






















































































































































































The document provides an overview of parametric and non-parametric tests in biostatistics, explaining their definitions, applications, and differences. It details various statistical methods used to analyze health-related data, including t-tests, ANOVA, and non-parametric tests, along with their assumptions and conditions for use. The document underscores the importance of biostatistics in improving health outcomes and evaluating medical interventions.
An introduction to biostatistics by Kapil Gautam at the Institute of Medicine, discussing its history, applications, and testing methods.
Overview of the origins of biostatistics, emphasizing Francis Galton as the father and his use of correlation.
Statistics is the discipline of data analysis; biostatistics applies these methods in health science to improve health outcomes.
Biostatistics determines risk factors for diseases, evaluates drugs, and assesses community health programs.
Differences between parametric tests, which assume data quality, and non-parametric tests, which do not require such assumptions.
Key assumptions of parametric tests and their advantages, including power in detecting true differences. Overview of various parametric tests (e.g., t-tests, ANOVA) for analyzing different data types and comparison goals.
Definition, situations for use, advantages and disadvantages of non-parametric tests in statistical analysis.
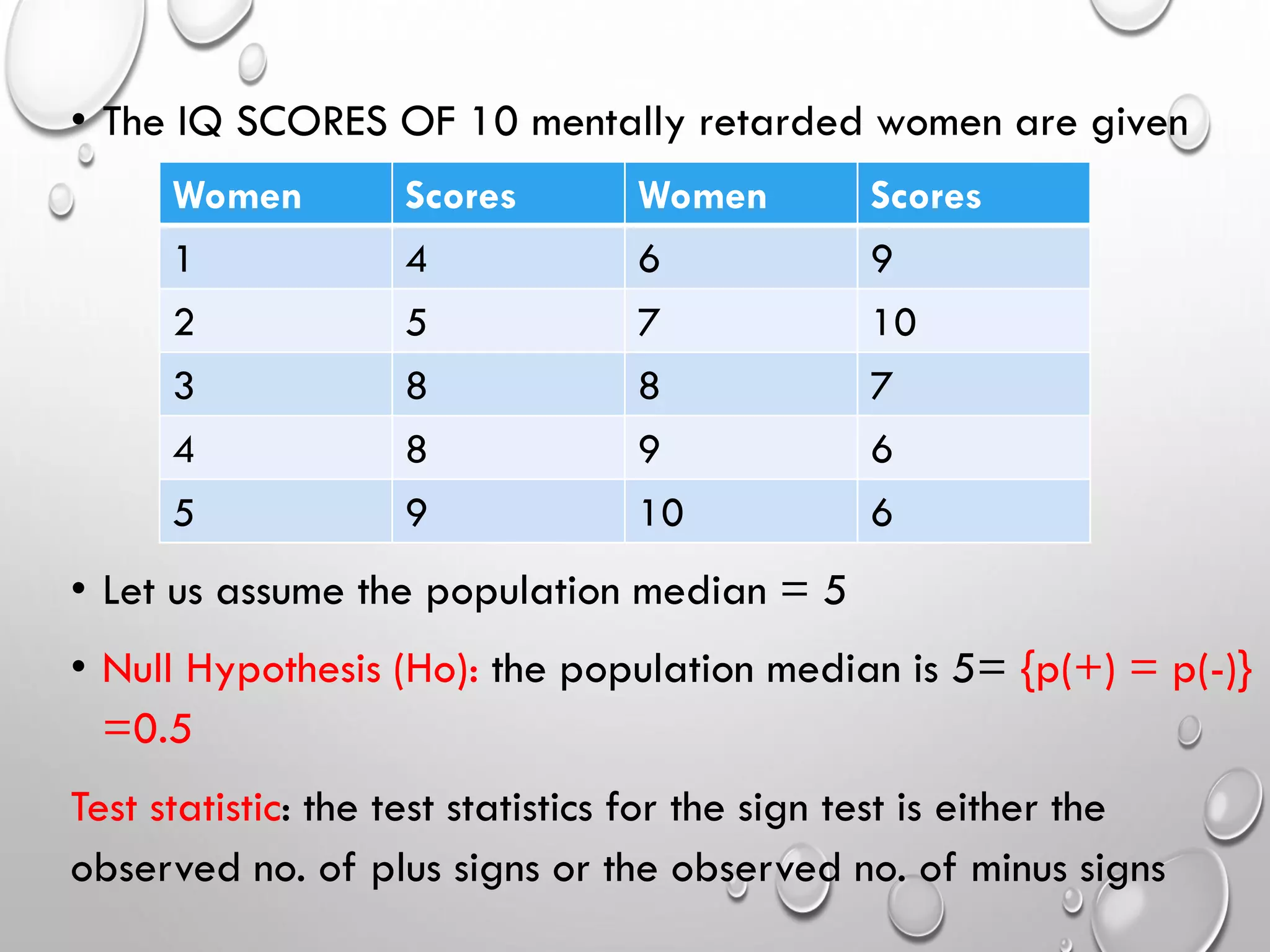
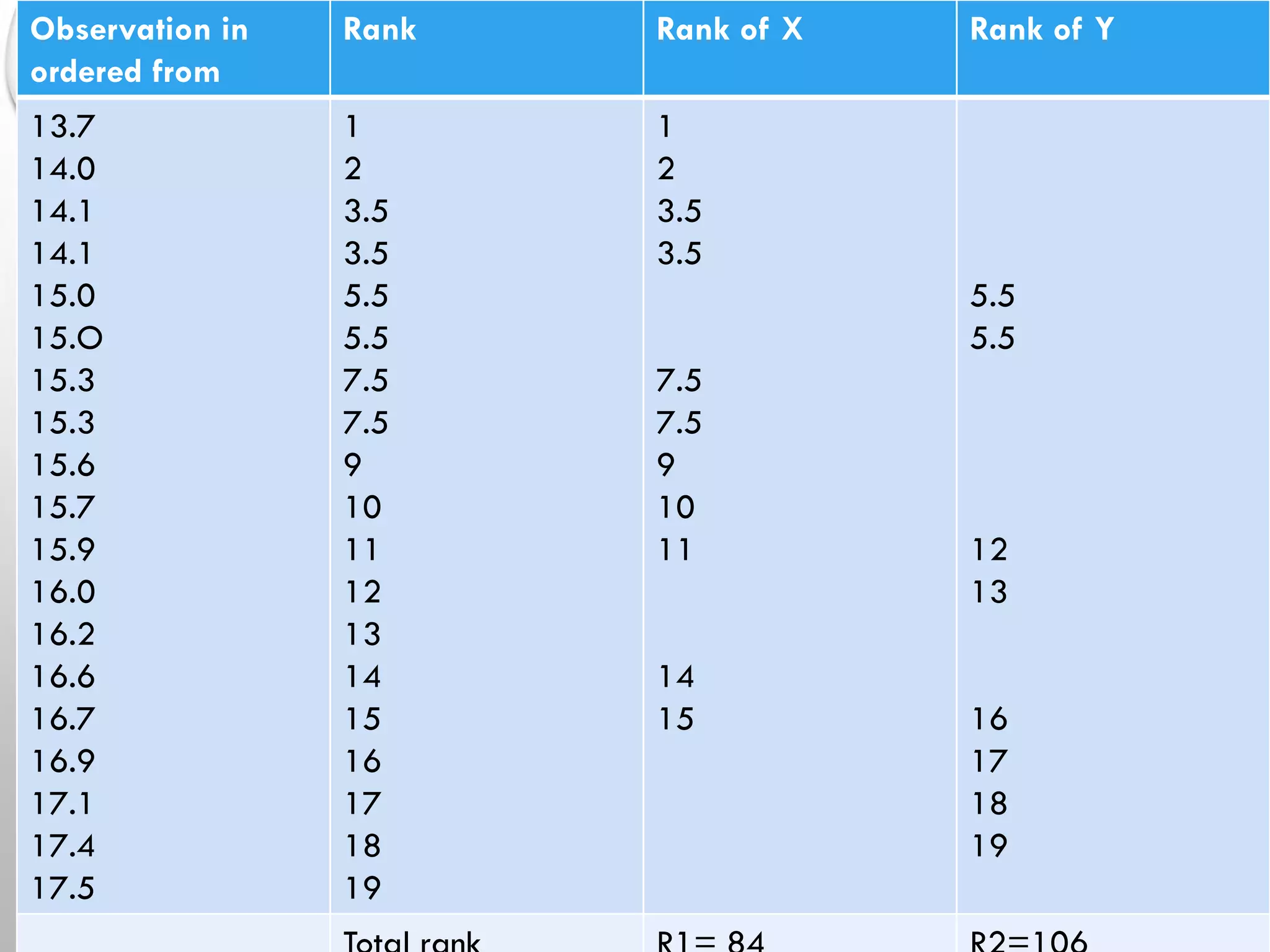
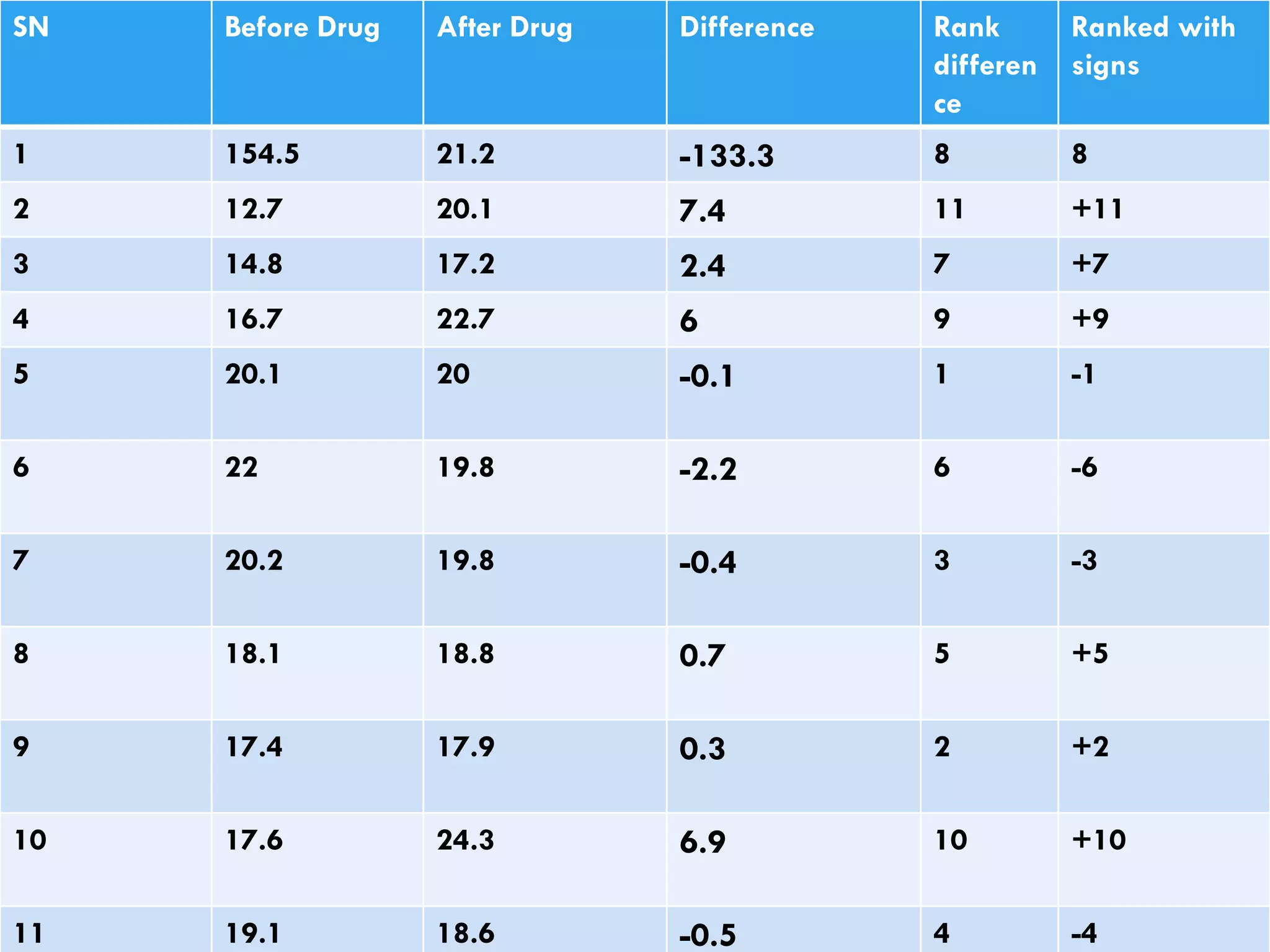
Different non-parametric tests (e.g., Mann-Whitney, Wilcoxon tests) with examples illustrating their applications.
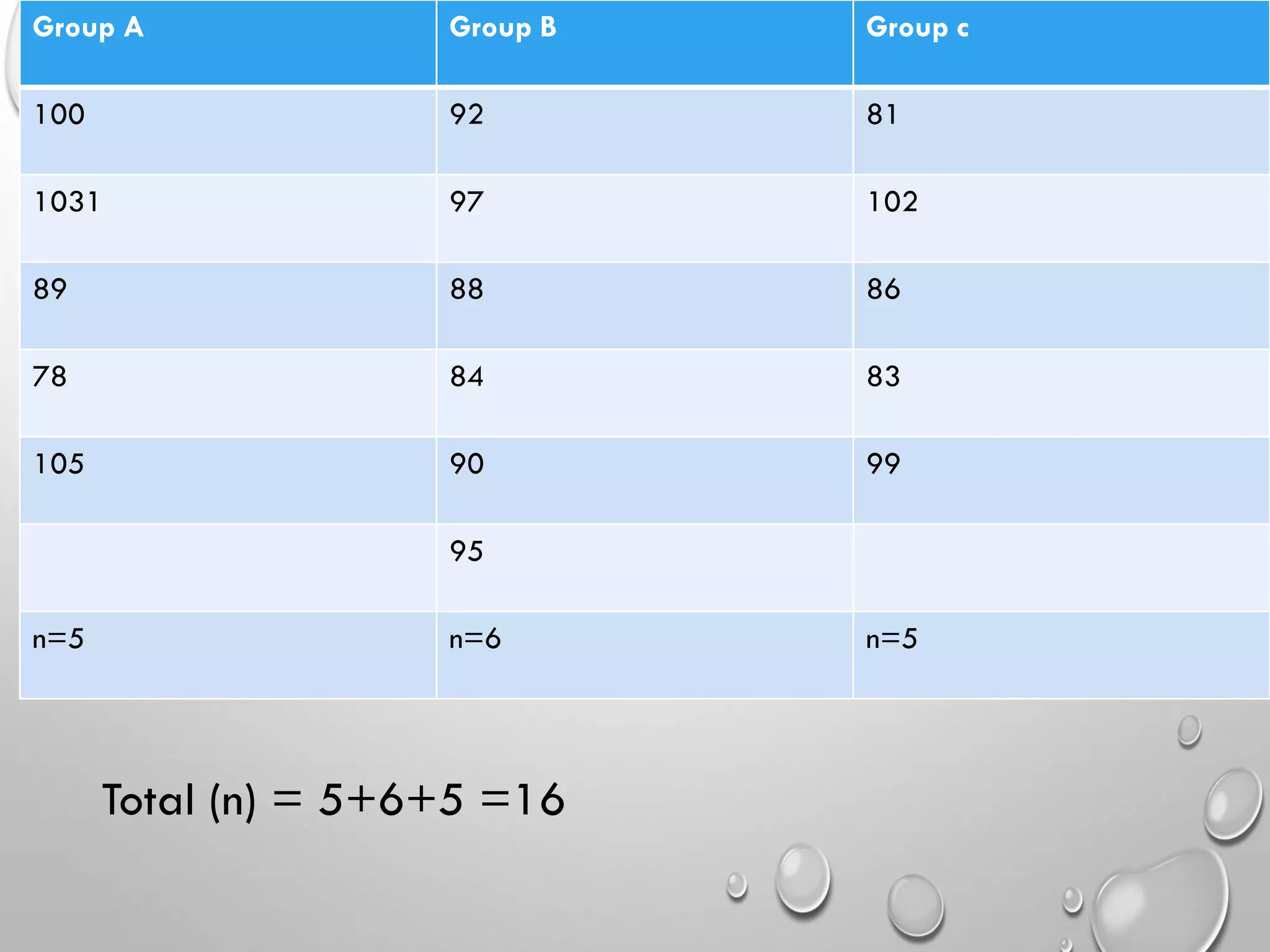
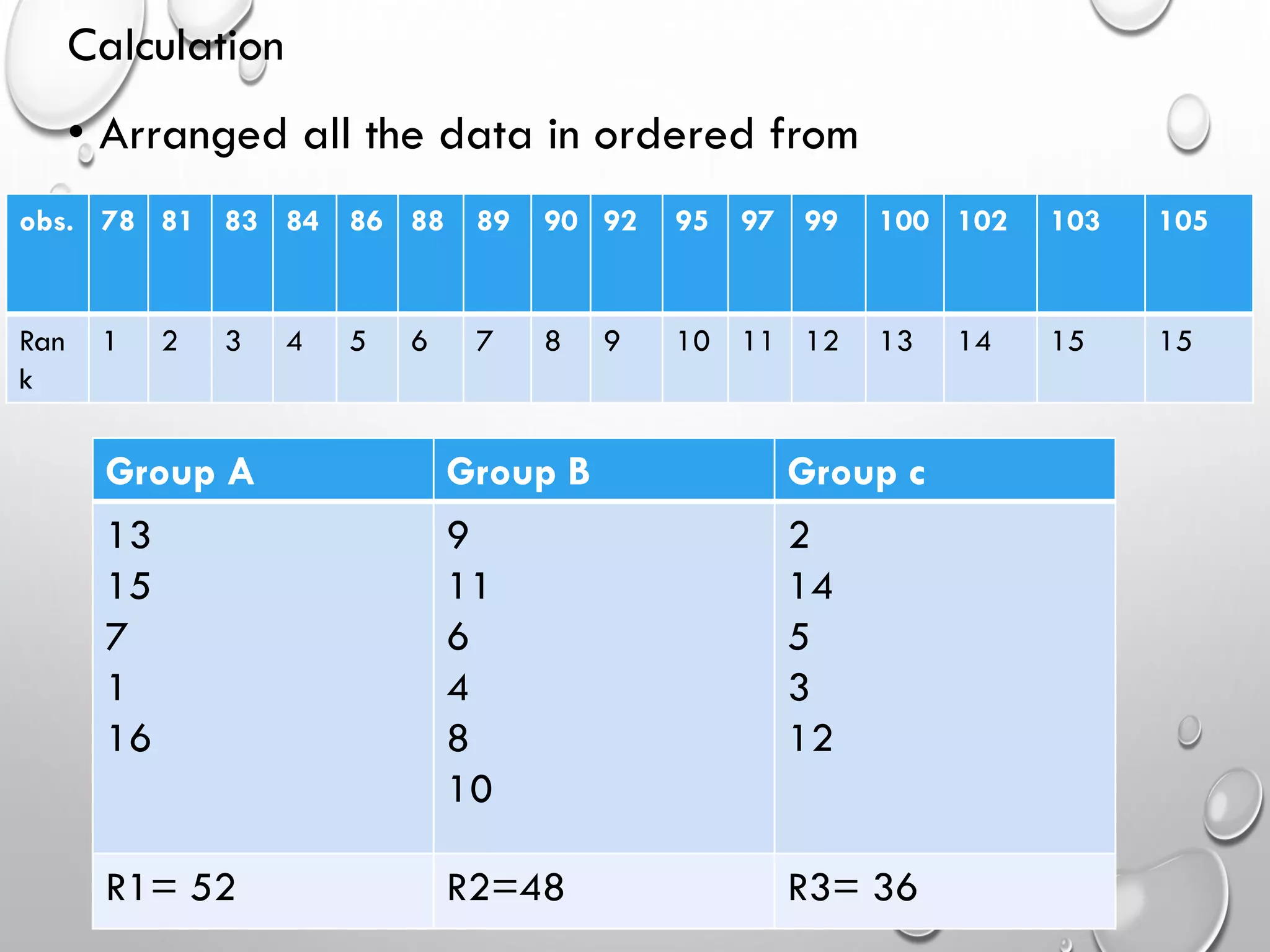
Non-parametric tests like Kruskal-Wallis for rank analysis and Chi-Square for analyzing frequency data.
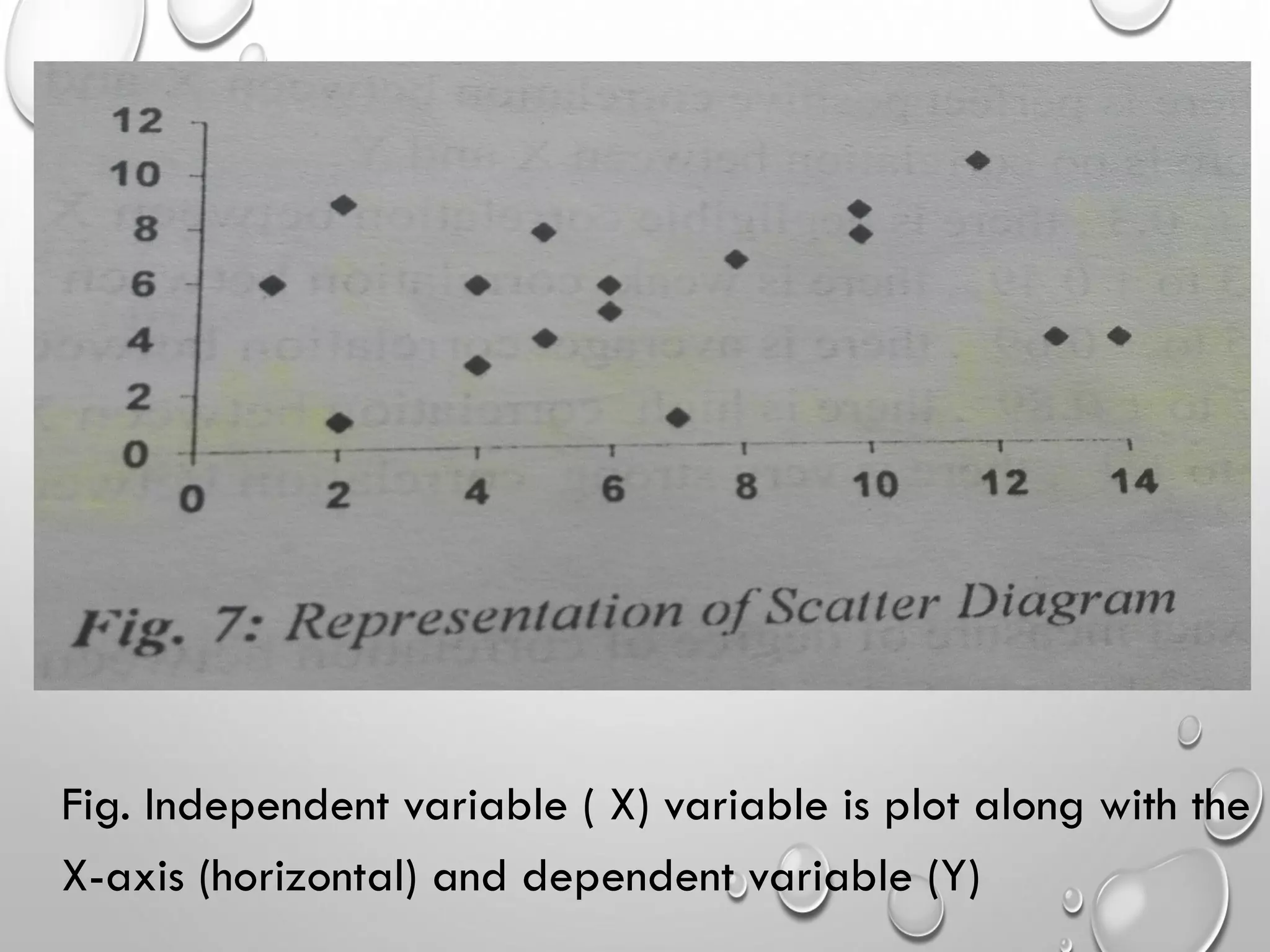
Further exploration of non-parametric methods, including McNemar’s test and Fisher’s exact test for binary outcomes.Methods for assessing correlation: scatter diagrams, Pearson's coefficient, and Spearman's rank correlation.Discussion on the limitations of parametric and non-parametric tests and the necessity of statistical knowledge.
A summary of parametric and non-parametric tests highlighting their applications and significance in research.
Final remarks and thanks from the presenter; a brief conclusion on the importance of biostatistics.























































































