Download as PDF, PPTX













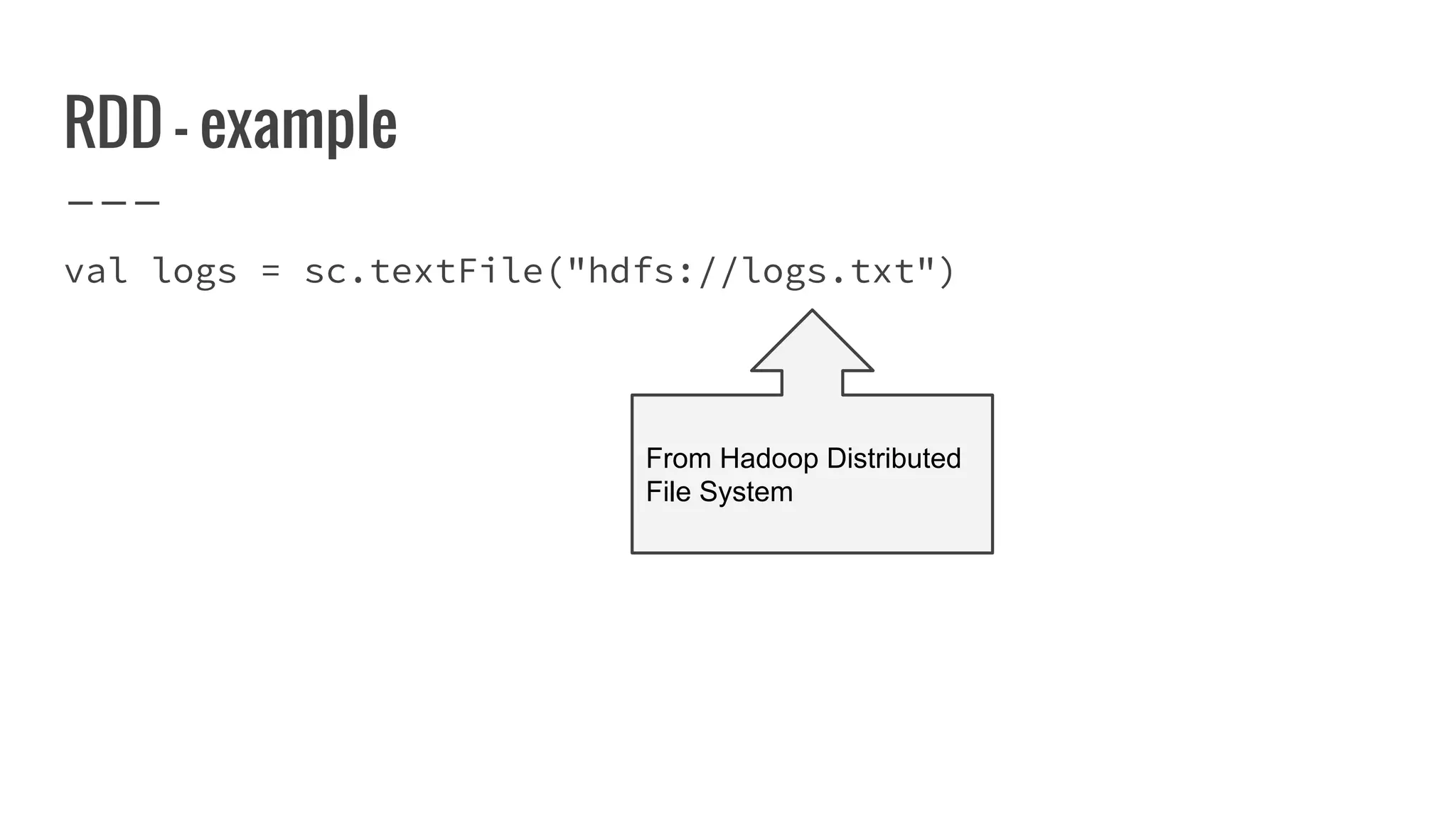



















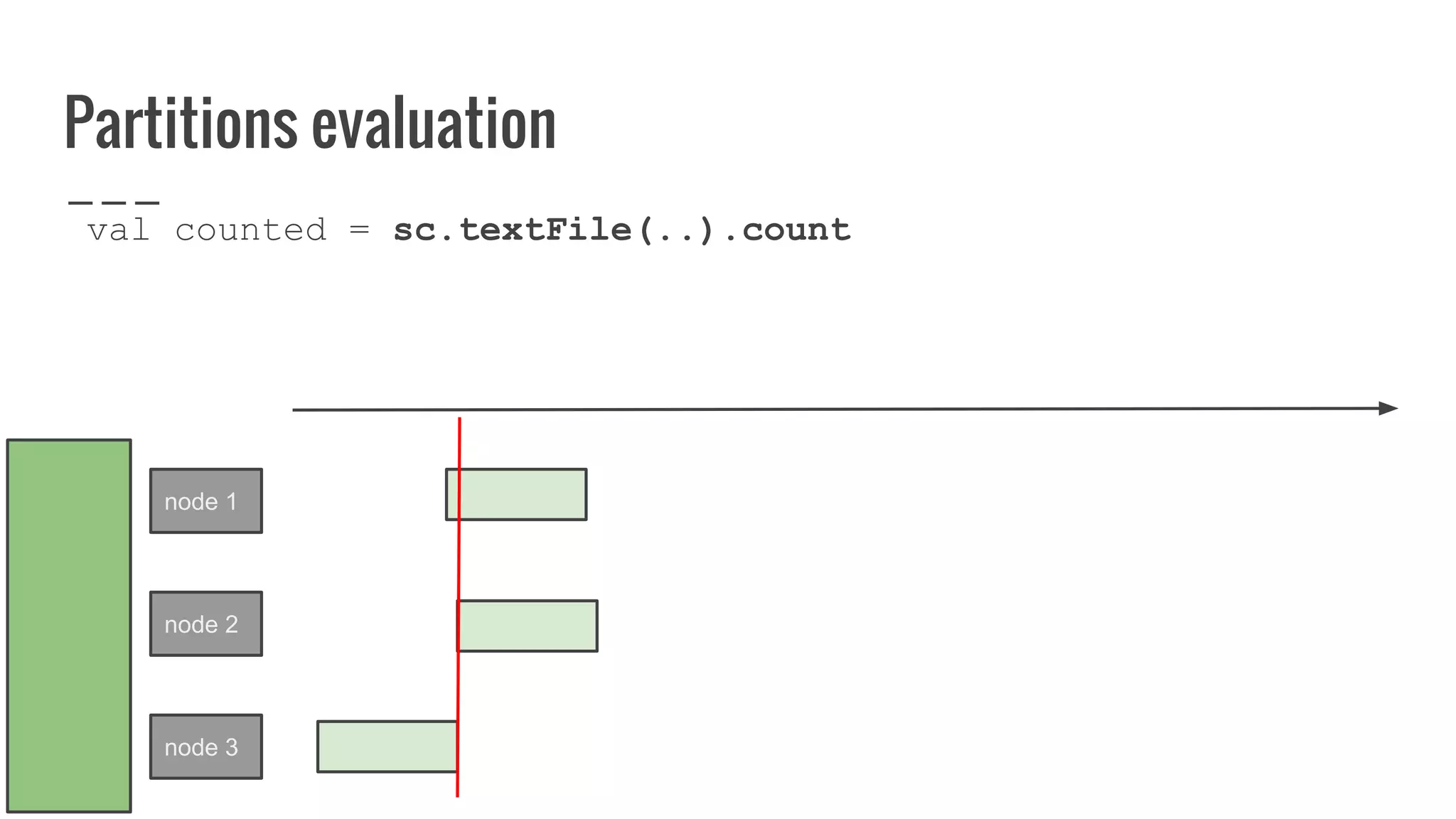

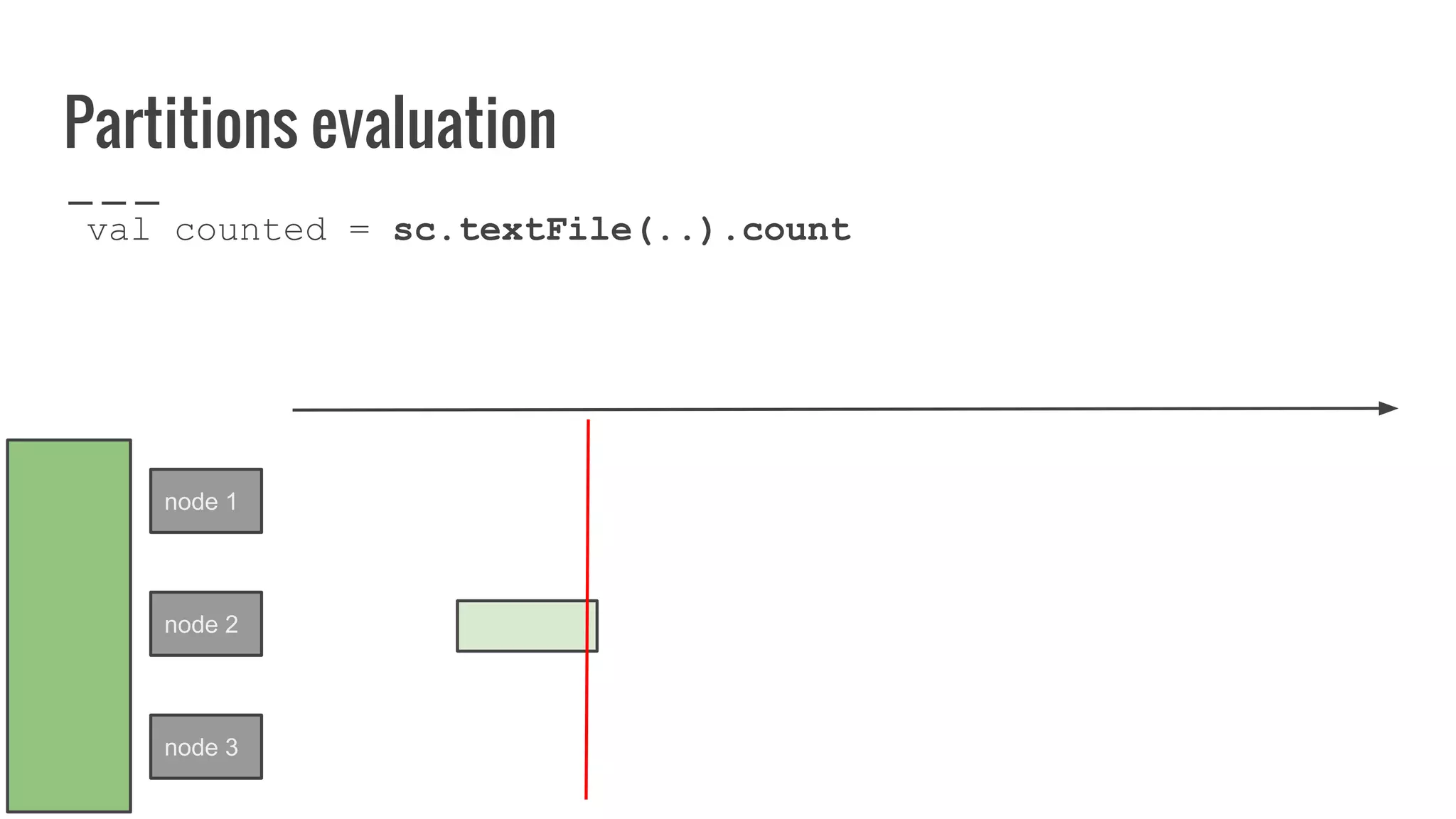









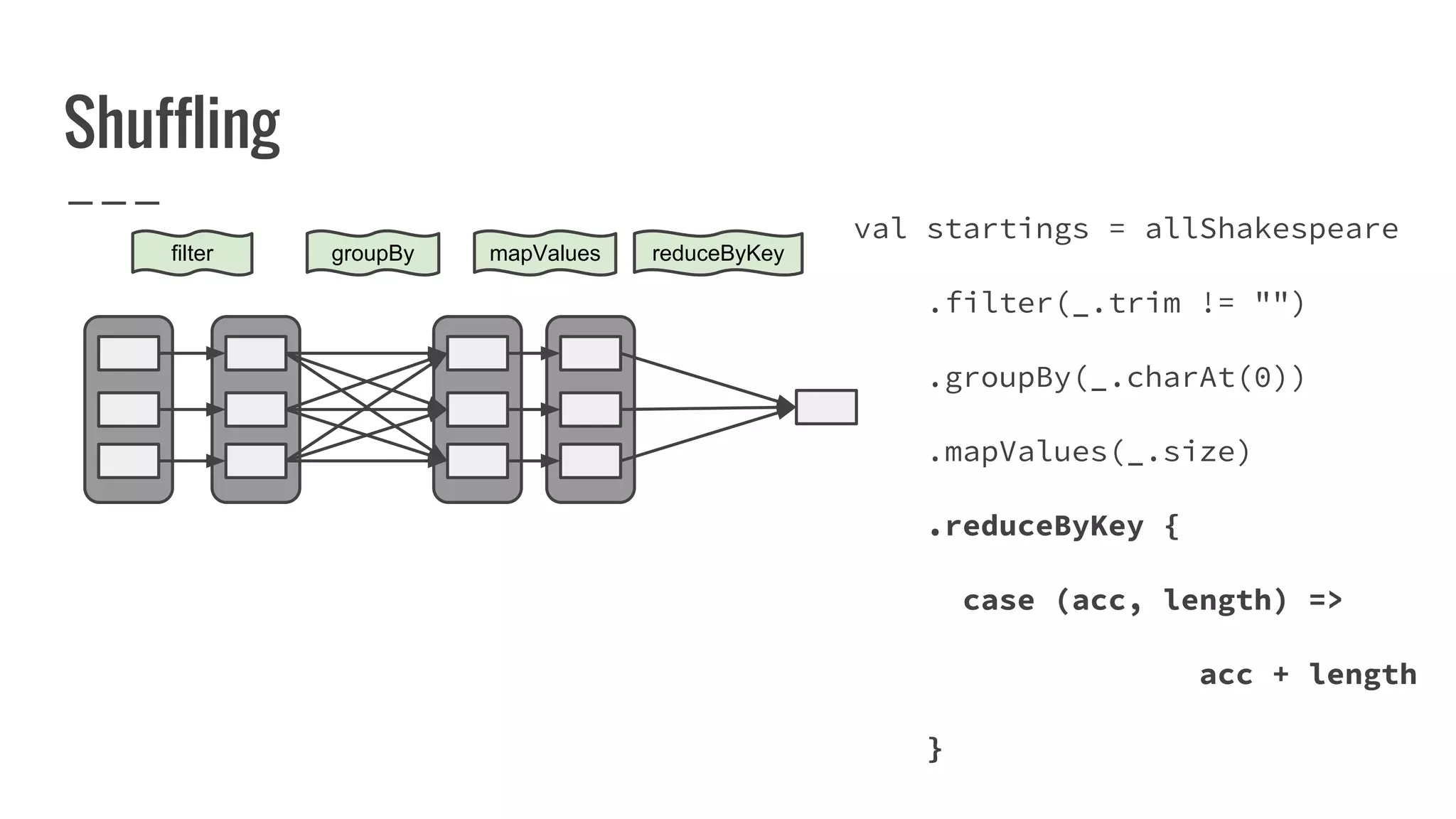
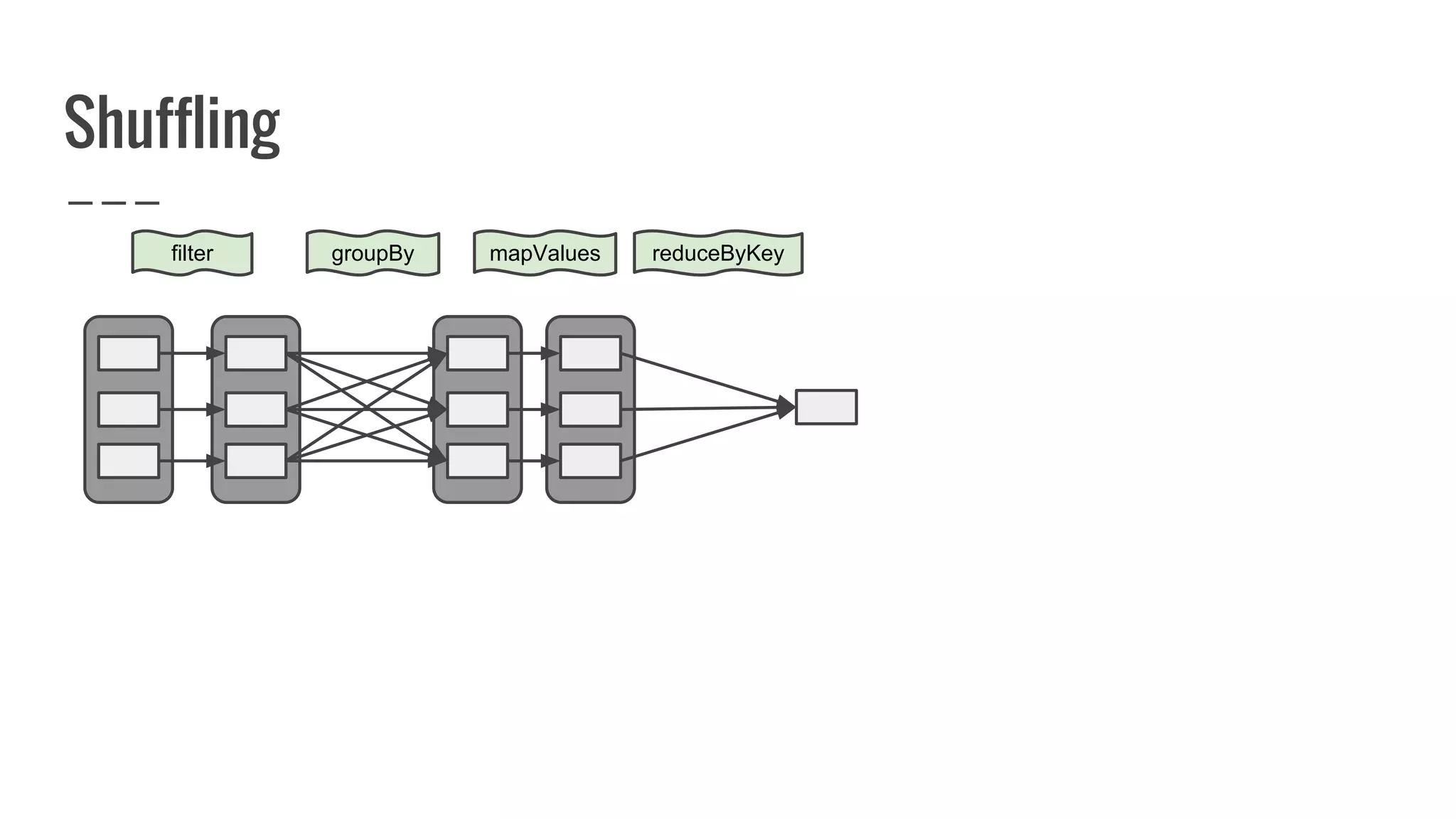
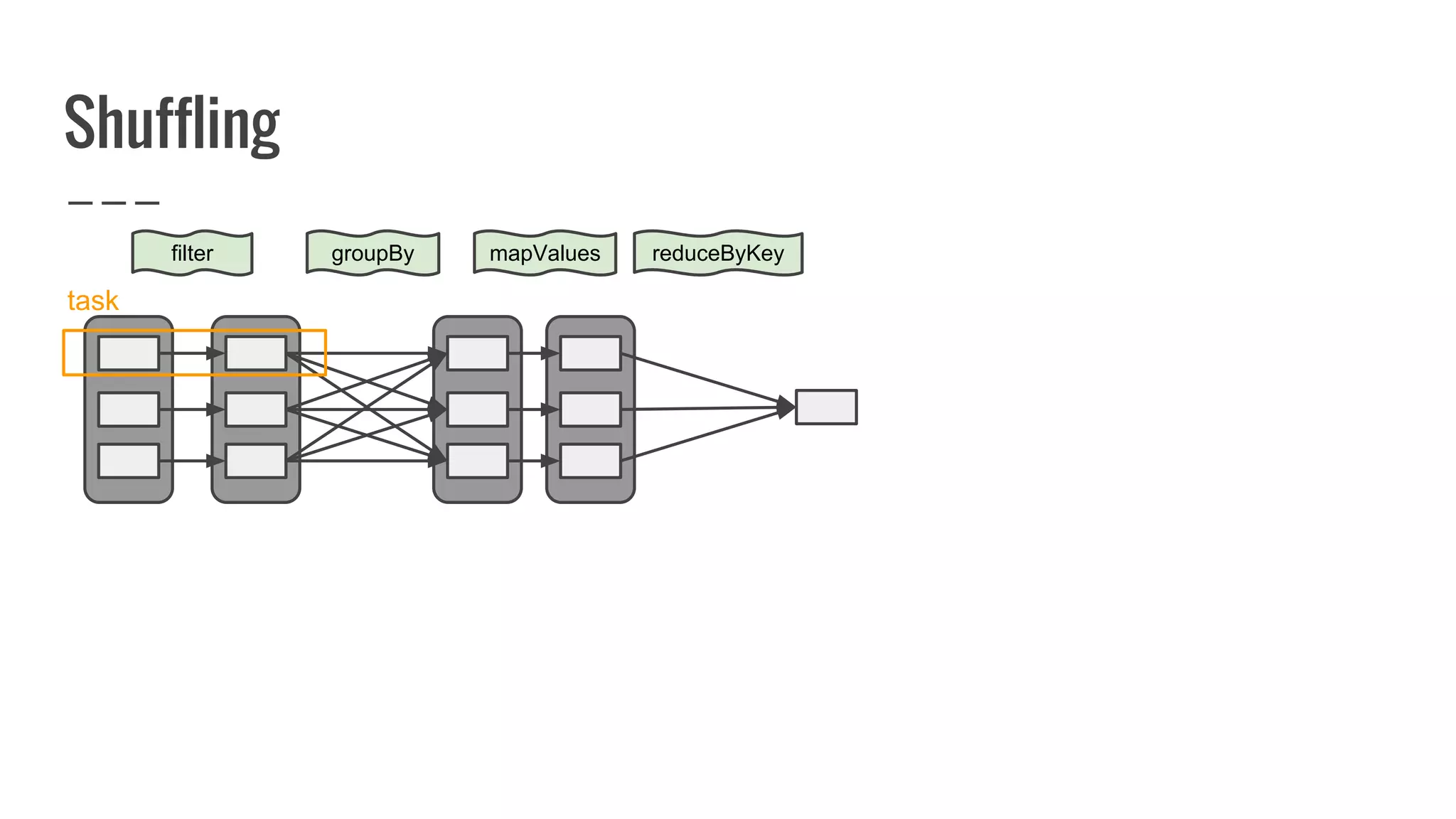
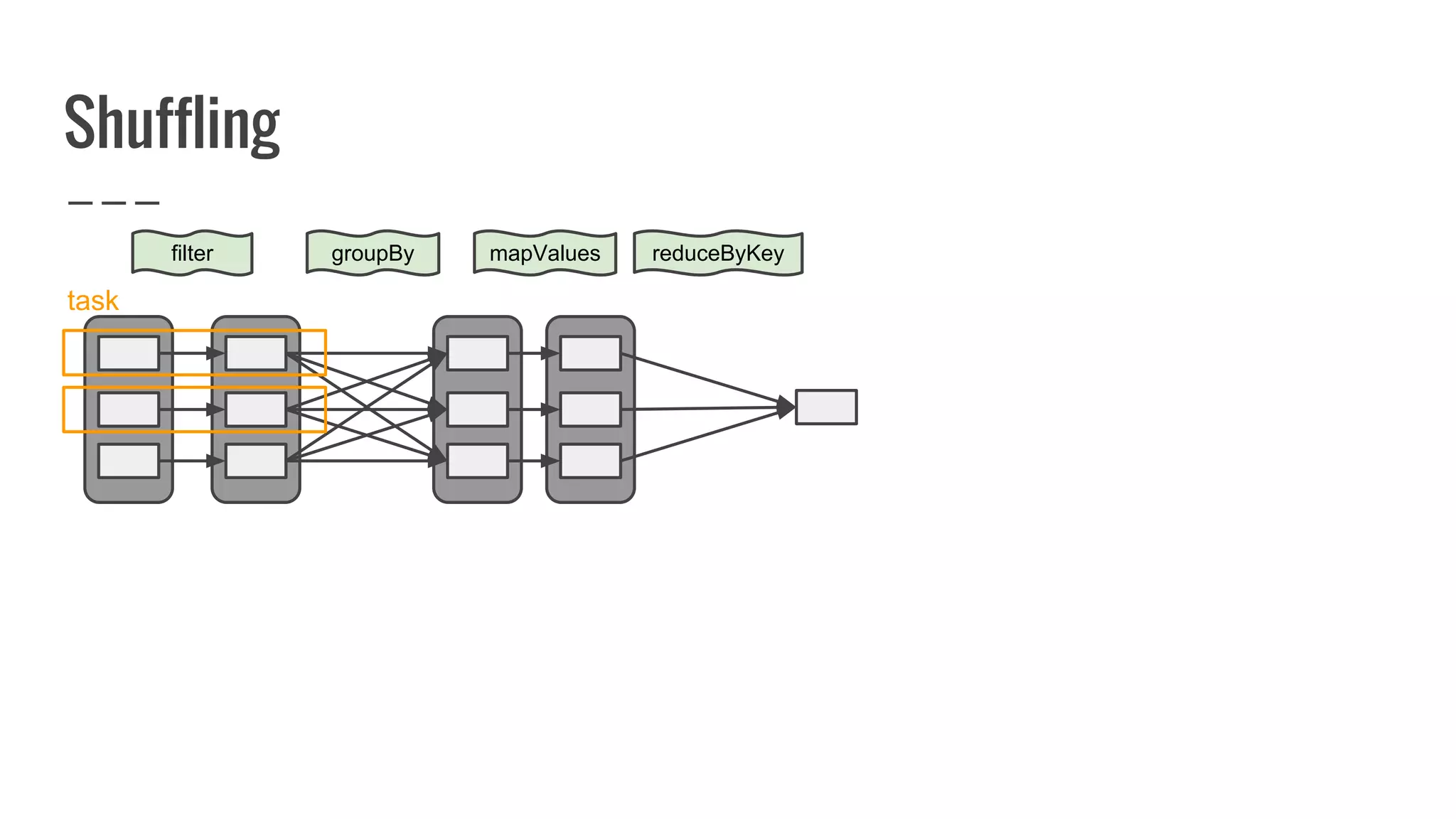










![What is a partition?
A partition represents subset of data within your
distributed collection.
override def getPartitions: Array[Partition]
= ???](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-86-2048.jpg)
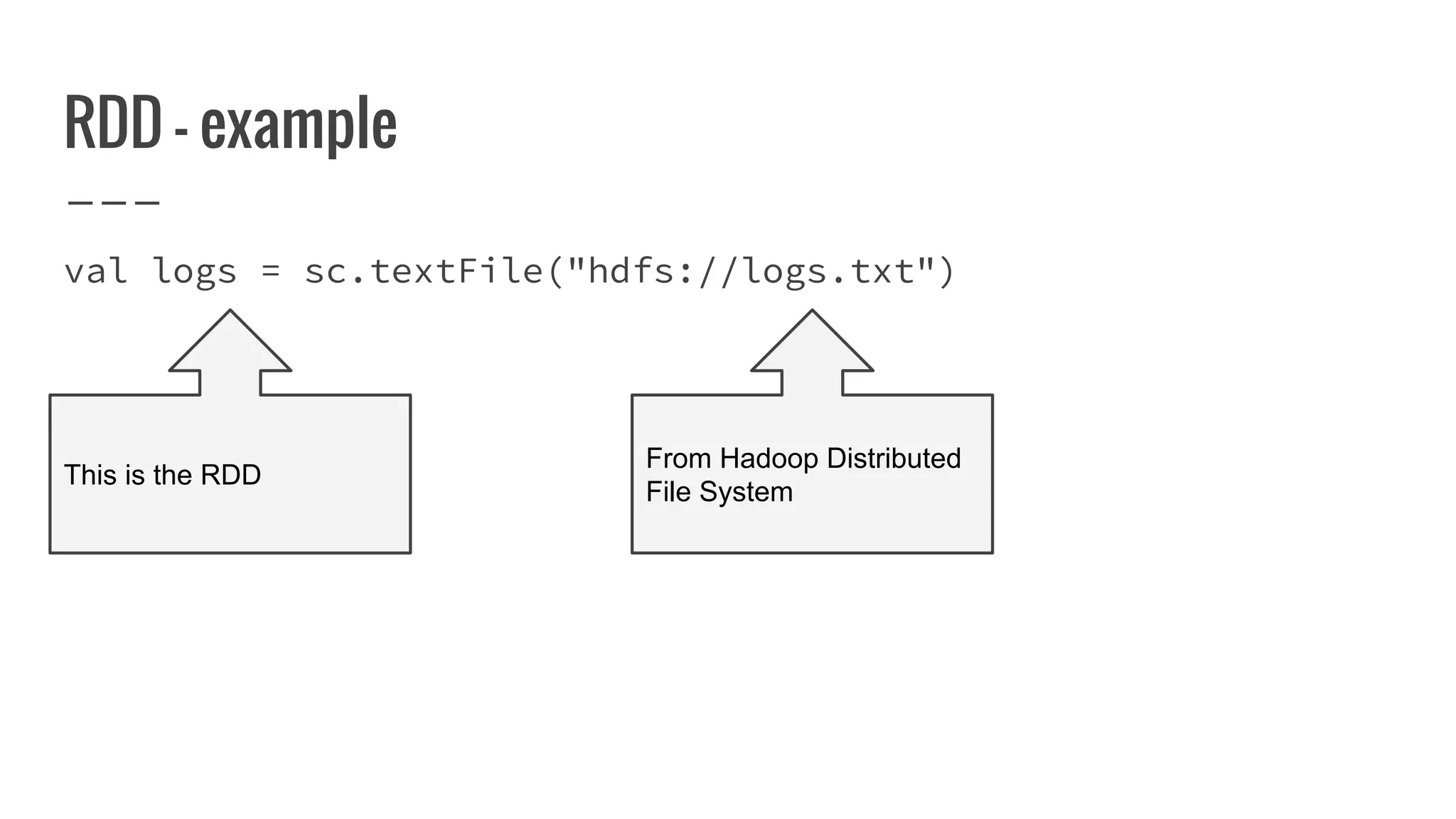
![What is a partition?
A partition represents subset of data within your
distributed collection.
override def getPartitions: Array[Partition]
= ???
How this subset is defined depends on type of the RDD](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-87-2048.jpg)




 extends RDD[(K, V)](sc, Nil) with Logging {
...
override def getPartitions: Array[Partition] = {
val jobConf = getJobConf()
SparkHadoopUtil.get.addCredentials(jobConf)
val inputFormat = getInputFormat(jobConf)
if (inputFormat.isInstanceOf[Configurable]) {
inputFormat.asInstanceOf[Configurable].setConf(jobConf)
}
val inputSplits = inputFormat.getSplits(jobConf, minPartitions)
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) { array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
}](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-97-2048.jpg)
 extends RDD[(K, V)](sc, Nil) with Logging {
...
override def getPartitions: Array[Partition] = {
val jobConf = getJobConf()
SparkHadoopUtil.get.addCredentials(jobConf)
val inputFormat = getInputFormat(jobConf)
if (inputFormat.isInstanceOf[Configurable]) {
inputFormat.asInstanceOf[Configurable].setConf(jobConf)
}
val inputSplits = inputFormat.getSplits(jobConf, minPartitions)
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) { array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
}](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-98-2048.jpg)
 extends RDD[(K, V)](sc, Nil) with Logging {
...
override def getPartitions: Array[Partition] = {
val jobConf = getJobConf()
SparkHadoopUtil.get.addCredentials(jobConf)
val inputFormat = getInputFormat(jobConf)
if (inputFormat.isInstanceOf[Configurable]) {
inputFormat.asInstanceOf[Configurable].setConf(jobConf)
}
val inputSplits = inputFormat.getSplits(jobConf, minPartitions)
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) { array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
}](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-99-2048.jpg)



 extends RDD[U](prev) {
...
override def getPartitions: Array[Partition] = firstParent[T].partitions](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-103-2048.jpg)






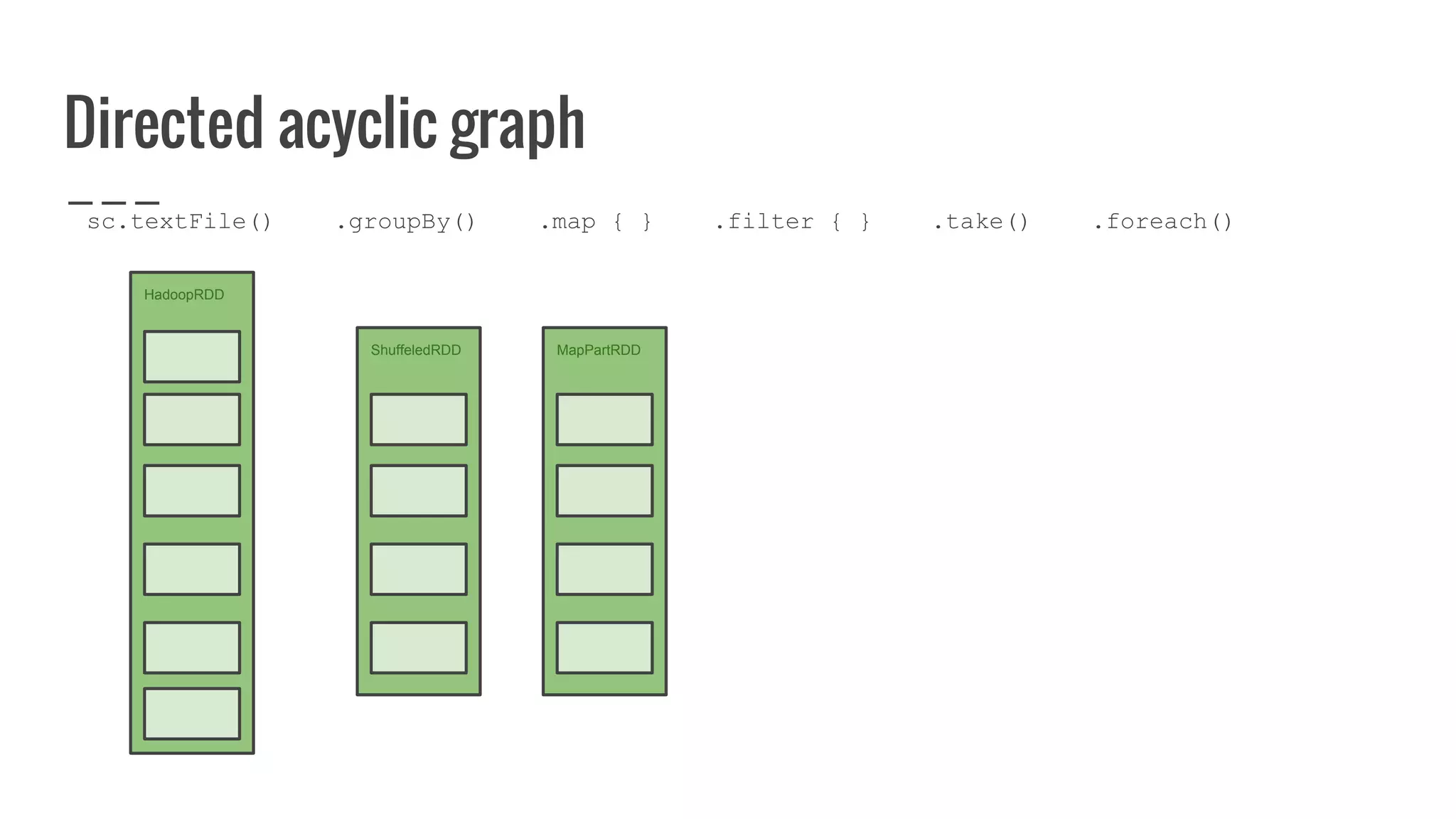
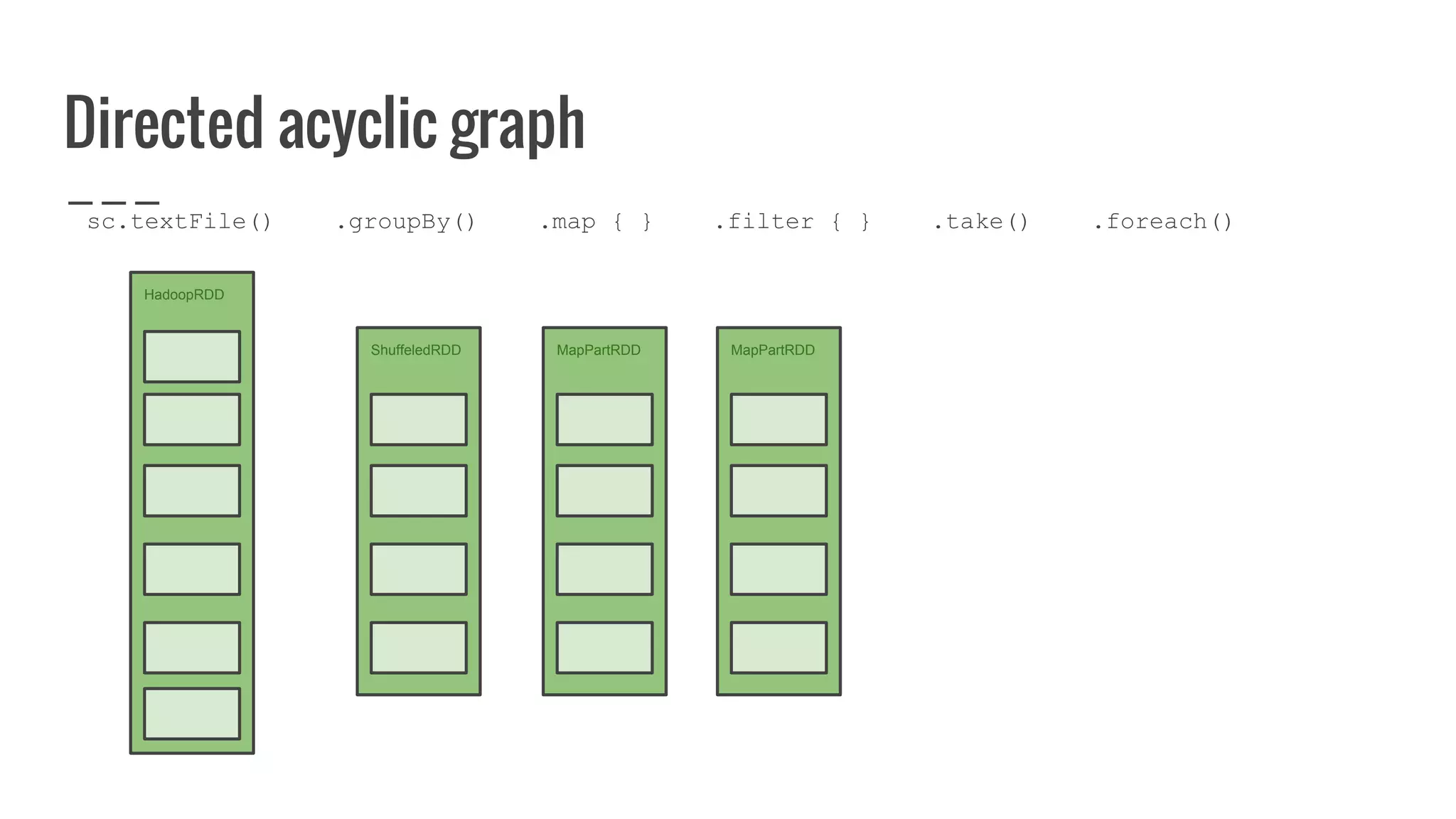
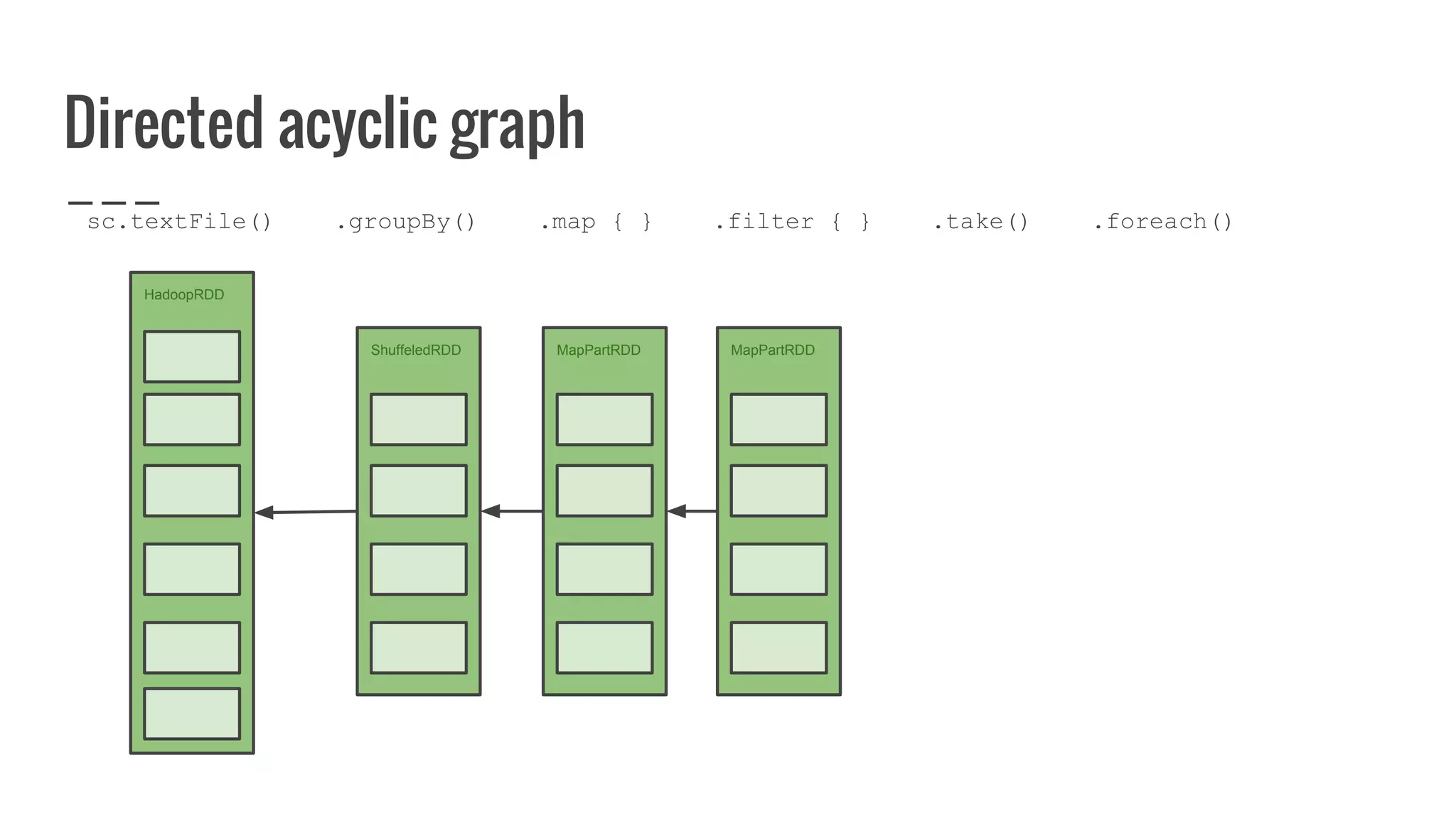
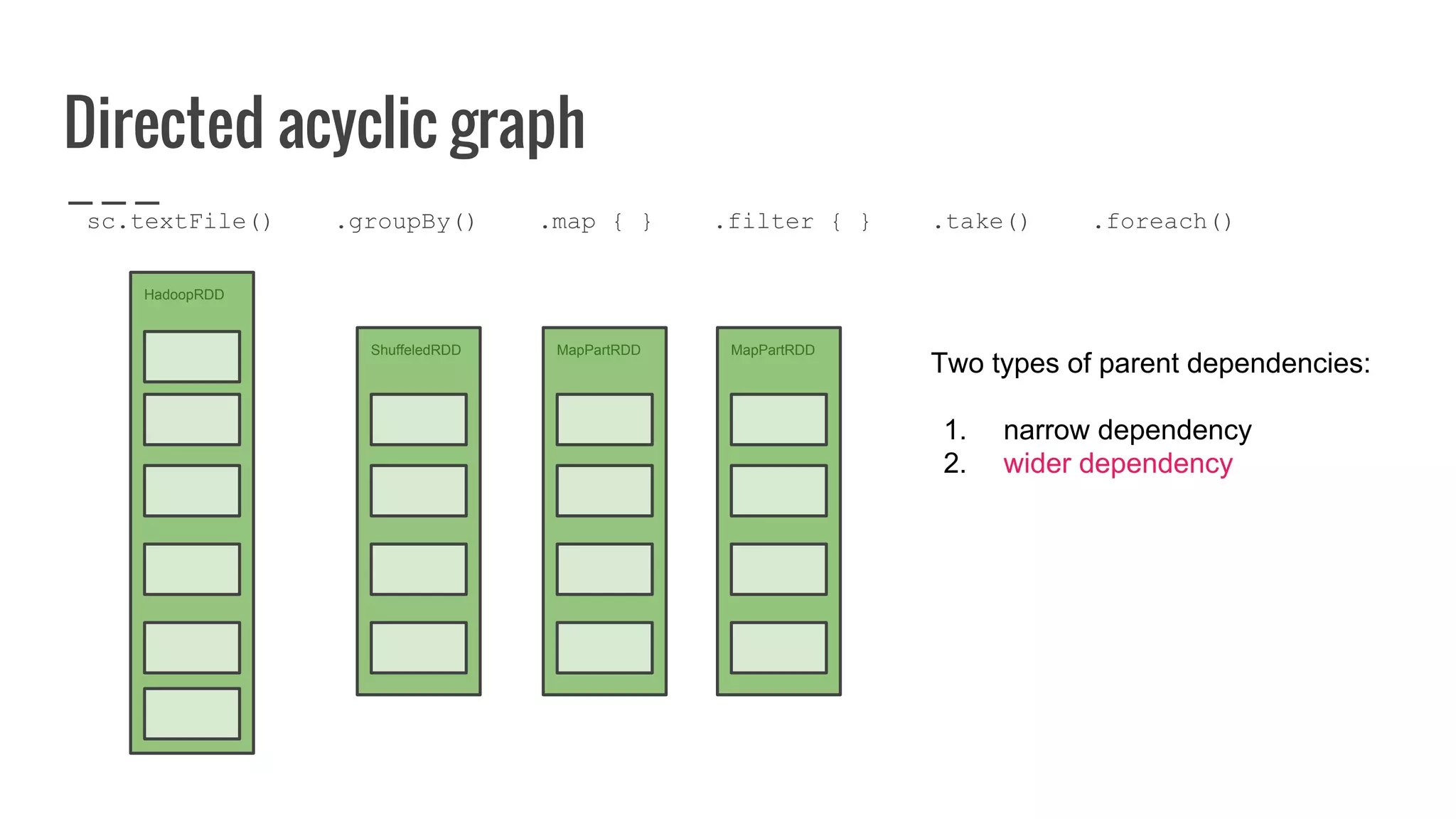
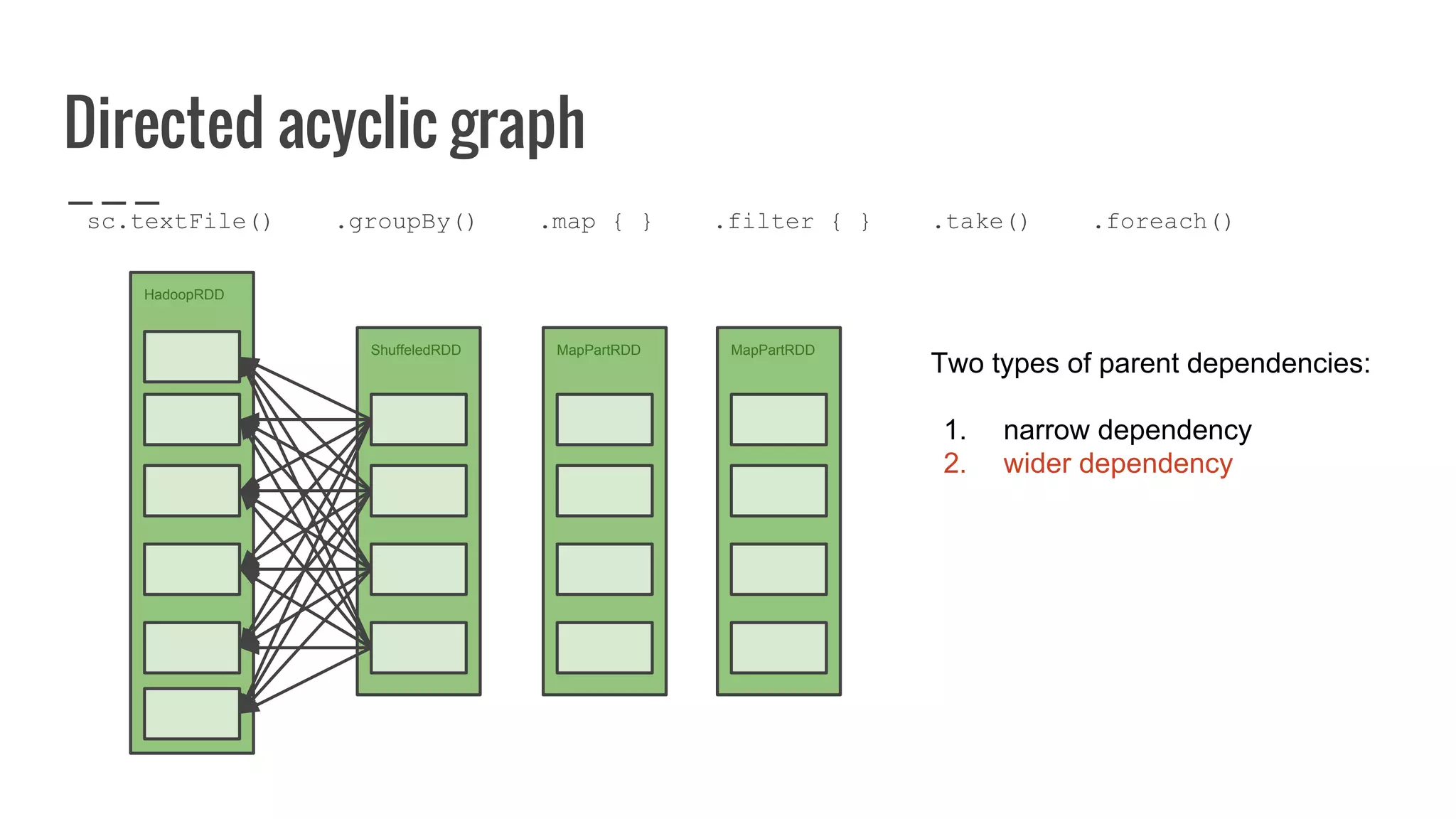
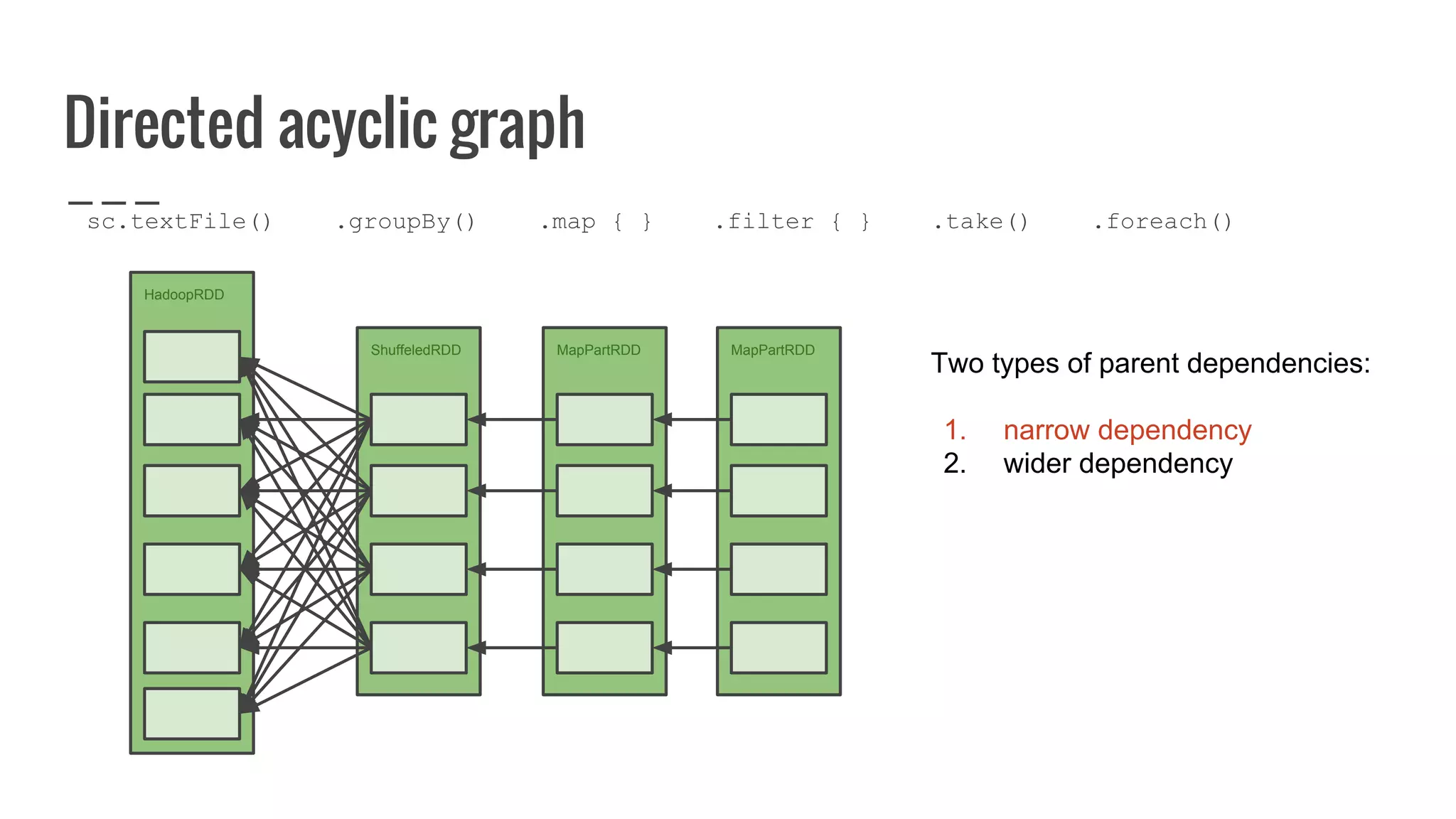
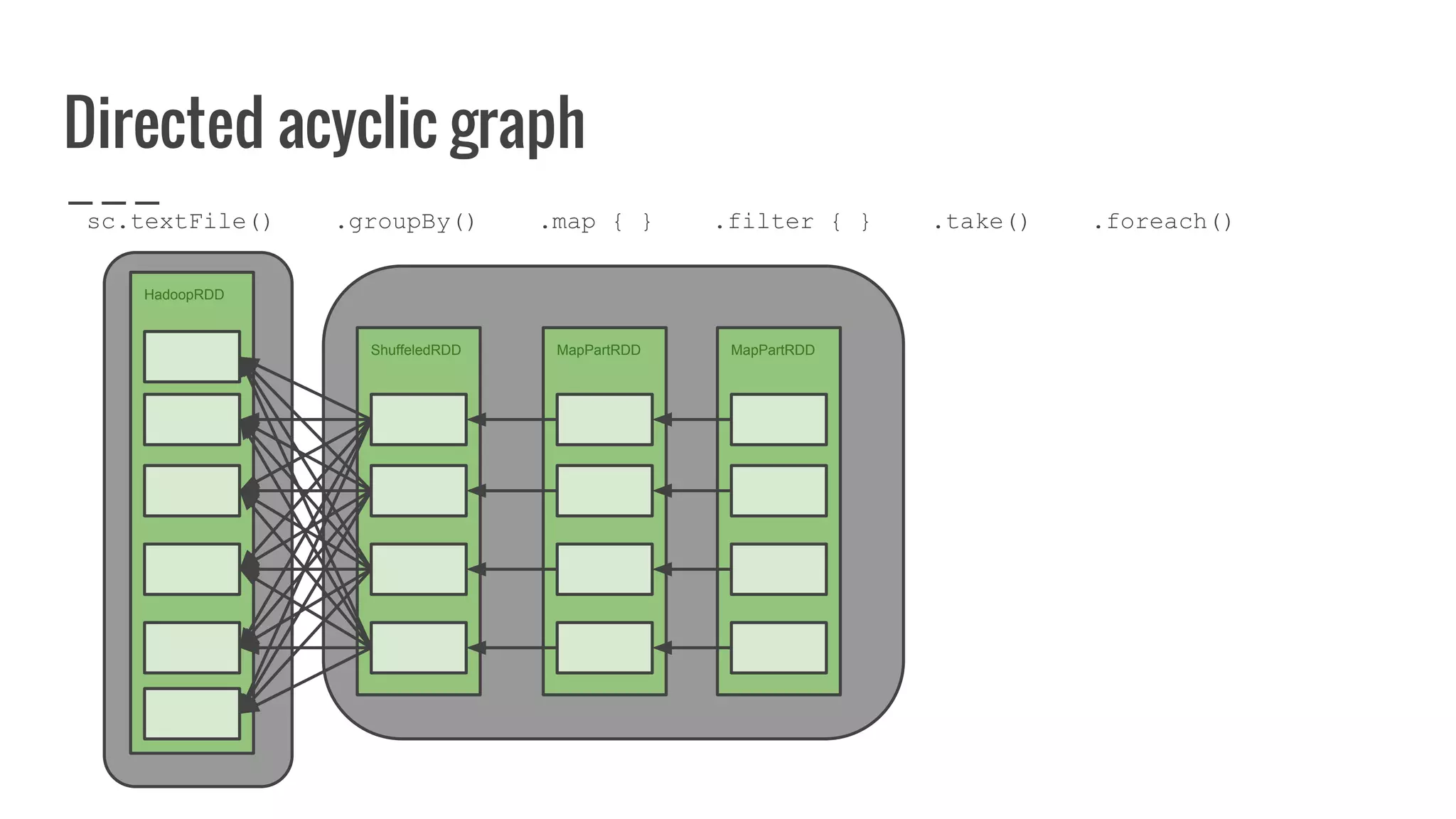
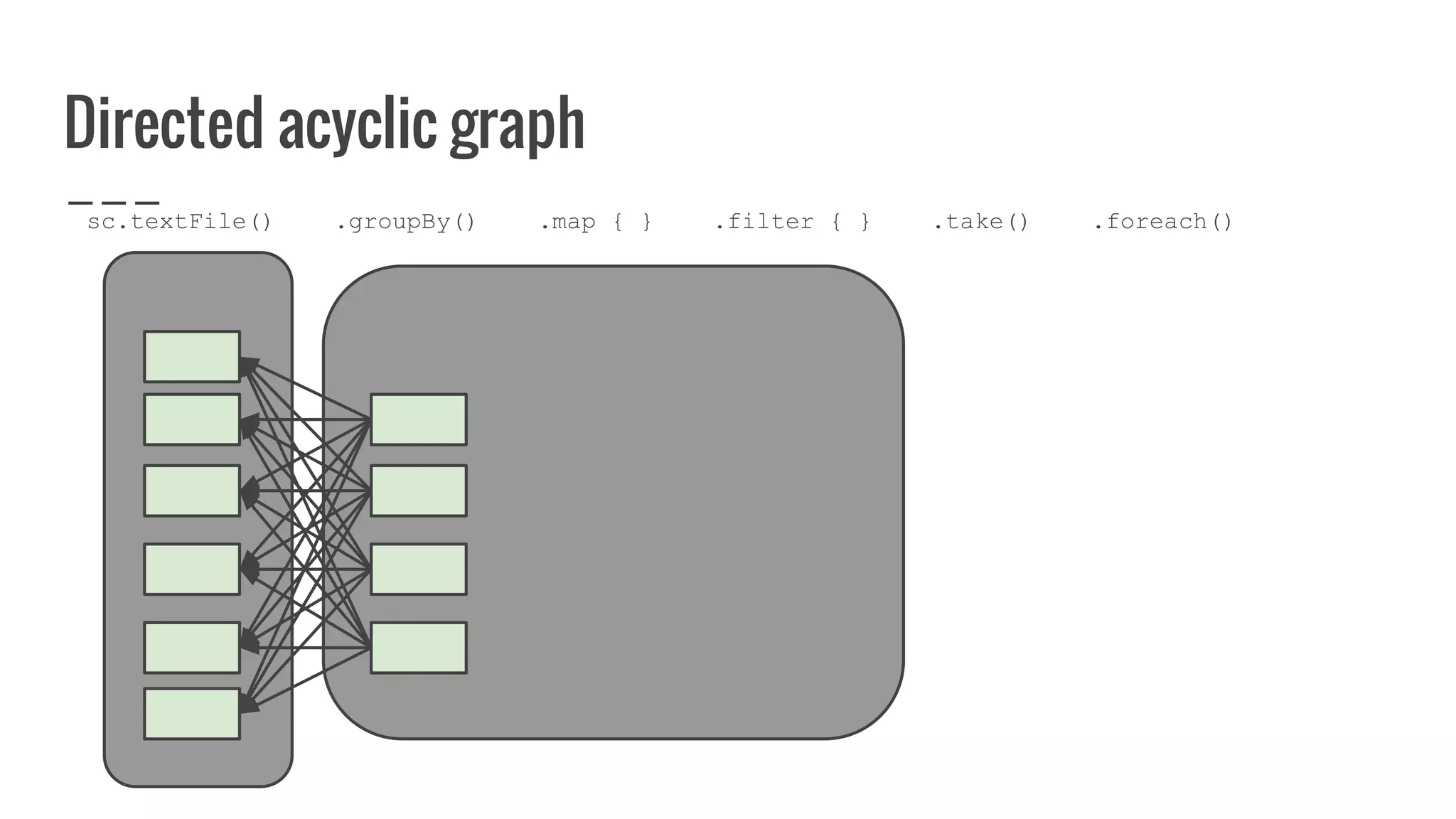
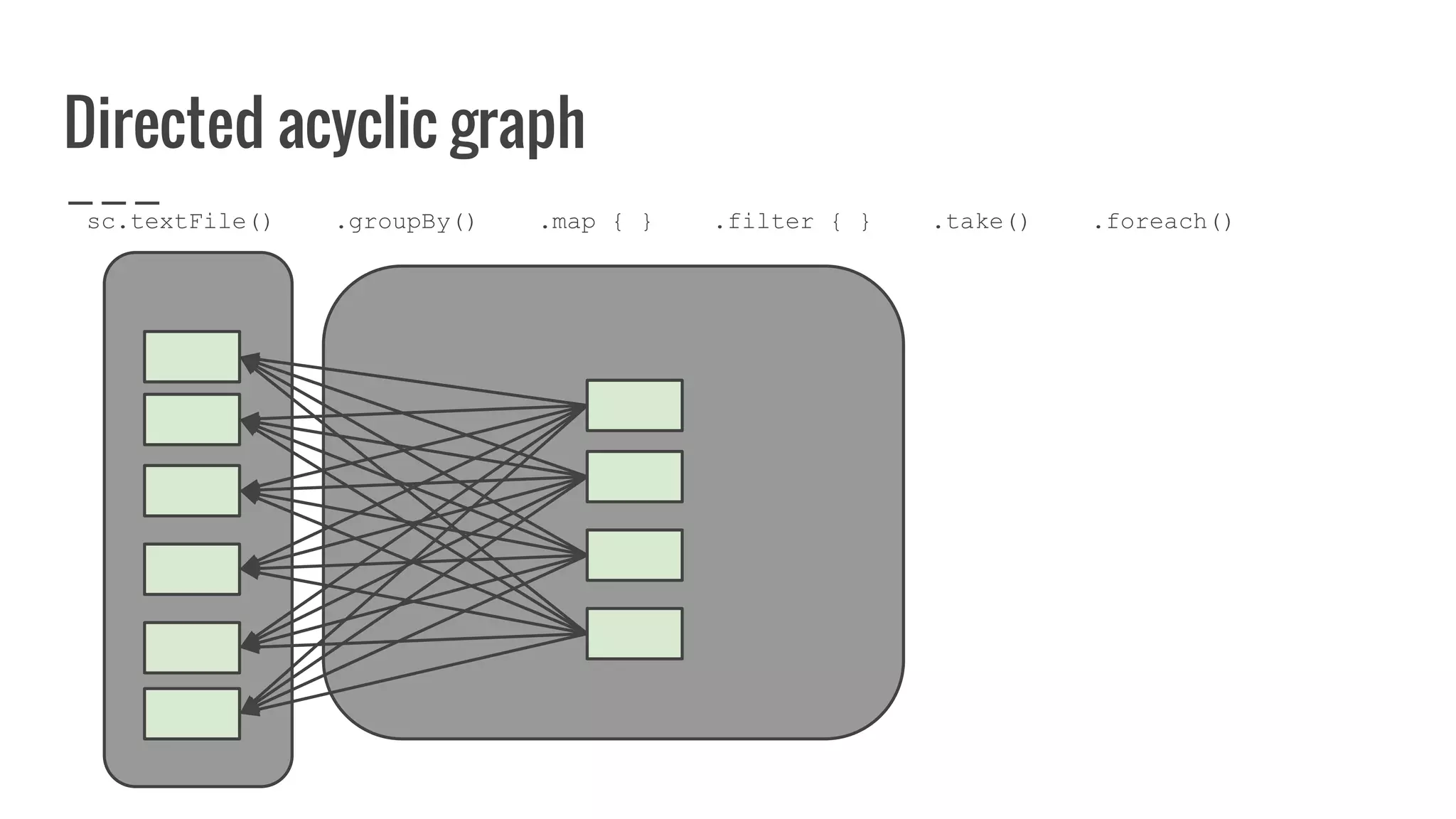
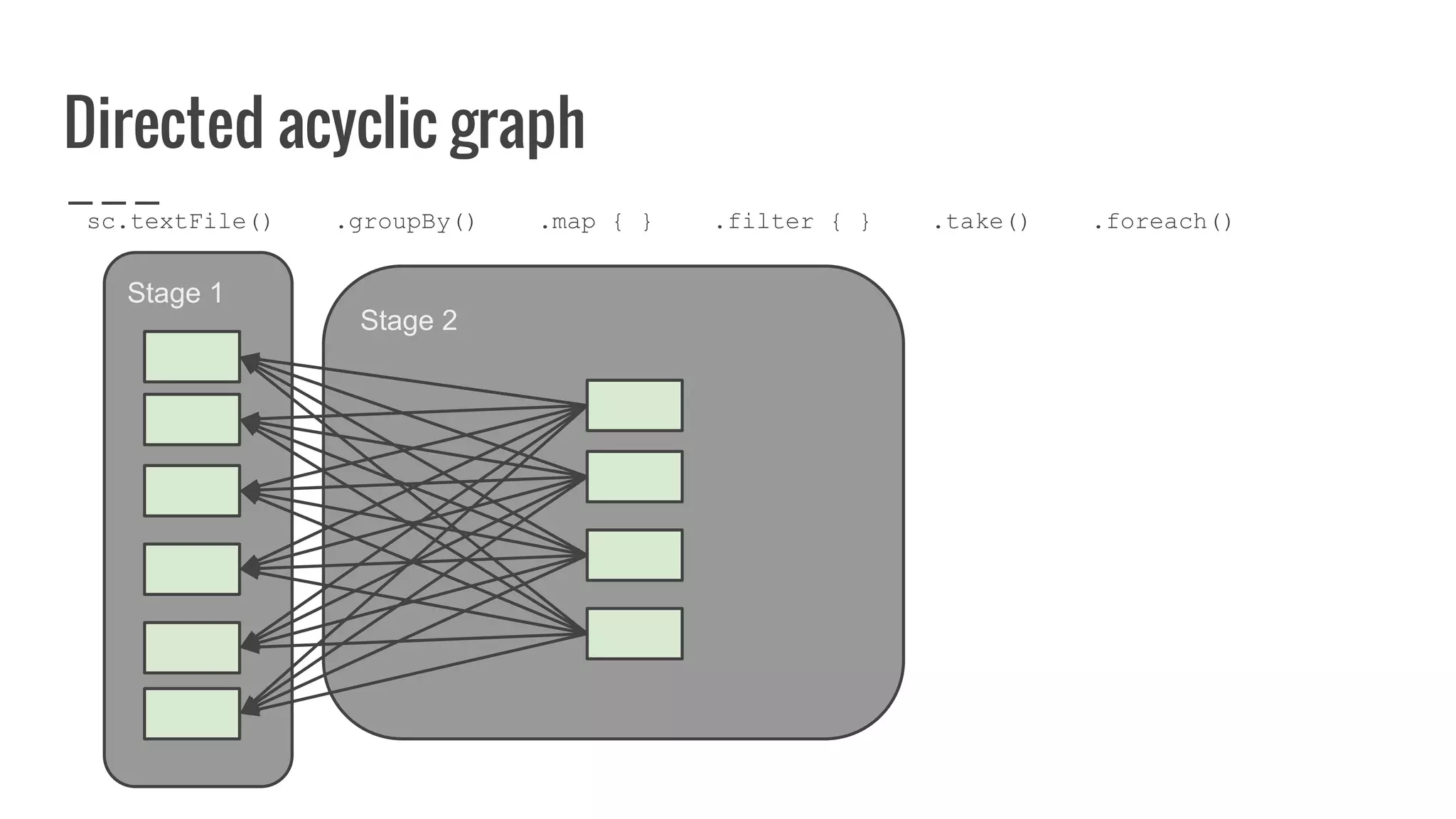


: Array[U]](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-128-2048.jpg)
: Array[U]](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-129-2048.jpg)
: Array[U]](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-130-2048.jpg)
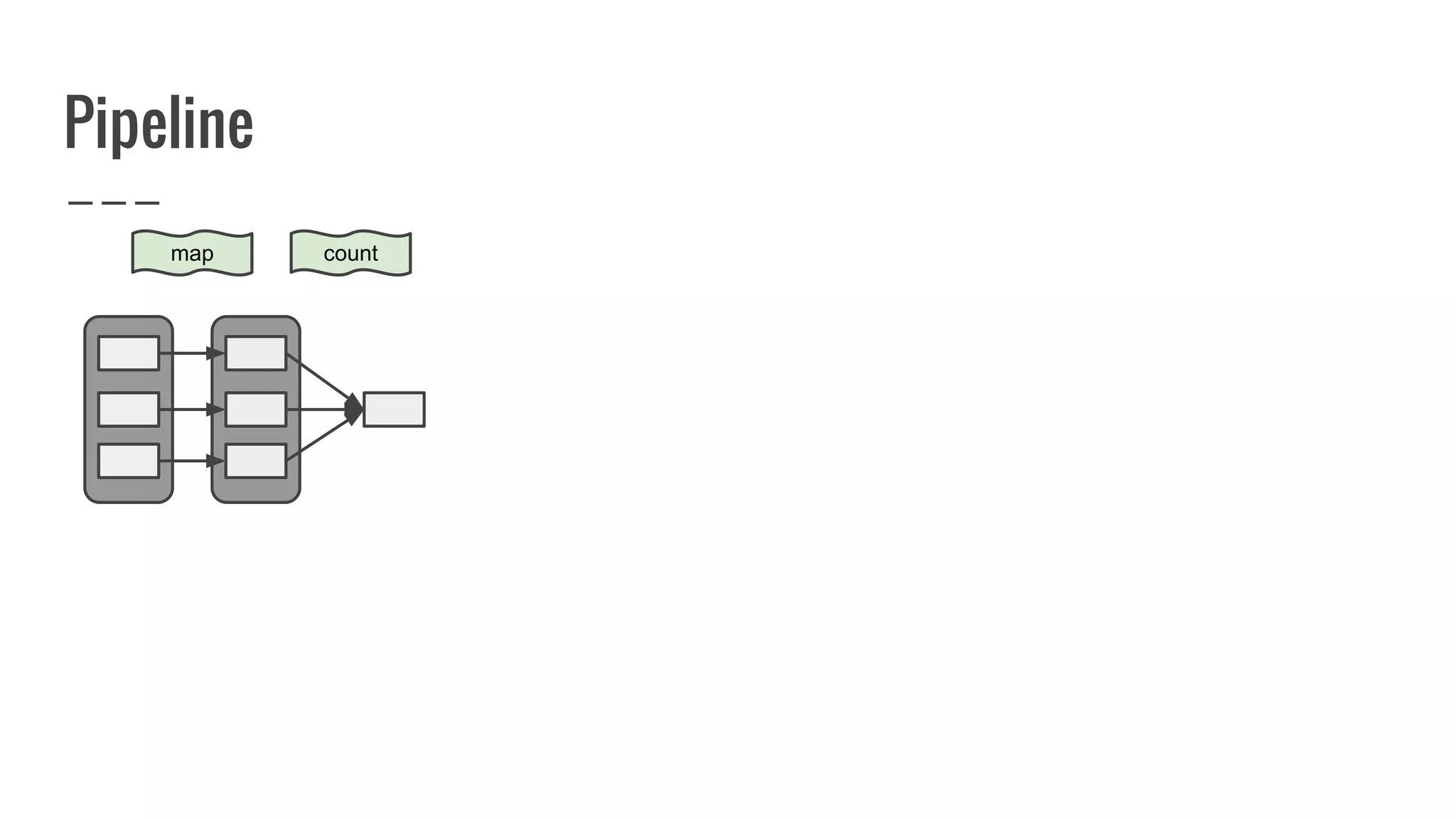
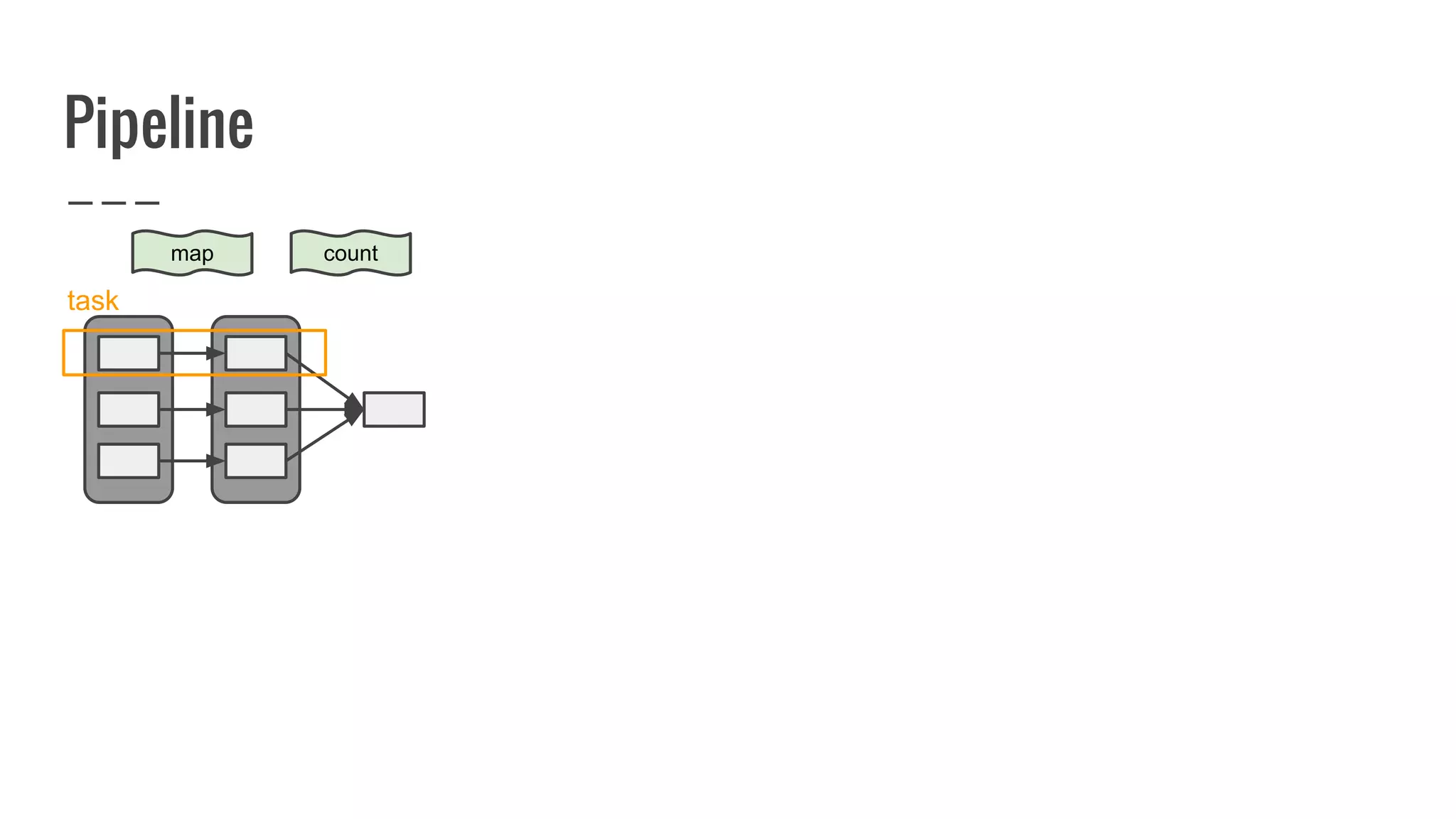
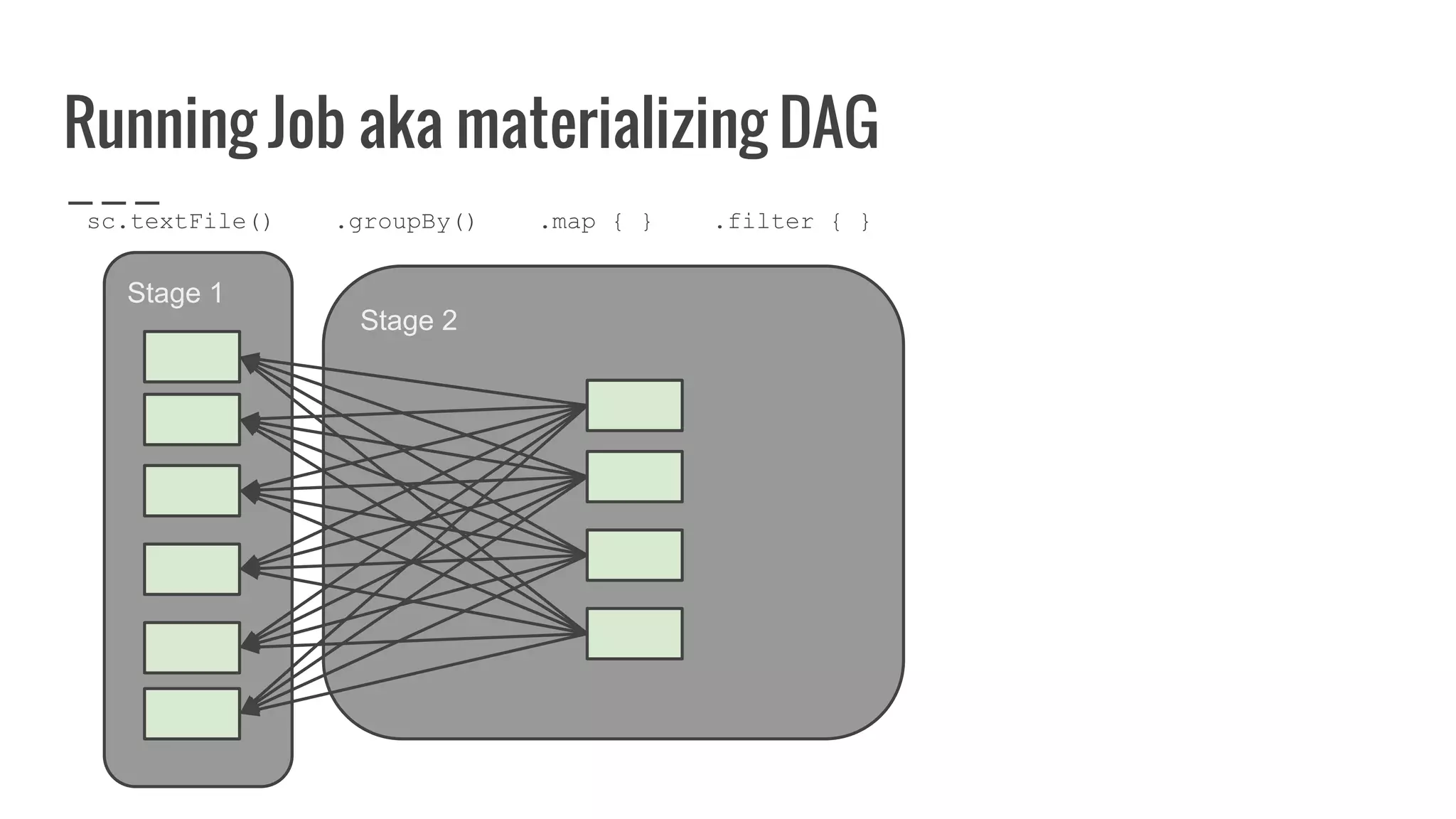
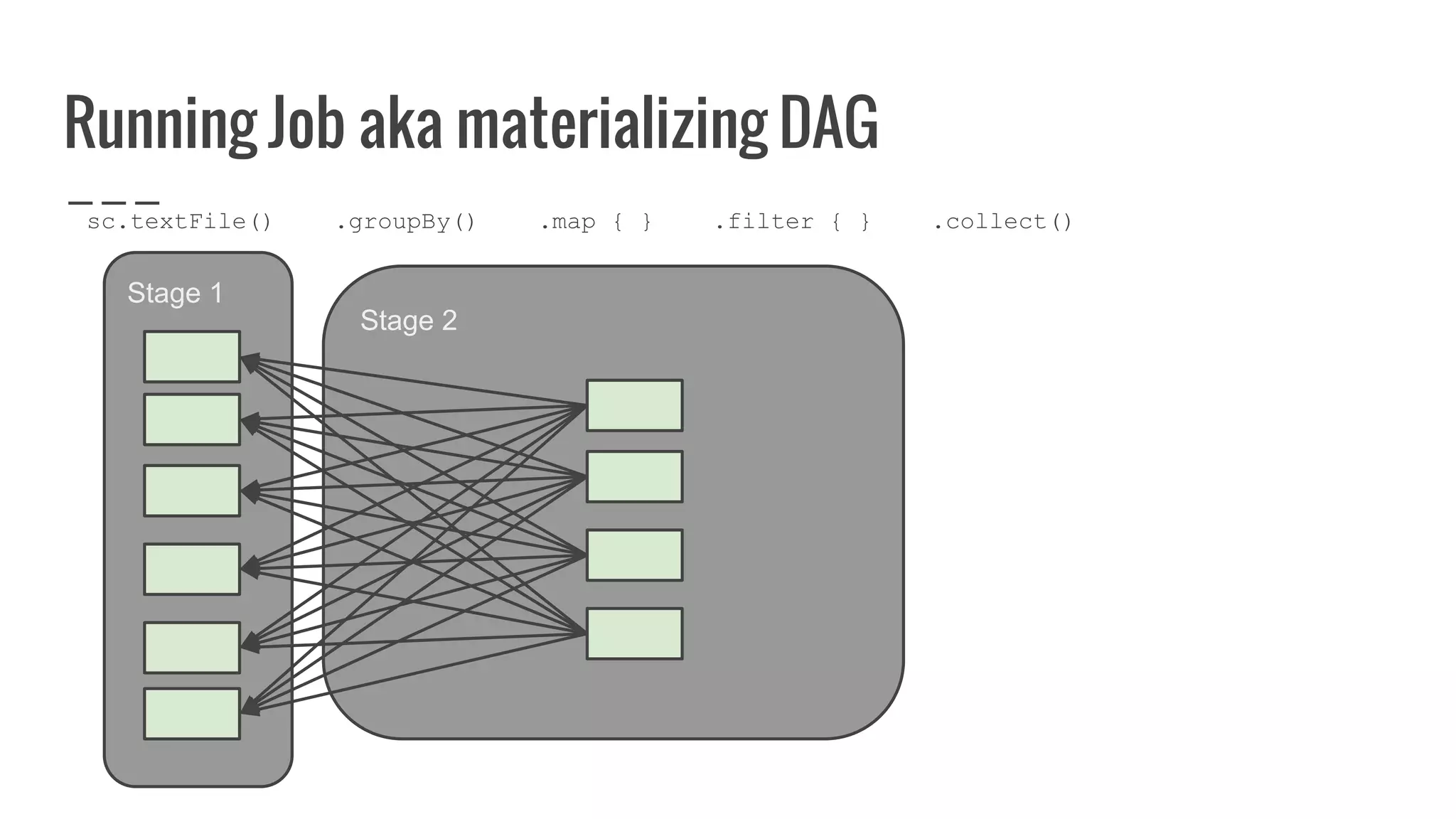
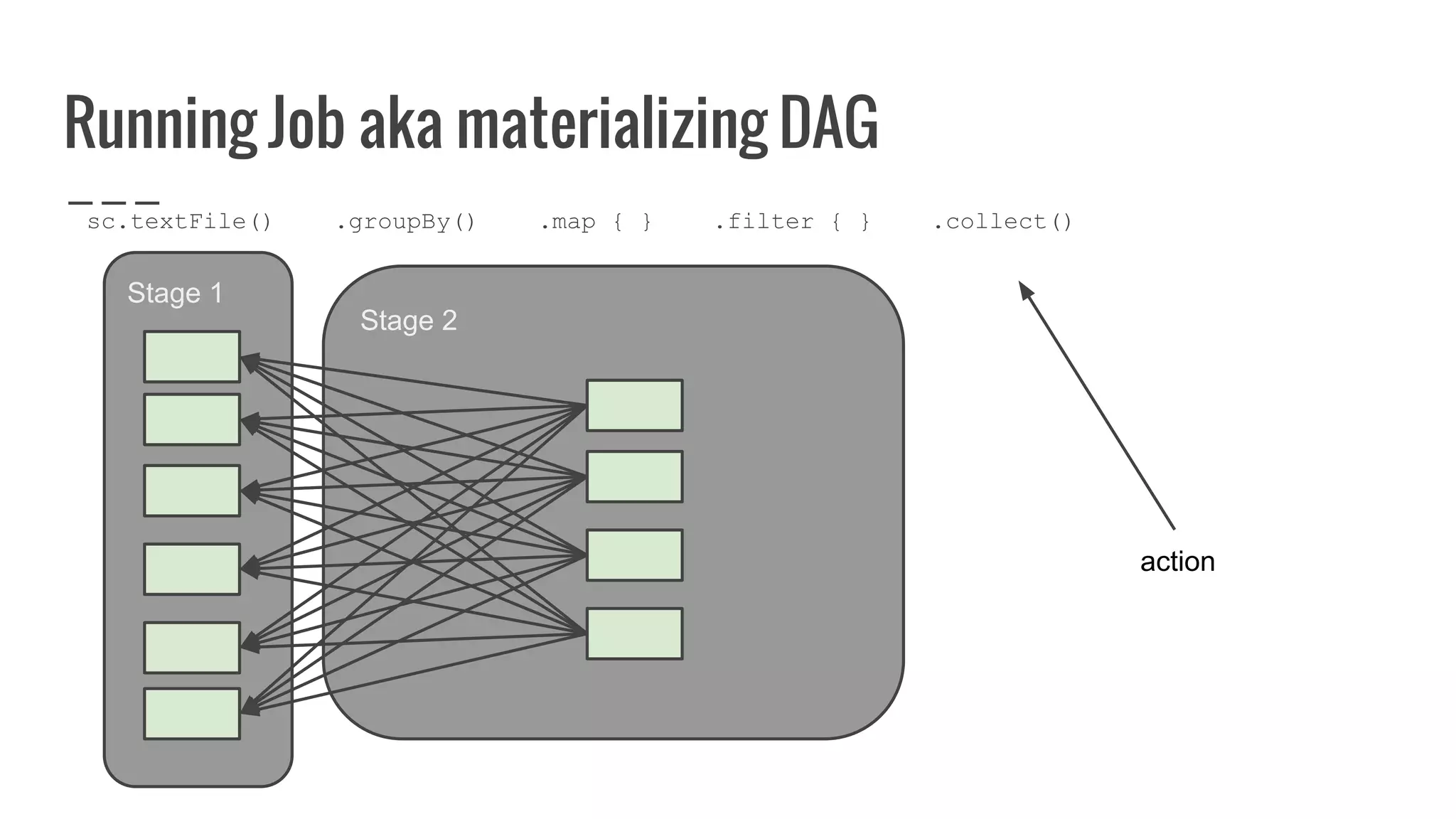
![Running Job aka materializing DAG
/**
* Return an array that contains all of the elements in this RDD.
*/
def collect(): Array[T] = {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-131-2048.jpg)

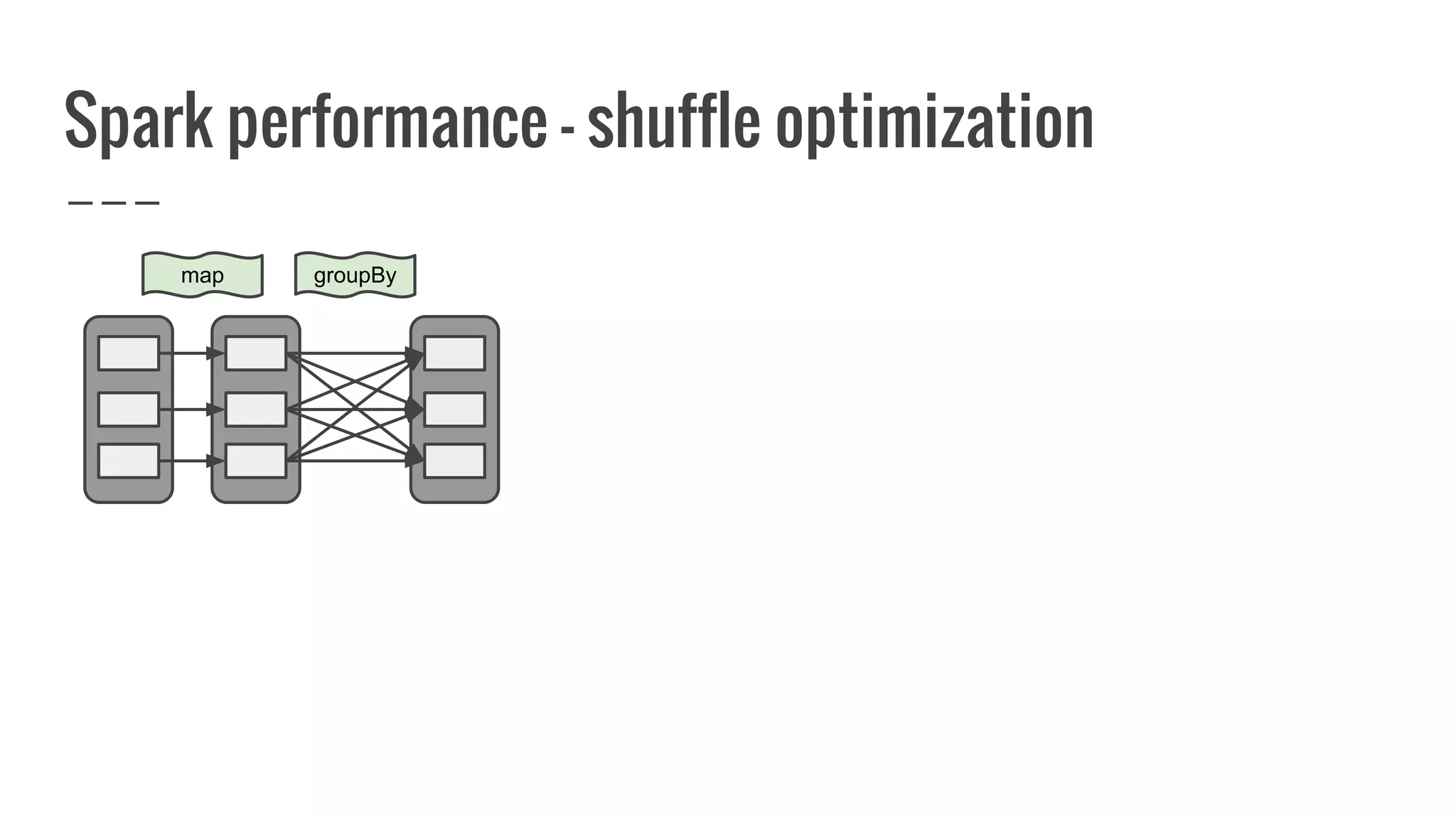
![Multiple jobs for single action
/**
* Take the first num elements of the RDD. It works by first scanning one partition, and use the
results from that partition to estimate the number of additional partitions needed to satisfy the
limit.
*/
def take(num: Int): Array[T] = {
while (buf.size < num && partsScanned < totalParts) {
(….)
val left = num - buf.size
val res = sc.runJob(this, (it: Iterator[T]) => it.take(left).toArray, p, allowLocal = true)
(….)
res.foreach(buf ++= _.take(num - buf.size))
partsScanned += numPartsToTry
(….)
}
buf.toArray
}](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-133-2048.jpg)
: Array[U]](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-134-2048.jpg)
: Array[U]](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-135-2048.jpg)
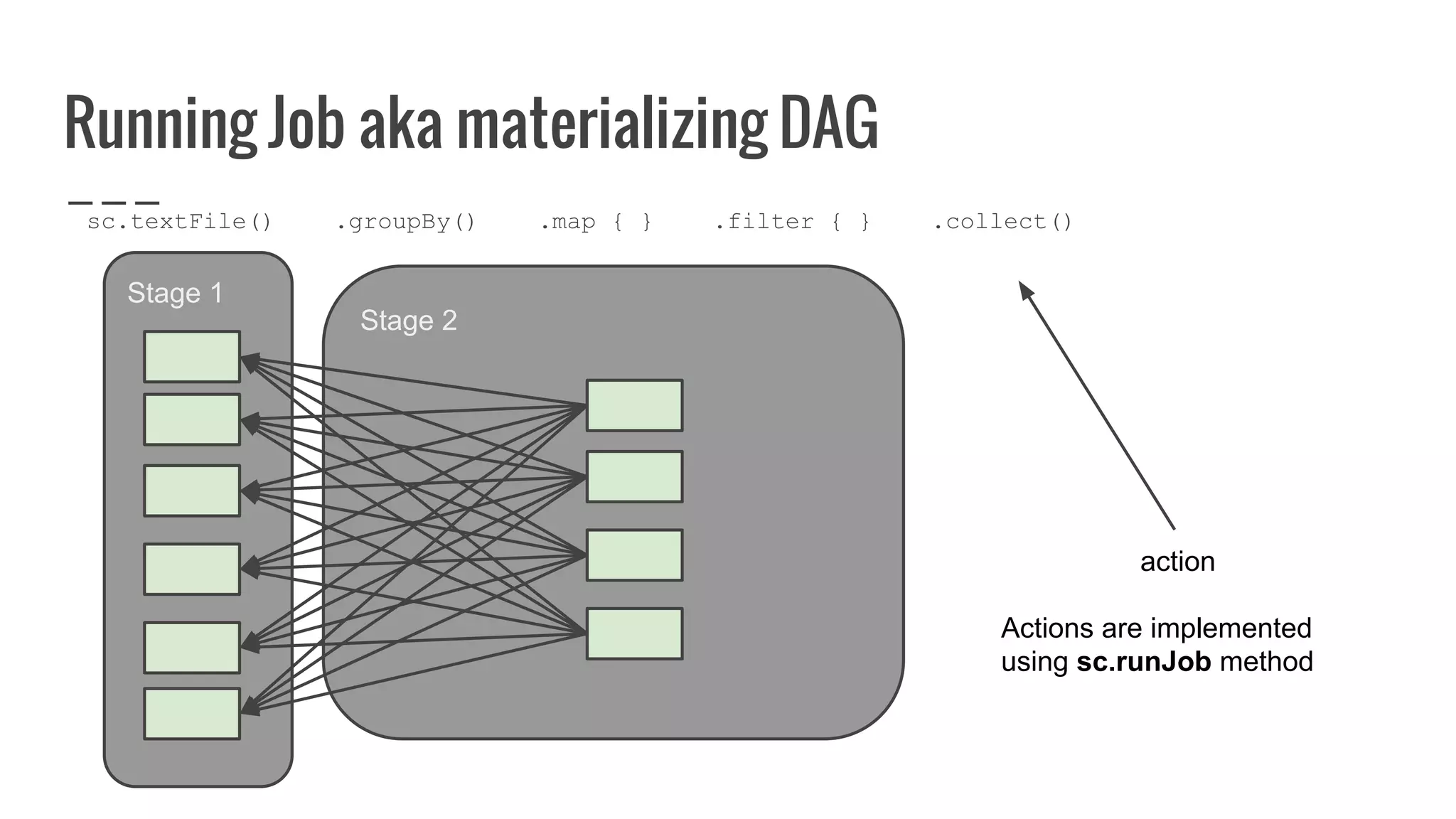
![Running Job aka materializing DAG
/**
* :: DeveloperApi ::
* Implemented by subclasses to compute a given partition.
*/
@DeveloperApi
def compute(split: Partition, context: TaskContext): Iterator[T]](https://image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-136-2048.jpg)
















































































































![What is a partition?
A partition represents subset of data within your
distributed collection.
override def getPartitions: Array[Partition]
= ???](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-86-2048.jpg)
![What is a partition?
A partition represents subset of data within your
distributed collection.
override def getPartitions: Array[Partition]
= ???
How this subset is defined depends on type of the RDD](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-87-2048.jpg)









 extends RDD[(K, V)](sc, Nil) with Logging {
...
override def getPartitions: Array[Partition] = {
val jobConf = getJobConf()
SparkHadoopUtil.get.addCredentials(jobConf)
val inputFormat = getInputFormat(jobConf)
if (inputFormat.isInstanceOf[Configurable]) {
inputFormat.asInstanceOf[Configurable].setConf(jobConf)
}
val inputSplits = inputFormat.getSplits(jobConf, minPartitions)
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) { array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
}](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-97-2048.jpg)
 extends RDD[(K, V)](sc, Nil) with Logging {
...
override def getPartitions: Array[Partition] = {
val jobConf = getJobConf()
SparkHadoopUtil.get.addCredentials(jobConf)
val inputFormat = getInputFormat(jobConf)
if (inputFormat.isInstanceOf[Configurable]) {
inputFormat.asInstanceOf[Configurable].setConf(jobConf)
}
val inputSplits = inputFormat.getSplits(jobConf, minPartitions)
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) { array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
}](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-98-2048.jpg)
 extends RDD[(K, V)](sc, Nil) with Logging {
...
override def getPartitions: Array[Partition] = {
val jobConf = getJobConf()
SparkHadoopUtil.get.addCredentials(jobConf)
val inputFormat = getInputFormat(jobConf)
if (inputFormat.isInstanceOf[Configurable]) {
inputFormat.asInstanceOf[Configurable].setConf(jobConf)
}
val inputSplits = inputFormat.getSplits(jobConf, minPartitions)
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) { array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
}](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-99-2048.jpg)



 extends RDD[U](prev) {
...
override def getPartitions: Array[Partition] = firstParent[T].partitions](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-103-2048.jpg)
























: Array[U]](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-128-2048.jpg)
: Array[U]](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-129-2048.jpg)
: Array[U]](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-130-2048.jpg)
![Running Job aka materializing DAG
/**
* Return an array that contains all of the elements in this RDD.
*/
def collect(): Array[T] = {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-131-2048.jpg)

![Multiple jobs for single action
/**
* Take the first num elements of the RDD. It works by first scanning one partition, and use the
results from that partition to estimate the number of additional partitions needed to satisfy the
limit.
*/
def take(num: Int): Array[T] = {
while (buf.size < num && partsScanned < totalParts) {
(….)
val left = num - buf.size
val res = sc.runJob(this, (it: Iterator[T]) => it.take(left).toArray, p, allowLocal = true)
(….)
res.foreach(buf ++= _.take(num - buf.size))
partsScanned += numPartsToTry
(….)
}
buf.toArray
}](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-133-2048.jpg)
: Array[U]](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-134-2048.jpg)
: Array[U]](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-135-2048.jpg)
![Running Job aka materializing DAG
/**
* :: DeveloperApi ::
* Implemented by subclasses to compute a given partition.
*/
@DeveloperApi
def compute(split: Partition, context: TaskContext): Iterator[T]](https://crownmelresort.com/image.slidesharecdn.com/writingyourownrddforfunandprofit1-161006181032/75/Writing-your-own-RDD-for-fun-and-profit-136-2048.jpg)












































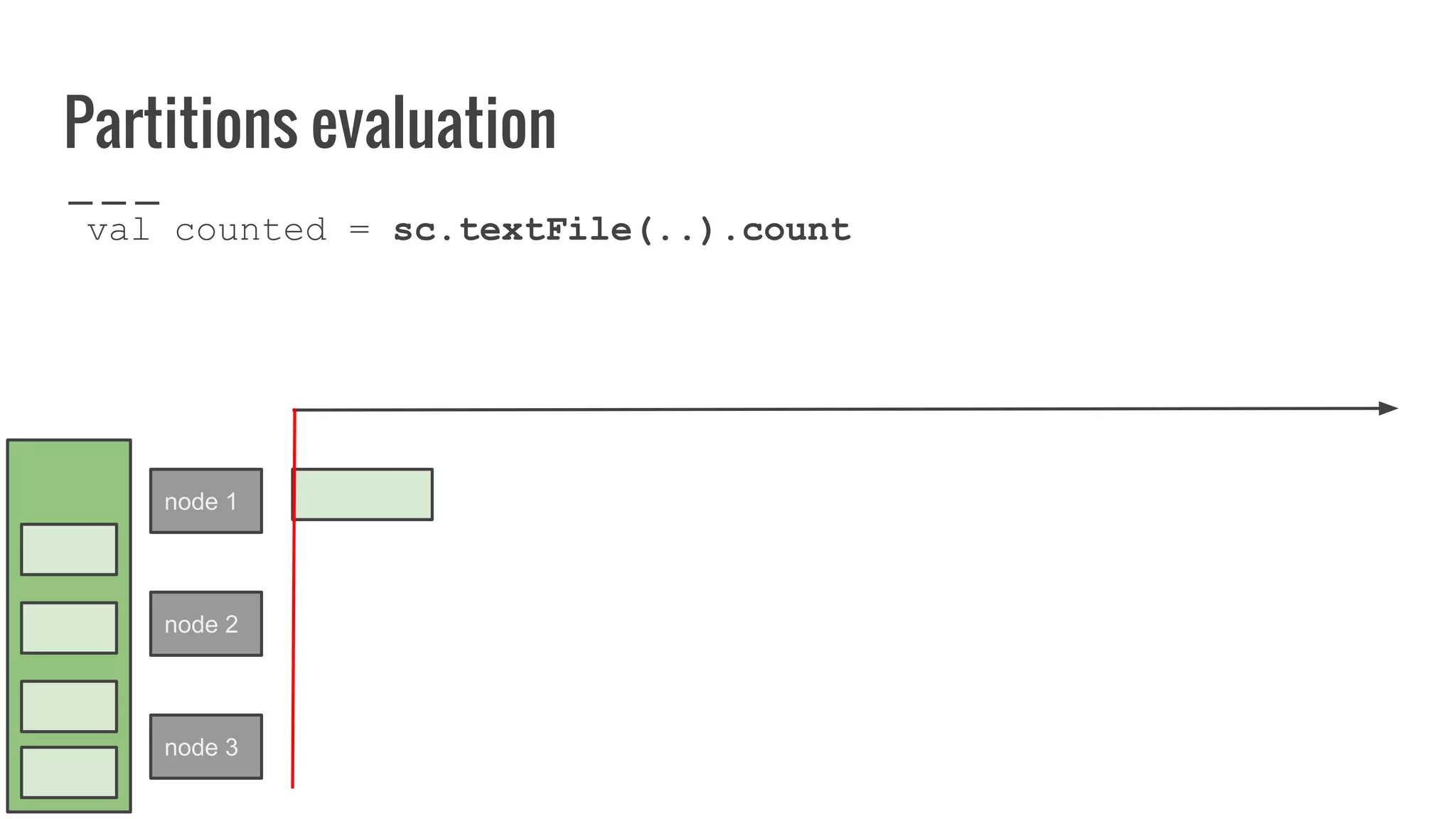
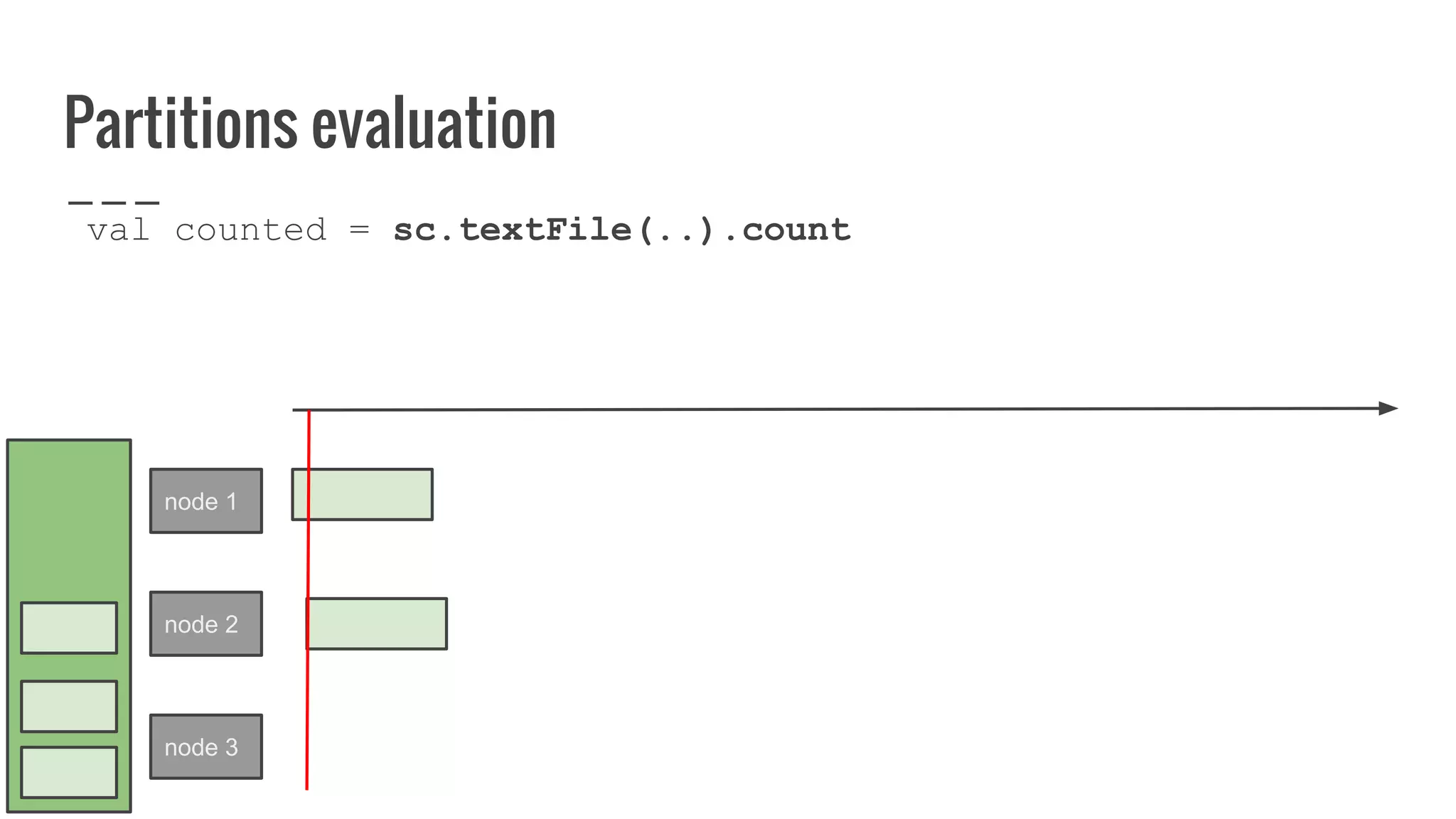
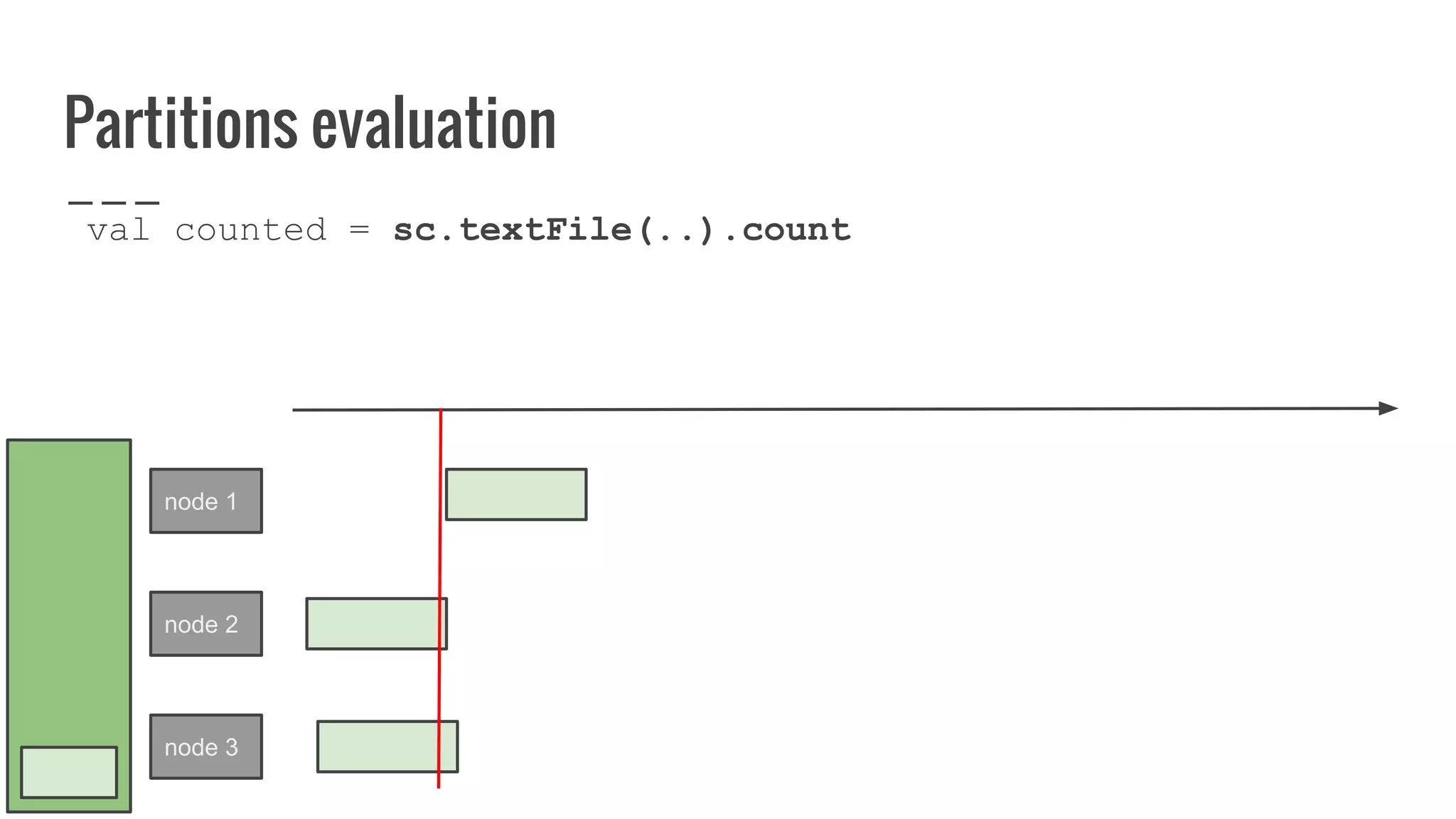
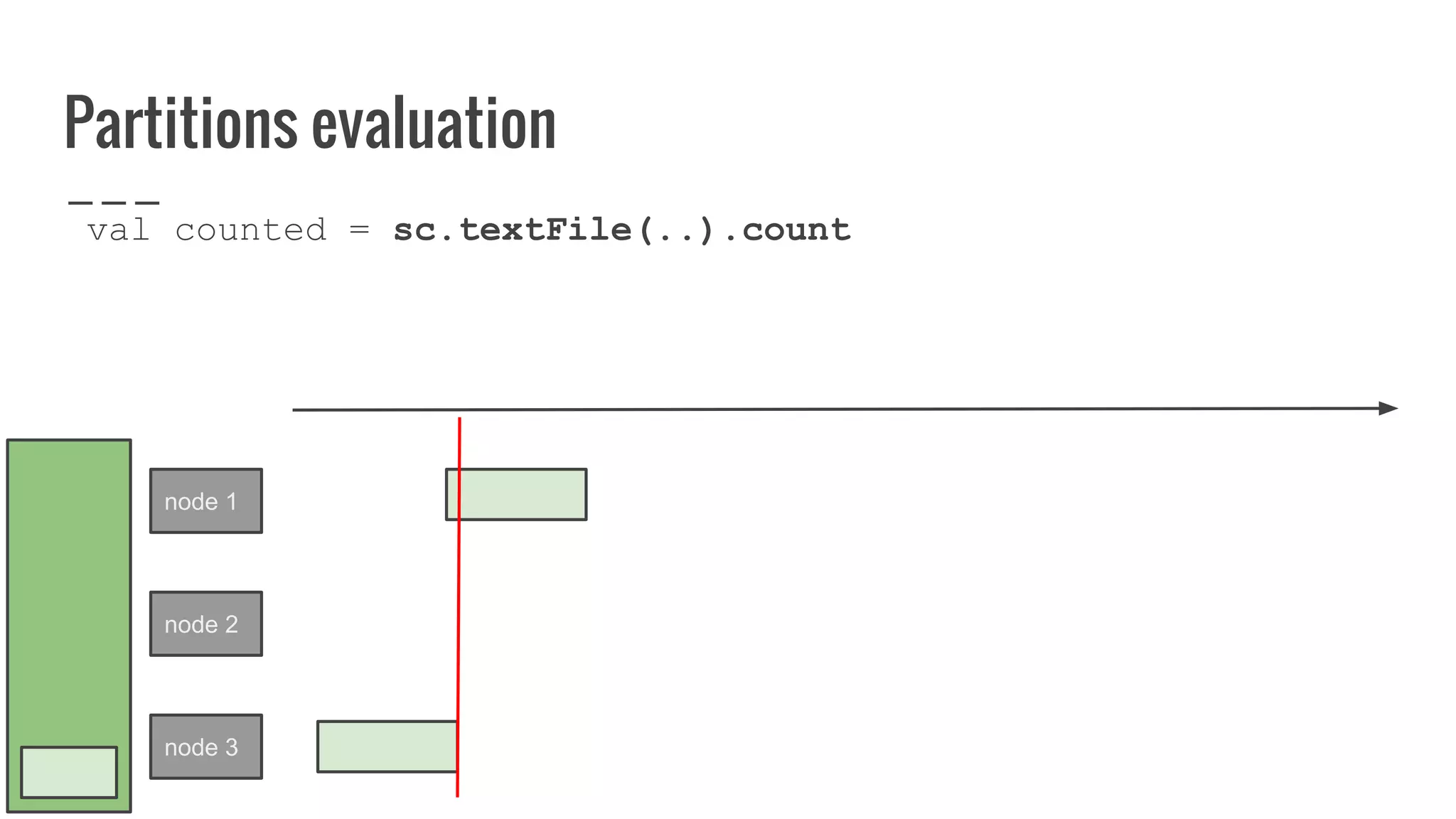
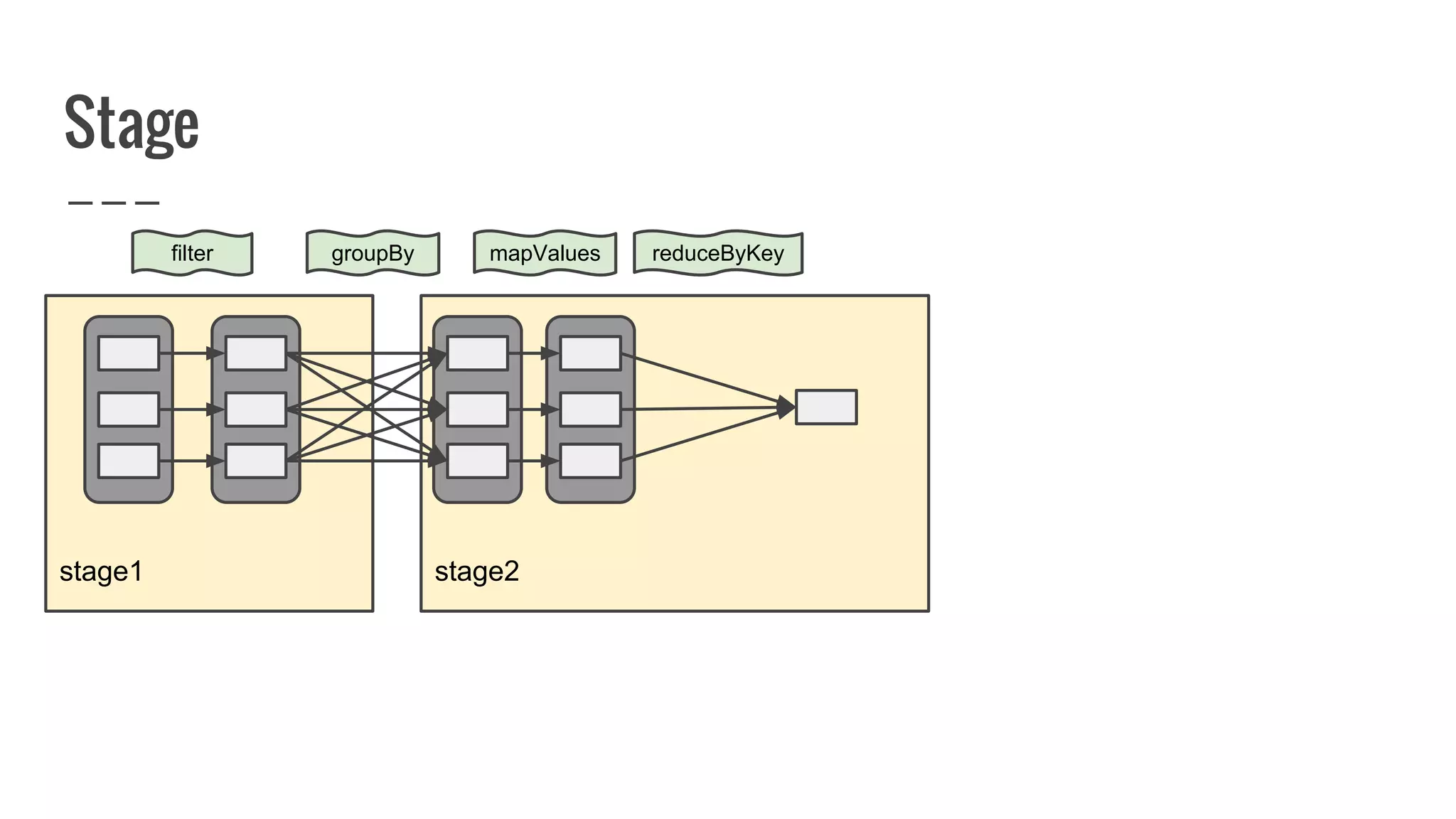
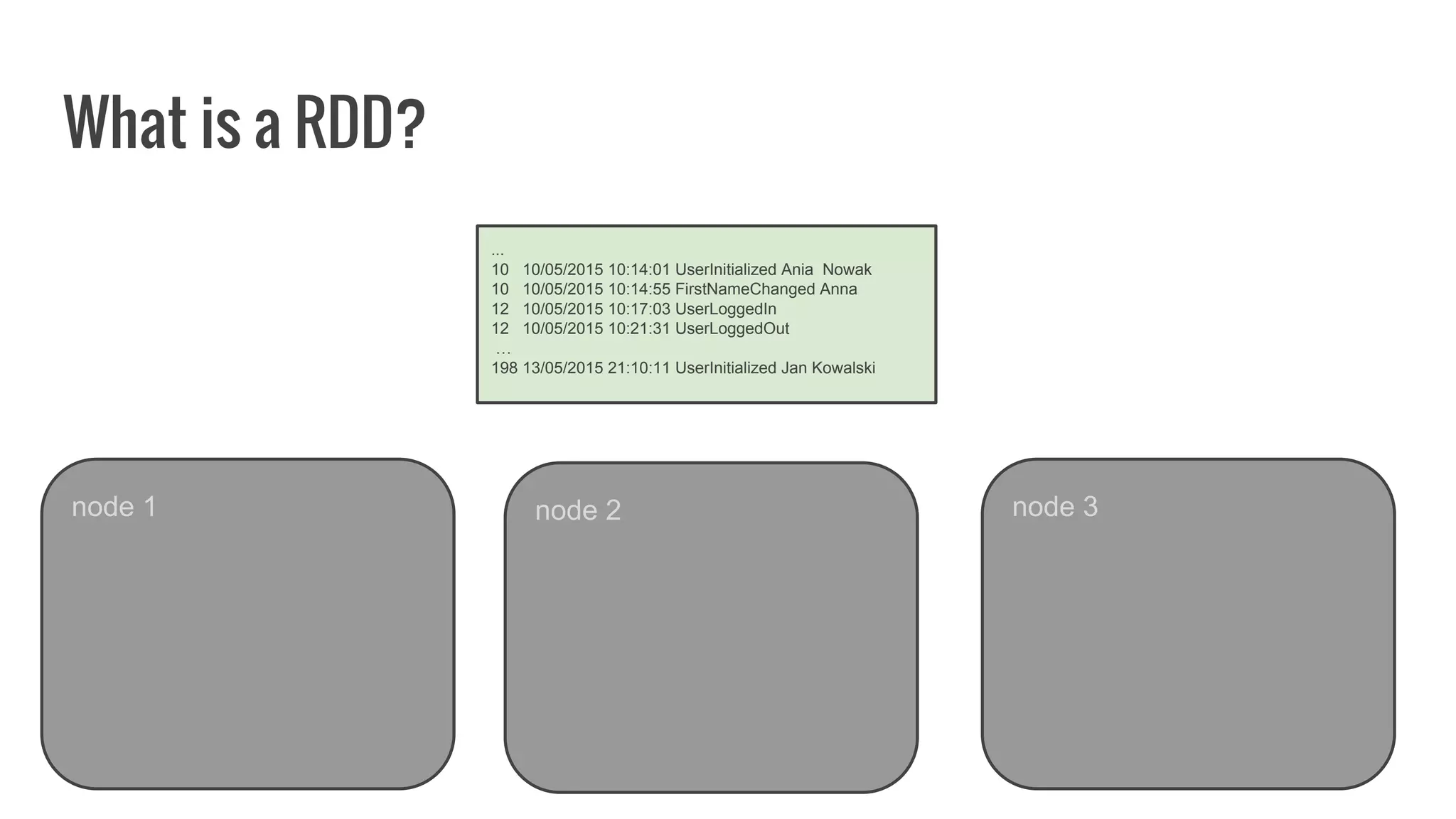
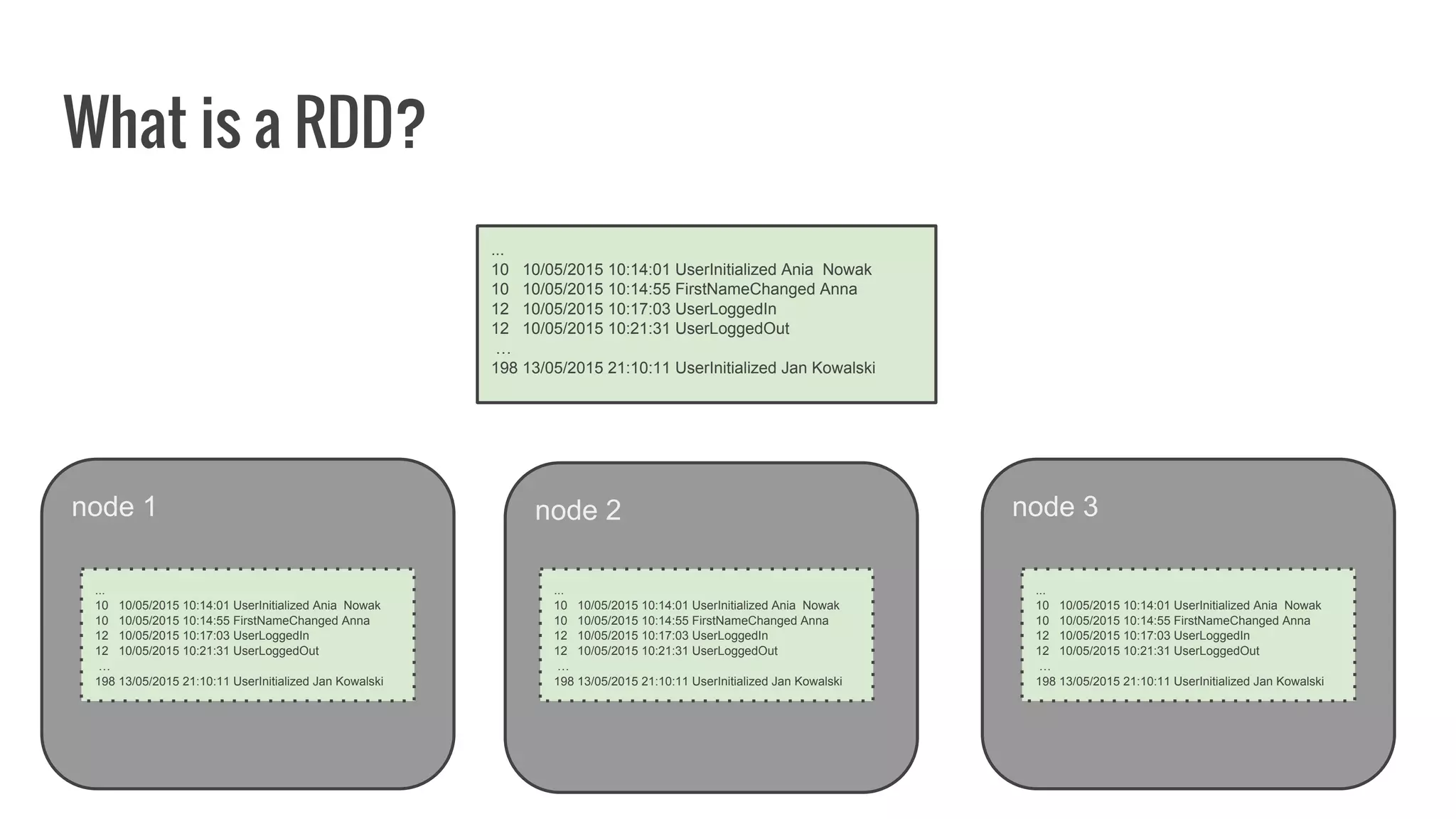
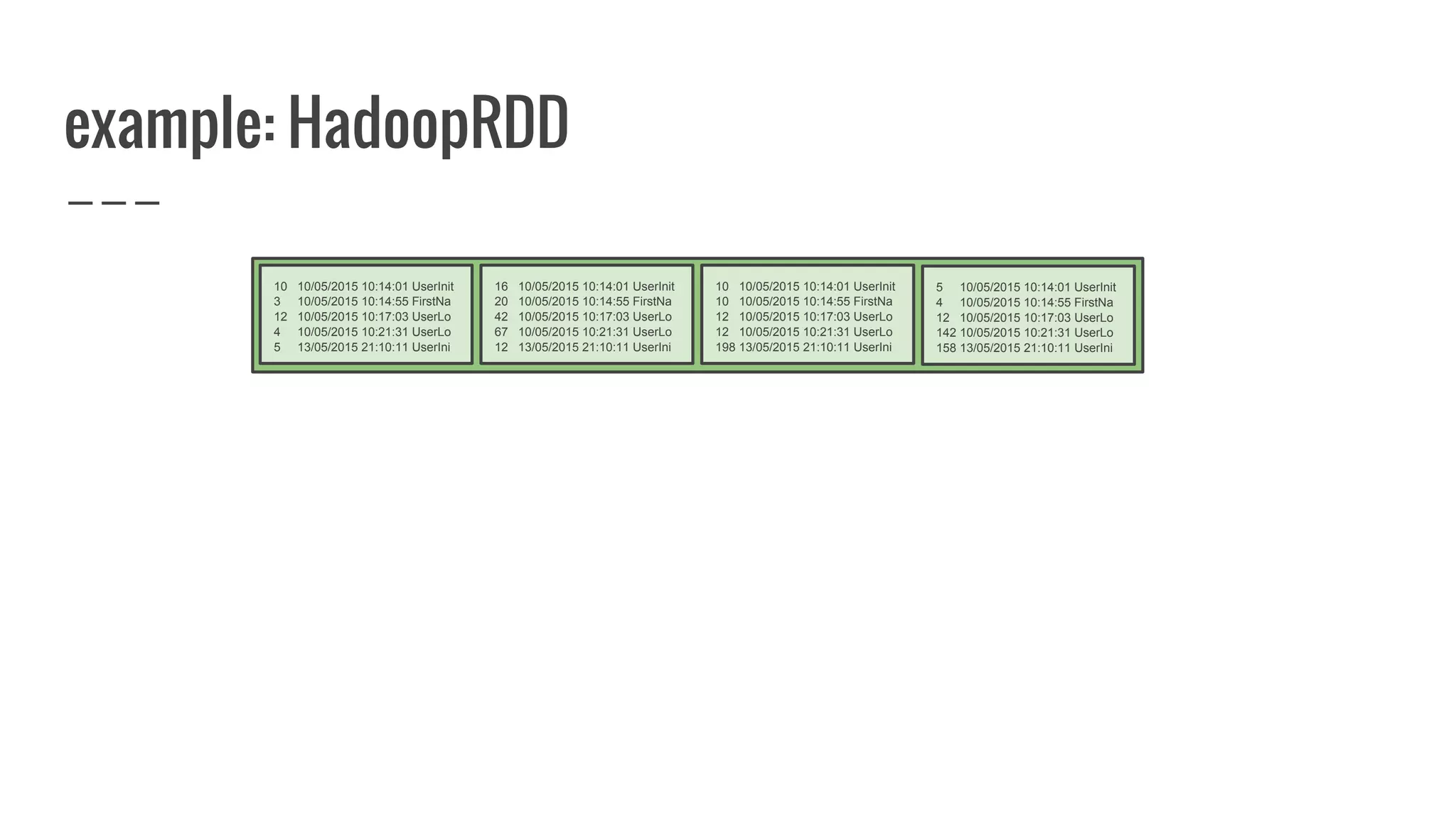
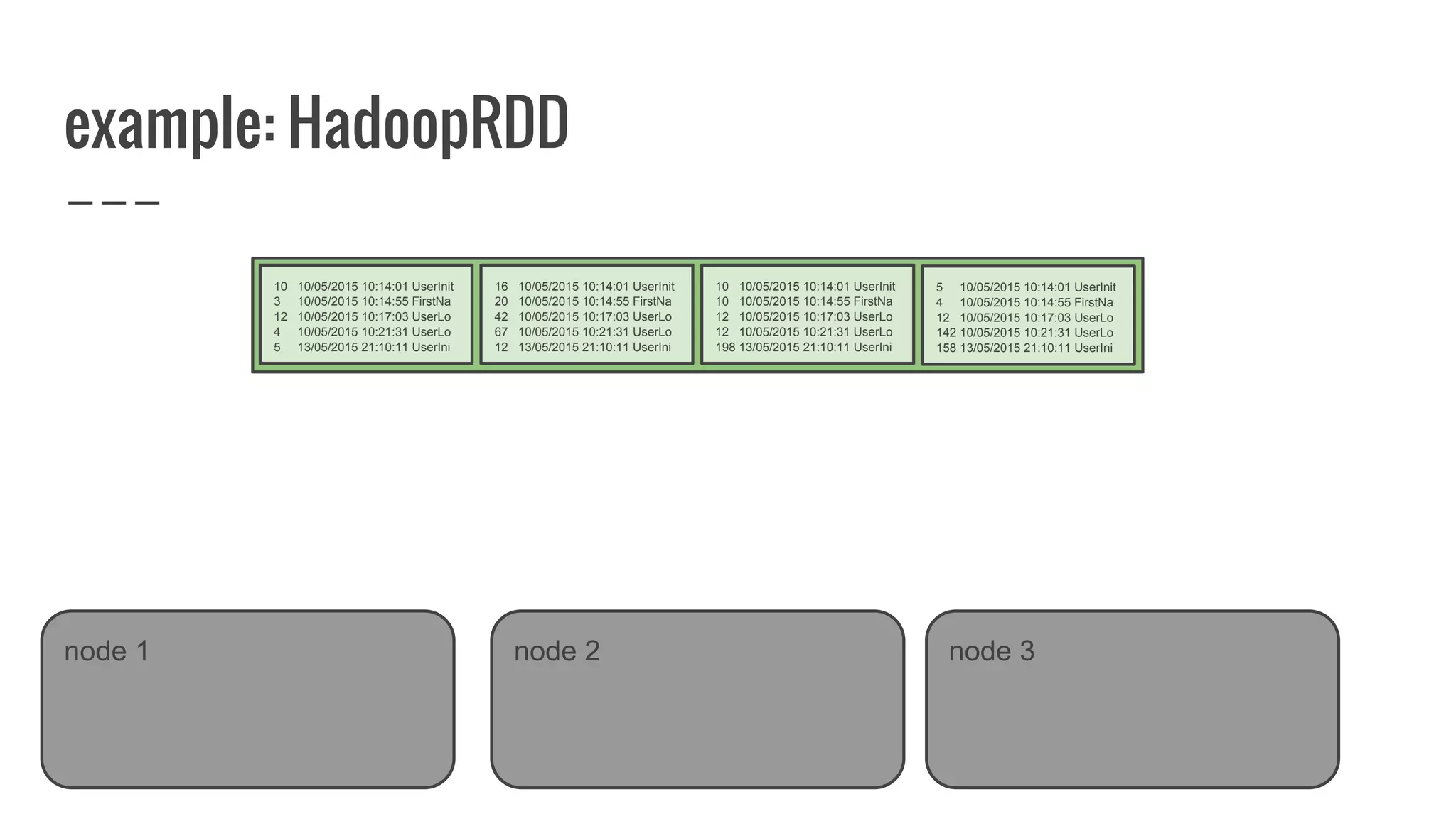
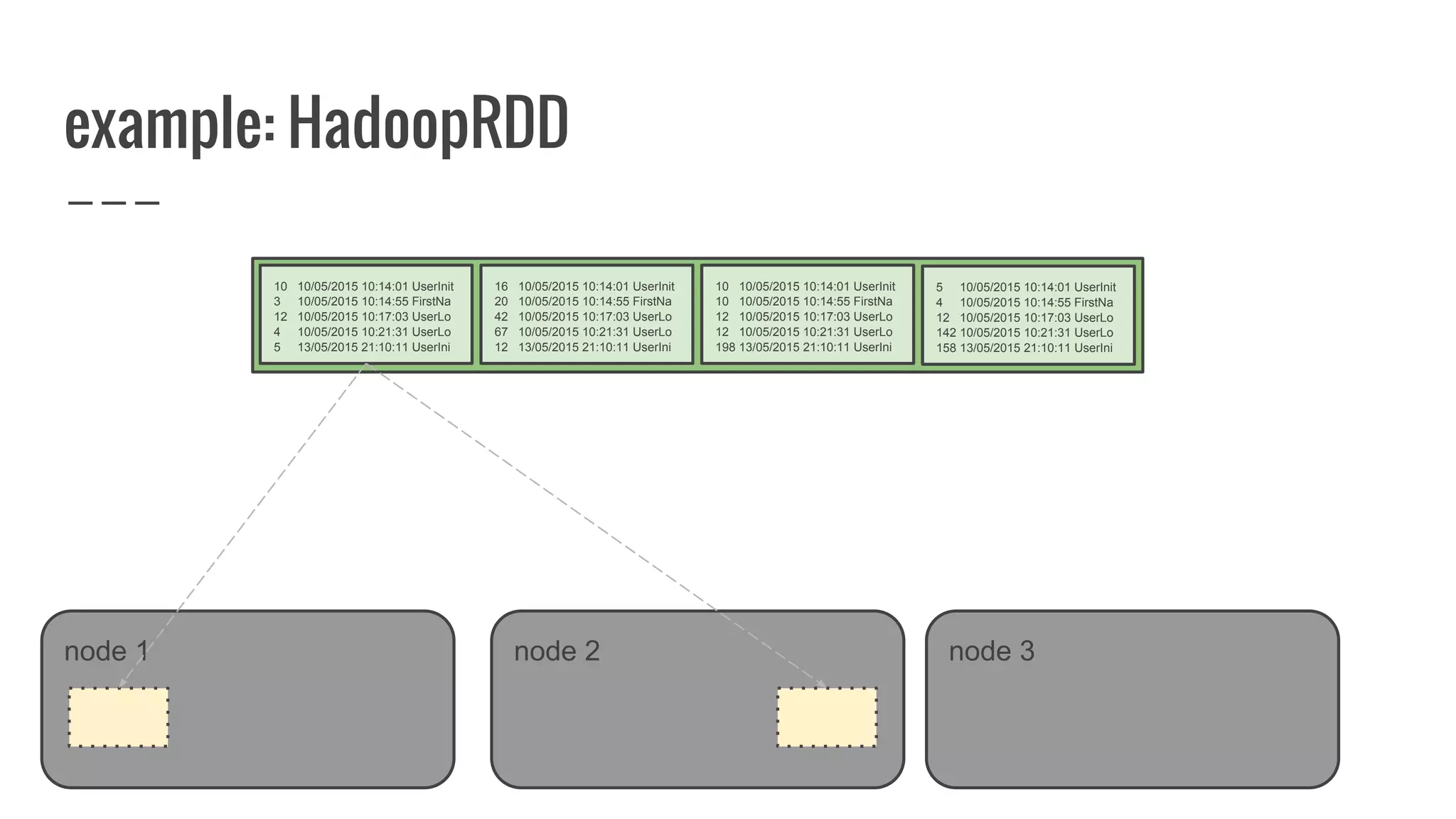
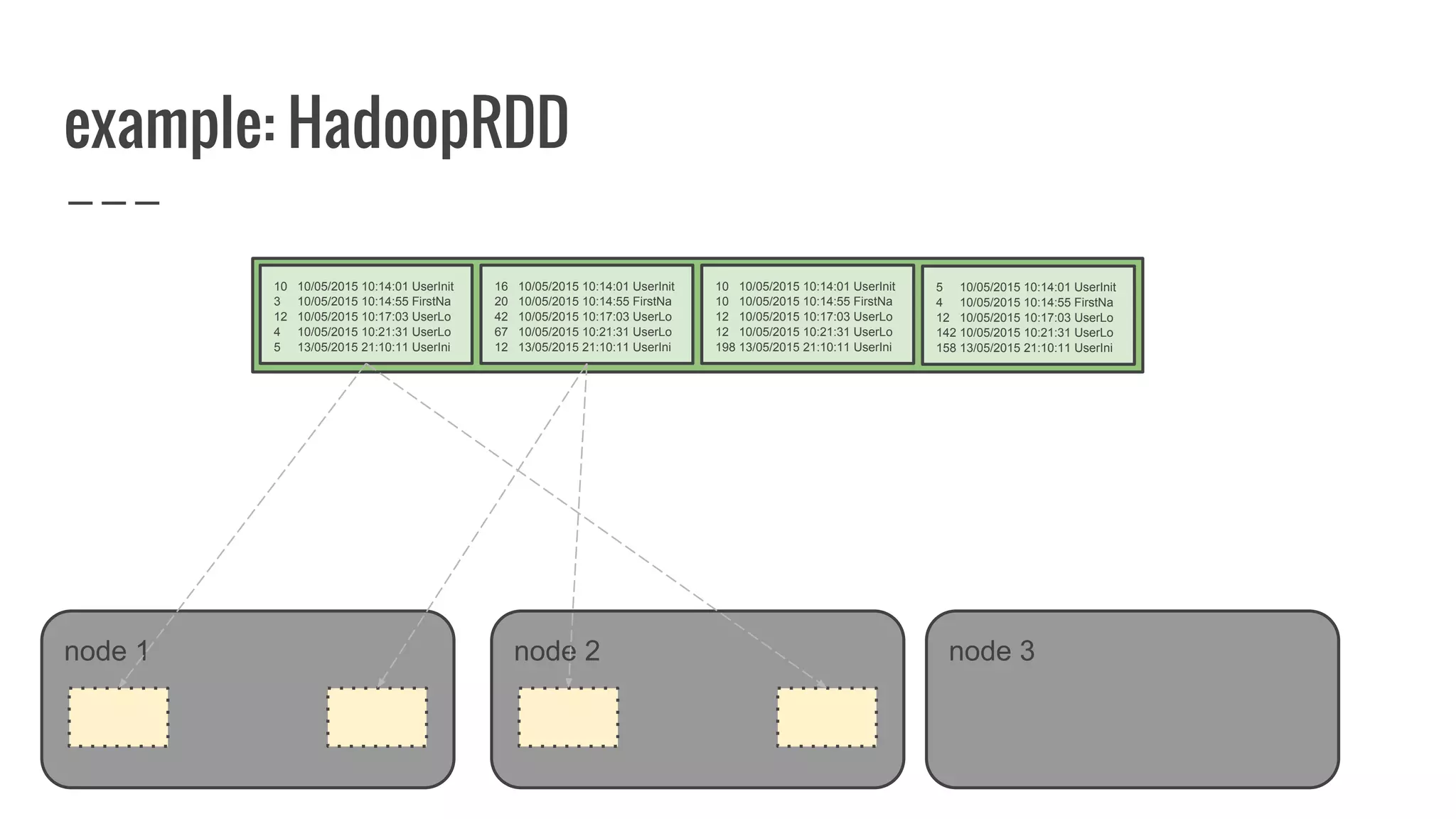
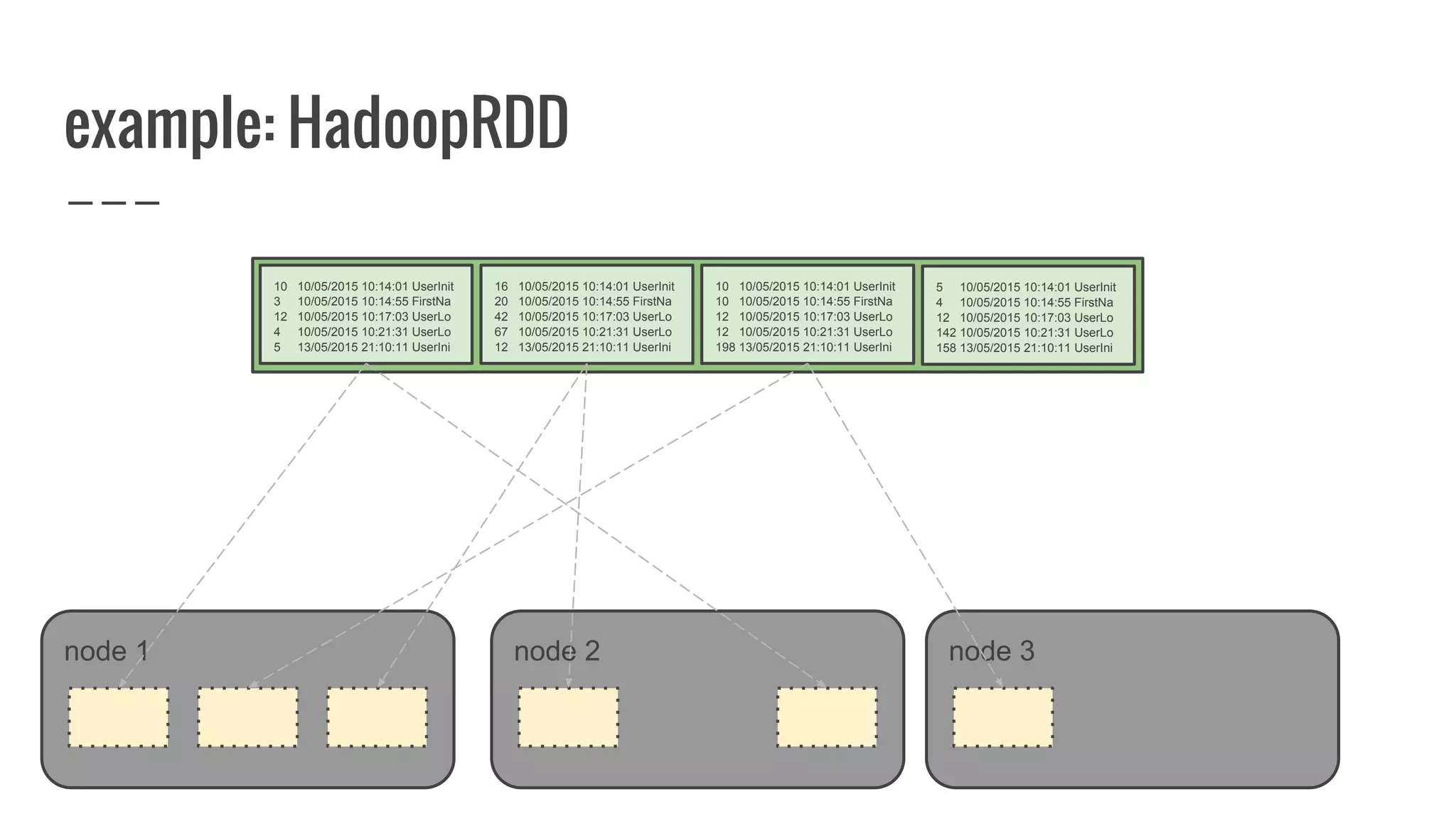
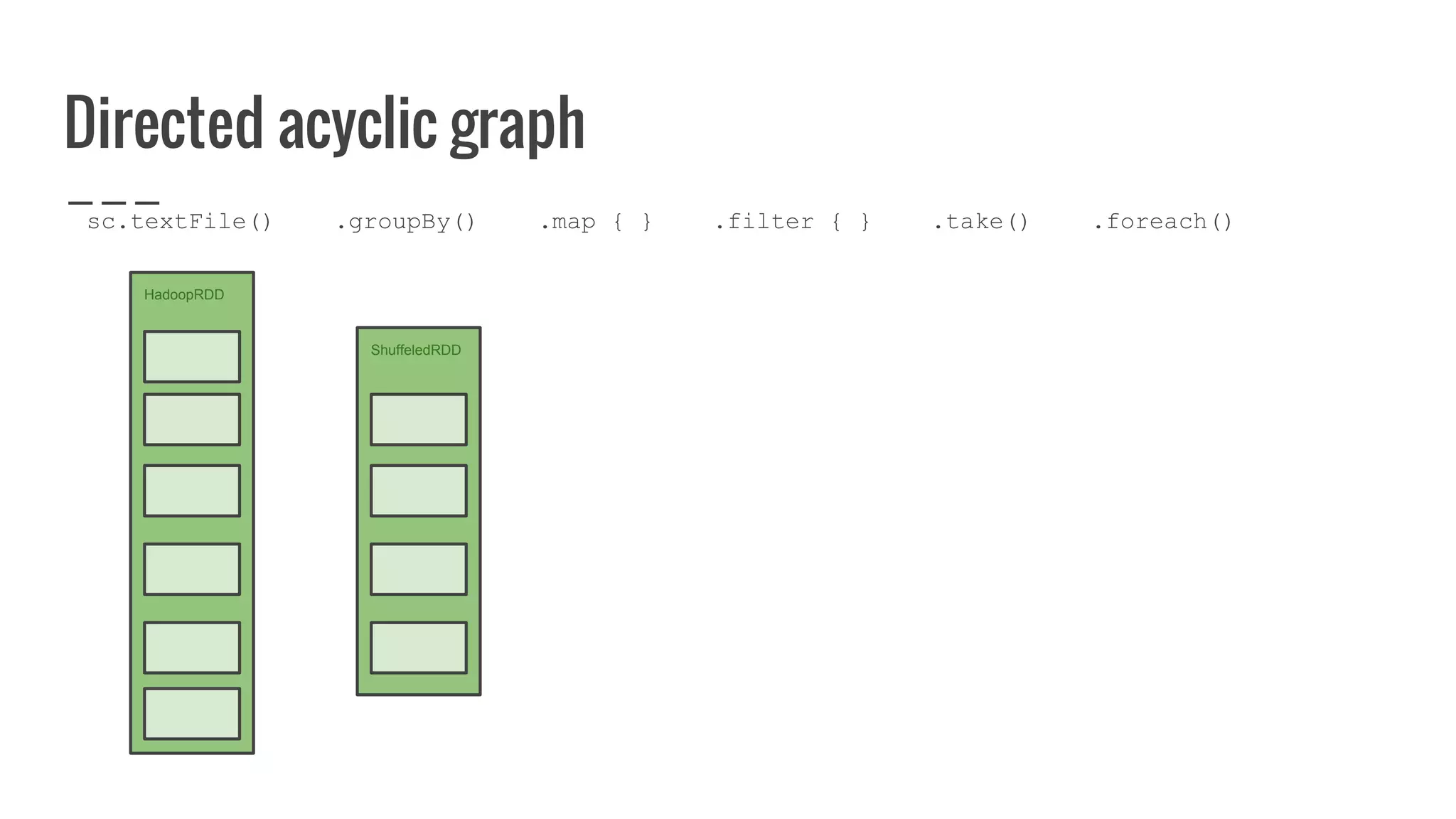
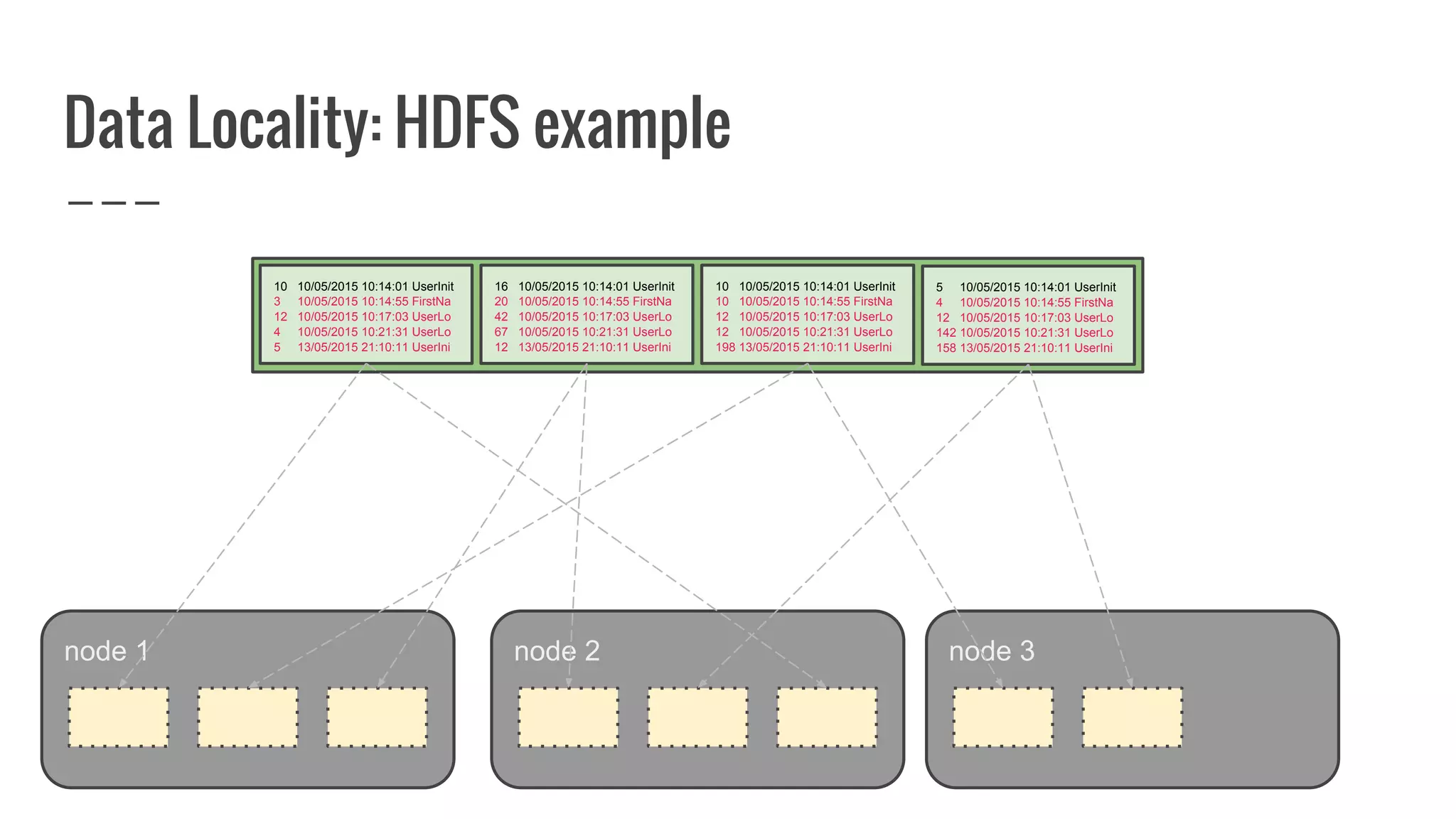
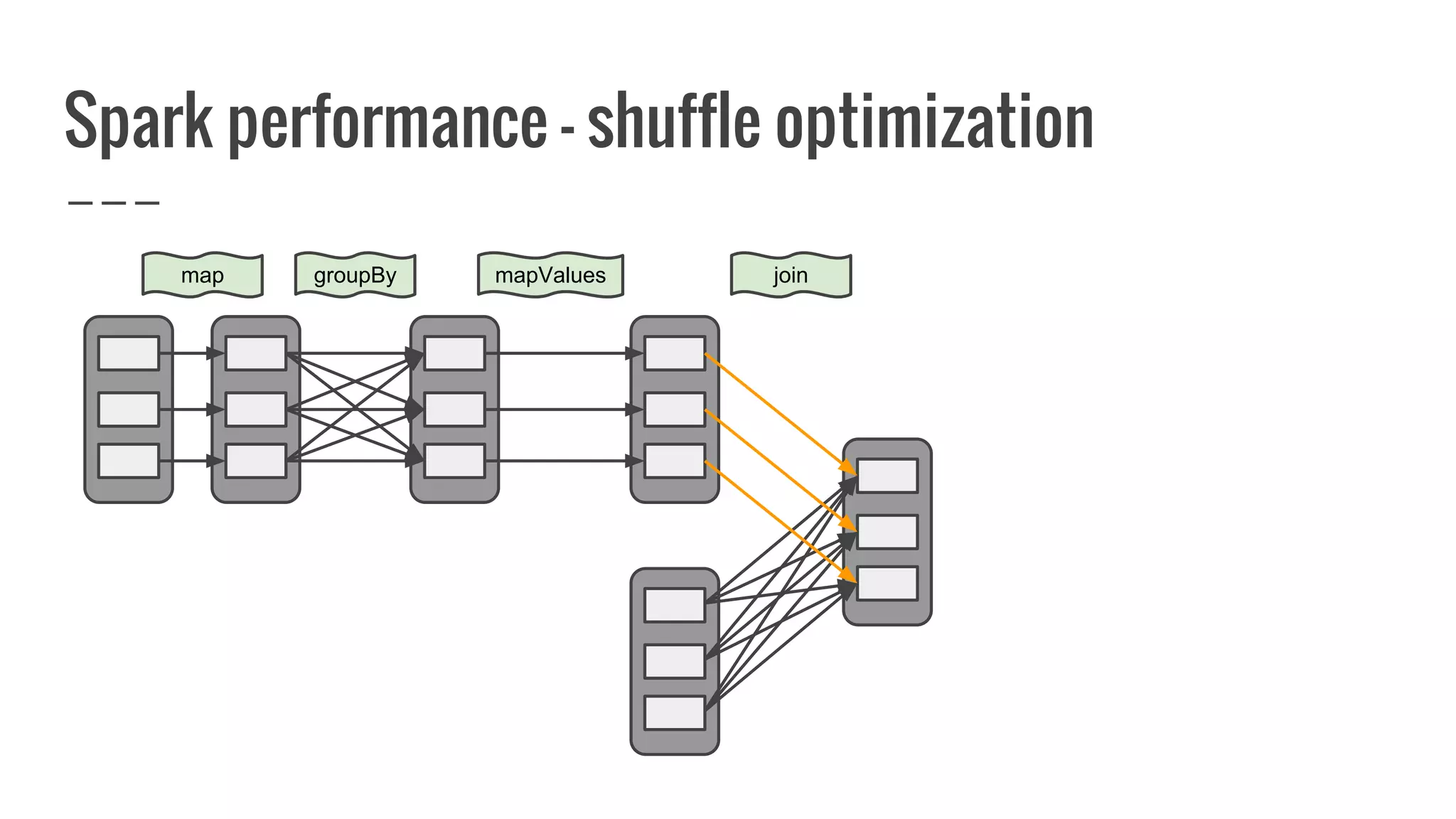
The document discusses writing your own resilient distributed dataset (RDD) in Apache Spark. It begins by outlining reasons for writing a custom RDD, such as understanding Spark's internal mechanics or connecting to external storage. It then provides an overview of RDD concepts like transformations, actions, and shuffling. The document dives into RDD internals like partitions, parents, and how data is evaluated. It uses examples like a HadoopRDD to illustrate how partitions map to data chunks in HDFS. The goal is to help understand how to write a custom RDD for specific use cases or to prove knowledge of Spark's architecture.
















































































![Apache Spark 101 [in 50 min]](https://cdn.slidesharecdn.com/ss_thumbnails/apachespark101-in50min1-150227110033-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)






















