Download as PDF, PPTX


























![Recurrent Neural Nets and
LSTMs
Now we’ll look at a method or two for time-series data.
• Method needs to learn patterns present in the sequence
• Sequences can have patterns of unknown length
• Recurrent neural networks (RNNs)[1][2] let you address
sequences of data](https://image.slidesharecdn.com/introtoanomalydetection-170421012904/75/An-Introduction-to-Anomaly-Detection-36-2048.jpg)



















































![Recurrent Neural Nets and
LSTMs
Now we’ll look at a method or two for time-series data.
• Method needs to learn patterns present in the sequence
• Sequences can have patterns of unknown length
• Recurrent neural networks (RNNs)[1][2] let you address
sequences of data](https://crownmelresort.com/image.slidesharecdn.com/introtoanomalydetection-170421012904/75/An-Introduction-to-Anomaly-Detection-36-2048.jpg)


















The document provides a comprehensive overview of anomaly detection, explaining its definition, types of anomalies, and various detection methods such as supervised, semi-supervised, and unsupervised techniques. It highlights the importance of understanding data context, types of input data, and relationships between instances for effective anomaly detection in applications like credit card fraud and medical data. Additionally, it discusses the use of neural networks, statistical methods, and graph-based techniques for identifying different kinds of anomalies.
Introduction by Ken Graham; overview of anomaly detection definitions, importance, methods, and applications.
Defining anomalies with various applications including fraud and intrusion detection; challenges in defining normal regions and handling imbalanced data.
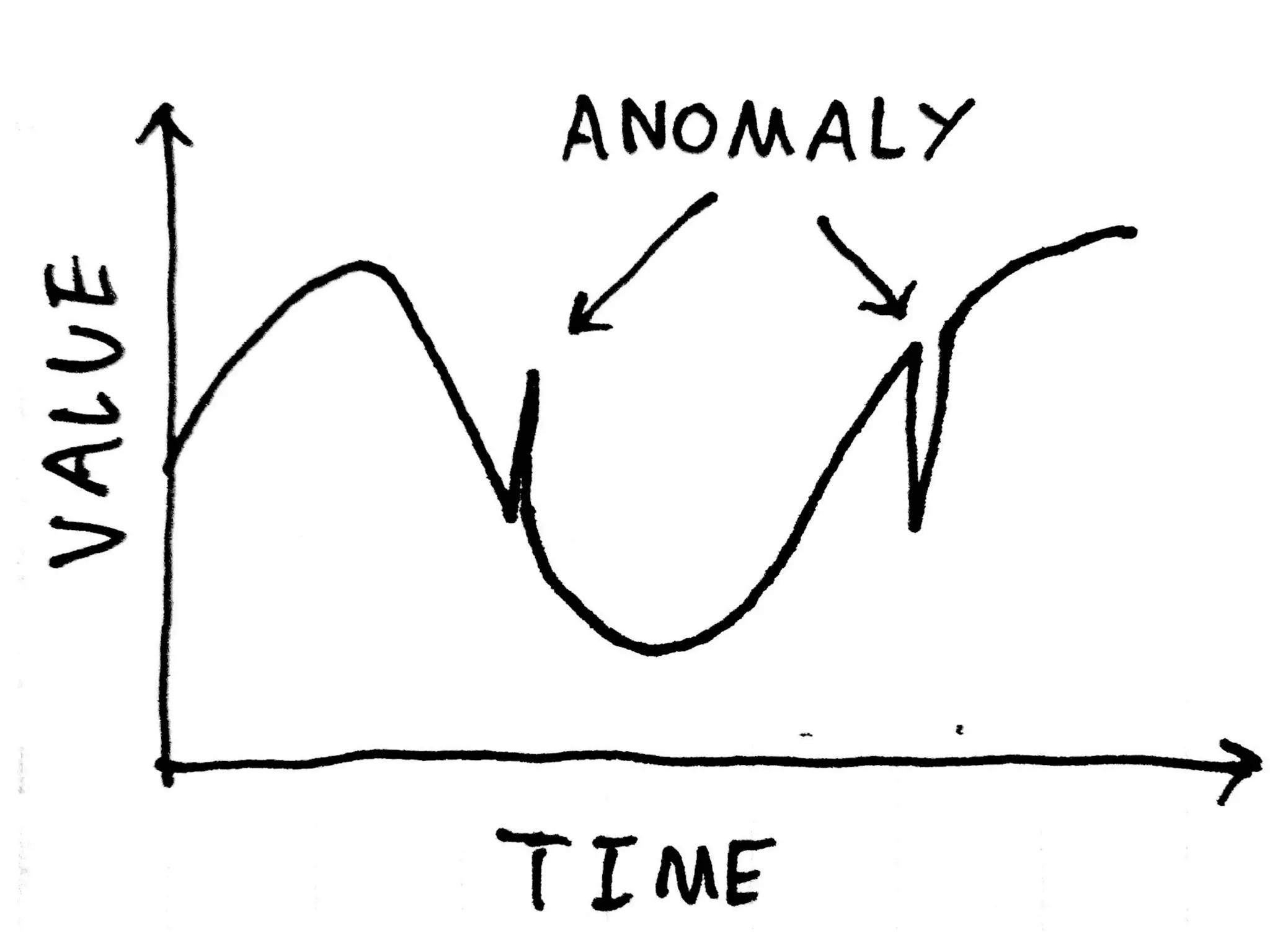
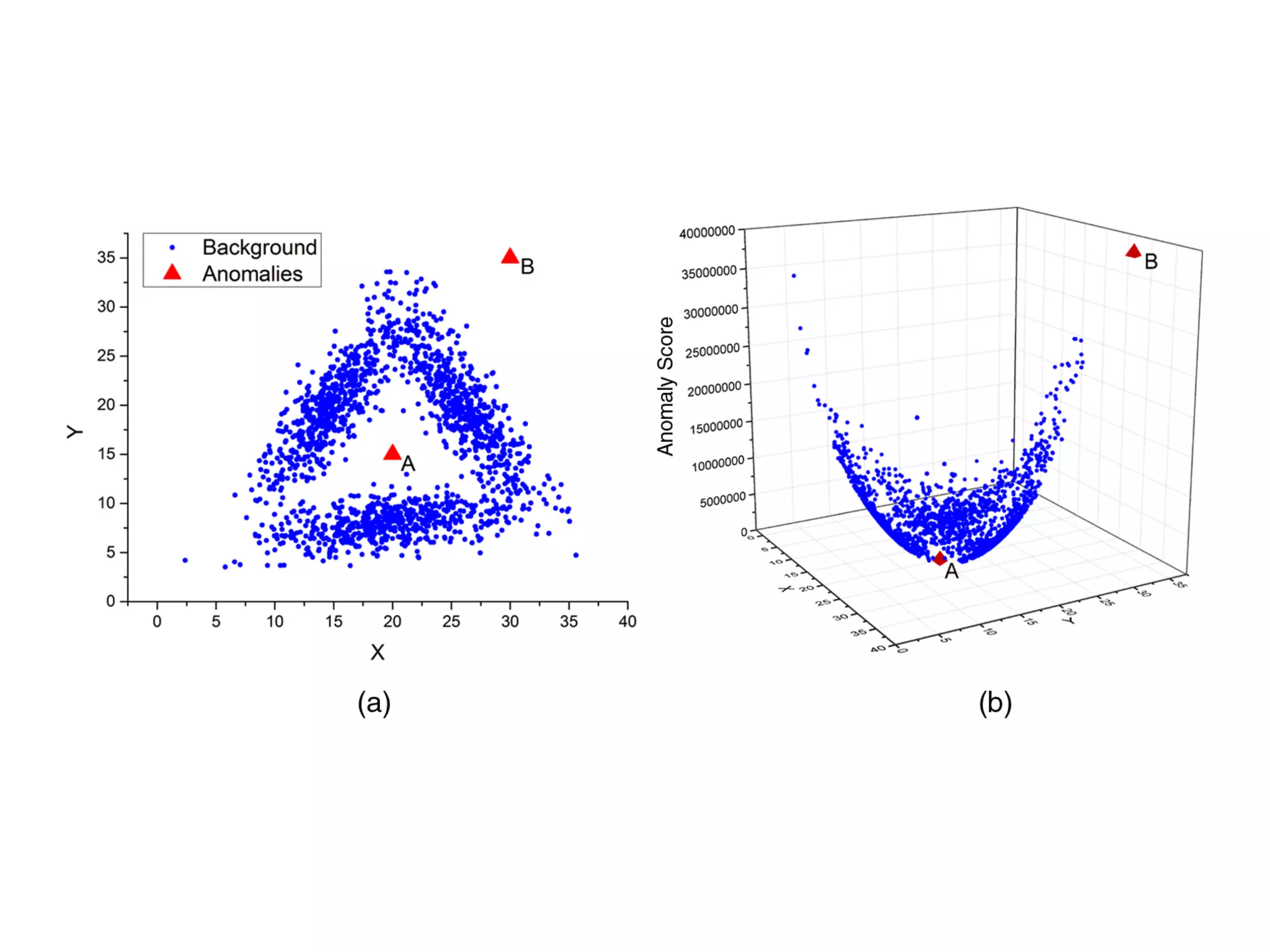
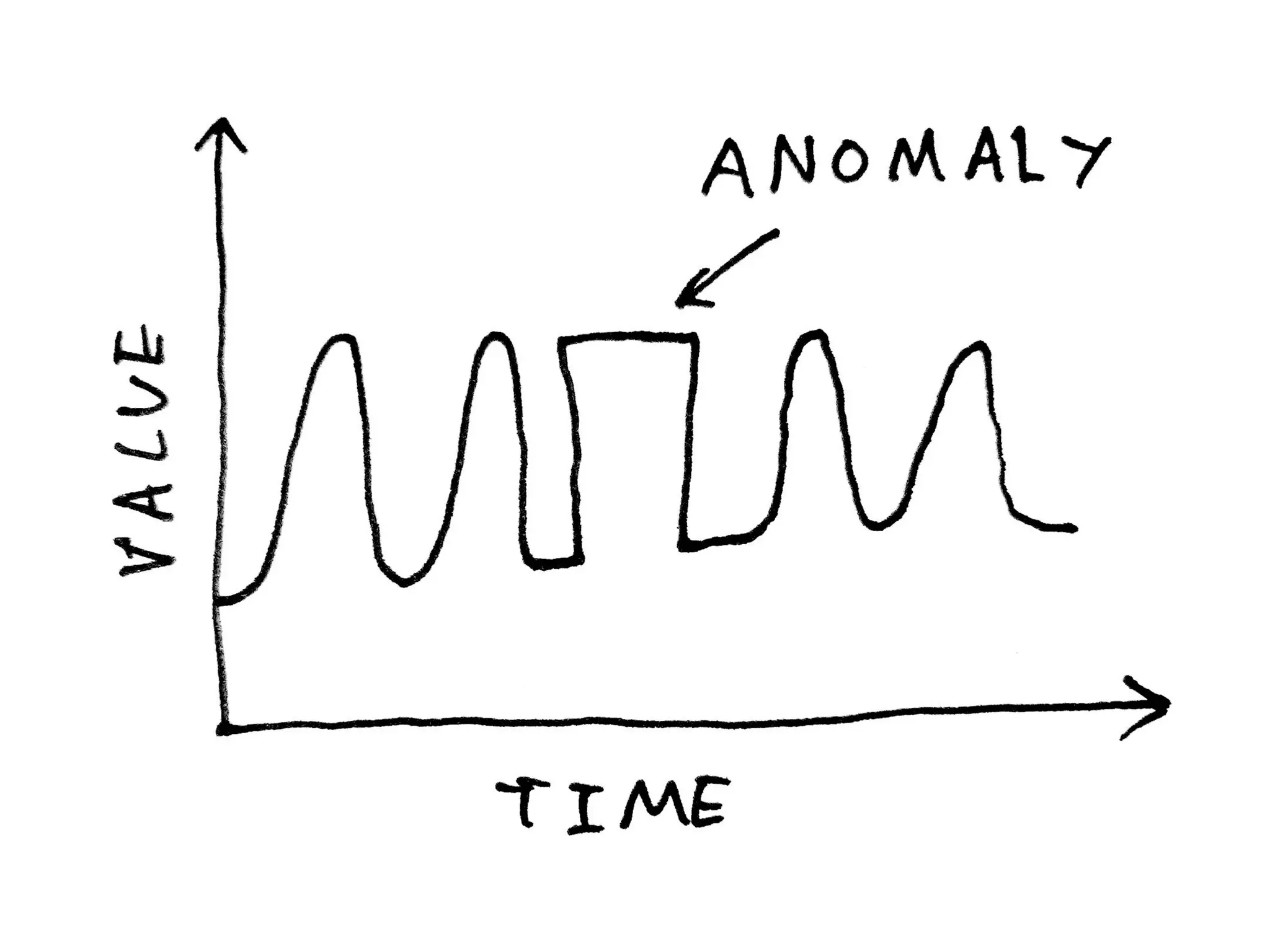
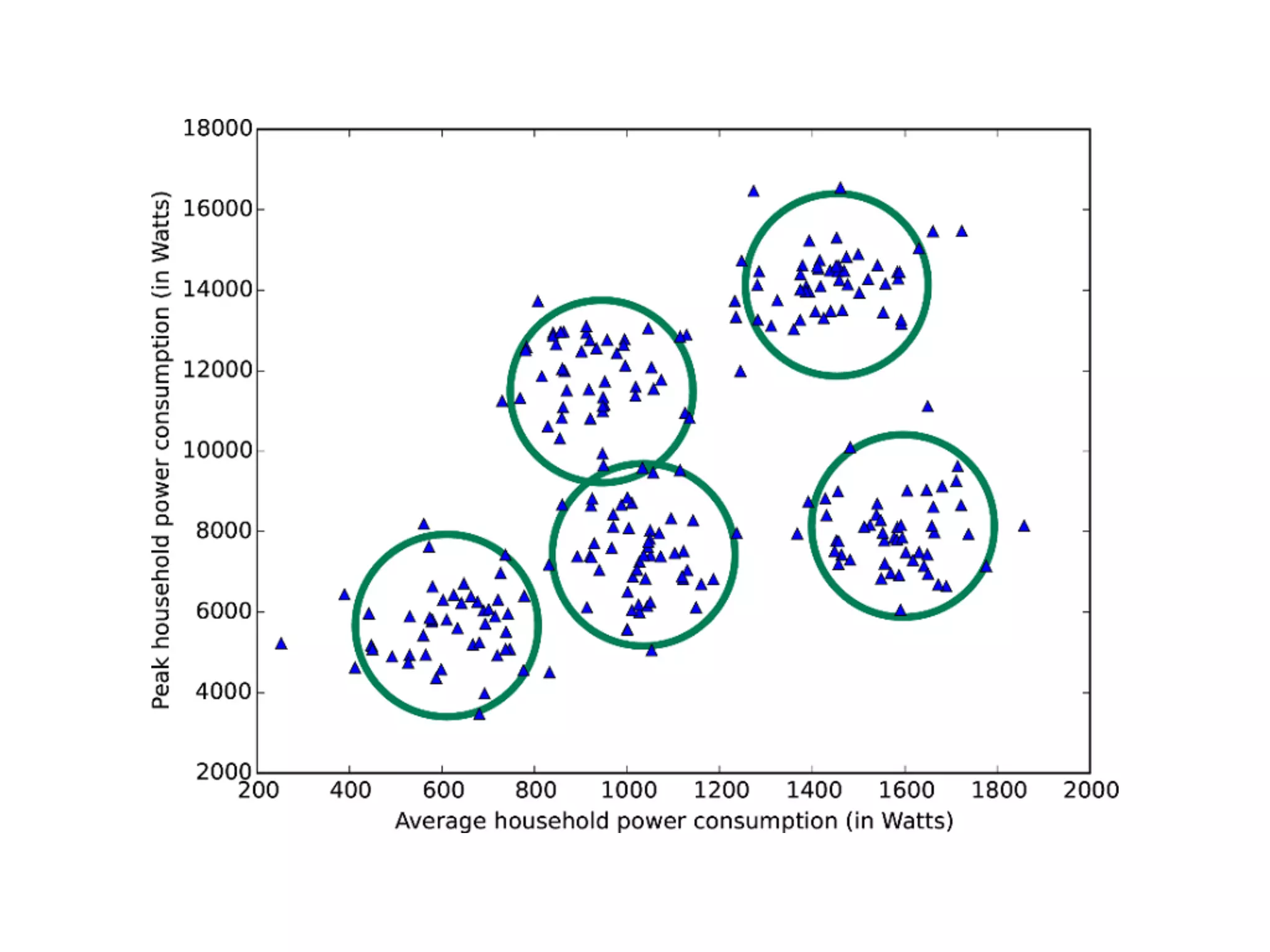
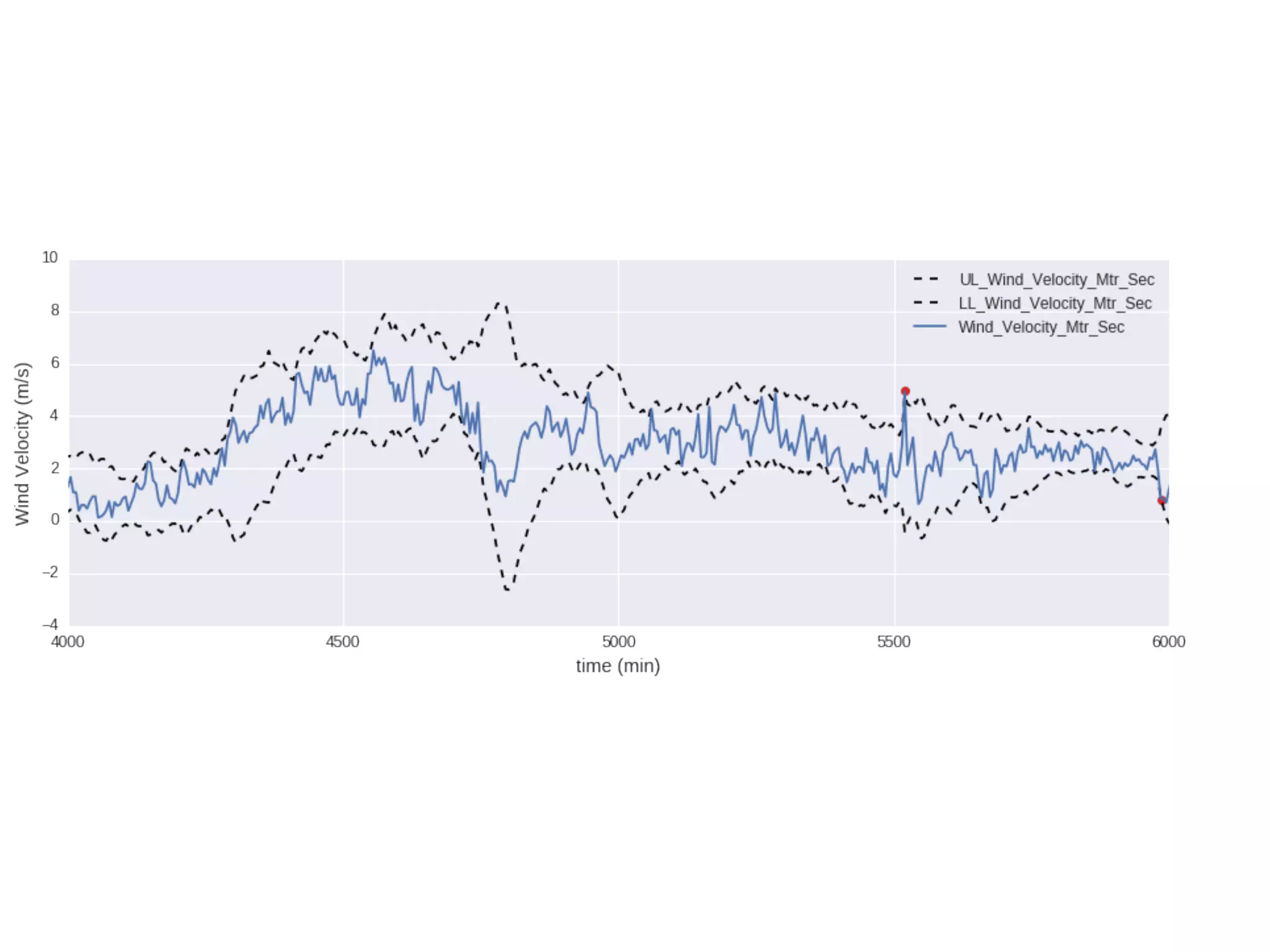
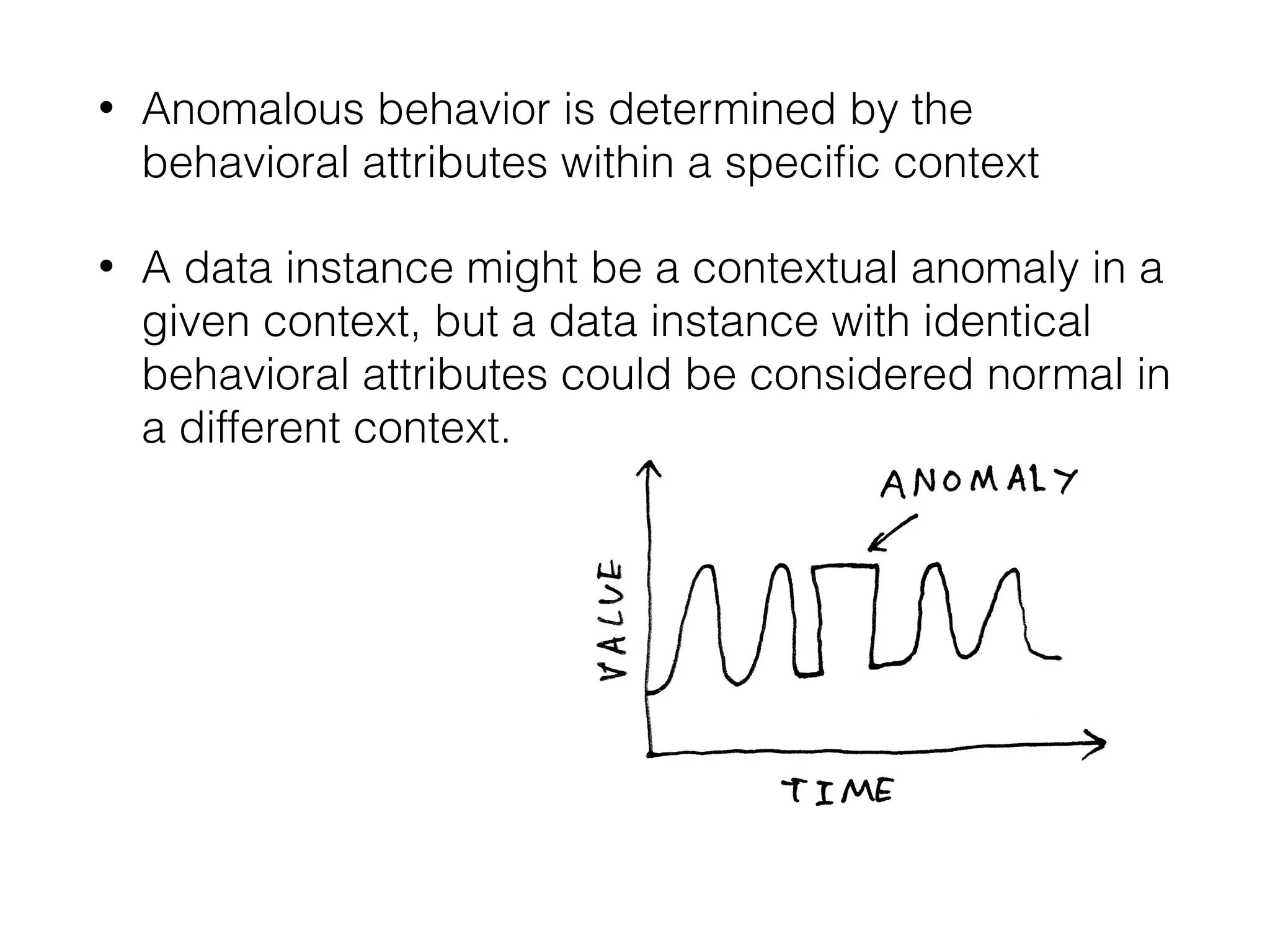
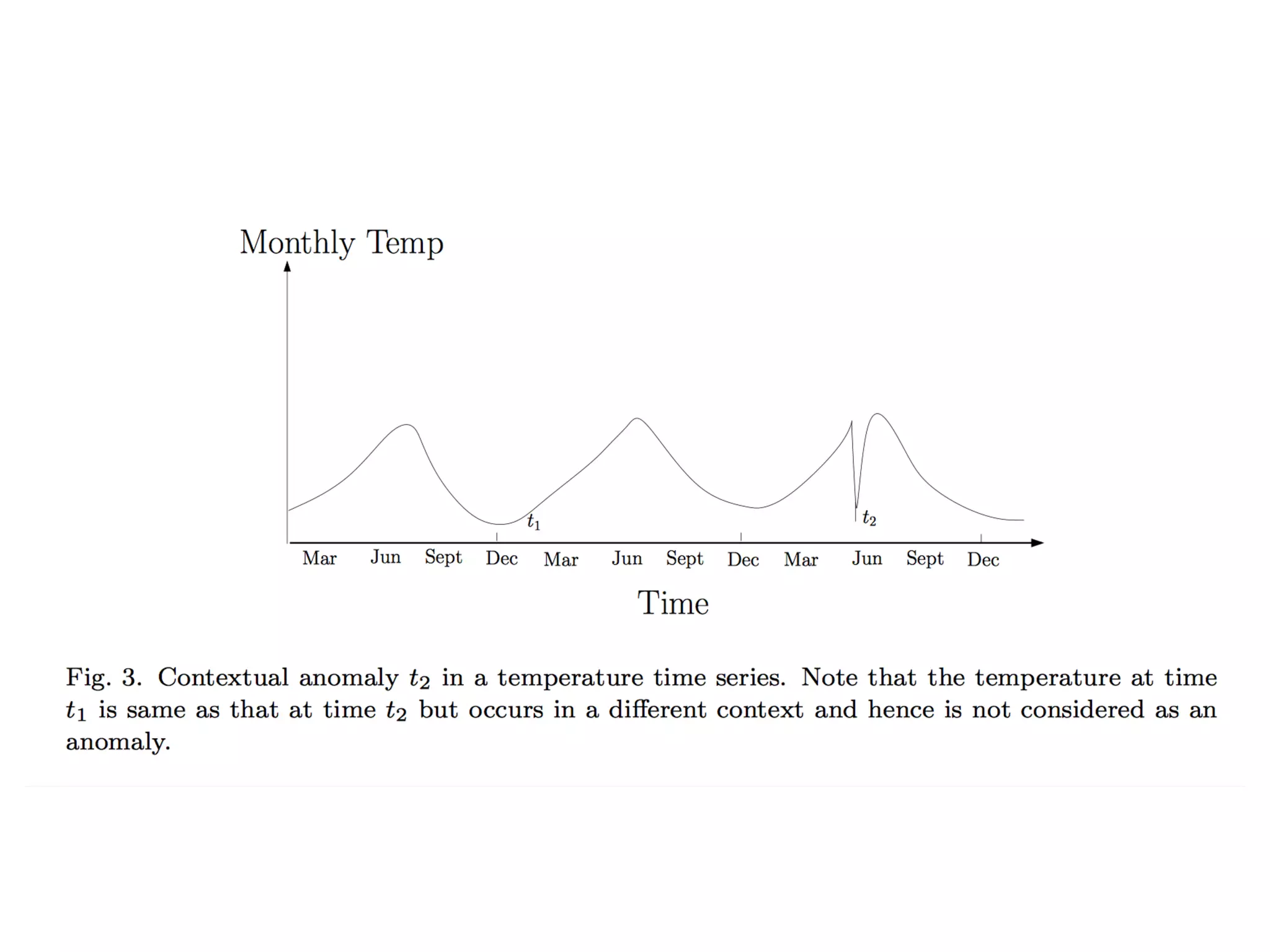
Discussion on types of data (binary, categorical, continuous) and the three major anomaly types: point, contextual, and collective.
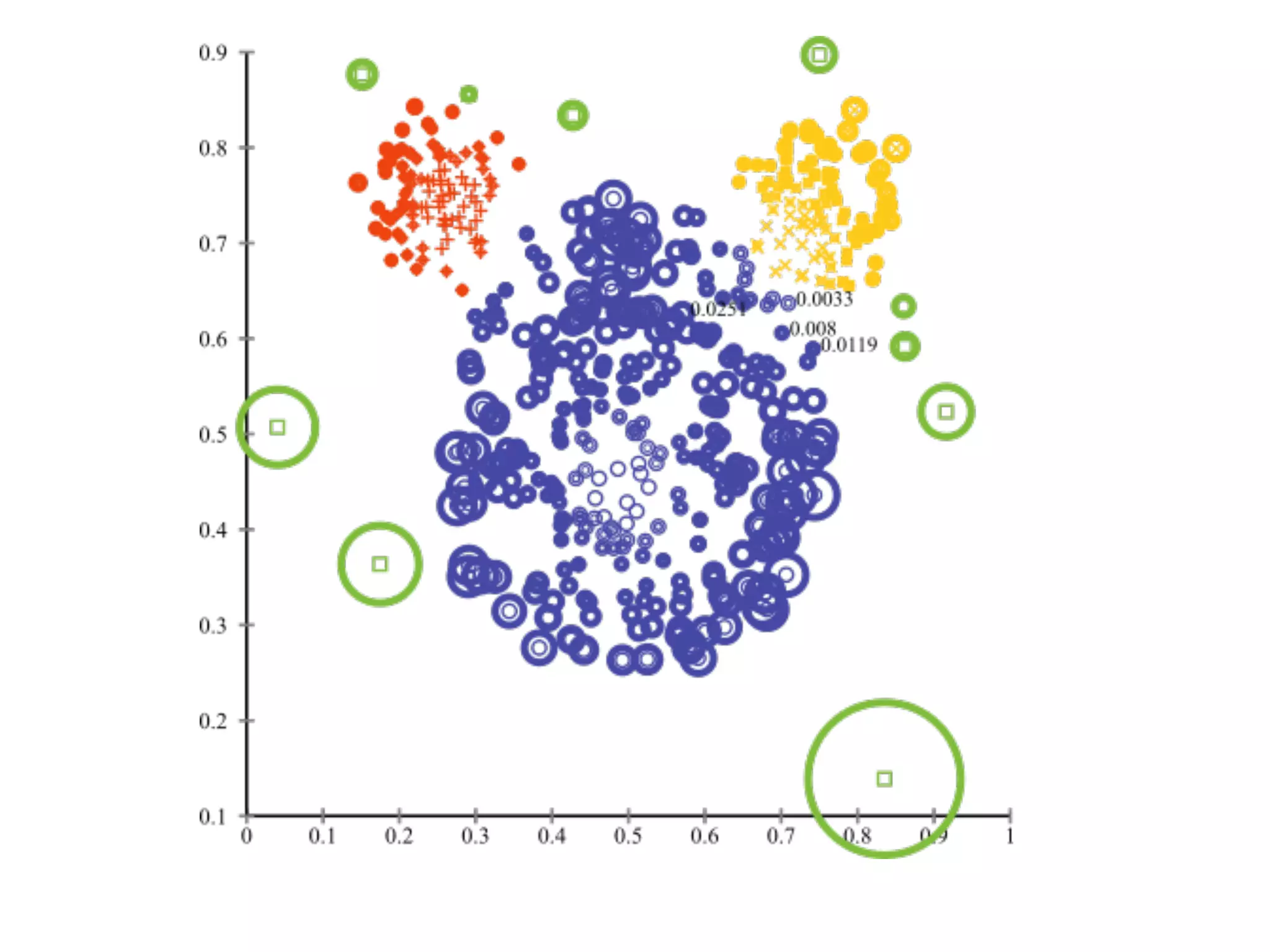
Three types of anomaly detection methods: supervised, semi-supervised, unsupervised, along with applications in credit card, cellphone fraud, and healthcare.
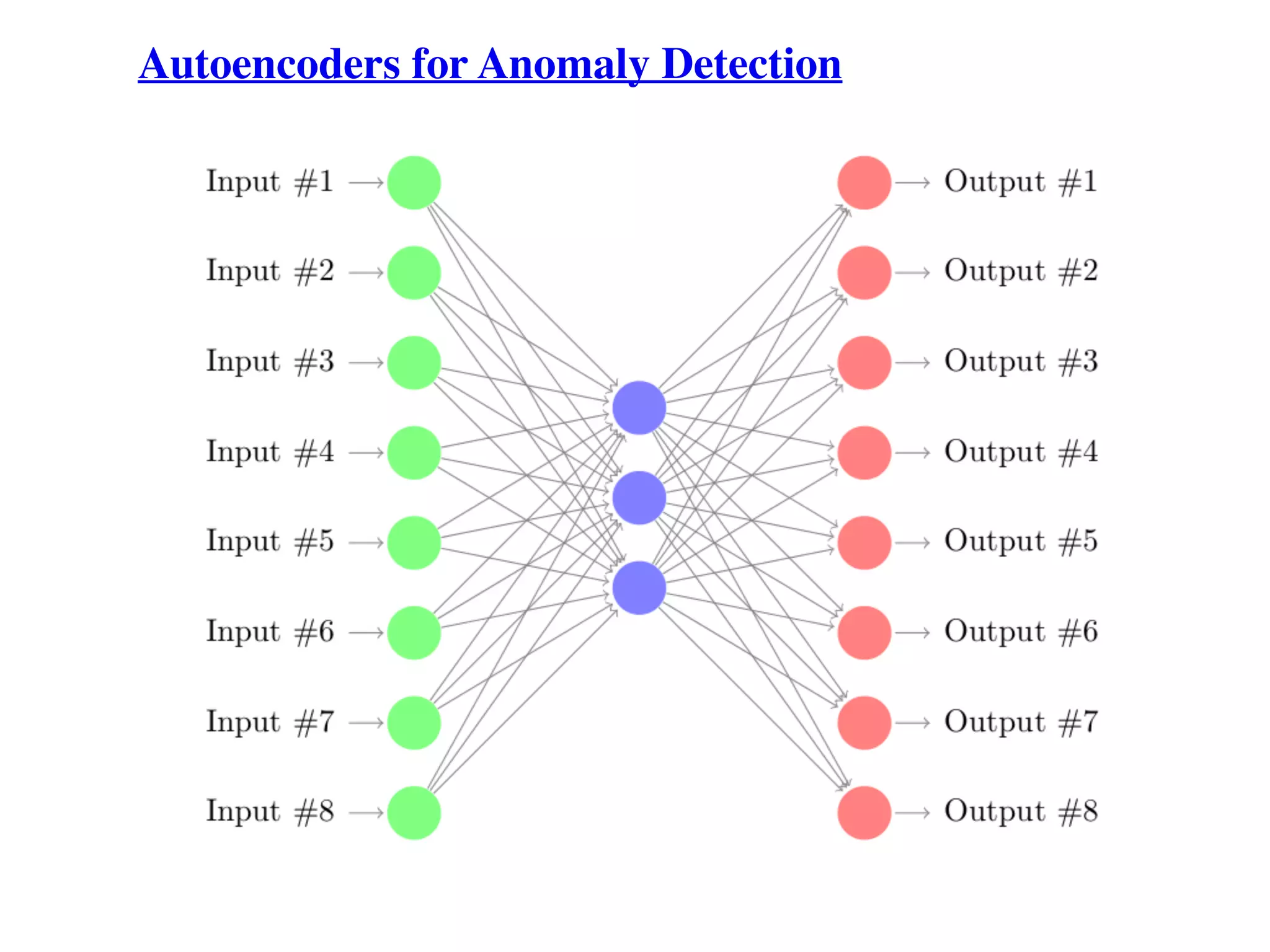
Overview of classification and various methods including RNNs, LSTMs, autoencoders, k-nearest neighbors, and statistical methods for anomaly detection.
Methods for detecting contextual and collective anomalies, emphasizing the importance of context and relationships among data instances.
Final note on understanding problem context before choosing anomaly detection methods.



































































