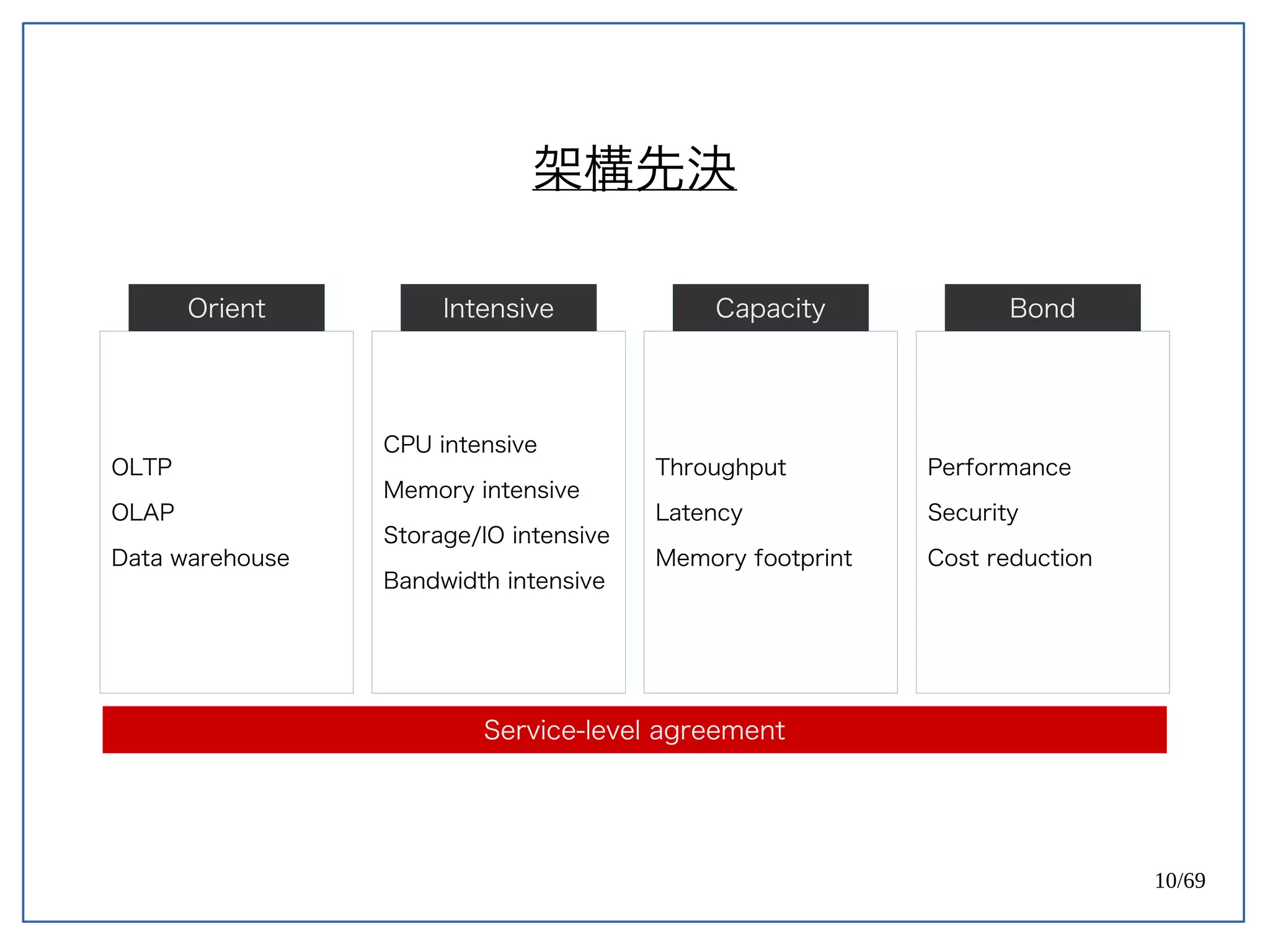
本文件讨论了Uber将数据库从PostgreSQL迁移到MySQL的技术理由,分析了两种数据库在频繁更新、无模式以及异地同步等业务需求下的表现。文中强调了架构对企业文化和业务扩展的影响,提出架构不是完美的,而是最适合的。最后,PostgreSQL团队开始考虑并改善Uber面临的热更新问题。











































![61/69
2015
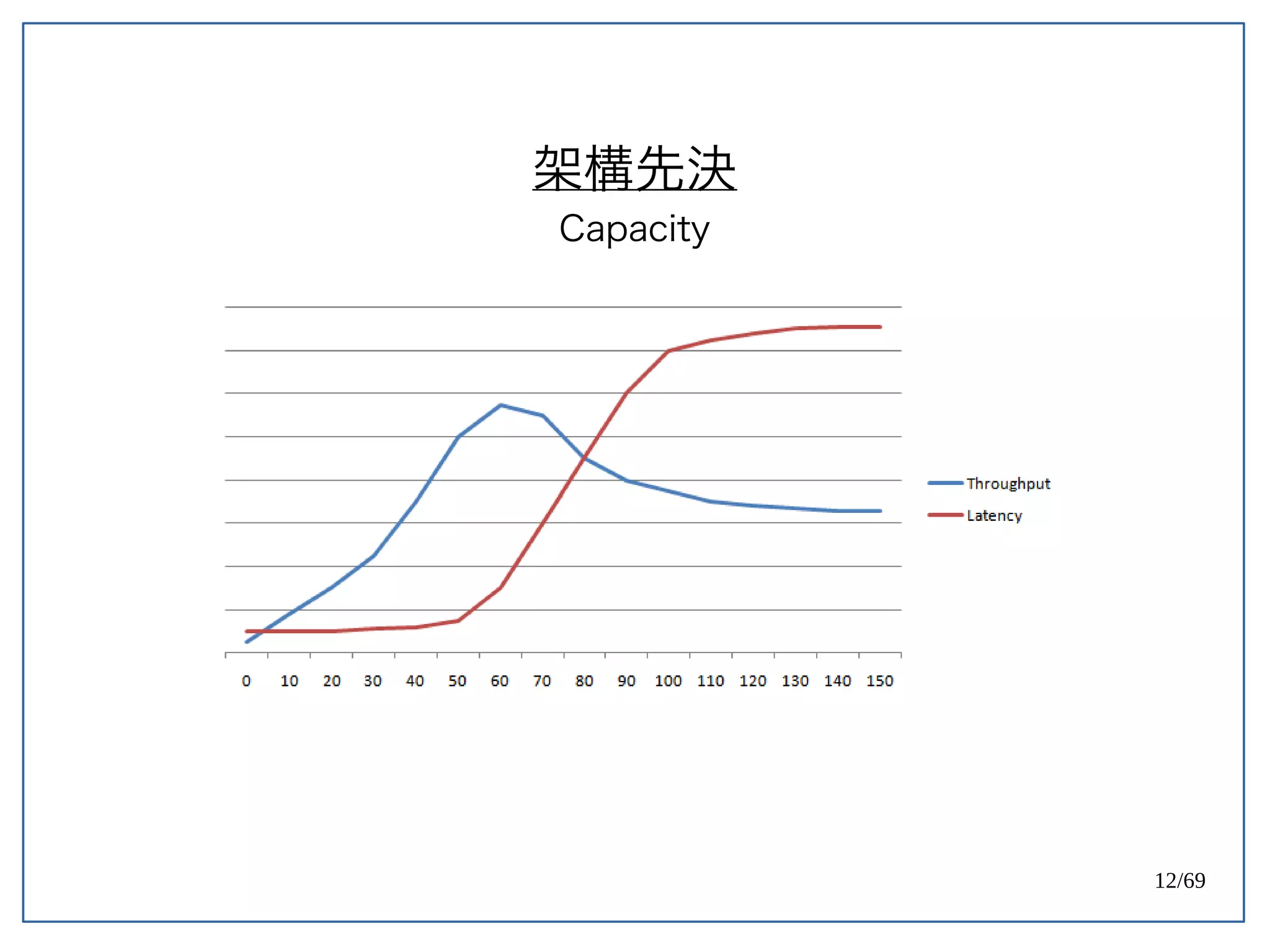
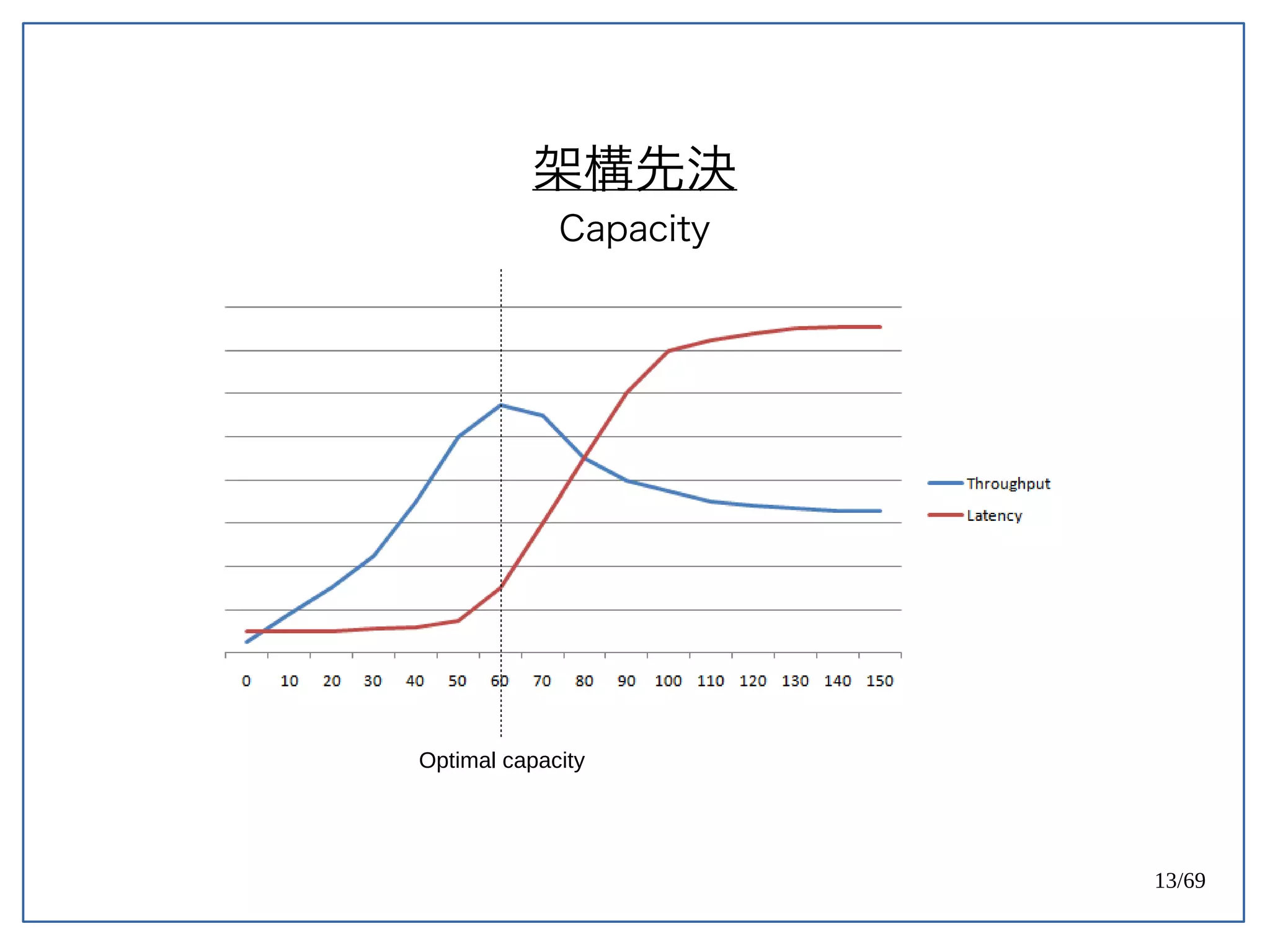
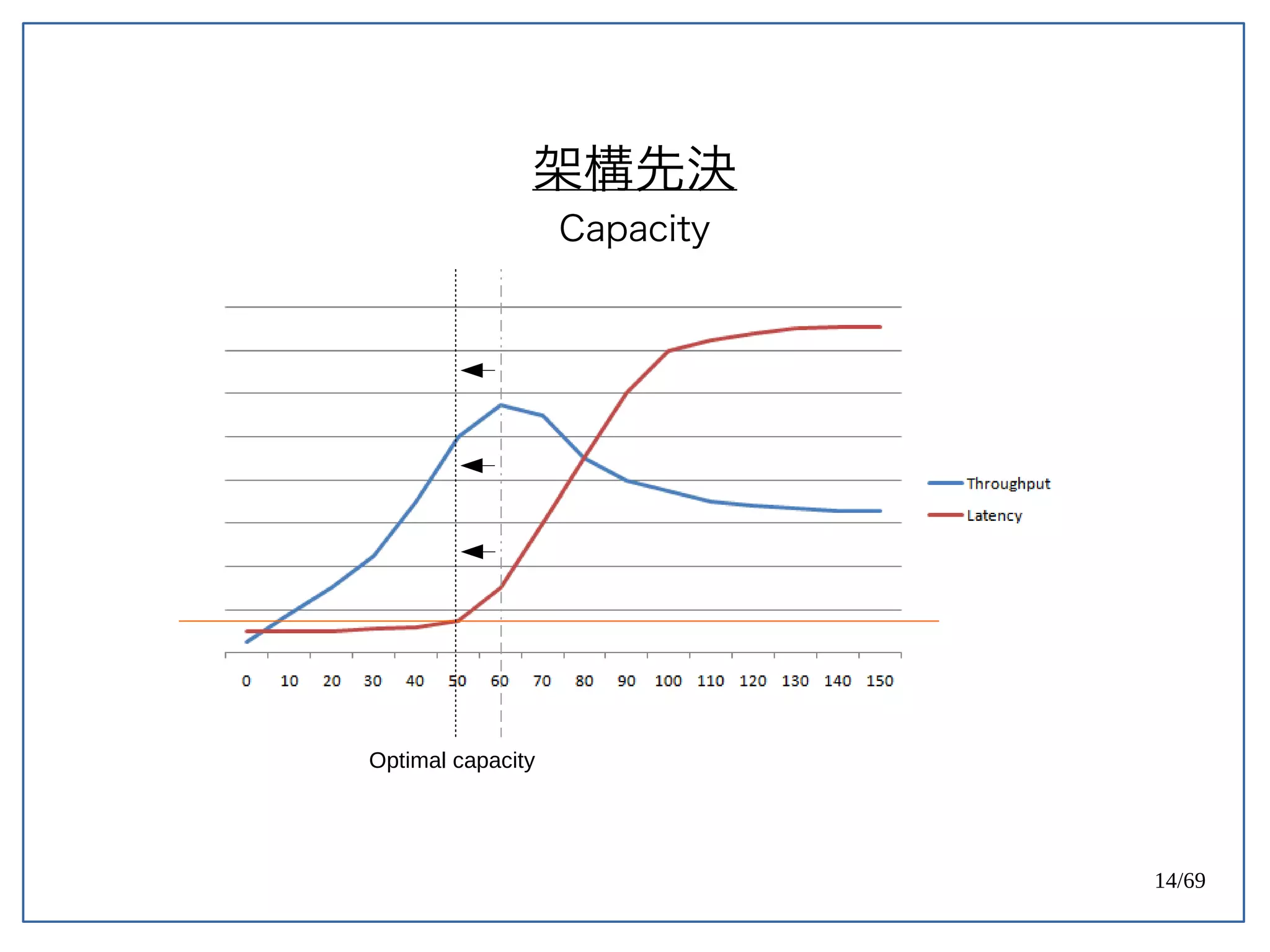
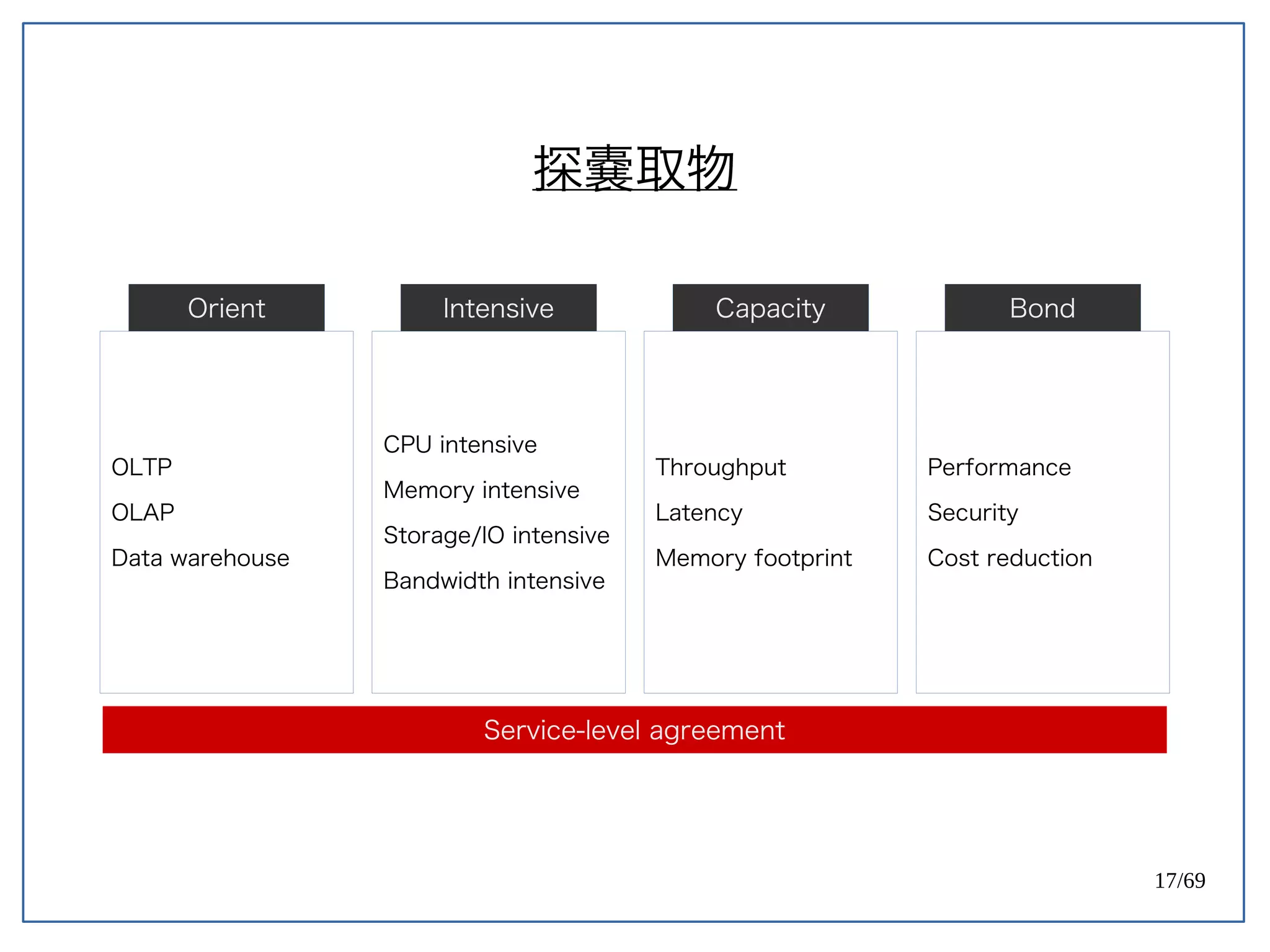
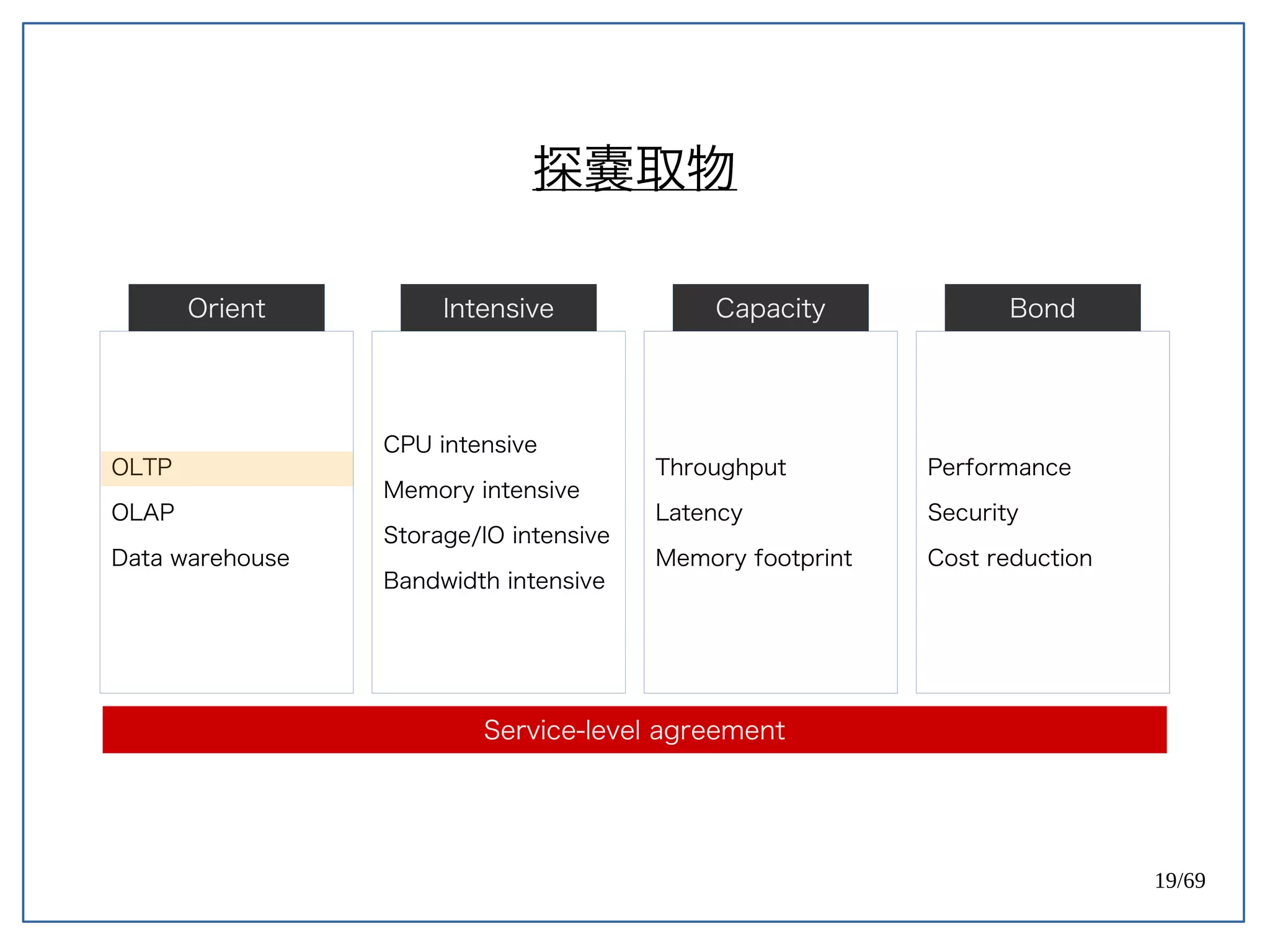
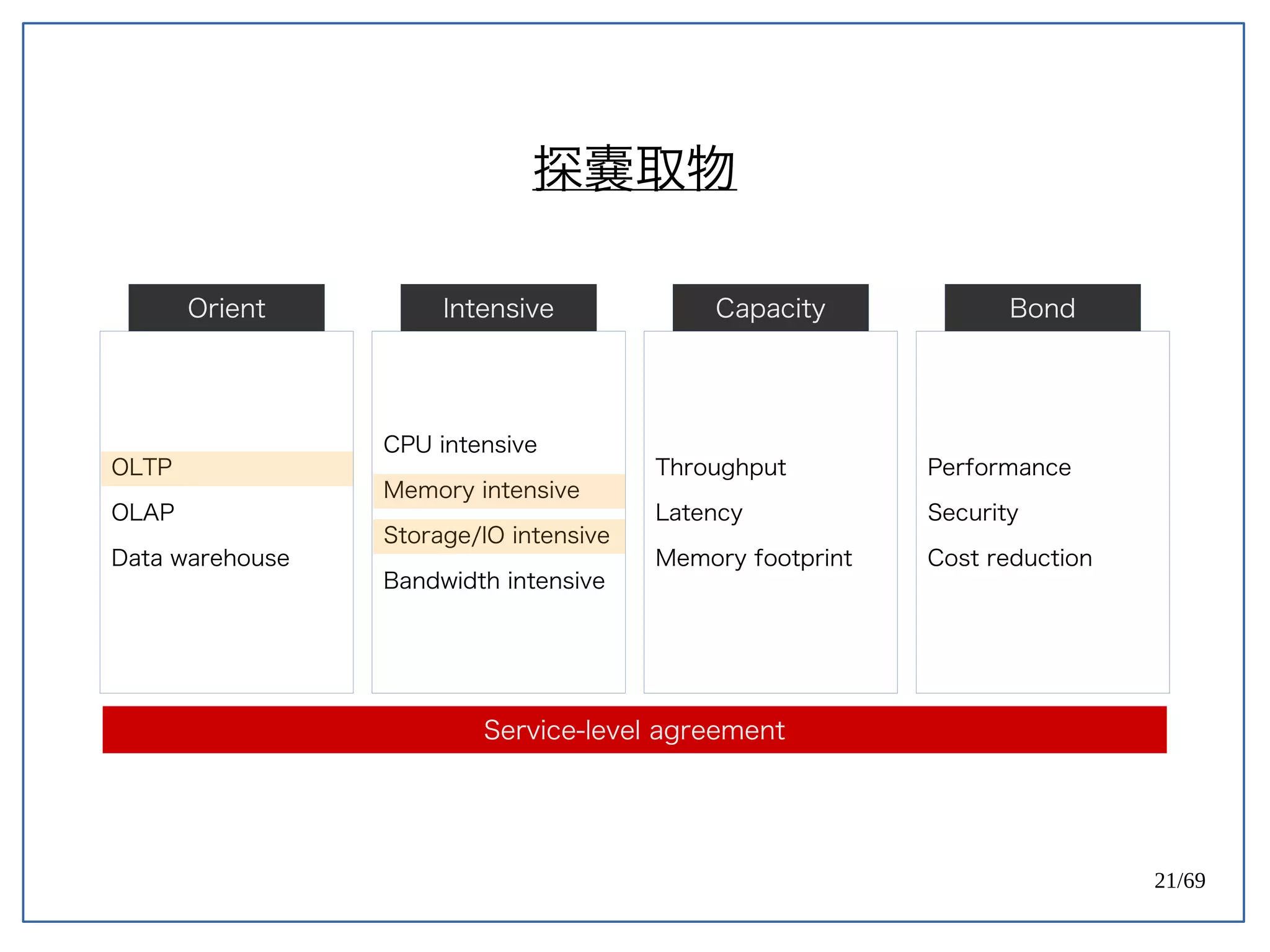
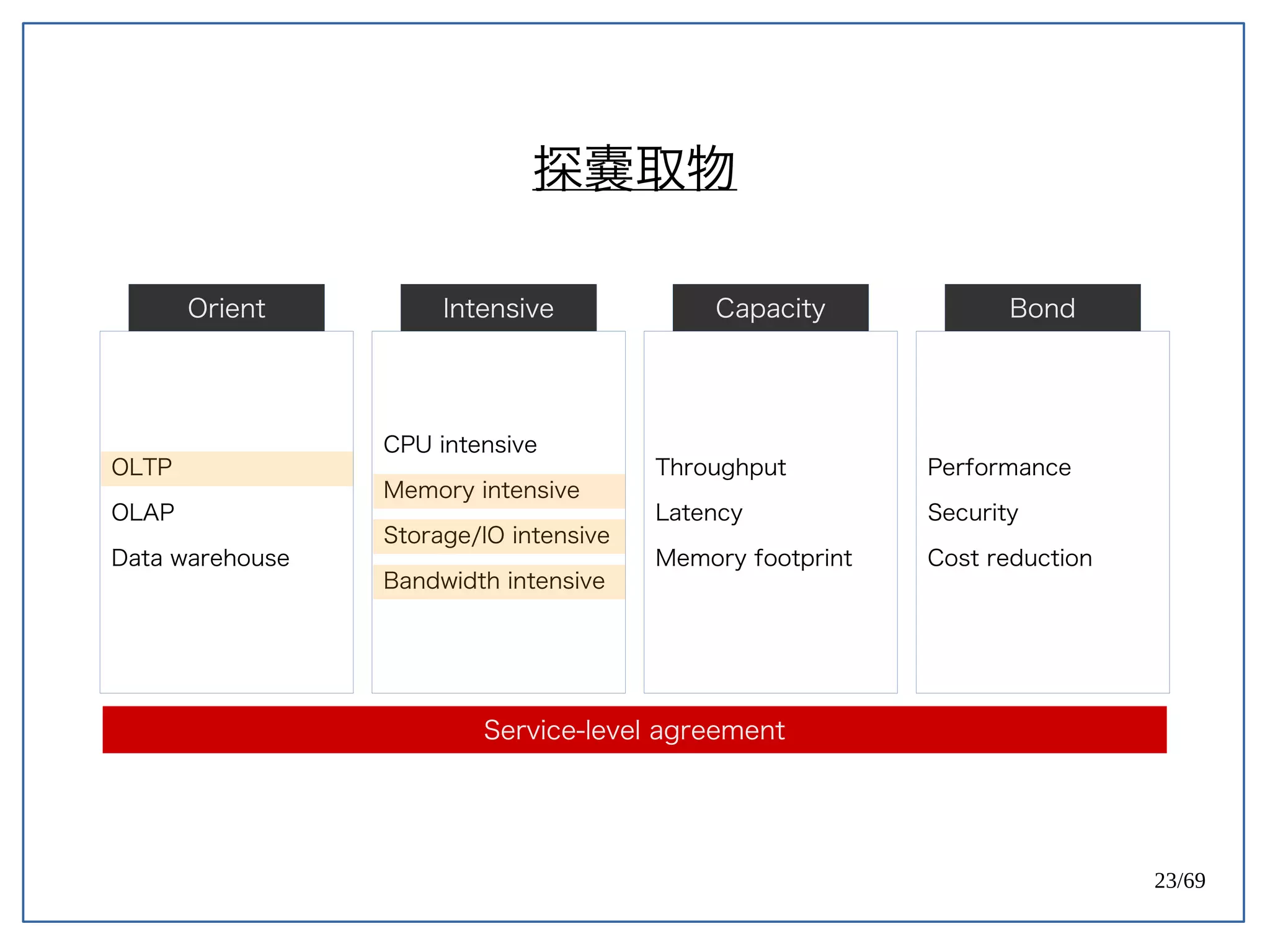
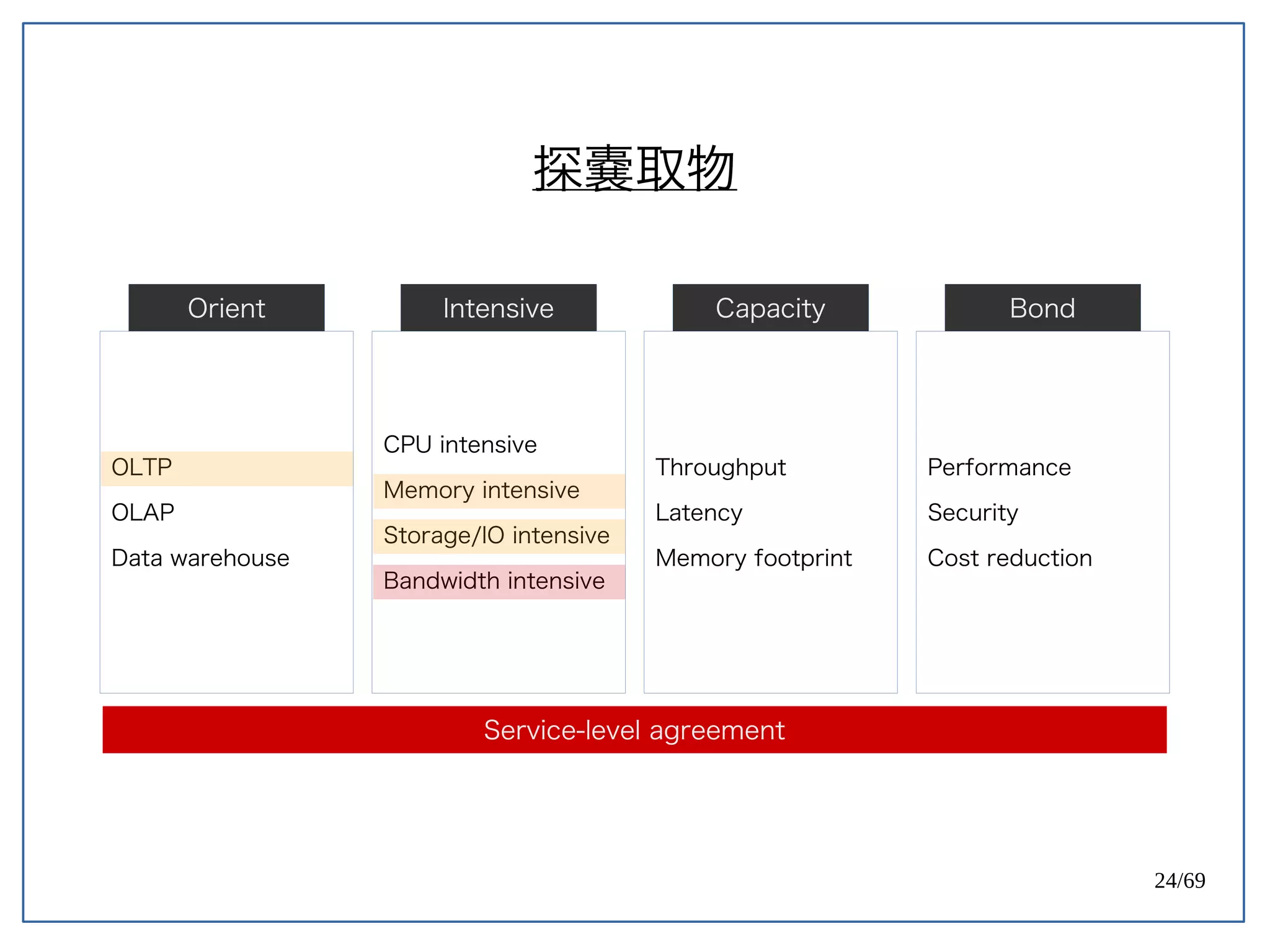
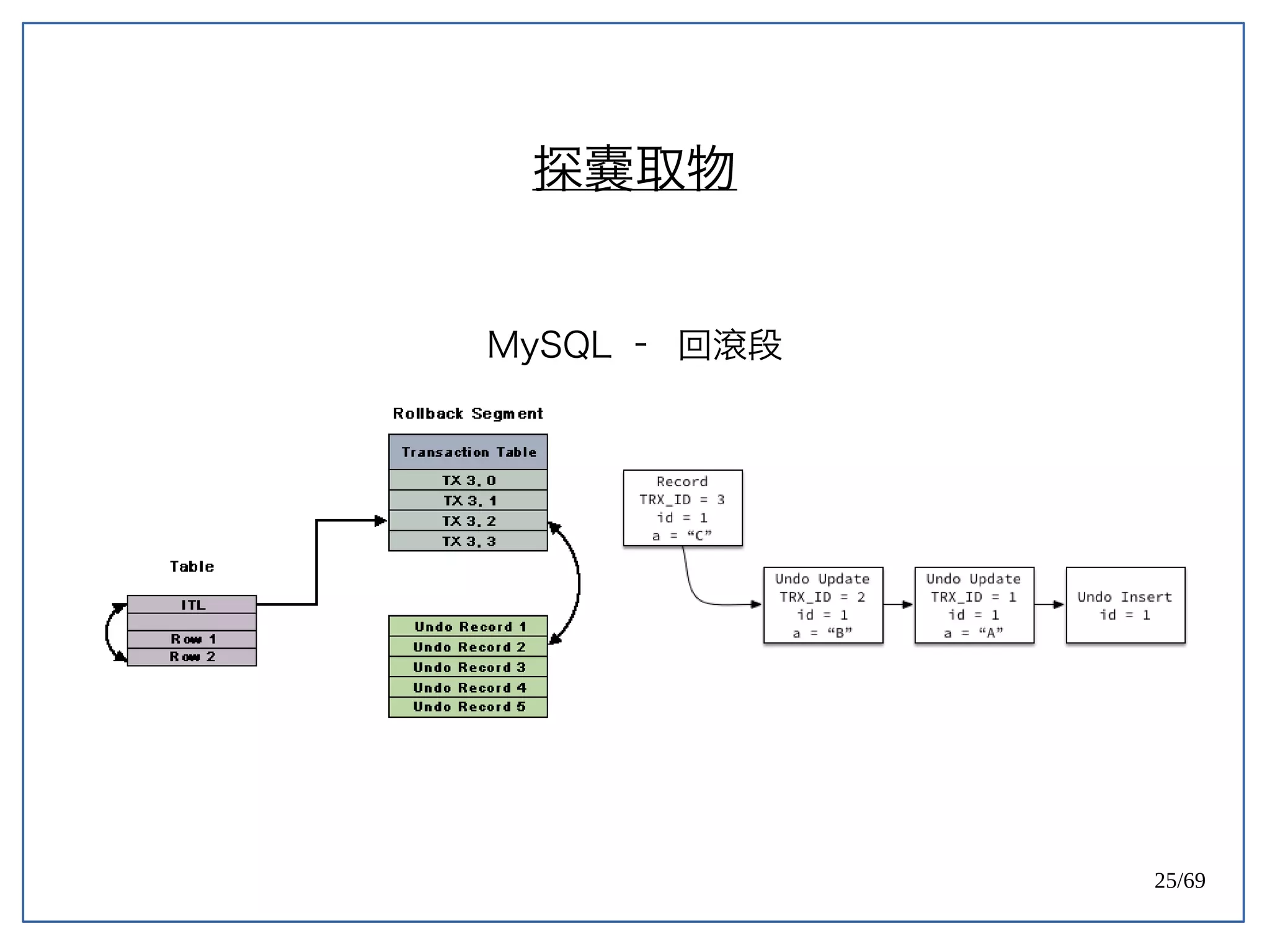
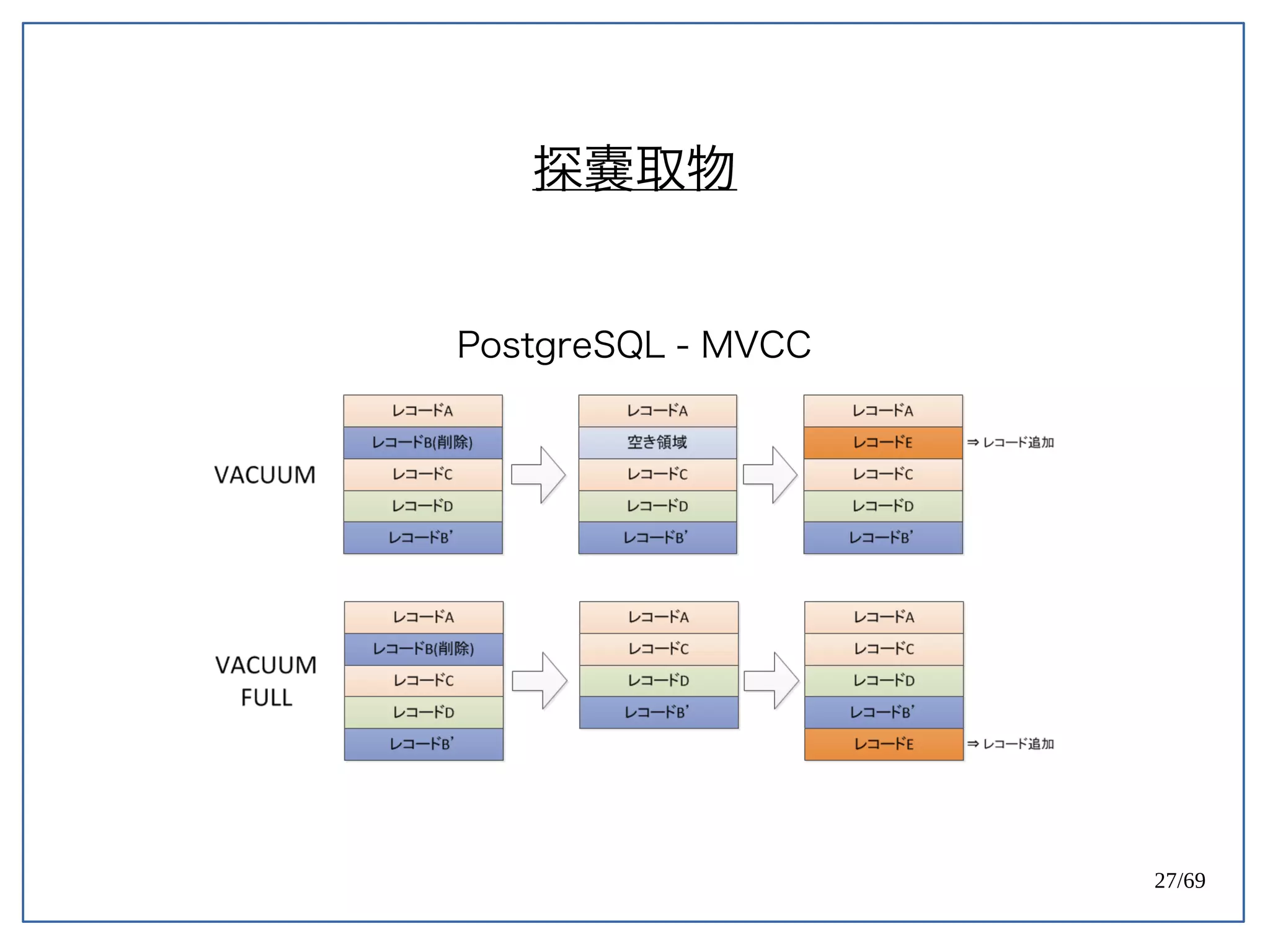
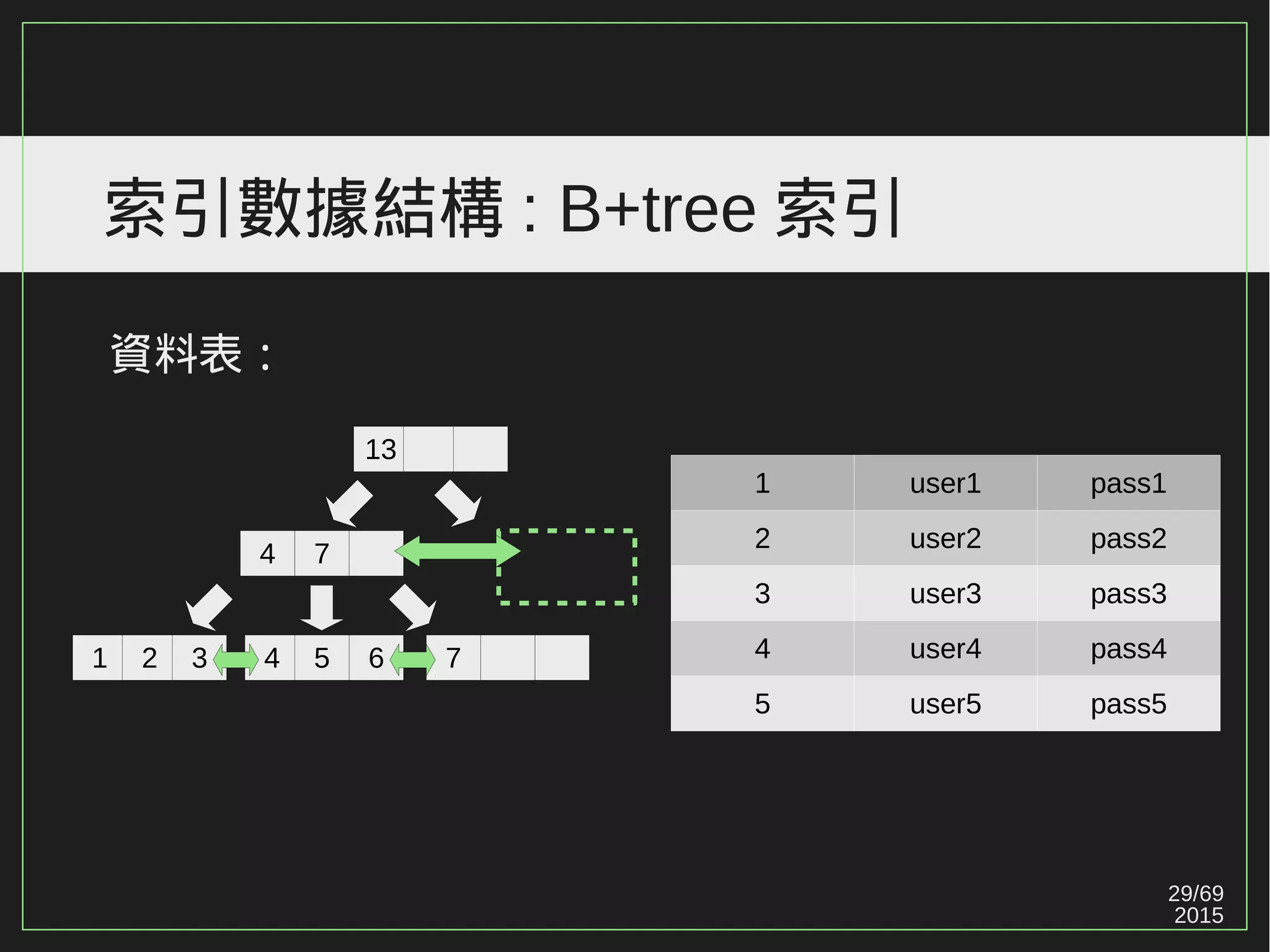
High Concurrent Write?(Hotspot:UPDATE)
《 PostgreSQL 》
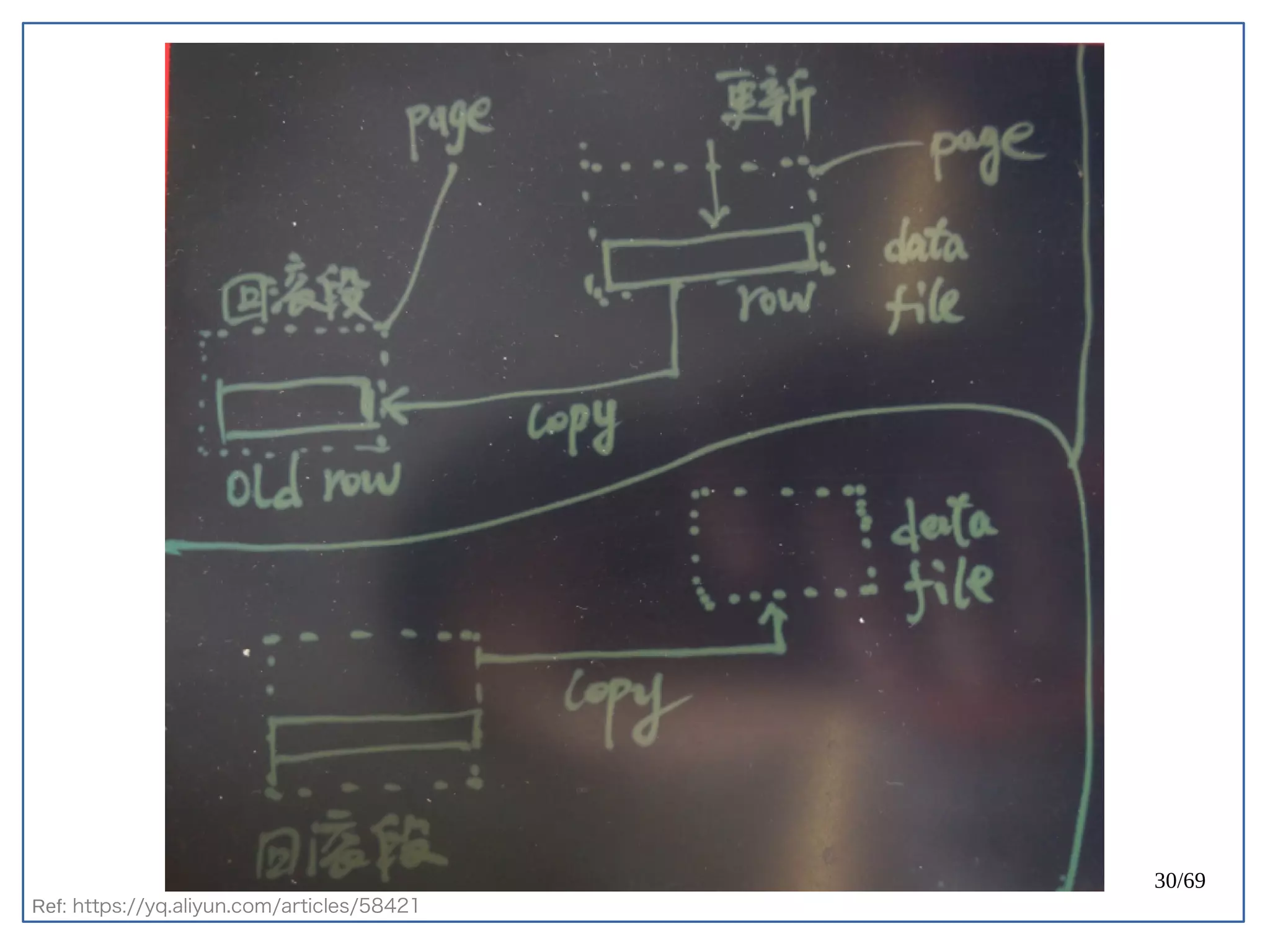
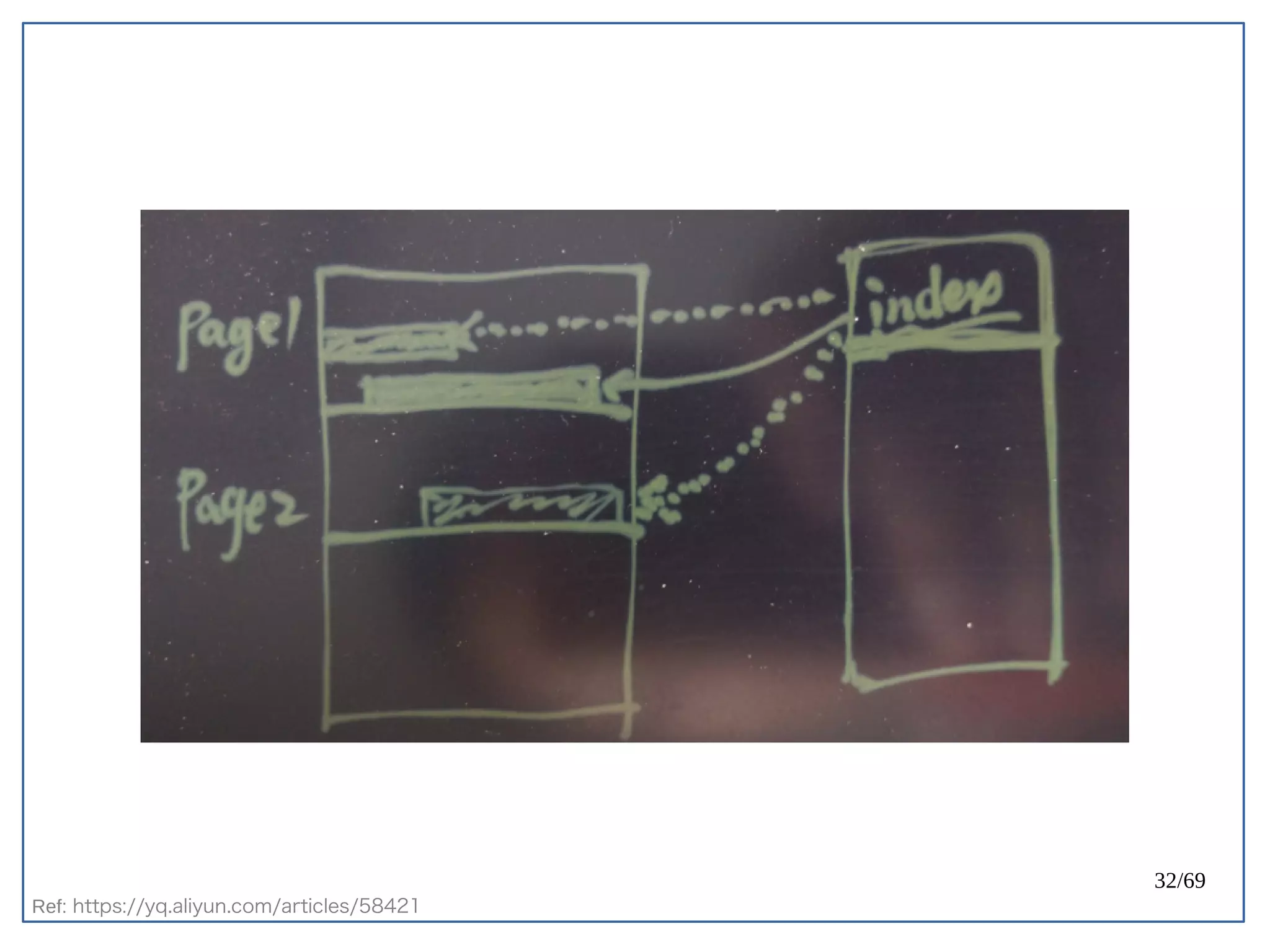
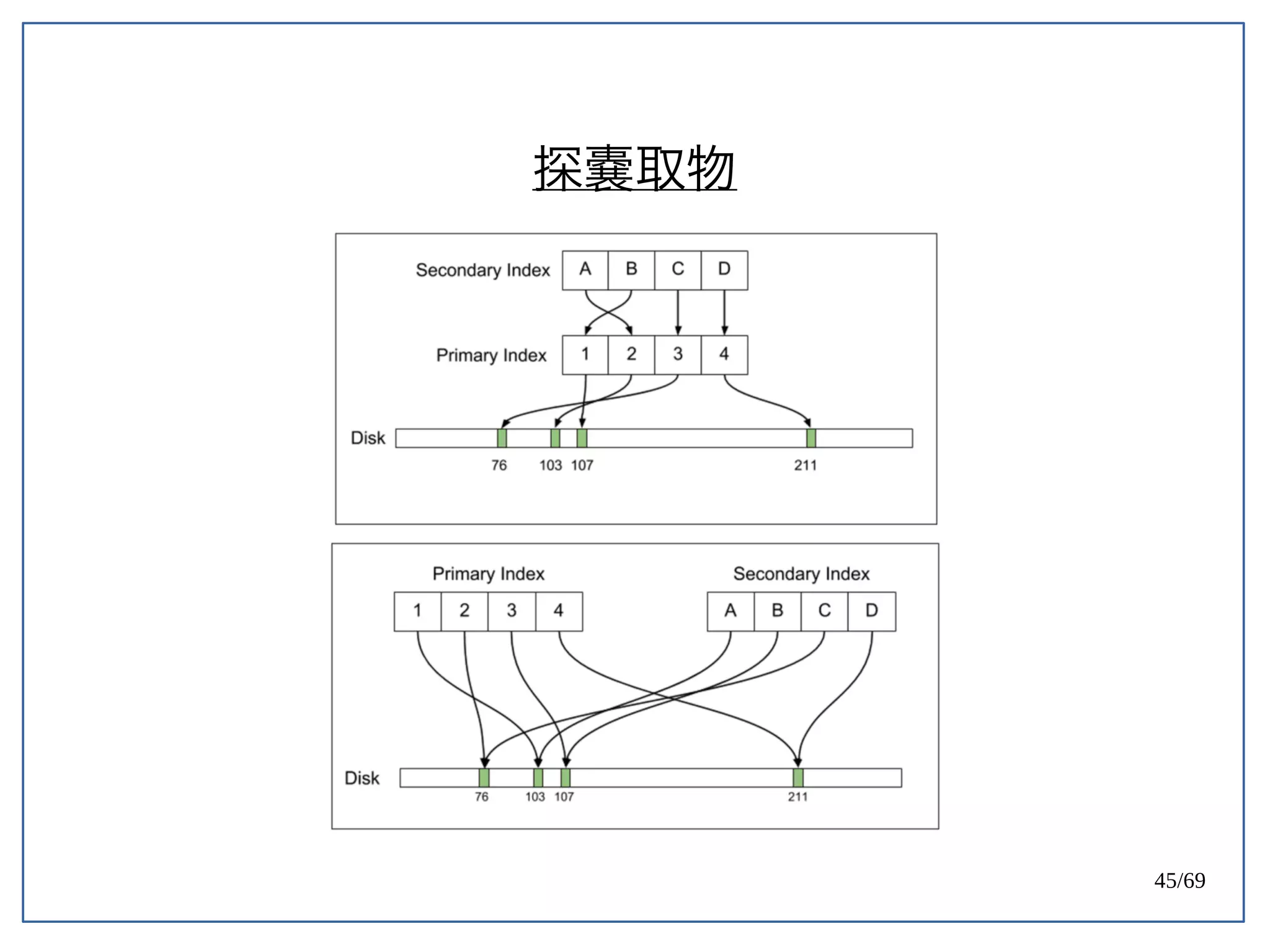
PostgreSQL 天生容易遇到 Index bloat 的問題。
Ref: PostgreSQL 9.0 High Performance [PACKT] (2010) (p171)](https://image.slidesharecdn.com/2016-08-05whyuberengineeringswitchedfrompostgrestomysql-160805112754/75/Uber-PostgreSQL-MySQL-61-2048.jpg)



































































![61/69
2015
High Concurrent Write?(Hotspot:UPDATE)
《 PostgreSQL 》
PostgreSQL 天生容易遇到 Index bloat 的問題。
Ref: PostgreSQL 9.0 High Performance [PACKT] (2010) (p171)](https://crownmelresort.com/image.slidesharecdn.com/2016-08-05whyuberengineeringswitchedfrompostgrestomysql-160805112754/75/Uber-PostgreSQL-MySQL-61-2048.jpg)







































![[BizLePro] 主題講座 #7:商業利用怎麼行? - 從開源授權十個常見 FAQ 來了解](https://cdn.slidesharecdn.com/ss_thumbnails/20130610-130610200023-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




![恰如其分的 MySQL 設計技巧 [Modern Web 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/2016-08-24modernweb-mysql-161019062706-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BizLePro] 主題講座 #4:給資訊人的智財導論_20130429_richard](https://cdn.slidesharecdn.com/ss_thumbnails/bizlepro20130429richard-130430014156-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[CBLP] 個資法雙連發-怪怪的個資法-ox-20130225](https://cdn.slidesharecdn.com/ss_thumbnails/2013-02-25cblp-ox-130226205618-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BizLePro] 主題講座 #5:台灣C2C第三方支付服務之發展_20130513_gillight](https://cdn.slidesharecdn.com/ss_thumbnails/c2c-130515050736-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



































