Download to read offline




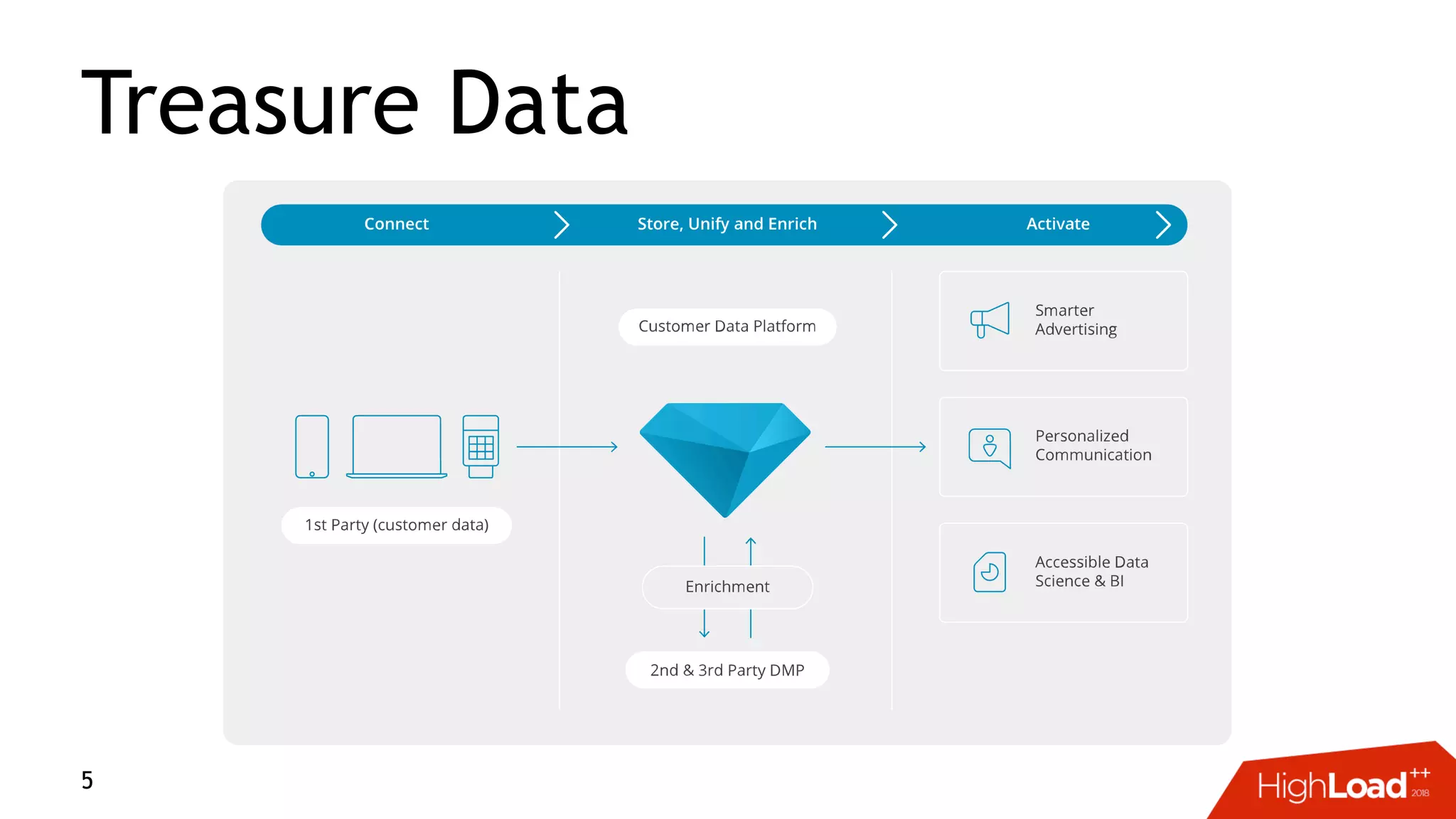


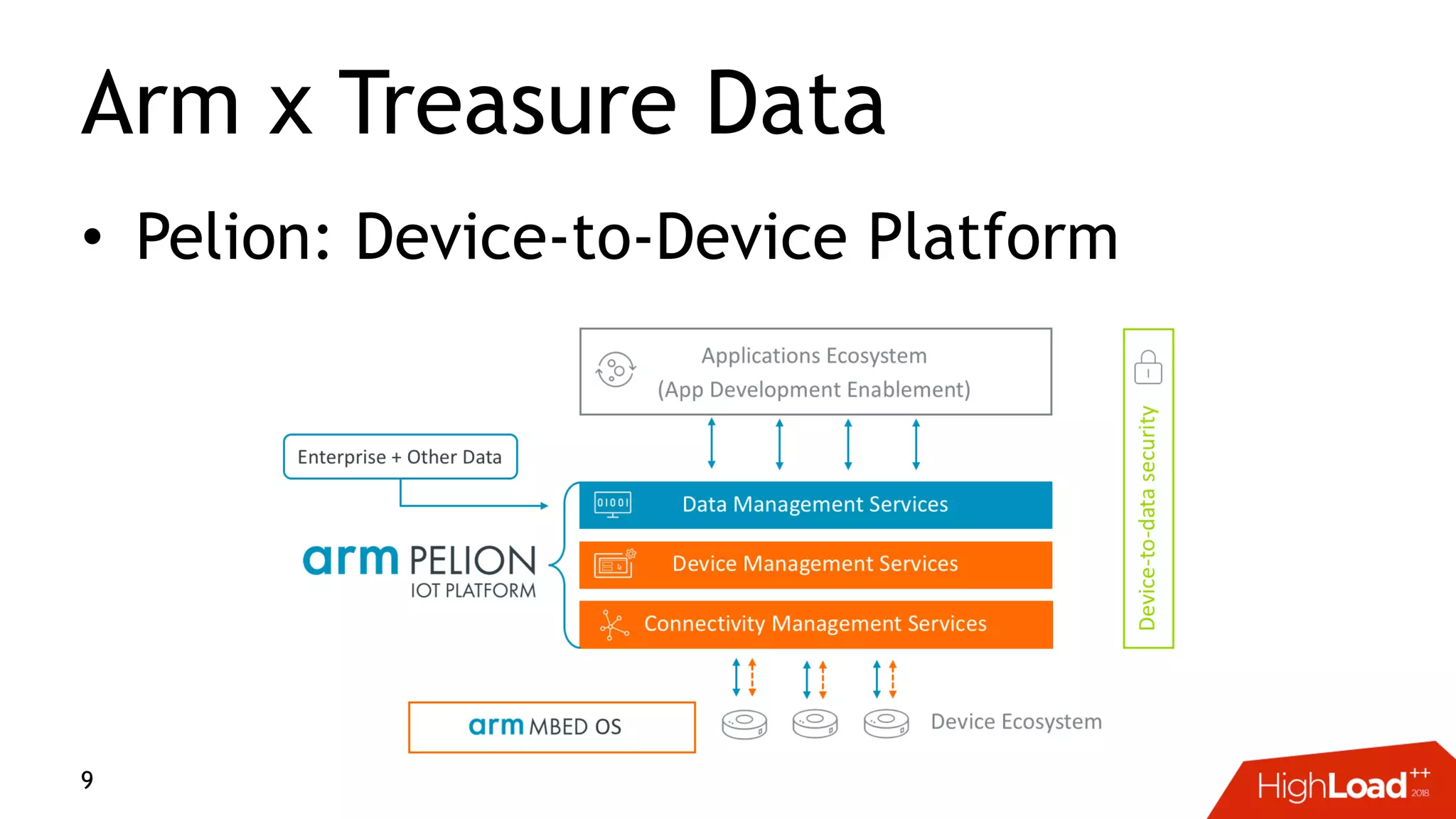


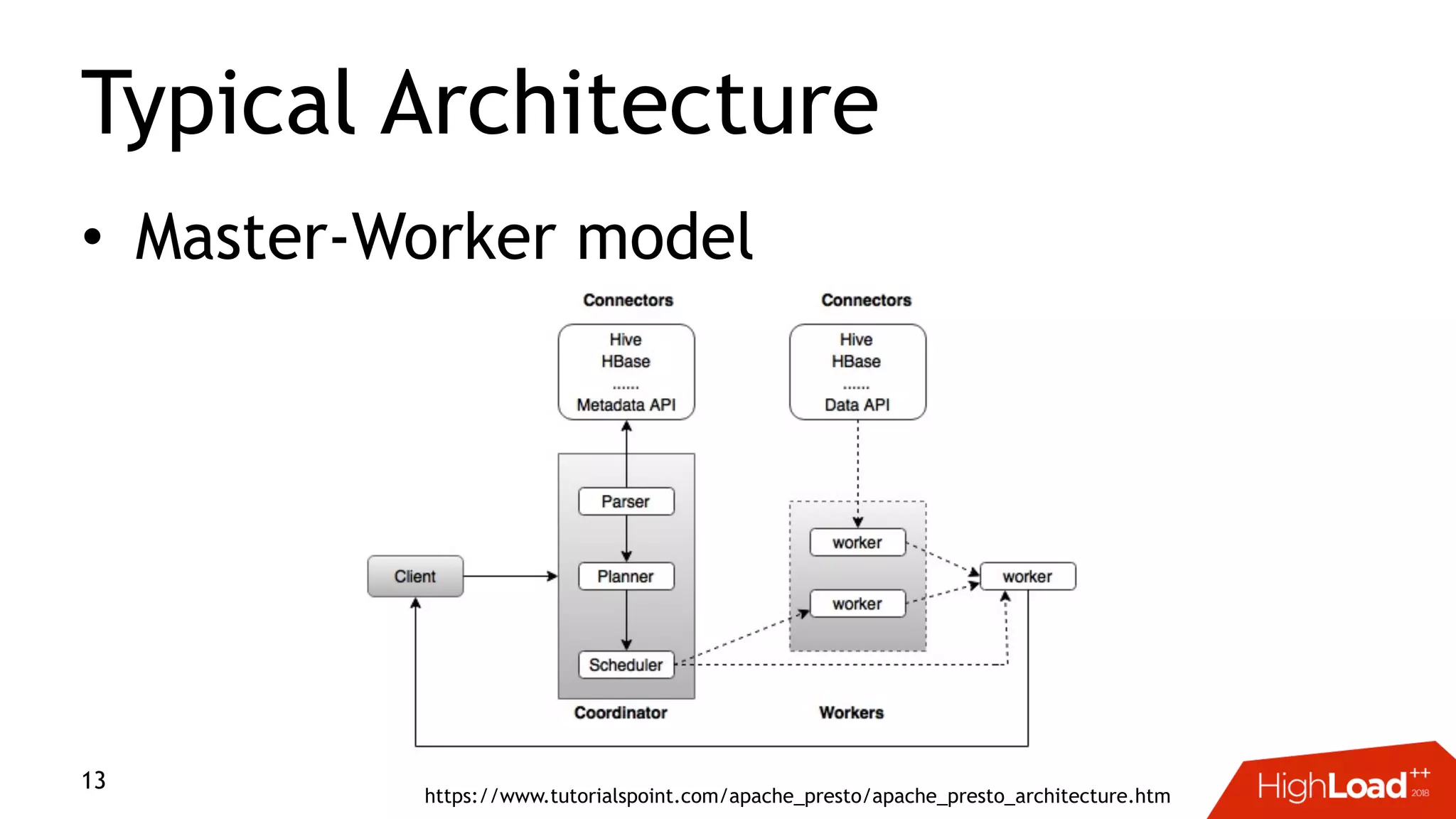
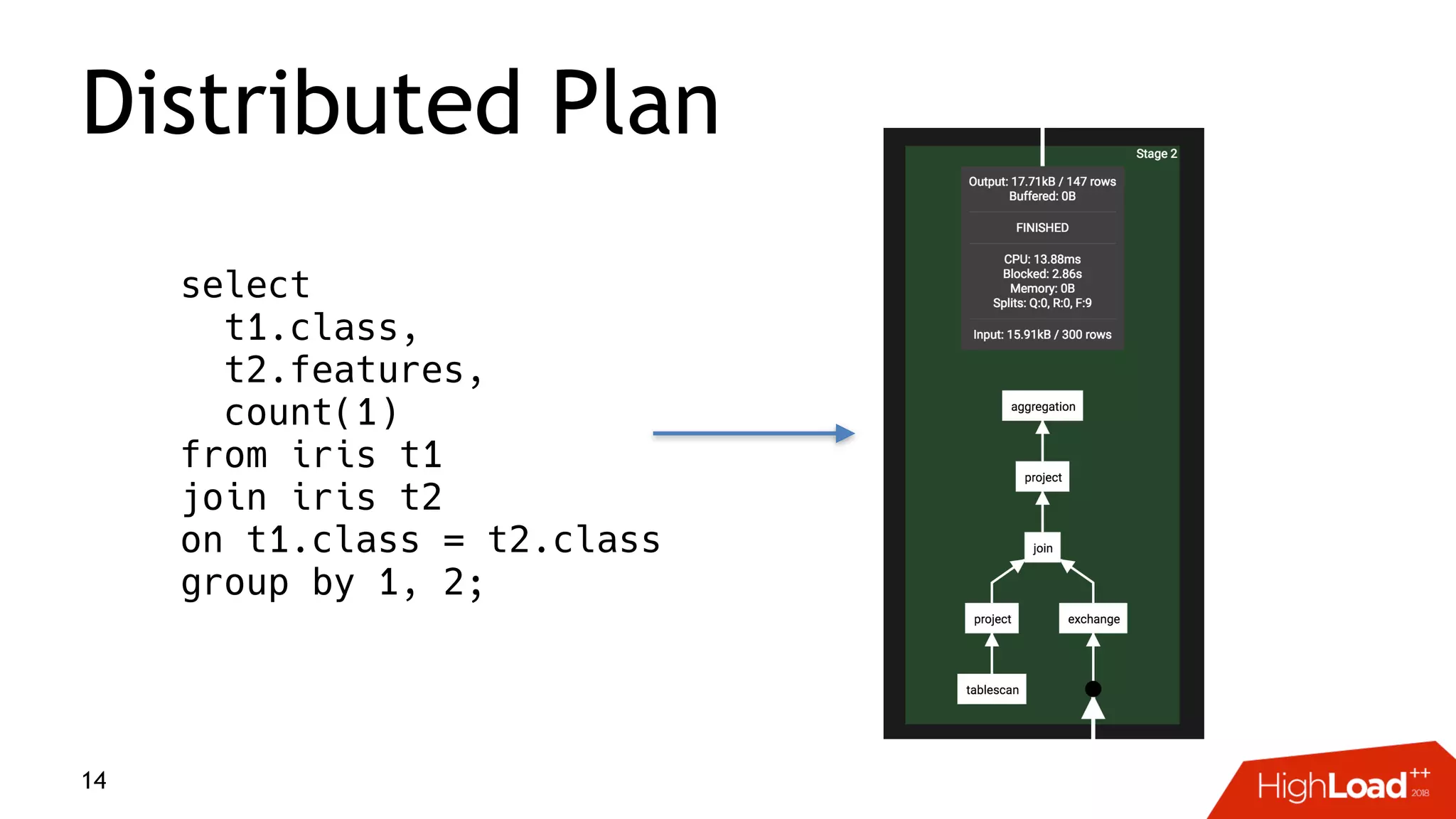





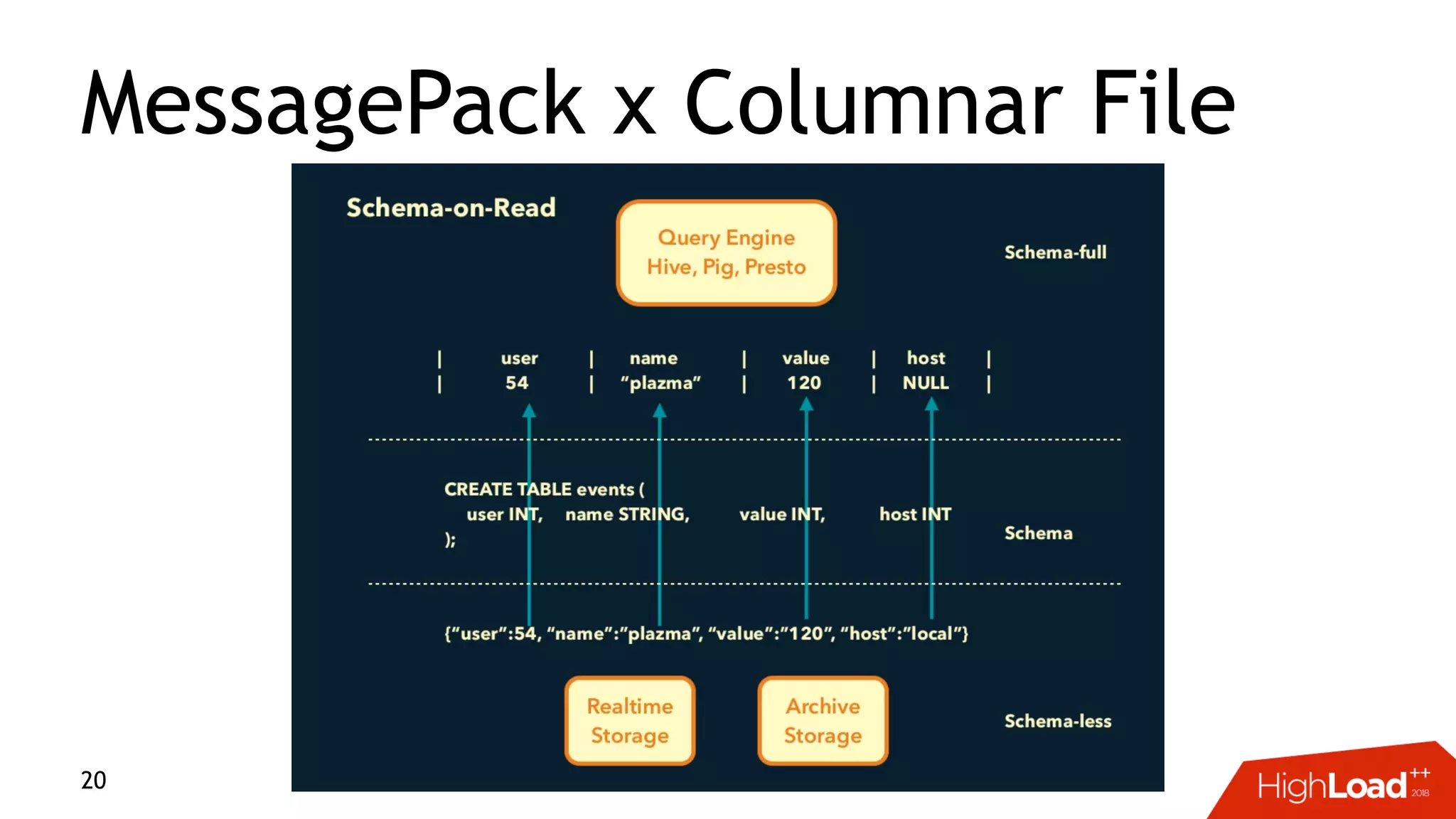


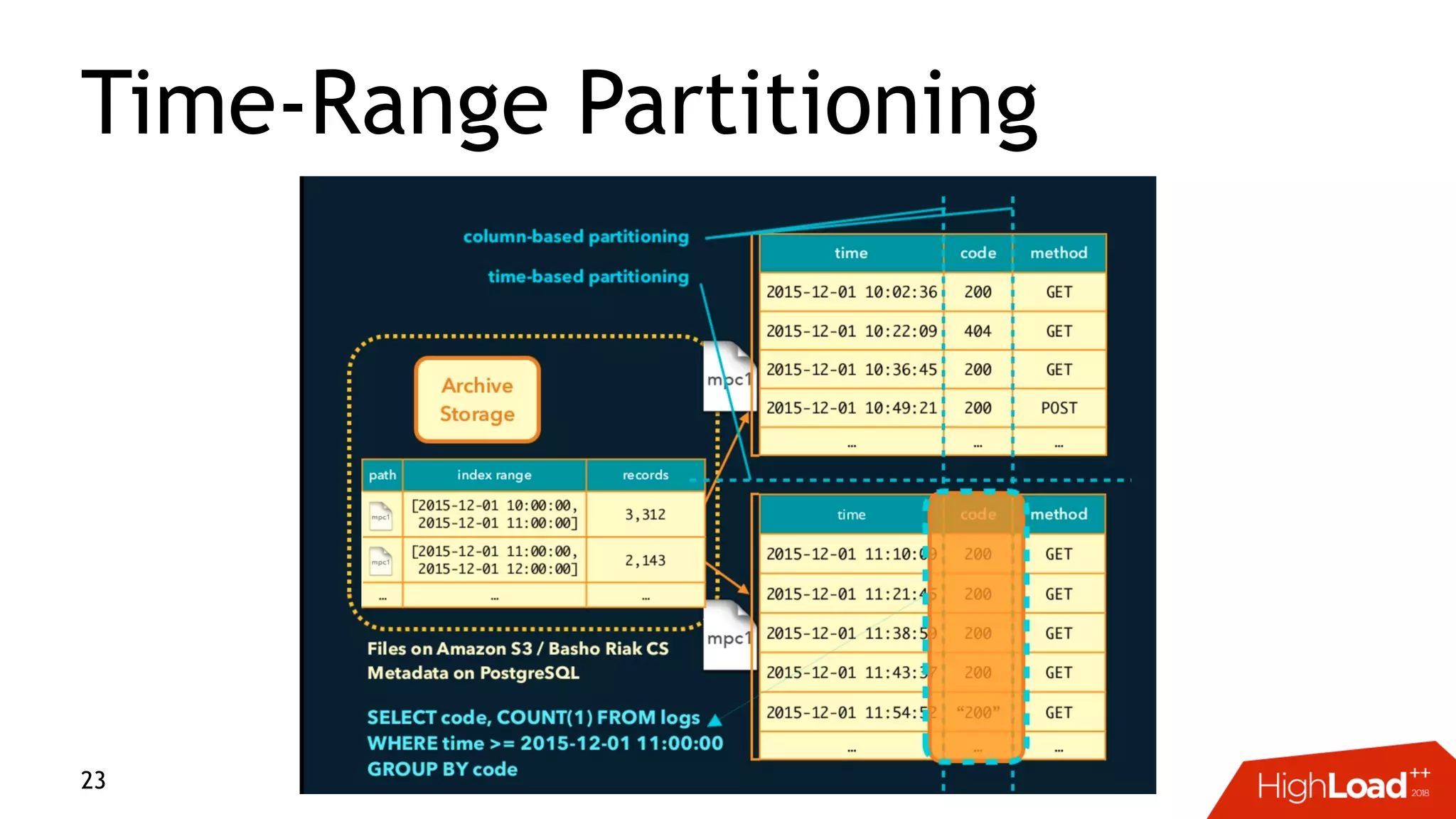
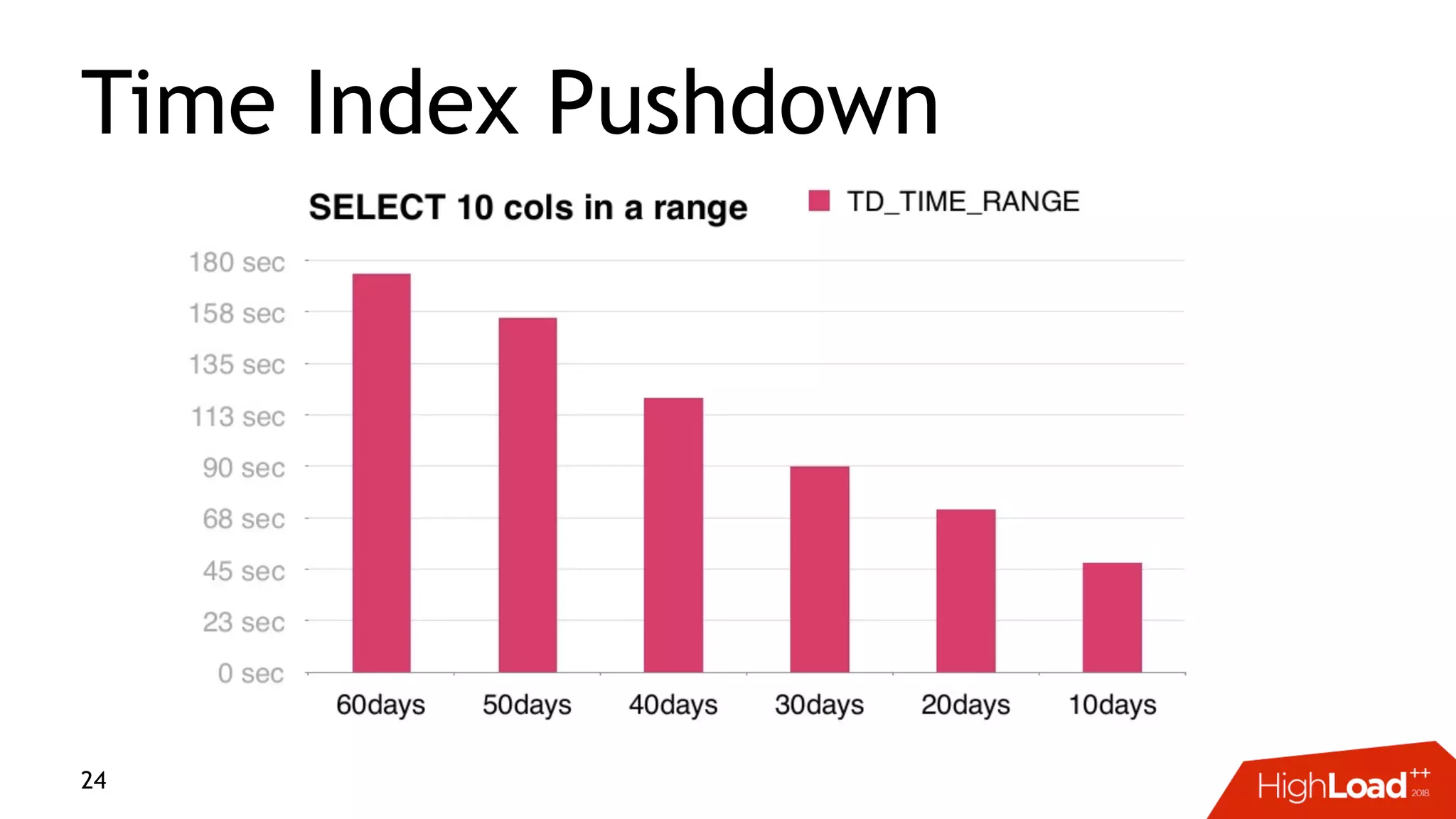




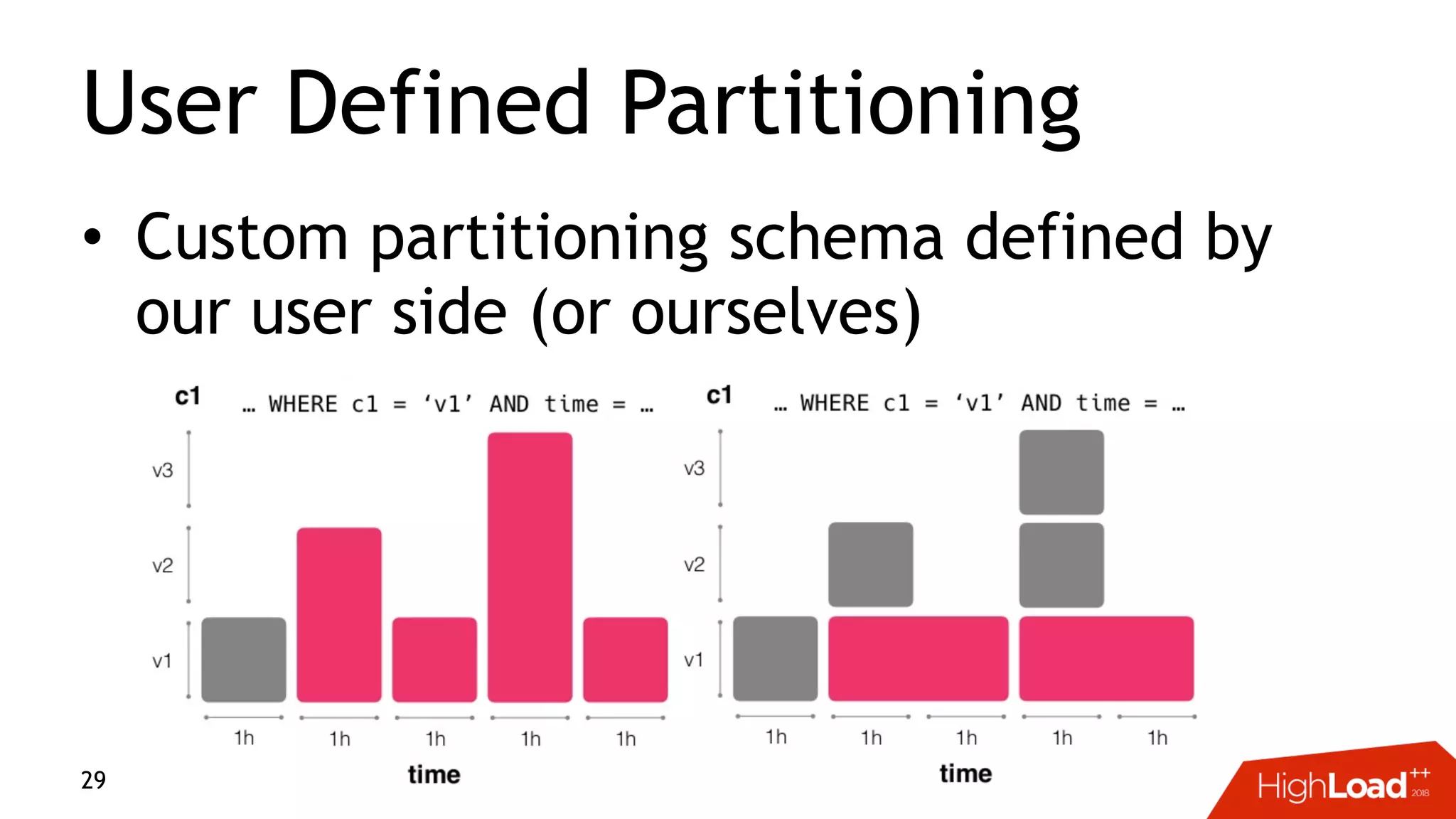
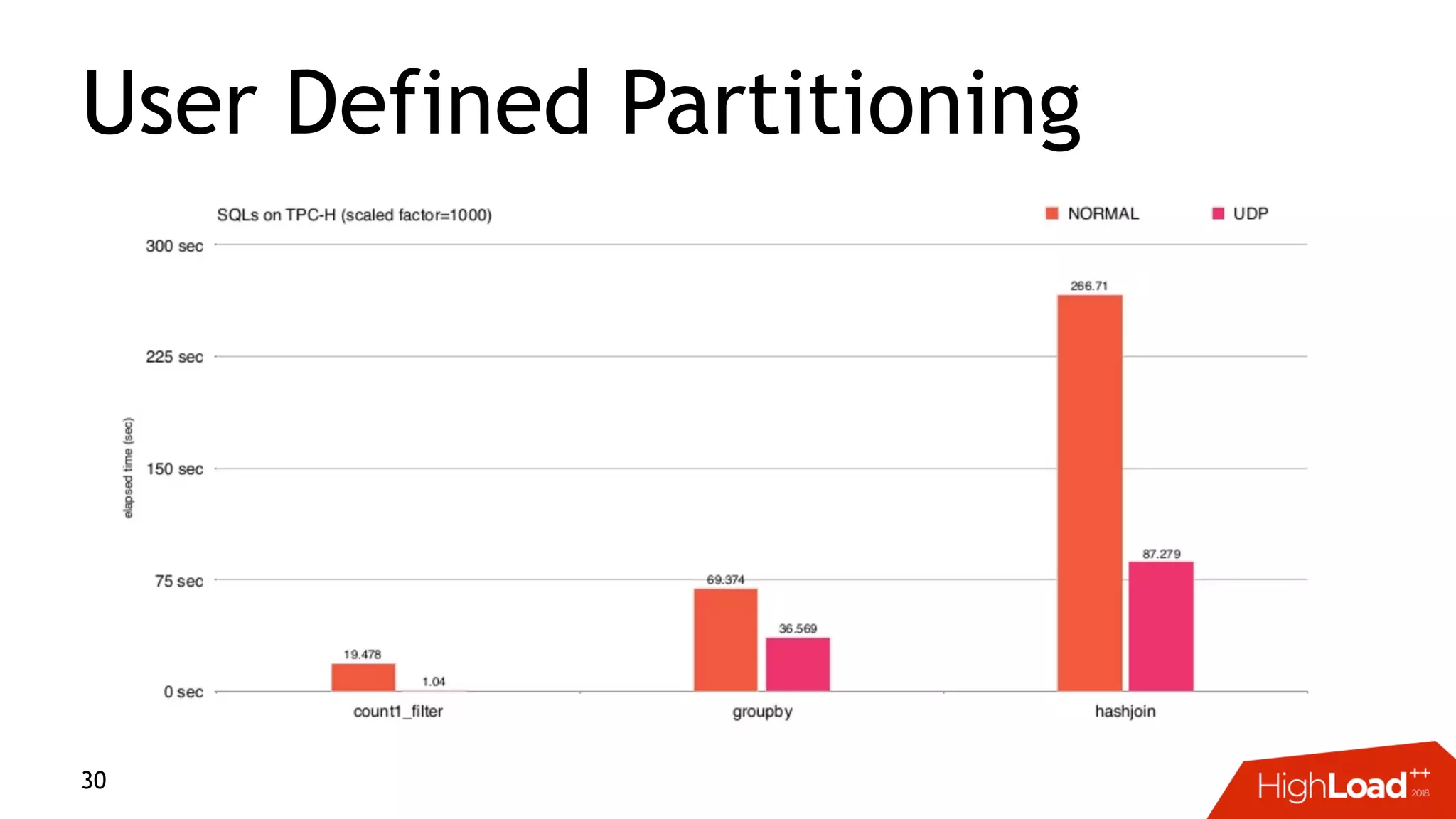
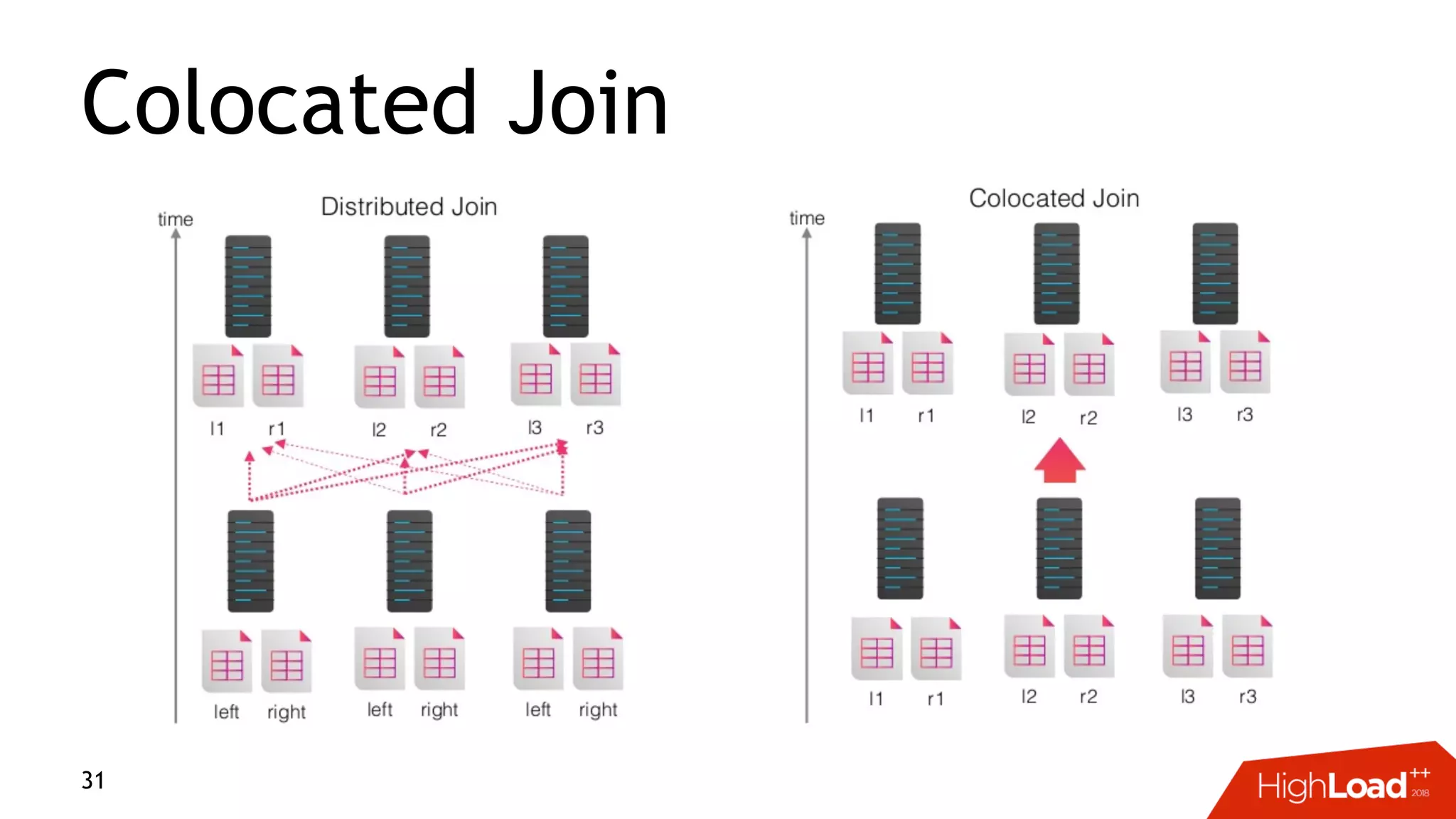












































This document discusses challenges with distributed data analysis and Treasure Data's approach to addressing them. Some key points: - Distributed data analysis faces challenges around network bandwidth, throughput, data consistency, and reliability. - Treasure Data uses a columnar storage format based on MessagePack to more efficiently save bandwidth and storage space. - They implement time index pushdown to enable reading only relevant data within a time range, reducing network usage. - Automatic optimization of partitioning layout and repartitioning aims to balance partition file size, time ranges, and keys to maximize performance and throughput while minimizing memory pressure.























































































