Downloaded 14 times



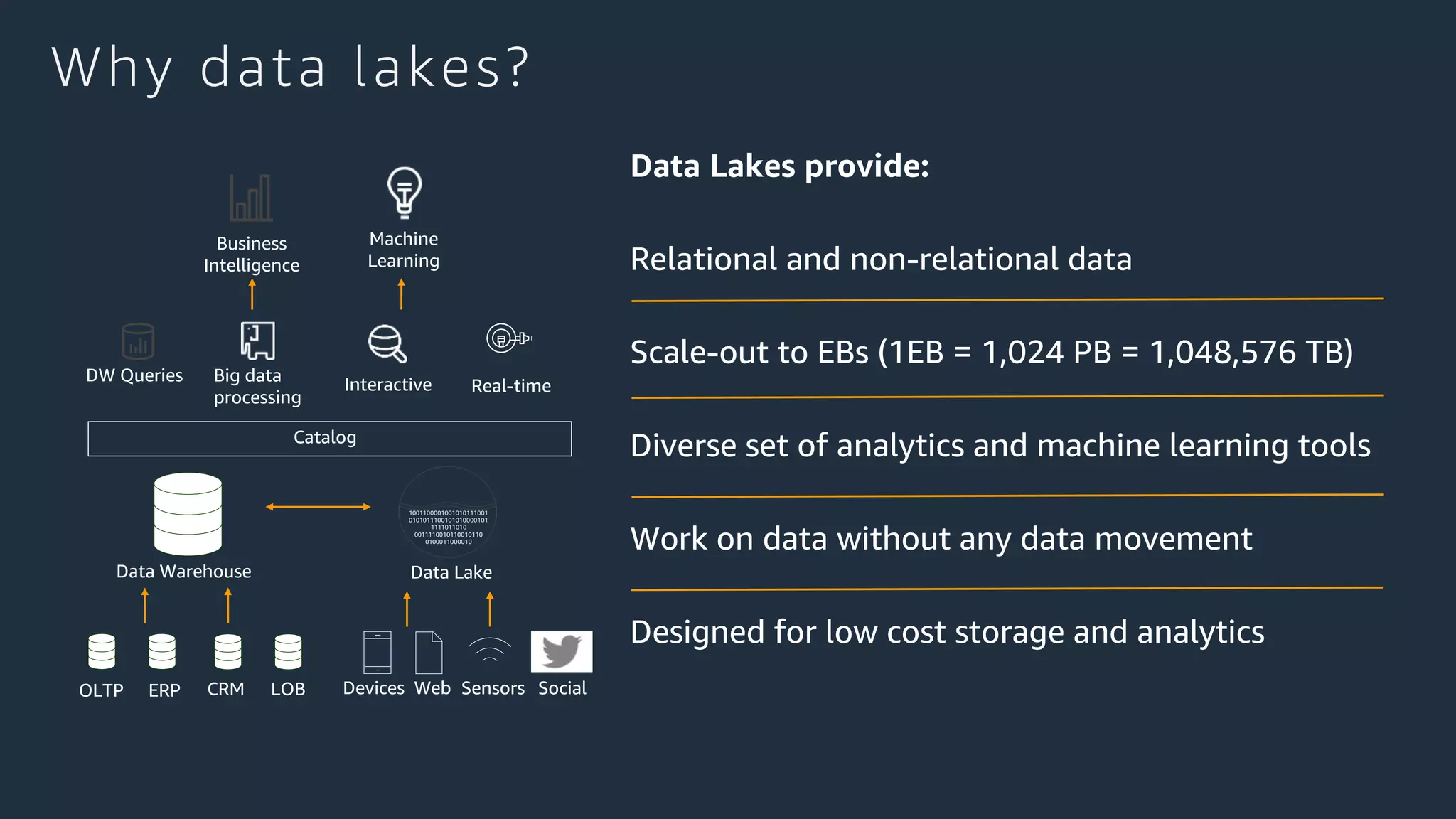

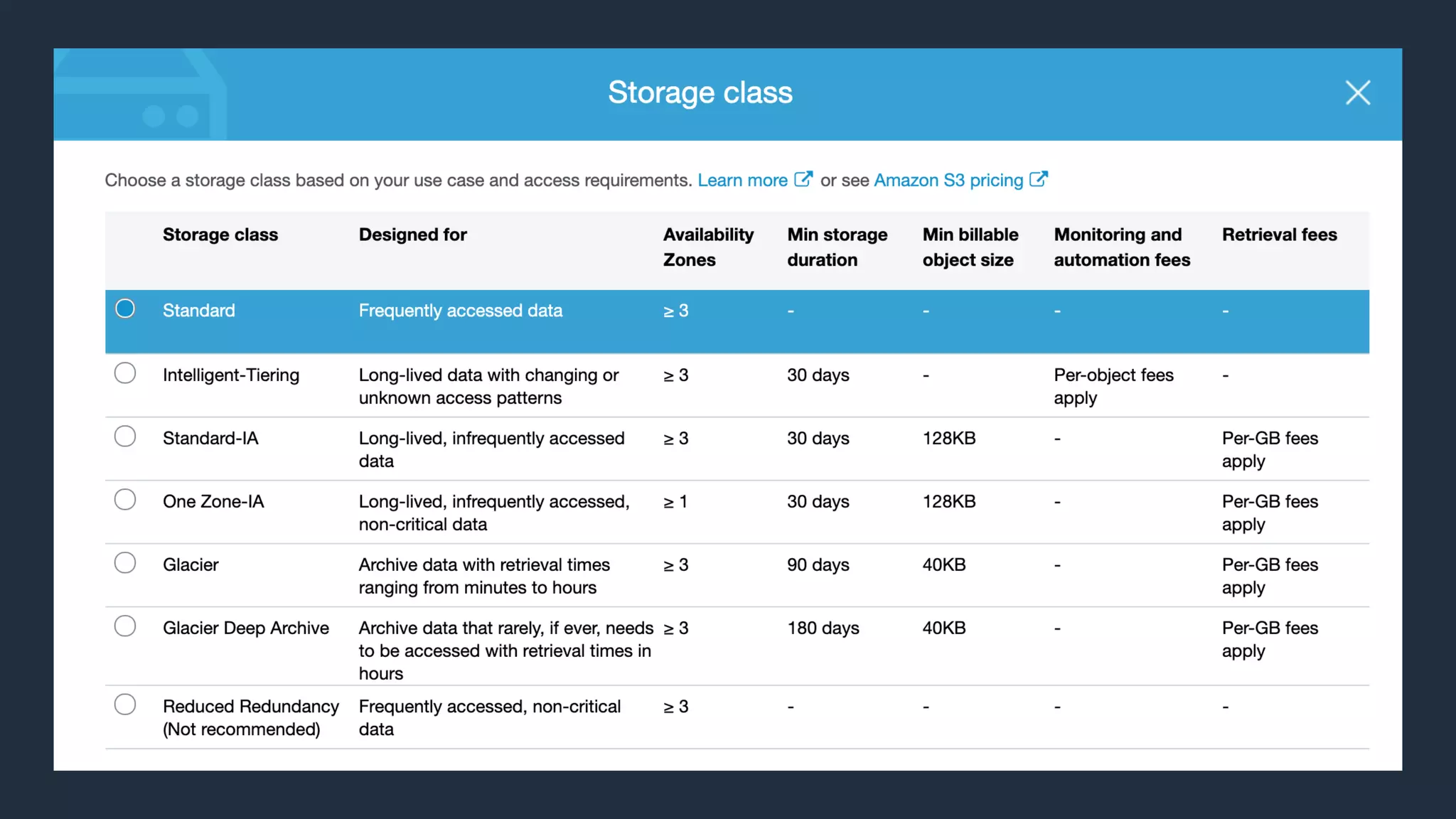
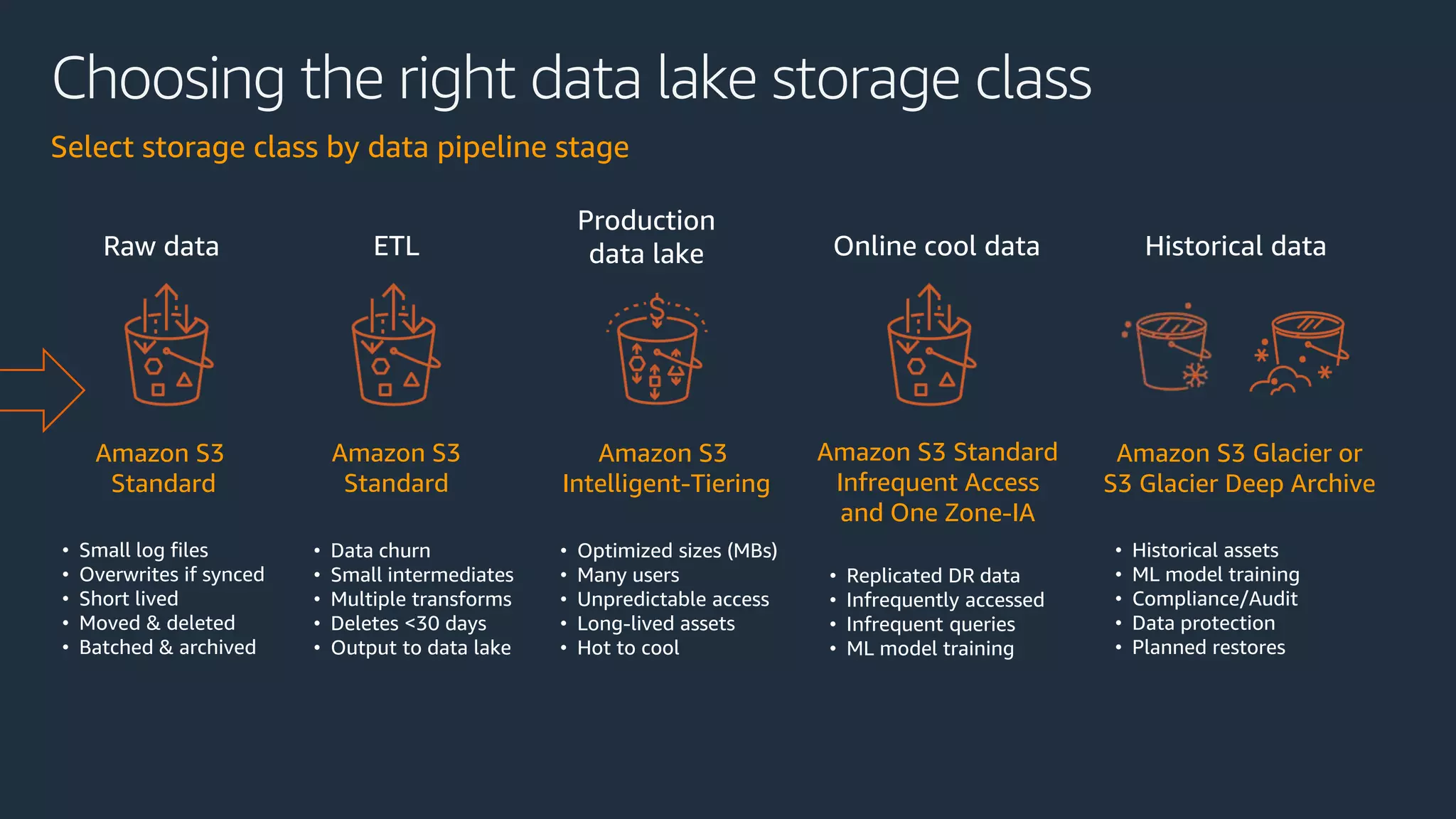
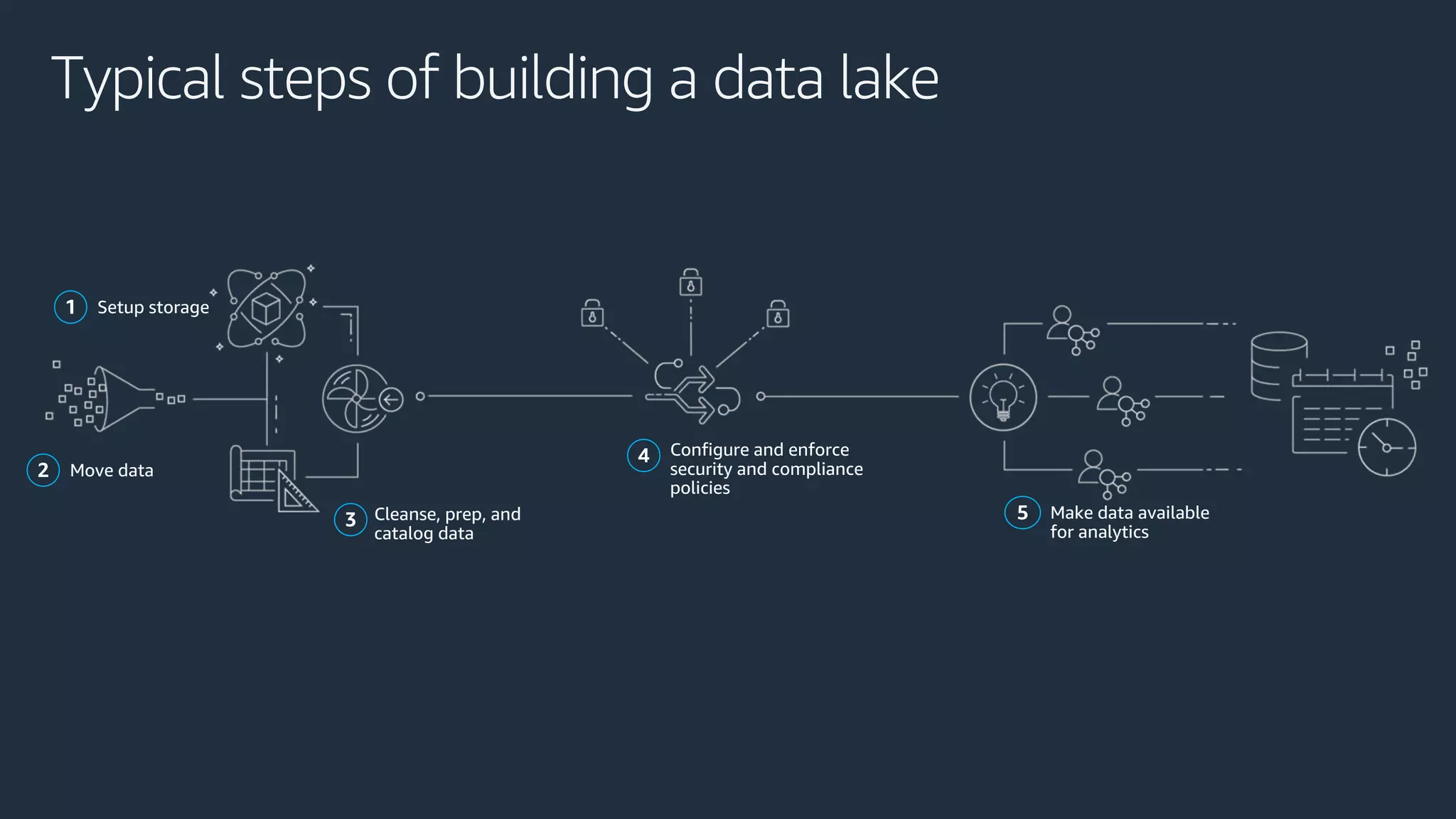



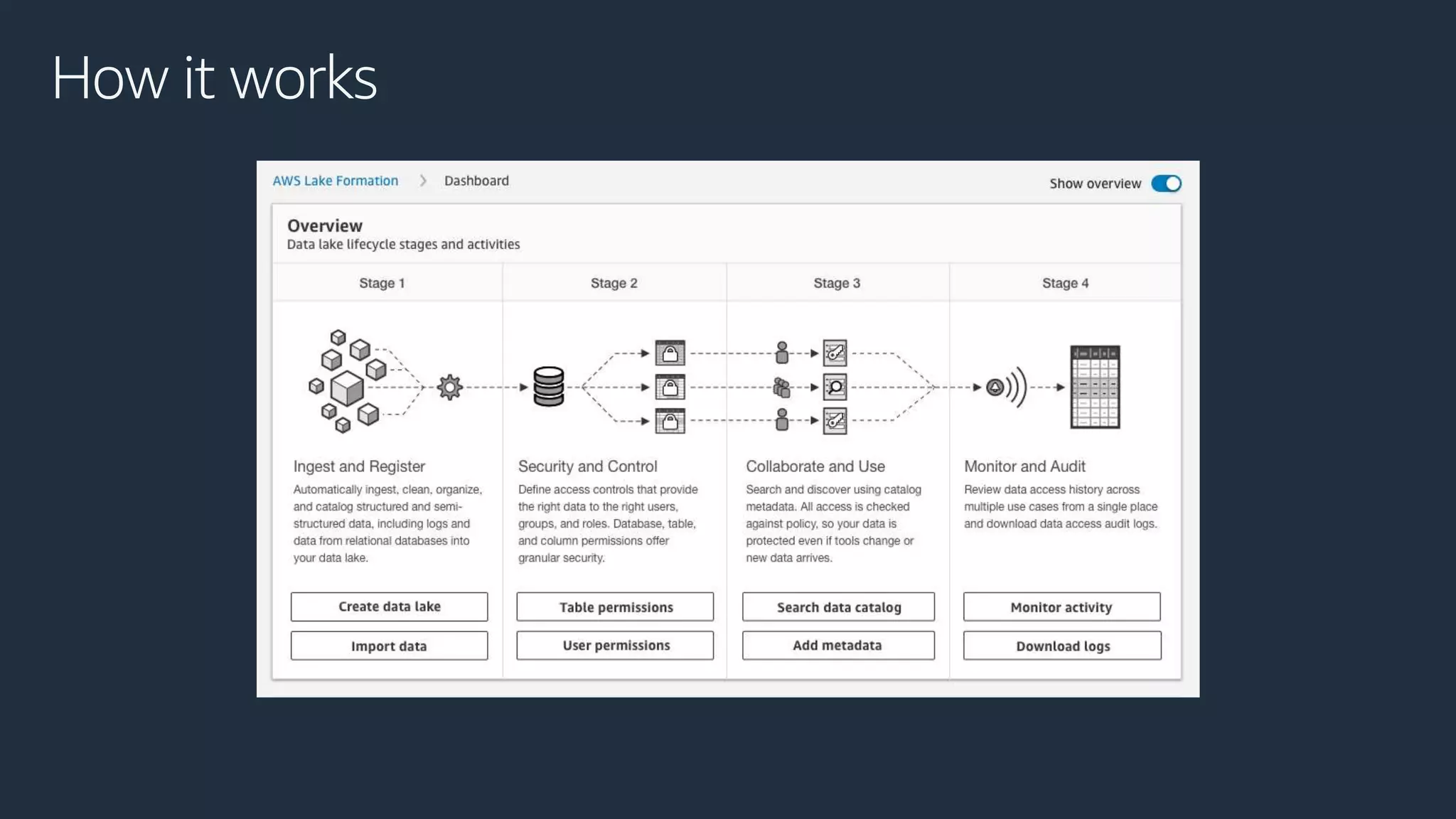
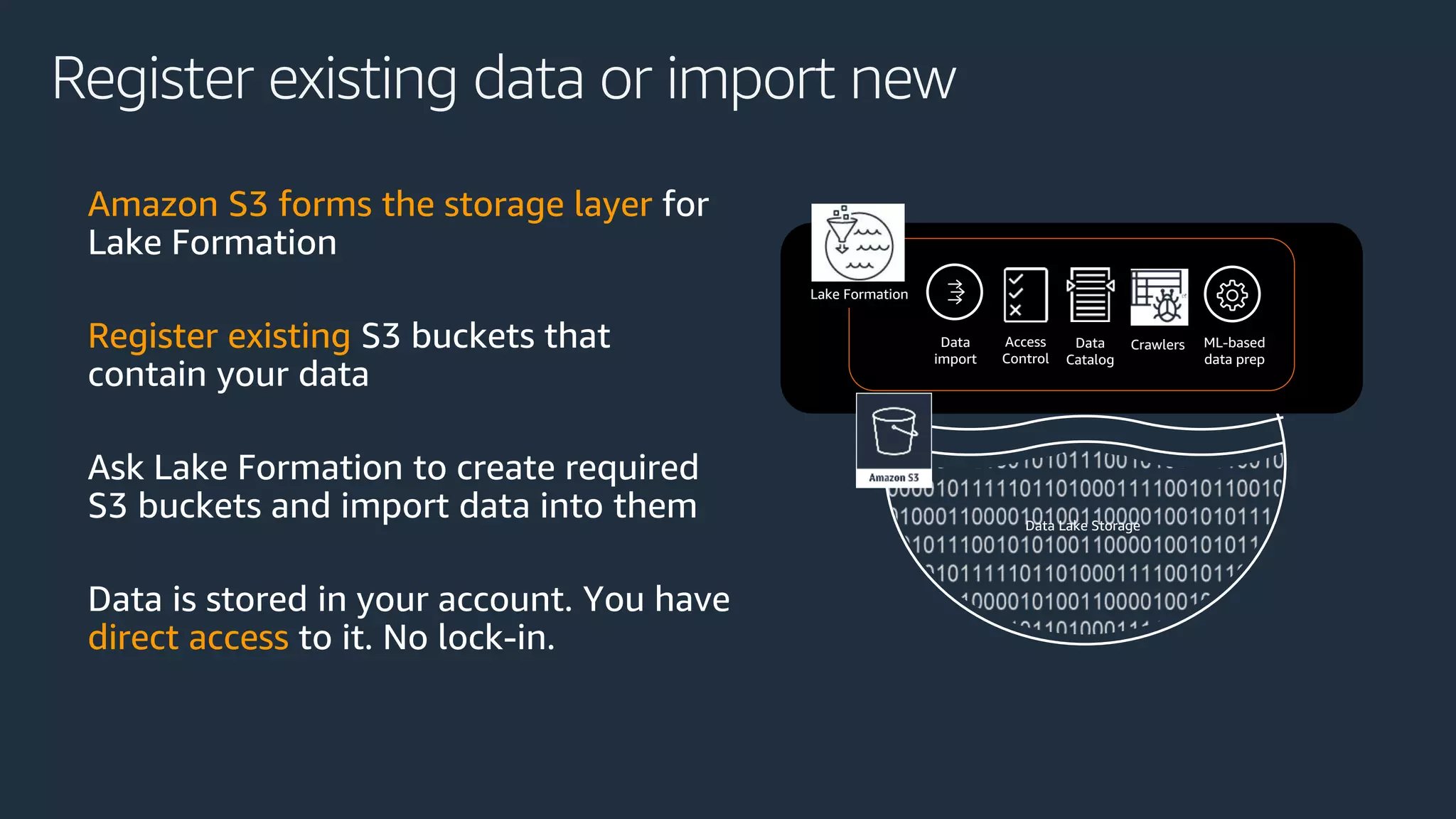
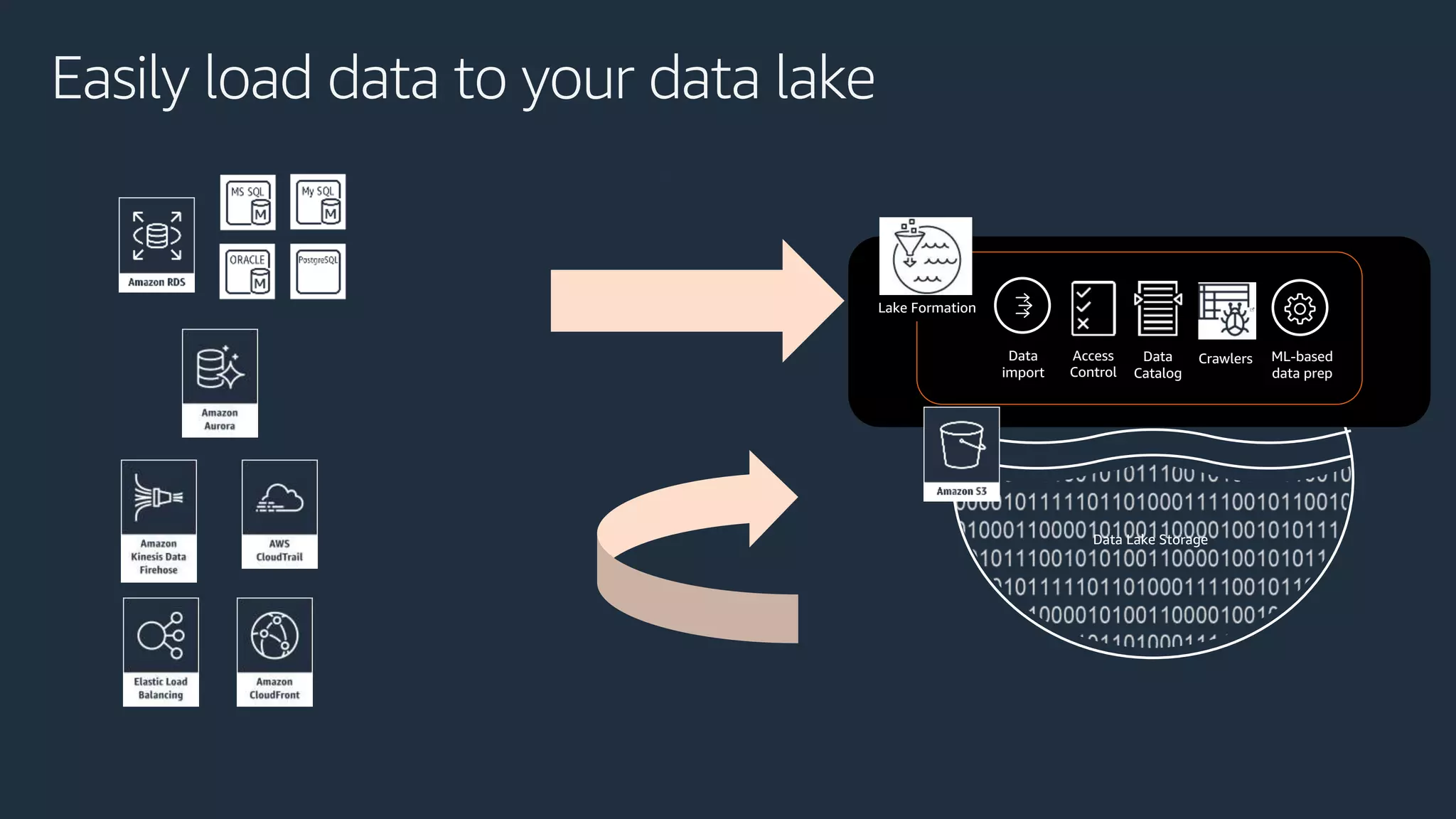

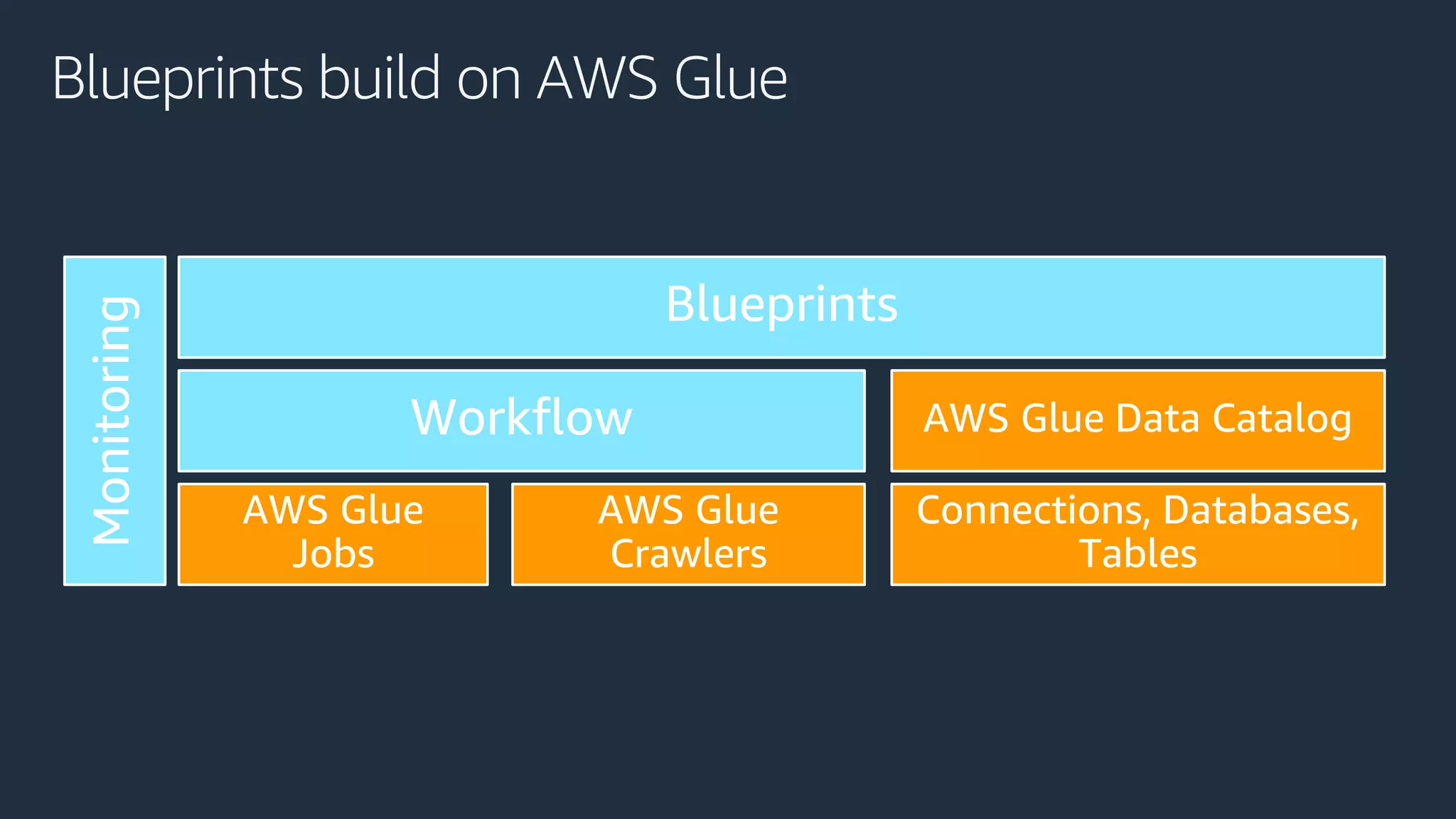























Cobus Bernard, a senior developer advocate at AWS, presents an overview of data lakes, explaining how they serve as centralized repositories for structured and unstructured data, provide scalability and accommodate diverse analytics tools. He outlines the steps to build a secure data lake using AWS services like Amazon S3 and Lake Formation, emphasizing the importance of data preparation and security policies. The document includes useful links and highlights the need for efficient data management processes.





























































