Download as PDF, PPTX




![7
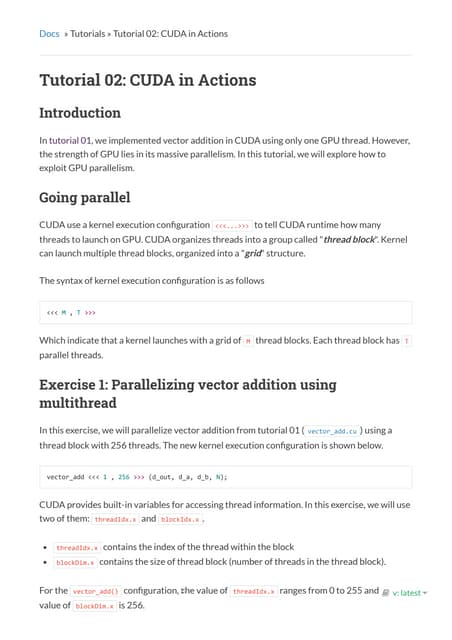
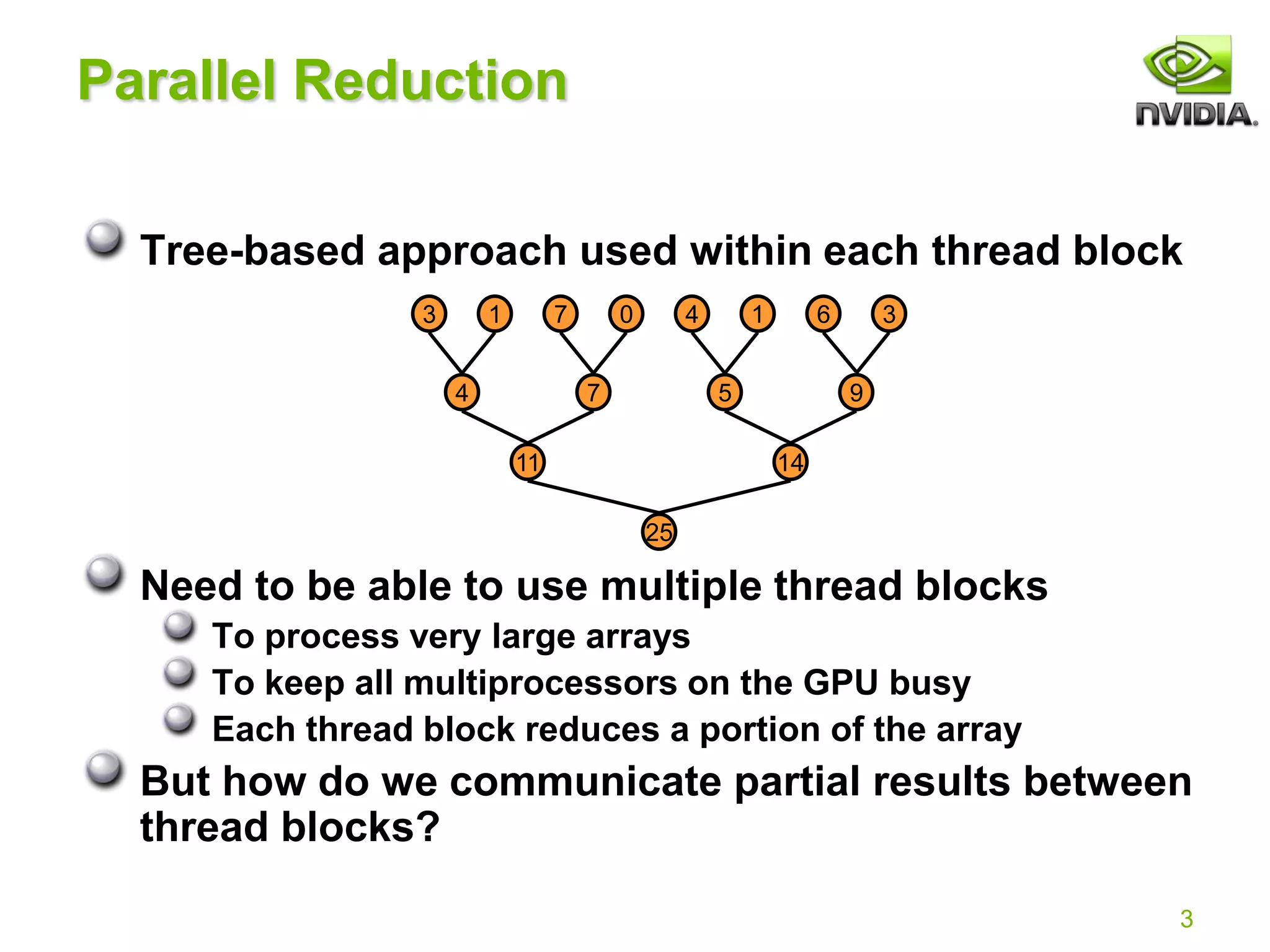
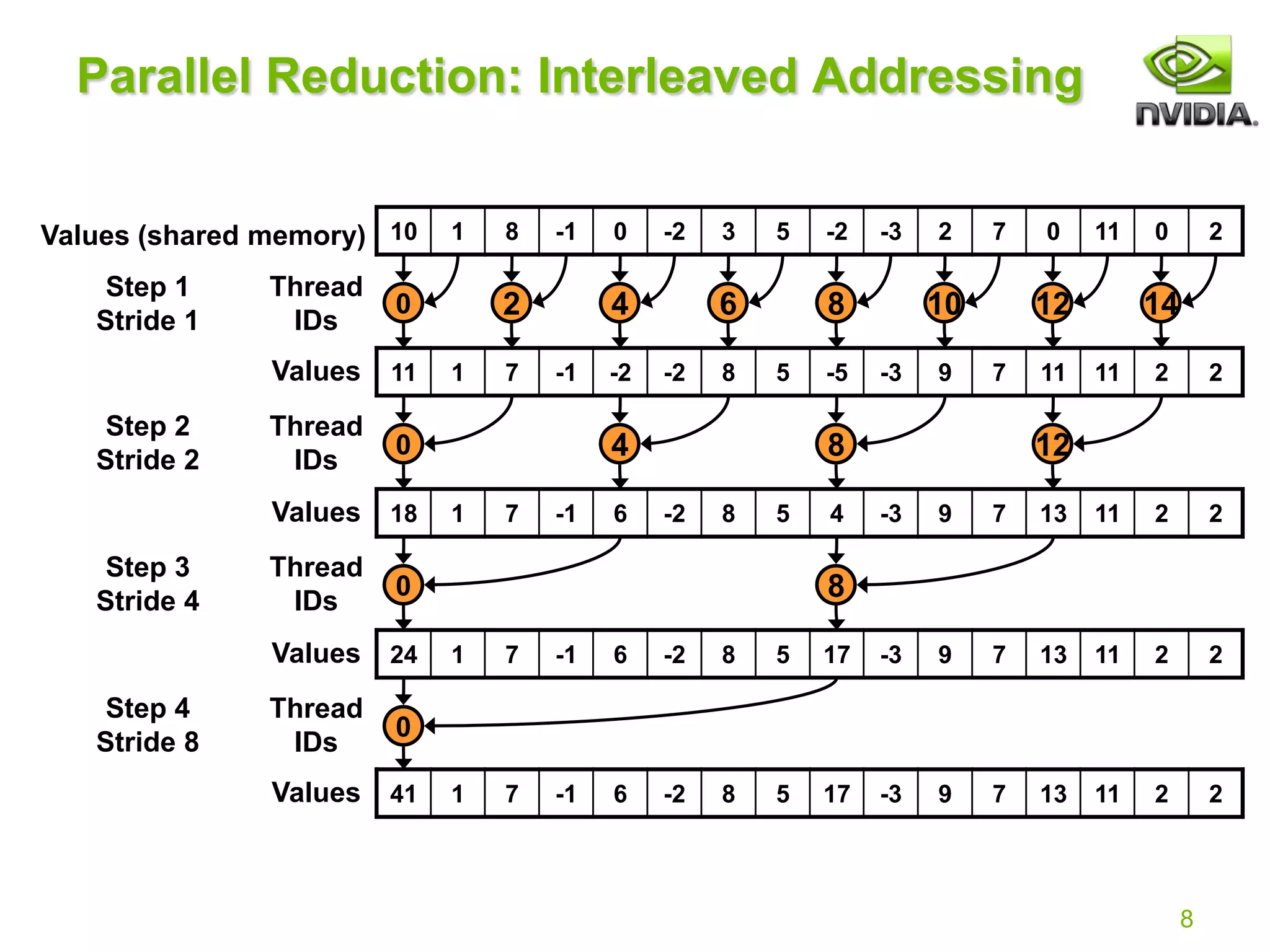
Reduction #1: Interleaved Addressing
__global__ void reduce0(int *g_idata, int *g_odata) {
extern __shared__ int sdata[];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=1; s < blockDim.x; s *= 2) {
if (tid % (2*s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}](https://image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-7-2048.jpg)
![9
Reduction #1: Interleaved Addressing
__global__ void reduce1(int *g_idata, int *g_odata) {
extern __shared__ int sdata[];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for (unsigned int s=1; s < blockDim.x; s *= 2) {
if (tid % (2*s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
Problem: highly divergent
warps are very inefficient, and
% operator is very slow](https://image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-9-2048.jpg)

![11
for (unsigned int s=1; s < blockDim.x; s *= 2) {
if (tid % (2*s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
for (unsigned int s=1; s < blockDim.x; s *= 2) {
int index = 2 * s * tid;
if (index < blockDim.x) {
sdata[index] += sdata[index + s];
}
__syncthreads();
}
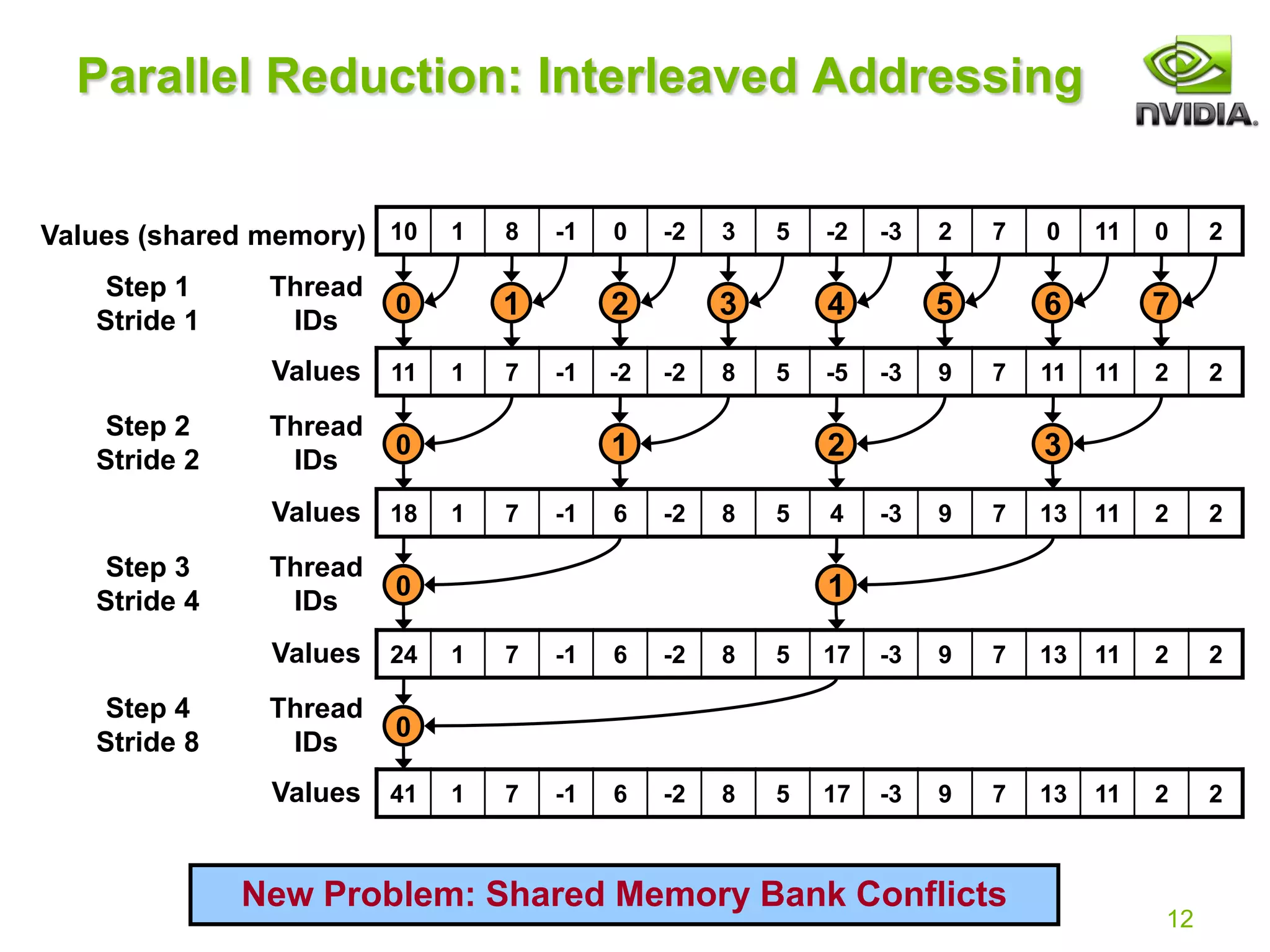
Reduction #2: Interleaved Addressing
Just replace divergent branch in inner loop:
With strided index and non-divergent branch:](https://image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-11-2048.jpg)

![15
for (unsigned int s=1; s < blockDim.x; s *= 2) {
int index = 2 * s * tid;
if (index < blockDim.x) {
sdata[index] += sdata[index + s];
}
__syncthreads();
}
for (unsigned int s=blockDim.x/2; s>0; s>>=1) {
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
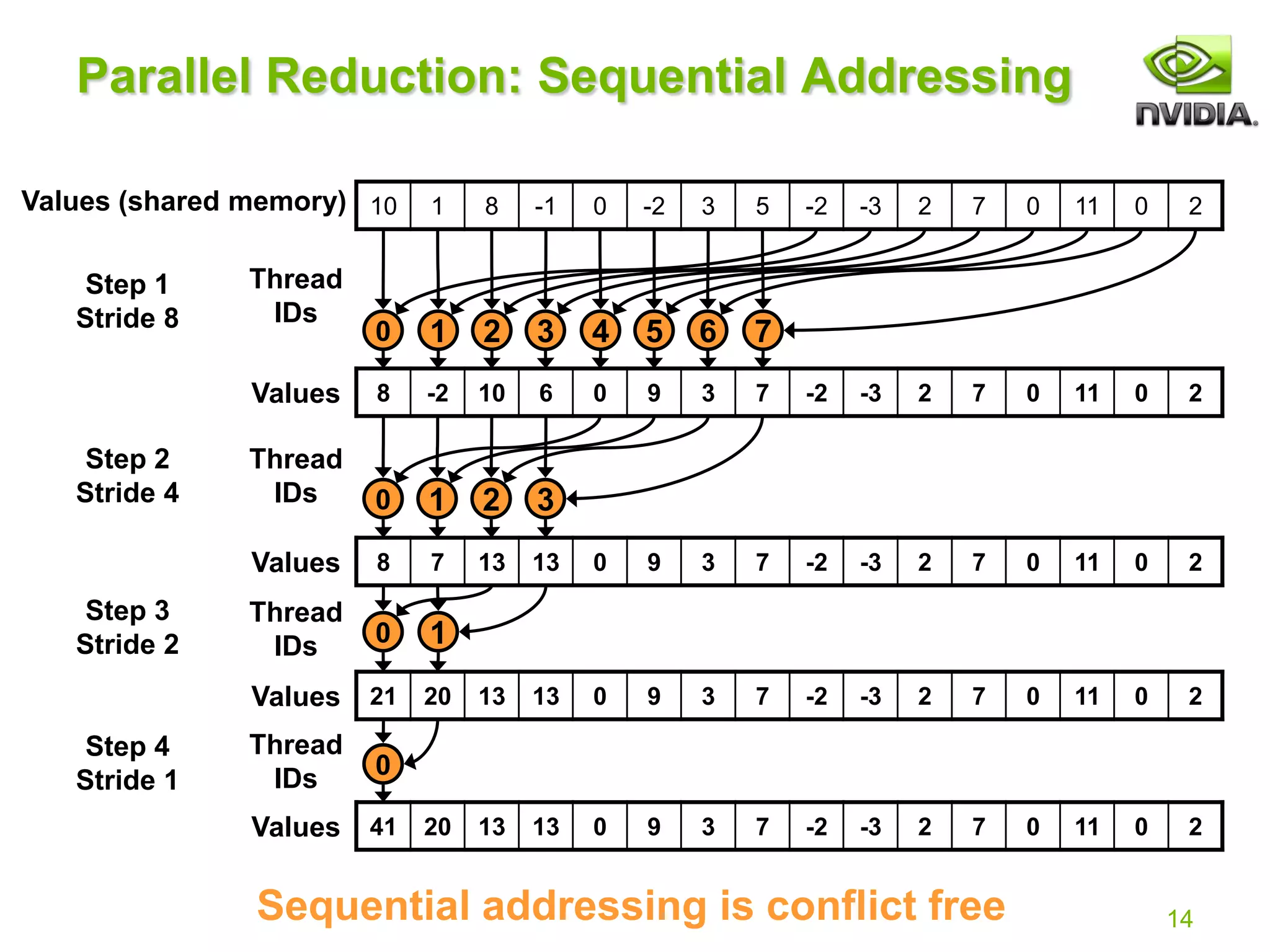
Reduction #3: Sequential Addressing
Just replace strided indexing in inner loop:
With reversed loop and threadID-based indexing:
// Already using this](https://image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-15-2048.jpg)
![17
for (unsigned int s=blockDim.x/2; s>0; s>>=1) {
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
Idle Threads
Problem:
Half of the threads are idle on first loop iteration!
This is wasteful…](https://image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-17-2048.jpg)
![18
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// perform first level of reduction,
// reading from global memory, writing to shared memory
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i] + g_idata[i+blockDim.x];
__syncthreads();
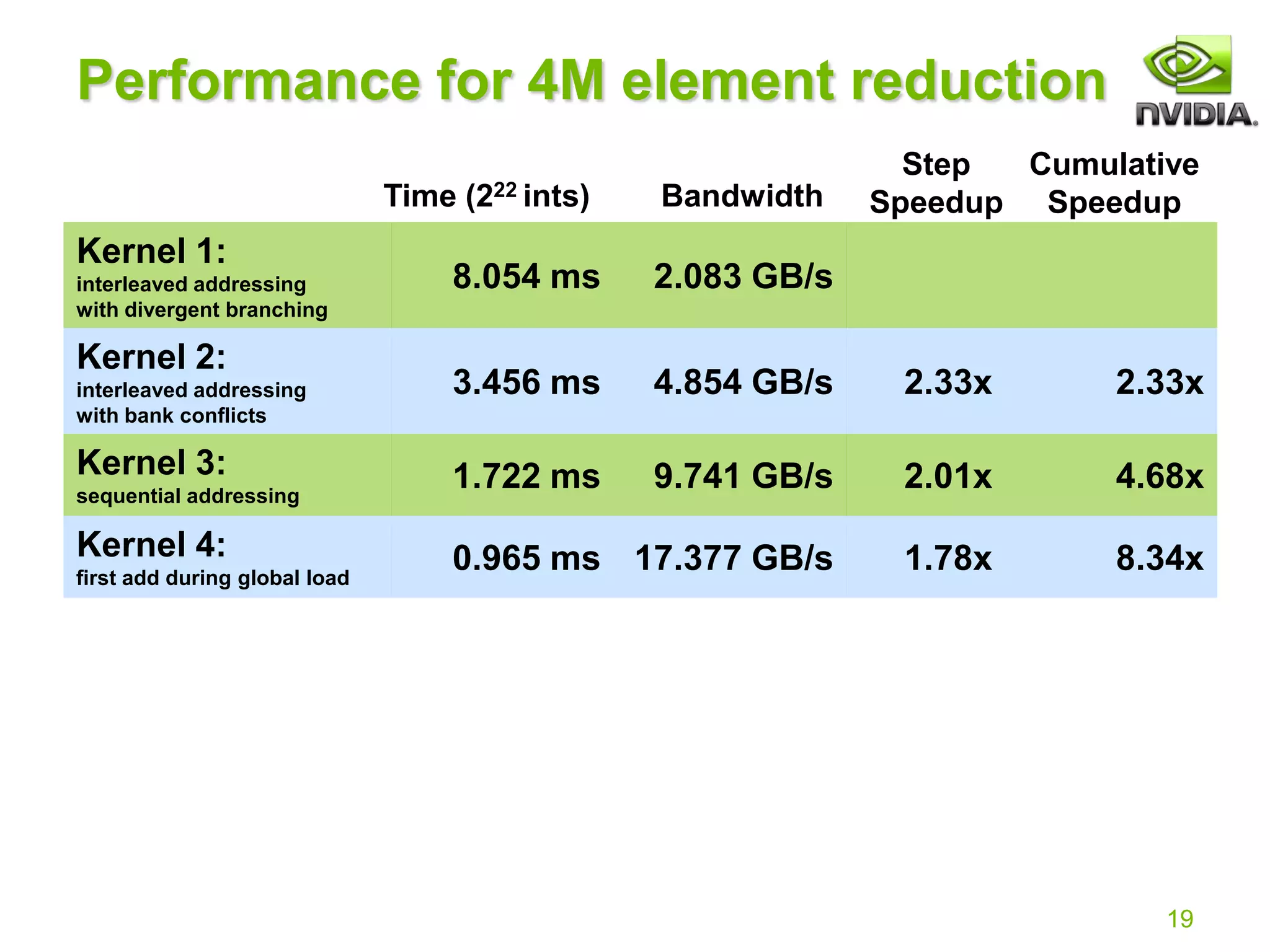
Reduction #4: First Add During Load
Halve the number of blocks, and replace single load:
With two loads and first add of the reduction:](https://image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-18-2048.jpg)


![__device__ void warpReduce(volatile int* sdata, int tid) {
sdata[tid] += sdata[tid + 32];
sdata[tid] += sdata[tid + 16];
sdata[tid] += sdata[tid + 8];
sdata[tid] += sdata[tid + 4];
sdata[tid] += sdata[tid + 2];
sdata[tid] += sdata[tid + 1];
}
// later…
for (unsigned int s=blockDim.x/2; s>32; s>>=1) {
if (tid < s)
sdata[tid] += sdata[tid + s];
__syncthreads();
}
if (tid < 32) warpReduce(sdata, tid);
22
Reduction #5: Unroll the Last Warp
Note: This saves useless work in all warps, not just the last one!
Without unrolling, all warps execute every iteration of the for loop and if statement
IMPORTANT:
For this to be correct,
we must use the
“volatile” keyword!](https://image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-22-2048.jpg)
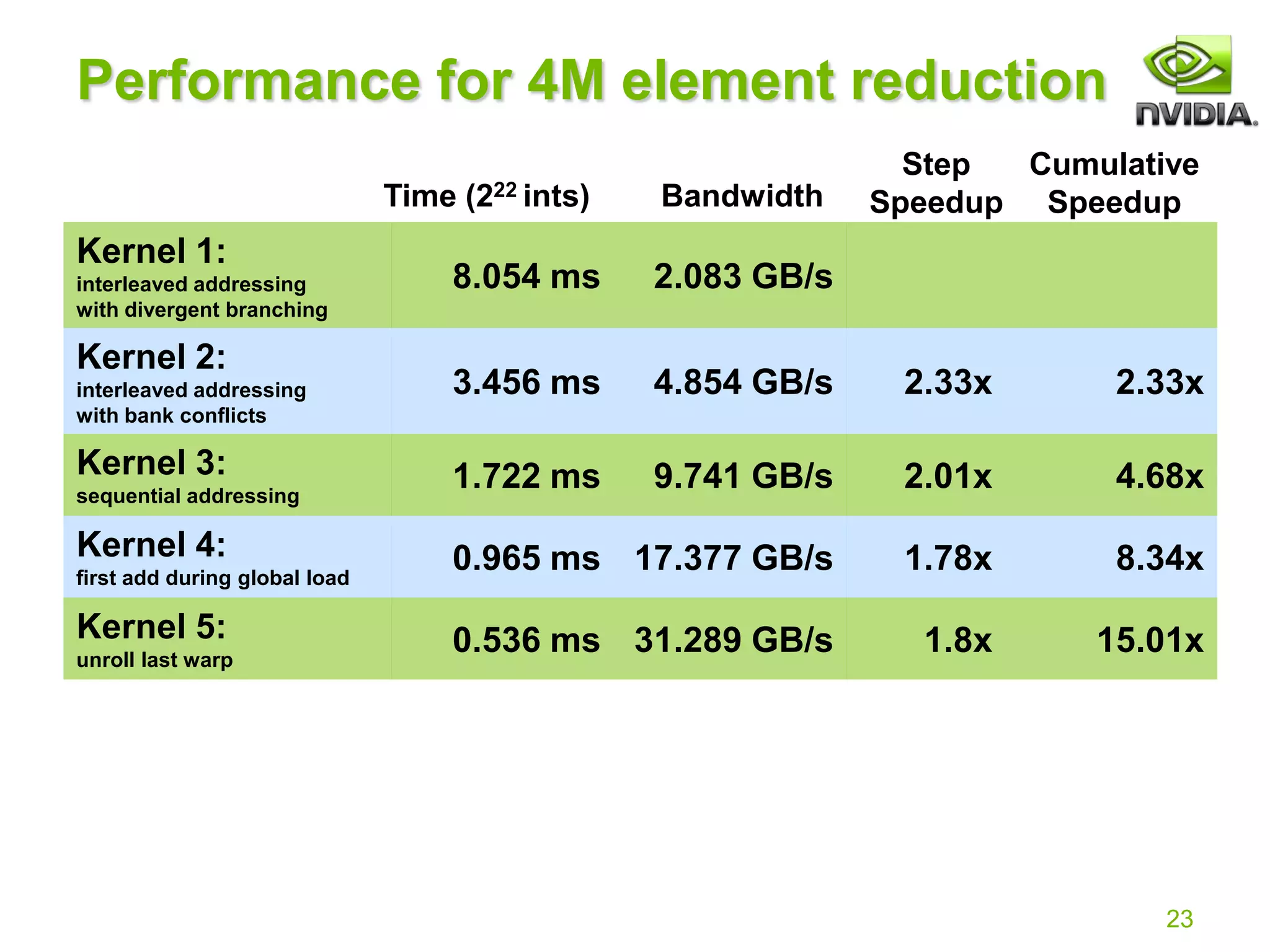


![26
Reduction #6: Completely Unrolled
if (blockSize >= 512) {
if (tid < 256) { sdata[tid] += sdata[tid + 256]; } __syncthreads(); }
if (blockSize >= 256) {
if (tid < 128) { sdata[tid] += sdata[tid + 128]; } __syncthreads(); }
if (blockSize >= 128) {
if (tid < 64) { sdata[tid] += sdata[tid + 64]; } __syncthreads(); }
if (tid < 32) warpReduce<blockSize>(sdata, tid);
Note: all code in RED will be evaluated at compile time.
Results in a very efficient inner loop!
Template <unsigned int blockSize>
__device__ void warpReduce(volatile int* sdata, int tid) {
if (blockSize >= 64) sdata[tid] += sdata[tid + 32];
if (blockSize >= 32) sdata[tid] += sdata[tid + 16];
if (blockSize >= 16) sdata[tid] += sdata[tid + 8];
if (blockSize >= 8) sdata[tid] += sdata[tid + 4];
if (blockSize >= 4) sdata[tid] += sdata[tid + 2];
if (blockSize >= 2) sdata[tid] += sdata[tid + 1];
}](https://image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-26-2048.jpg)

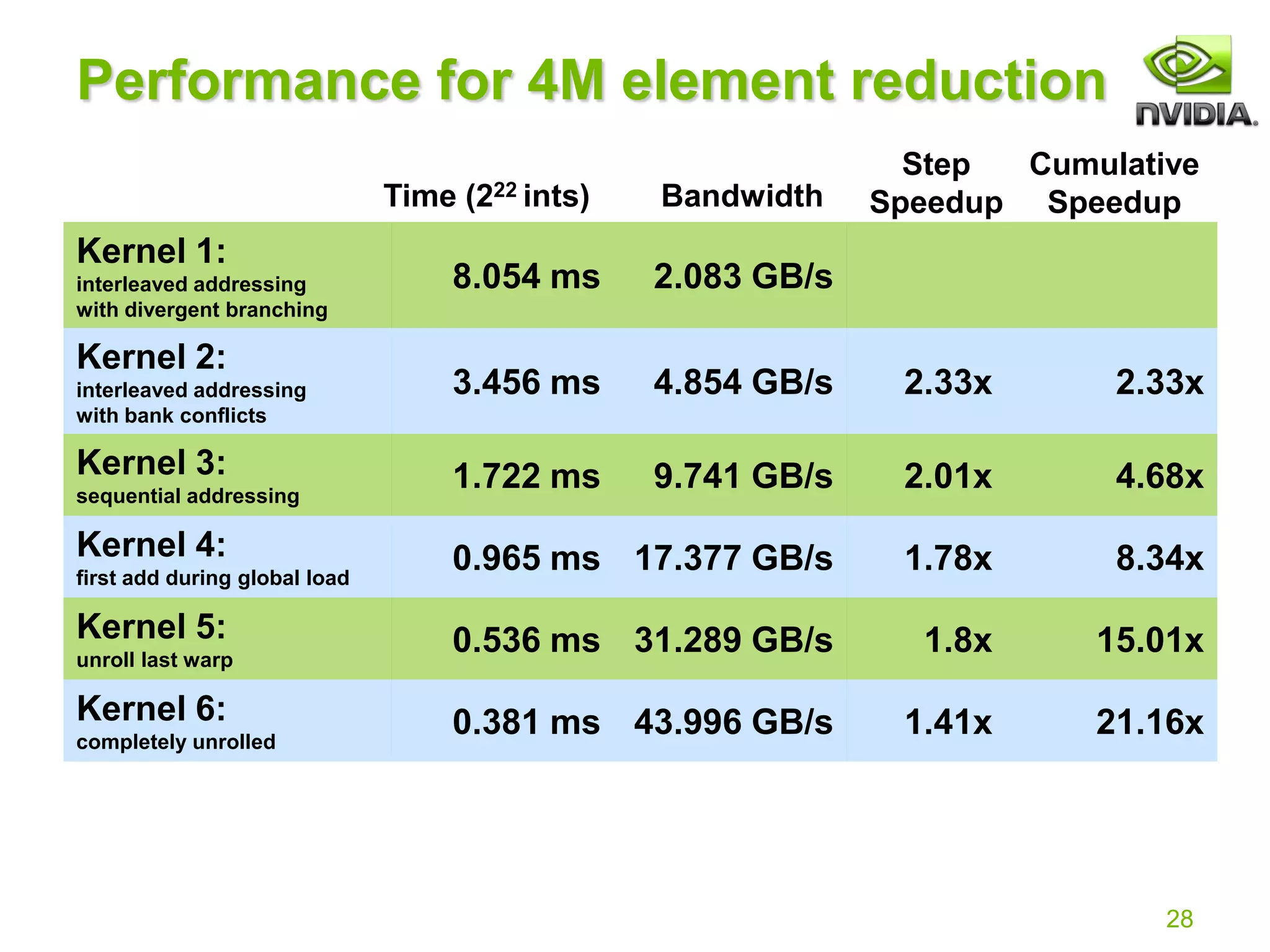
![29
Parallel Reduction Complexity
Log(N) parallel steps, each step S does N/2S
independent ops
Step Complexity is O(log N)
For N=2D, performs S[1..D]2D-S = N-1 operations
Work Complexity is O(N) – It is work-efficient
i.e. does not perform more operations than a sequential
algorithm
With P threads physically in parallel (P processors),
time complexity is O(N/P + log N)
Compare to O(N) for sequential reduction
In a thread block, N=P, so O(log N)](https://image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-29-2048.jpg)


![32
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i] + g_idata[i+blockDim.x];
__syncthreads();
Reduction #7: Multiple Adds / Thread
Replace load and add of two elements:
With a while loop to add as many as necessary:
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockSize*2) + threadIdx.x;
unsigned int gridSize = blockSize*2*gridDim.x;
sdata[tid] = 0;
while (i < n) {
sdata[tid] += g_idata[i] + g_idata[i+blockSize];
i += gridSize;
}
__syncthreads();](https://image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-32-2048.jpg)
![33
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i] + g_idata[i+blockDim.x];
__syncthreads();
Reduction #7: Multiple Adds / Thread
Replace load and add of two elements:
With a while loop to add as many as necessary:
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockSize*2) + threadIdx.x;
unsigned int gridSize = blockSize*2*gridDim.x;
sdata[tid] = 0;
while (i < n) {
sdata[tid] += g_idata[i] + g_idata[i+blockSize];
i += gridSize;
}
__syncthreads();
Note: gridSize loop stride
to maintain coalescing!](https://image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-33-2048.jpg)

![35
template <unsigned int blockSize>
__device__ void warpReduce(volatile int *sdata, unsigned int tid) {
if (blockSize >= 64) sdata[tid] += sdata[tid + 32];
if (blockSize >= 32) sdata[tid] += sdata[tid + 16];
if (blockSize >= 16) sdata[tid] += sdata[tid + 8];
if (blockSize >= 8) sdata[tid] += sdata[tid + 4];
if (blockSize >= 4) sdata[tid] += sdata[tid + 2];
if (blockSize >= 2) sdata[tid] += sdata[tid + 1];
}
template <unsigned int blockSize>
__global__ void reduce6(int *g_idata, int *g_odata, unsigned int n) {
extern __shared__ int sdata[];
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockSize*2) + tid;
unsigned int gridSize = blockSize*2*gridDim.x;
sdata[tid] = 0;
while (i < n) { sdata[tid] += g_idata[i] + g_idata[i+blockSize]; i += gridSize; }
__syncthreads();
if (blockSize >= 512) { if (tid < 256) { sdata[tid] += sdata[tid + 256]; } __syncthreads(); }
if (blockSize >= 256) { if (tid < 128) { sdata[tid] += sdata[tid + 128]; } __syncthreads(); }
if (blockSize >= 128) { if (tid < 64) { sdata[tid] += sdata[tid + 64]; } __syncthreads(); }
if (tid < 32) warpReduce(sdata, tid);
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
Final Optimized Kernel
// I guess for global memory, 2 loads in 1 loop good enough
// For shared memory, better load as mush as possible at once (near instruction bottleneck)](https://image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-35-2048.jpg)
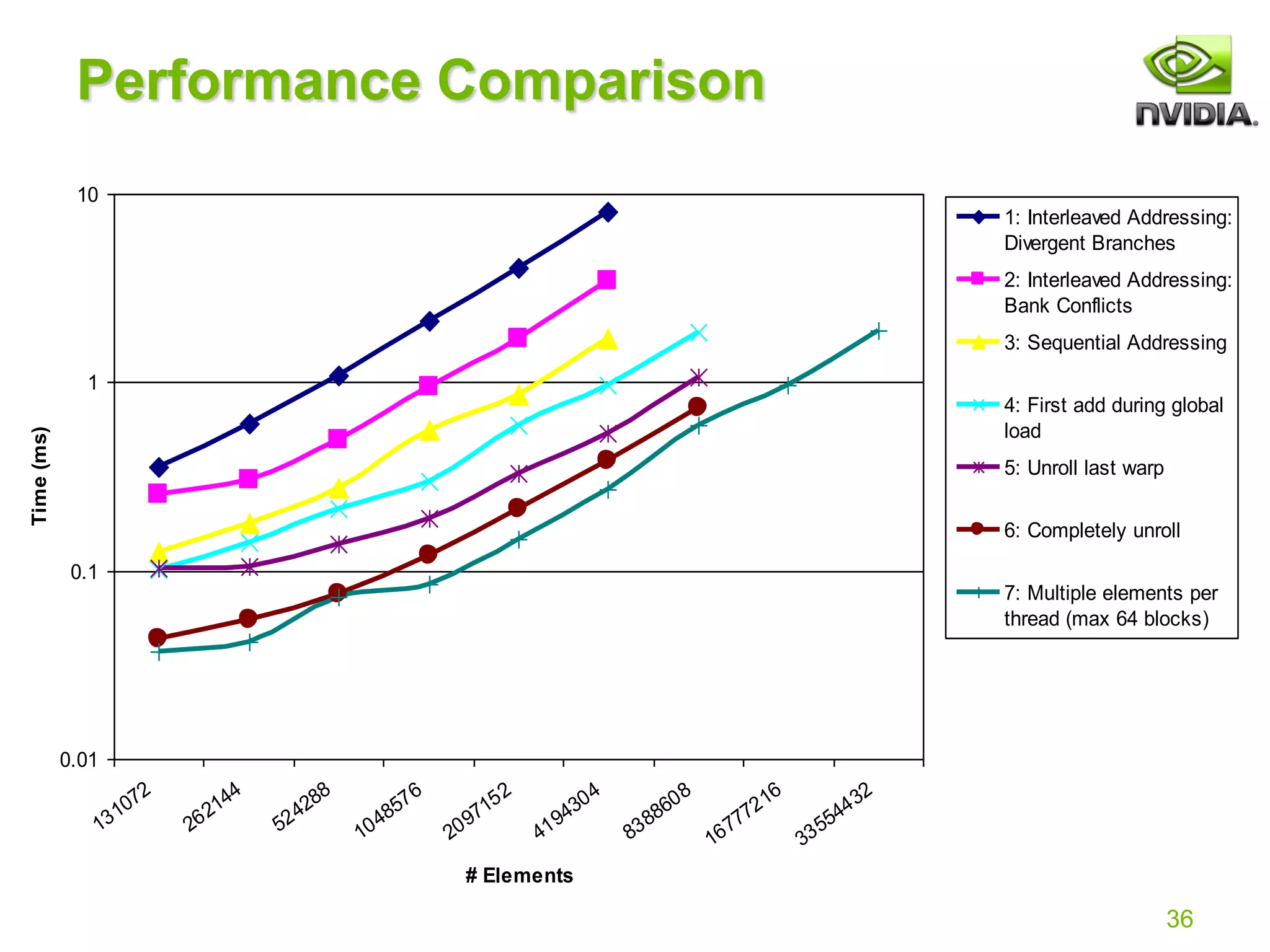








![7
Reduction #1: Interleaved Addressing
__global__ void reduce0(int *g_idata, int *g_odata) {
extern __shared__ int sdata[];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=1; s < blockDim.x; s *= 2) {
if (tid % (2*s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}](https://crownmelresort.com/image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-7-2048.jpg)

![9
Reduction #1: Interleaved Addressing
__global__ void reduce1(int *g_idata, int *g_odata) {
extern __shared__ int sdata[];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for (unsigned int s=1; s < blockDim.x; s *= 2) {
if (tid % (2*s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
Problem: highly divergent
warps are very inefficient, and
% operator is very slow](https://crownmelresort.com/image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-9-2048.jpg)

![11
for (unsigned int s=1; s < blockDim.x; s *= 2) {
if (tid % (2*s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
for (unsigned int s=1; s < blockDim.x; s *= 2) {
int index = 2 * s * tid;
if (index < blockDim.x) {
sdata[index] += sdata[index + s];
}
__syncthreads();
}
Reduction #2: Interleaved Addressing
Just replace divergent branch in inner loop:
With strided index and non-divergent branch:](https://crownmelresort.com/image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-11-2048.jpg)



![15
for (unsigned int s=1; s < blockDim.x; s *= 2) {
int index = 2 * s * tid;
if (index < blockDim.x) {
sdata[index] += sdata[index + s];
}
__syncthreads();
}
for (unsigned int s=blockDim.x/2; s>0; s>>=1) {
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
Reduction #3: Sequential Addressing
Just replace strided indexing in inner loop:
With reversed loop and threadID-based indexing:
// Already using this](https://crownmelresort.com/image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-15-2048.jpg)

![17
for (unsigned int s=blockDim.x/2; s>0; s>>=1) {
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
Idle Threads
Problem:
Half of the threads are idle on first loop iteration!
This is wasteful…](https://crownmelresort.com/image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-17-2048.jpg)
![18
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// perform first level of reduction,
// reading from global memory, writing to shared memory
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i] + g_idata[i+blockDim.x];
__syncthreads();
Reduction #4: First Add During Load
Halve the number of blocks, and replace single load:
With two loads and first add of the reduction:](https://crownmelresort.com/image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-18-2048.jpg)



![__device__ void warpReduce(volatile int* sdata, int tid) {
sdata[tid] += sdata[tid + 32];
sdata[tid] += sdata[tid + 16];
sdata[tid] += sdata[tid + 8];
sdata[tid] += sdata[tid + 4];
sdata[tid] += sdata[tid + 2];
sdata[tid] += sdata[tid + 1];
}
// later…
for (unsigned int s=blockDim.x/2; s>32; s>>=1) {
if (tid < s)
sdata[tid] += sdata[tid + s];
__syncthreads();
}
if (tid < 32) warpReduce(sdata, tid);
22
Reduction #5: Unroll the Last Warp
Note: This saves useless work in all warps, not just the last one!
Without unrolling, all warps execute every iteration of the for loop and if statement
IMPORTANT:
For this to be correct,
we must use the
“volatile” keyword!](https://crownmelresort.com/image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-22-2048.jpg)



![26
Reduction #6: Completely Unrolled
if (blockSize >= 512) {
if (tid < 256) { sdata[tid] += sdata[tid + 256]; } __syncthreads(); }
if (blockSize >= 256) {
if (tid < 128) { sdata[tid] += sdata[tid + 128]; } __syncthreads(); }
if (blockSize >= 128) {
if (tid < 64) { sdata[tid] += sdata[tid + 64]; } __syncthreads(); }
if (tid < 32) warpReduce<blockSize>(sdata, tid);
Note: all code in RED will be evaluated at compile time.
Results in a very efficient inner loop!
Template <unsigned int blockSize>
__device__ void warpReduce(volatile int* sdata, int tid) {
if (blockSize >= 64) sdata[tid] += sdata[tid + 32];
if (blockSize >= 32) sdata[tid] += sdata[tid + 16];
if (blockSize >= 16) sdata[tid] += sdata[tid + 8];
if (blockSize >= 8) sdata[tid] += sdata[tid + 4];
if (blockSize >= 4) sdata[tid] += sdata[tid + 2];
if (blockSize >= 2) sdata[tid] += sdata[tid + 1];
}](https://crownmelresort.com/image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-26-2048.jpg)


![29
Parallel Reduction Complexity
Log(N) parallel steps, each step S does N/2S
independent ops
Step Complexity is O(log N)
For N=2D, performs S[1..D]2D-S = N-1 operations
Work Complexity is O(N) – It is work-efficient
i.e. does not perform more operations than a sequential
algorithm
With P threads physically in parallel (P processors),
time complexity is O(N/P + log N)
Compare to O(N) for sequential reduction
In a thread block, N=P, so O(log N)](https://crownmelresort.com/image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-29-2048.jpg)


![32
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i] + g_idata[i+blockDim.x];
__syncthreads();
Reduction #7: Multiple Adds / Thread
Replace load and add of two elements:
With a while loop to add as many as necessary:
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockSize*2) + threadIdx.x;
unsigned int gridSize = blockSize*2*gridDim.x;
sdata[tid] = 0;
while (i < n) {
sdata[tid] += g_idata[i] + g_idata[i+blockSize];
i += gridSize;
}
__syncthreads();](https://crownmelresort.com/image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-32-2048.jpg)
![33
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i] + g_idata[i+blockDim.x];
__syncthreads();
Reduction #7: Multiple Adds / Thread
Replace load and add of two elements:
With a while loop to add as many as necessary:
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockSize*2) + threadIdx.x;
unsigned int gridSize = blockSize*2*gridDim.x;
sdata[tid] = 0;
while (i < n) {
sdata[tid] += g_idata[i] + g_idata[i+blockSize];
i += gridSize;
}
__syncthreads();
Note: gridSize loop stride
to maintain coalescing!](https://crownmelresort.com/image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-33-2048.jpg)

![35
template <unsigned int blockSize>
__device__ void warpReduce(volatile int *sdata, unsigned int tid) {
if (blockSize >= 64) sdata[tid] += sdata[tid + 32];
if (blockSize >= 32) sdata[tid] += sdata[tid + 16];
if (blockSize >= 16) sdata[tid] += sdata[tid + 8];
if (blockSize >= 8) sdata[tid] += sdata[tid + 4];
if (blockSize >= 4) sdata[tid] += sdata[tid + 2];
if (blockSize >= 2) sdata[tid] += sdata[tid + 1];
}
template <unsigned int blockSize>
__global__ void reduce6(int *g_idata, int *g_odata, unsigned int n) {
extern __shared__ int sdata[];
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockSize*2) + tid;
unsigned int gridSize = blockSize*2*gridDim.x;
sdata[tid] = 0;
while (i < n) { sdata[tid] += g_idata[i] + g_idata[i+blockSize]; i += gridSize; }
__syncthreads();
if (blockSize >= 512) { if (tid < 256) { sdata[tid] += sdata[tid + 256]; } __syncthreads(); }
if (blockSize >= 256) { if (tid < 128) { sdata[tid] += sdata[tid + 128]; } __syncthreads(); }
if (blockSize >= 128) { if (tid < 64) { sdata[tid] += sdata[tid + 64]; } __syncthreads(); }
if (tid < 32) warpReduce(sdata, tid);
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
Final Optimized Kernel
// I guess for global memory, 2 loads in 1 loop good enough
// For shared memory, better load as mush as possible at once (near instruction bottleneck)](https://crownmelresort.com/image.slidesharecdn.com/reduction12-compressed-210716124854/75/Optimizing-Parallel-Reduction-in-CUDA-NOTES-35-2048.jpg)




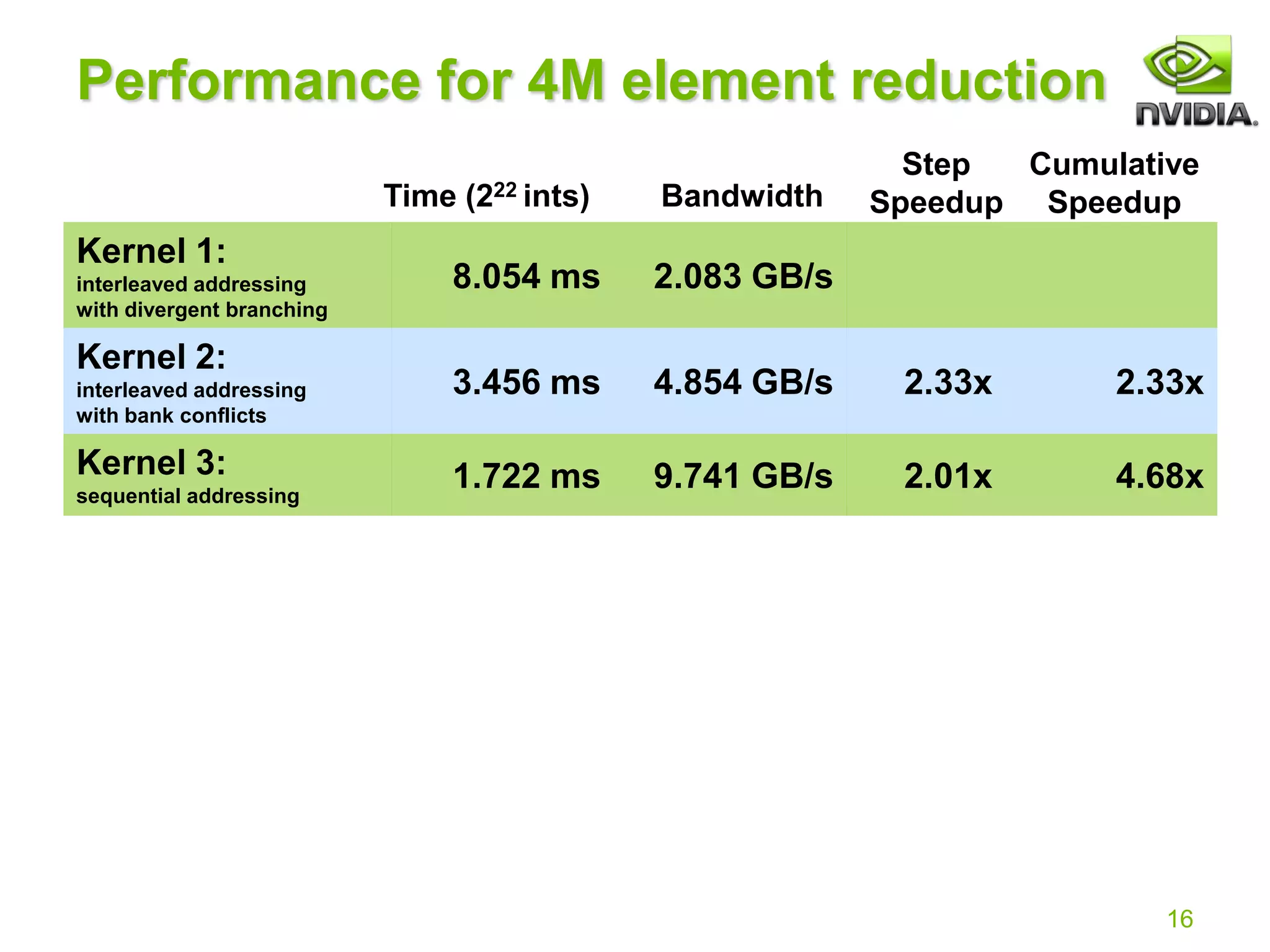
The document discusses optimization strategies for parallel reduction in CUDA, demonstrating step-by-step versions emphasizing efficient communication between thread blocks without global synchronization. It highlights the importance of maximizing GPU performance by focusing on bandwidth and reducing divergent branching while exploring multiple kernel implementations. The optimization techniques include kernel decomposition, avoiding shared memory bank conflicts, and utilizing loop unrolling techniques with templates for enhanced efficiency.