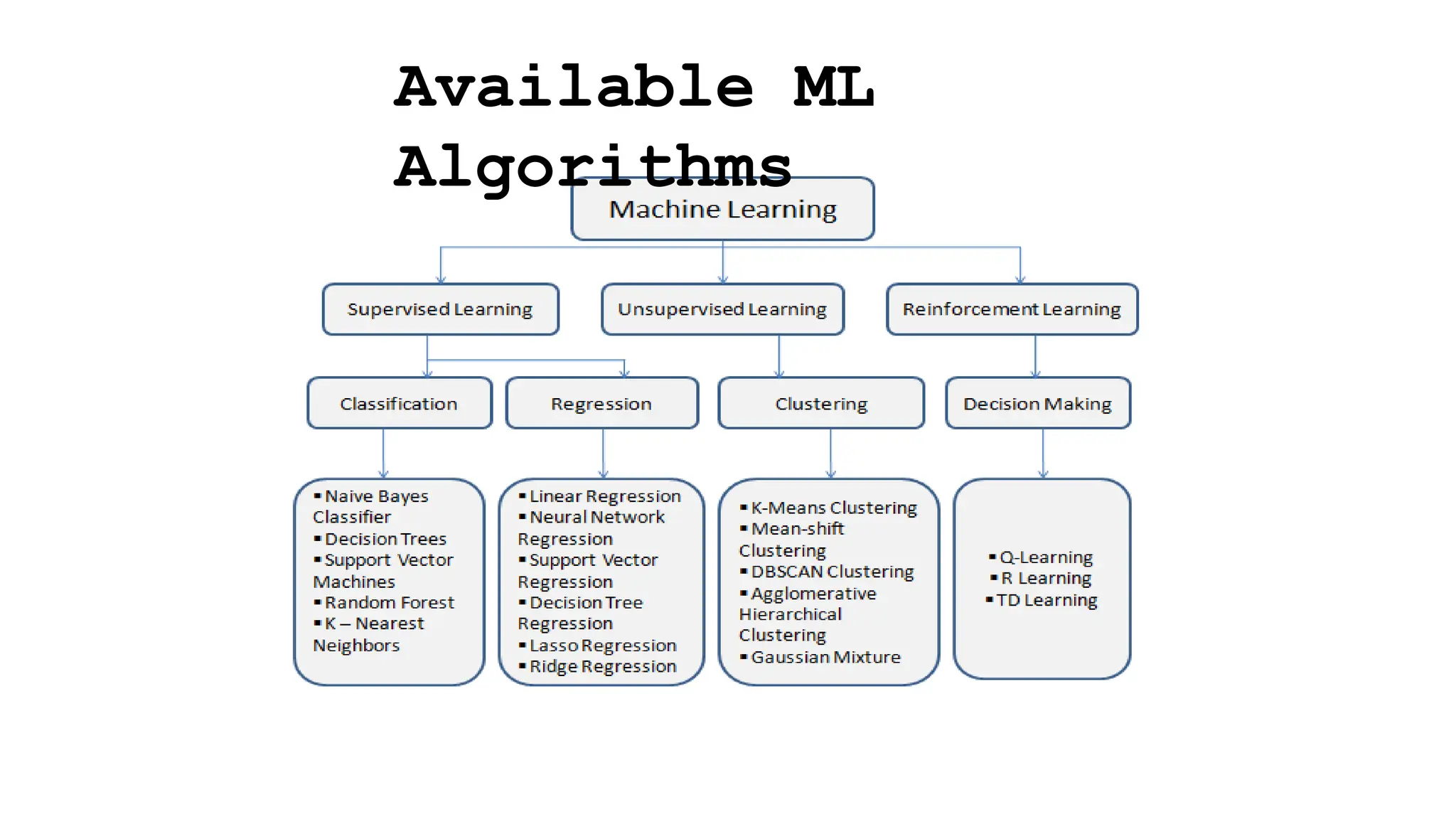
Here are the key types of unsupervised learning algorithms:
- Clustering: Groups unlabeled data points that are similar to each other. Examples include K-means clustering, hierarchical clustering.
- Association Rule Learning: Finds relationships between variables in large datasets. Apriori algorithm is commonly used.
- Dimensionality Reduction: Reduces the number of random variables in the data. Principal Component Analysis (PCA) and t-Distributed Stochastic Neighbor Embedding (t-SNE) are popular techniques.
- Anomaly Detection: Finds unusual data points that do not fit a expected distribution or pattern. Isolation Forest algorithm is often used.
- Representation Learning: Learns representations of the data