Download to read offline








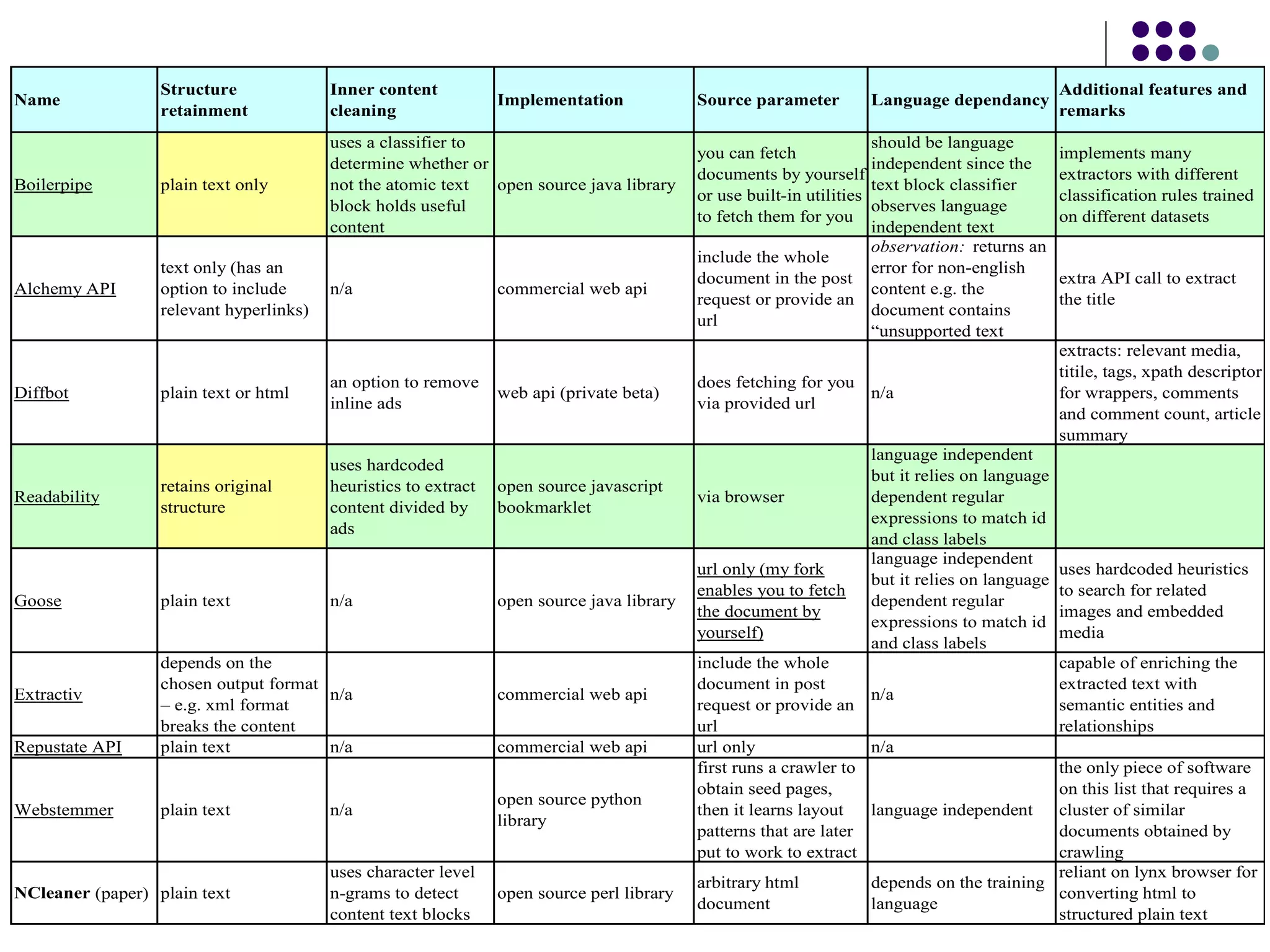














The document discusses improvements made to Boilerpipe, a tool for extracting the main content from web pages. It describes known issues with extracting content, the necessary and optional parameters for integration, and different output modes. Testing on 150 news articles achieved a 94% success rate. Issues addressed included incorrect encodings, missing content bodies, and JavaScript or HTML escape characters. The failure cases were analyzed and solutions developed, such as handling encodings better and downloading the full HTML.


























































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




