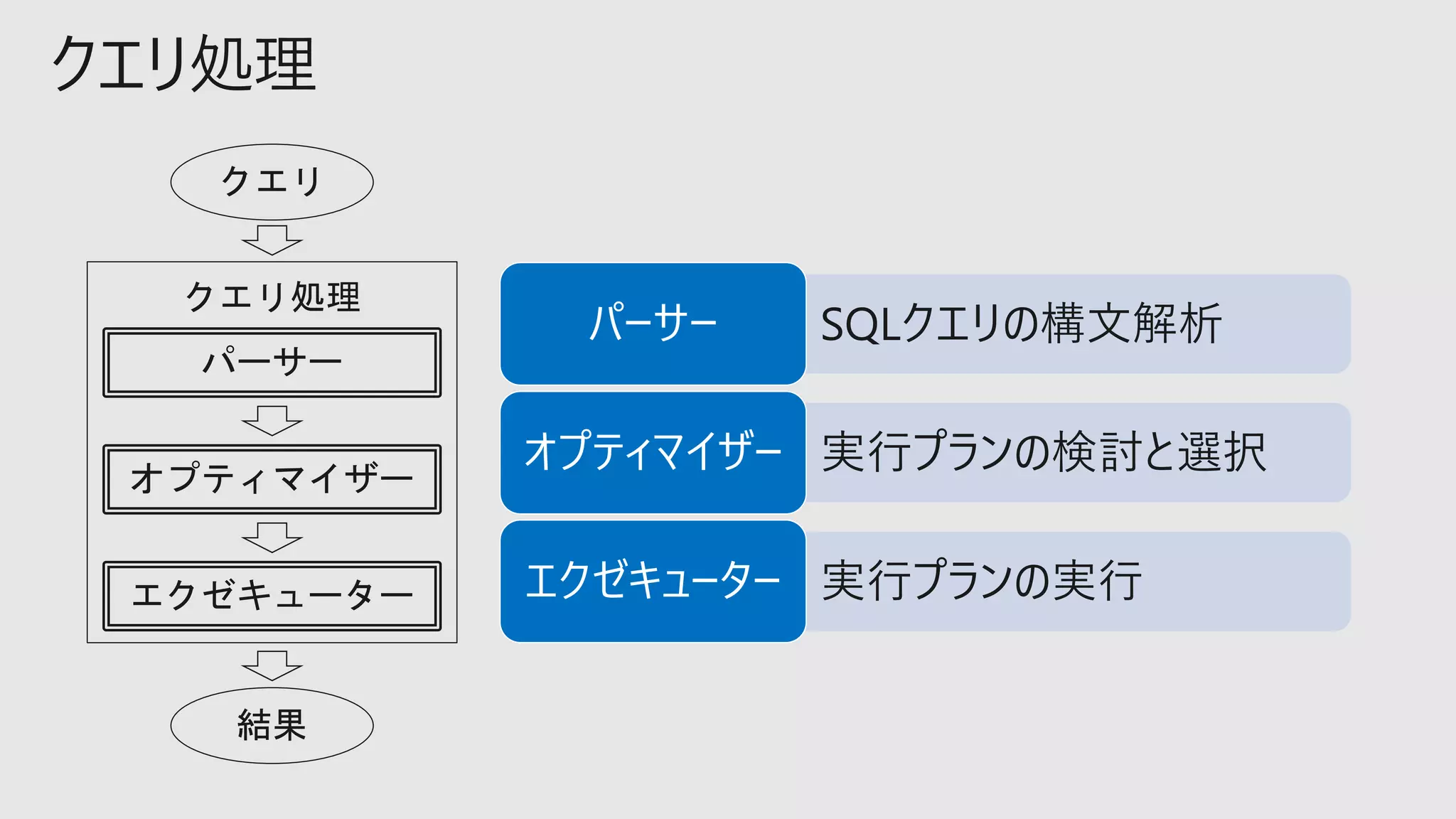
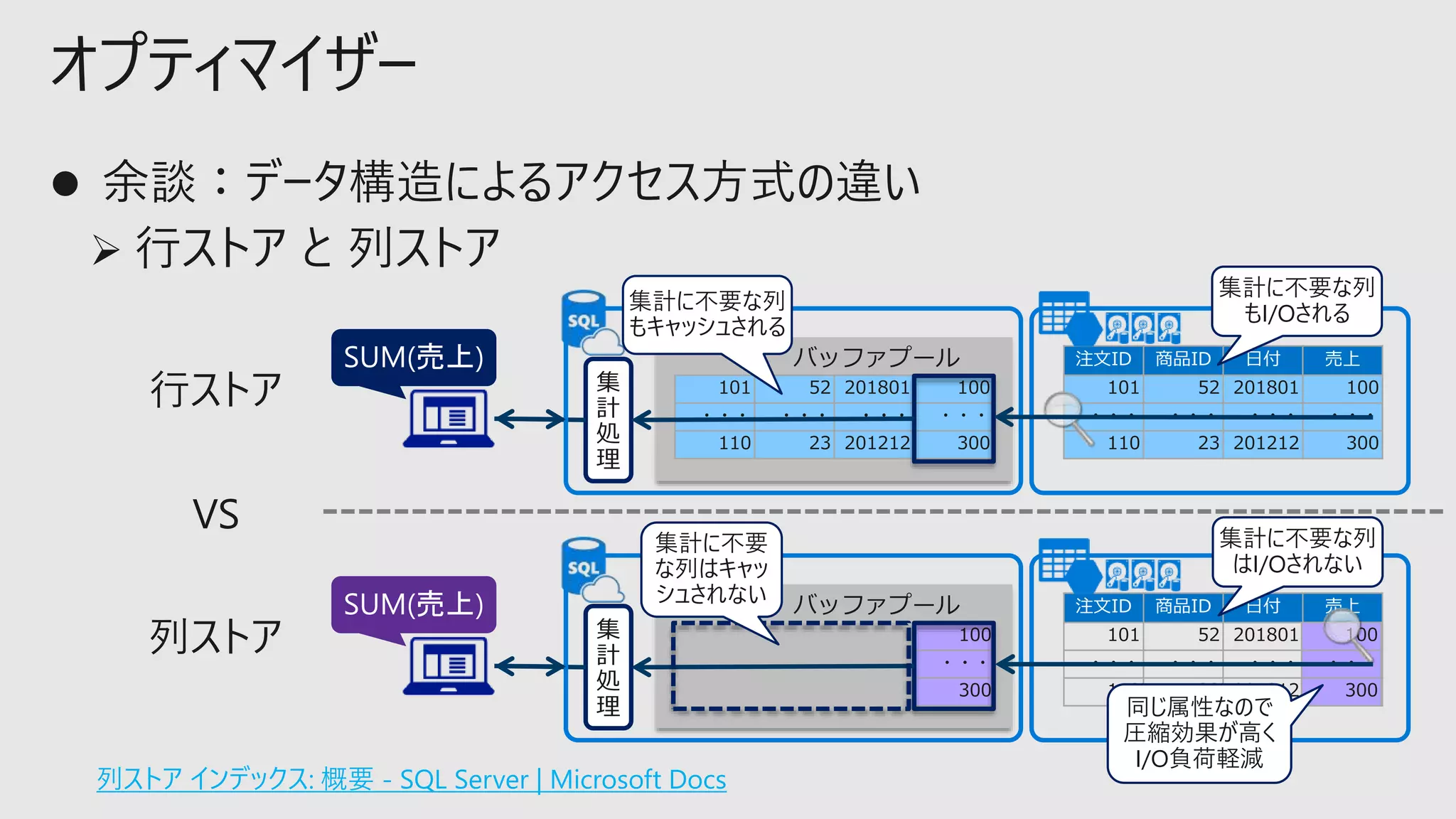
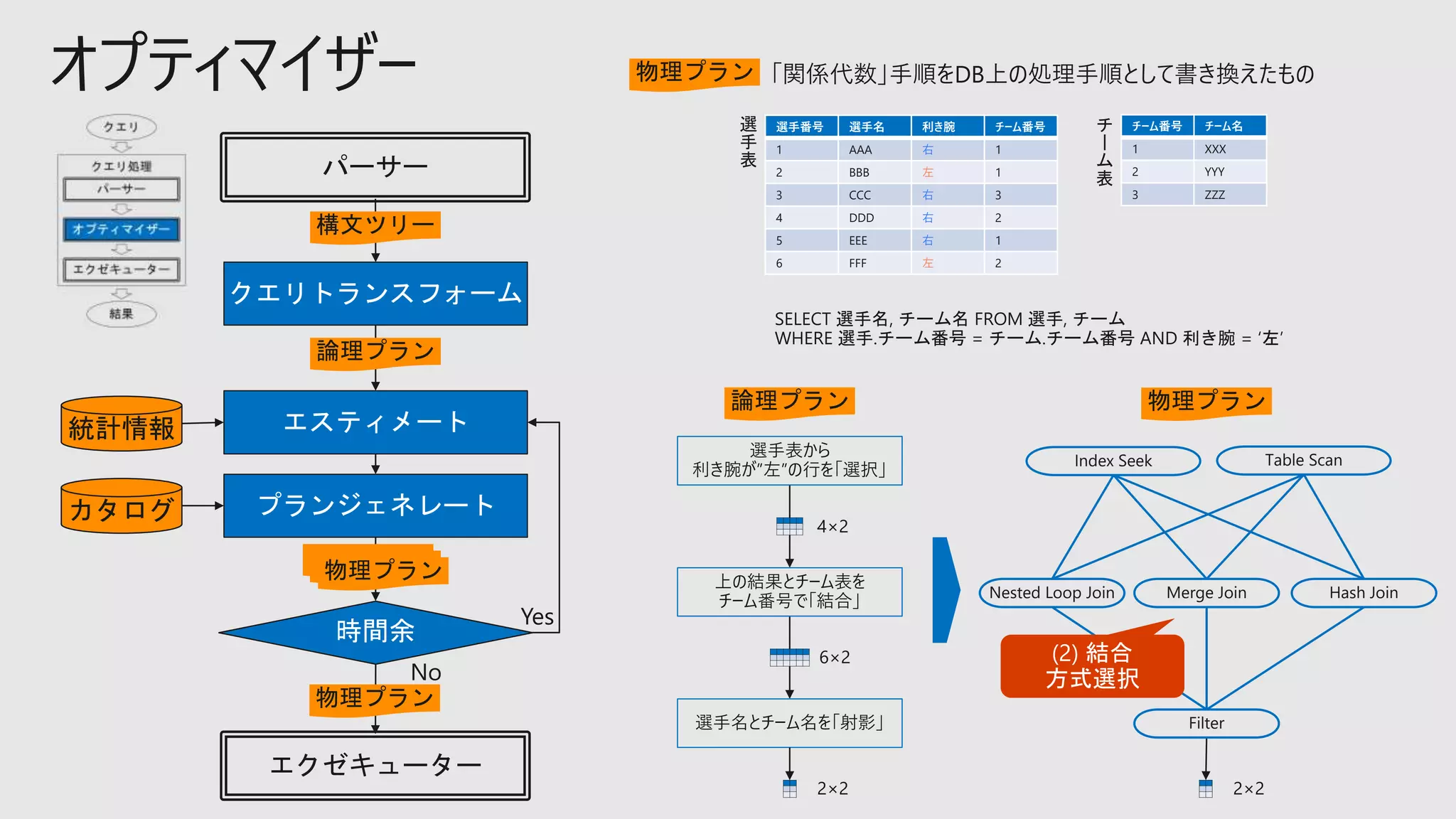
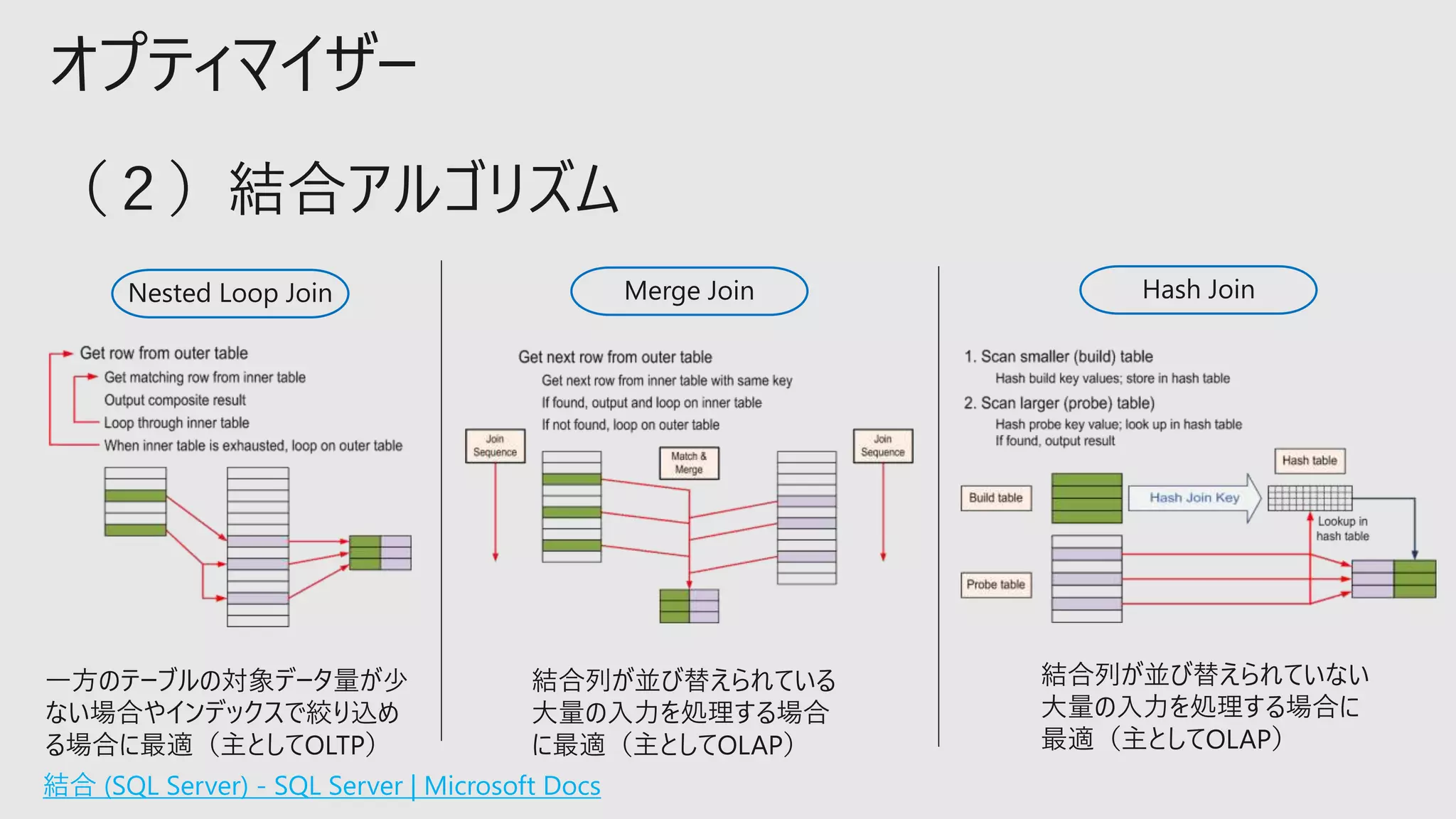
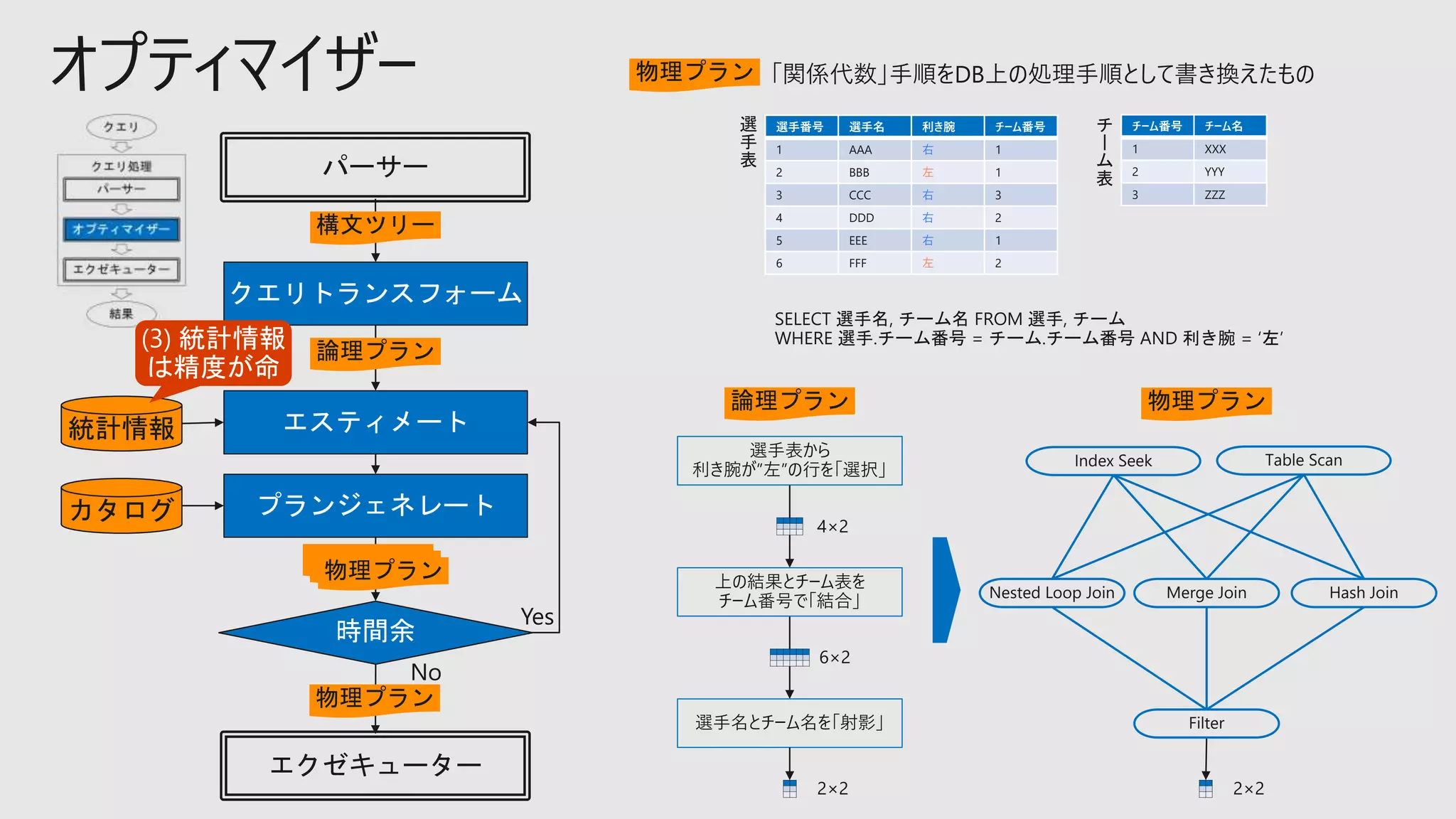
オプティマイザー
ヒント (Transact-SQL) -SQL Server | Microsoft Docs
例)結合順序の指定
SELECT * FROM A
JOIN B on A.ID = B.ID
JOIN C on A.ID = C.ID
OPTION (FORCE ORDER)
例)利用したい結合方式の指定
SELECT * FROM A
JOIN B on A.ID = B.ID
OPTION (MERGE JOIN)
例)実行プランを直指定
SELECT * FROM A
JOIN B on A.ID = B.ID
OPTION (USE PLAN N’XMLフォーマットのプラン’)
例)利用したいインデックスの指定
SELECT * FROM A
WHERE IDX_A_COL = 1
OPTION (TABLE HINT(A, INDEX(IDX_A_COL)))
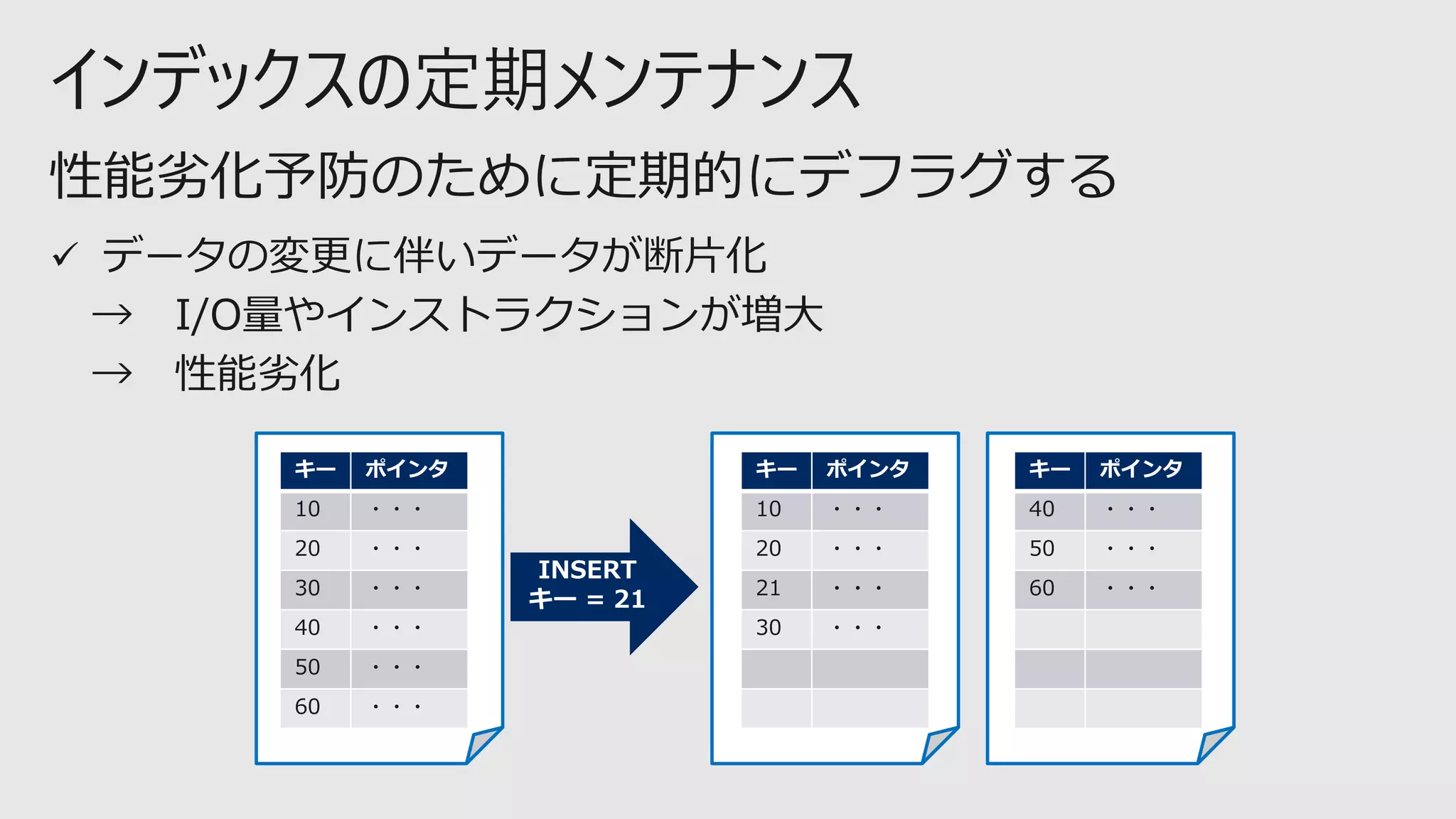
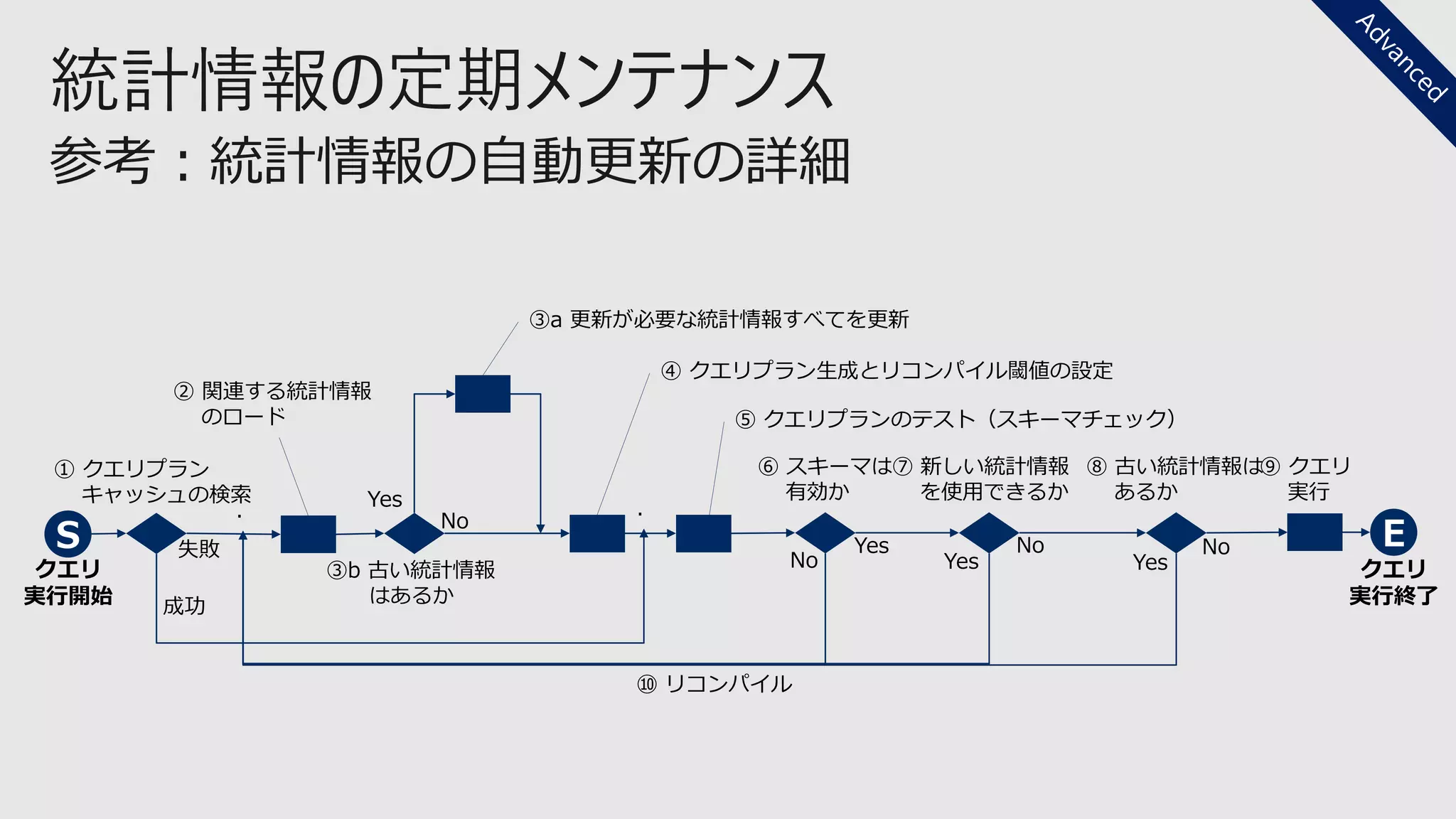
インデックスの定期メンテナンス
⚫ 外部断片化
➢ インデックス論理順とファイル内物理順の不一致度合いを示す
➢データ順が不連続状態になることでのアクセス効率低下
断片化の種類とその影響
10
- 11
index
record
11
10 20
index
record
12
p n
index
record
13
p n
index
record
14
p n
index
record
15
26 16
index
record
16
15 17
index
record
17
16 18
index
record
18
p n
index
record
19
p n
index
record
20
11 23
index
record
21
p n
index
record
22
p n
index
record
23
20 24
index
record
24
23 15
index
record
25
p n
index
record
~
ファイル内の物理番地 →
インデックスの論理順 →
インデックスAの断片
(大きさ=2)
インデックスAの断片
(大きさ=3)
インデックスAの断片
(大きさ=1)
インデックスAの断片化率 = =37.5%
3(赤線ホップ数)
8(総ページ数)
インデックスAの断片
(大きさ=2)




















































































![[Oracle Code Tokyo 2017] Live Challenge!! SQLパフォーマンスの高速化の限界を目指せ!](https://cdn.slidesharecdn.com/ss_thumbnails/livechallengeoraclecodetokyo2017v4-200702090817-thumbnail.jpg?width=640&height=640&fit=bounds)





![[D11] SQL Server エンジニアに知ってもらいたい!! SQL Server チューニングアプローチ by masayuki ozawa](https://cdn.slidesharecdn.com/ss_thumbnails/d11sqlserver-140623035219-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[B31,32]SQL Server Internal と パフォーマンスチューニング by Yukio Kumazawa](https://cdn.slidesharecdn.com/ss_thumbnails/sqlserverinternalupload-140204185245-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![オラクルのデータベースセキュリティへの取り組み [2021年2月版]](https://cdn.slidesharecdn.com/ss_thumbnails/202102oracledbsecurityoverview-210215070200-thumbnail.jpg?width=640&height=640&fit=bounds)



































