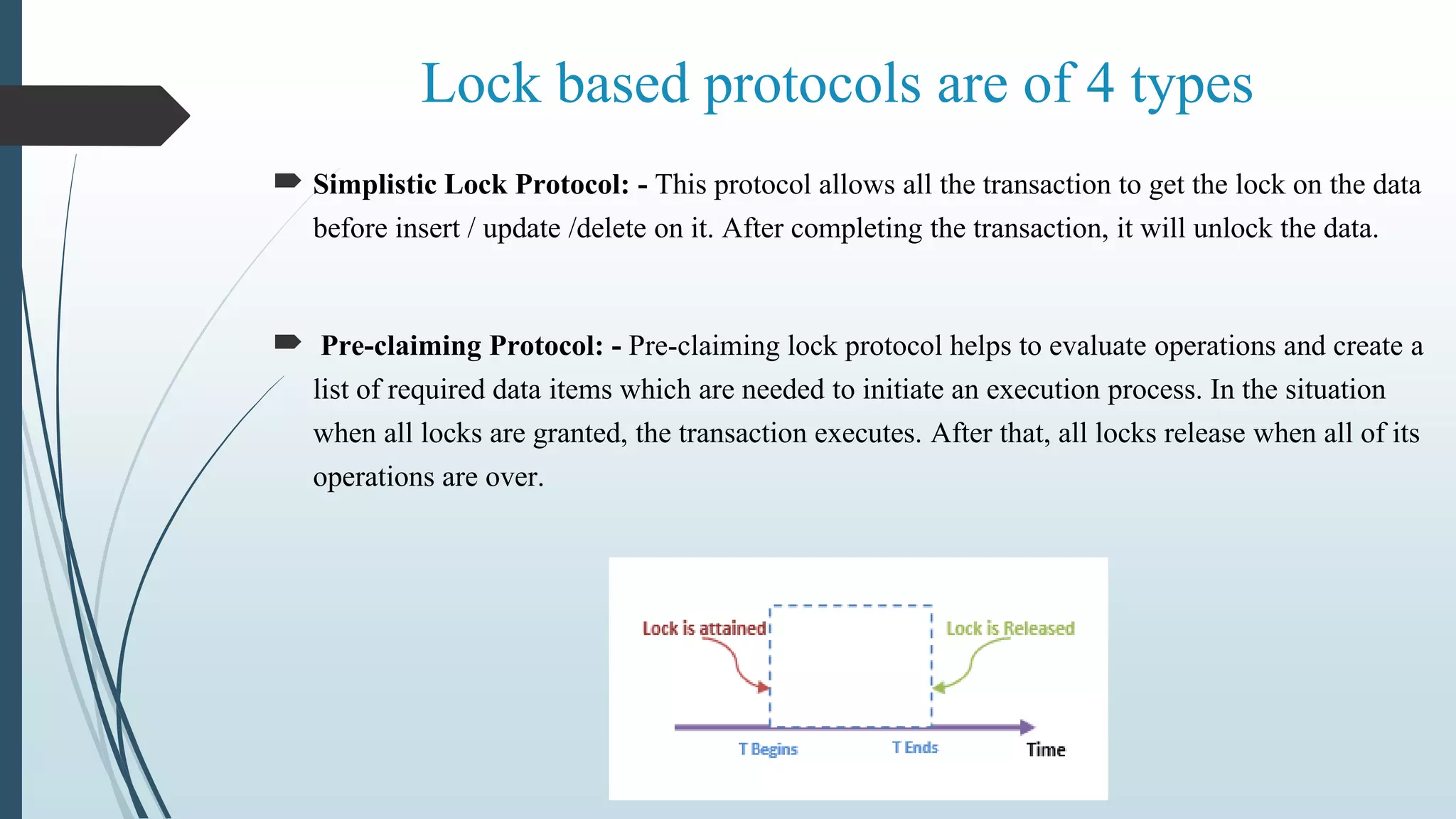
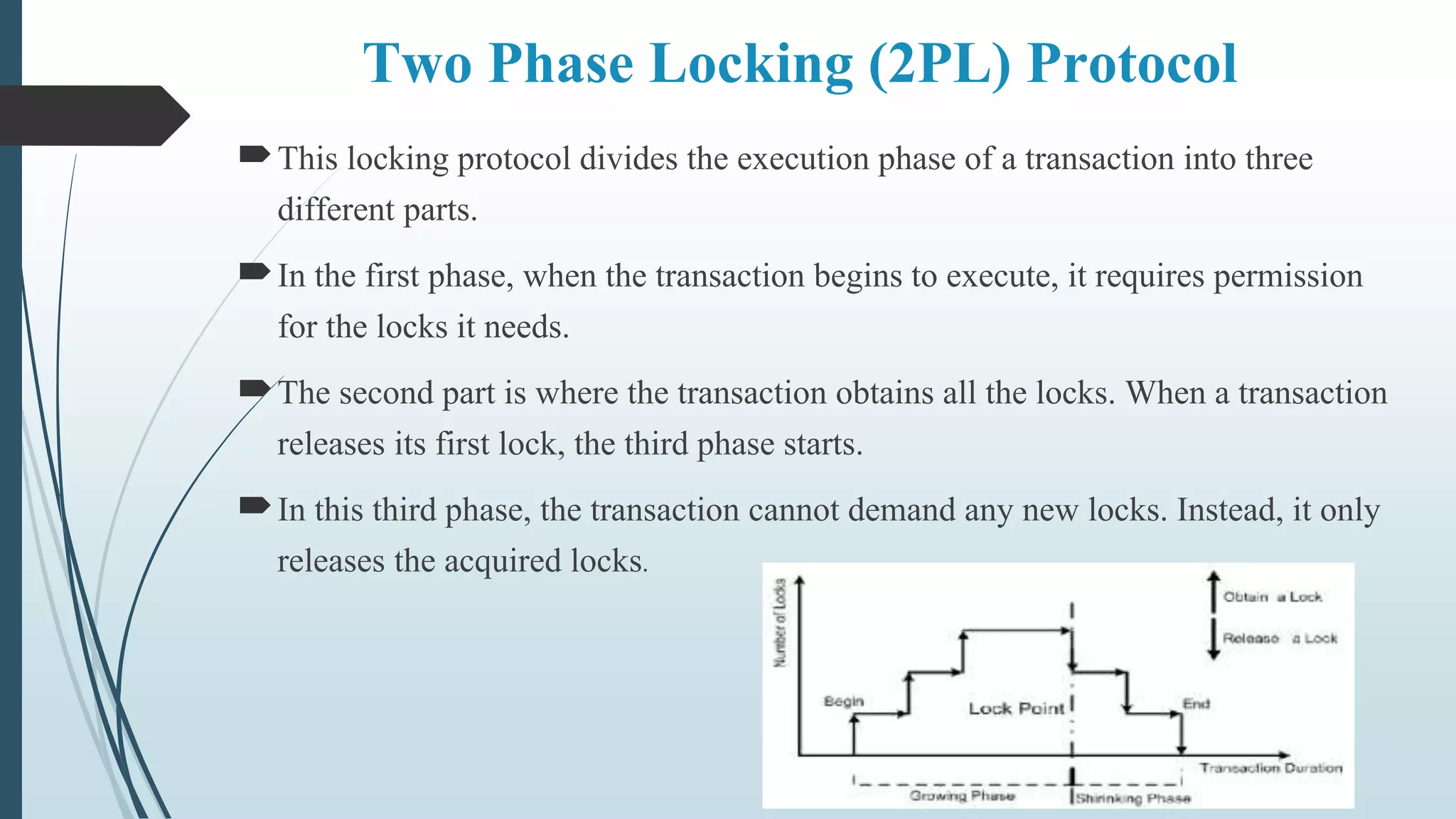
The document provides an overview of concurrency control and recovery mechanisms in distributed databases. It discusses various concurrency control protocols, including lock-based and timestamp-based protocols, to manage simultaneous operations and ensure database consistency. Recovery methods are also outlined, focusing on maintaining atomicity and durability of transactions in case of failures.