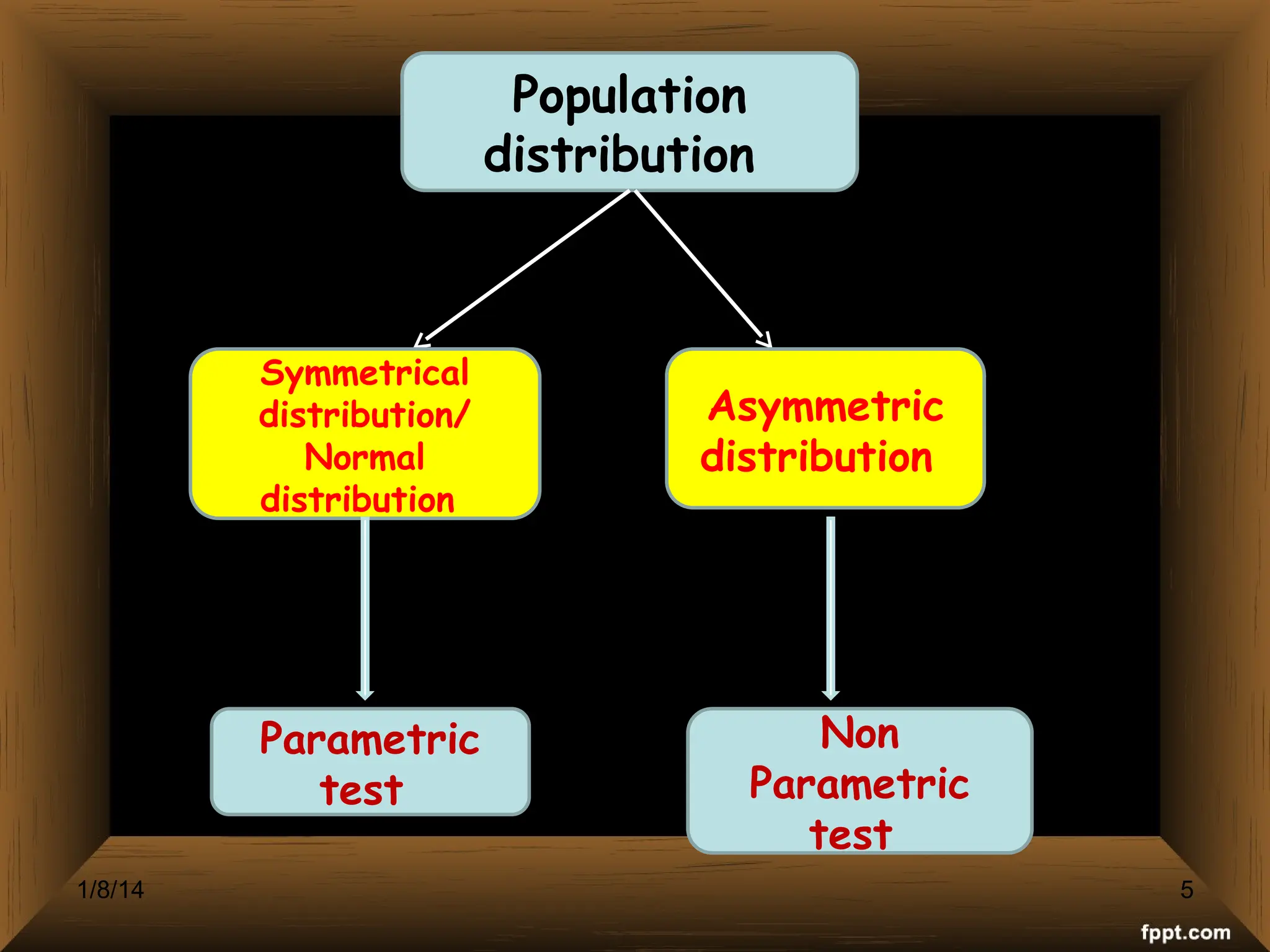
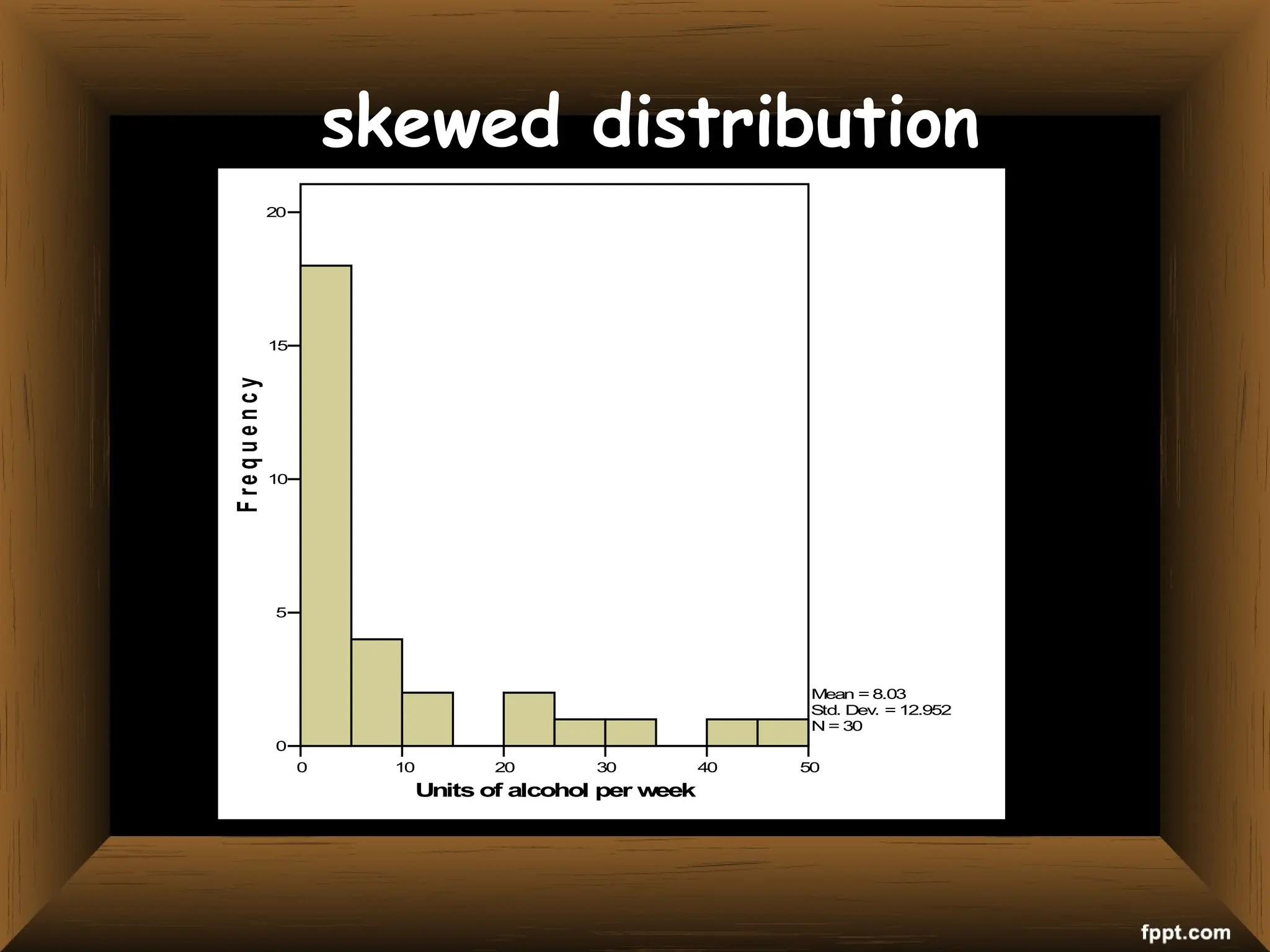
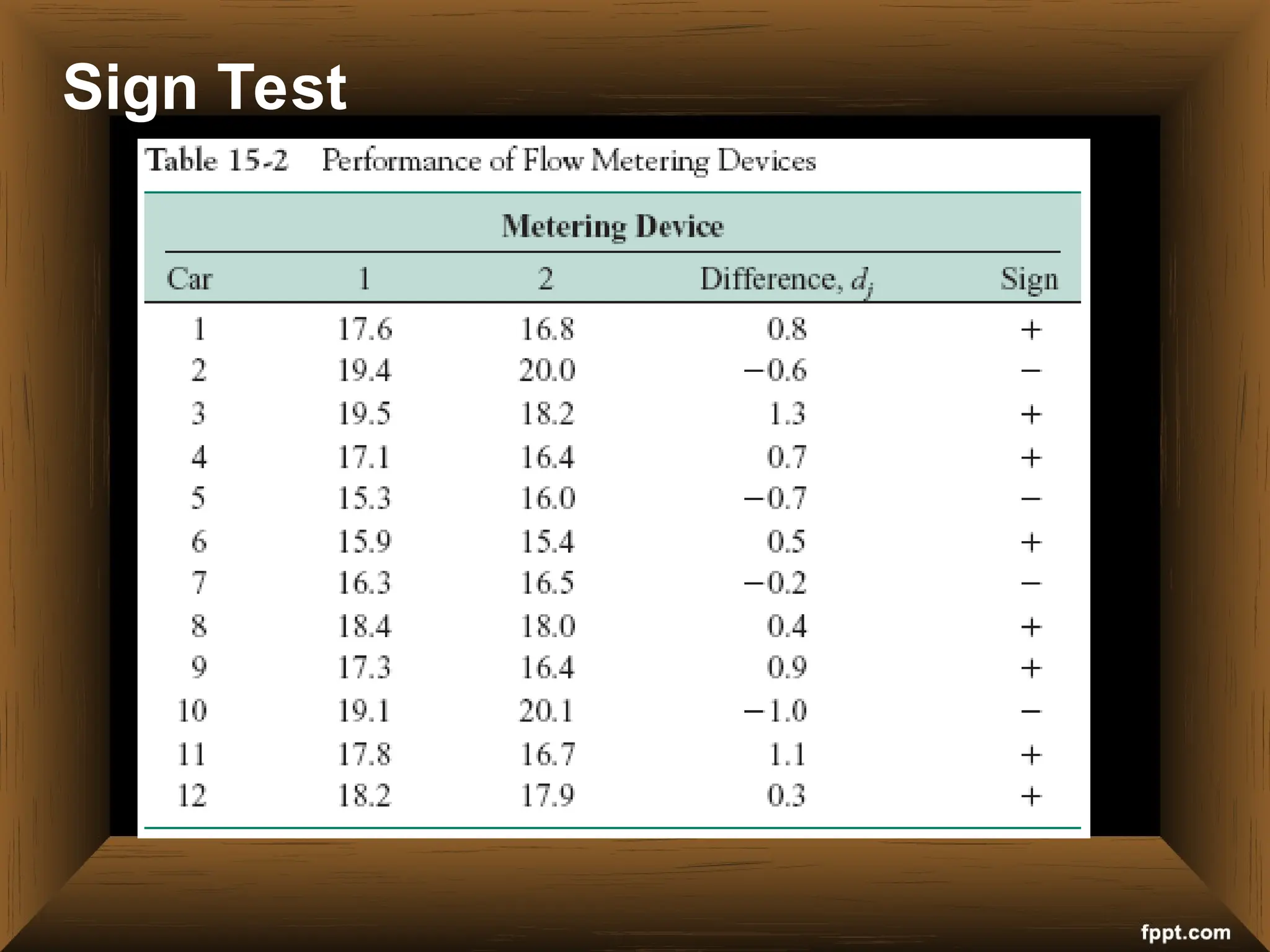
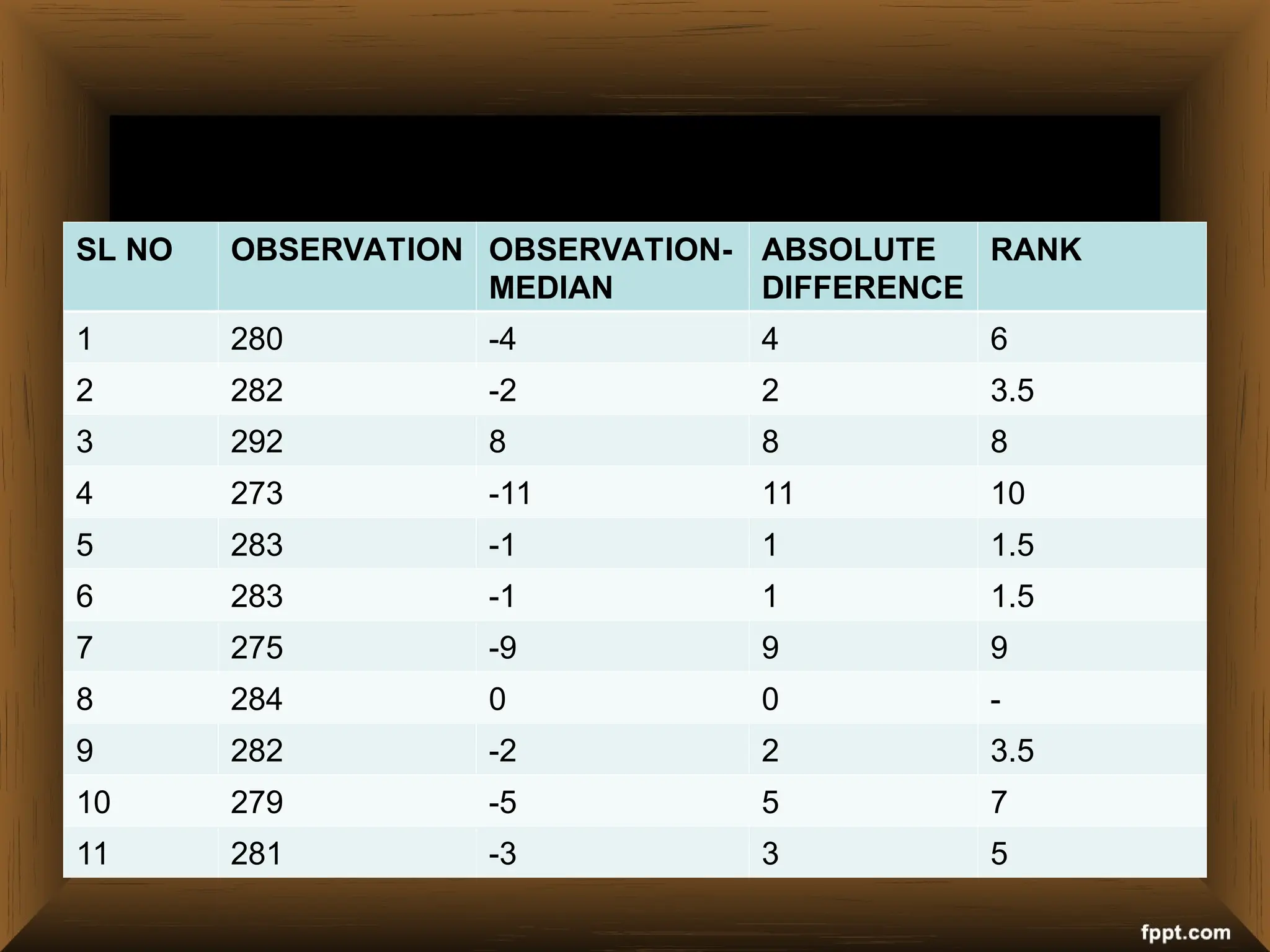
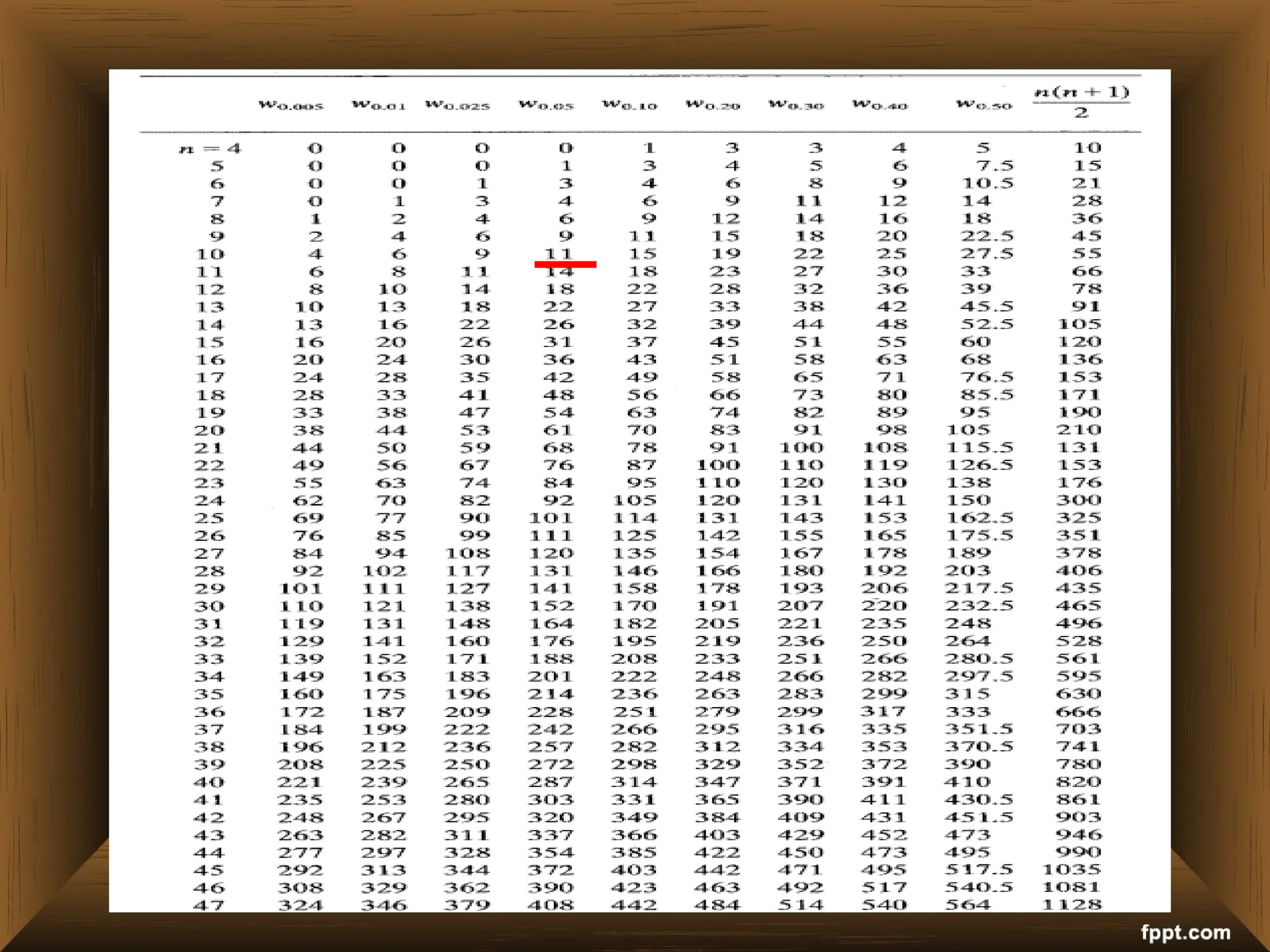
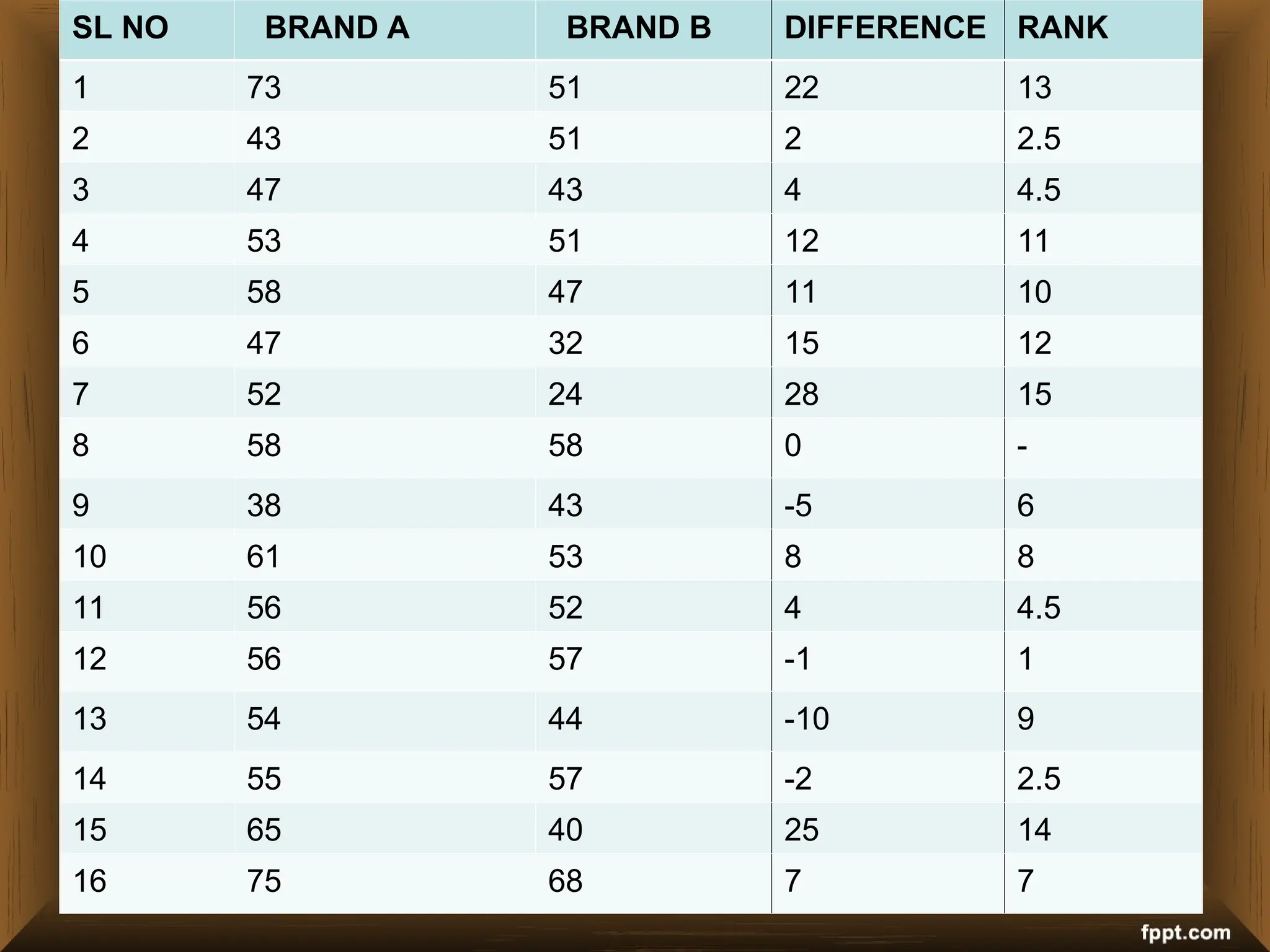
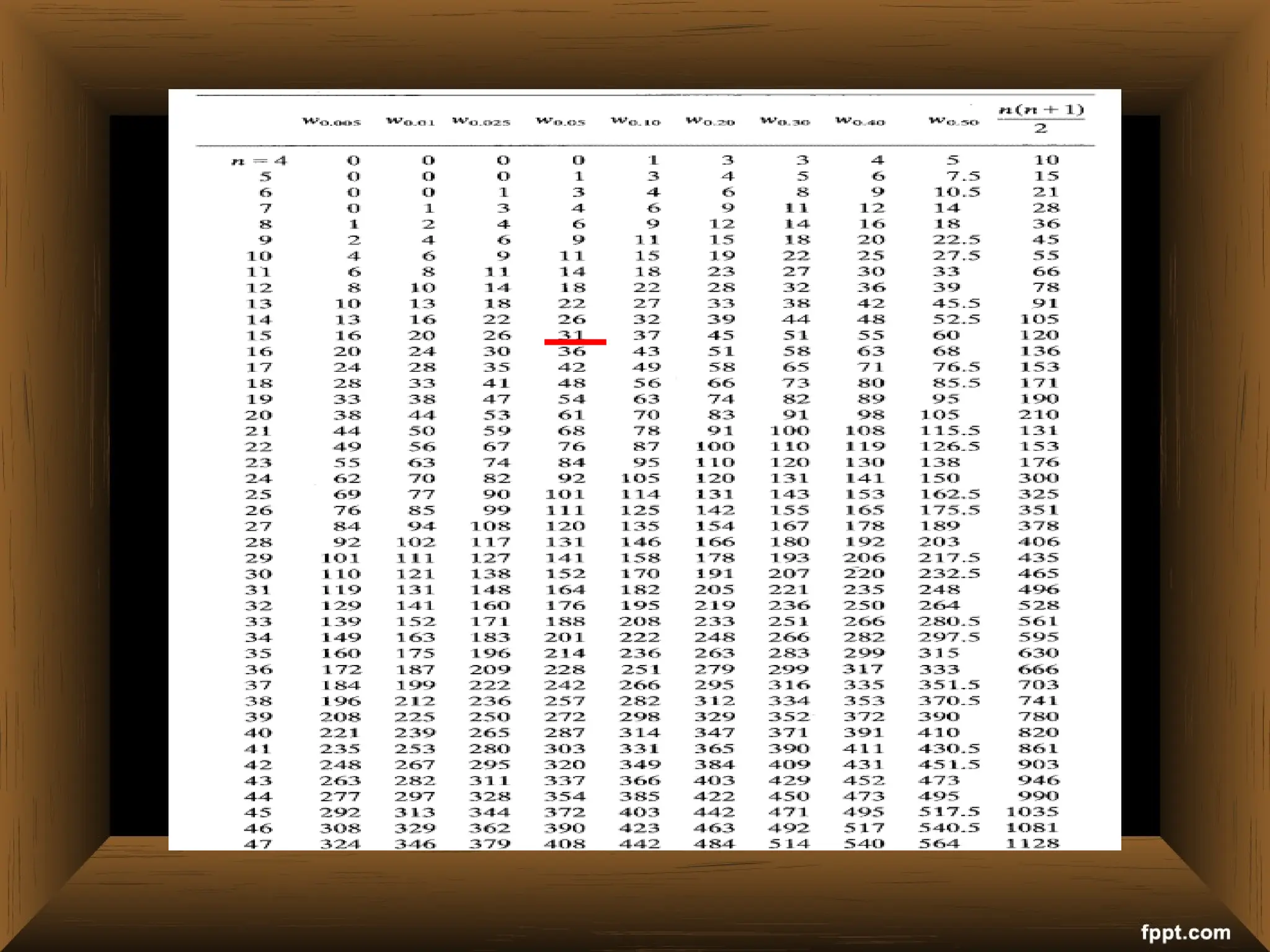
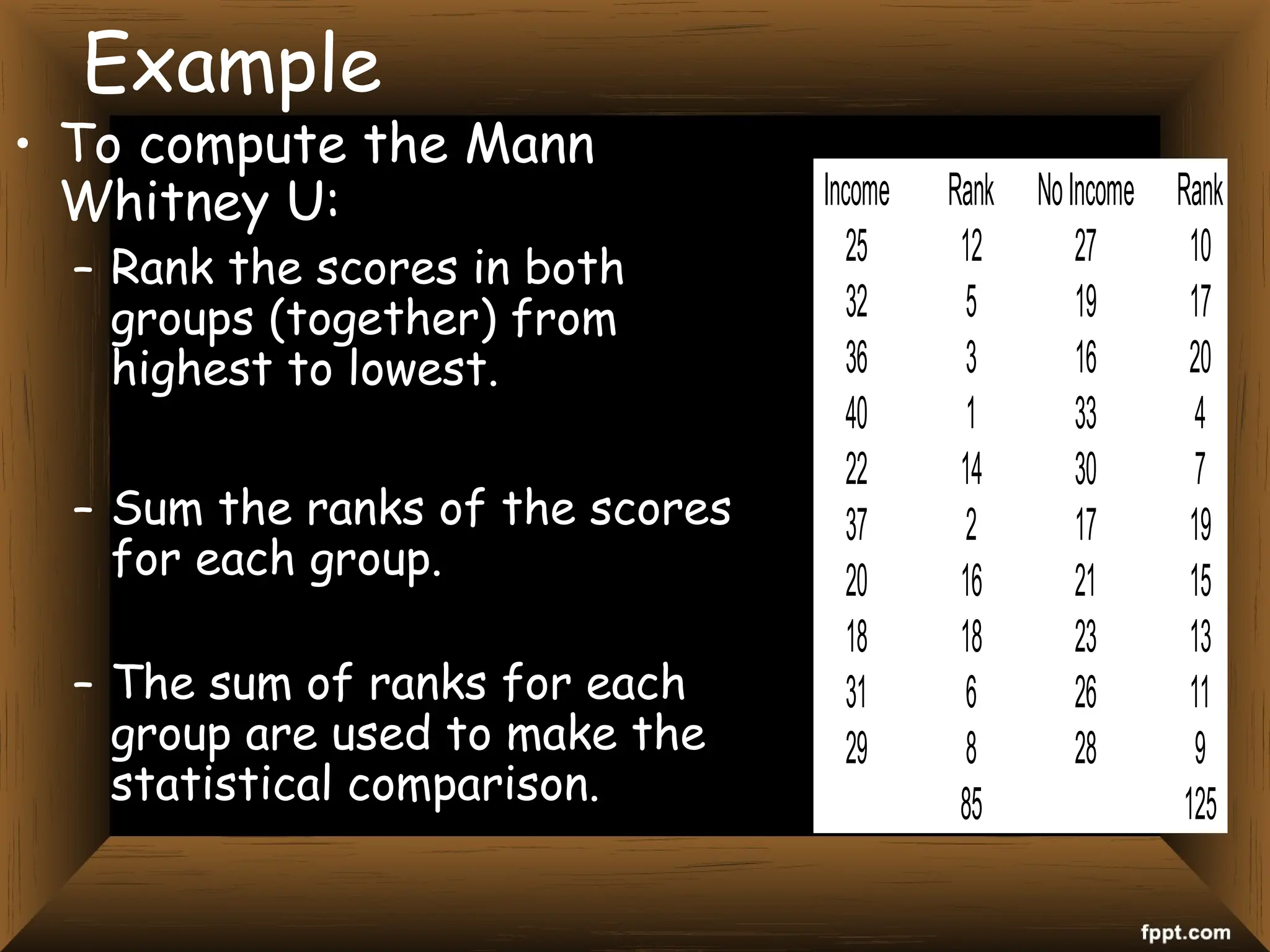
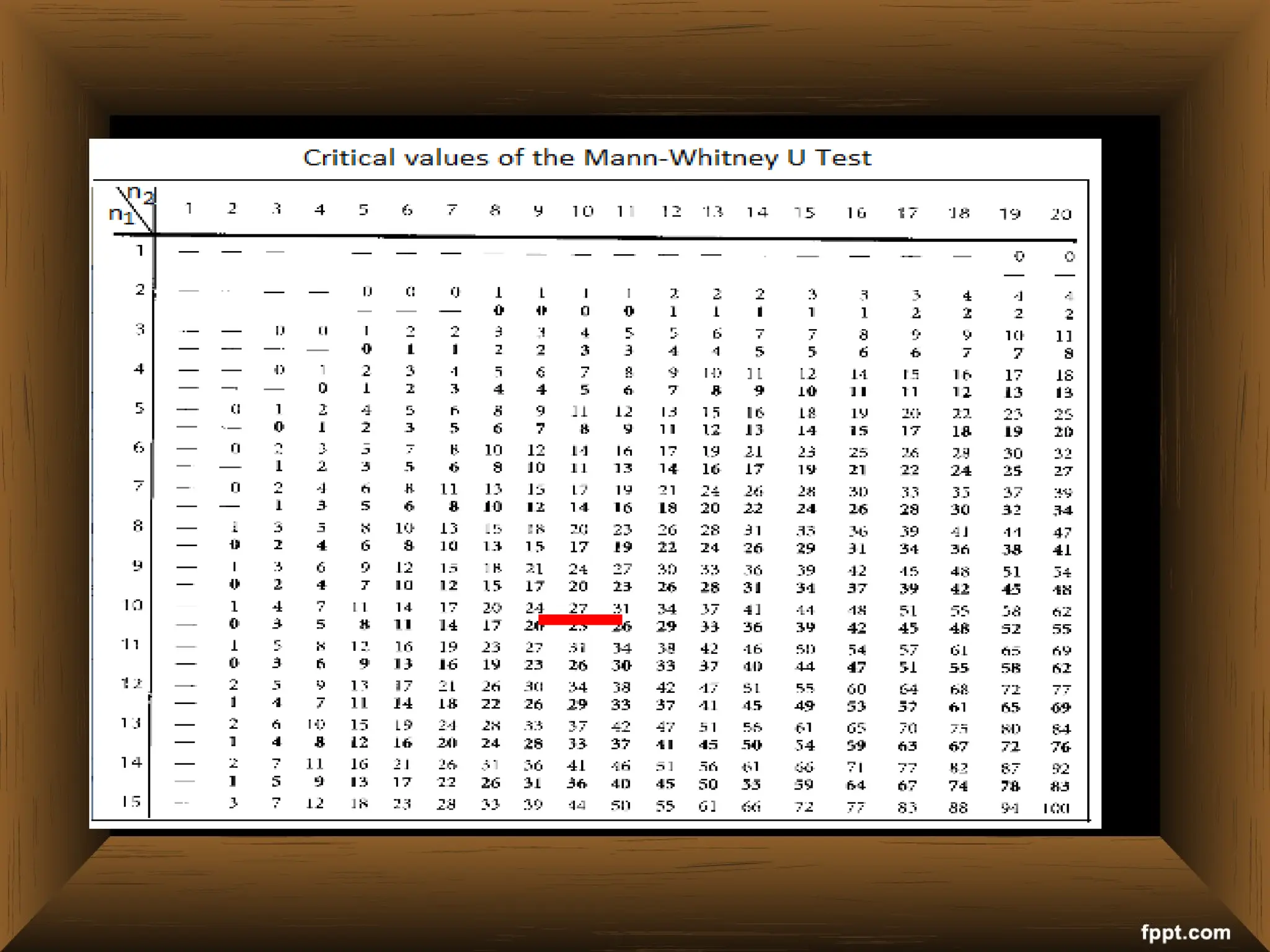
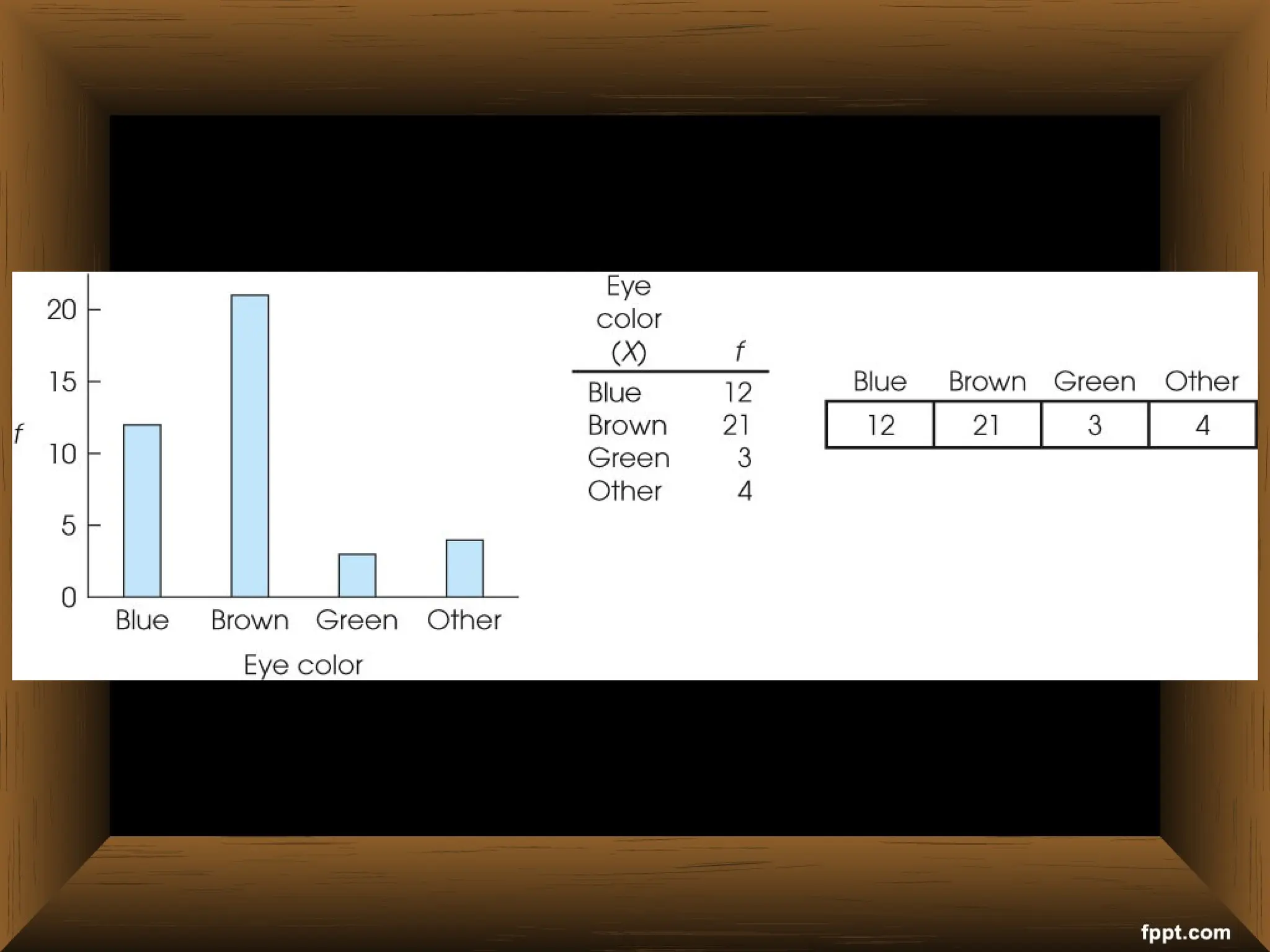
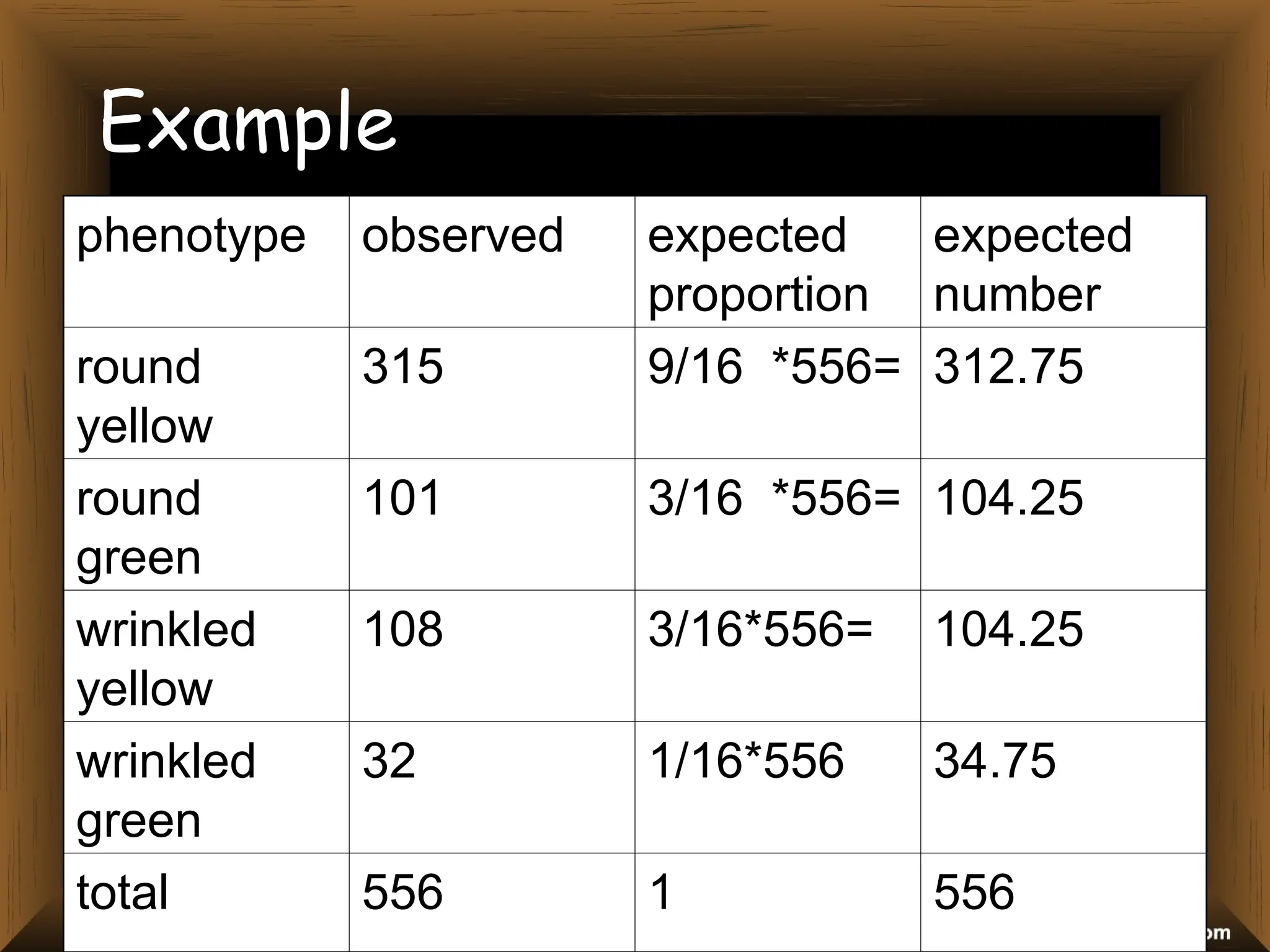
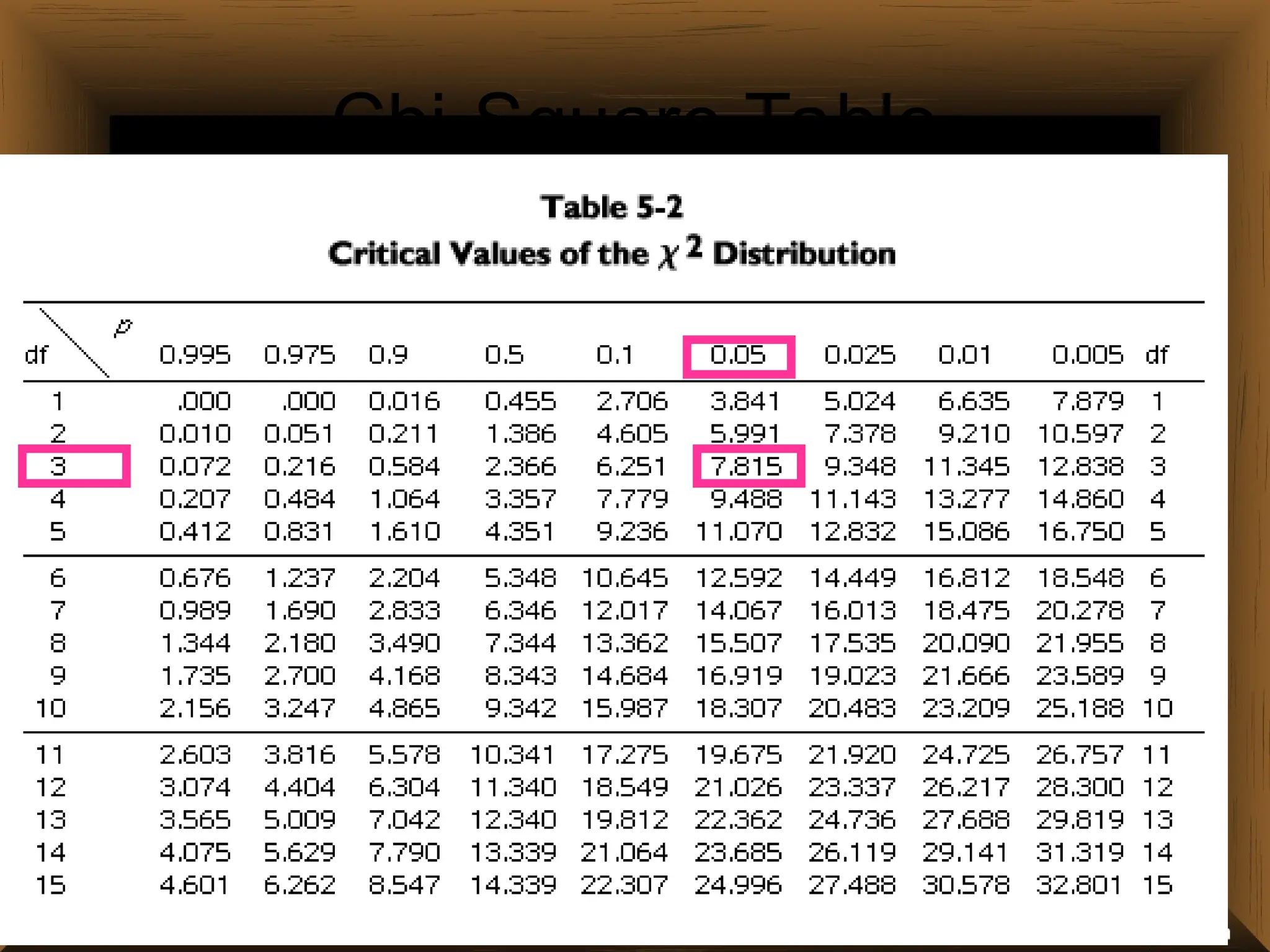
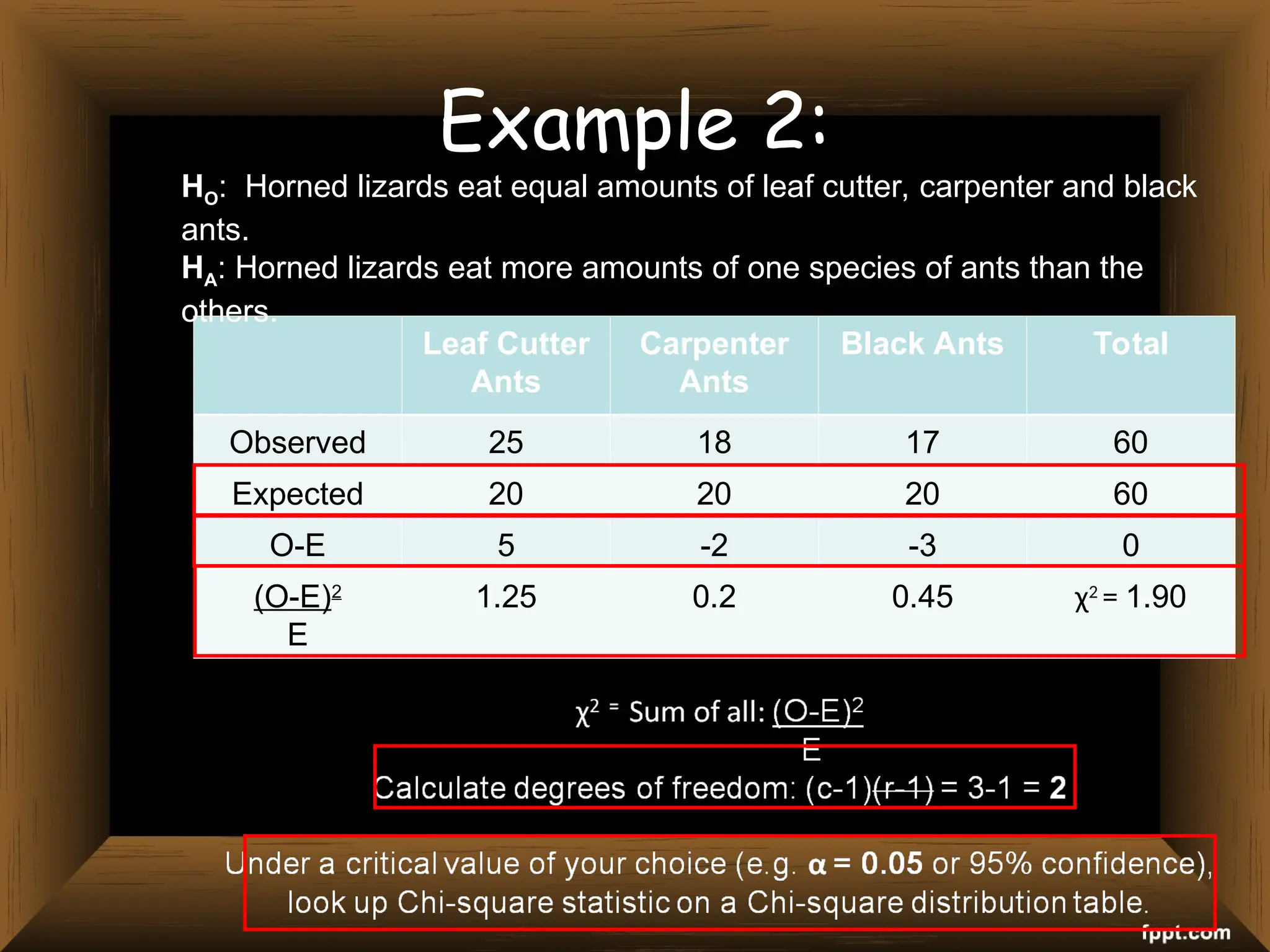
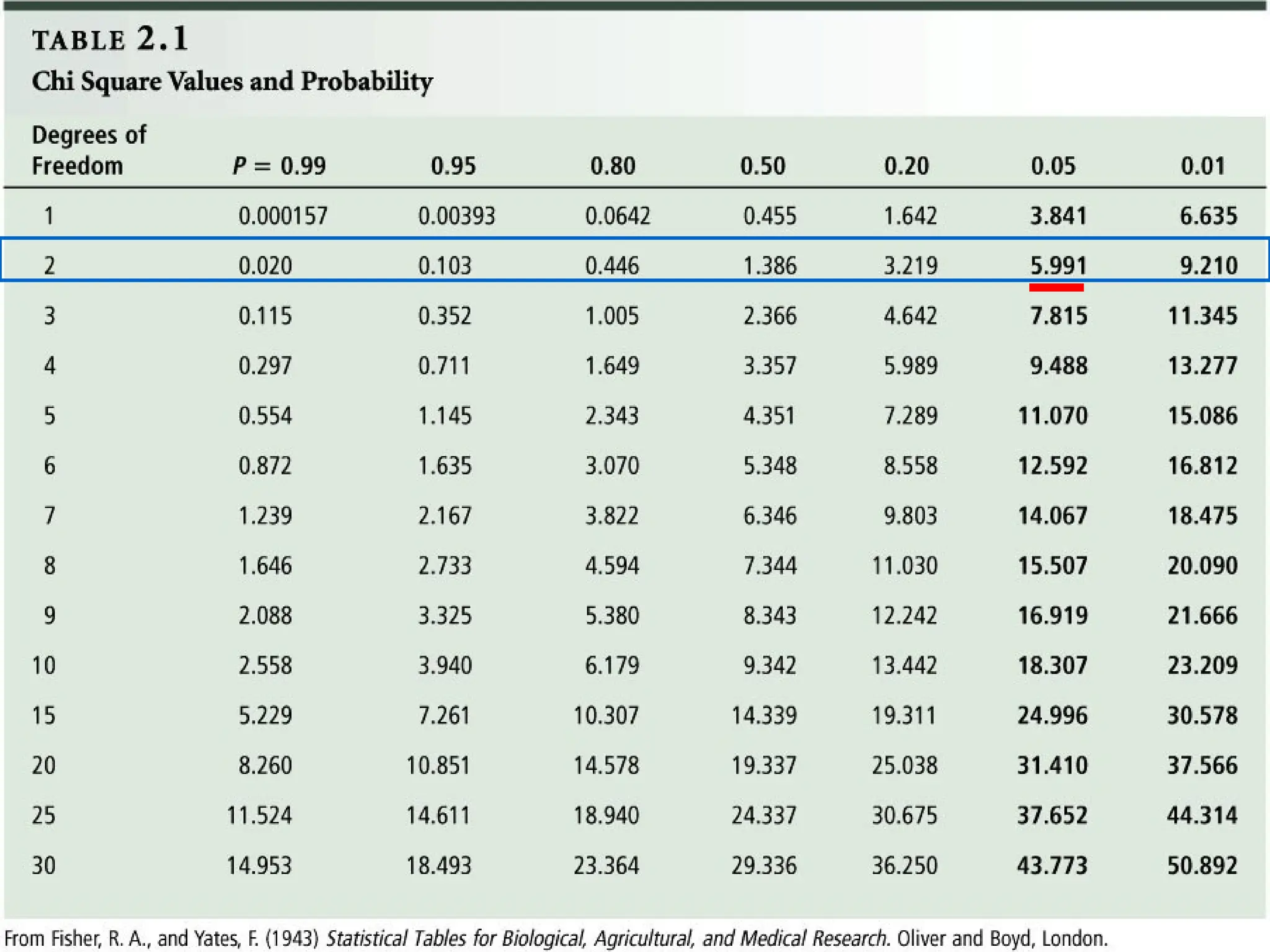
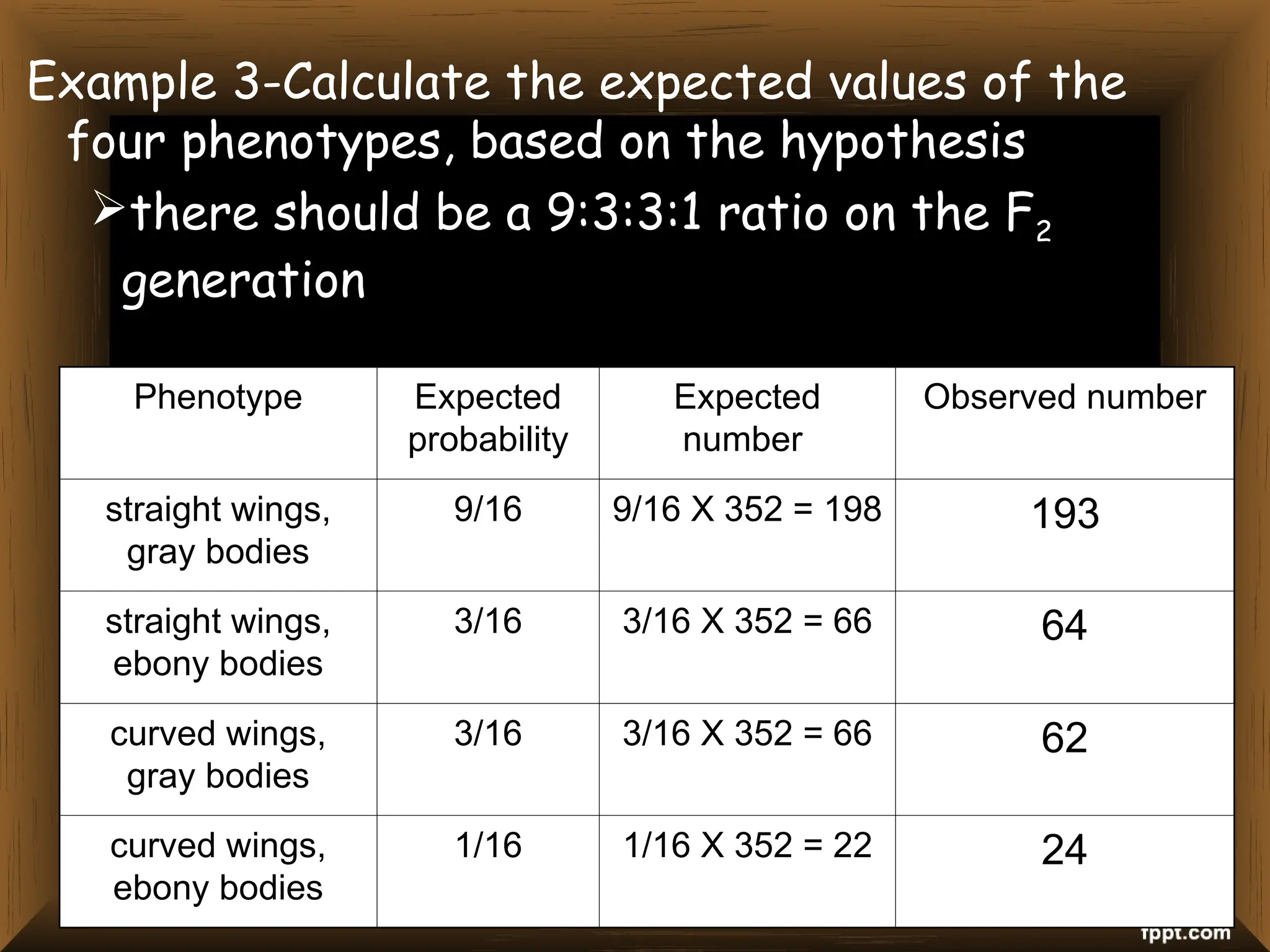
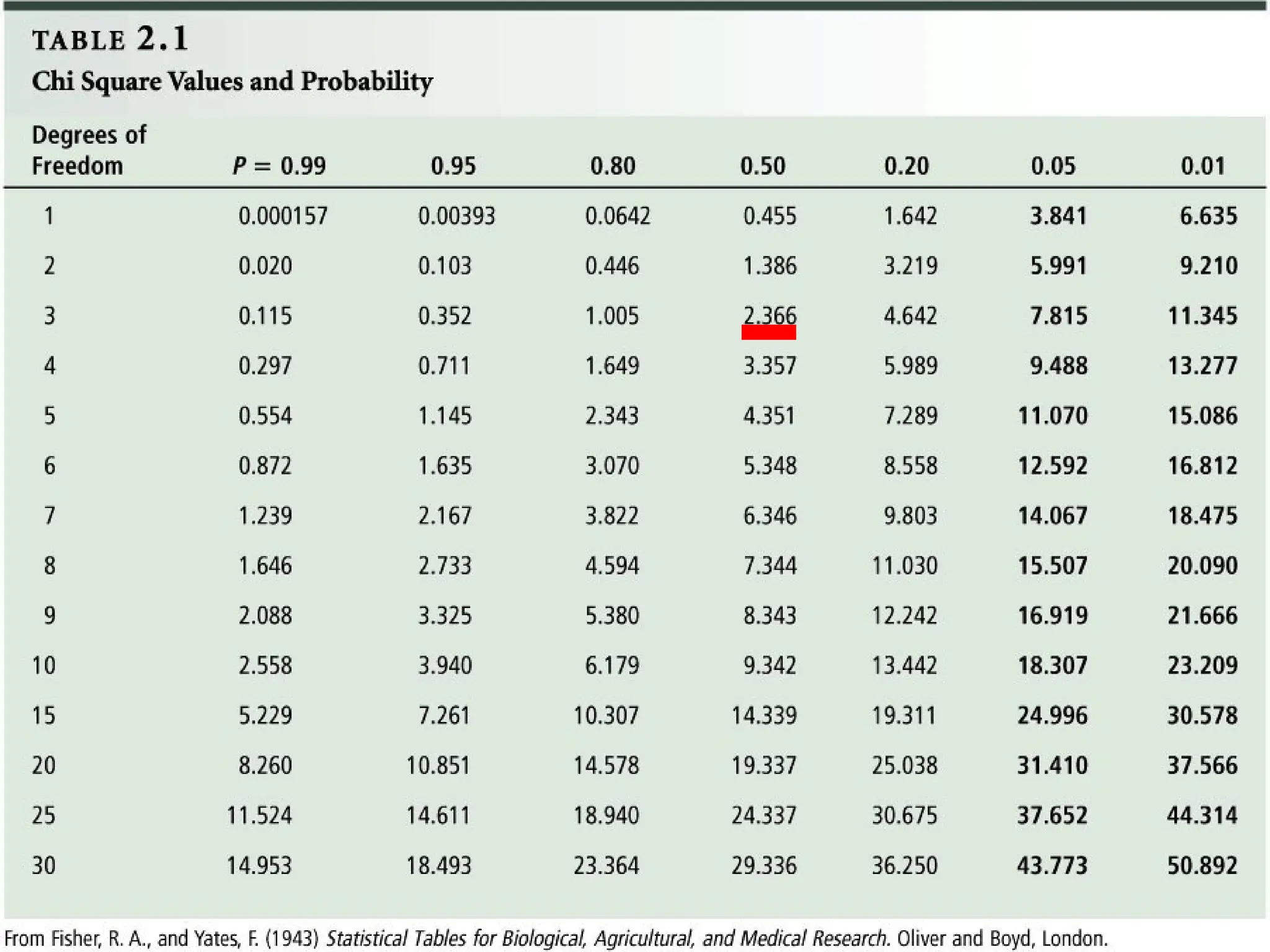
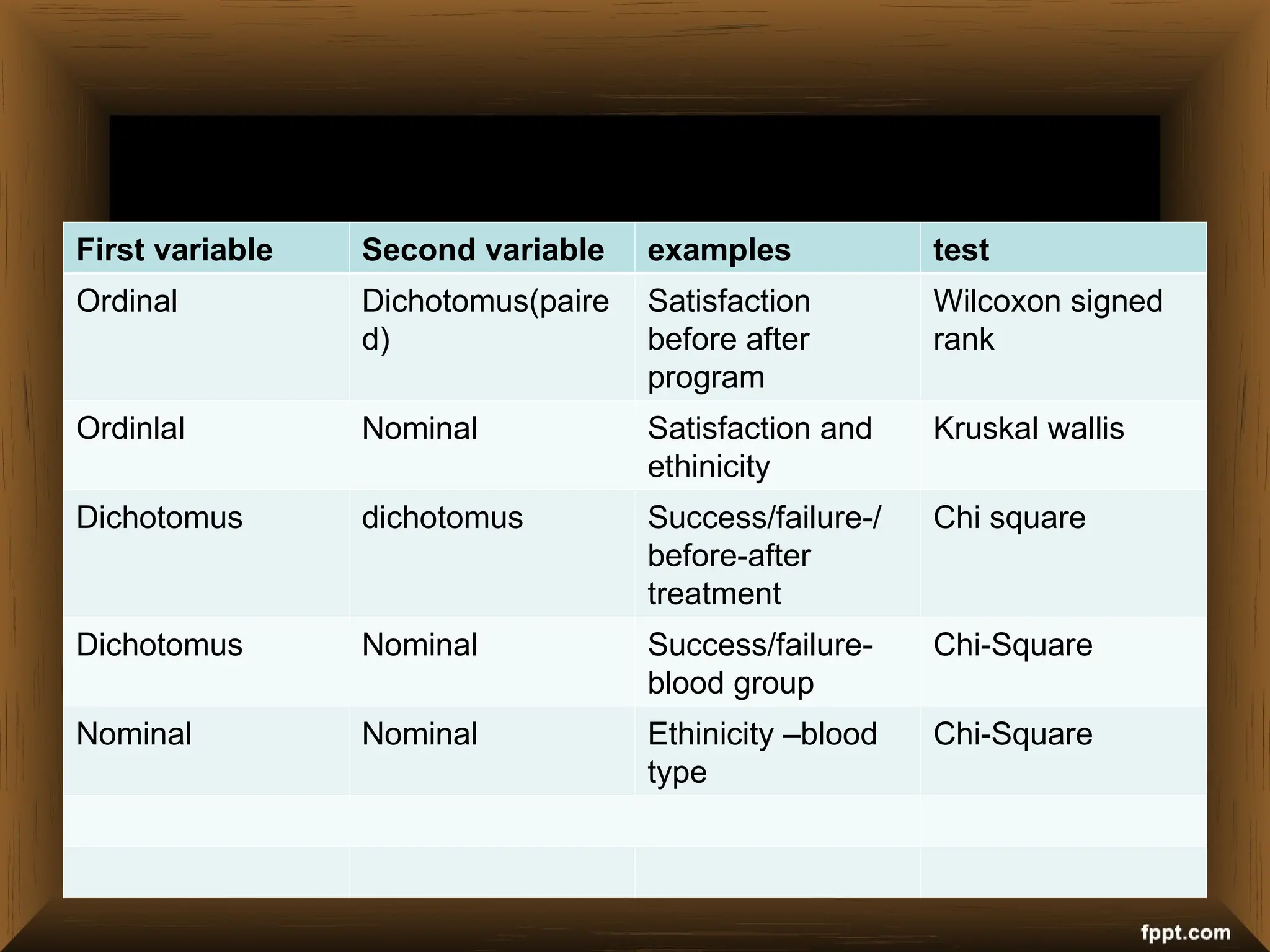
The document provides an overview of various non-parametric statistical tests, including the sign test, Wilcoxon signed-rank test, Mann-Whitney U test, and Chi-square test, outlining their assumptions, applications, and procedures. It explains the differences between parametric and non-parametric tests, emphasizing situations where non-parametric tests are preferred due to fewer assumptions regarding data distribution. Examples and calculations illustrate the implementation of each test, alongside conclusions about interpreting results and hypotheses.