This document compares Apache Spark and Apache Flink. Both are open-source platforms for distributed data processing. Spark was created in 2009 at UC Berkeley and donated to the Apache Foundation in 2013. It uses resilient distributed datasets (RDDs) and lazy evaluation. Flink was started in 2010 as a collaboration between universities in Germany and became an Apache project in 2014. It uses cyclic data flows and supports both batch and stream processing. While Spark is currently more mature with more components and community support, Flink claims to be faster for stream and batch processing. Overall, both platforms continue to evolve and improve.
Apache Spark vsApache Flink
Two most contemporary general purpose data processing platform.
AKASH SIHAGPh. No. : +91-7737111579
asihag70@gmail.com akash.sihag@infoobjects.com
2.
Introduction
Apache Spark isa fast and general
engine for large-scale data processing.
Apache Flink
Apache Flink is an open source
platform for distributed stream and
batch data processing.
Apache Spark
3.
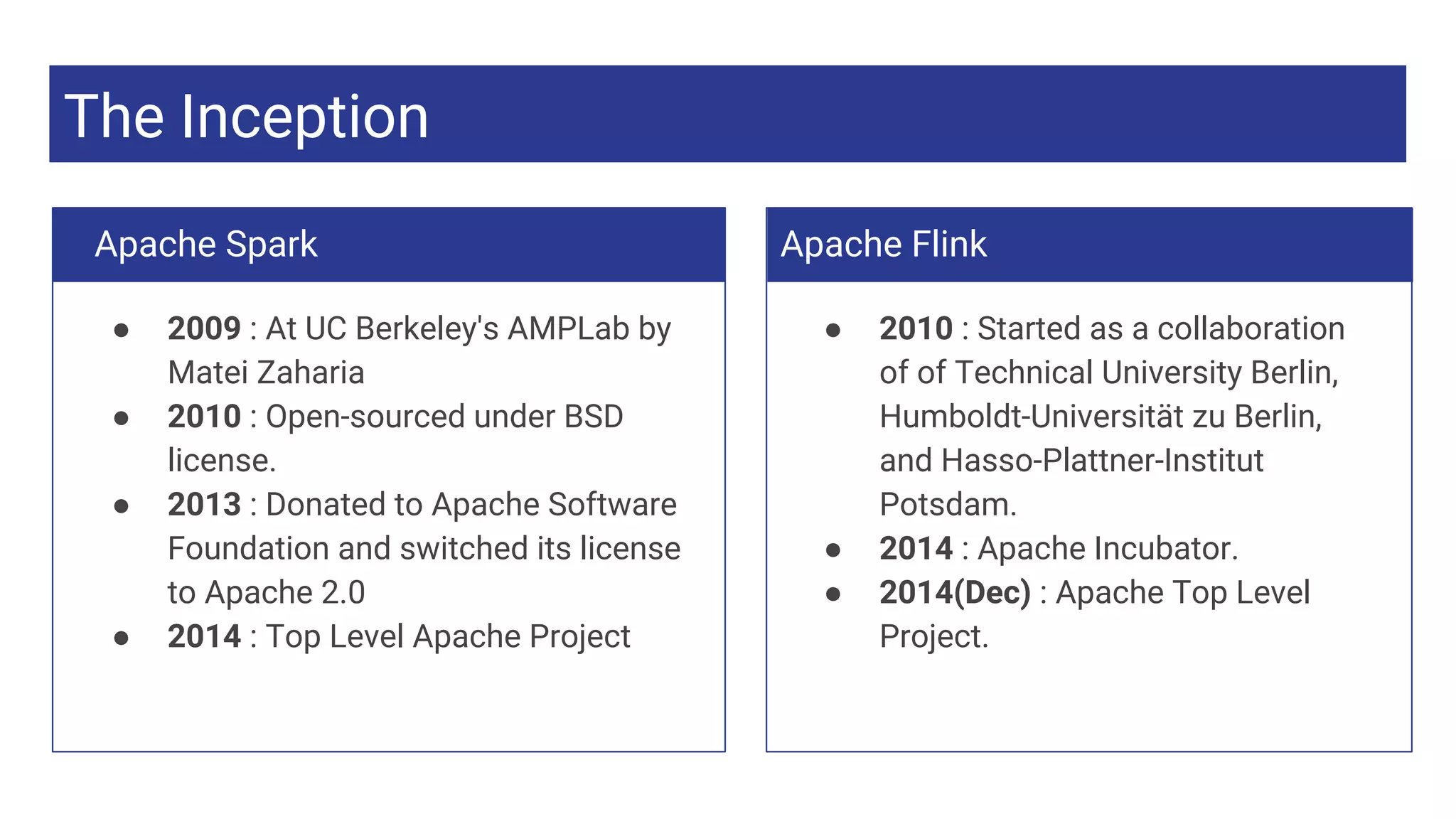
The Inception
● 2009: At UC Berkeley's AMPLab by
Matei Zaharia
● 2010 : Open-sourced under BSD
license.
● 2013 : Donated to Apache Software
Foundation and switched its license
to Apache 2.0
● 2014 : Top Level Apache Project
Apache Flink
● 2010 : Started as a collaboration
of of Technical University Berlin,
Humboldt-Universität zu Berlin,
and Hasso-Plattner-Institut
Potsdam.
● 2014 : Apache Incubator.
● 2014(Dec) : Apache Top Level
Project.
Apache Spark
4.
Overview Spark
Apache link
Components:
●Spark SQL : For SQL and unstructured data processing.
● Spark Streaming: For processing live streaming data.
● MLib : Machine Learning Algorithm.
● GraphX : Graph based processing.
● Spark Core : Its the base processing engine in Spark that works on the concept of RDD and
all API’s resides on top of it.
Deploy:
● Standalone : Included with Spark.
● Apache Mesos
● Apache YARN : Hadoop 2 resource manager.
Spark Core
5.
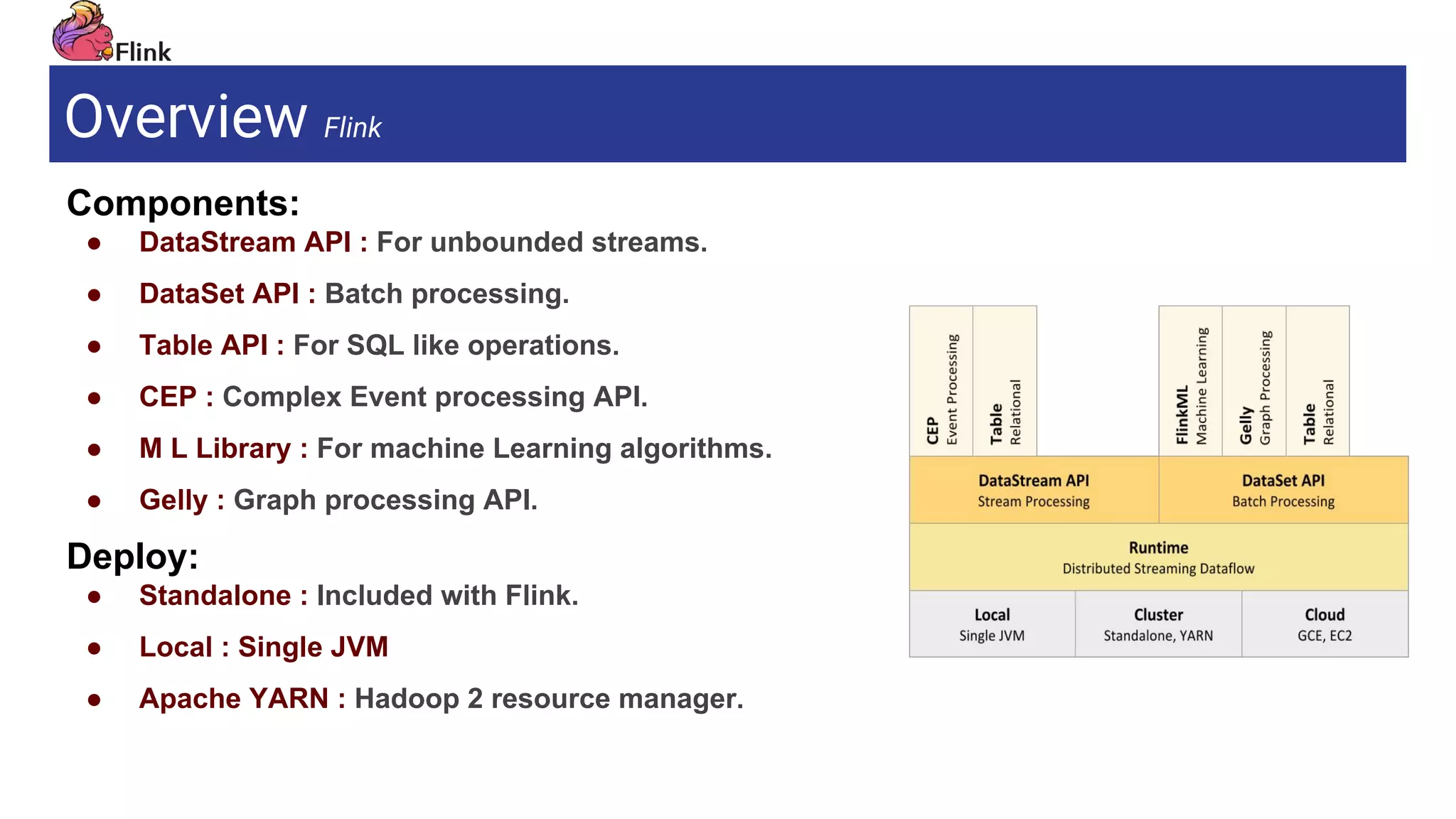
Overview Flink
Apache link
Components:
●DataStream API : For unbounded streams.
● DataSet API : Batch processing.
● Table API : For SQL like operations.
● CEP : Complex Event processing API.
● M L Library : For machine Learning algorithms.
● Gelly : Graph processing API.
Deploy:
● Standalone : Included with Flink.
● Local : Single JVM
● Apache YARN : Hadoop 2 resource manager.
Computing Paradigm
● Workon the abstraction of RDD i.e.
Resilient distributed datasets.
● Supports in-memory computation.
● Lazy Evaluation (Transformation-
action).
● DAG is generated for every Spark
Job.
● Streams are processed as chunks
of batches.
Apache Flink
● Works on the abstraction of Cyclic
Data Flows.
● Supports in-memory computation.
● Lazy Evaluation (Iterative-
Transformation).
● Job Graph are generated.
● Batches are processed as
streams.
Apache Spark
8.
Similarities
Apache link● Bothare data processing platforms.
● Similar kind of collection APIs.
● Leverages frameworks like AKKA, YARN.
● Since APIs are similar, code porting takes less efforts.
● Both provides stream and batch processing.
● Fault-Tolerant.
● APIs in JAVA and Scala.
9.
Apache Spark ApacheFlink
● Near real time stream processing.
● Batch and streaming transformations are
possible.
● Limited window based operations.
● Catalyst Optimizer for SQL operations.
● Stateful Operation till v1.5 are not so
efficient.
Note: In Spark 1.6 stateful operations are
drastically improved.
● Structured data source support is matured.
Ex: HiveContext can be created directly via
Spark SQL.
● More committer and third party APIs.
● Spark uses JAVA Heap memory allocation
for cached data.
Note: From Spark 1.5 spark started implementing
off-heap memory allocation (Tungsten).
● ML algos are implemented via DAG
● Real time stream processing.
● Batch with streams operations are not
possible and so operating on historic data
with live streaming is not so great.
● Various flavours of window based
operations based on triggers, record counts
and events.
● Optimizer for streams as well as batches.
● Efficient stateful stream operations.
● Structured data support is not so matured
and still only have Hadoop InputFormat
API.
● Relatively new ecosystem.
● Flink implemented custom memory
allocation from its inception.
● ML algos are implemented in native style.
VS
10.
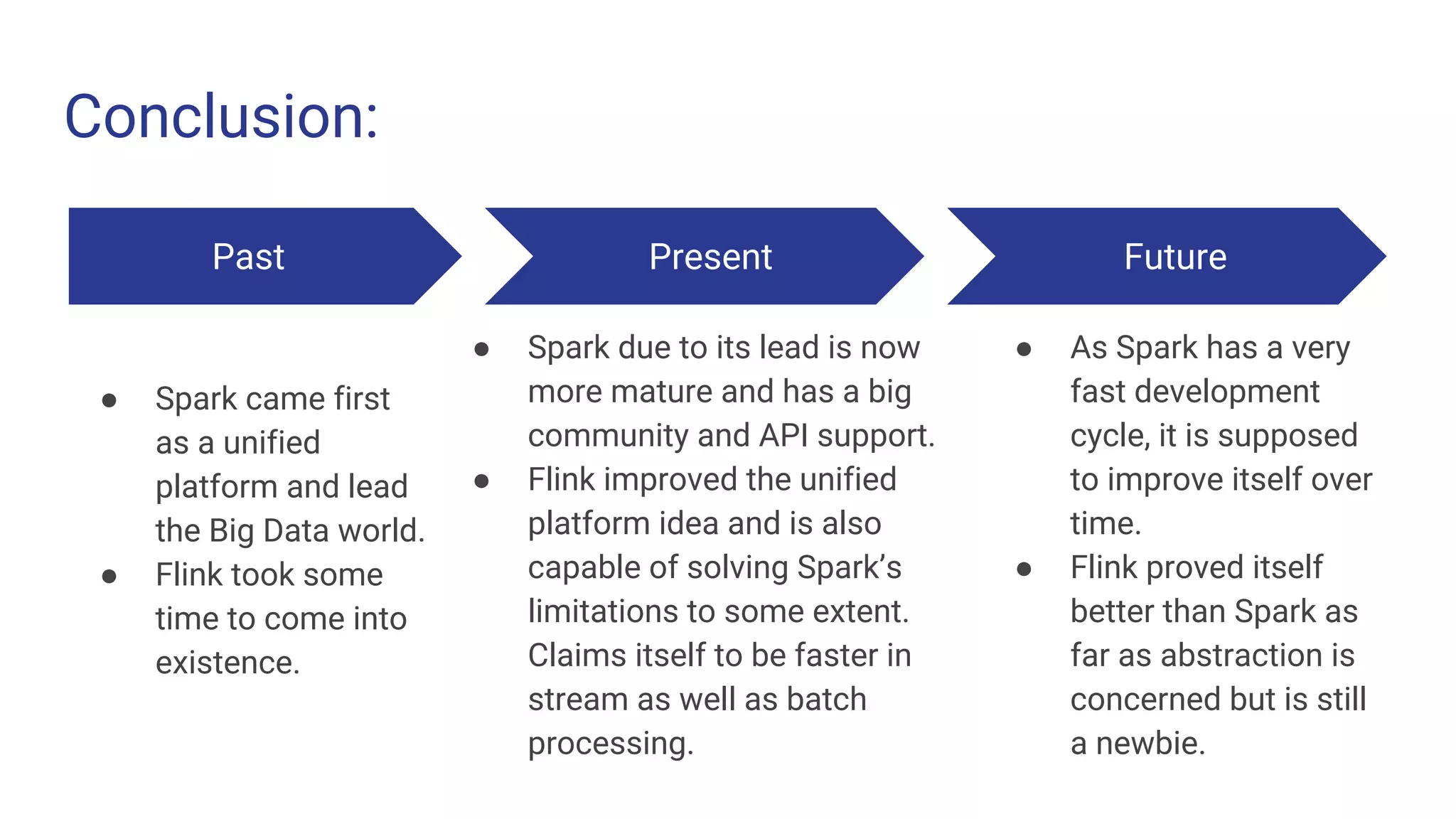
Conclusion:
Past
● Spark camefirst
as a unified
platform and lead
the Big Data world.
● Flink took some
time to come into
existence.
Present
● Spark due to its lead is now
more mature and has a big
community and API support.
● Flink improved the unified
platform idea and is also
capable of solving Spark’s
limitations to some extent.
Claims itself to be faster in
stream as well as batch
processing.
Future
● As Spark has a very
fast development
cycle, it is supposed
to improve itself over
time.
● Flink proved itself
better than Spark as
far as abstraction is
concerned but is still
a newbie.






















![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)


















































































