




















![Prepare and Submit job
public class WordCountJob {
public static void main(String[] args) throws Exception{
JobConf conf = new JobConf(WordCount.class);
// specify input and output dirs
FileInputFormat.addInputPath(conf, new Path("input"));
FileOutputFormat.addOutputPath(conf, new Path("output"));
// specify output types
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
//InputFormat and OutputFormat
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
conf.setMapperClass(WordCountMapper.class); // specify a mapper
conf.setReducerClass(WordCountReducer.class); // specify a reducer
conf.setCombinerClass(WordCountReducer.class);
conf.setNumberOfReducer(2); //Number of reducer
JobClient.runJob(conf); // Submit the job to Job Tracker
}}](https://image.slidesharecdn.com/apachehadoophdfsandmapreduceoverview-140706125521-phpapp01/75/Apache-hadoop-hdfs-and-map-reduce-Overview-25-2048.jpg)
























![Prepare and Submit job
public class WordCountJob {
public static void main(String[] args) throws Exception{
JobConf conf = new JobConf(WordCount.class);
// specify input and output dirs
FileInputFormat.addInputPath(conf, new Path("input"));
FileOutputFormat.addOutputPath(conf, new Path("output"));
// specify output types
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
//InputFormat and OutputFormat
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
conf.setMapperClass(WordCountMapper.class); // specify a mapper
conf.setReducerClass(WordCountReducer.class); // specify a reducer
conf.setCombinerClass(WordCountReducer.class);
conf.setNumberOfReducer(2); //Number of reducer
JobClient.runJob(conf); // Submit the job to Job Tracker
}}](https://crownmelresort.com/image.slidesharecdn.com/apachehadoophdfsandmapreduceoverview-140706125521-phpapp01/75/Apache-hadoop-hdfs-and-map-reduce-Overview-25-2048.jpg)




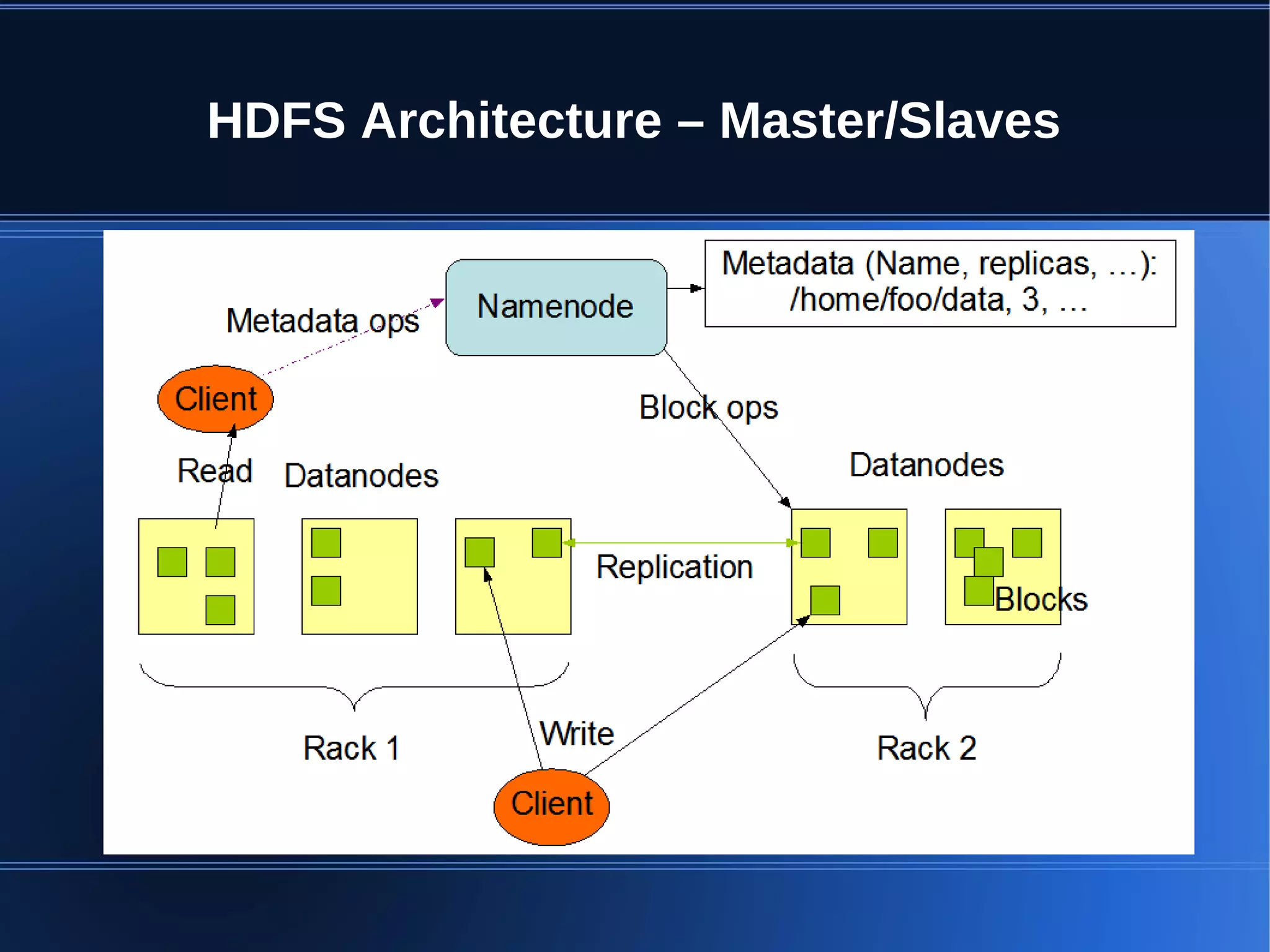
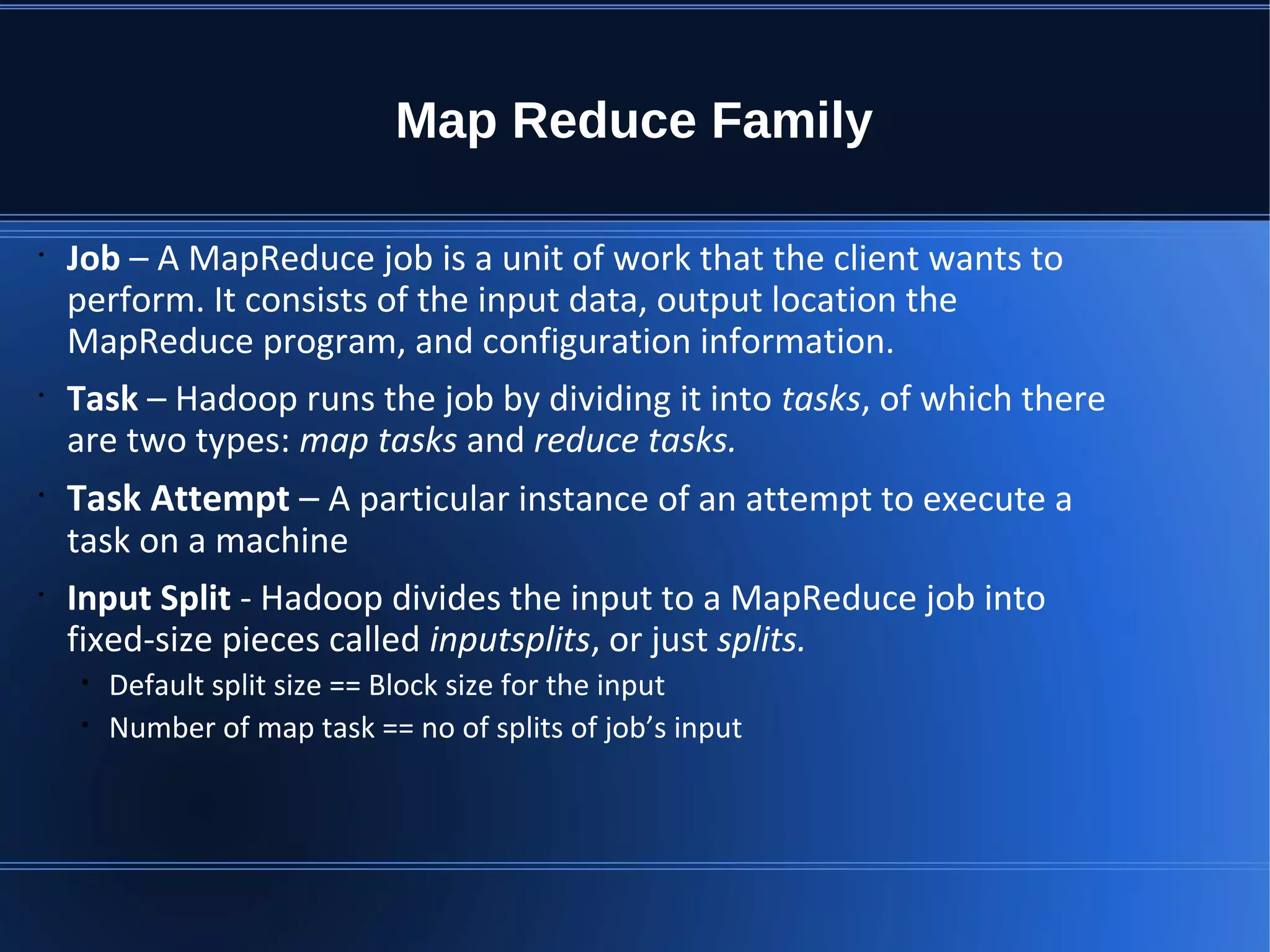
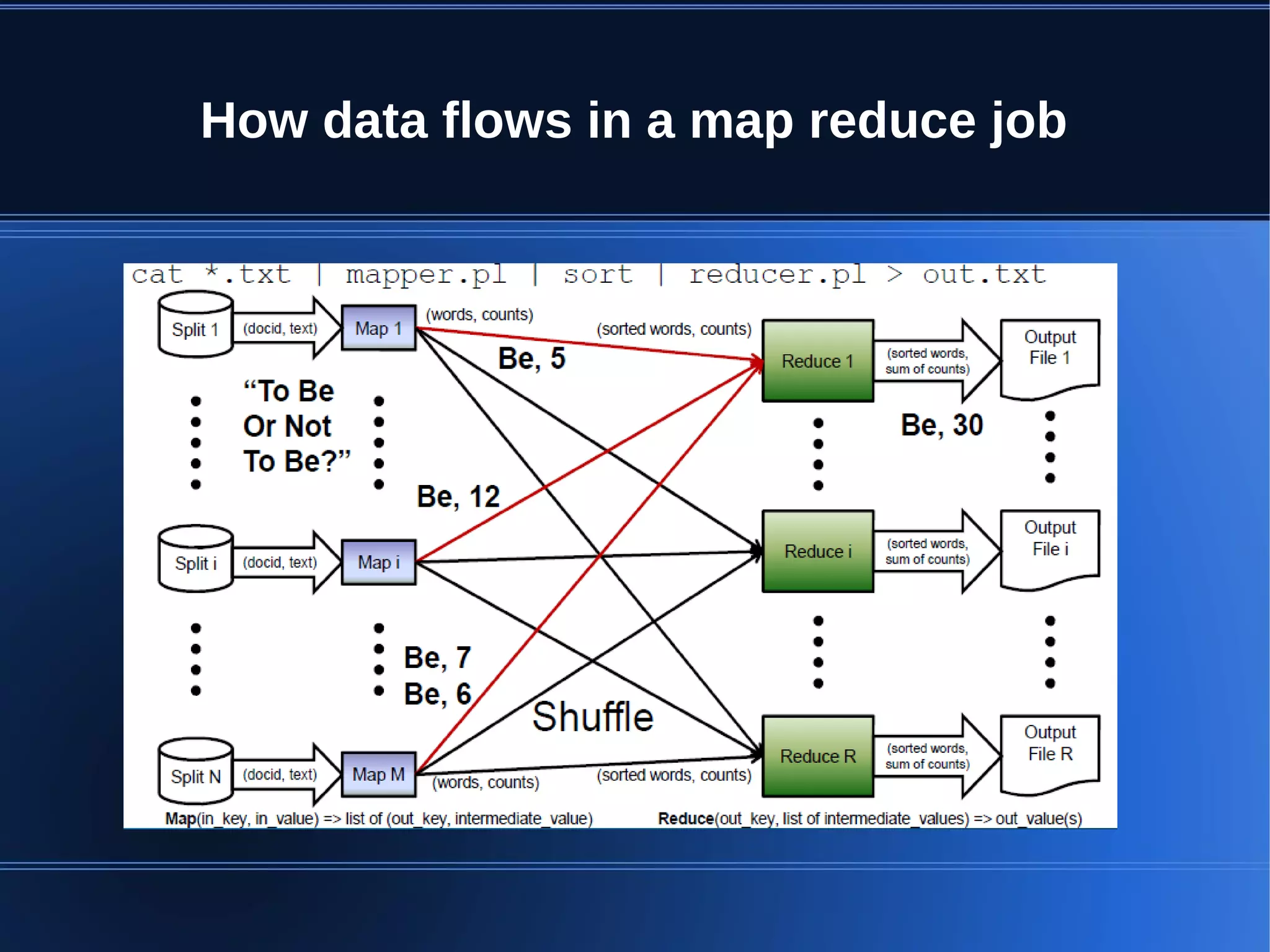
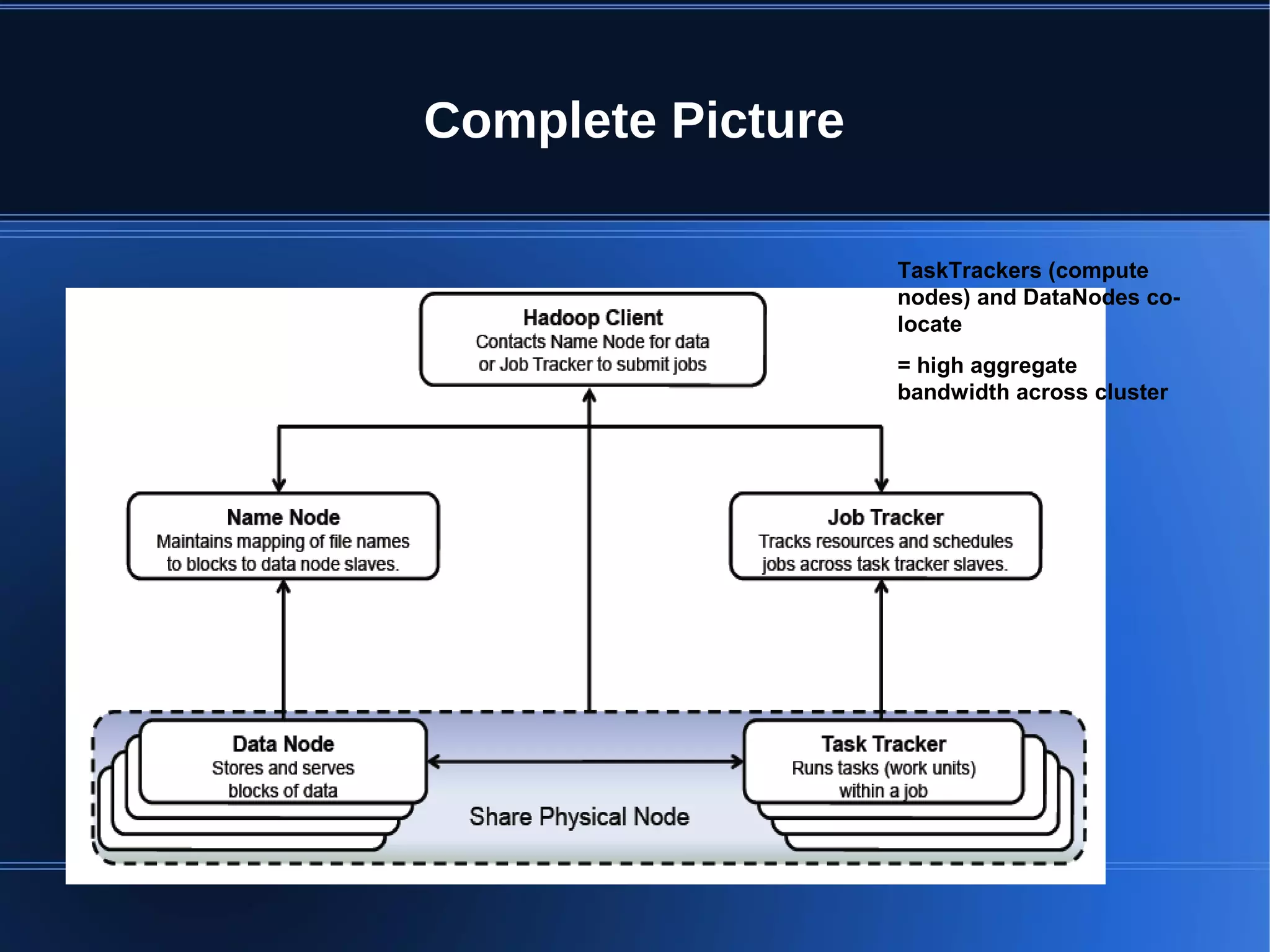
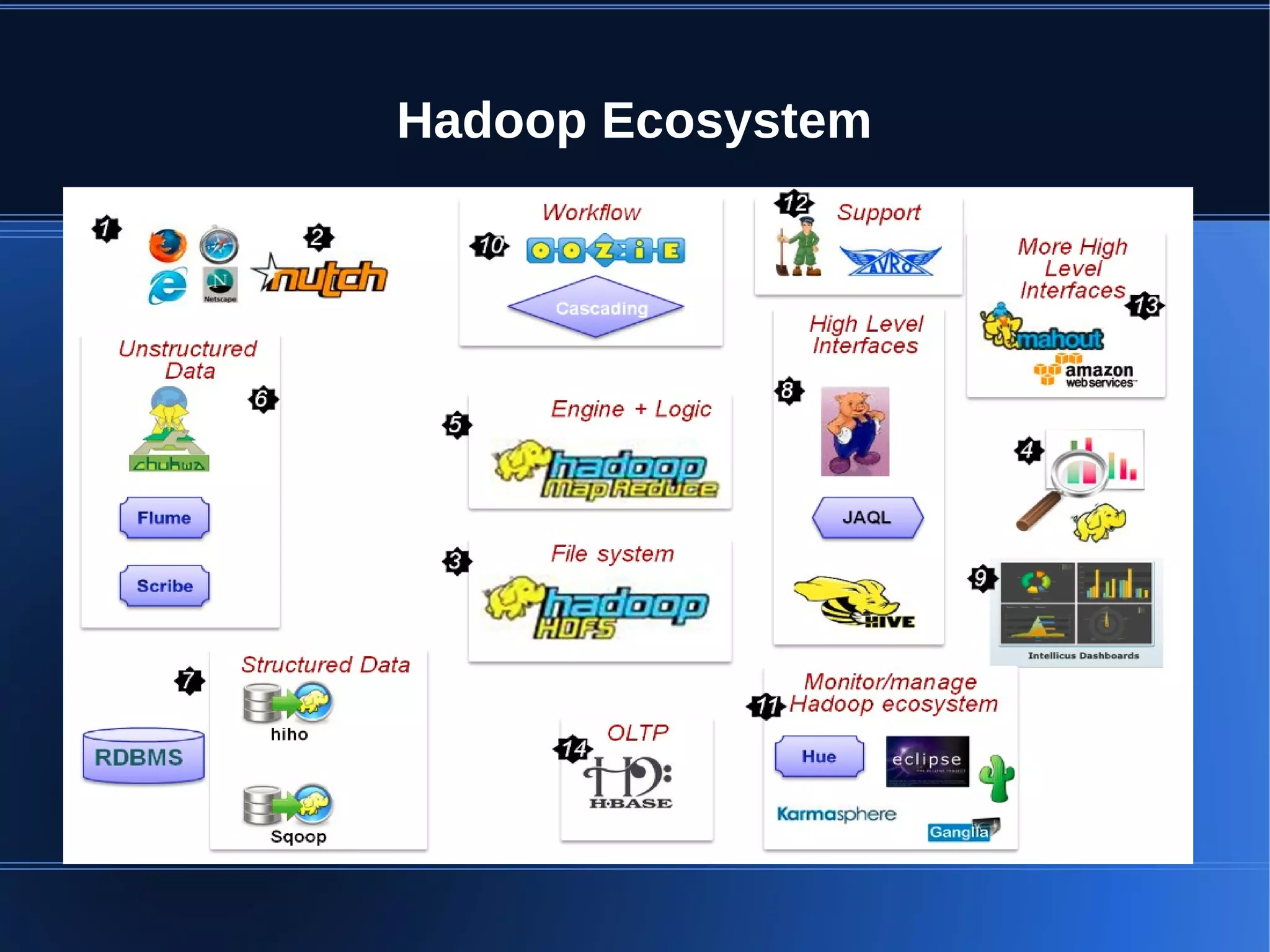
This document provides an overview of Apache Hadoop, HDFS, and MapReduce. It describes how Hadoop uses a distributed file system (HDFS) to store large amounts of data across commodity hardware. It also explains how MapReduce allows distributed processing of that data by allocating map and reduce tasks across nodes. Key components discussed include the HDFS architecture with NameNodes and DataNodes, data replication for fault tolerance, and how the MapReduce engine works with a JobTracker and TaskTrackers to parallelize jobs.

































































