Downloaded 203 times





![5
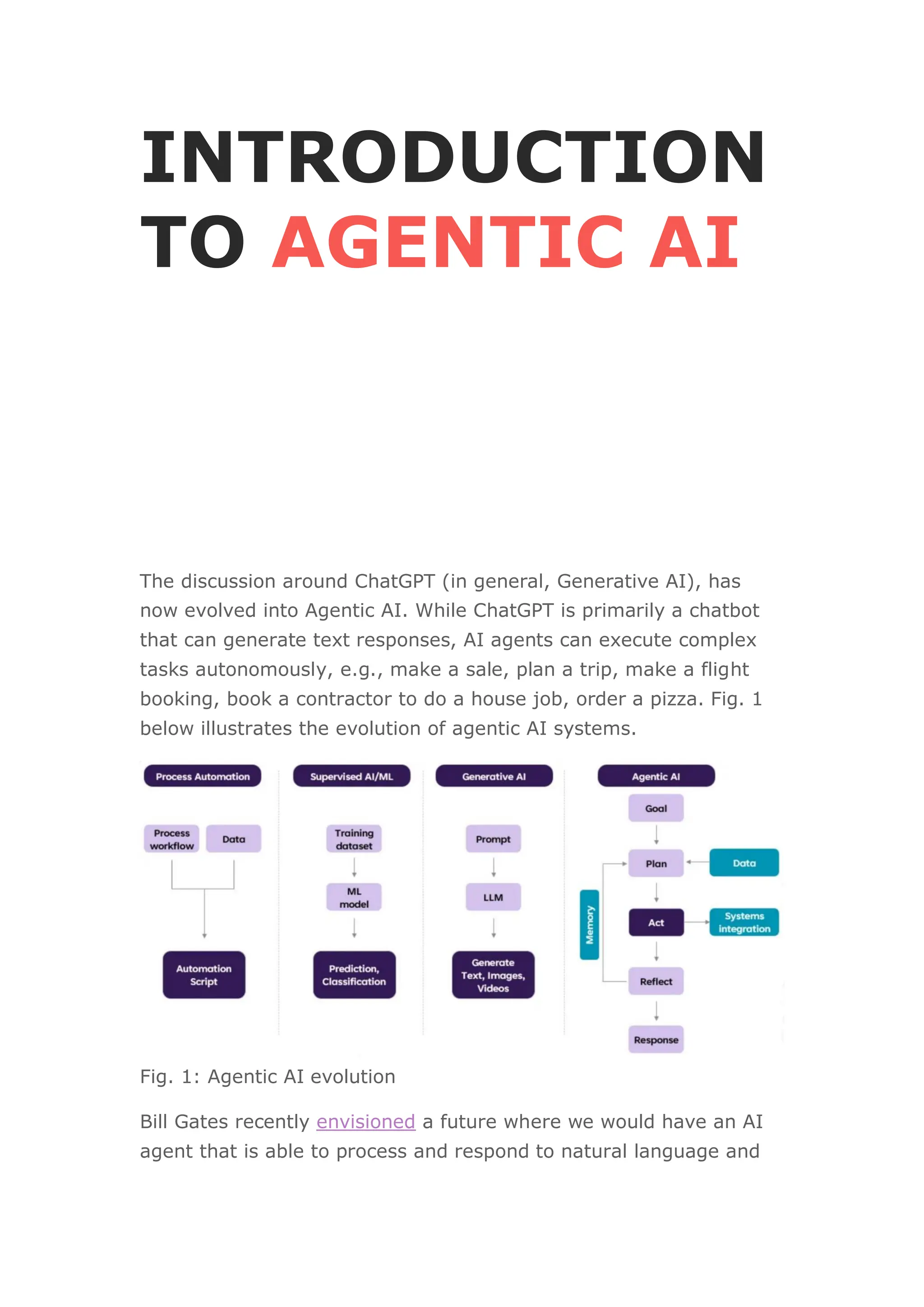
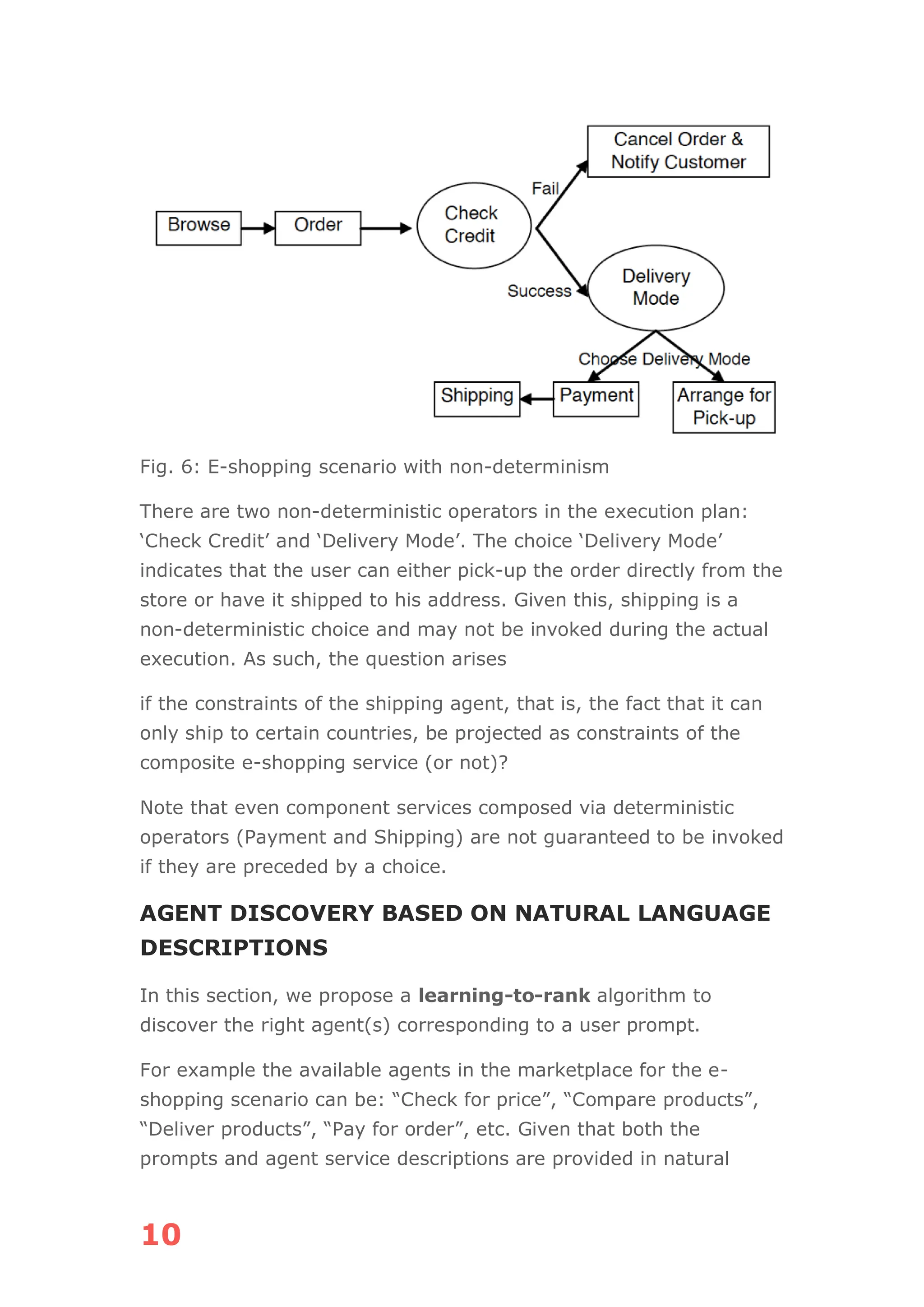
Fig. 3: AI agent platform reference architecture
Given a user task, we prompt a LLM for the task decomposition—
this is the overlap with Gen AI. Unfortunately, this also means that
agentic AI systems today are limited by the reasoning capabilities
of large language models (LLMs). For ex., the GPT4 task
decomposition of the prompt:
Generate a tailored email campaign to achieve sales of USD 1
Million in 1 month, The applicable products and their performance
metrics are available at [url]. Connect to CRM system [integration]
for customer names, email addresses, and demographic details.
is detailed in Fig. 4: (Analyze products)—(Identify target
audience)—(Create tailored email campaign).](https://image.slidesharecdn.com/agenticaiguidedebmalya-250202122738-82d5a179/75/Agentic-AI-Scalable-Responsible-Deployment-of-AI-Agents-in-the-Enterprise-7-2048.jpg)








































![5
Fig. 3: AI agent platform reference architecture
Given a user task, we prompt a LLM for the task decomposition—
this is the overlap with Gen AI. Unfortunately, this also means that
agentic AI systems today are limited by the reasoning capabilities
of large language models (LLMs). For ex., the GPT4 task
decomposition of the prompt:
Generate a tailored email campaign to achieve sales of USD 1
Million in 1 month, The applicable products and their performance
metrics are available at [url]. Connect to CRM system [integration]
for customer names, email addresses, and demographic details.
is detailed in Fig. 4: (Analyze products)—(Identify target
audience)—(Create tailored email campaign).](https://crownmelresort.com/image.slidesharecdn.com/agenticaiguidedebmalya-250202122738-82d5a179/75/Agentic-AI-Scalable-Responsible-Deployment-of-AI-Agents-in-the-Enterprise-7-2048.jpg)










































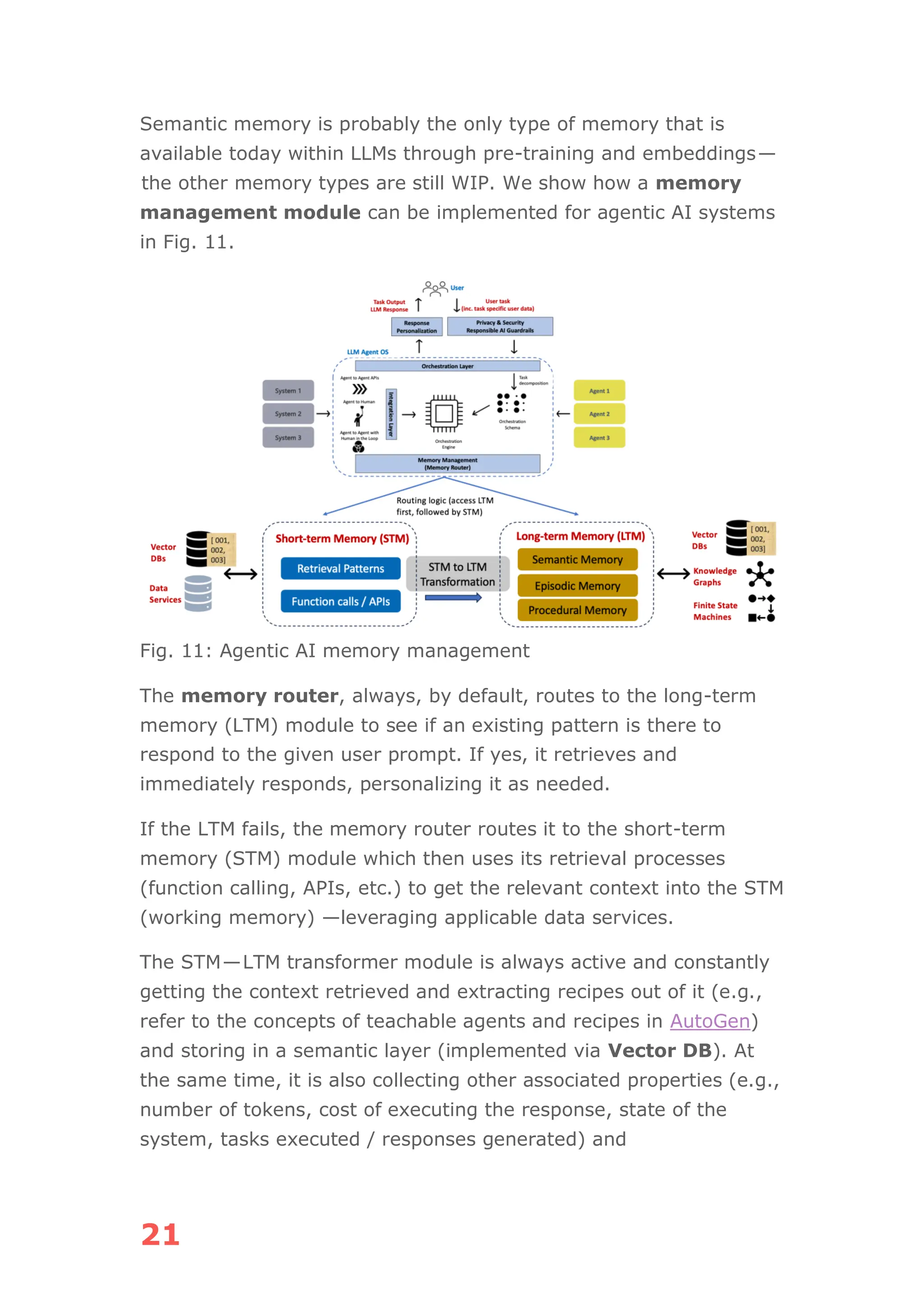
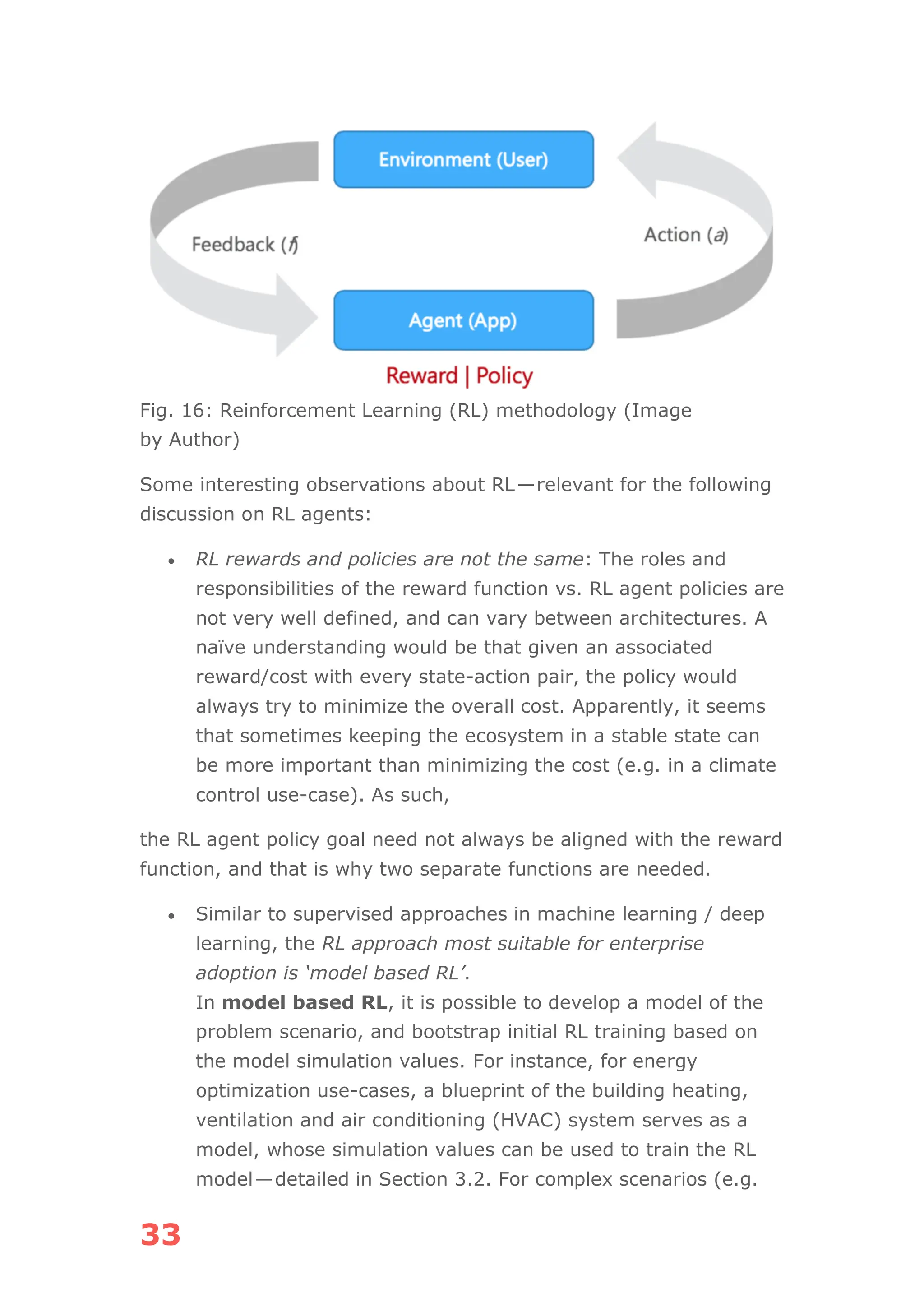
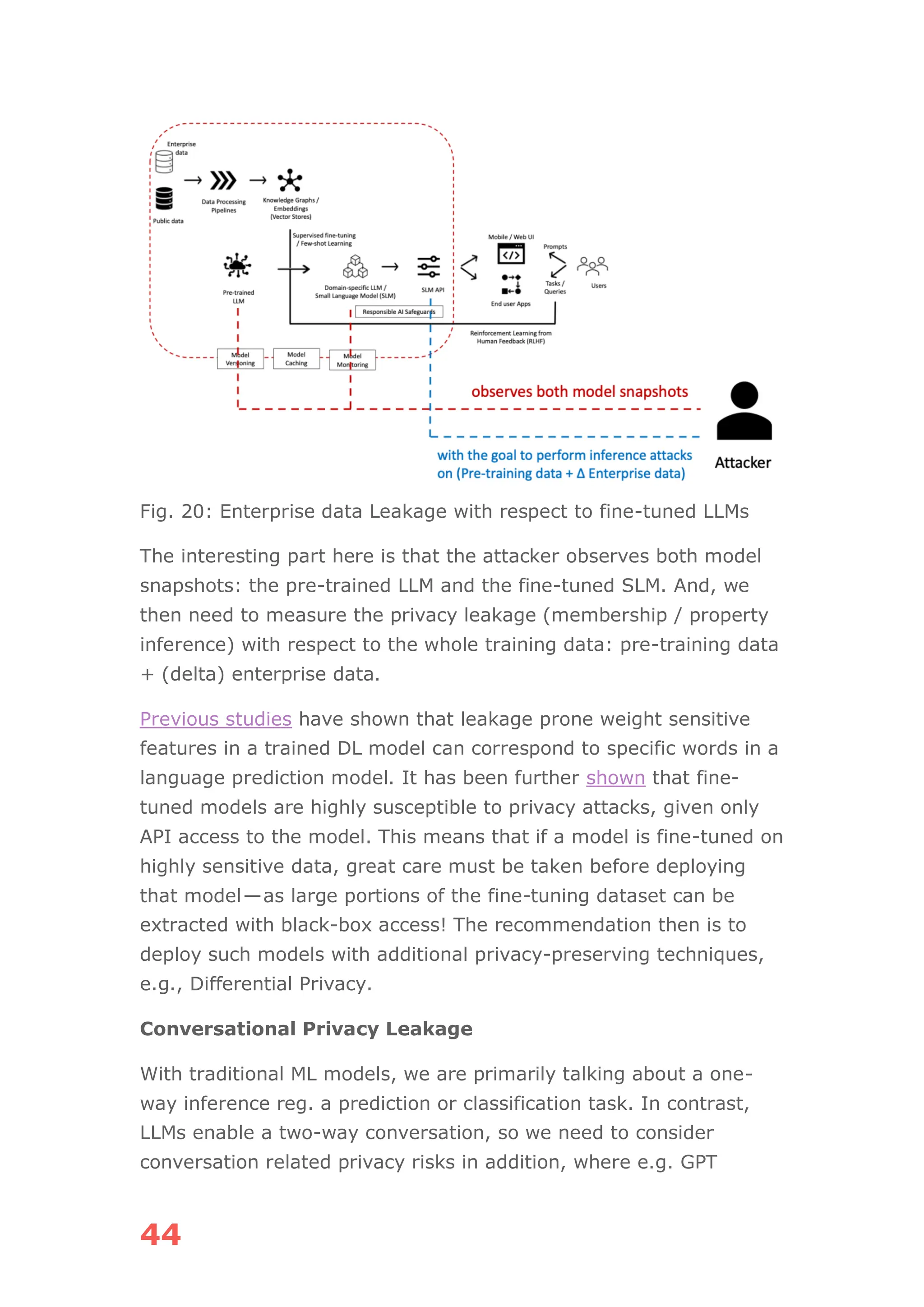
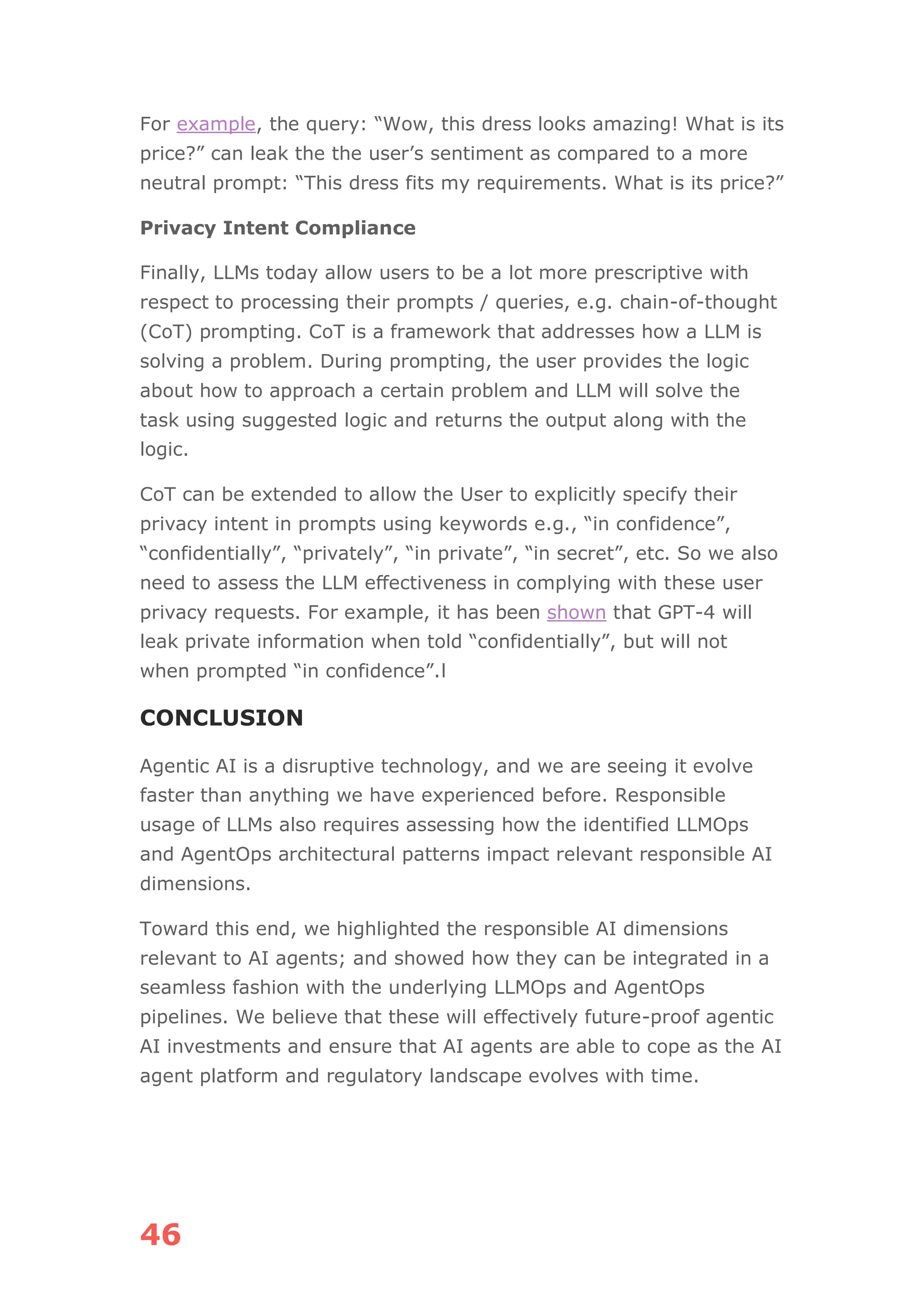
The document discusses the concept of agentic AI, which refers to autonomous AI agents capable of executing complex tasks like making bookings and managing projects, as opposed to traditional chatbots. It covers key aspects including the architecture of agentic AI systems, the importance of agent discovery and personalization, and the need for effective memory management using vector databases. Emphasis is placed on the potential applications of agentic AI across various industries and the challenges faced in their deployment and integration into existing enterprise systems.





















































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)

