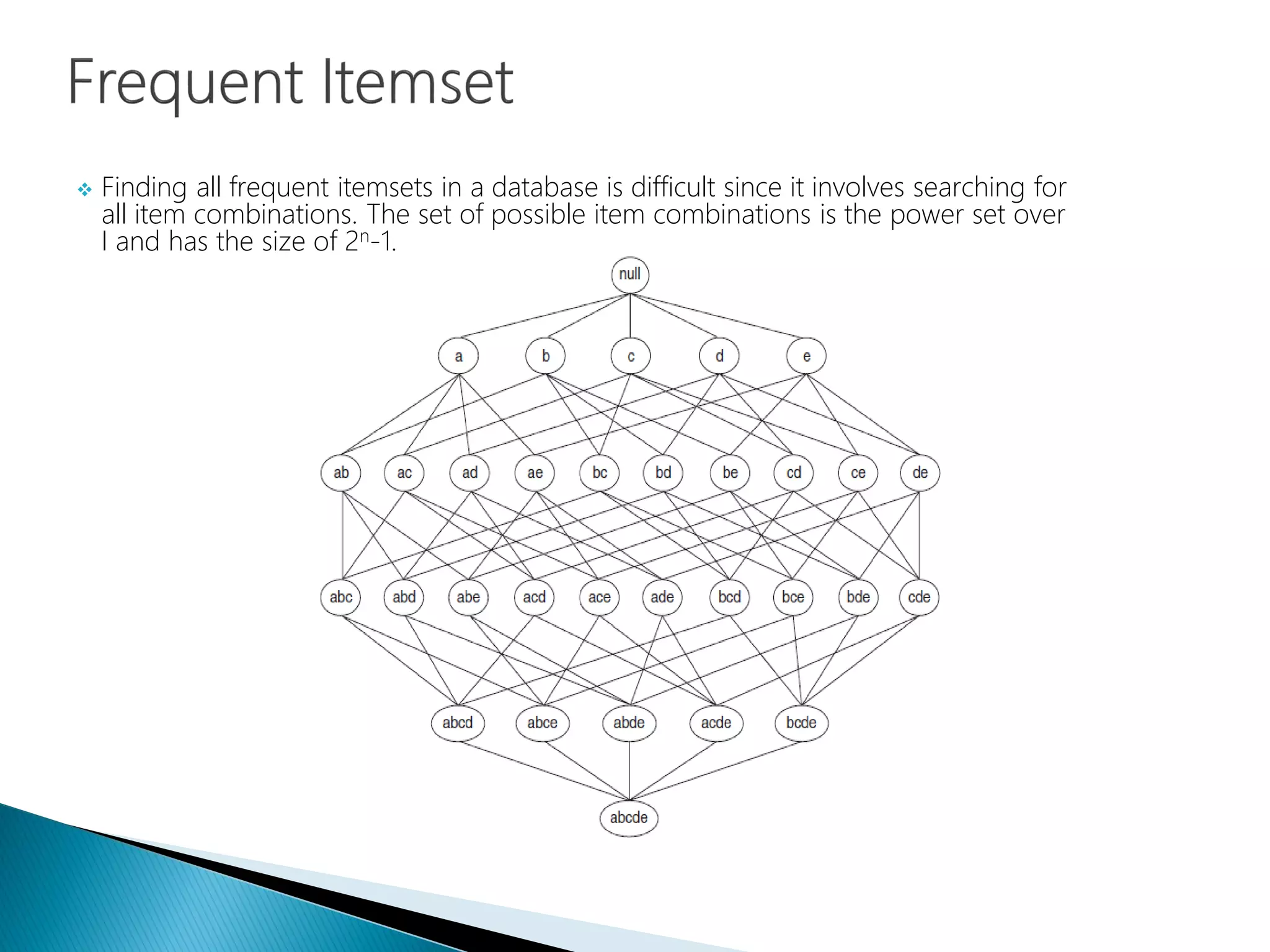
Difficulty in finding frequent itemsets due to the large power set of items in the database.
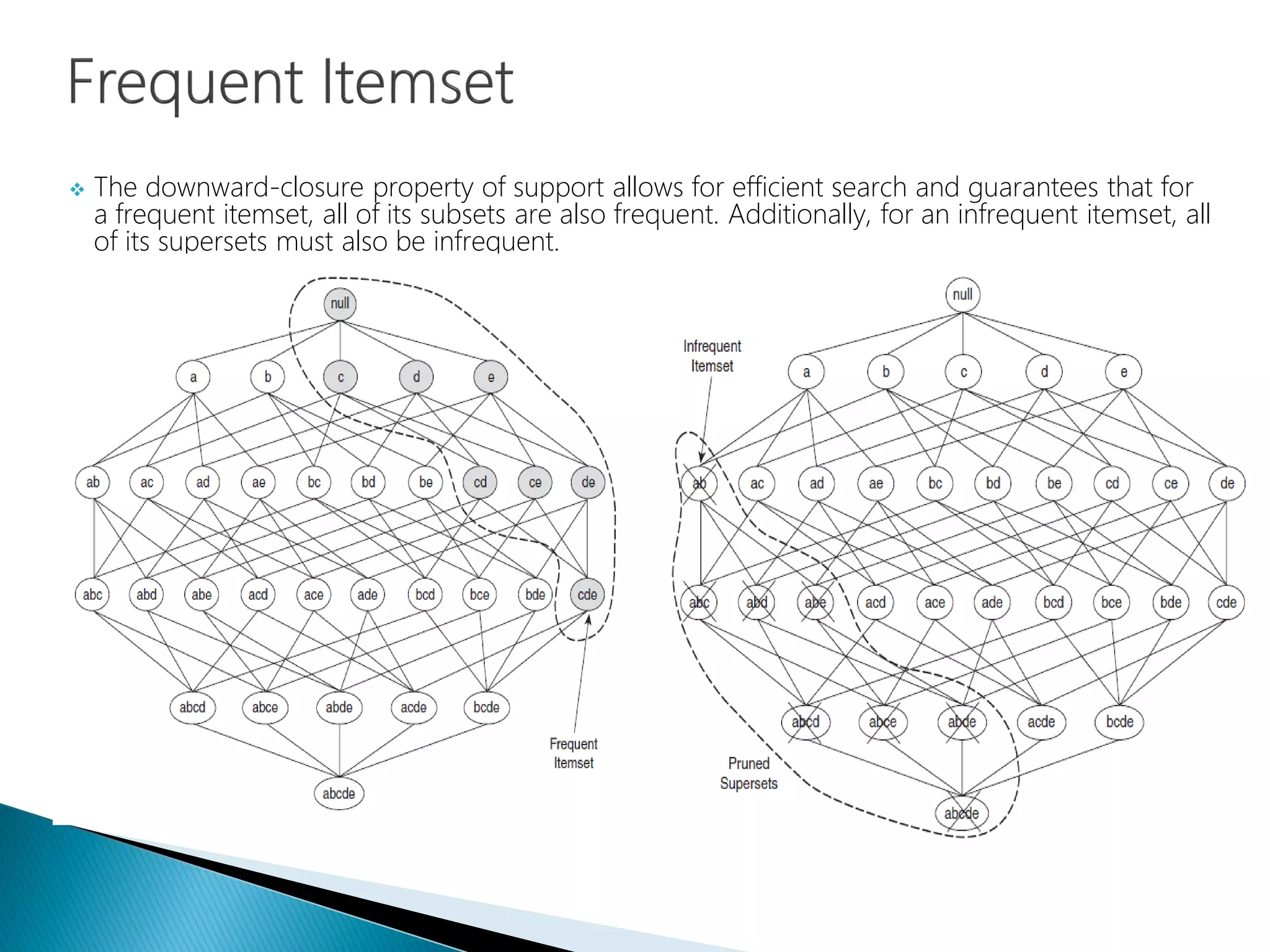
Explanation of downward closure property for efficient itemset support searching.
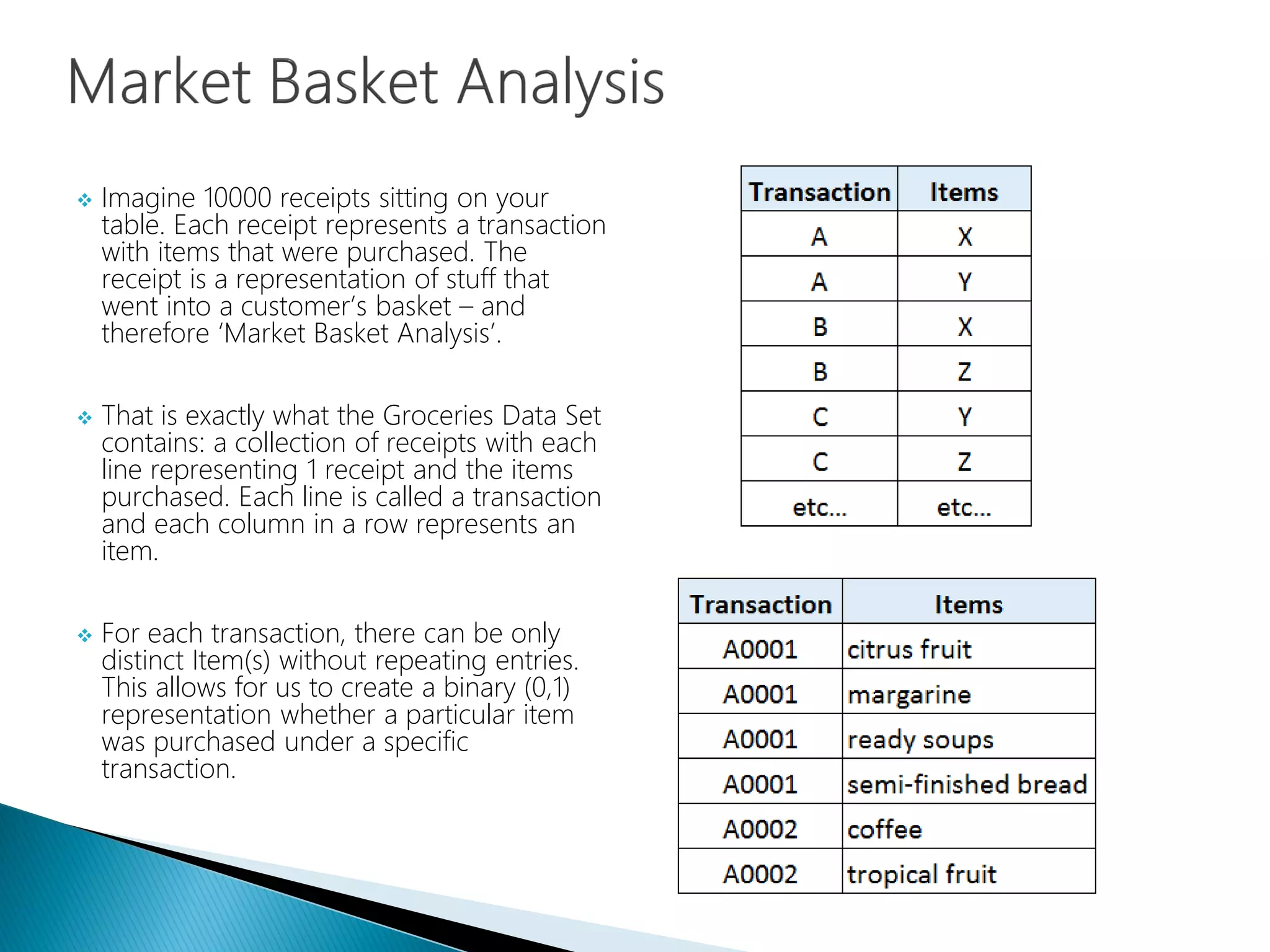
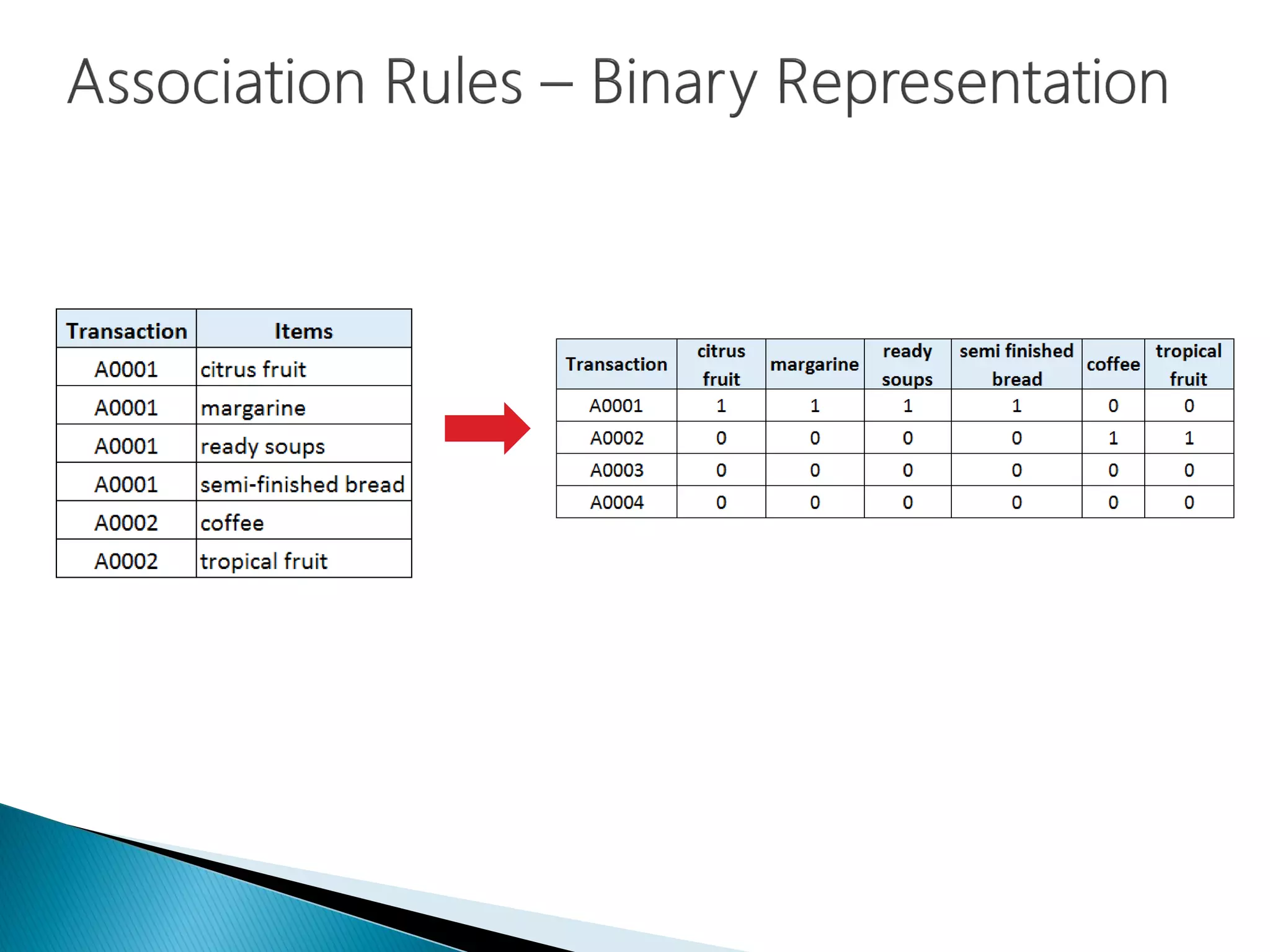
Overview of market basket analysis using transactional receipts for item correlation.
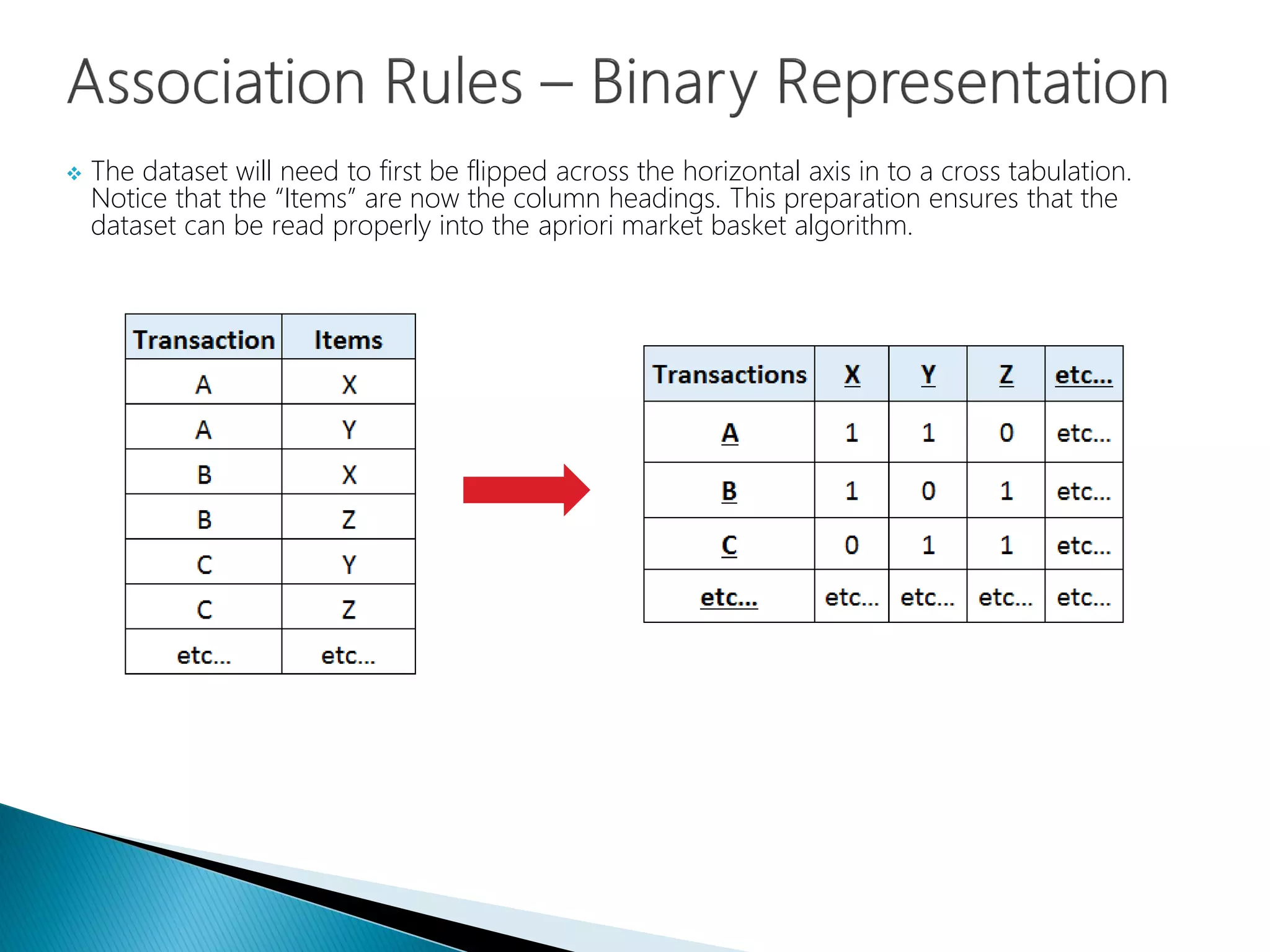
Data transformation to cross-tabulation to facilitate input into the Apriori algorithm.
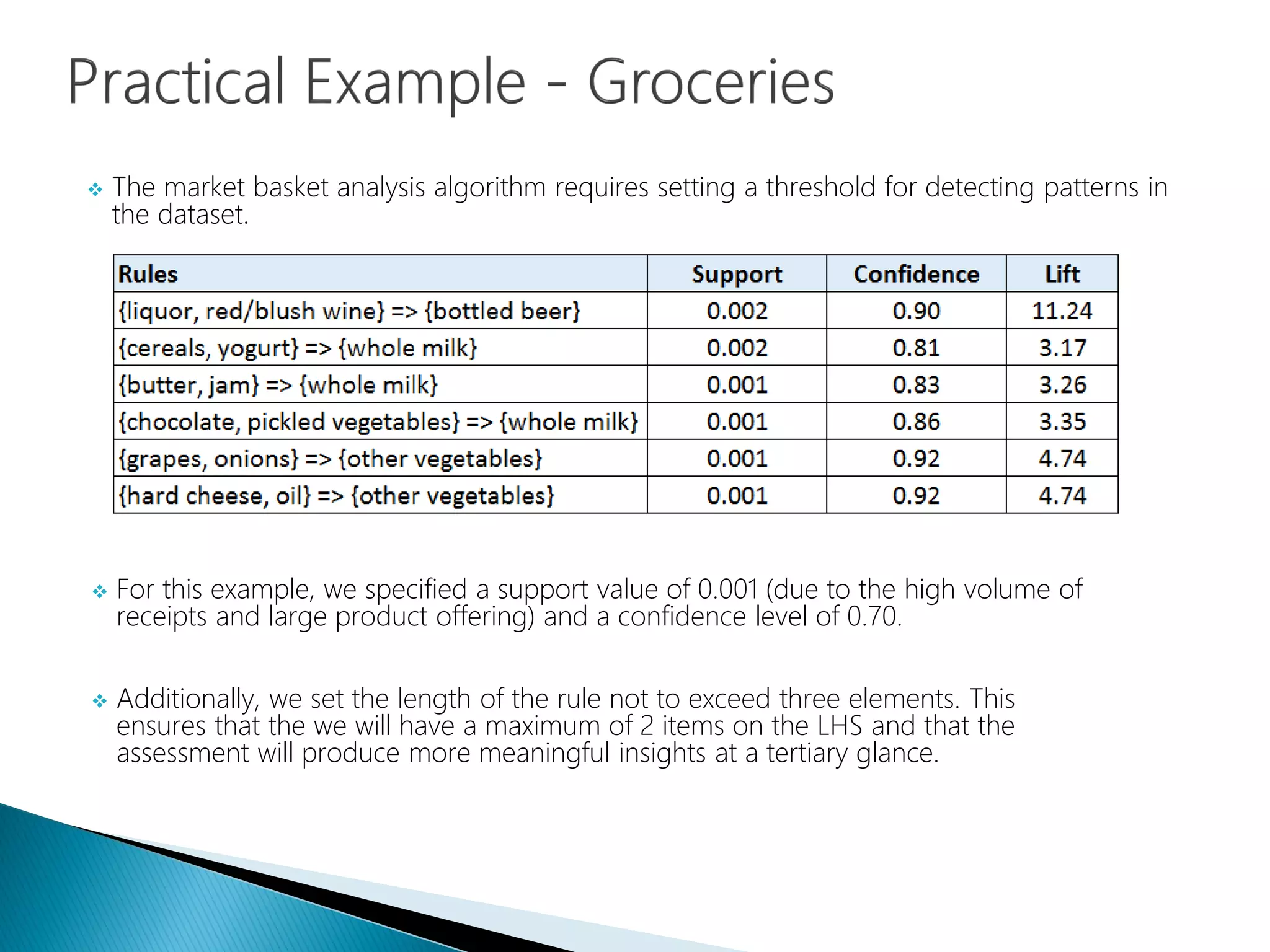
Threshold settings for support, confidence, and rule length in market basket analysis.
Need for businesses to experiment with different parameters to optimize rule generation.
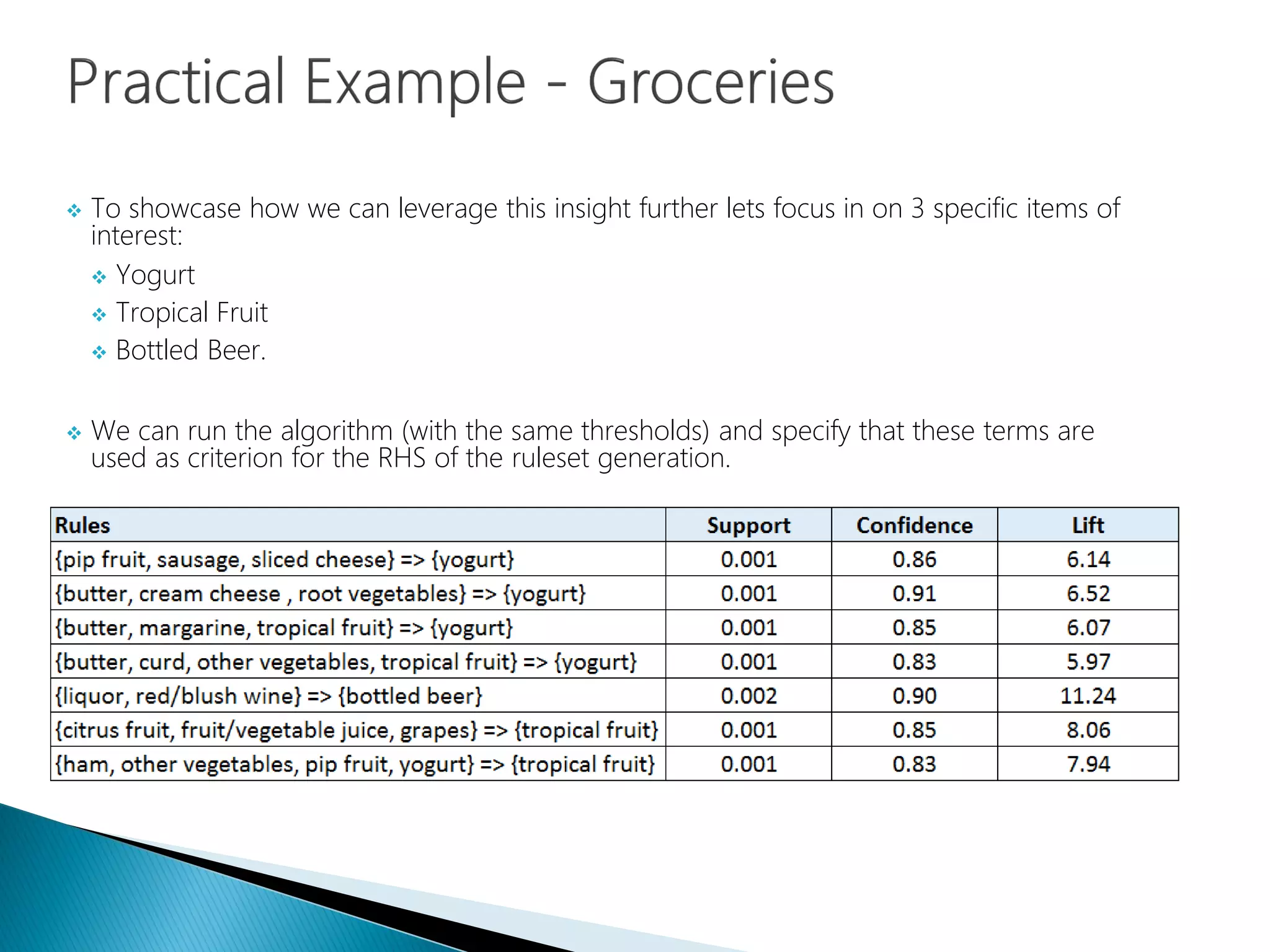
Focusing on three items: Yogurt, Tropical Fruit, and Bottled Beer for association rule generation.
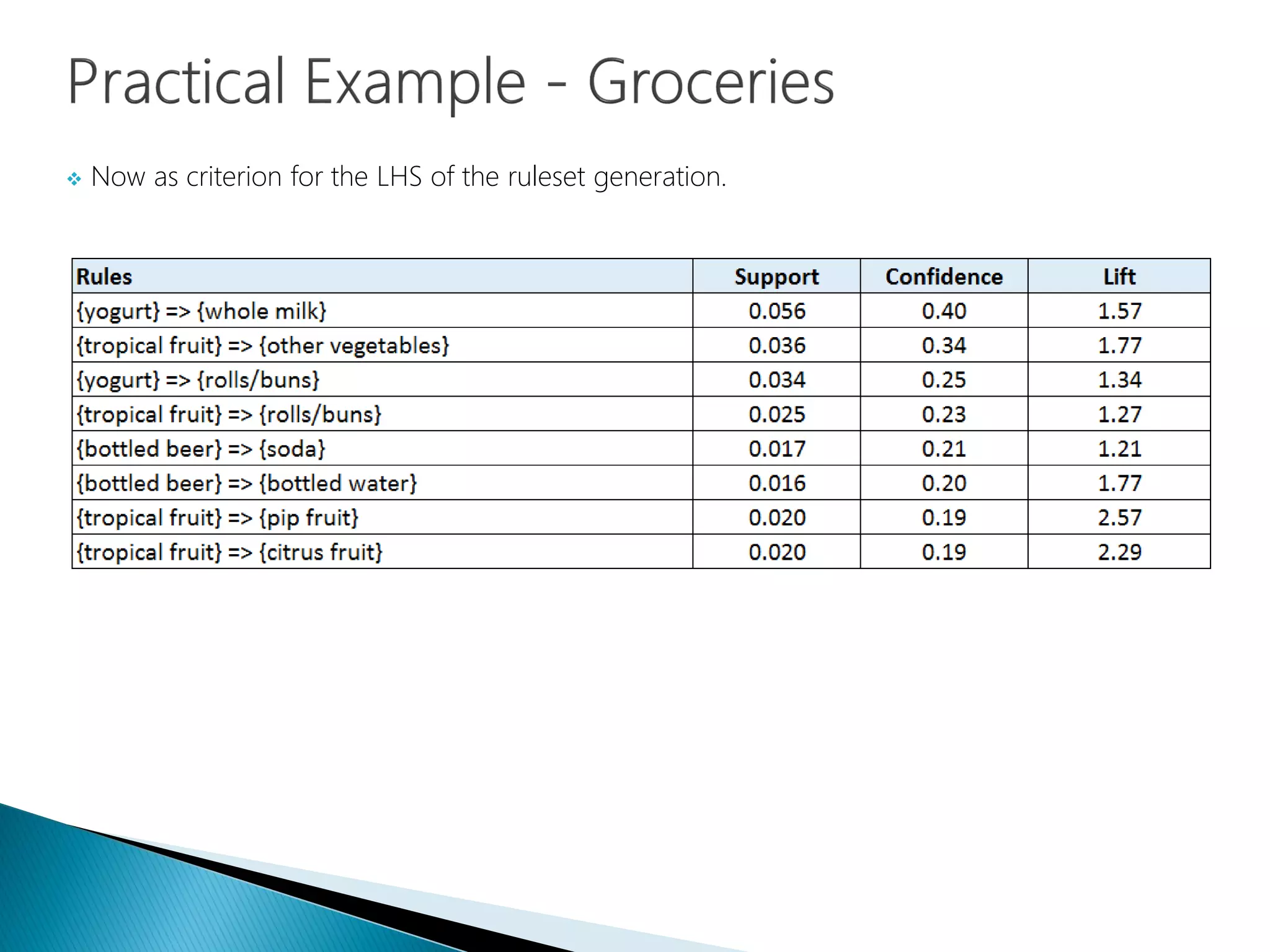
Using items as criterion for LHS to test association rules.
Understanding that co-occurrences may be influenced by presentation, not just association.
Leveraging market basket analysis results for targeted marketing and recommendation strategies.
Using co-occurrence data to inform site organization, product placements, and recommendations.
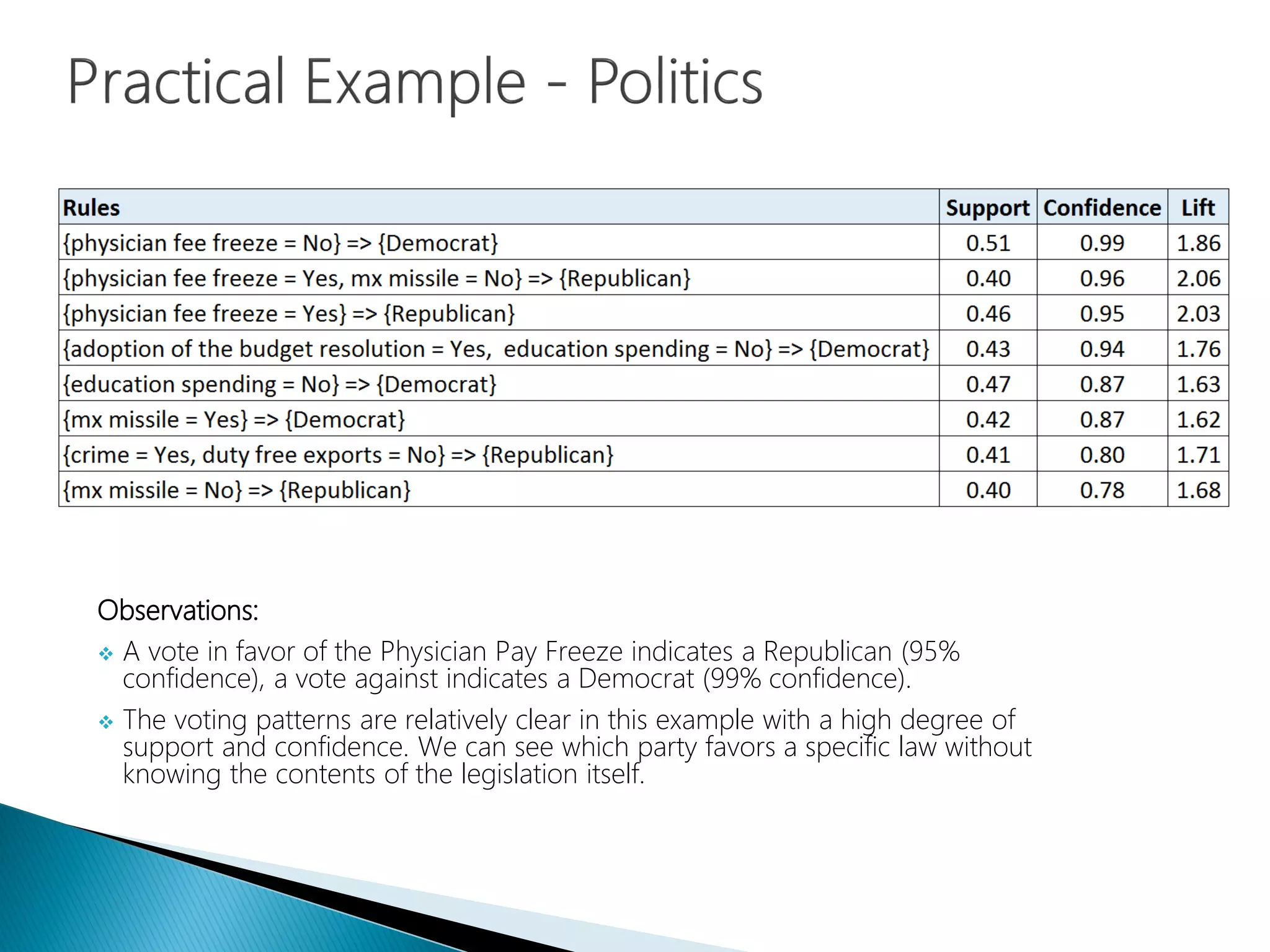
Applying association analysis to U.S. House voting records database for political insights.
Inference about voting patterns indicating party affiliations with high confidence metrics.
Personal details about Derek Kane including hobbies and interests.





























































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


















