

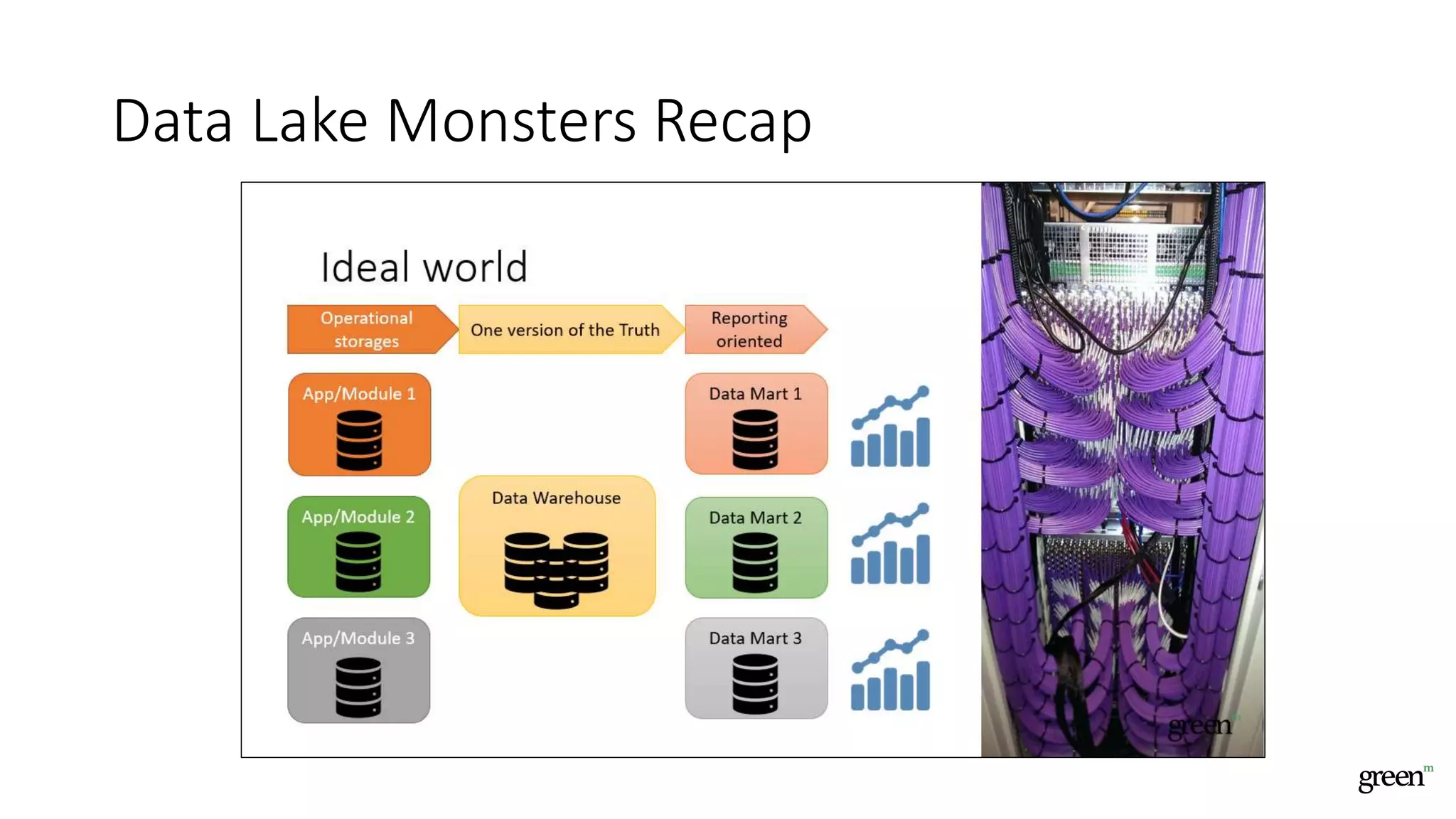

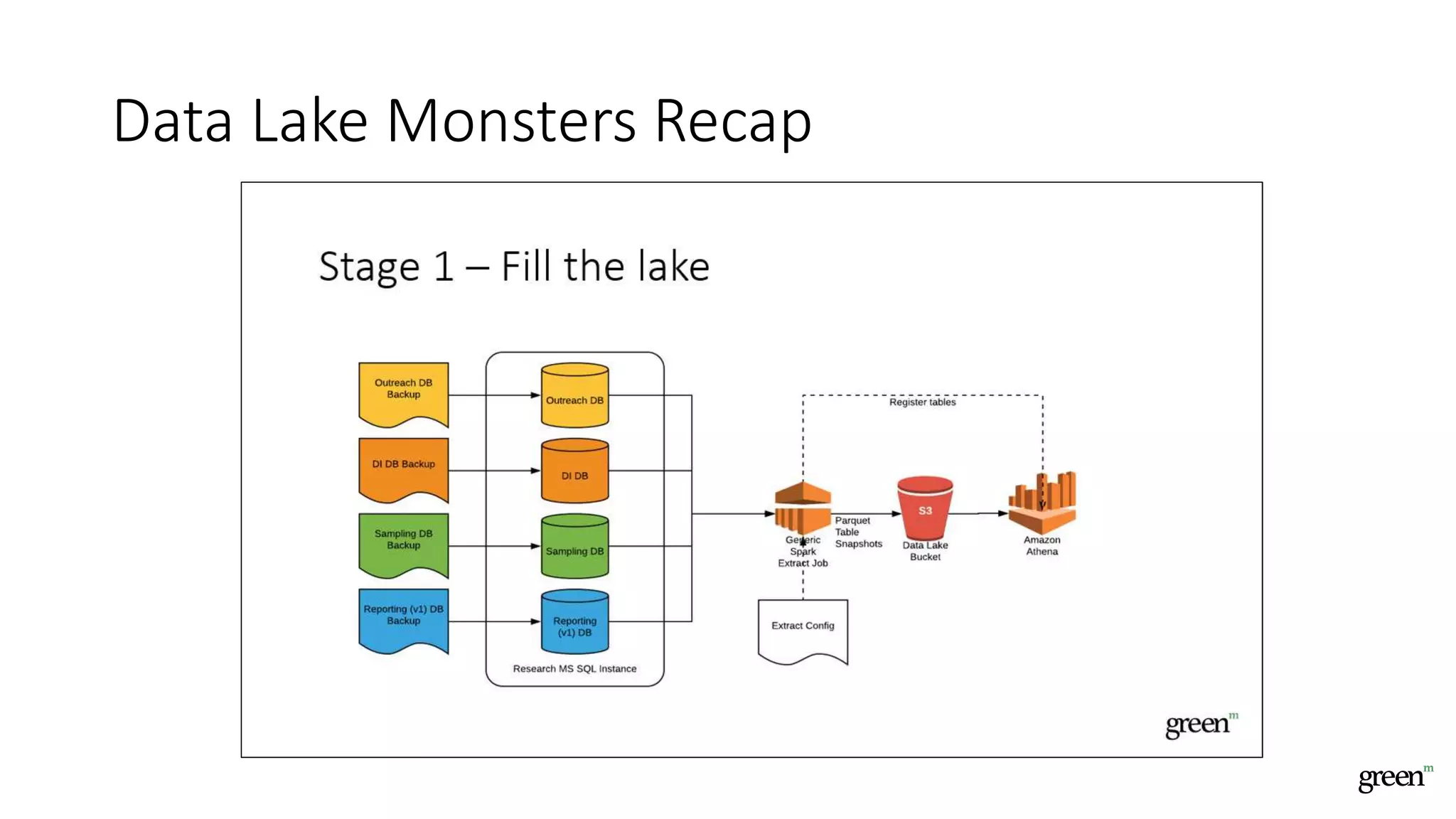
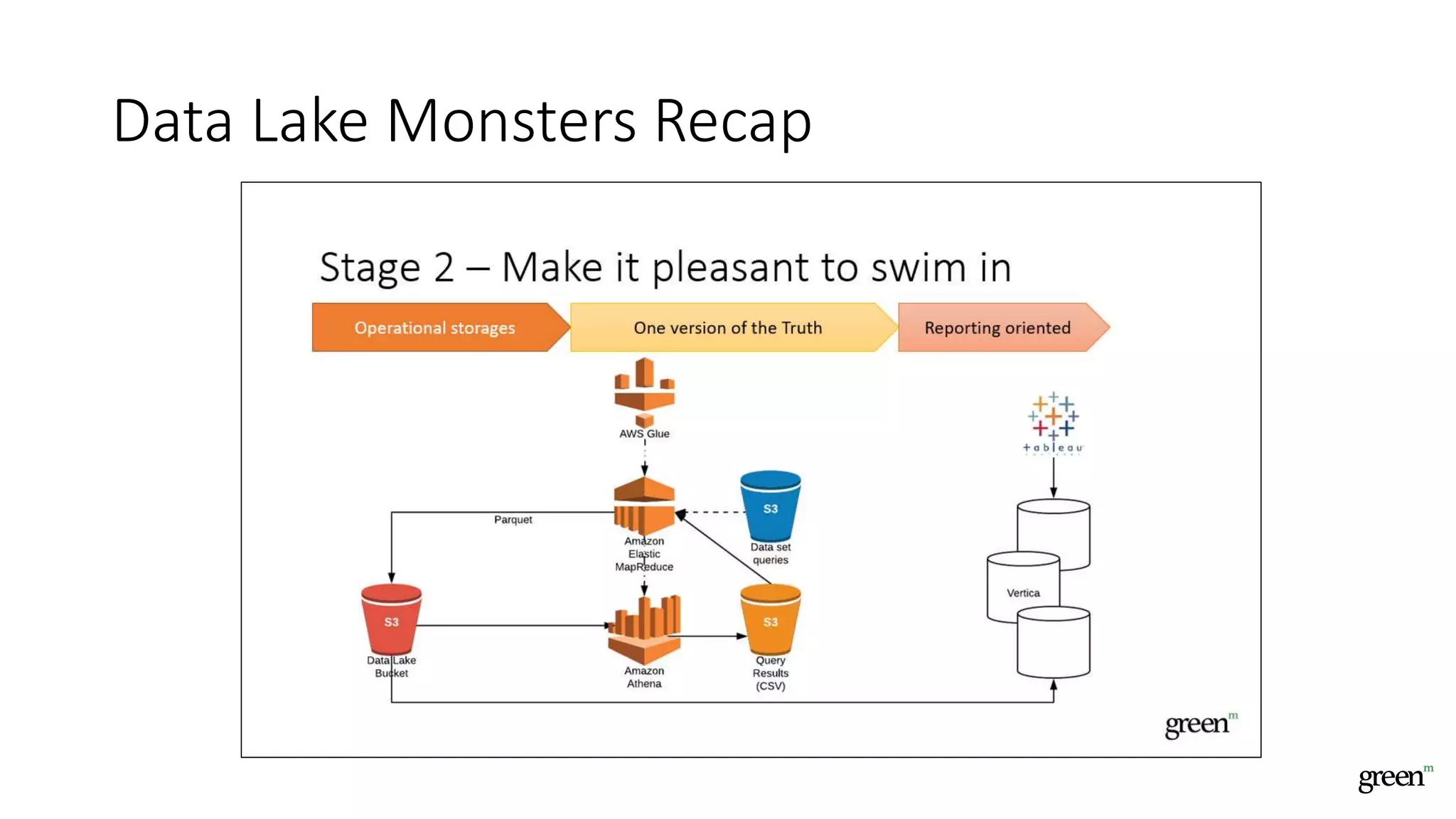


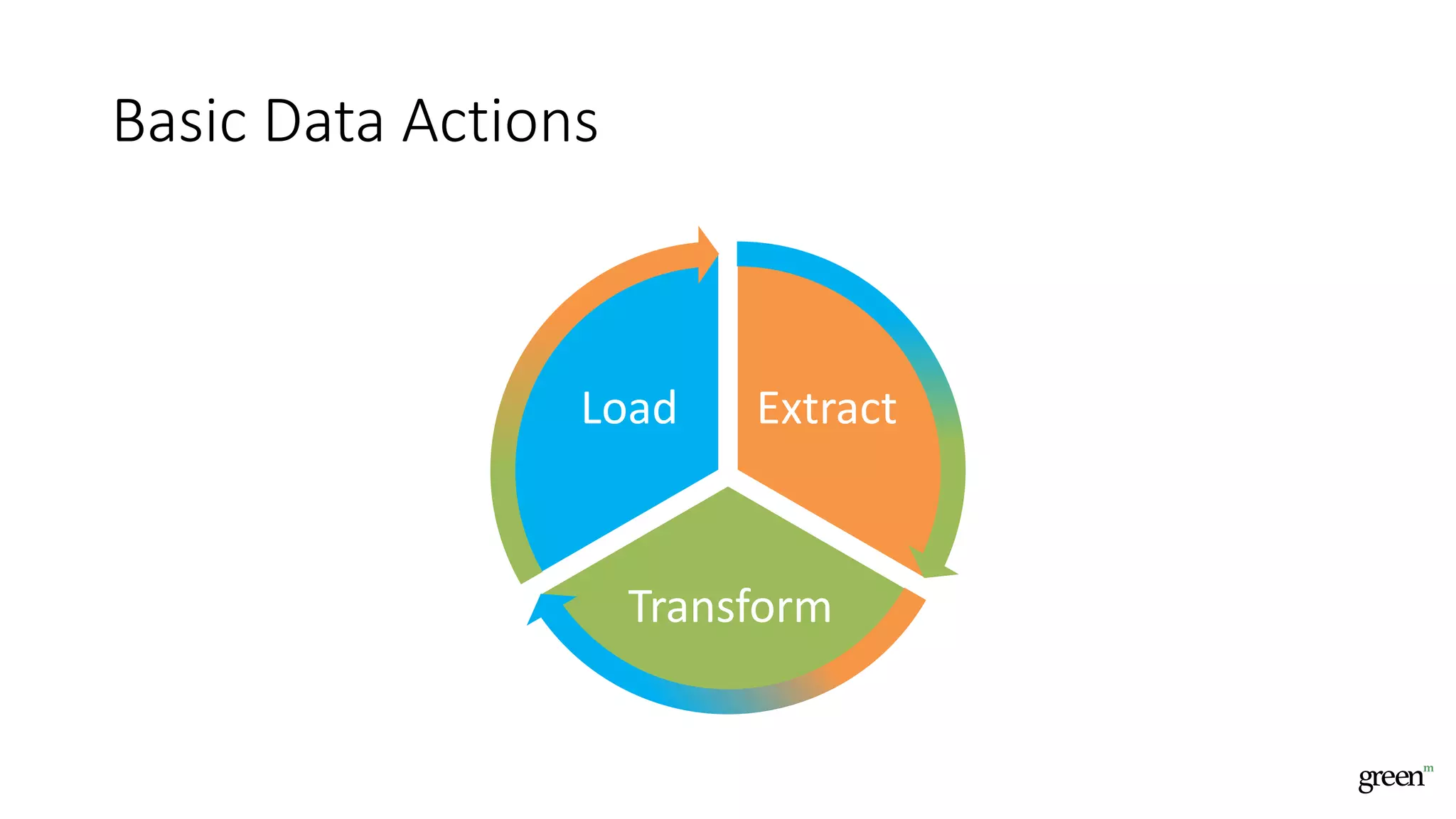
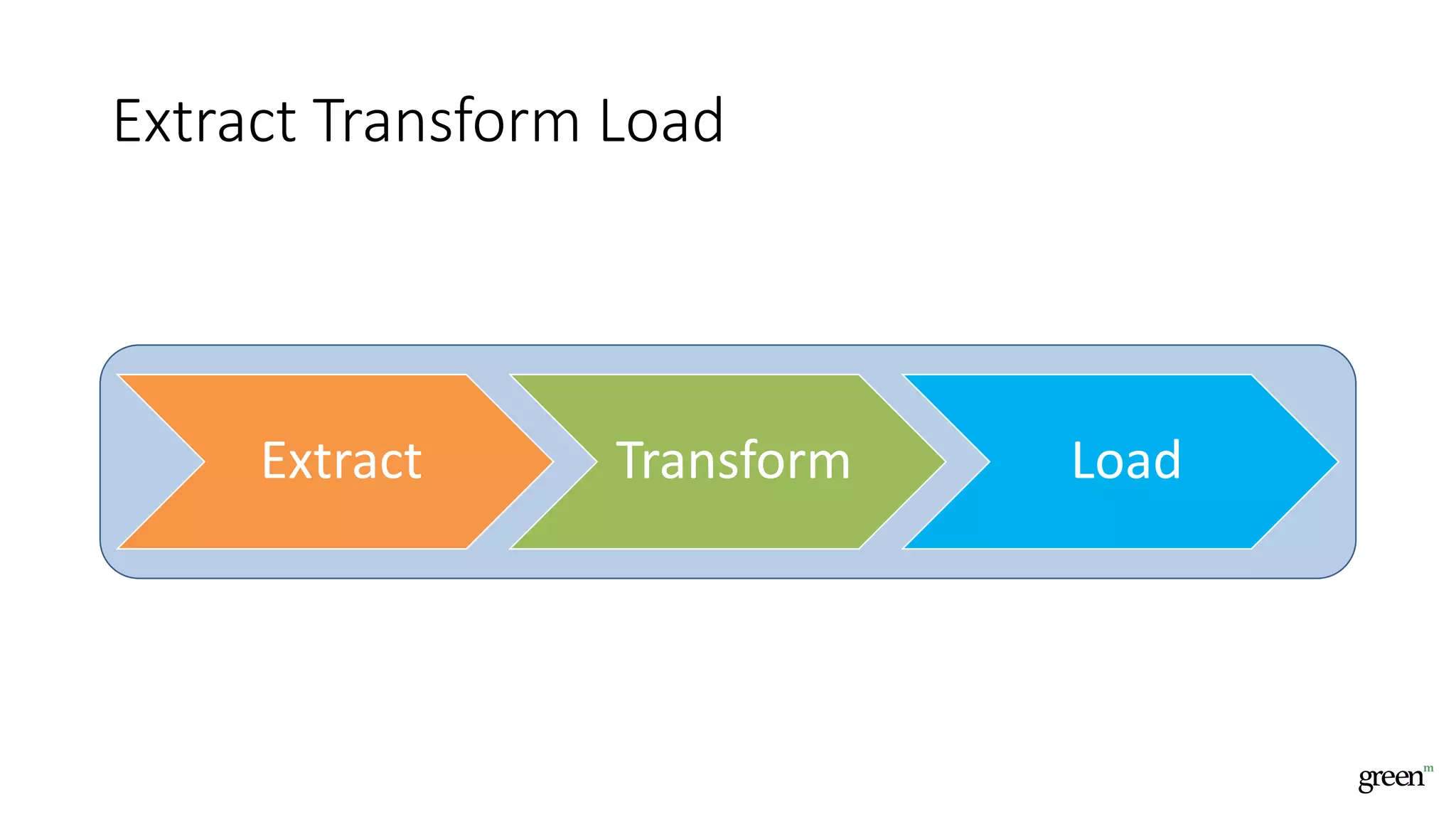
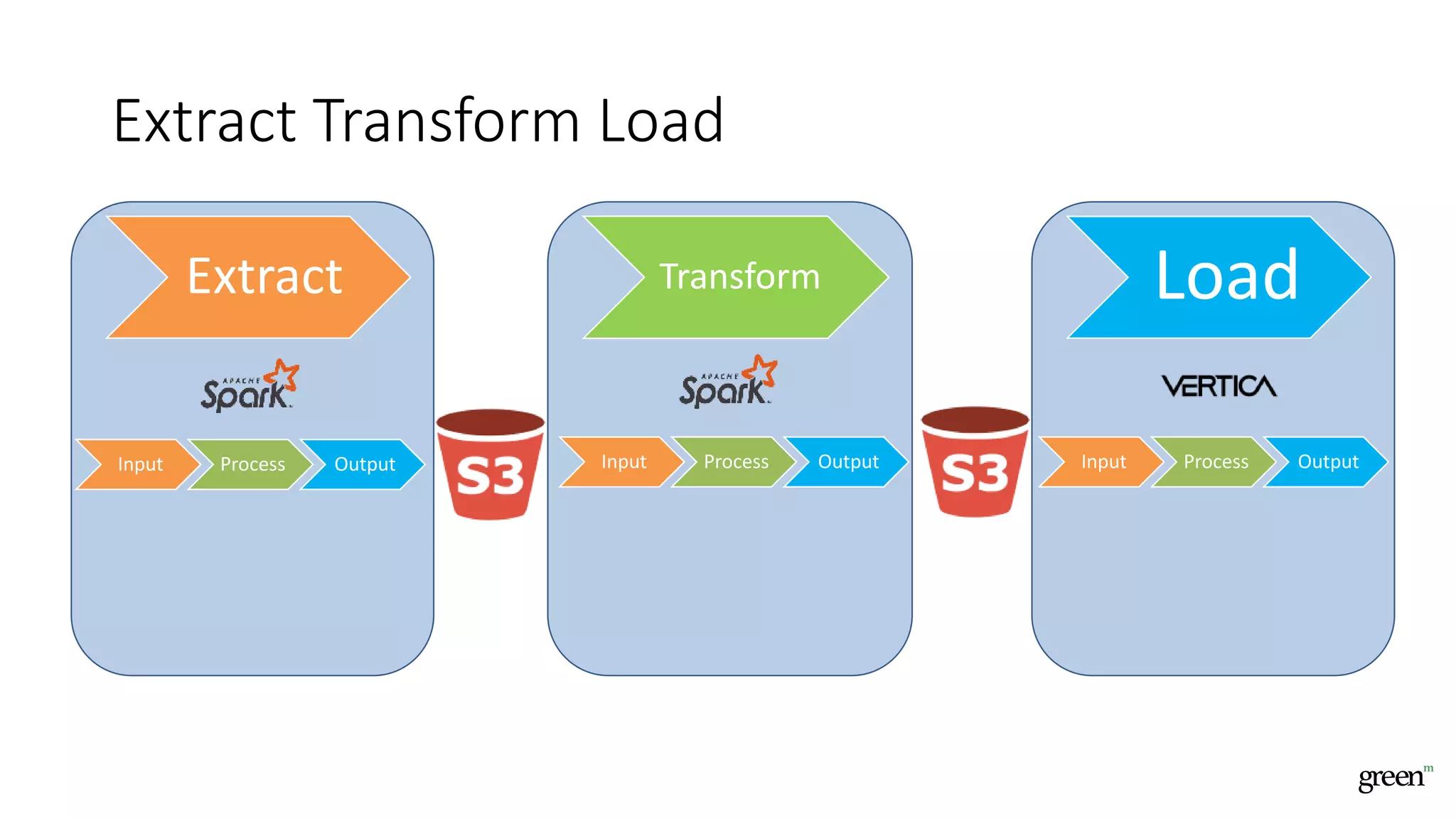
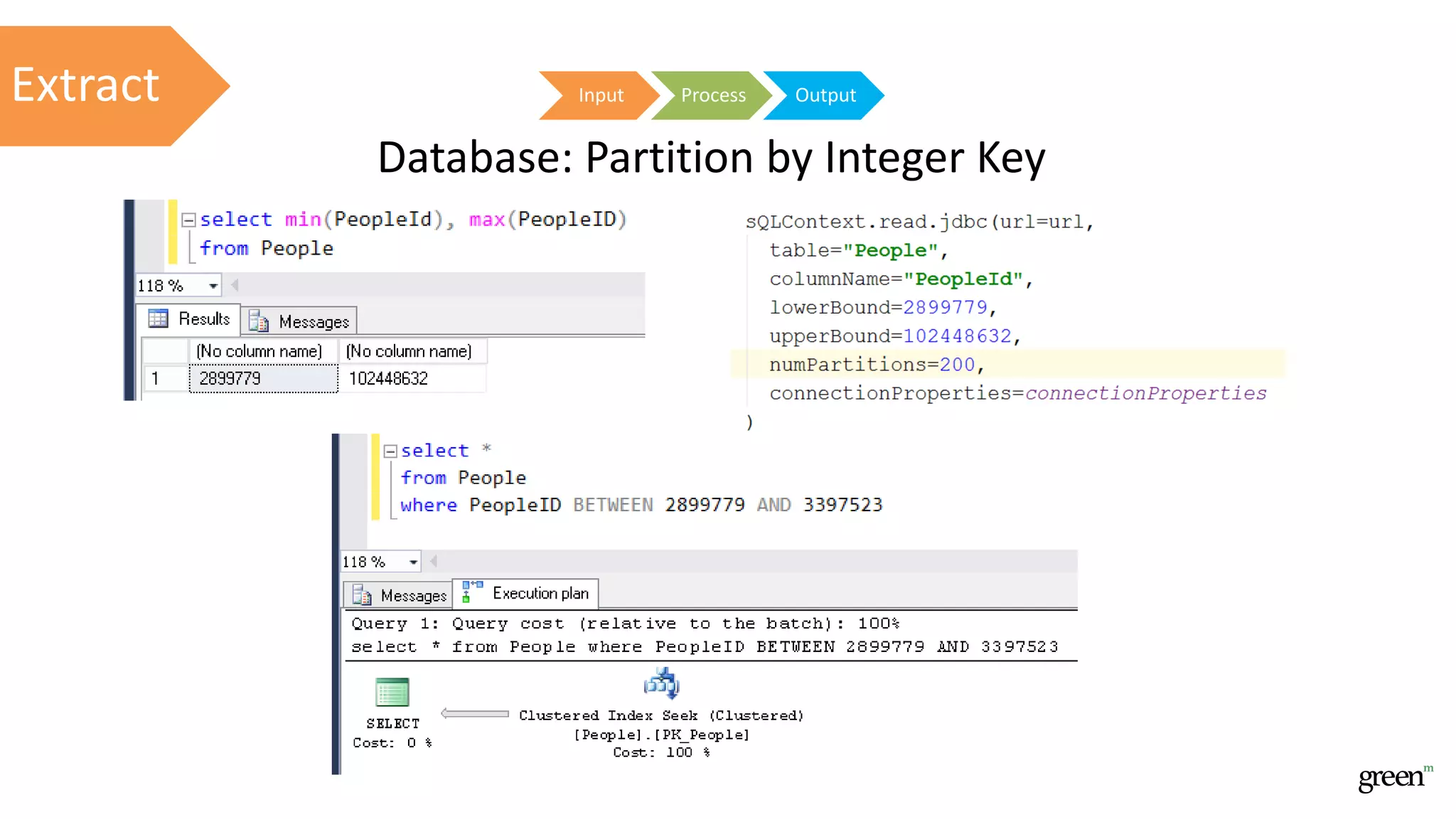
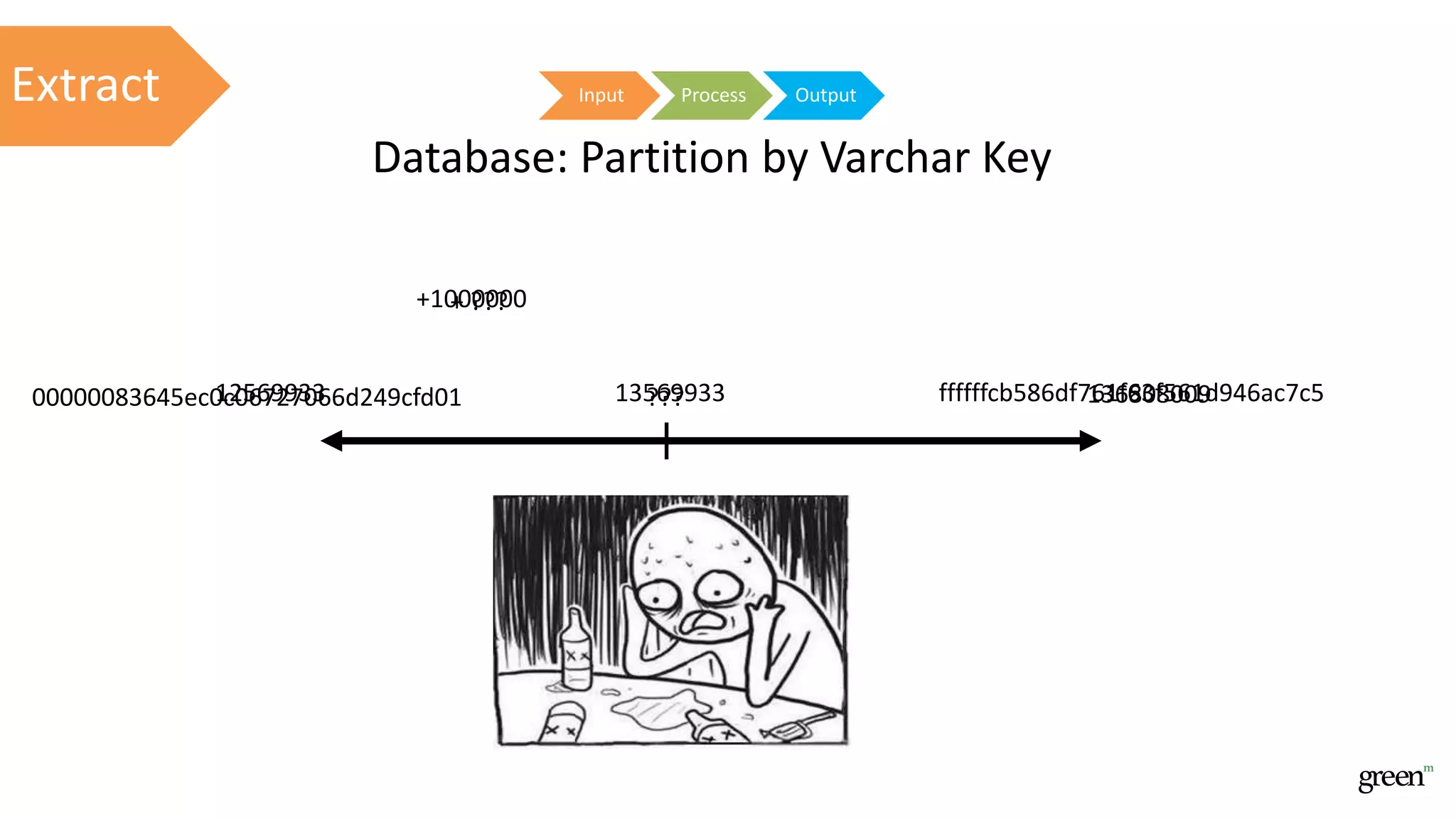
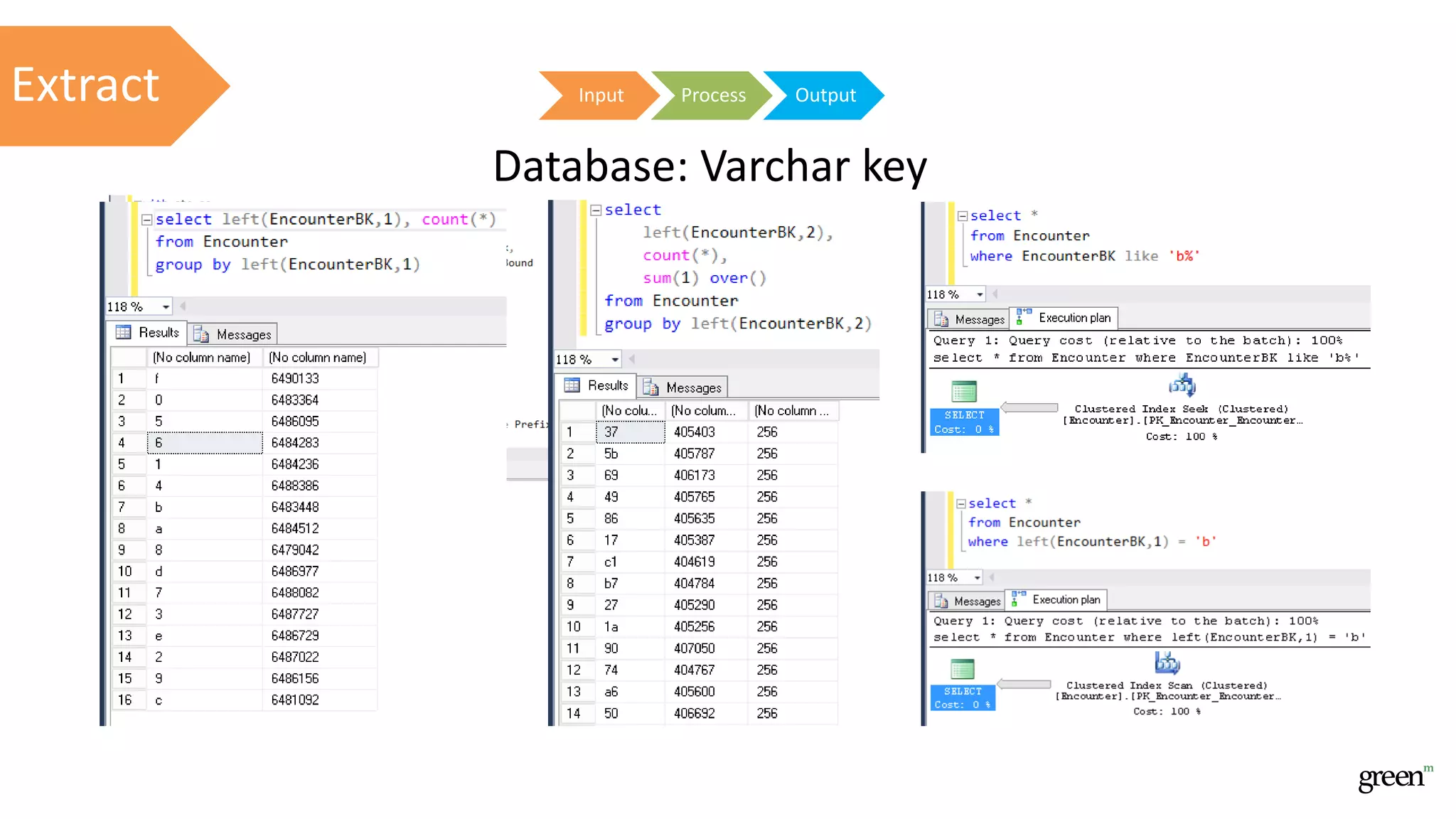


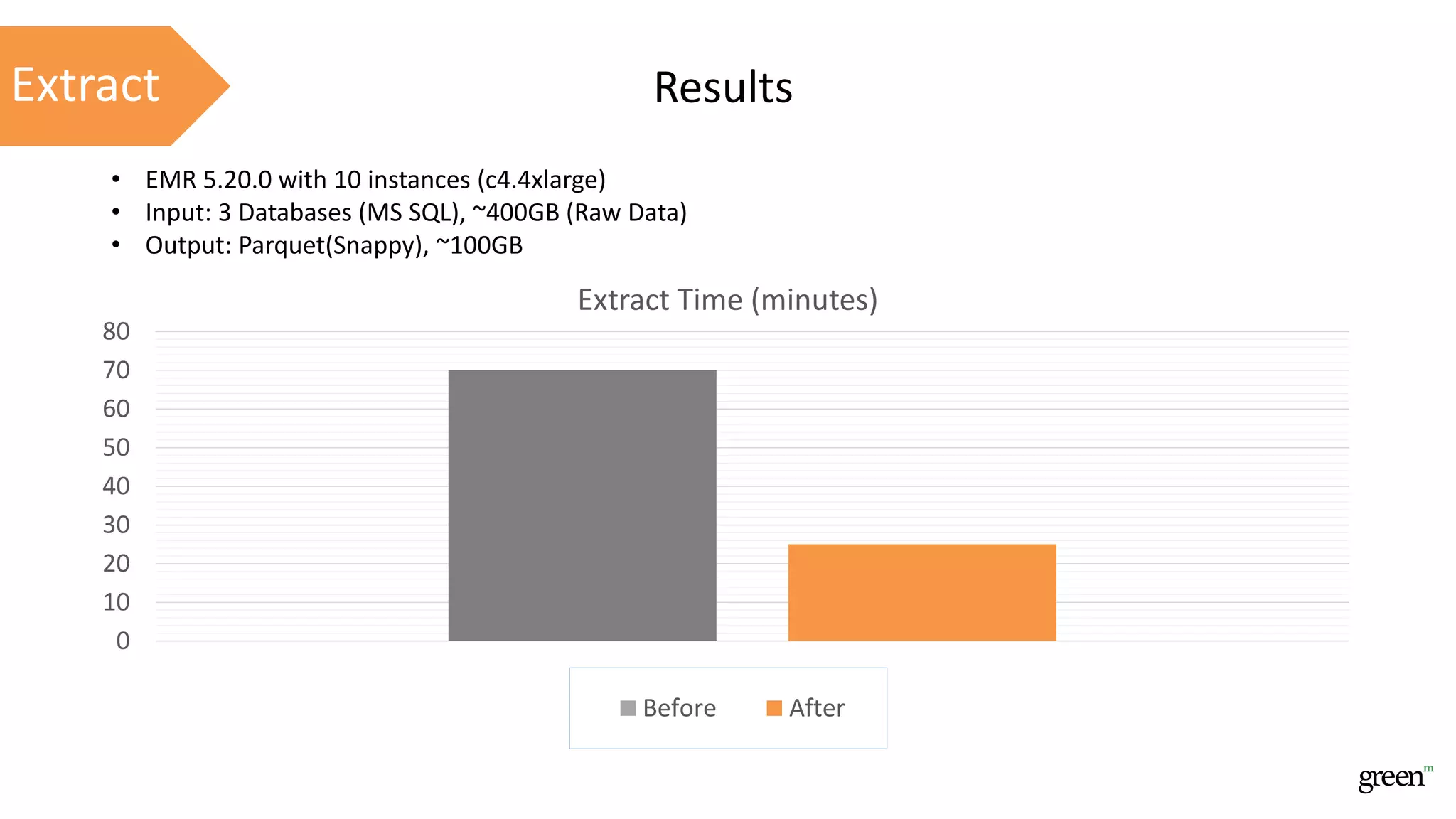
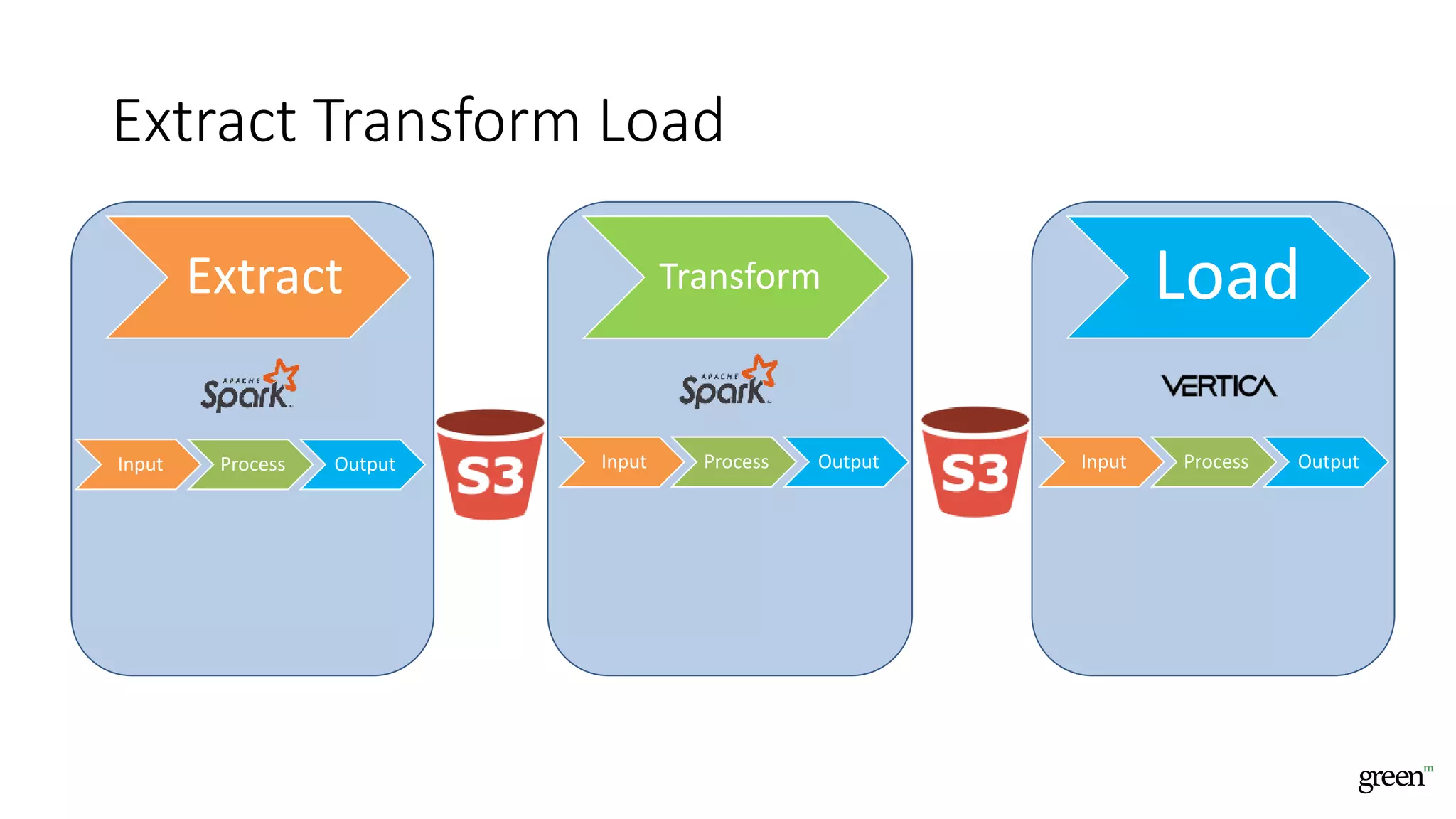
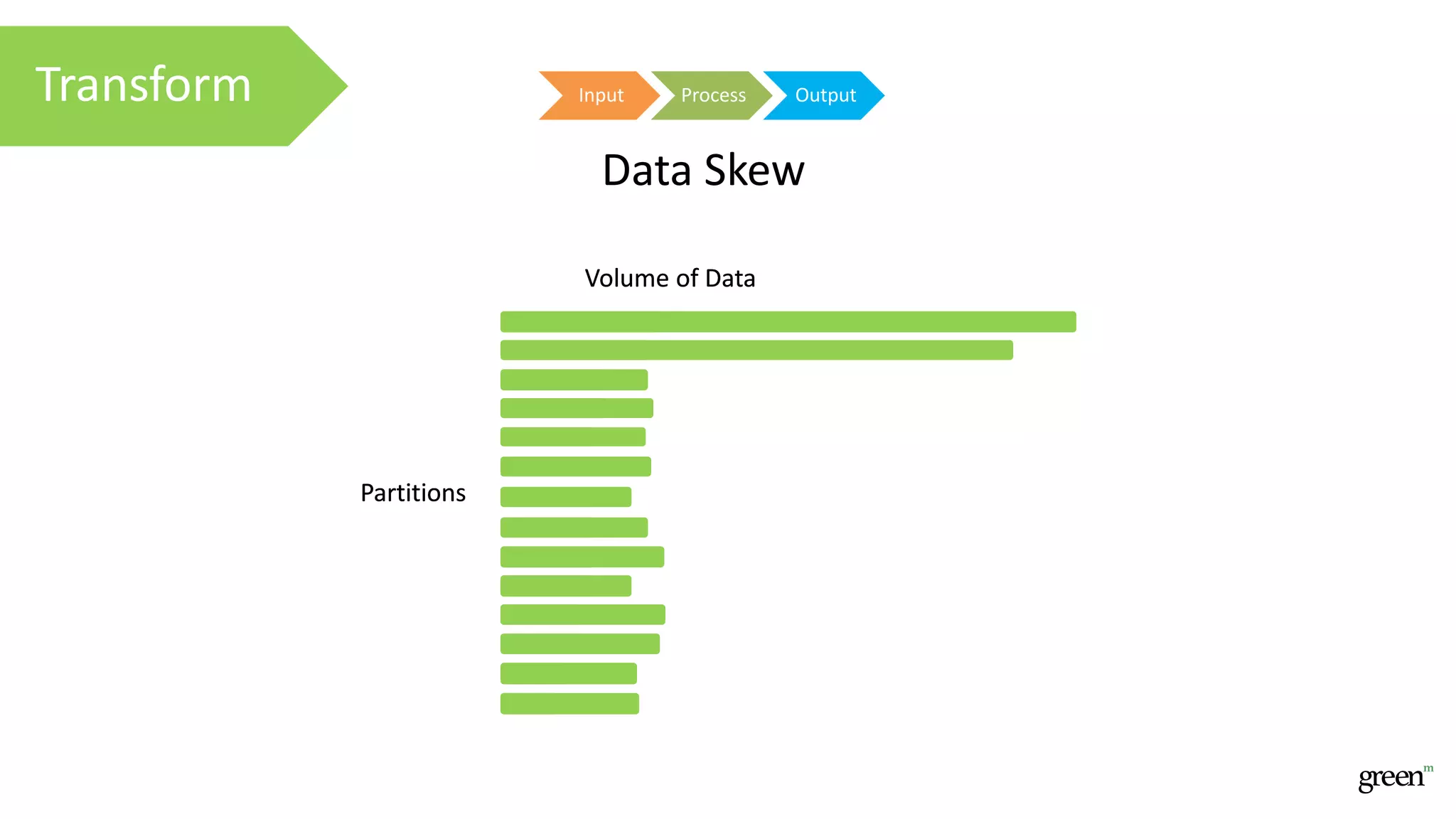
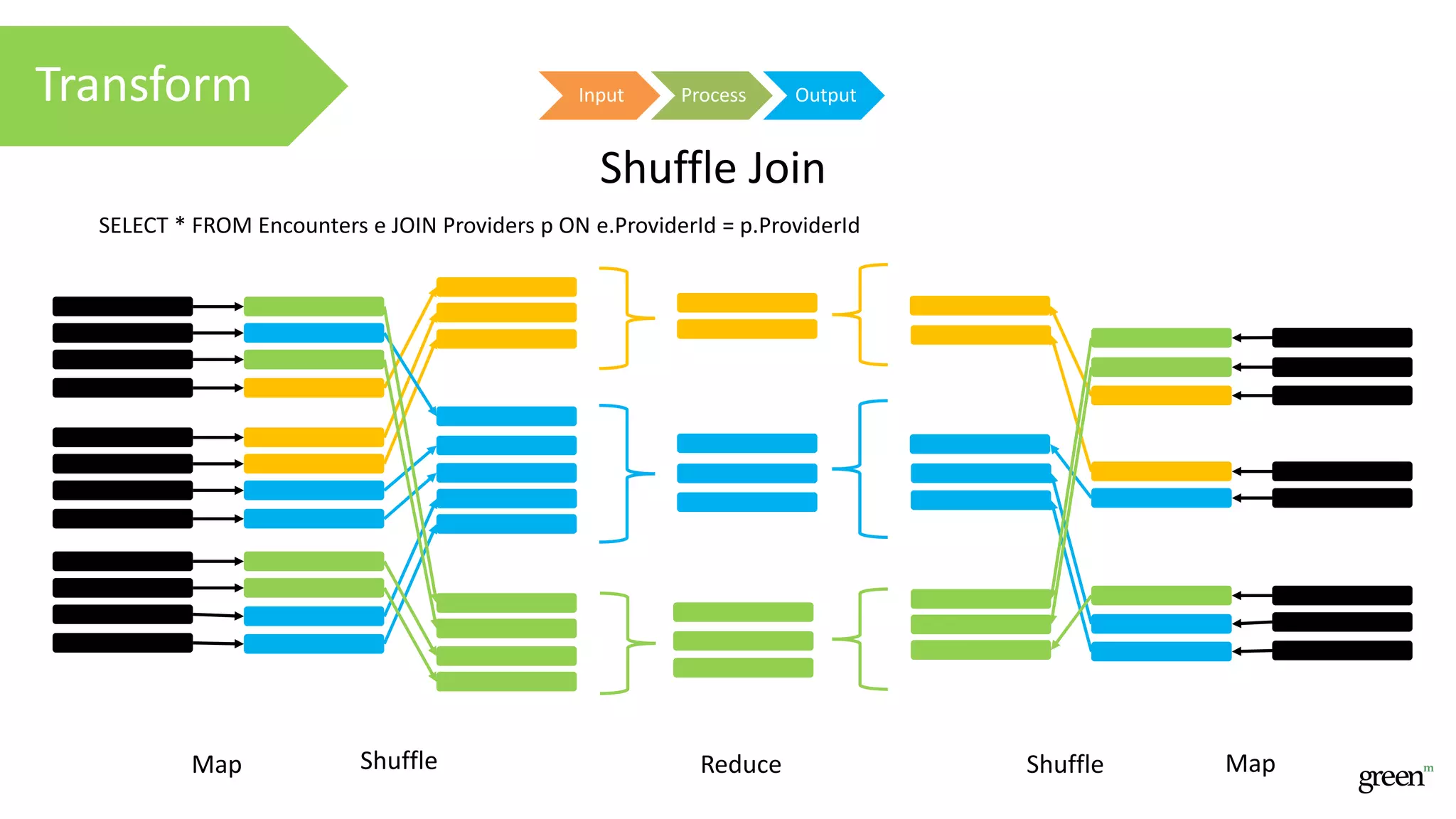
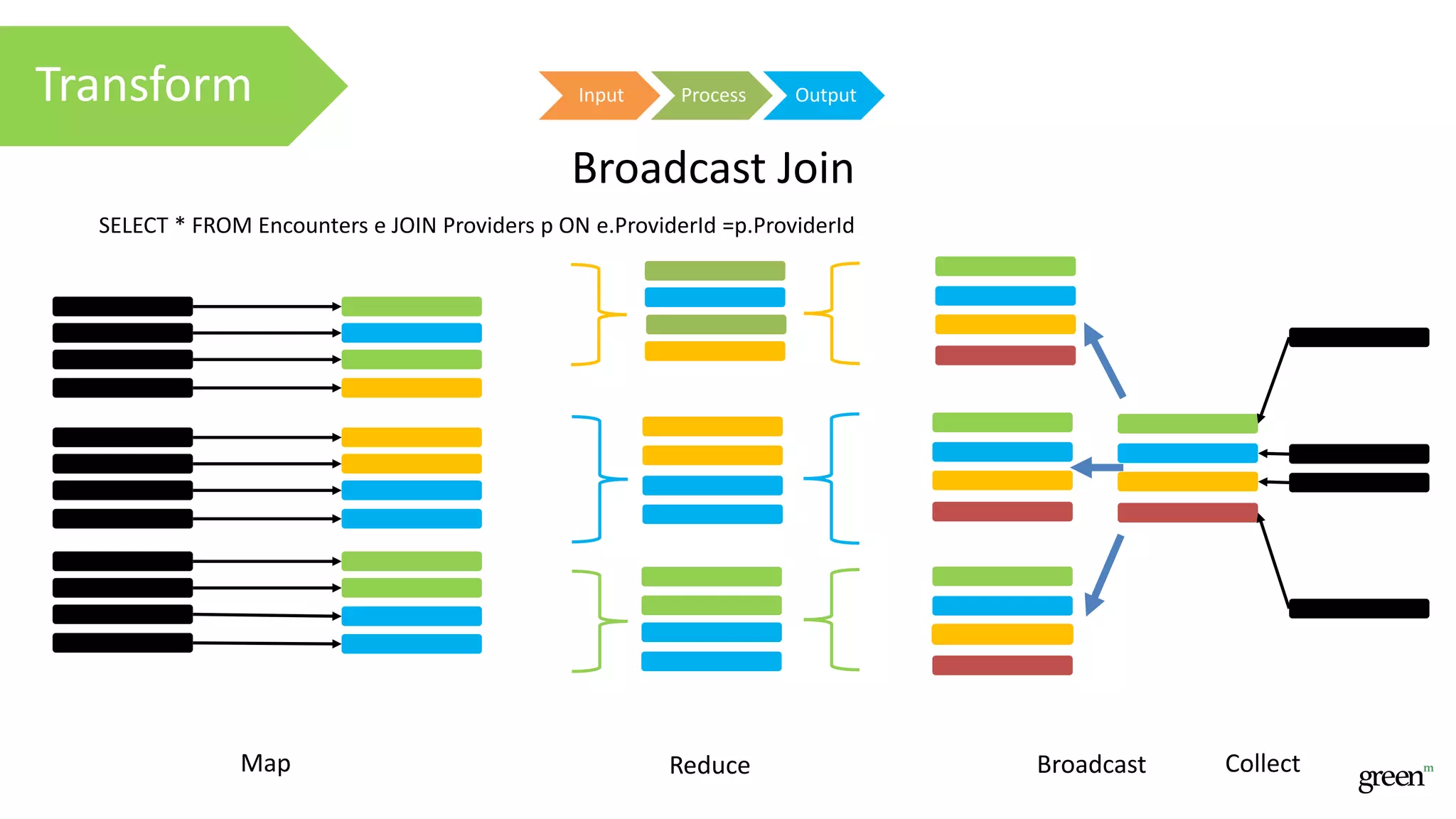

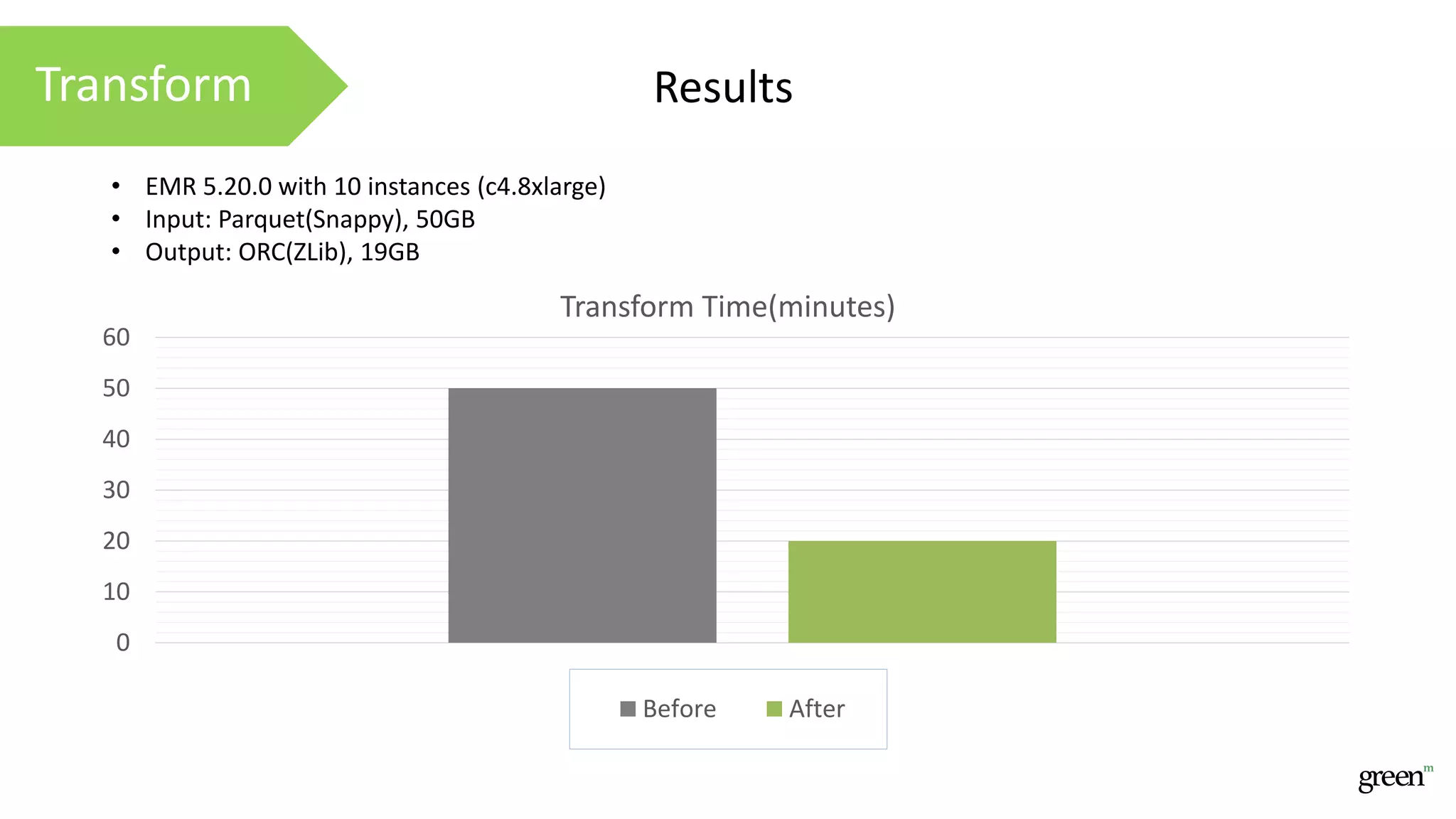
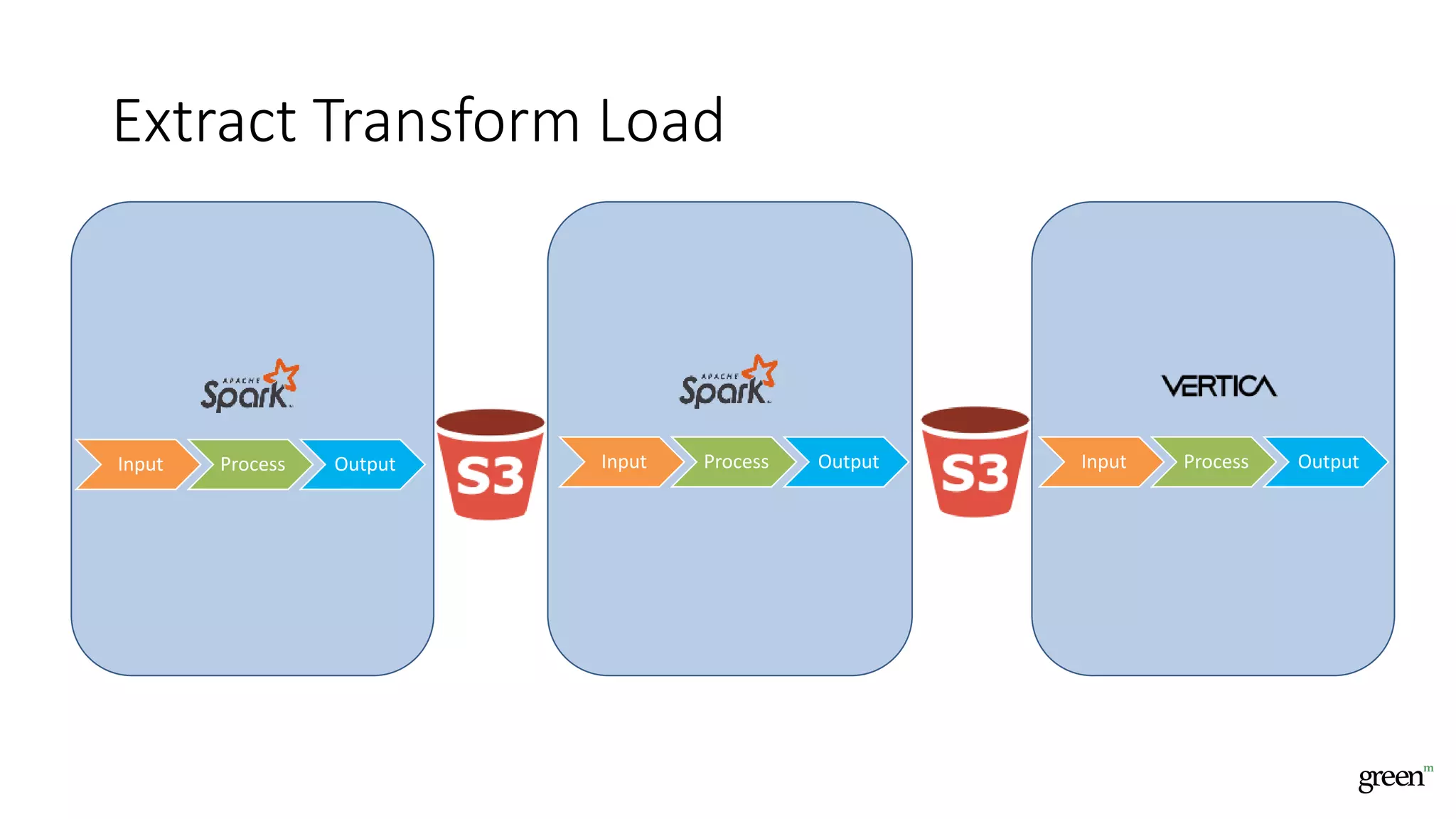

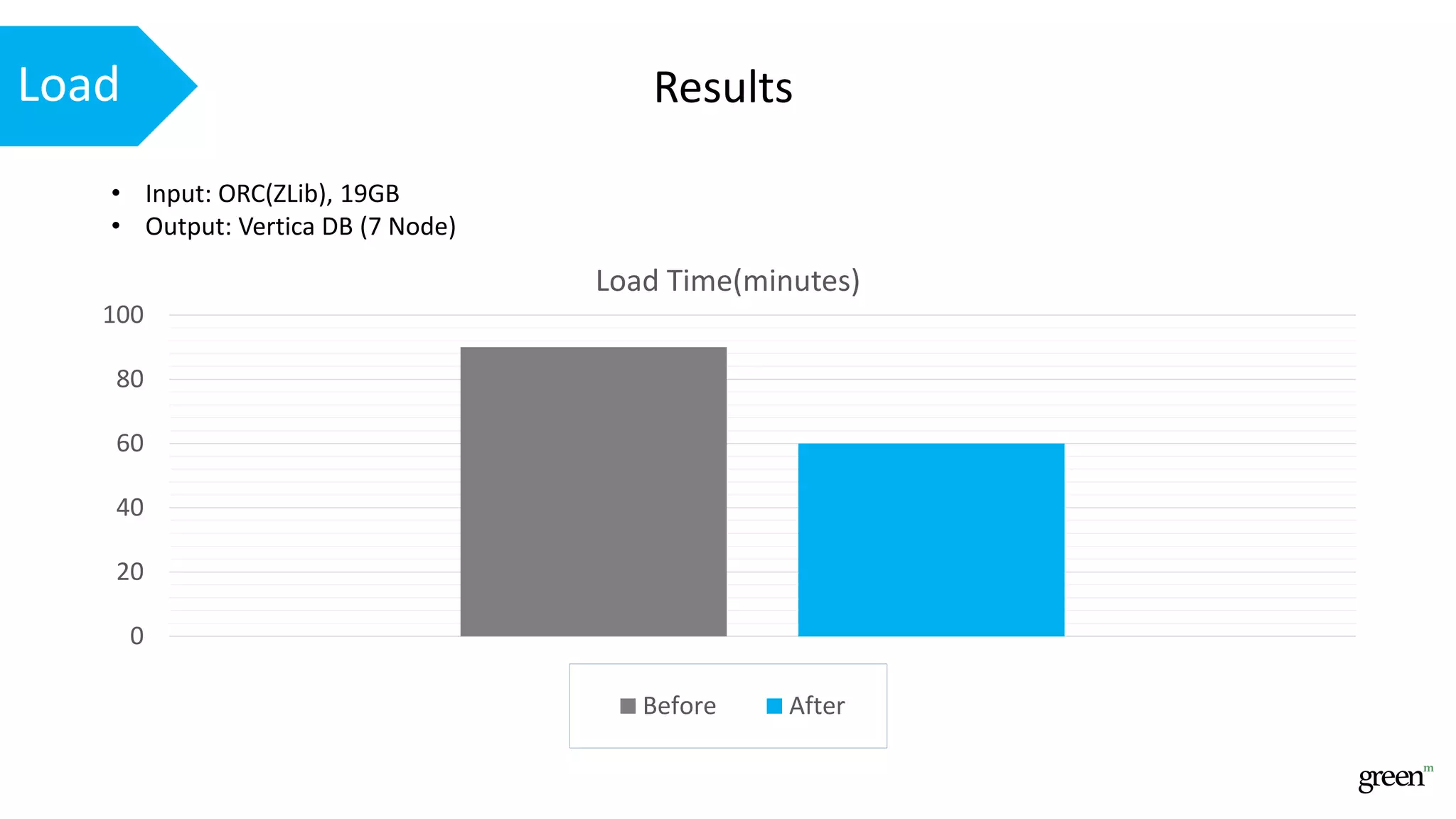

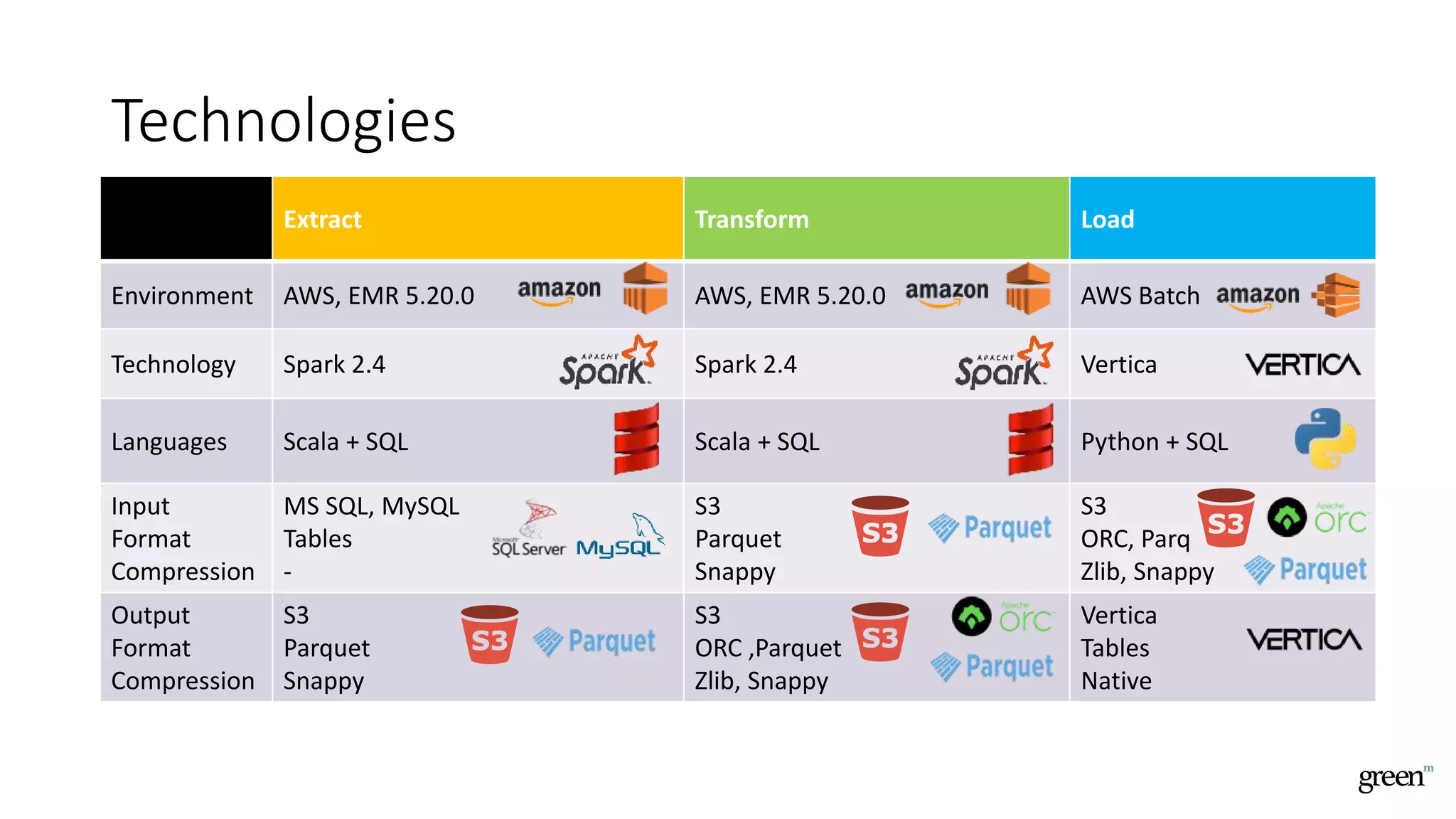





























The document discusses scalable data pipeline challenges and strategies to handle big data, focusing on technologies like AWS and Spark. It highlights the importance of effective data management practices such as partitioning, compression, and choosing the right storage formats to optimize workloads. Additionally, it emphasizes building resilience within architecture to accommodate future data volumes and associated risks.











































































