Data mining involves discovering patterns from large amounts of data. It can be used for applications like credit ratings, targeted marketing, fraud detection, and customer relationship management. Some common data mining techniques include classification, clustering, regression, and association rule mining. Decision trees are a popular classification technique that uses a tree structure with internal nodes representing attributes and leaf nodes representing target classes.
DATA MINING
SUBMITTED BY:
SHUBHAM GUPTA, SUMAN CHATTERJEE,
SIDDHARTH TIU
SUBMITTED TO :
Dr. A.C.S. Rao
2.
3
1. What isData Mining
Data mining is the process of discovering interesting patterns (or knowledge)
from large amounts of data.
The data sources can include databases, data warehouses, the Web, other
information repositories, or data that are streamed into the system dynamically.
3.
Why Data Mining
Credit ratings/targeted marketing:
Given a database of 100,000 names, which persons are the
least likely to default on their credit cards?
Identify likely responders to sales promotions
Fraud detection
Which types of transactions are likely to be fraudulent, given
the demographics and transactional history of a particular
customer?
Customer relationship management:
Which of my customers are likely to be the most loyal, and
which are most likely to leave for a competitor? :
4.
Data mining
Processof semi-automatically analyzing large
databases to find patterns that are:
valid: hold on new data with some certainity
novel: non-obvious to the system
useful: should be possible to act on the item
understandable: humans should be able to interpret
the pattern
Also known as Knowledge Discovery in Databases (KDD)
5.
Applications
Banking: loan/creditcard approval
predict good customers based on old customers
Customer relationship management:
identify those who are likely to leave for a competitor.
Targeted marketing:
identify likely responders to promotions
Fraud detection: telecommunications, financial
transactions
from an online stream of event identify fraudulent events
Manufacturing and production:
automatically adjust knobs when process parameter changes
6.
Applications (continued)
Medicine:disease outcome, effectiveness of
treatments
analyze patient disease history: find relationship between
diseases
Molecular/Pharmaceutical: identify new drugs
Scientific data analysis:
identify new galaxies by searching for sub clusters
Web site/store design and promotion:
find affinity of visitor to pages and modify layout
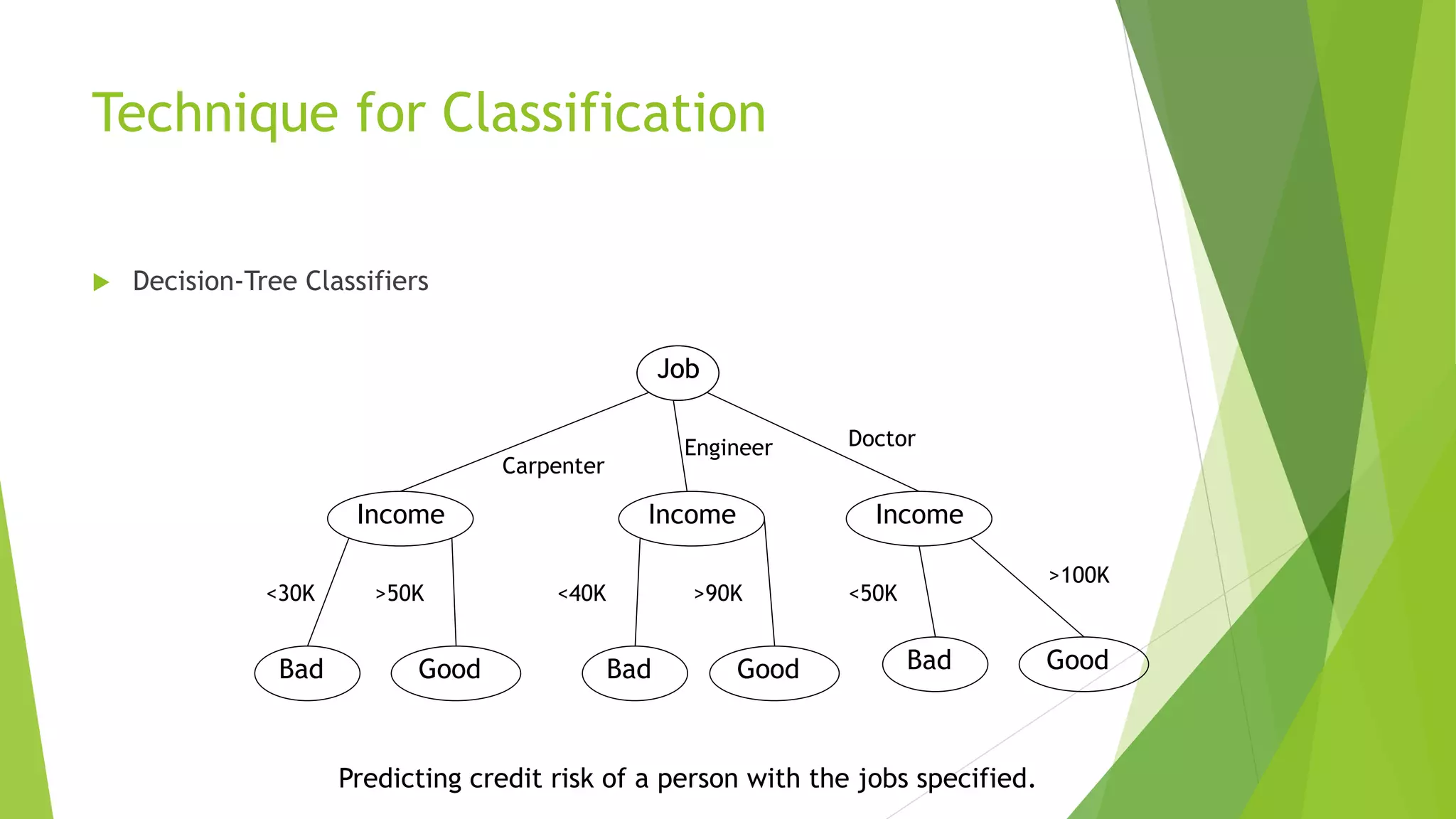
Technique for Classification
Decision-Tree Classifiers
Job
Income
Job
Income Income
Carpenter
Engineer Doctor
Bad Good Bad Good Bad Good
<30K <40K <50K>50K >90K
>100K
Predicting credit risk of a person with the jobs specified.
11.
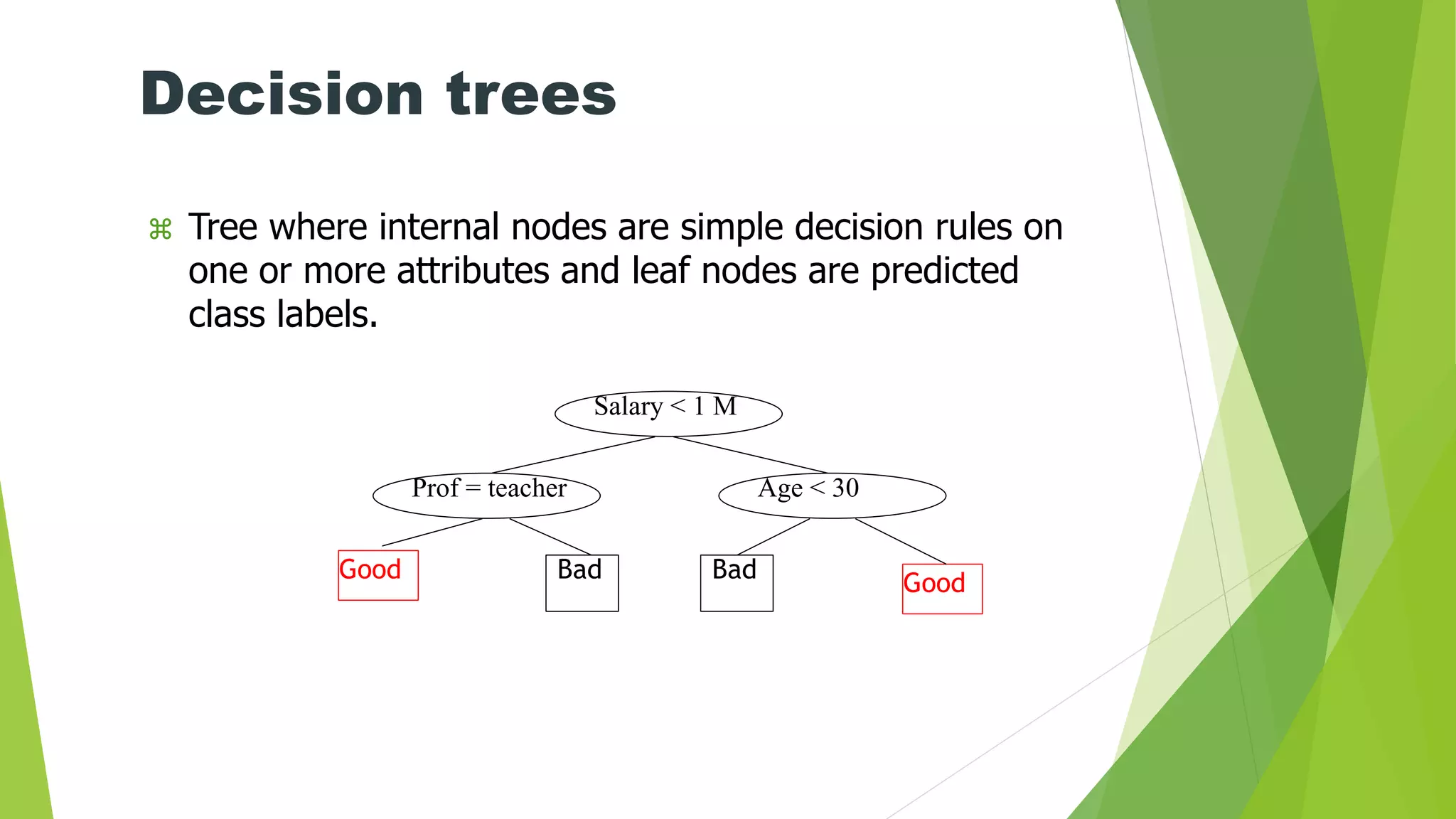
Decision trees
Treewhere internal nodes are simple decision rules on
one or more attributes and leaf nodes are predicted
class labels.
Salary < 1 M
Prof = teacher
Good
Age < 30
BadBad
Good
12.
Decision Trees
Adecision tree T encodes d (a classifier or regression function) in form of a
tree.
A node t in T without children is called a leaf node. Otherwise t is called an
internal node.
12
13.
Internal Nodes
Eachinternal node has an associated splitting predicate. Most common are
binary predicates.
Example predicates:
Age <= 20
Profession in {student, teacher}
5000*Age + 3*Salary – 10000 > 0
13
14.
Leaf Nodes
Consider leafnode t:
Classification problem: Node t is labeled with one class label c in
dom(C)
Regression problem: Two choices
Piecewise constant model:
t is labeled with a constant y in dom(Y).
Piecewise linear model:
t is labeled with a linear model
Y = yt + Σ aiXi
14
15.
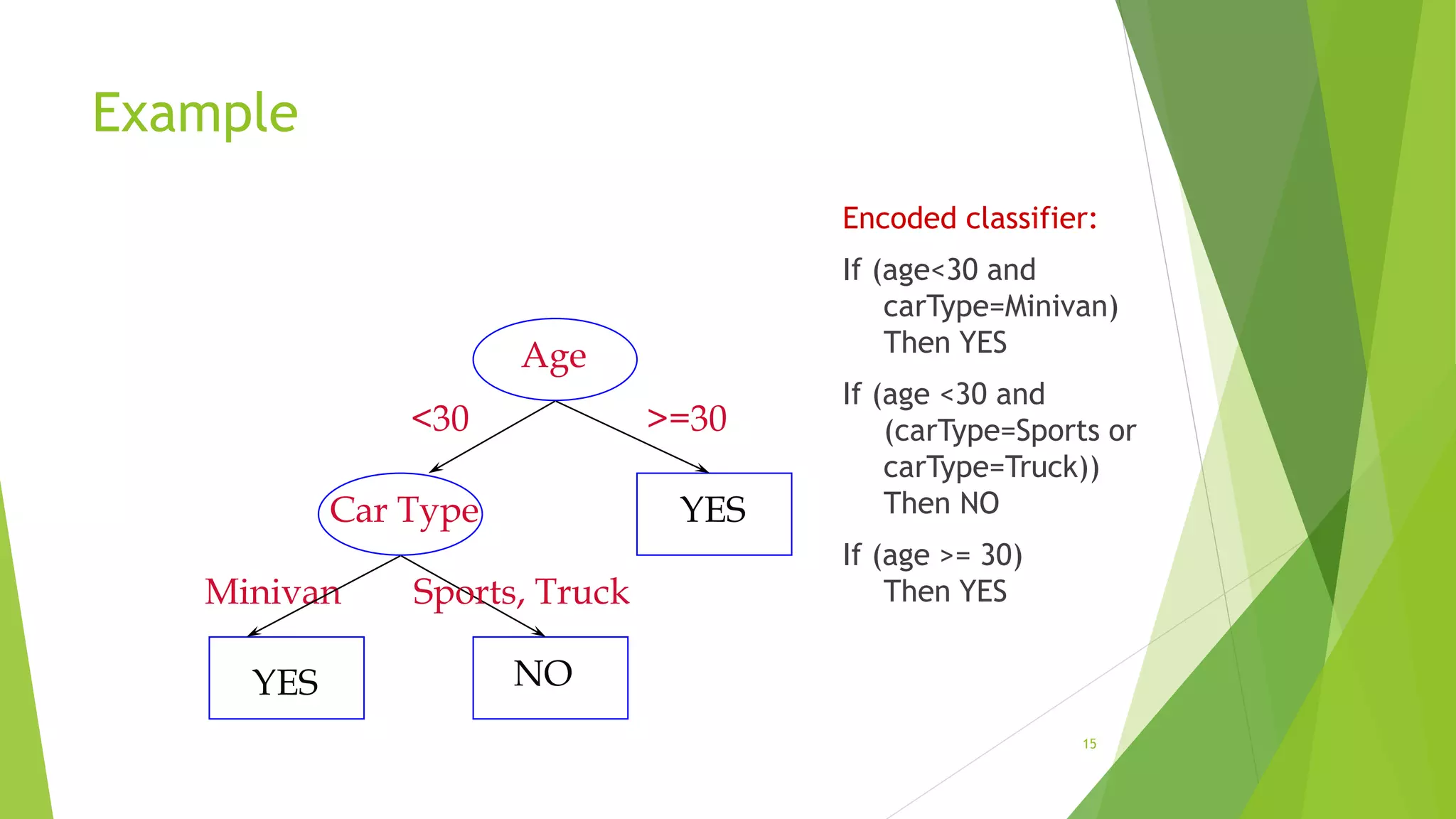
Example
Encoded classifier:
If (age<30and
carType=Minivan)
Then YES
If (age <30 and
(carType=Sports or
carType=Truck))
Then NO
If (age >= 30)
Then YES
15
Minivan
Age
Car Type
YES NO
YES
<30 >=30
Sports, Truck
16.
Why Decision TreeModel?
Relatively fast compared to other classification models
Obtain similar and sometimes better accuracy compared to other models
Simple and easy to understand
Can be converted into simple and easy to understand classification rules
16
17.
Pros and Consof decision trees
· Cons
- Cannot handle complicated
relationship between features
- simple decision boundaries
- problems with lots of missing
data
· Pros
+ Reasonable training
time
+ Fast application
+ Easy to interpret
+ Easy to implement
+ Can handle large
number of features
18.
Consumer Profiling
Businesses needto effectively leverage
available data to improve customer
acquisition and retention. We will explore
how analytics tools such as decision
trees can help with customer
acquisition.
19.
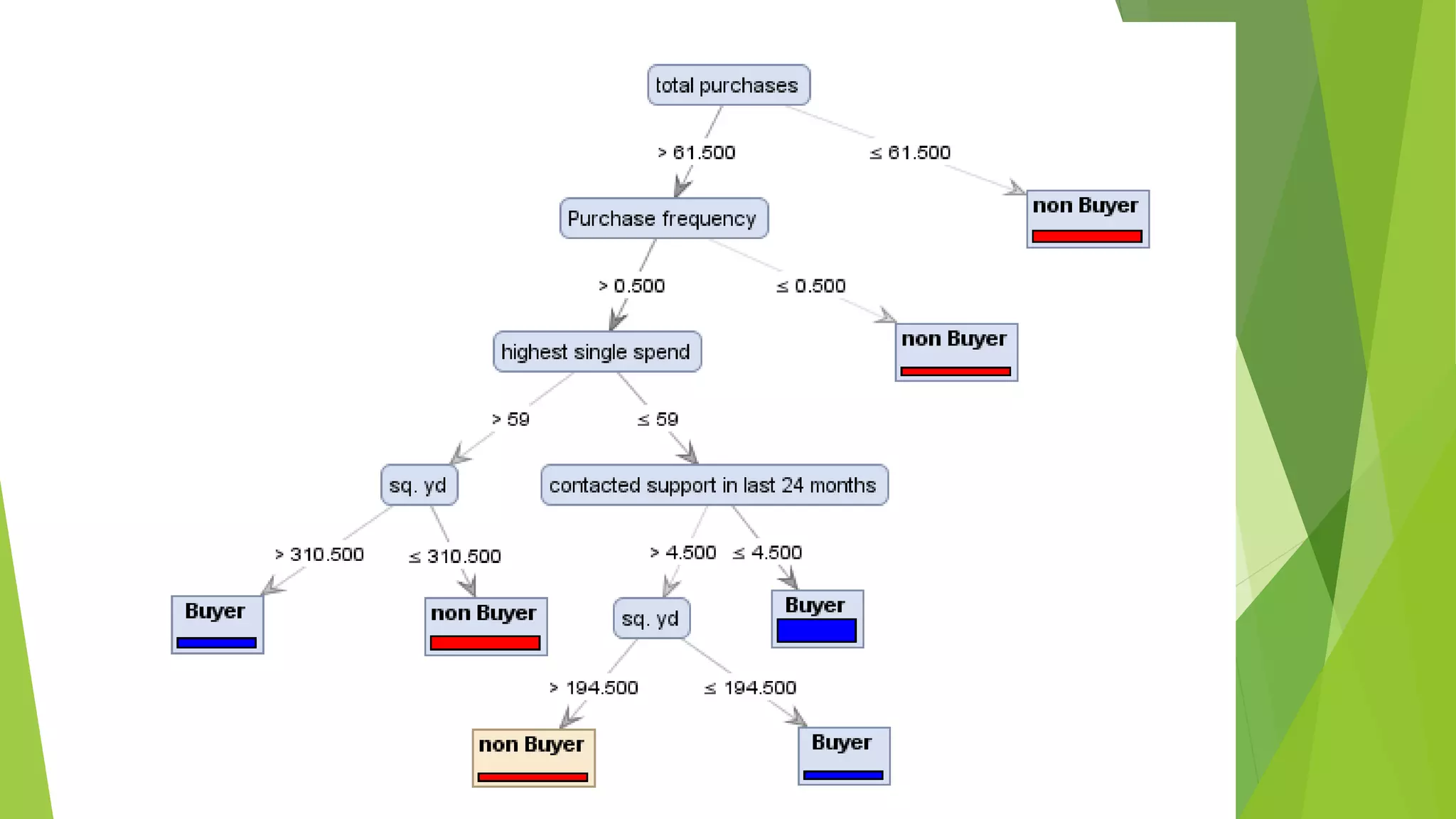
EXAMPLE
A manufacturer ofhome improvement
equipment wants to identify which
existing customers are best candidates
for a new product they are developing.
A decision tree such as the one shown
below
21.
Clustering
Group Datainto Clusters
Similar data is grouped in the same cluster
Dissimilar data is grouped in the same cluster
How is this achieved ?
K-Nearest Neighbor
A classification method that classifies a point by calculating the
distances between the point and points in the training data set.
Then it assigns the point to the class that is most common among
its k-nearest neighbors (where k is an integer).(2)
Hierarchical
Group data into t-trees
22.
Regression
“Regression dealswith the prediction of a value, rather than a class.”
(1, P747)
Example: Find out if there is a relationship between smoking patients
and cancer related illness.
Given values: X1, X2... Xn
Objective predict variable Y
One way is to predict coefficients a0, a1, a2
Y = a0 + a1X1 + a2X2 + … anXn
Linear Regression
23.
Association Rules
“Anassociation algorithm creates rules that describe how often
events have occurred together.” (2)
Example: When a customer buys a hammer, then 90% of the
time they will buy nails.
24.
Advantages of DataMining
Provides new knowledge from existing data
Public databases
Government sources
Company Databases
Old data can be used to develop new knowledge
New knowledge can be used to improve services or products
Improvements lead to:
Bigger profits
More efficient service
25.
Uses of DataMining
Sales/ Marketing
Diversify target market
Identify clients needs to increase response rates
Risk Assessment
Identify Customers that pose high credit risk
Fraud Detection
Identify people misusing the system. E.g. People who have two Social
Security Numbers
Customer Care
Identify customers likely to change providers
Identify customer needs
26.
Relationship with otherfields
Overlaps with machine learning, statistics,
artificial intelligence, databases, visualization
but more stress on
scalability of number of features and instances
stress on algorithms and architectures whereas
foundations of methods and formulations provided
by statistics and machine learning.
automation for handling large, heterogeneous data