Downloaded 21 times




![Text Files – how to get schema?
• File header is not present in file.
• Can Infer schema, but what about column names?
• Data from last couple of years and the file format has been evolved.
scala> df.columns
res01: Array[String] = Array(_c0, _c1, _c2)
XML, JSON or RDBMS sources
• Schema present in the source.
• Spark can automatically infer schema from the source.
scala> df.columns
res02: Array[String] = Array(id, name, address)](https://image.slidesharecdn.com/062009vineetkumar-190510180448/75/Data-Migration-with-Spark-to-Hive-7-2048.jpg)


















![Text Files – how to get schema?
• File header is not present in file.
• Can Infer schema, but what about column names?
• Data from last couple of years and the file format has been evolved.
scala> df.columns
res01: Array[String] = Array(_c0, _c1, _c2)
XML, JSON or RDBMS sources
• Schema present in the source.
• Spark can automatically infer schema from the source.
scala> df.columns
res02: Array[String] = Array(id, name, address)](https://crownmelresort.com/image.slidesharecdn.com/062009vineetkumar-190510180448/75/Data-Migration-with-Spark-to-Hive-7-2048.jpg)

















The document outlines the process and challenges of data migration to a data lake, using Spark for transformation and loading. It covers the need for standardization of data formats, handling inconsistent schemas, and the importance of timestamps in historical data. It also discusses strategies for inferring schemas from various data sources and optimizing performance during migration.
Presenter Vineet Kumar introduces the presentation on Data Migration with Spark, highlighting the Spark AI Summit.
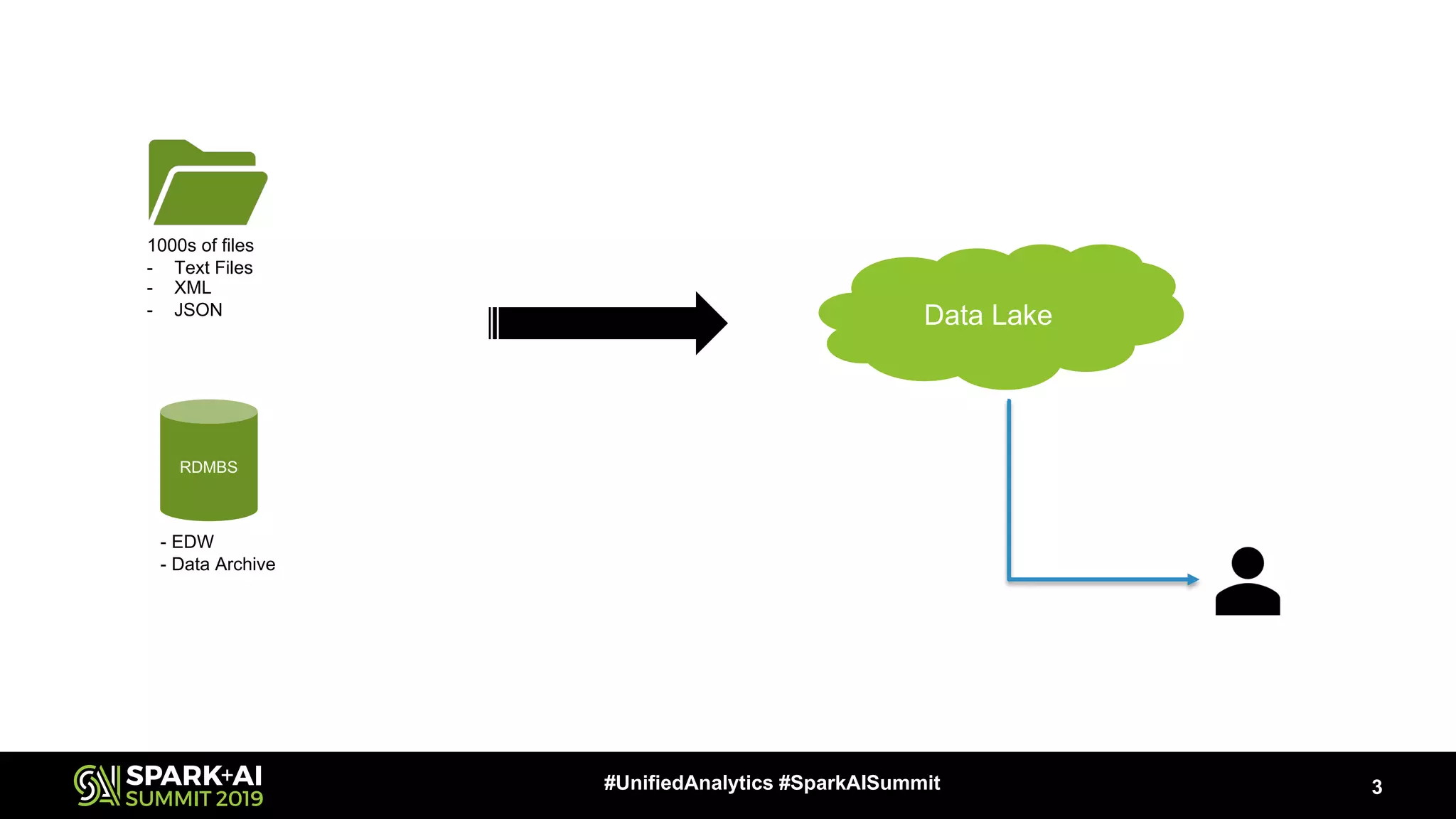
Data migration is crucial for better insights and business requirements. It supports data lake management and archival from EDW, ensuring standards are met.
A data lake consists of various file formats such as text, XML, and JSON. It signifies a vast storage system for diverse data sources.
Migration issues include inconsistent schemas, variable data structures, and large file sizes. ETL processes must adapt to these challenges.
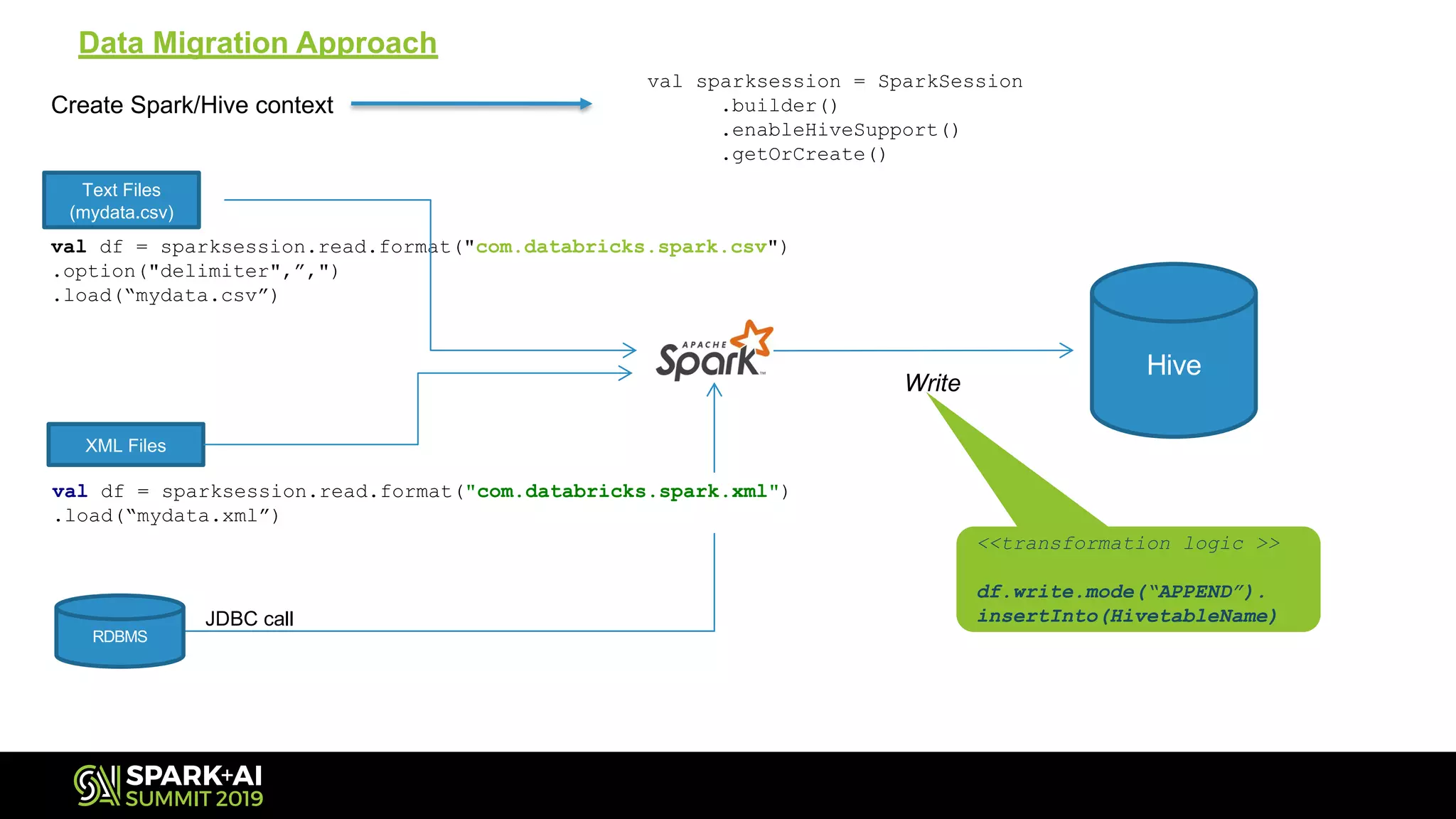
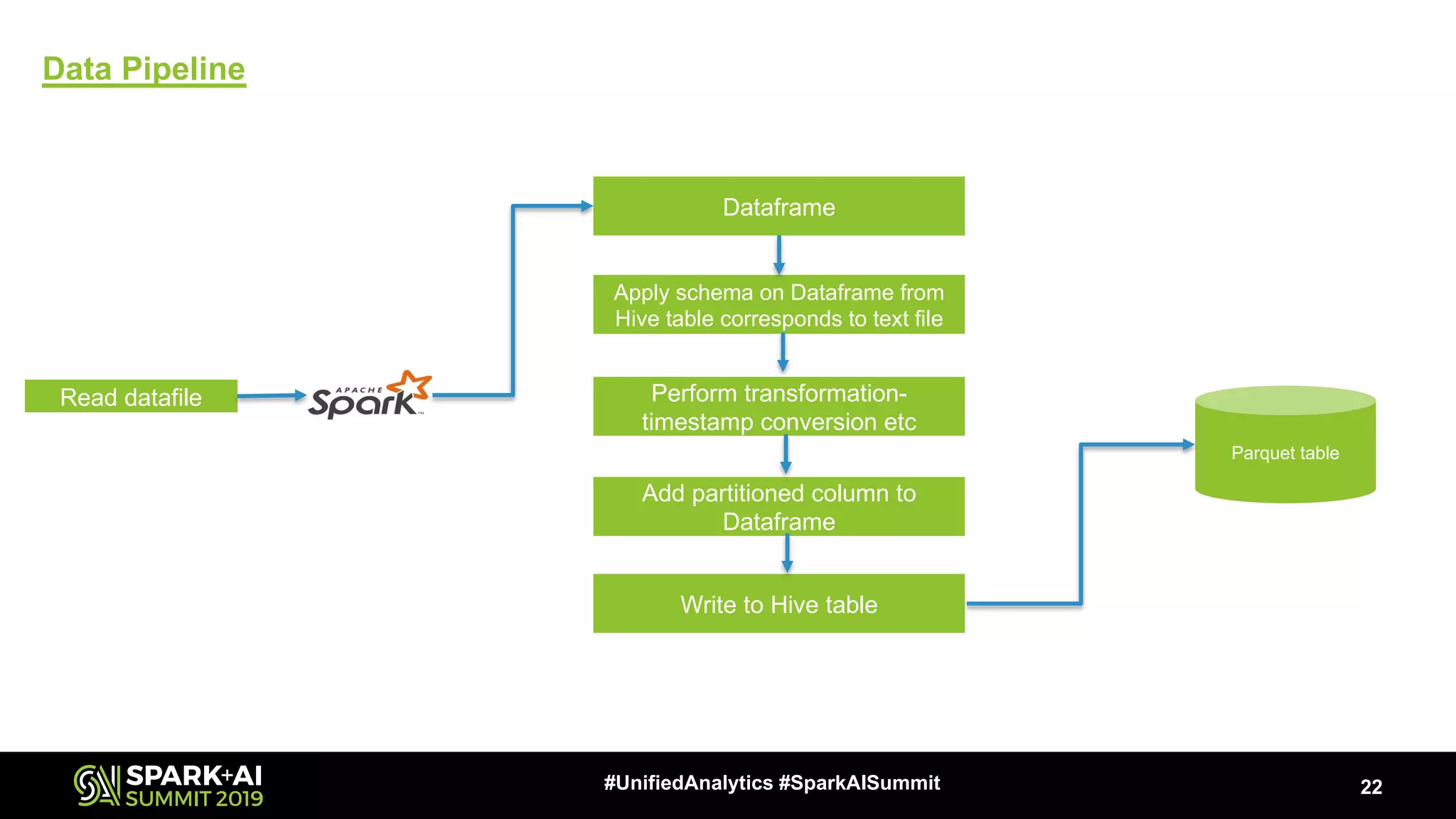
Illustrates the methods of reading text and XML files into Spark, setting up contexts, and writing transformed data to Hive.
Emphasizes the importance of defining schemas, particularly when migrating text files.
Discusses how schemas can be inferred from data sources like XML or RDBMS, especially when file headers are absent.
Outlines options for schema definition for text files, including external sources and structured tables.
Demonstrates creating corresponding Hive structures for CSV files, ensuring proper schema mapping.
Shows the transformation process for renaming columns in a DataFrame to match the target schema.
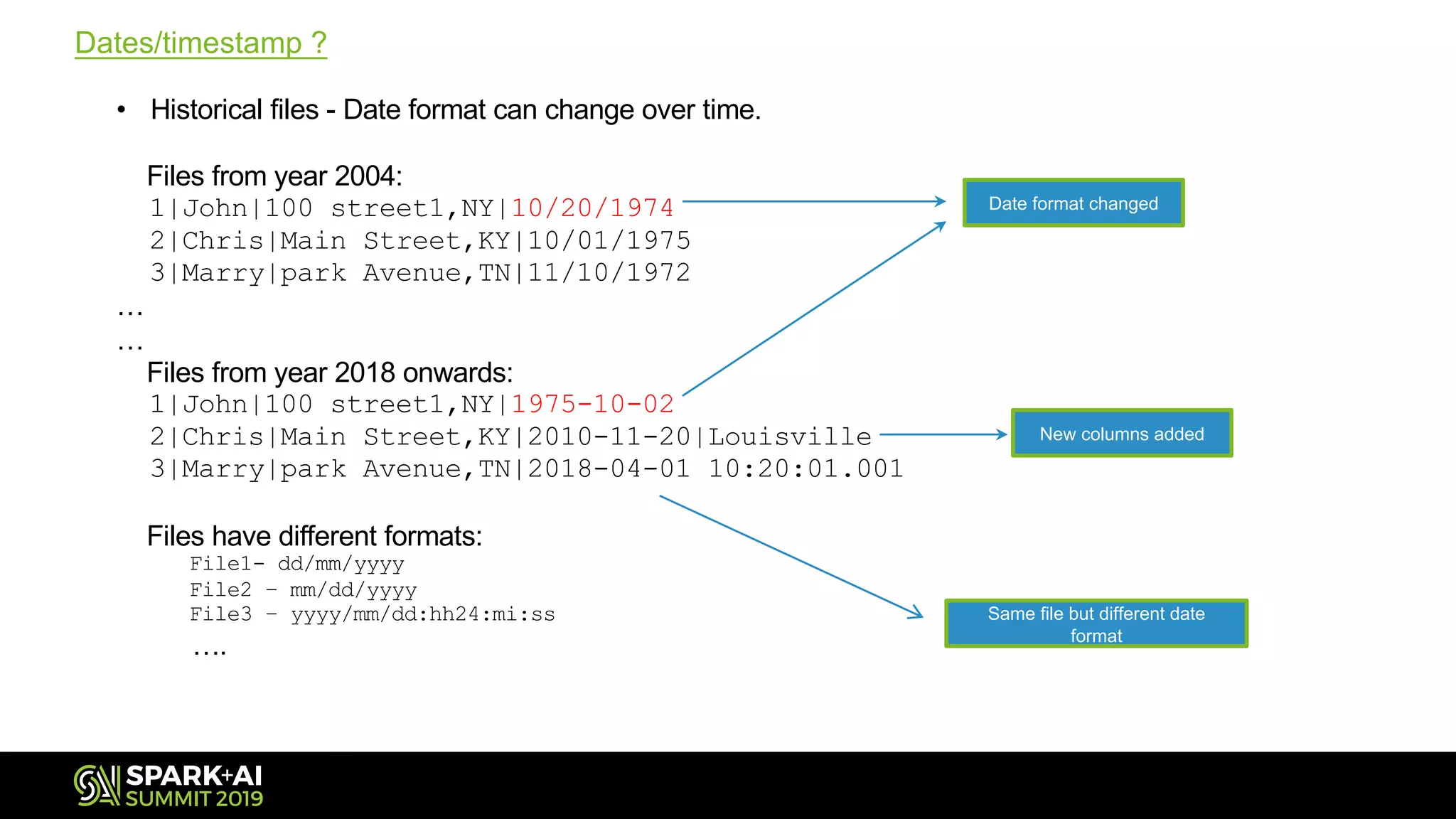
Addresses challenges with historical date formats changing over the years during data migration.
Focuses on identifying and managing timestamp columns in the target Hive table during migration.
Explains how to create User-Defined Functions (UDFs) to convert date formats into Hive-compliant formats.
Describes the UDF logic used for normalizing date formats during migration.
Demonstrates how to apply UDFs for transforming date formats in data migrations.
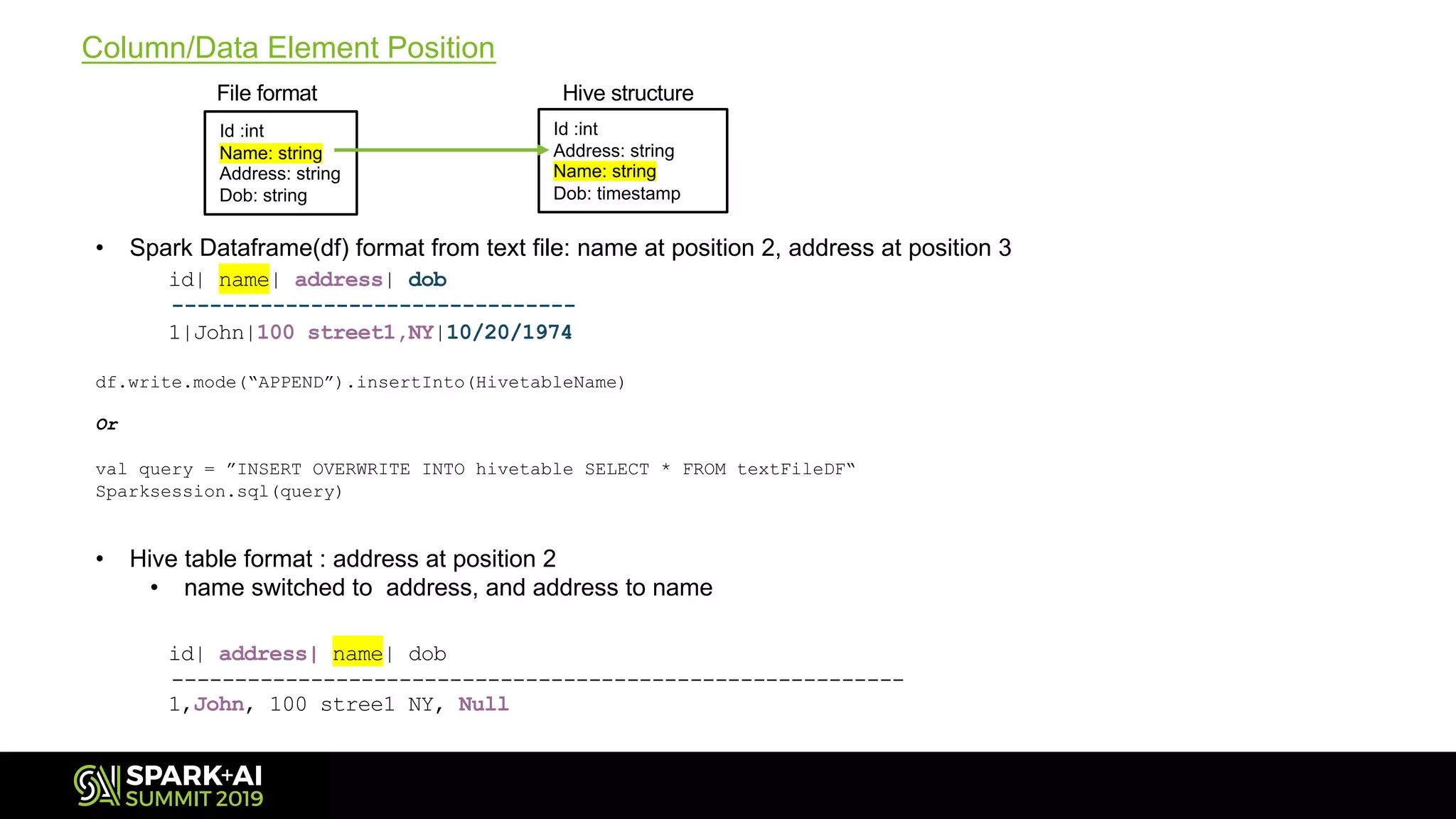
Explains the importance of column positioning when inserting data into Hive from Spark DataFrames.
Details the process of selecting and inserting the DataFrame data into target Hive tables.
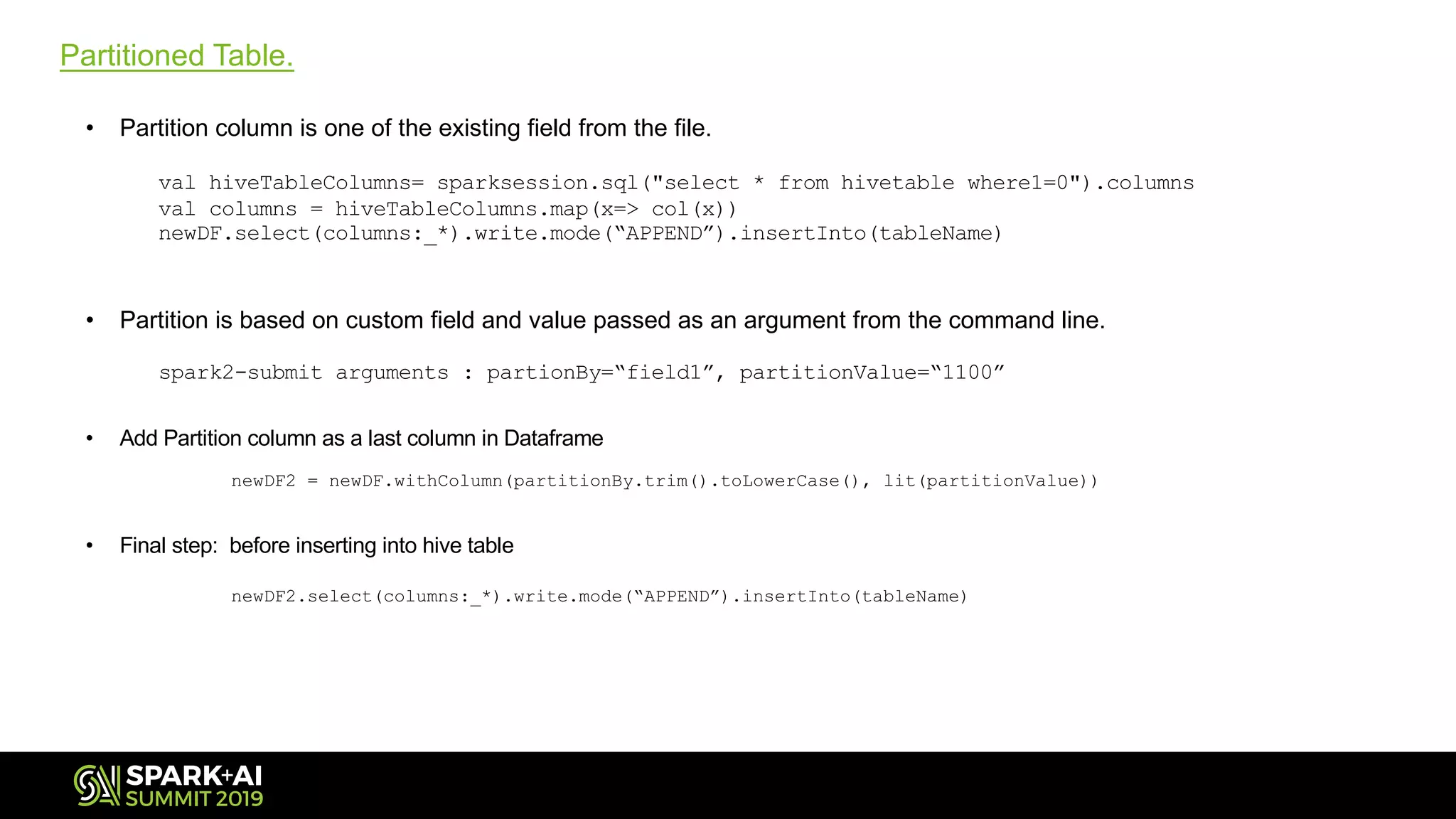
Discusses the benefits of partitioning Hive tables and ways to add partition columns during data insertion.
Explains implementing custom partitioning based on arguments and preparing data frames for Hive.
Highlights performance optimization for large data migrations in Spark using cluster resources.
Summarizes the data migration pipeline from reading data to writing to Hive, emphasizing transformations.
Encourages audience feedback and engagement on the presentations covered.




































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


















