Download to read offline




![6
Data Prep is time-consuming!
Source: CrowdFlower, 2015
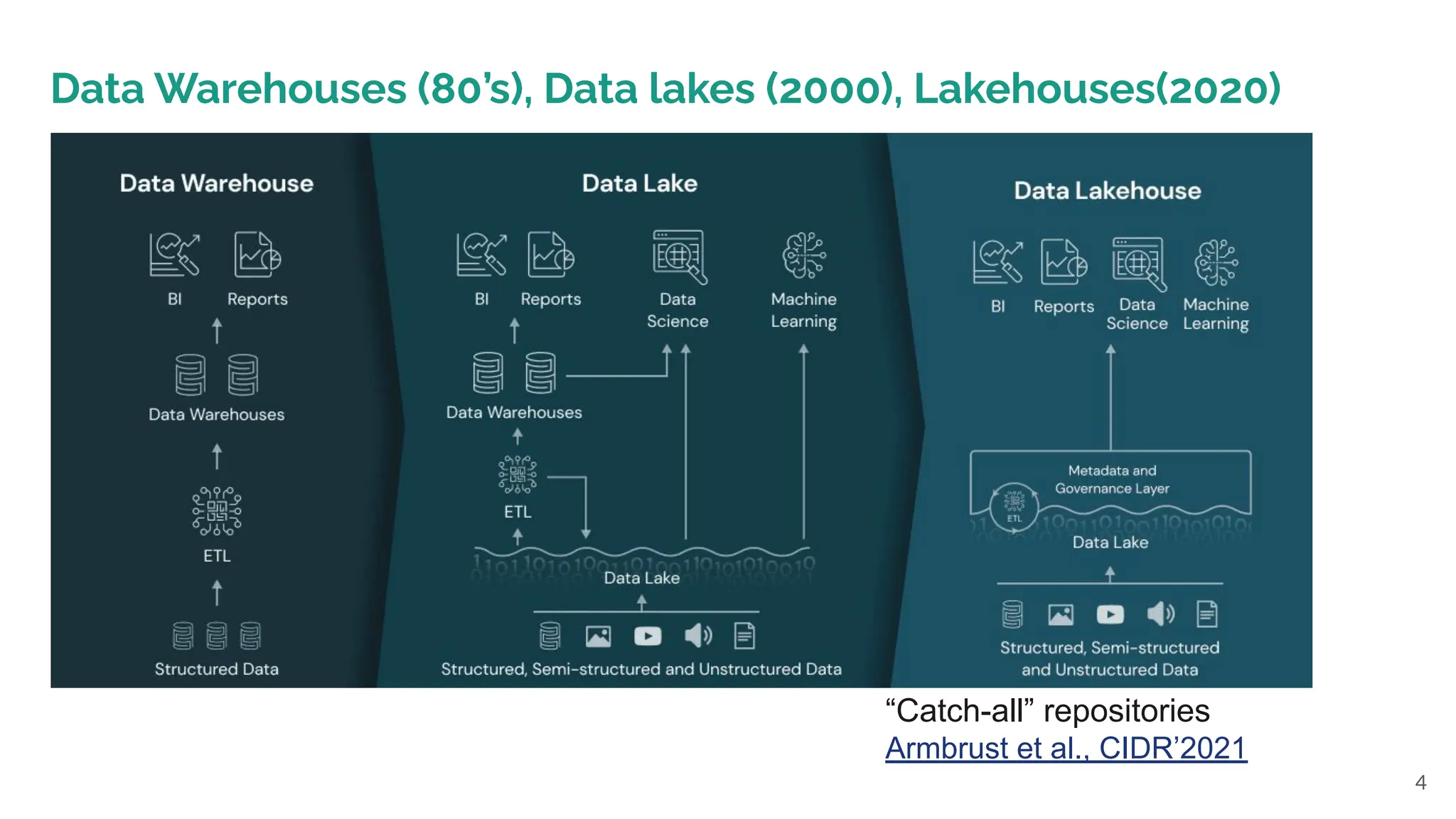
Data to insights pipeline. Data science pipelines are often
complex with several stages, each with many participants.
One team prepares the data, sourced from heterogeneous
data sources in data lakes. Another team builds models on
the data. Finally, end users access the data and models
through interactive dashboards. The database community
needs to develop simple and efficient tools that support
building and maintaining data pipelines. Data scientists
repeatedly say that data cleaning, integration, and
transformation together consume 80%-90% of their
time. These are problems the database community has
experienced in the context of enterprise data for decades.
However, much of our past efforts focused on solving
algorithmic challenges for important “point problems,” such
as schema mapping and entity resolution. Moving forward,
we must adapt our community’s expertise in data cleaning,
integration, and transformation to aid the iterative
end-to-end development of the data-to-insights pipeline.
Source: The Seattle Database Report, 2022 [1]](https://image.slidesharecdn.com/isncc2024-1-241217104706-93390a39/75/data-pipelines-complexity-human-expertise-and-LLM-era-6-2048.jpg)




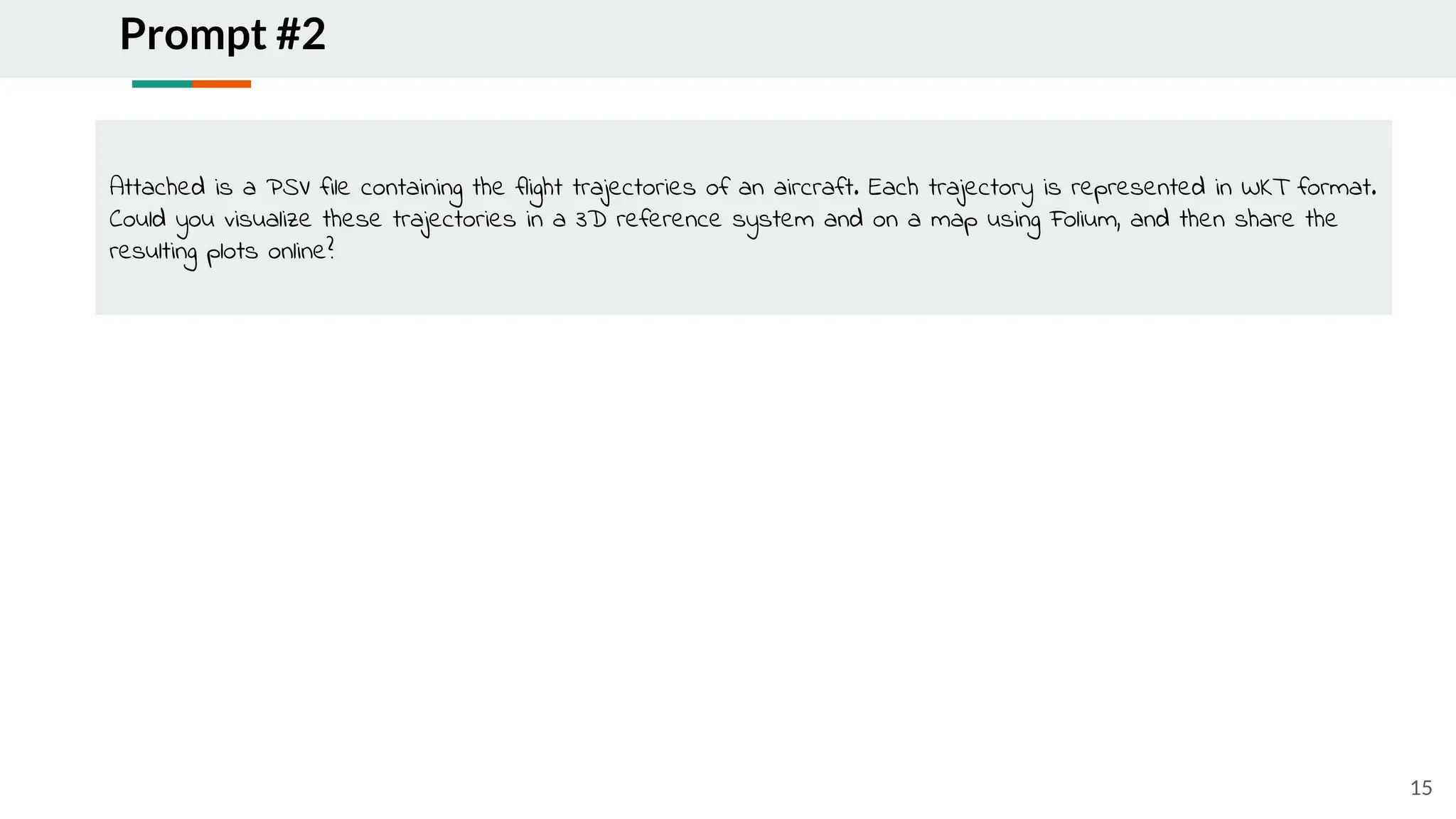
![Prompt #1
14
Attached two csv files in google drive link [...], in dropbox link [...]
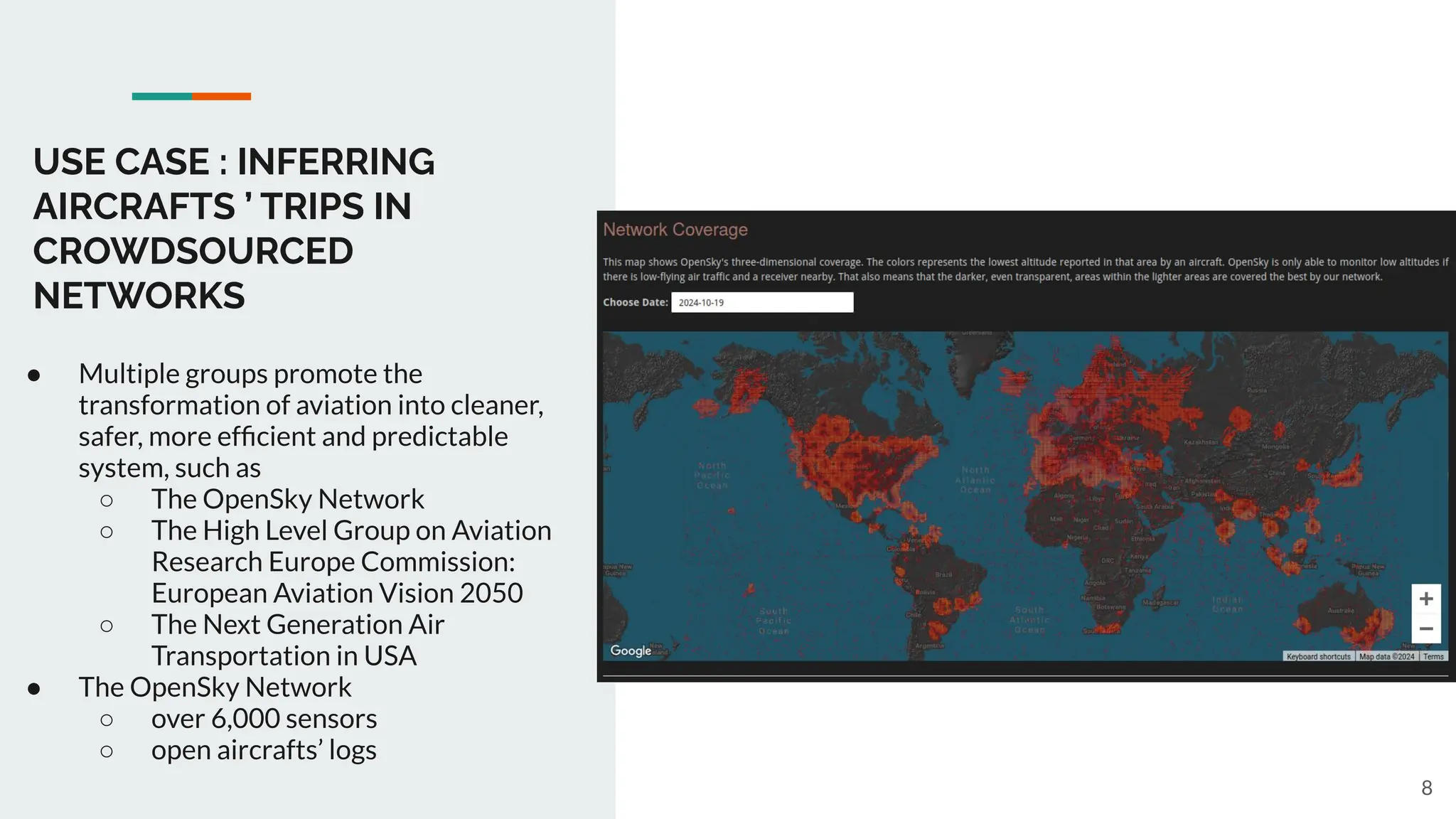
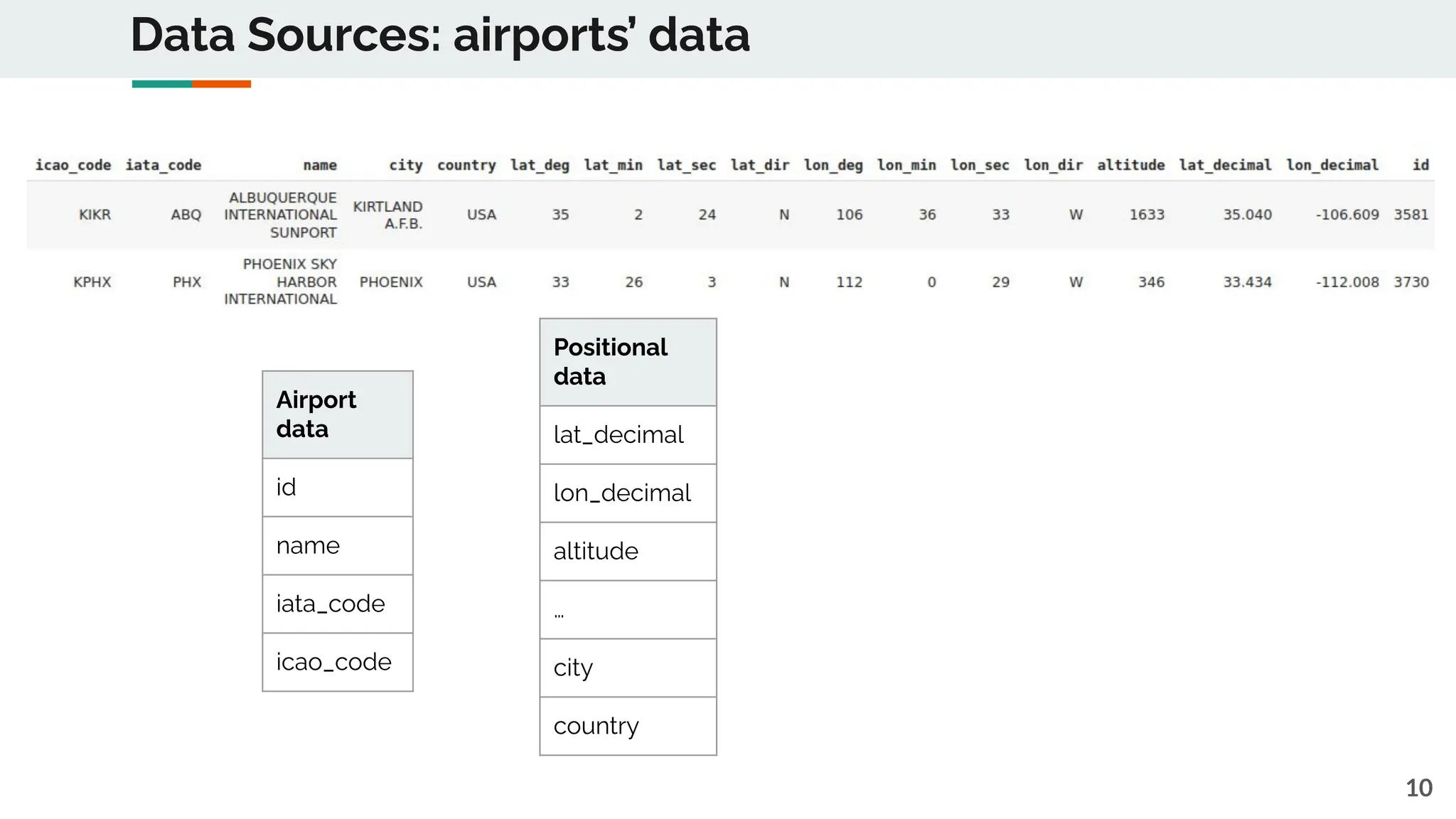
The first file "airports.csv" is a dataset of airports. Each airport is identified by an id, is located in a country, and
each airport is located in a 3d reference system given its decimal longitude ('lon decimal' column), decimal latitude
('lat_decimal' column), and its altitude ('altitude' column).
The second file "logs.csv" is an extract of logs captured by the open sky network during one day. Each entry
denotes the
position of an aircraft, identified by the column 'icao24', in a 3d reference system given latitude ('lat' column),
longitude ('lon' column) and 'geoaltitude' column.
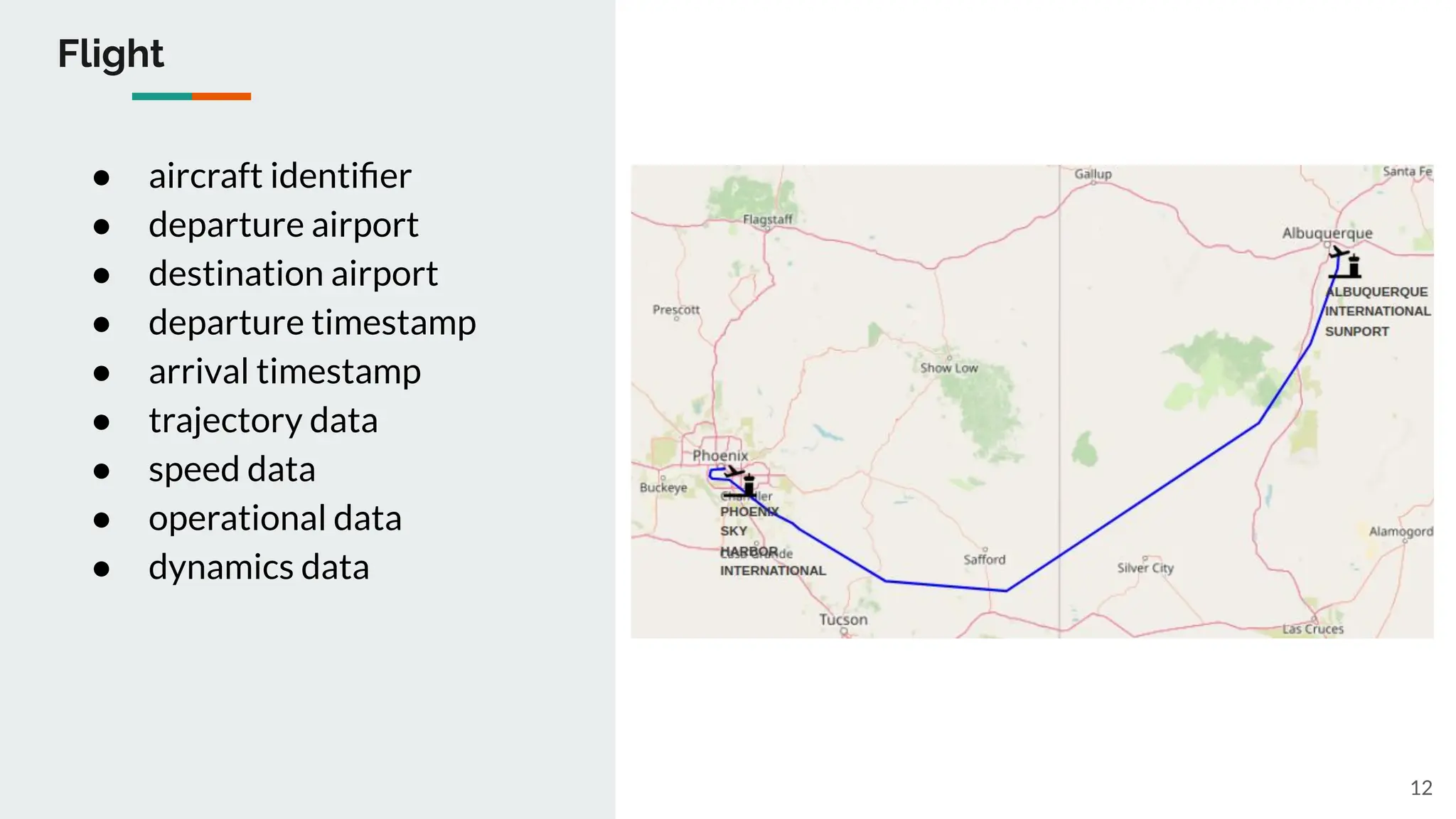
We want to infer the flight(s) details performed by each aircraft, determine the departure airport (takeoff event),
the arrival
airport (landing event), the first recorded timestamp, the last recorded timestamp, the duration calculated as last
recorded
timestamp minus first recorded timestamp.
Notice that for some flights, the departure airport and/or the arrival airport are unknown, consequently we could
only
extract a part of the trajectory. There are four types of inferred flights:
_type 0: a flight such that the departure airport is unknown, and the arrival airport is known
_type 1: a flight such that both departure and arrival airports are known
_type 2: a flight such that the departure airport is known, and the arrival airport is unknown
_type 3: a flight such that both departure and arrival airports are known.
-1 denotes an unknown airport either for departure or arrival.
Could you propose a solution using [....], incorporating the inferred flights derived from the shared datasets?](https://image.slidesharecdn.com/isncc2024-1-241217104706-93390a39/75/data-pipelines-complexity-human-expertise-and-LLM-era-14-2048.jpg)

![Related Work
20
● Description Languages [3]
● Data Quality [4]–[5]
● Frameworks Apache Airflow, Dagster,...
● Implementation technologies
● Apache Hadoop -Pig Latin, Apache Spark, Nvidia RAPIDS NVTabular, …
● AutoETL [10], generate pre-processing pipelines.
● Auto-Pipeline [11], synthesize pipelines using deep reinforcement-learning.
● Pipemizer [13] - improve the performance of queries or jobs in pipeline at
Microsoft.
● LLM: [17] and [18], respectively describe LLM as aim to combine human expertise
with LLM-driven automation and to achieve a favorable cost-optimization balance in
data pipeline engineering.
● Benchmarking
● keep the pipeline cost-effective, and manage the resources, such as storage,
compute power, and network bandwidth,](https://image.slidesharecdn.com/isncc2024-1-241217104706-93390a39/75/data-pipelines-complexity-human-expertise-and-LLM-era-20-2048.jpg)

![References
[1] D. Abadi, A. Ailamaki, D. G. Andersen, P. Bailis, M. Balazinska, P. A. Bernstein, P. A. Boncz, S. Chaudhuri, A. Cheung, A. Doan, L.
Dong, M. J. Franklin, J. Freire, A. Y. Halevy, J. M. Hellerstein, S. Idreos, D. Kossmann, T. Kraska, S. Krishnamurthy, V. Markl, S.
Melnik, T. Milo, C. Mohan, T. Neumann, B. C. Ooi, F. Ozcan, J. M. Patel, A. Pavlo, R. A. Popa, R. Ramakrishnan, C. Ré, M.
Stonebraker, and D. Suciu, “The seattle report on database research,” Commun. ACM, vol. 65, no. 8, pp. 72–79, 2022. ↬
[2] Mattias Schaffer and Vincent Lenders and Ivan Martinovis, “OpenSky Network: Open Air Traffic Data for Research,”
https://opensky-network.org/, online; accessed 10 August 2024..
[3] C. Nielsen, Z. Su, and G. Indiveri, “Yak: An asynchronous bundled data pipeline description language,” in 28th IEEE International
Symposium on Asynchronous Circuits and Systems, ASYNC 2023, Beijing, China, July 16-19, 2023. IEEE, 2023, pp. 34–41.
[4] H. Foidl, V. Golendukhina, R. Ramler, and M. Felderer, “Data pipeline quality: Influencing factors, root causes of data-related
issues, and processing problem areas for developers,” J. Syst. Softw., vol. 207, p. 111855, 2024.
[5] F. J. de Haro-Olmo, Á. Valencia-Parra, Á. J. VarelaVaca, J. A. Álvarez-Bermejo, and M. T. Gómez-López, “ELI: an iot-aware big
data pipeline with data curation and data quality,” PeerJ Comput. Sci., vol. 9, p. e1605, 2023. [Online]. Available:
https://doi.org/10.7717/peerj-cs.1605
[6] P. Maymounkov, “Koji: Automating pipelines with mixed-semantics data sources,” CoRR, vol. abs/1901.01908, 2019. [Online].
Available: http://arxiv.org/abs/1901.01908
22](https://image.slidesharecdn.com/isncc2024-1-241217104706-93390a39/75/data-pipelines-complexity-human-expertise-and-LLM-era-22-2048.jpg)
![References
[7] S. Redyuk, Z. Kaoudi, S. Schelter, and V. Markl, “DORIAN in action: Assisted design of data science pipelines,” Proc. VLDB
Endow., vol. 15, no. 12, pp.3714–3717, 2022.
[8] G. Vargas-Solar, K. Belhajjame, J. Espinosa-Oviedo, S. Negrete-Yankelevich, and J. Zechinelli-Martini, “MATILDA: inclusive
data science pipelines design through computational creativity,” in Proceedings of the Workshops of the EDBT/ICDT Joint
Conference, vol. 3651, 2024. [Online]. Available: https://ceur-ws.org/Vol-3651/DARLI-AP-11.pdf
[9] Z. Liu, T. Hoang, J. Zhang, M. Zhu, T. Lan, S. Kokane, J. Tan, W. Yao, Z. Liu, Y. Feng, R. Murthy, L. Yang, S. Savarese, J. C. Niebles,
H. Wang, S. Heinecke, and C. Xiong, “Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets,”
CoRR, vol. abs/2406.18518, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2406.18518
[10] J. Giovanelli, B. Bilalli, and A. Abelló, “Data preprocessing pipeline generation for autoetl,” Inf. Syst., vol. 108, p. 101957,
2022.
[11] J. Yang, Y. He, and S. Chaudhuri, “Autopipeline: Synthesize data pipelines by-target using reinforcement learning and
search,” CoRR, vol. abs/2106.13861, 2021. [Online]. Available: https://arxiv.org/abs/2106.13861
[12] Z. Miao, “Simplifying human-in-the-loop data science pipeline: Explanations, debugging, and data preparation,” Ph.D.
dissertation, Duke University, Durham, NC, USA, 2022. [Online]. Available: https://hdl.handle.net/10161/26796
[13] S. Gakhar, J. Cahoon, W. Le, X. Li, K. Ravichandran, H. Patel, M. T. Friedman, B. Haynes, S. Qiao, A. Jindal, and J. Leeka,
“Pipemizer: An optimizer for analytics data pipelines,” Proc. VLDB Endow., vol. 15, no. 12, pp. 3710–3713, 2022.
23](https://image.slidesharecdn.com/isncc2024-1-241217104706-93390a39/75/data-pipelines-complexity-human-expertise-and-LLM-era-23-2048.jpg)
![References
[14] M. Dareck, C. Edelstenne, T. Enders, E. Fernandez, J.-P. Herteman, M. Kerkloh, I. King, P. Ky, M. Mathieu, G. Orsi, G.
Schotman, C. Smith, and J.-D. Worner, “FlightPath 2050: Europe’s Vision for Aviation -Maintaining Global Leadership and Serving
Society’s Needs,” http://www.sesarju.eu/ , 2010, online; accessed 10 August 2024.
[15] European Union and EuroControl and SESAR, “The DART Project: Data-Driven Aircraft Trajectory Prediction Research,”
http://dart-research.eu/ , online; accessed 10 August 2024.
[16] US NextGen, “Modernization of United States Airspace,” https://www.faa.gov/nextgen/ , 2019, online; accessed 10 August
2024.
[17] A. Remadi, K. E. Hage, Y. Hobeika, and F. Bugiotti, “To prompt or not to prompt: Navigating the use of large language models for
integrating and modeling heterogeneous data,” Data Knowl. Eng., vol. 152, p. 102313, 2024.
[18] S. Arora, B. Yang, S. Eyuboglu, A. Narayan, A. Hojel, I. Trummer, and C. Ré, “Language models enable simple systems for
generating structured views of heterogeneous data lakes,” Proc. VLDB Endow., vol. 17, no. 2, pp. 92–105, 2023.
24](https://image.slidesharecdn.com/isncc2024-1-241217104706-93390a39/75/data-pipelines-complexity-human-expertise-and-LLM-era-24-2048.jpg)






![6
Data Prep is time-consuming!
Source: CrowdFlower, 2015
Data to insights pipeline. Data science pipelines are often
complex with several stages, each with many participants.
One team prepares the data, sourced from heterogeneous
data sources in data lakes. Another team builds models on
the data. Finally, end users access the data and models
through interactive dashboards. The database community
needs to develop simple and efficient tools that support
building and maintaining data pipelines. Data scientists
repeatedly say that data cleaning, integration, and
transformation together consume 80%-90% of their
time. These are problems the database community has
experienced in the context of enterprise data for decades.
However, much of our past efforts focused on solving
algorithmic challenges for important “point problems,” such
as schema mapping and entity resolution. Moving forward,
we must adapt our community’s expertise in data cleaning,
integration, and transformation to aid the iterative
end-to-end development of the data-to-insights pipeline.
Source: The Seattle Database Report, 2022 [1]](https://crownmelresort.com/image.slidesharecdn.com/isncc2024-1-241217104706-93390a39/75/data-pipelines-complexity-human-expertise-and-LLM-era-6-2048.jpg)







![Prompt #1
14
Attached two csv files in google drive link [...], in dropbox link [...]
The first file "airports.csv" is a dataset of airports. Each airport is identified by an id, is located in a country, and
each airport is located in a 3d reference system given its decimal longitude ('lon decimal' column), decimal latitude
('lat_decimal' column), and its altitude ('altitude' column).
The second file "logs.csv" is an extract of logs captured by the open sky network during one day. Each entry
denotes the
position of an aircraft, identified by the column 'icao24', in a 3d reference system given latitude ('lat' column),
longitude ('lon' column) and 'geoaltitude' column.
We want to infer the flight(s) details performed by each aircraft, determine the departure airport (takeoff event),
the arrival
airport (landing event), the first recorded timestamp, the last recorded timestamp, the duration calculated as last
recorded
timestamp minus first recorded timestamp.
Notice that for some flights, the departure airport and/or the arrival airport are unknown, consequently we could
only
extract a part of the trajectory. There are four types of inferred flights:
_type 0: a flight such that the departure airport is unknown, and the arrival airport is known
_type 1: a flight such that both departure and arrival airports are known
_type 2: a flight such that the departure airport is known, and the arrival airport is unknown
_type 3: a flight such that both departure and arrival airports are known.
-1 denotes an unknown airport either for departure or arrival.
Could you propose a solution using [....], incorporating the inferred flights derived from the shared datasets?](https://crownmelresort.com/image.slidesharecdn.com/isncc2024-1-241217104706-93390a39/75/data-pipelines-complexity-human-expertise-and-LLM-era-14-2048.jpg)





![Related Work
20
● Description Languages [3]
● Data Quality [4]–[5]
● Frameworks Apache Airflow, Dagster,...
● Implementation technologies
● Apache Hadoop -Pig Latin, Apache Spark, Nvidia RAPIDS NVTabular, …
● AutoETL [10], generate pre-processing pipelines.
● Auto-Pipeline [11], synthesize pipelines using deep reinforcement-learning.
● Pipemizer [13] - improve the performance of queries or jobs in pipeline at
Microsoft.
● LLM: [17] and [18], respectively describe LLM as aim to combine human expertise
with LLM-driven automation and to achieve a favorable cost-optimization balance in
data pipeline engineering.
● Benchmarking
● keep the pipeline cost-effective, and manage the resources, such as storage,
compute power, and network bandwidth,](https://crownmelresort.com/image.slidesharecdn.com/isncc2024-1-241217104706-93390a39/75/data-pipelines-complexity-human-expertise-and-LLM-era-20-2048.jpg)

![References
[1] D. Abadi, A. Ailamaki, D. G. Andersen, P. Bailis, M. Balazinska, P. A. Bernstein, P. A. Boncz, S. Chaudhuri, A. Cheung, A. Doan, L.
Dong, M. J. Franklin, J. Freire, A. Y. Halevy, J. M. Hellerstein, S. Idreos, D. Kossmann, T. Kraska, S. Krishnamurthy, V. Markl, S.
Melnik, T. Milo, C. Mohan, T. Neumann, B. C. Ooi, F. Ozcan, J. M. Patel, A. Pavlo, R. A. Popa, R. Ramakrishnan, C. Ré, M.
Stonebraker, and D. Suciu, “The seattle report on database research,” Commun. ACM, vol. 65, no. 8, pp. 72–79, 2022. ↬
[2] Mattias Schaffer and Vincent Lenders and Ivan Martinovis, “OpenSky Network: Open Air Traffic Data for Research,”
https://opensky-network.org/, online; accessed 10 August 2024..
[3] C. Nielsen, Z. Su, and G. Indiveri, “Yak: An asynchronous bundled data pipeline description language,” in 28th IEEE International
Symposium on Asynchronous Circuits and Systems, ASYNC 2023, Beijing, China, July 16-19, 2023. IEEE, 2023, pp. 34–41.
[4] H. Foidl, V. Golendukhina, R. Ramler, and M. Felderer, “Data pipeline quality: Influencing factors, root causes of data-related
issues, and processing problem areas for developers,” J. Syst. Softw., vol. 207, p. 111855, 2024.
[5] F. J. de Haro-Olmo, Á. Valencia-Parra, Á. J. VarelaVaca, J. A. Álvarez-Bermejo, and M. T. Gómez-López, “ELI: an iot-aware big
data pipeline with data curation and data quality,” PeerJ Comput. Sci., vol. 9, p. e1605, 2023. [Online]. Available:
https://doi.org/10.7717/peerj-cs.1605
[6] P. Maymounkov, “Koji: Automating pipelines with mixed-semantics data sources,” CoRR, vol. abs/1901.01908, 2019. [Online].
Available: http://arxiv.org/abs/1901.01908
22](https://crownmelresort.com/image.slidesharecdn.com/isncc2024-1-241217104706-93390a39/75/data-pipelines-complexity-human-expertise-and-LLM-era-22-2048.jpg)
![References
[7] S. Redyuk, Z. Kaoudi, S. Schelter, and V. Markl, “DORIAN in action: Assisted design of data science pipelines,” Proc. VLDB
Endow., vol. 15, no. 12, pp.3714–3717, 2022.
[8] G. Vargas-Solar, K. Belhajjame, J. Espinosa-Oviedo, S. Negrete-Yankelevich, and J. Zechinelli-Martini, “MATILDA: inclusive
data science pipelines design through computational creativity,” in Proceedings of the Workshops of the EDBT/ICDT Joint
Conference, vol. 3651, 2024. [Online]. Available: https://ceur-ws.org/Vol-3651/DARLI-AP-11.pdf
[9] Z. Liu, T. Hoang, J. Zhang, M. Zhu, T. Lan, S. Kokane, J. Tan, W. Yao, Z. Liu, Y. Feng, R. Murthy, L. Yang, S. Savarese, J. C. Niebles,
H. Wang, S. Heinecke, and C. Xiong, “Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets,”
CoRR, vol. abs/2406.18518, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2406.18518
[10] J. Giovanelli, B. Bilalli, and A. Abelló, “Data preprocessing pipeline generation for autoetl,” Inf. Syst., vol. 108, p. 101957,
2022.
[11] J. Yang, Y. He, and S. Chaudhuri, “Autopipeline: Synthesize data pipelines by-target using reinforcement learning and
search,” CoRR, vol. abs/2106.13861, 2021. [Online]. Available: https://arxiv.org/abs/2106.13861
[12] Z. Miao, “Simplifying human-in-the-loop data science pipeline: Explanations, debugging, and data preparation,” Ph.D.
dissertation, Duke University, Durham, NC, USA, 2022. [Online]. Available: https://hdl.handle.net/10161/26796
[13] S. Gakhar, J. Cahoon, W. Le, X. Li, K. Ravichandran, H. Patel, M. T. Friedman, B. Haynes, S. Qiao, A. Jindal, and J. Leeka,
“Pipemizer: An optimizer for analytics data pipelines,” Proc. VLDB Endow., vol. 15, no. 12, pp. 3710–3713, 2022.
23](https://crownmelresort.com/image.slidesharecdn.com/isncc2024-1-241217104706-93390a39/75/data-pipelines-complexity-human-expertise-and-LLM-era-23-2048.jpg)
![References
[14] M. Dareck, C. Edelstenne, T. Enders, E. Fernandez, J.-P. Herteman, M. Kerkloh, I. King, P. Ky, M. Mathieu, G. Orsi, G.
Schotman, C. Smith, and J.-D. Worner, “FlightPath 2050: Europe’s Vision for Aviation -Maintaining Global Leadership and Serving
Society’s Needs,” http://www.sesarju.eu/ , 2010, online; accessed 10 August 2024.
[15] European Union and EuroControl and SESAR, “The DART Project: Data-Driven Aircraft Trajectory Prediction Research,”
http://dart-research.eu/ , online; accessed 10 August 2024.
[16] US NextGen, “Modernization of United States Airspace,” https://www.faa.gov/nextgen/ , 2019, online; accessed 10 August
2024.
[17] A. Remadi, K. E. Hage, Y. Hobeika, and F. Bugiotti, “To prompt or not to prompt: Navigating the use of large language models for
integrating and modeling heterogeneous data,” Data Knowl. Eng., vol. 152, p. 102313, 2024.
[18] S. Arora, B. Yang, S. Eyuboglu, A. Narayan, A. Hojel, I. Trummer, and C. Ré, “Language models enable simple systems for
generating structured views of heterogeneous data lakes,” Proc. VLDB Endow., vol. 17, no. 2, pp. 92–105, 2023.
24](https://crownmelresort.com/image.slidesharecdn.com/isncc2024-1-241217104706-93390a39/75/data-pipelines-complexity-human-expertise-and-LLM-era-24-2048.jpg)


This document discusses the complexities of data pipeline engineering, particularly in the context of inferring aircraft flights in crowdsourced networks using artificial intelligence. It outlines the objectives, review of AI assistants, and implications for optimizing data pipelines, highlighting the role of human expertise and large language models. The conclusion emphasizes future work on training models for complex data integration and analysis of aircraft trajectories to enhance aviation efficiency and safety.


































































