Download as PDF, PPTX





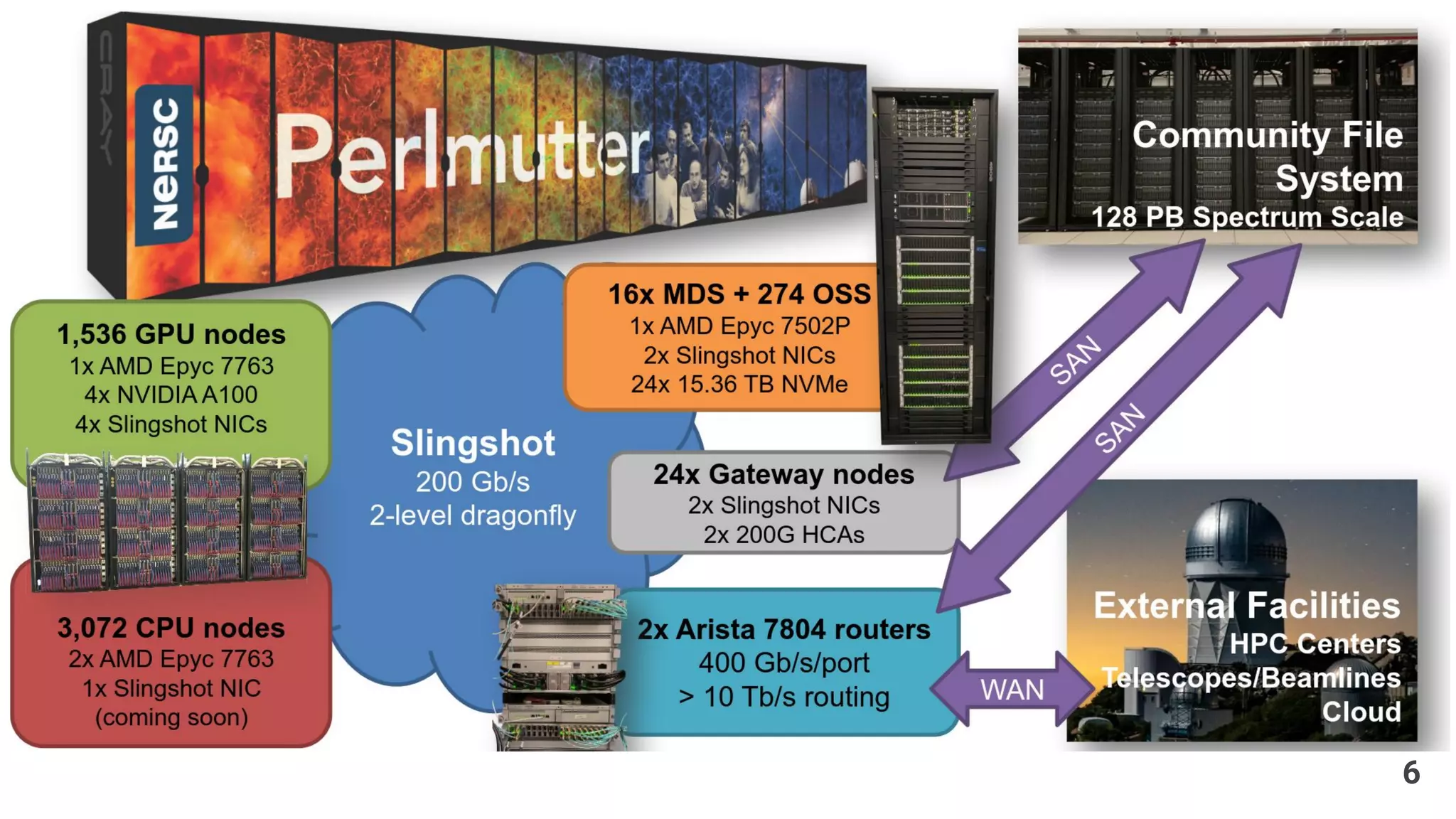










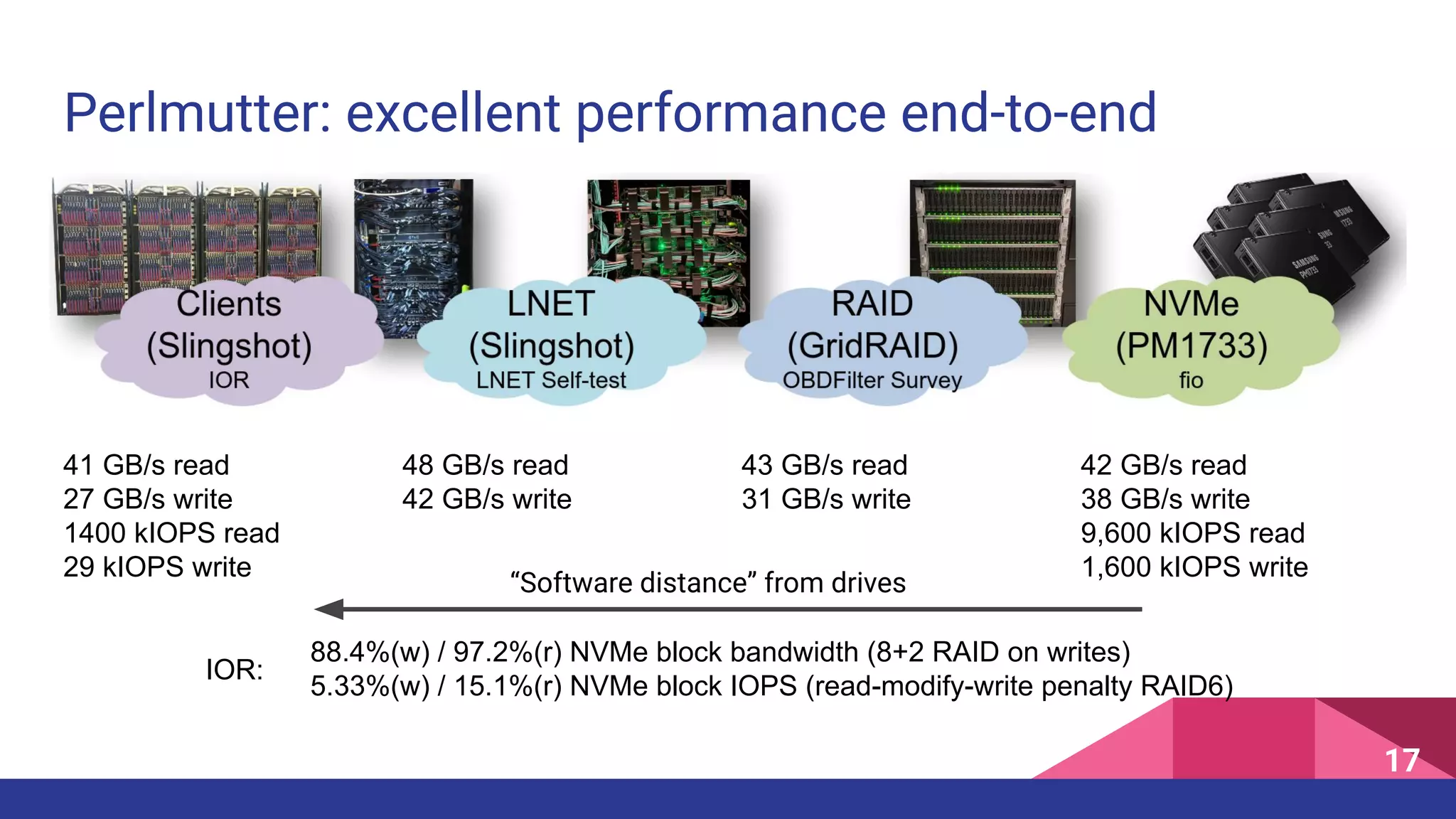

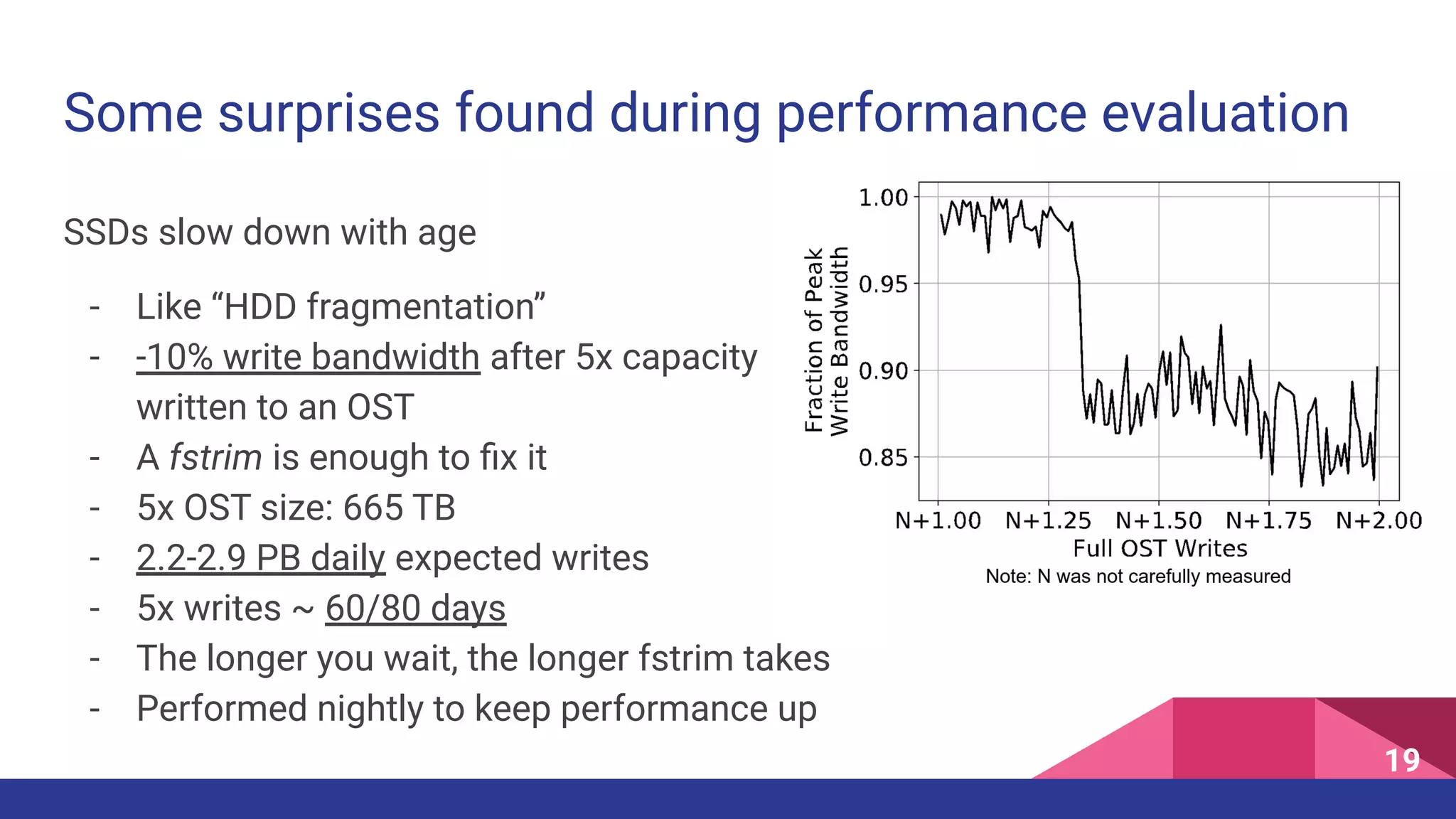






















The document discusses the architecture and engineering of a 35 petabyte distributed parallel file system used in high-performance computing (HPC) at the National Energy Research Scientific Computing Center. It highlights the evolution of the author's career in HPC, the significance of the Perlmutter supercomputer, and the technical intricacies of storage and I/O processes essential for scientific applications. The document addresses challenges, software, and performance metrics associated with the system's file management and data processing capabilities.



































































