Downloaded 29 times






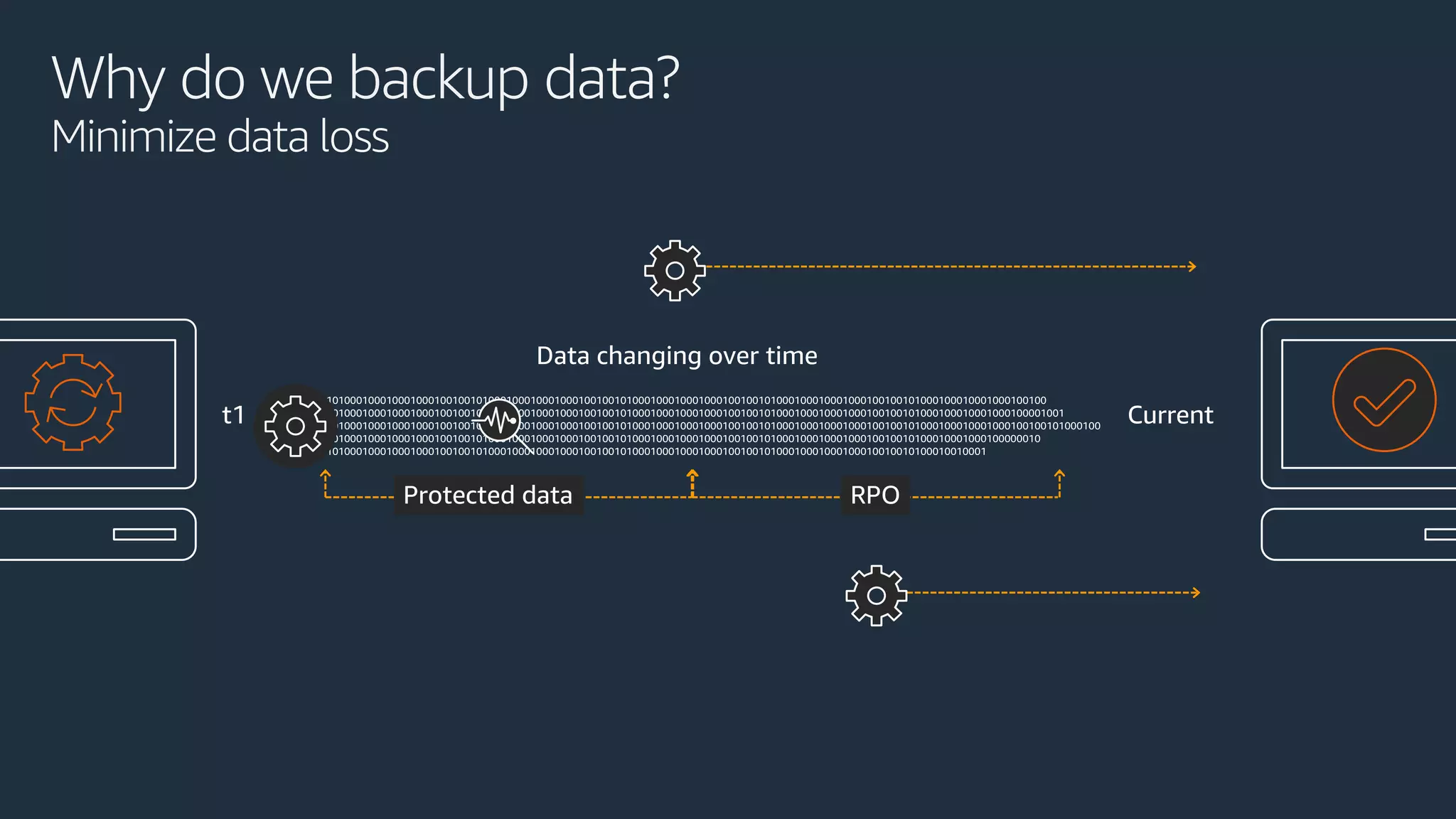
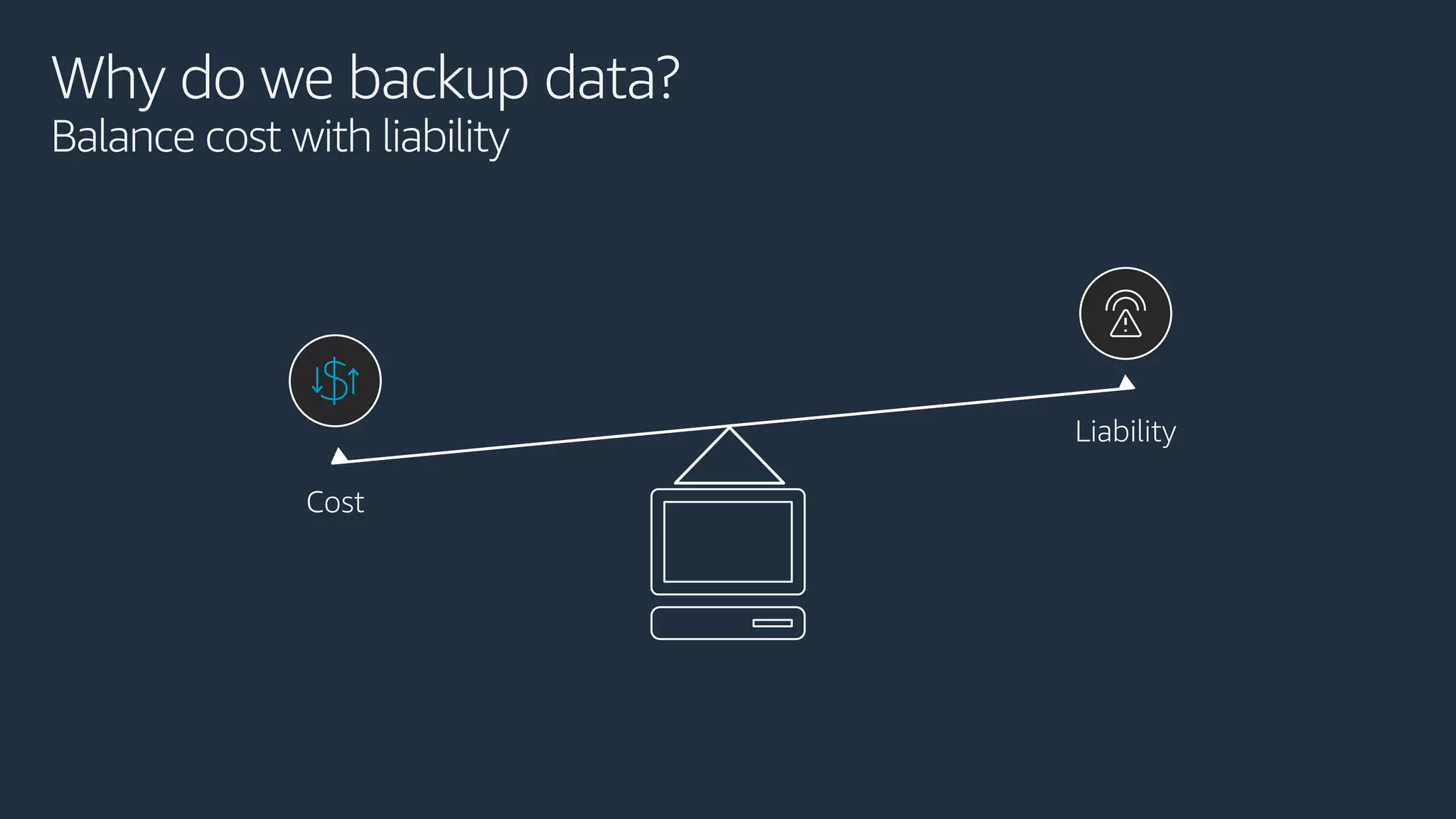


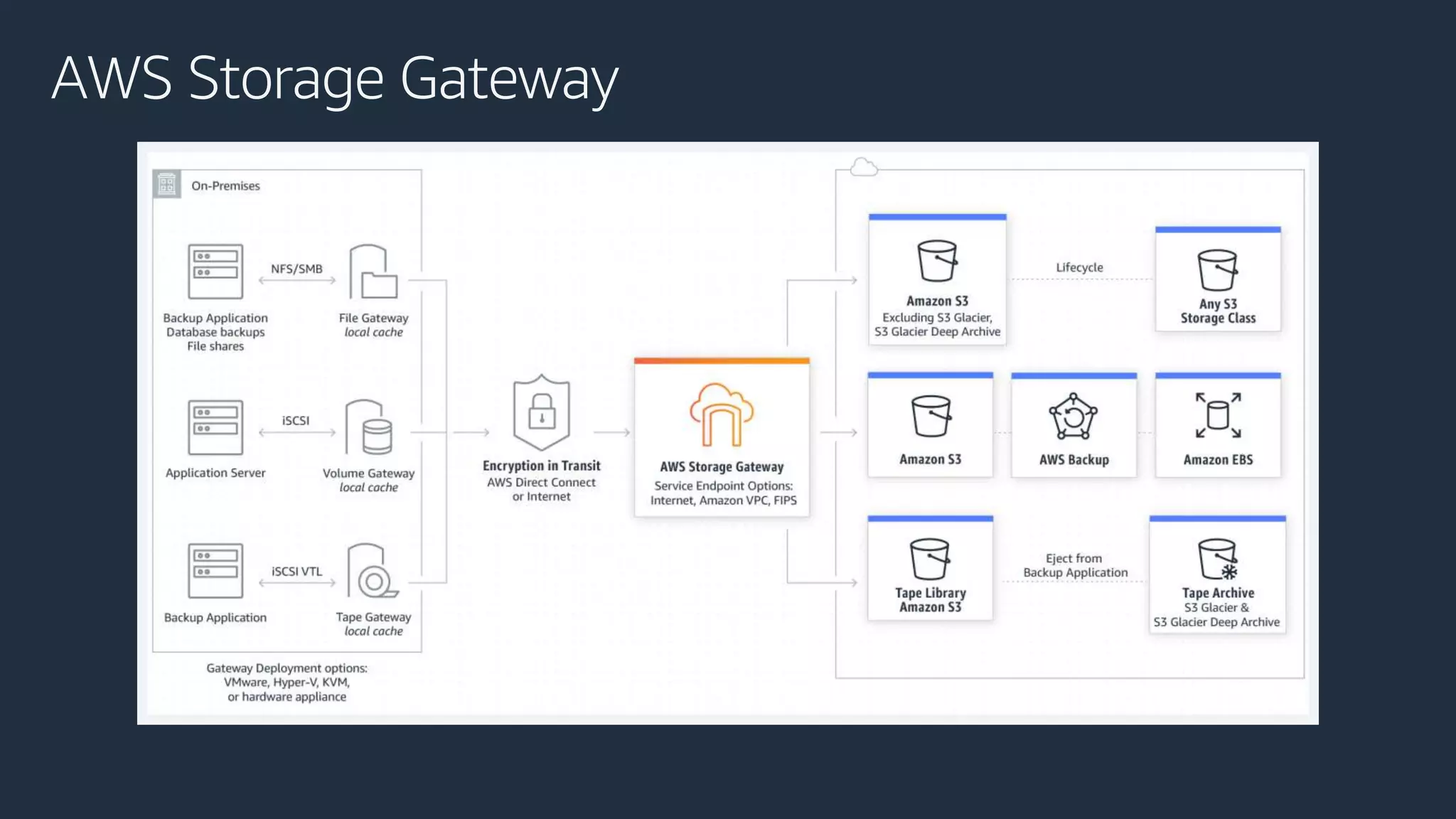
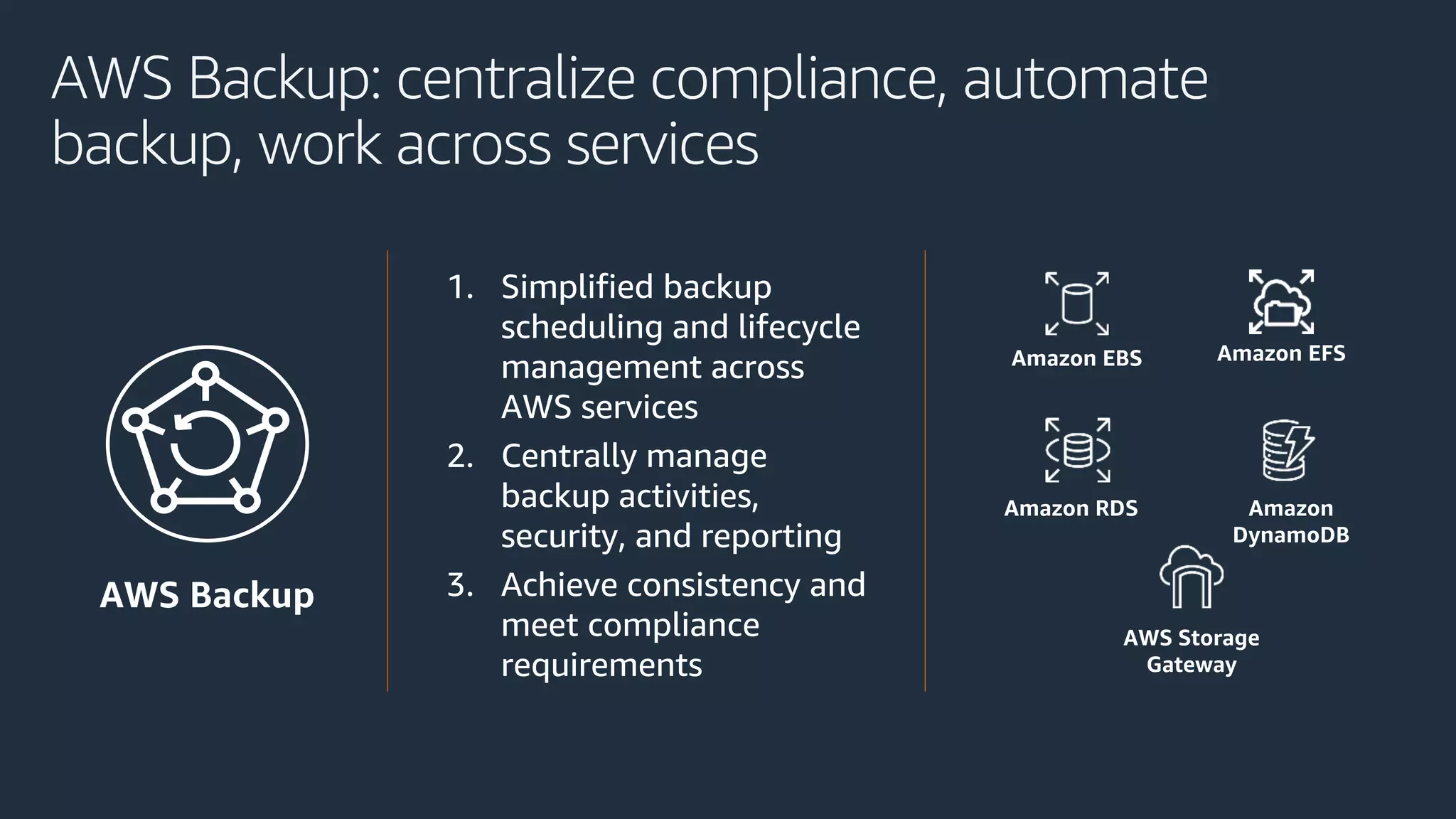

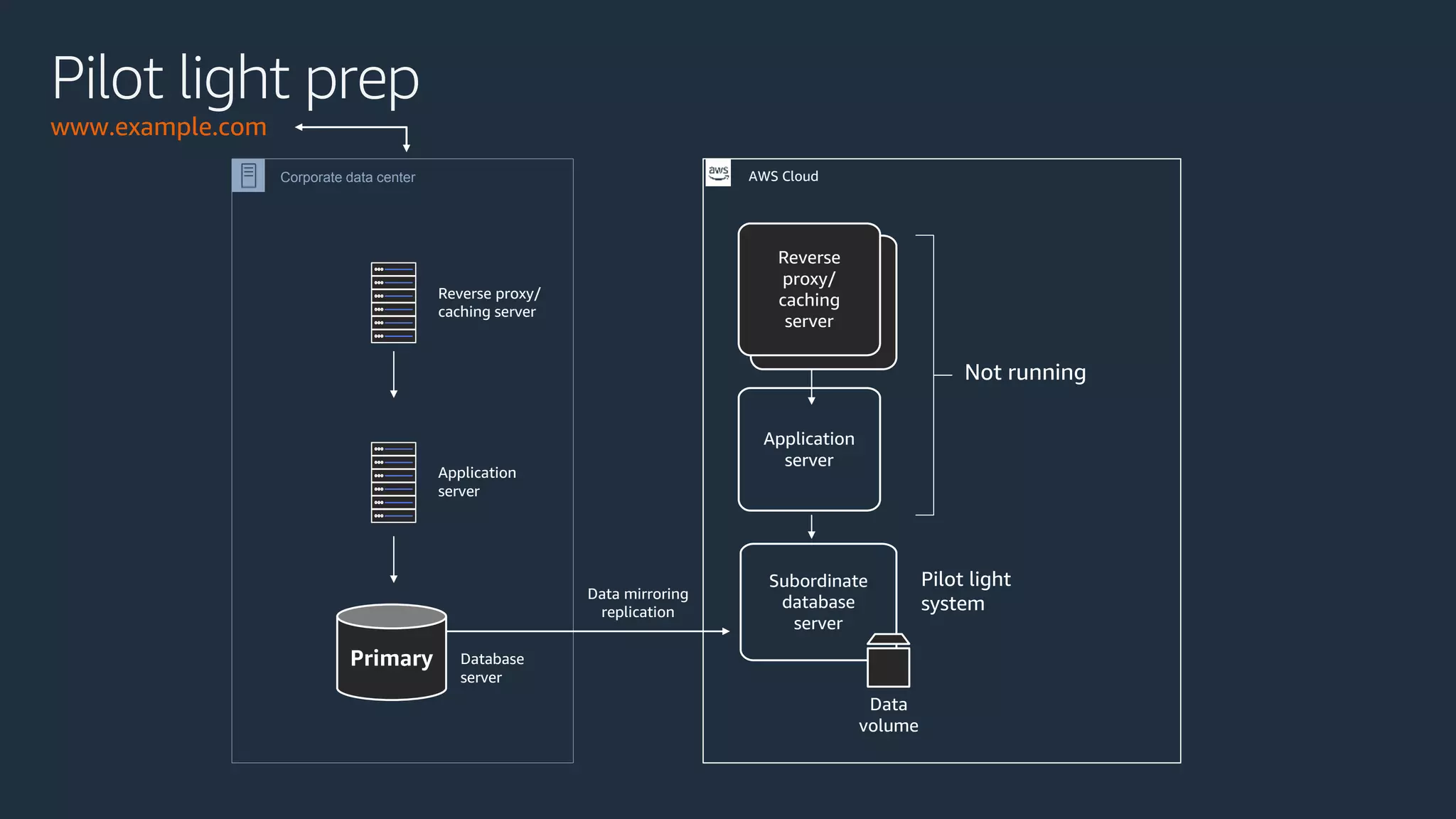
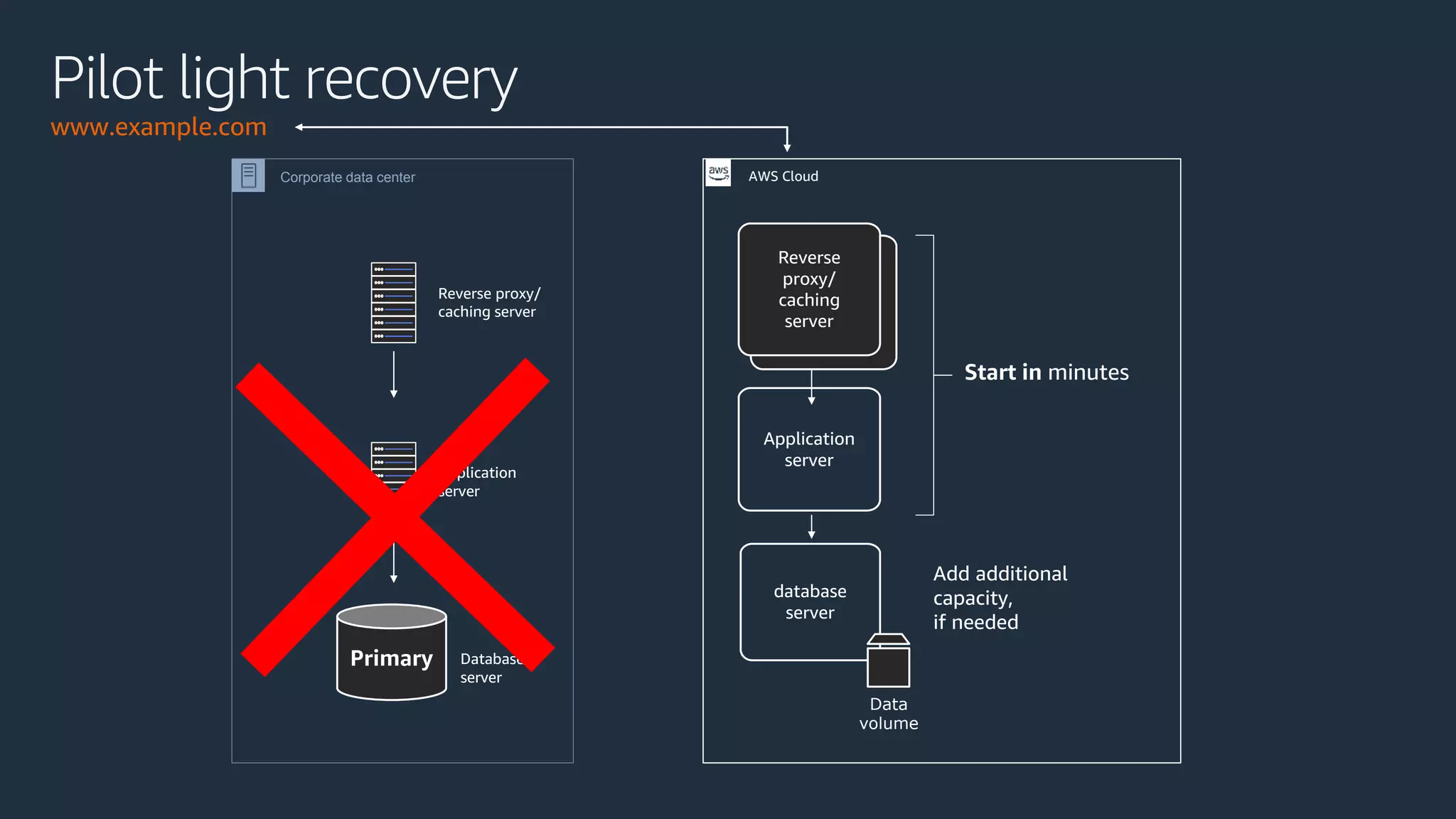
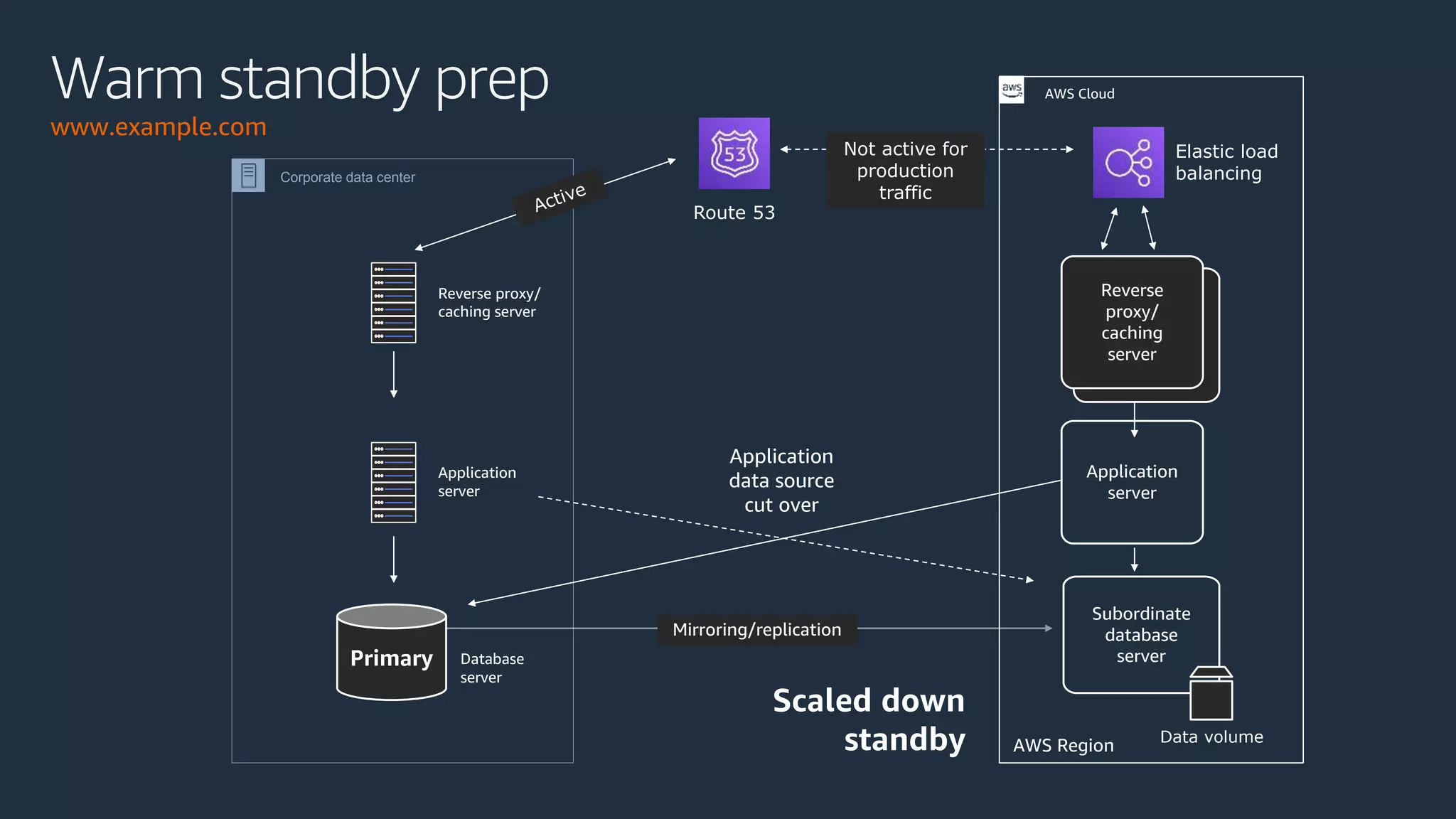
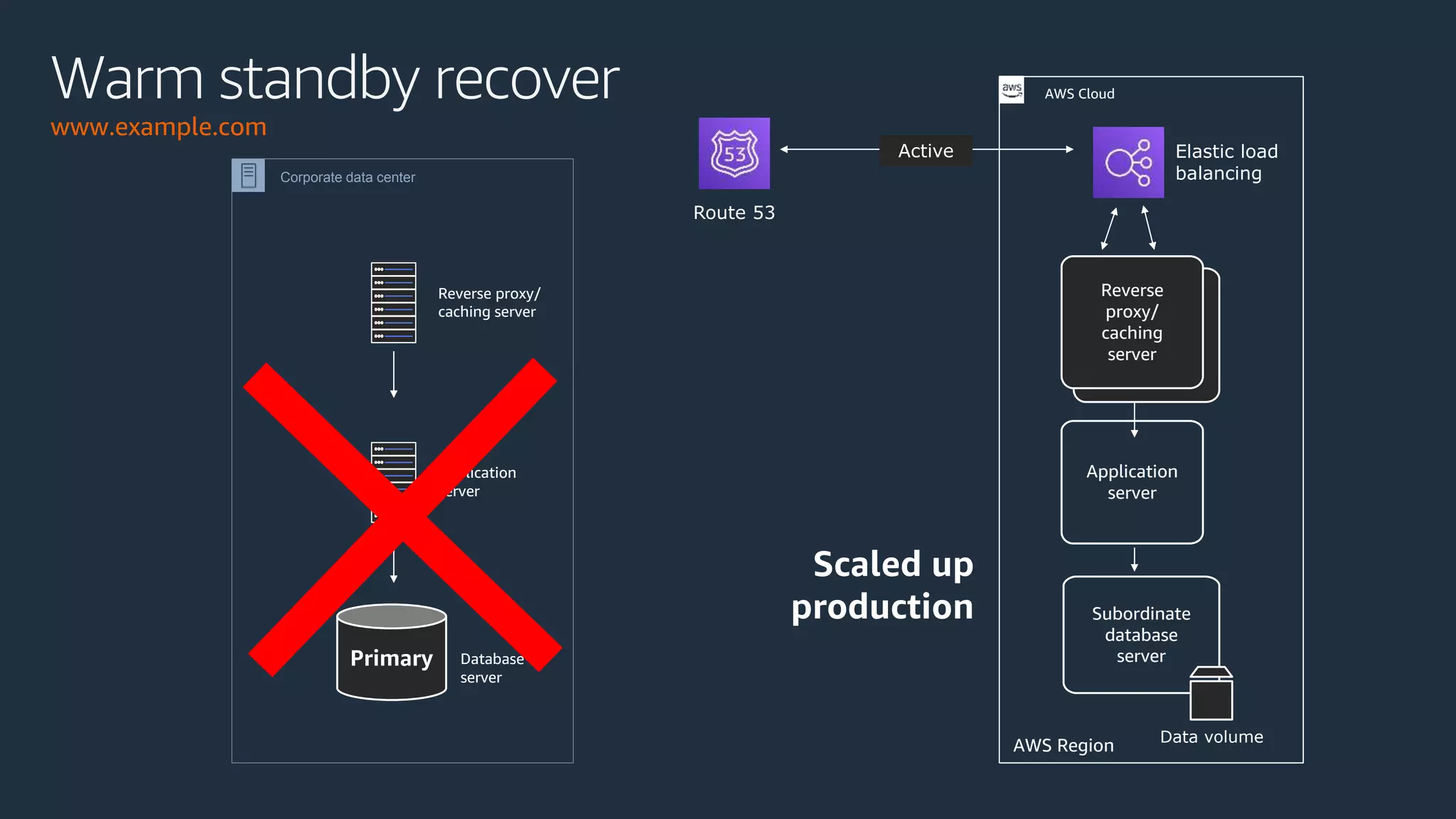
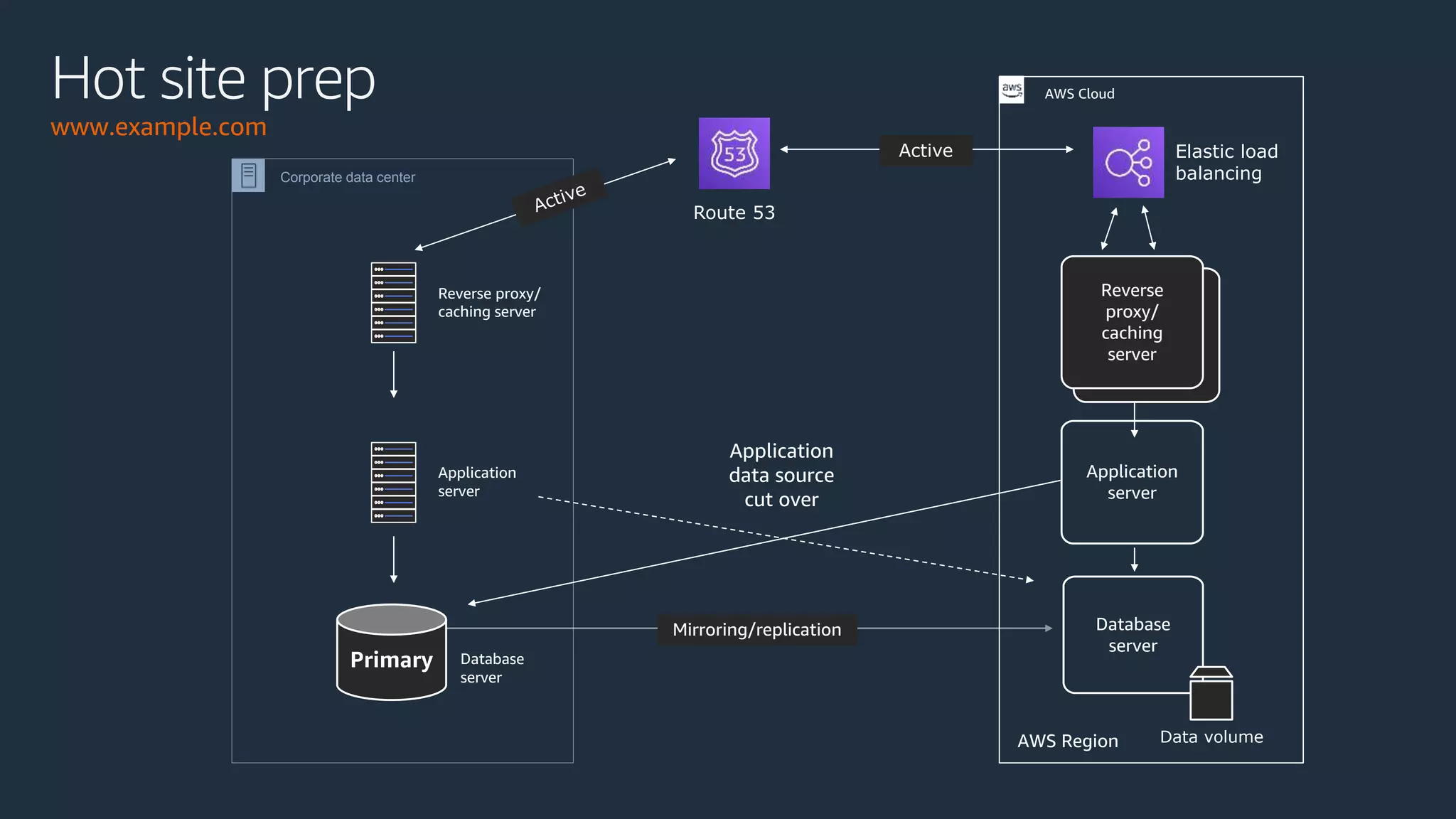
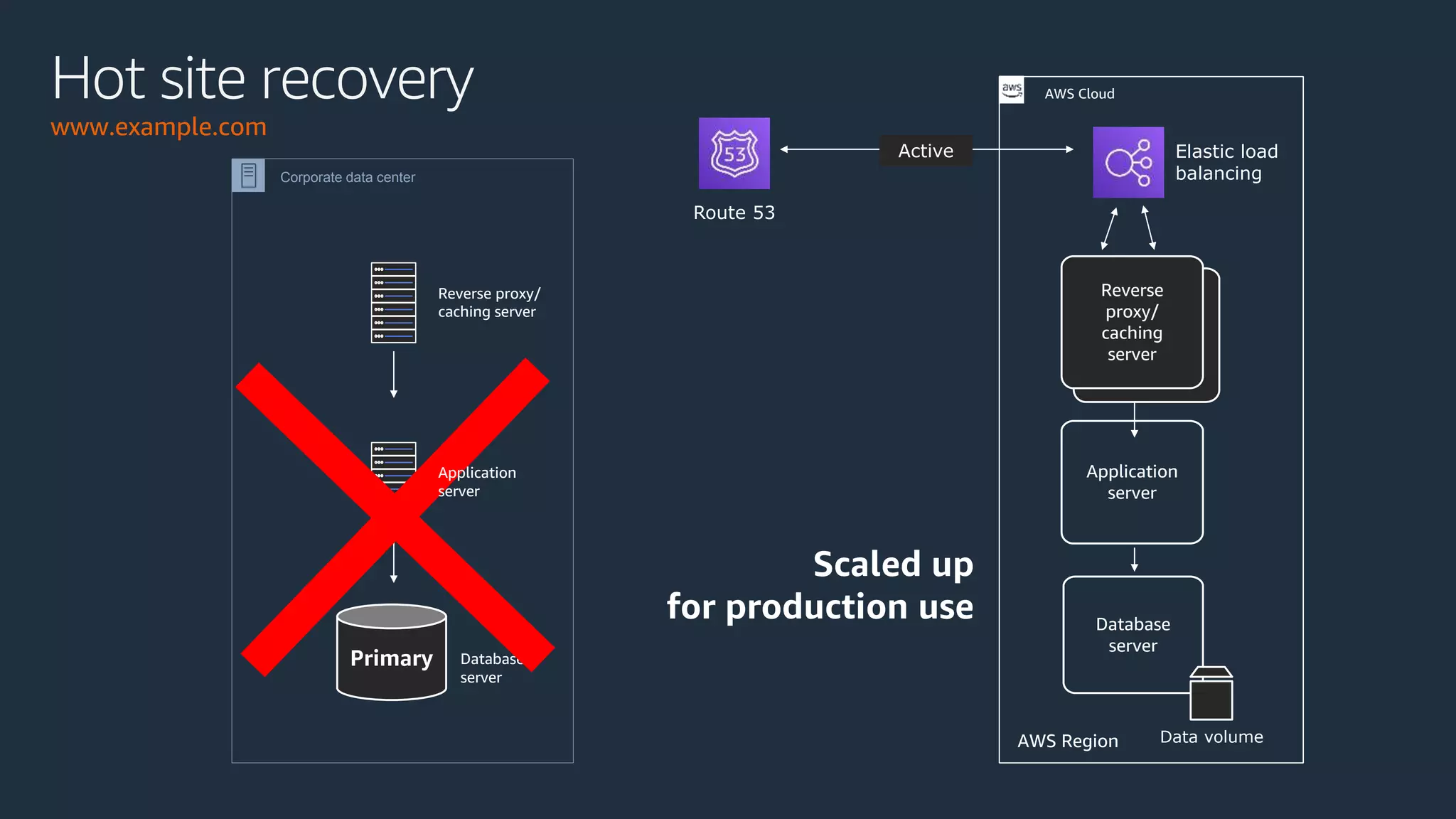



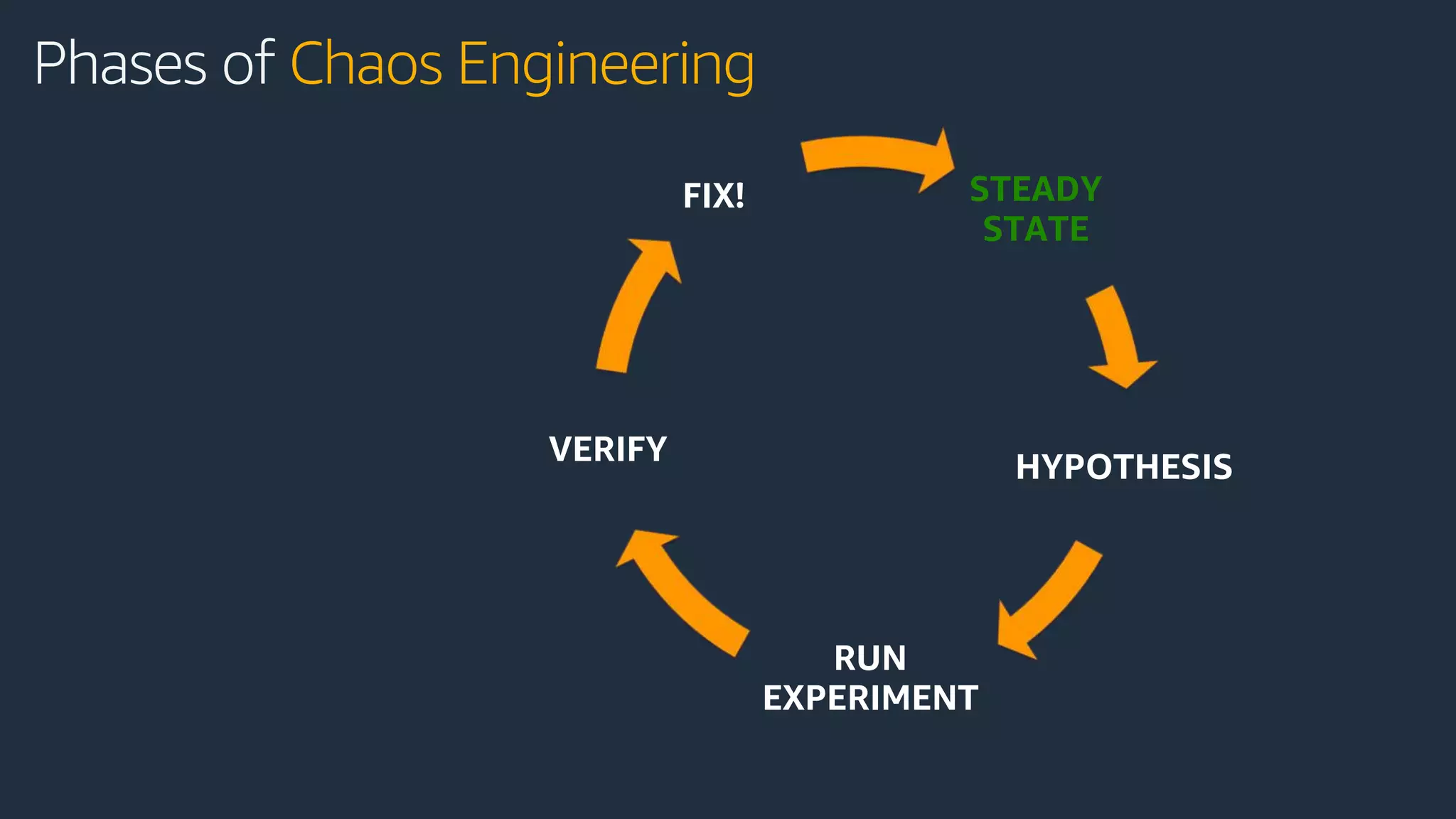




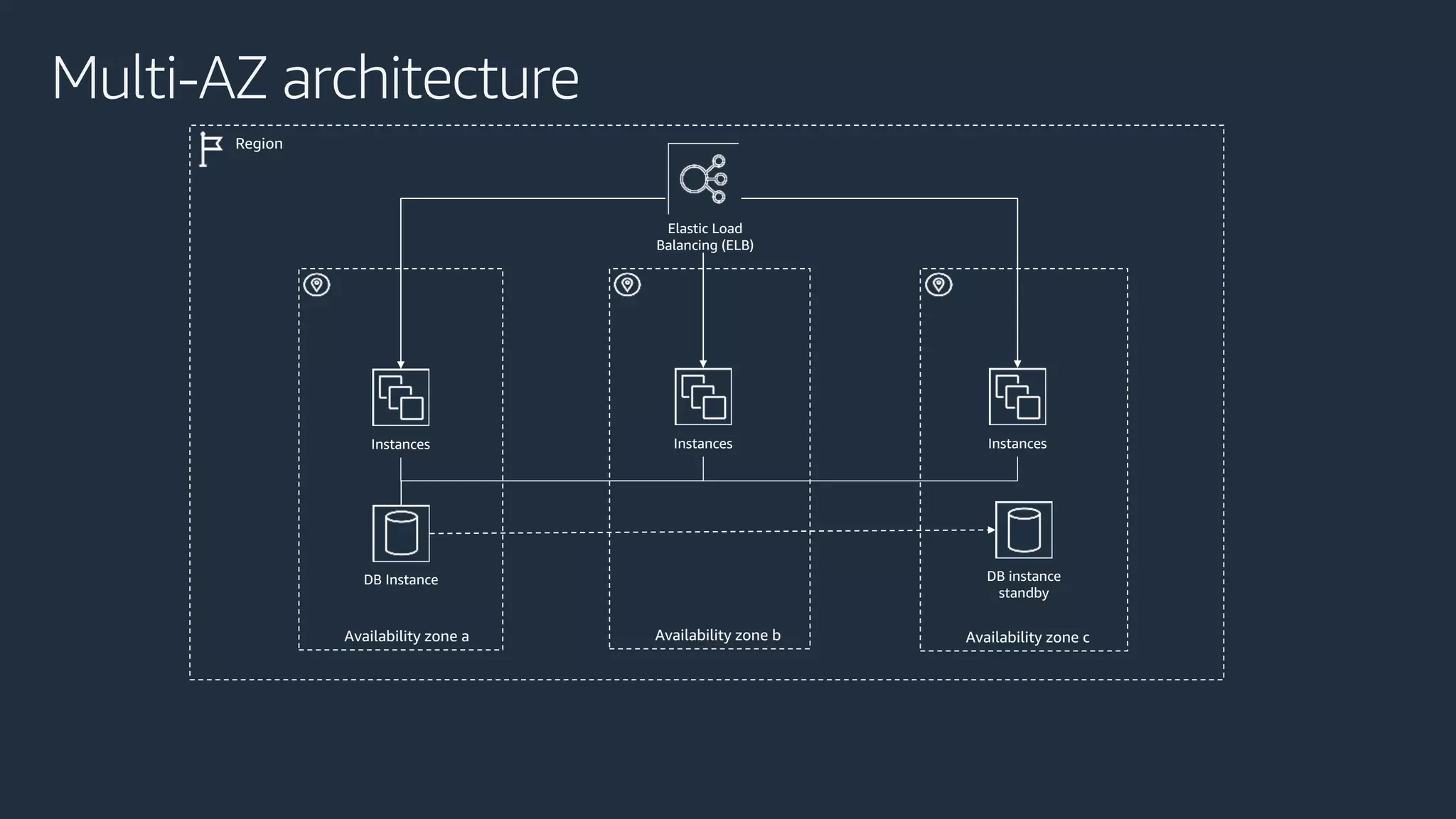
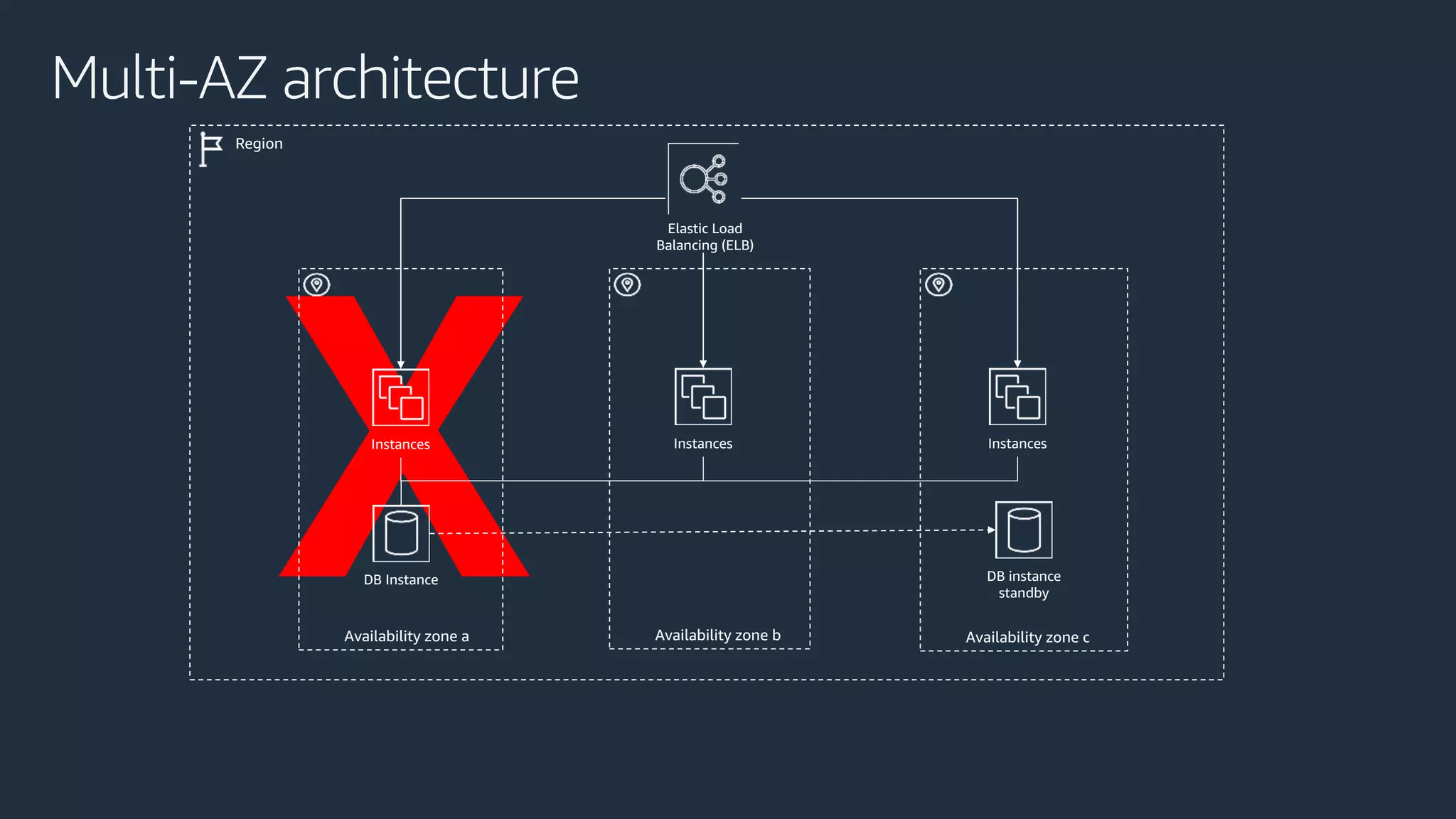
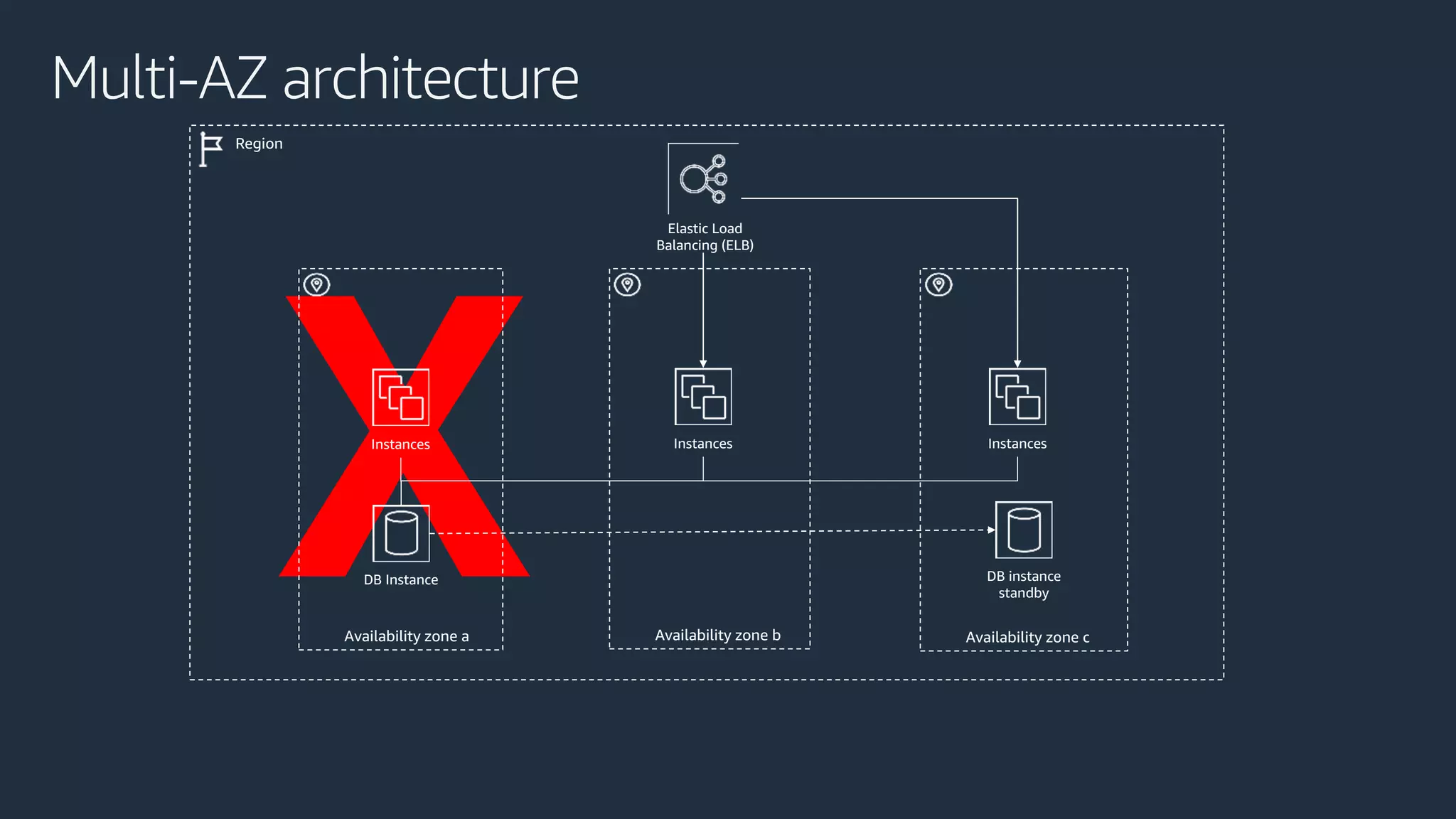
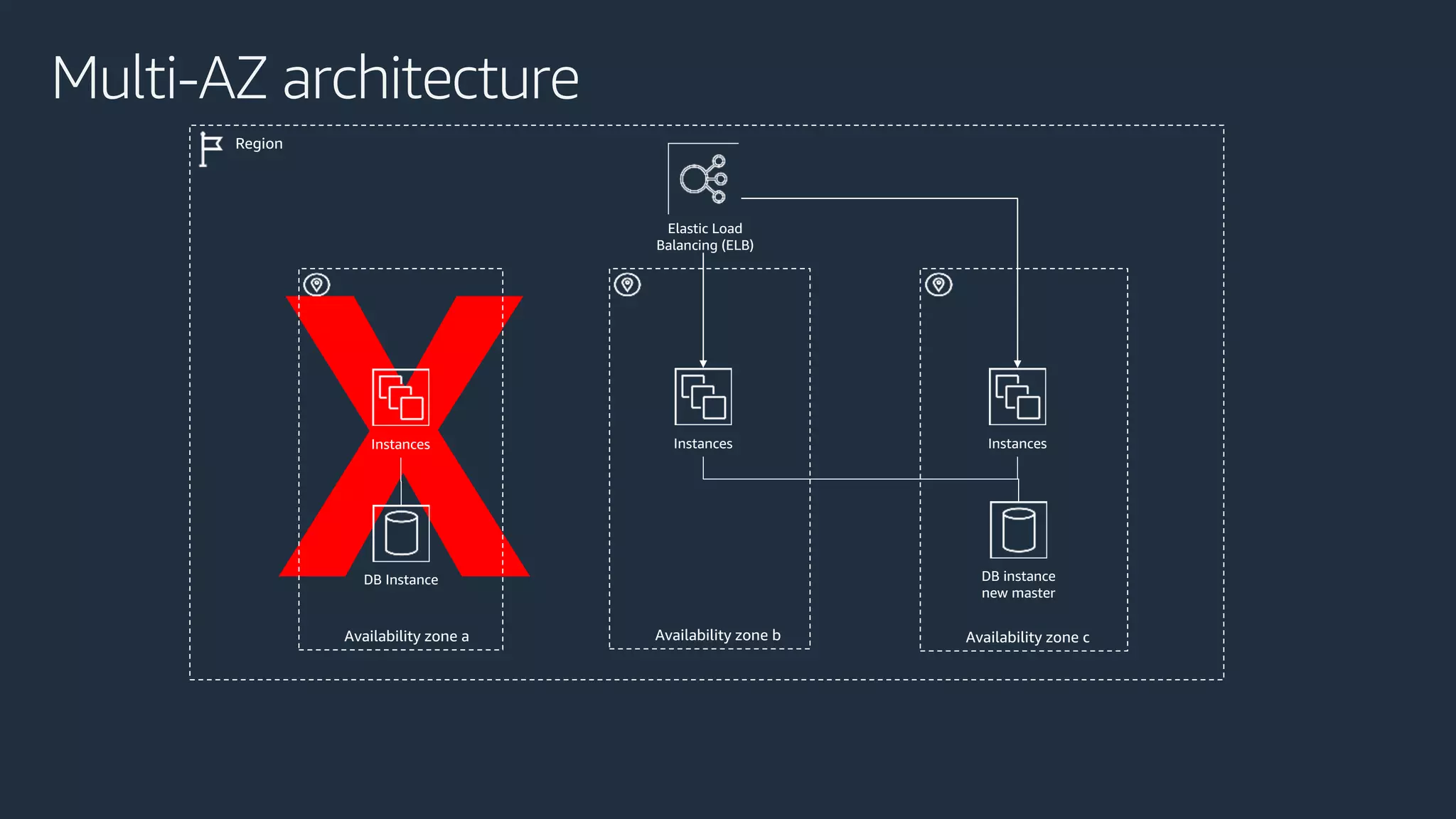
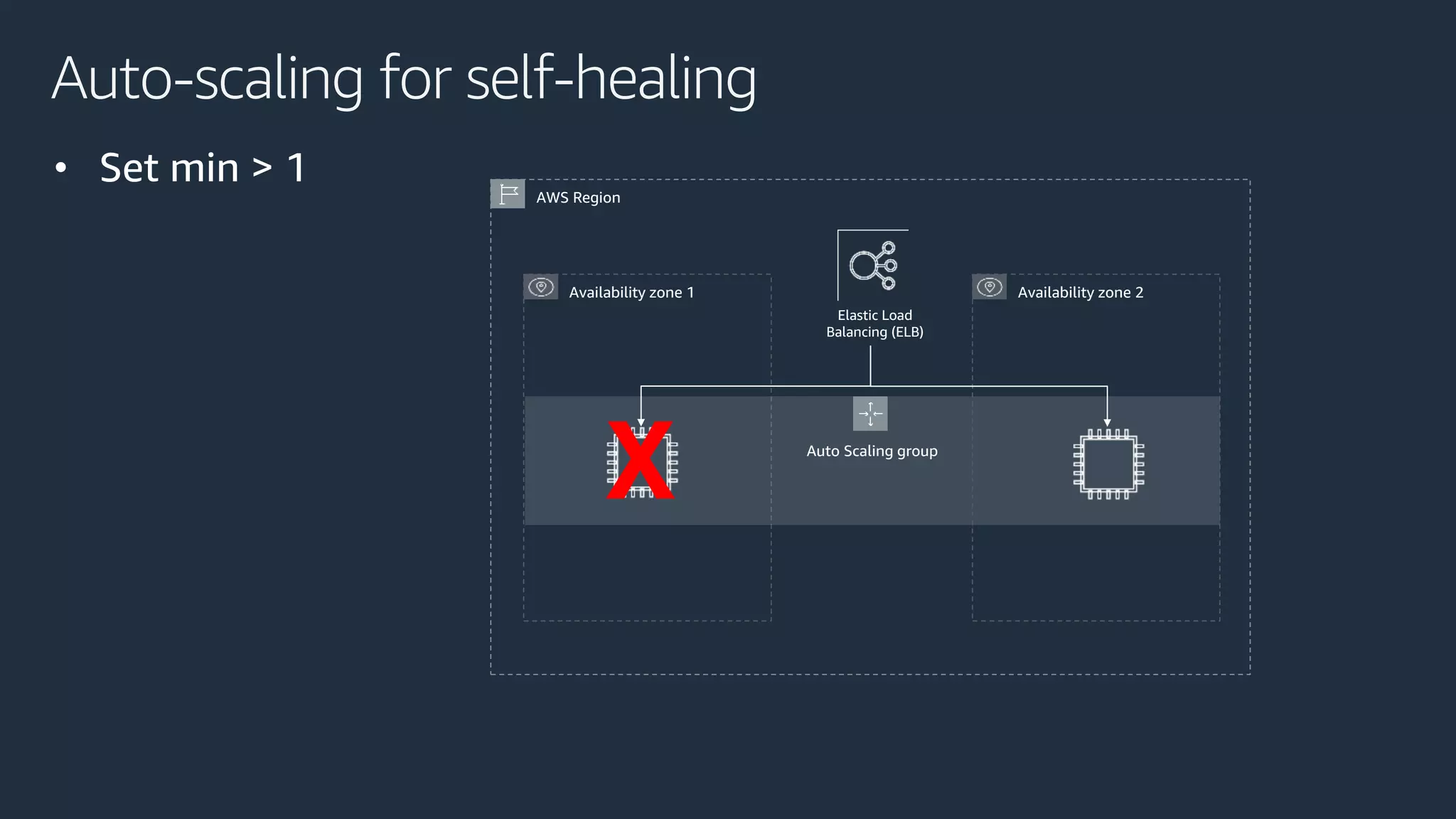

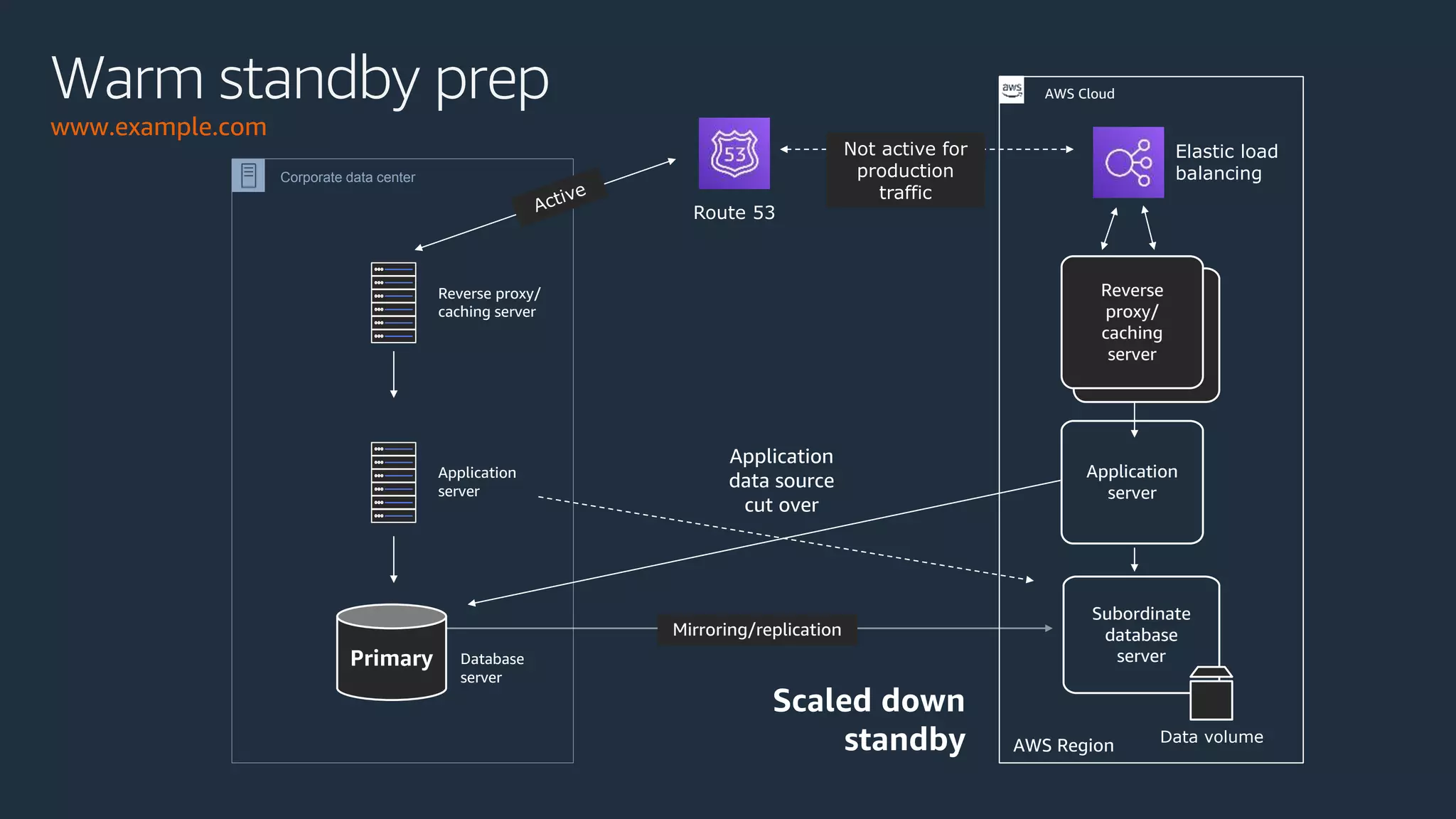
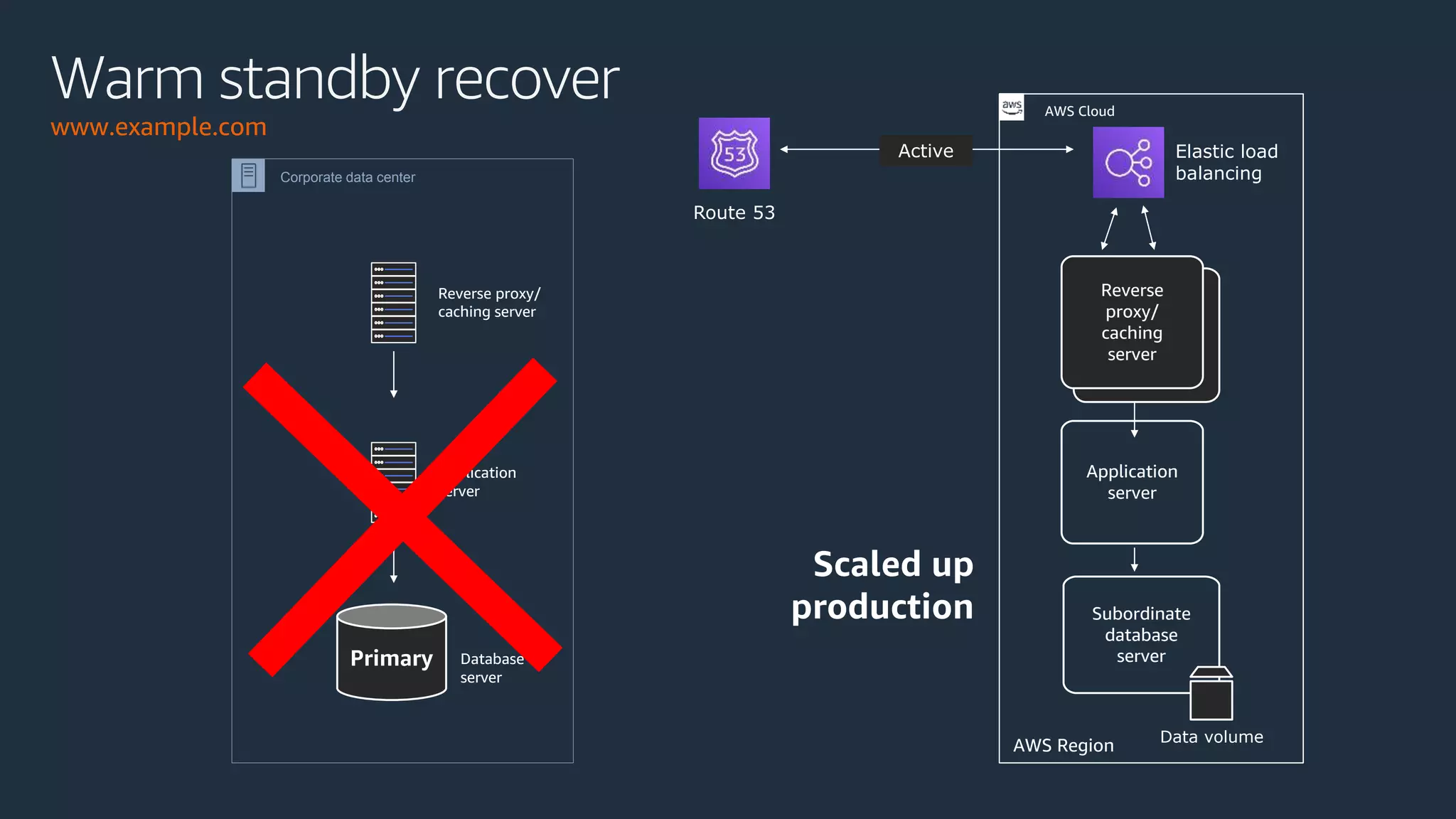
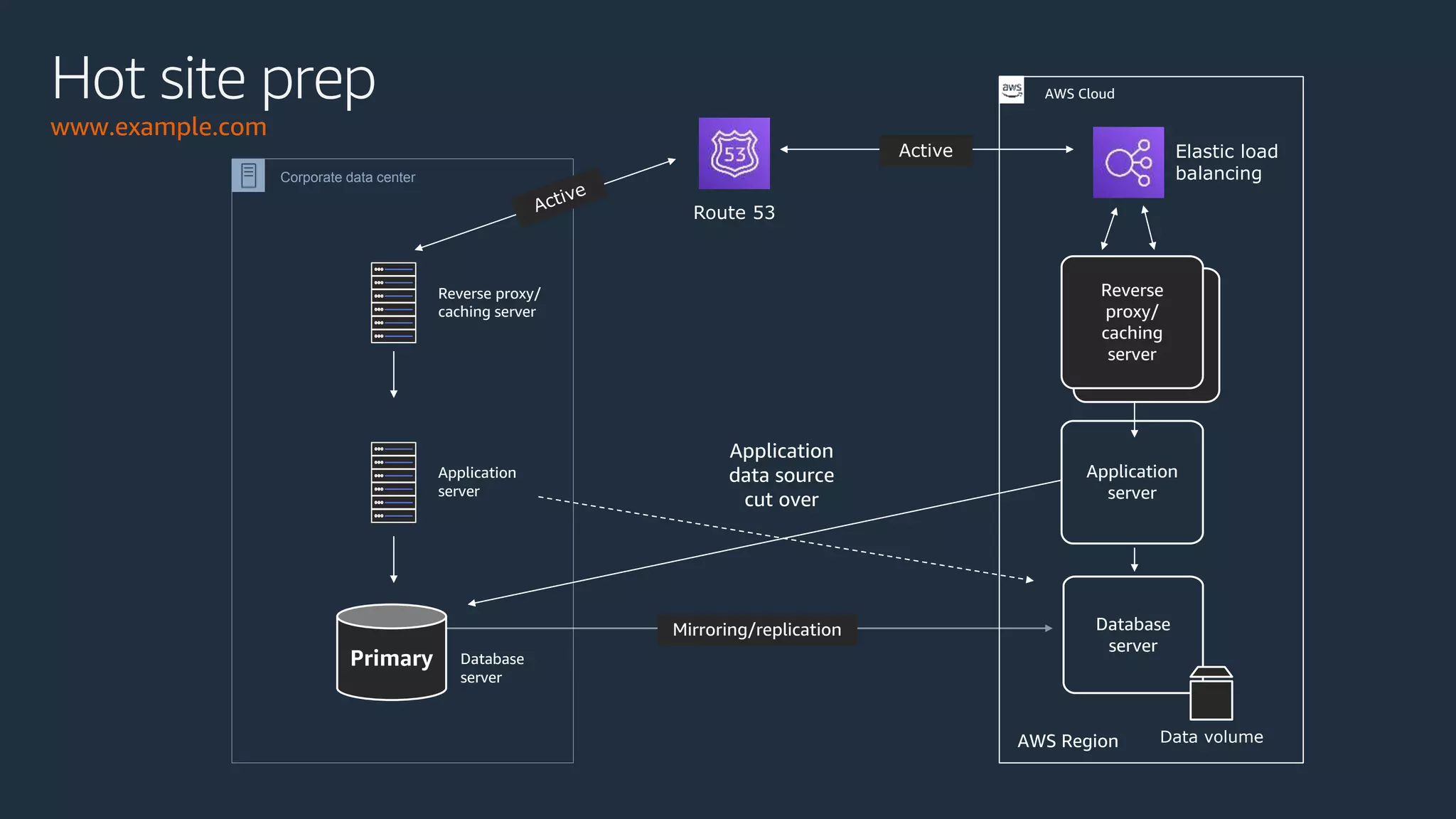
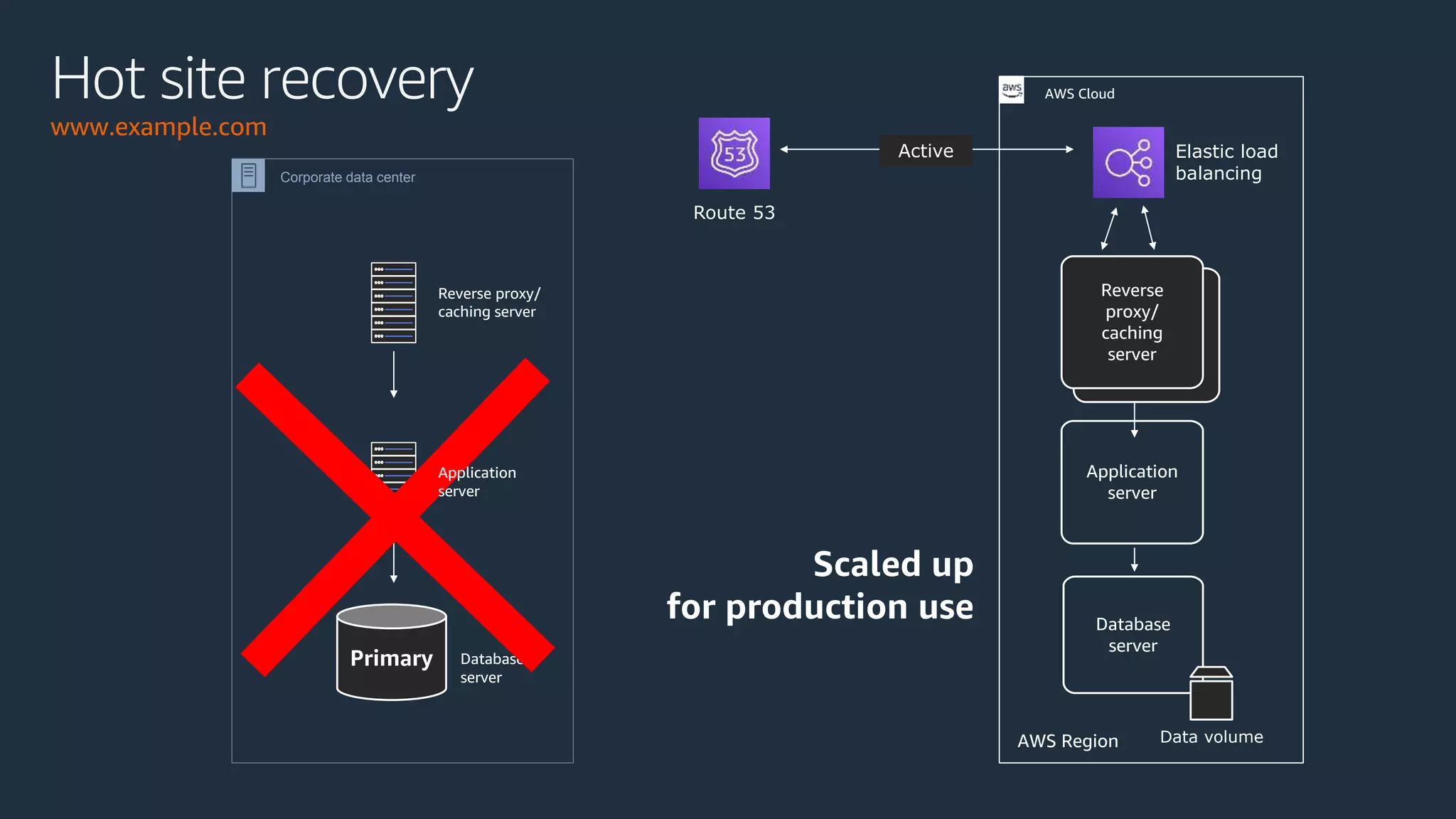
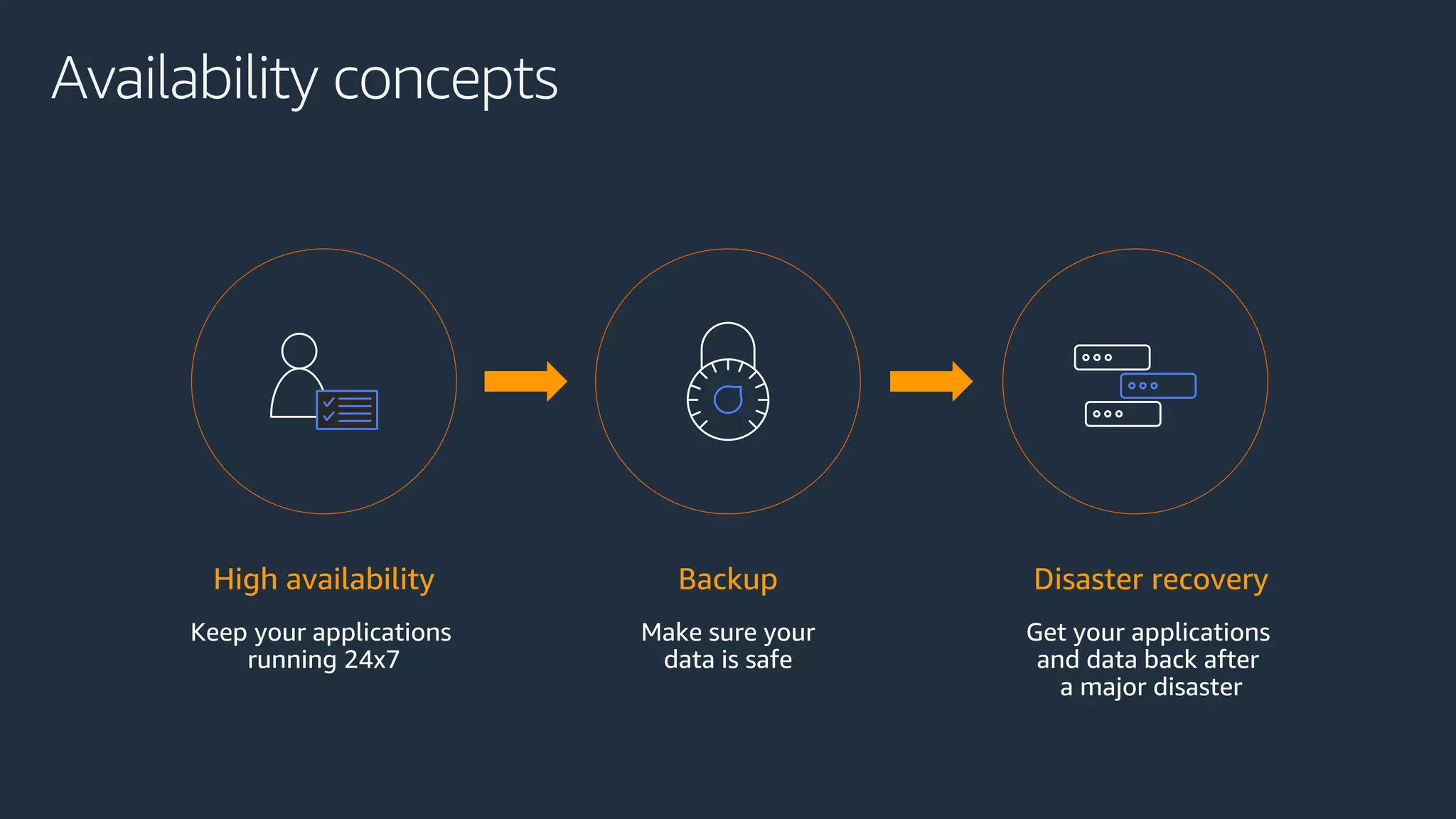











































The document discusses disaster recovery strategies using AWS, outlining key requirements, recovery methods, and backup solutions. It covers four levels of backup complexity and time management, emphasizing the importance of minimizing data loss and balancing costs. Additionally, the document introduces chaos engineering as a means to test system resilience and highlights high availability concepts for continuous operation.





























































