Download as PDF, PPTX


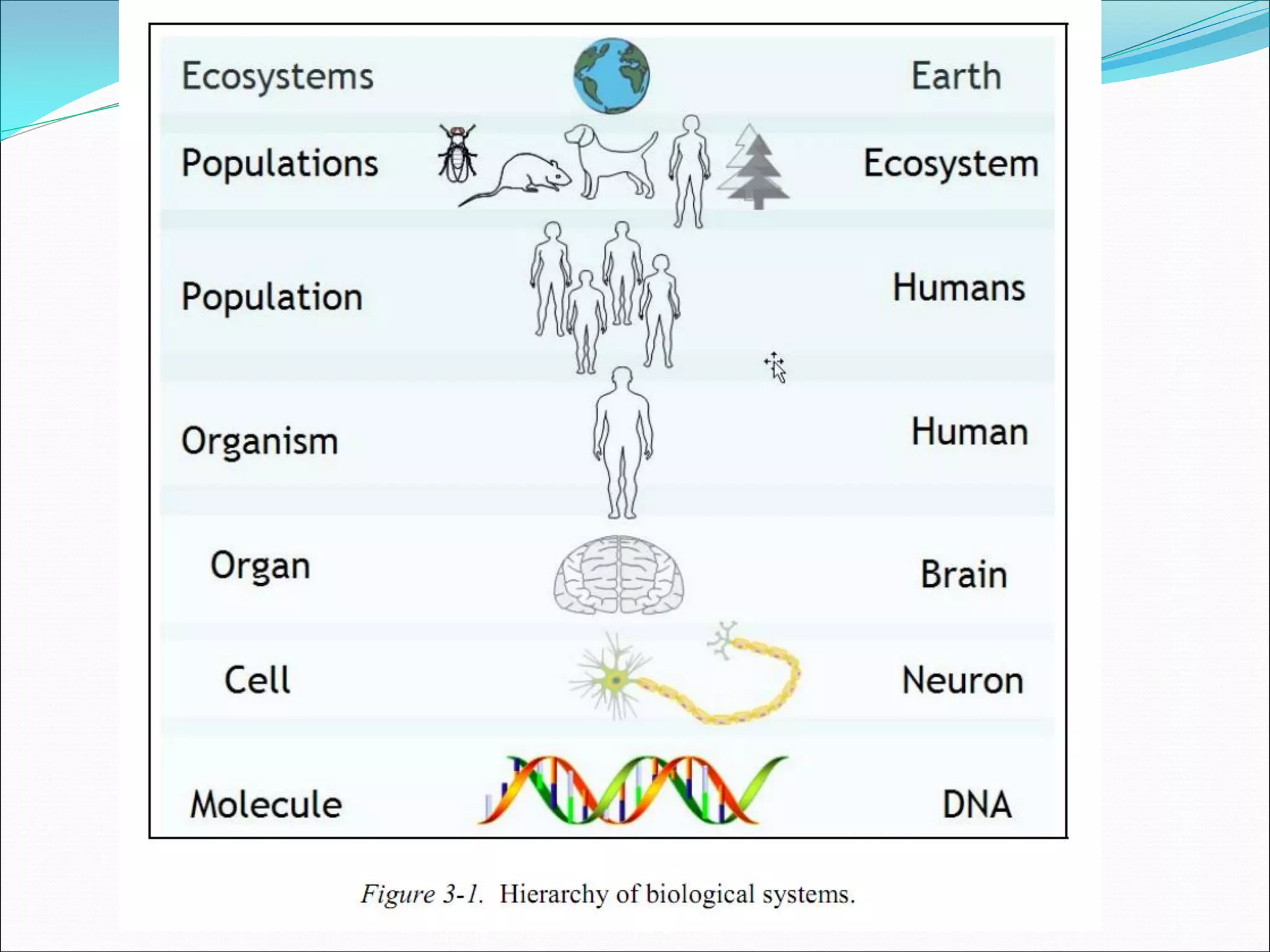
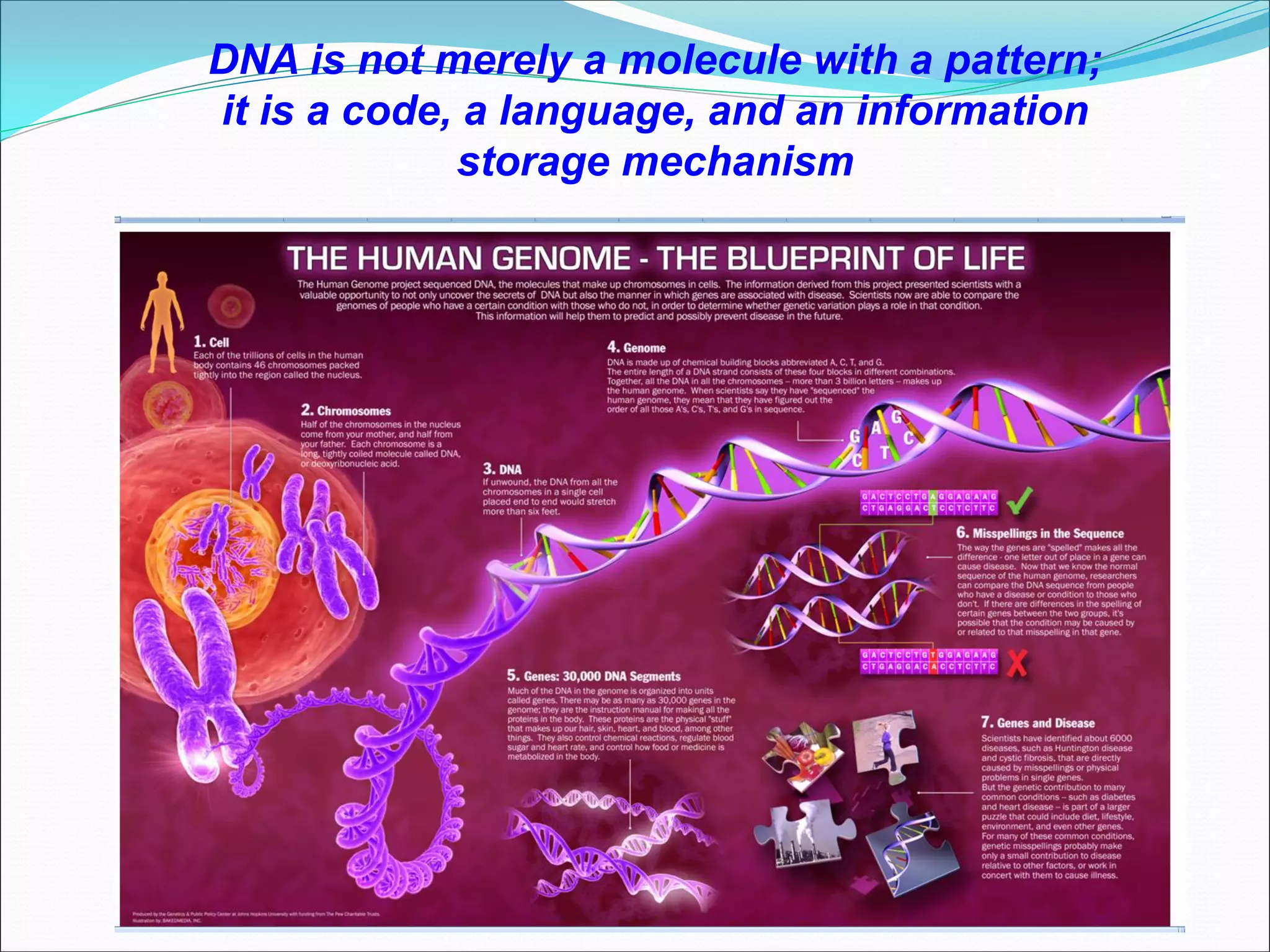

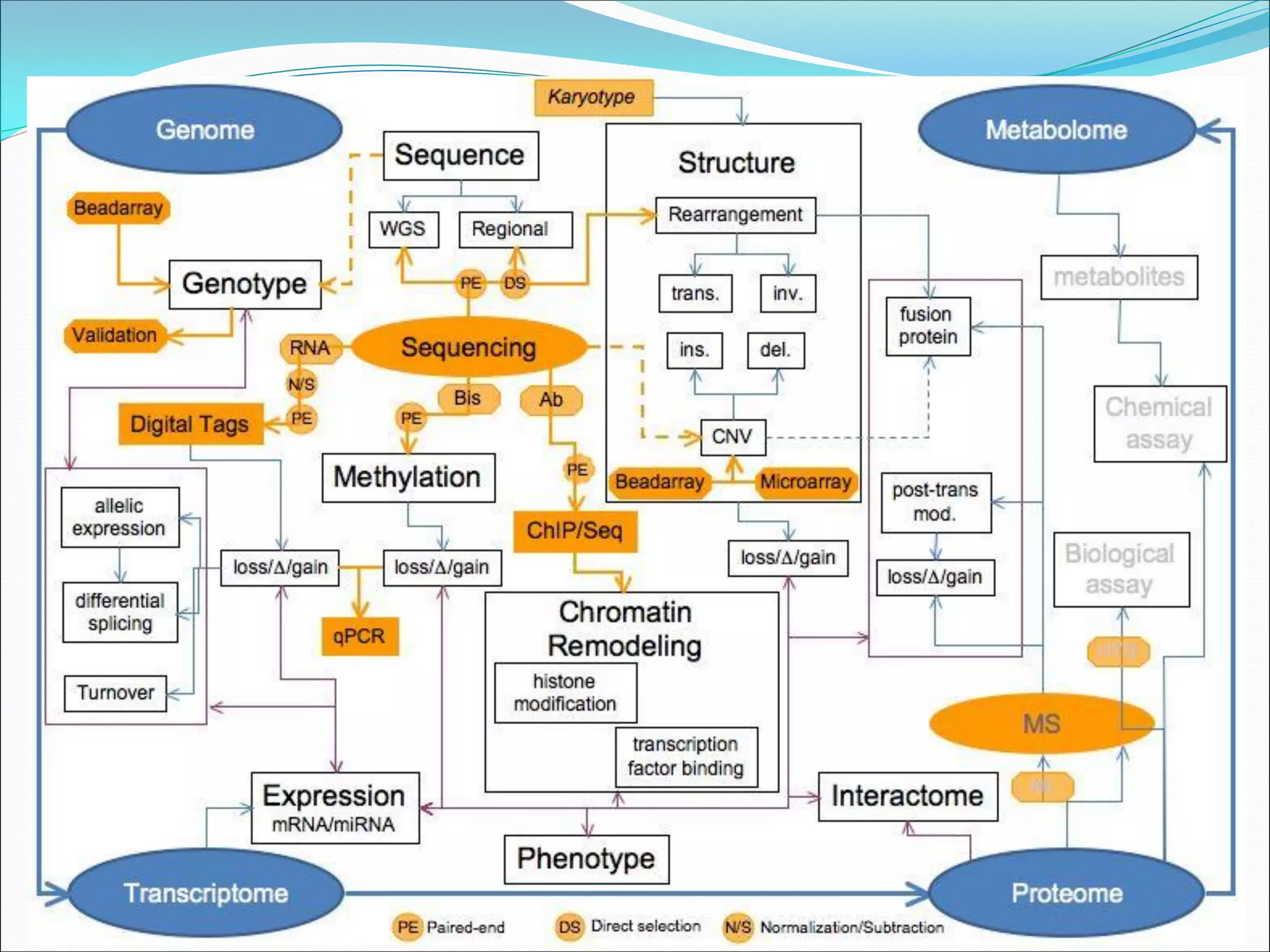


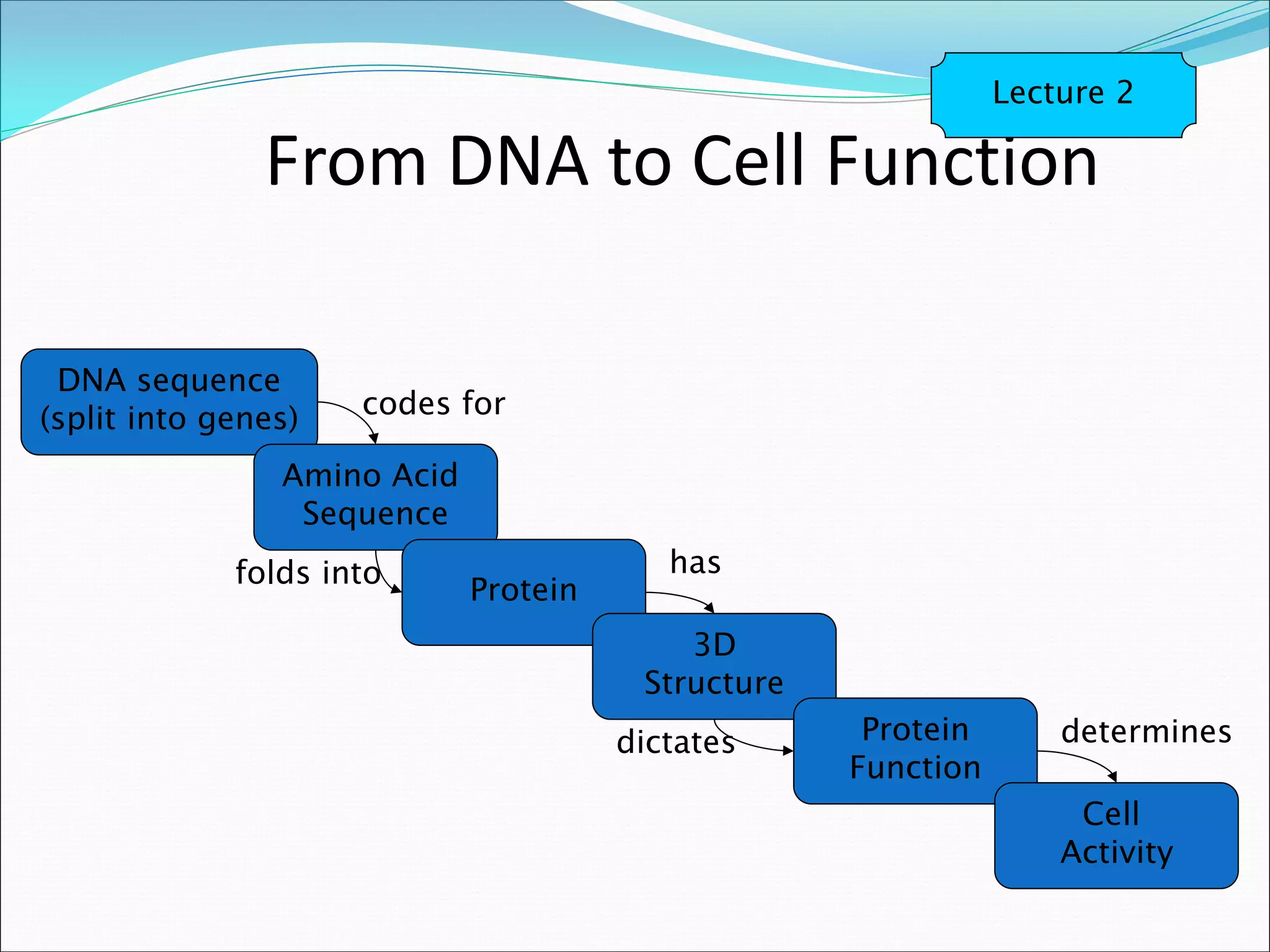
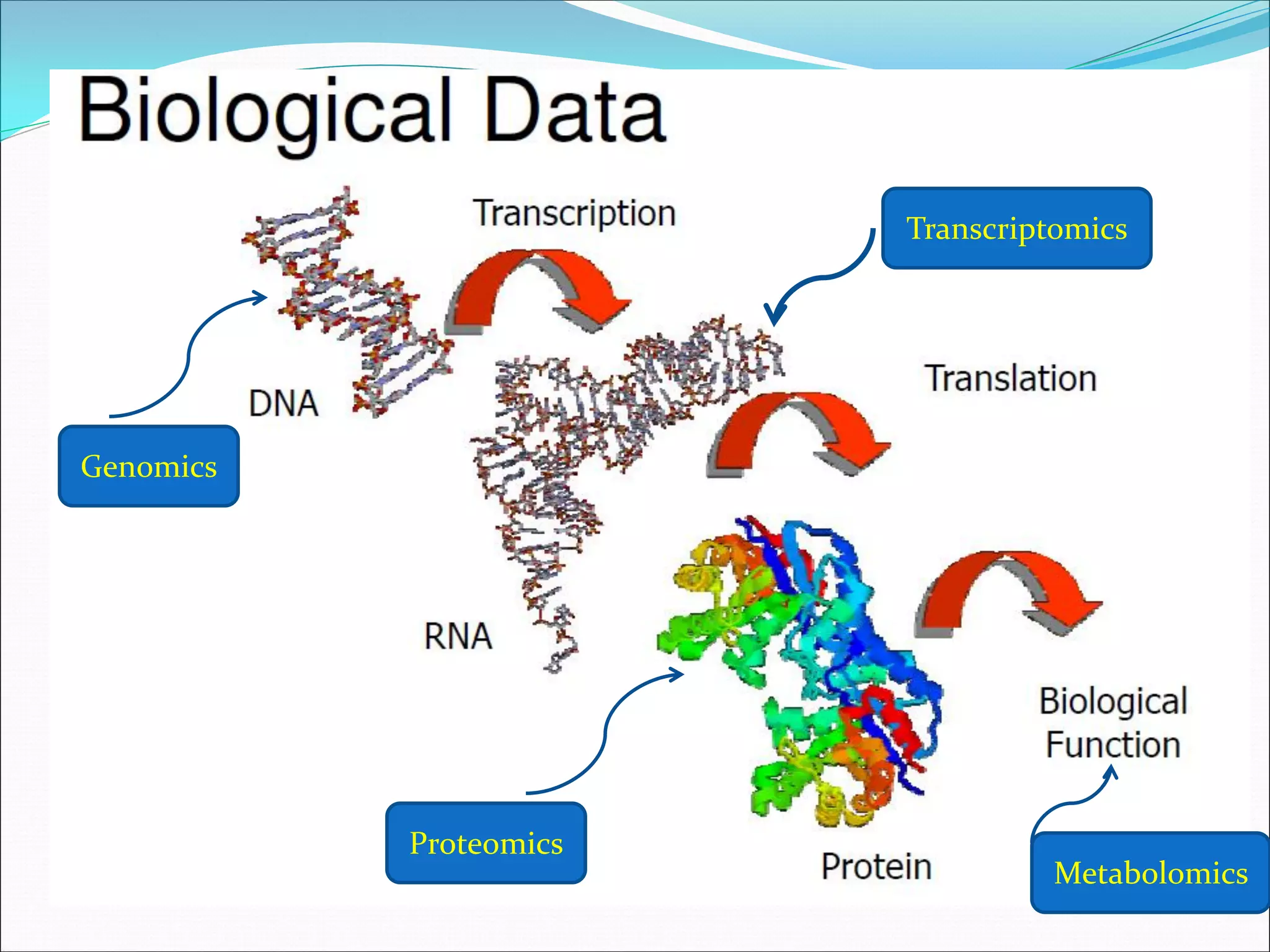
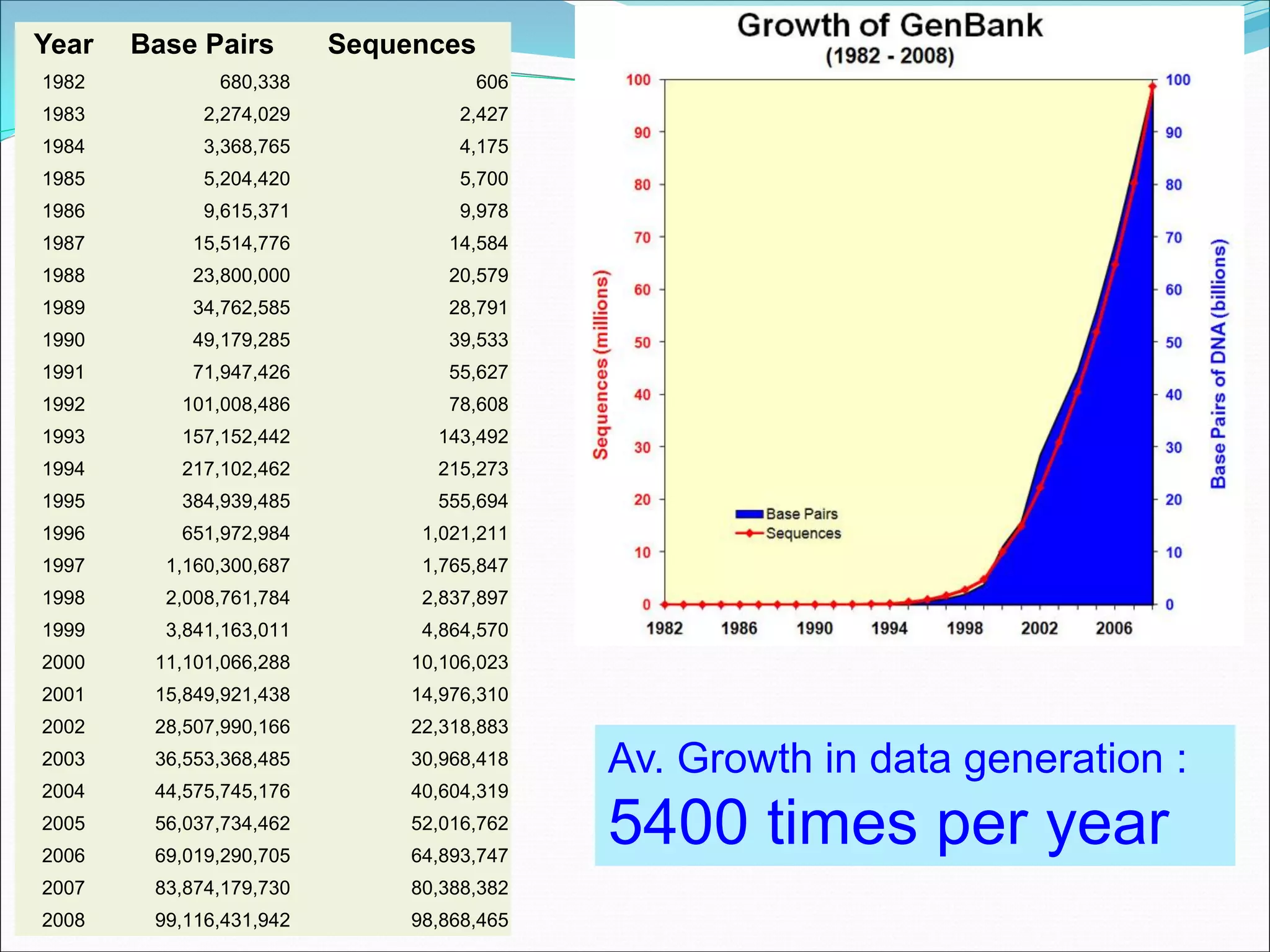
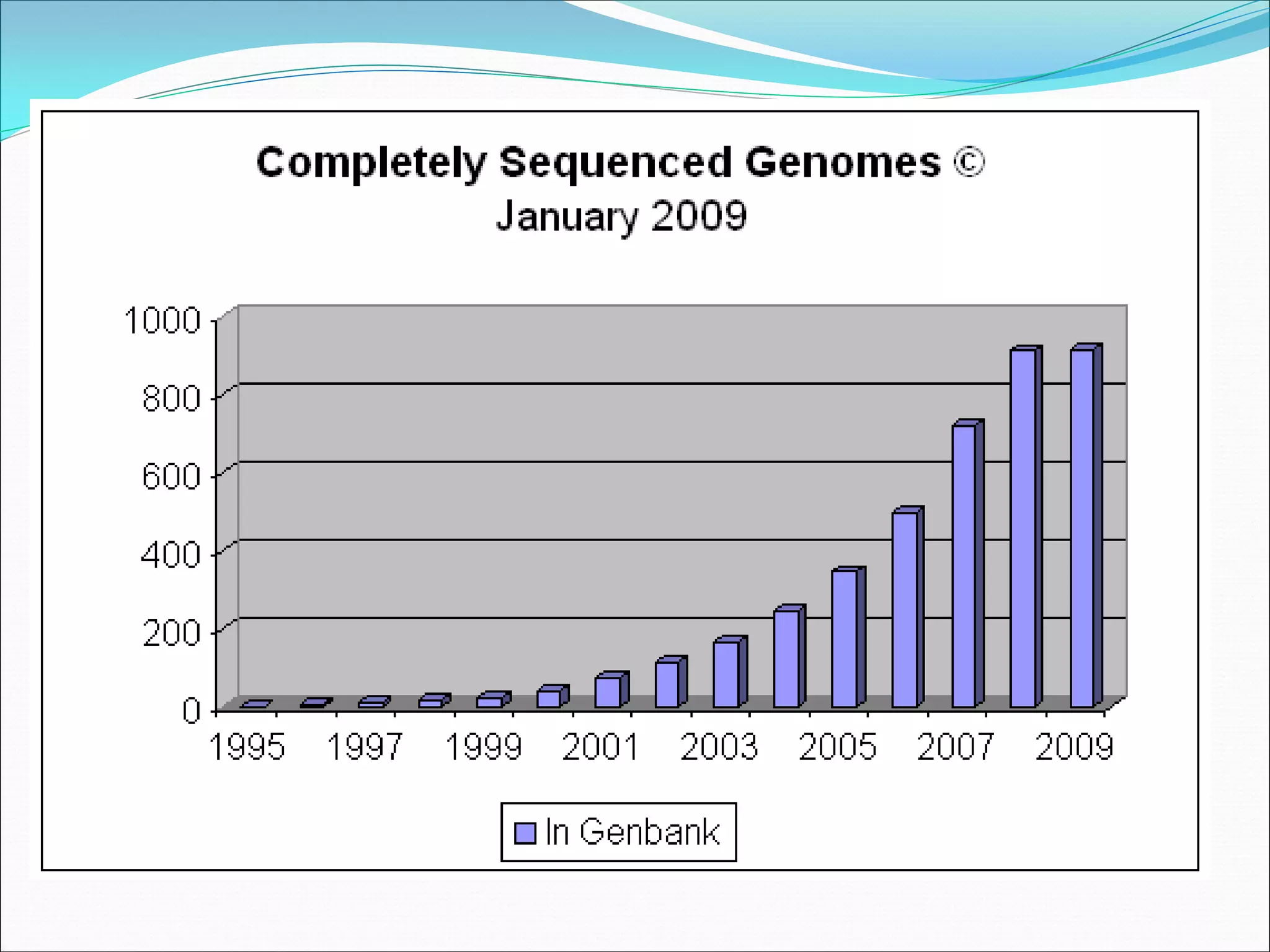

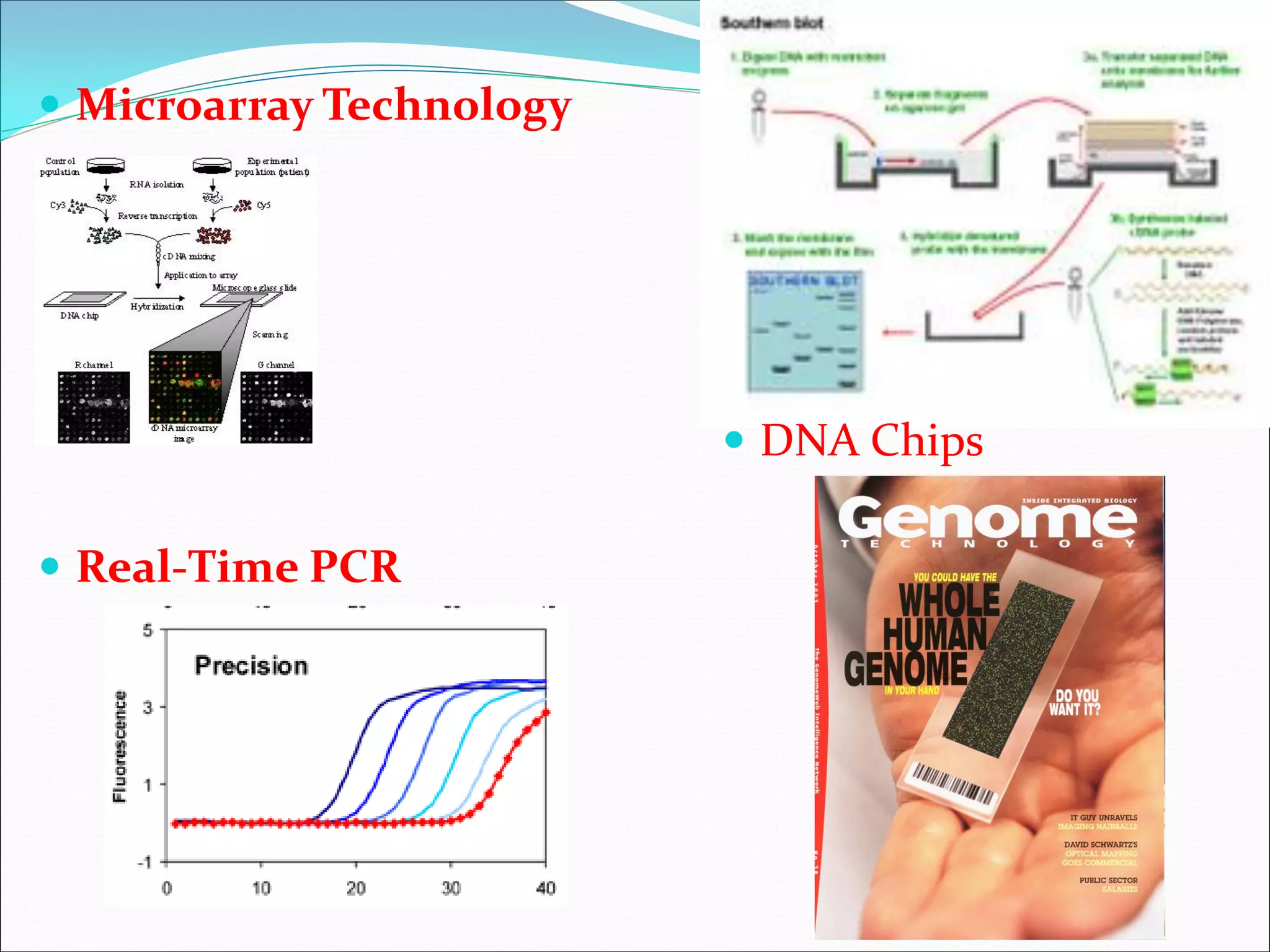

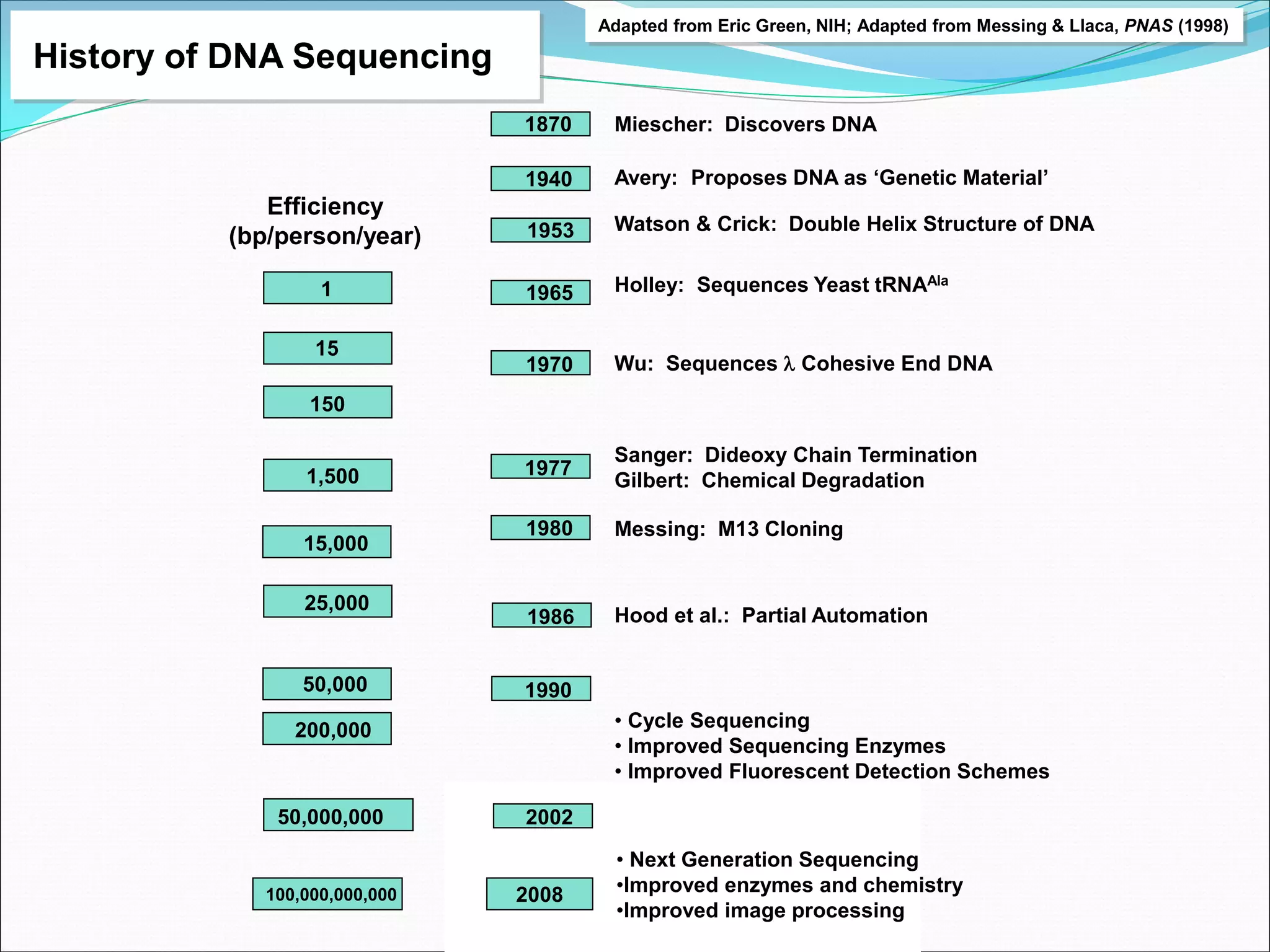















































This document provides an overview of bioinformatics and some key concepts: - It discusses the exponential growth of biological data from technologies like PCR and microarrays, and how bioinformatics is needed to analyze this data. - Bioinformatics is defined as integrating biology and computer science to collect, analyze, and interpret large amounts of molecular-level information. It uses databases and tools to study genomes, proteins, and biological processes. - Major databases like GenBank, EMBL, and SwissProt store DNA, RNA, protein sequences and provide access to researchers. Tools like BLAST are used to search databases and analyze sequences. - Benefits of bioinformatics include advances in medicine, agriculture, forensics























































































