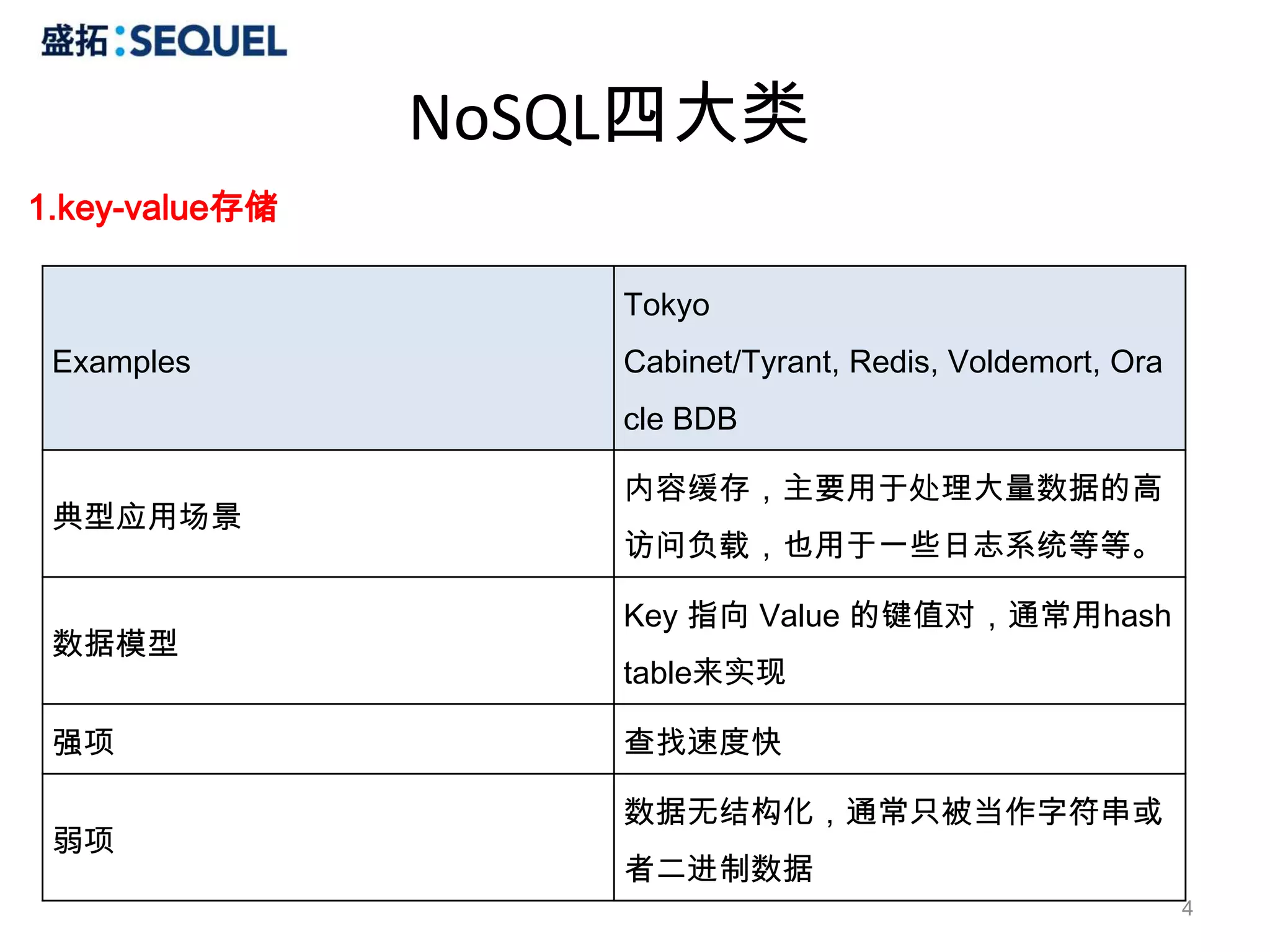
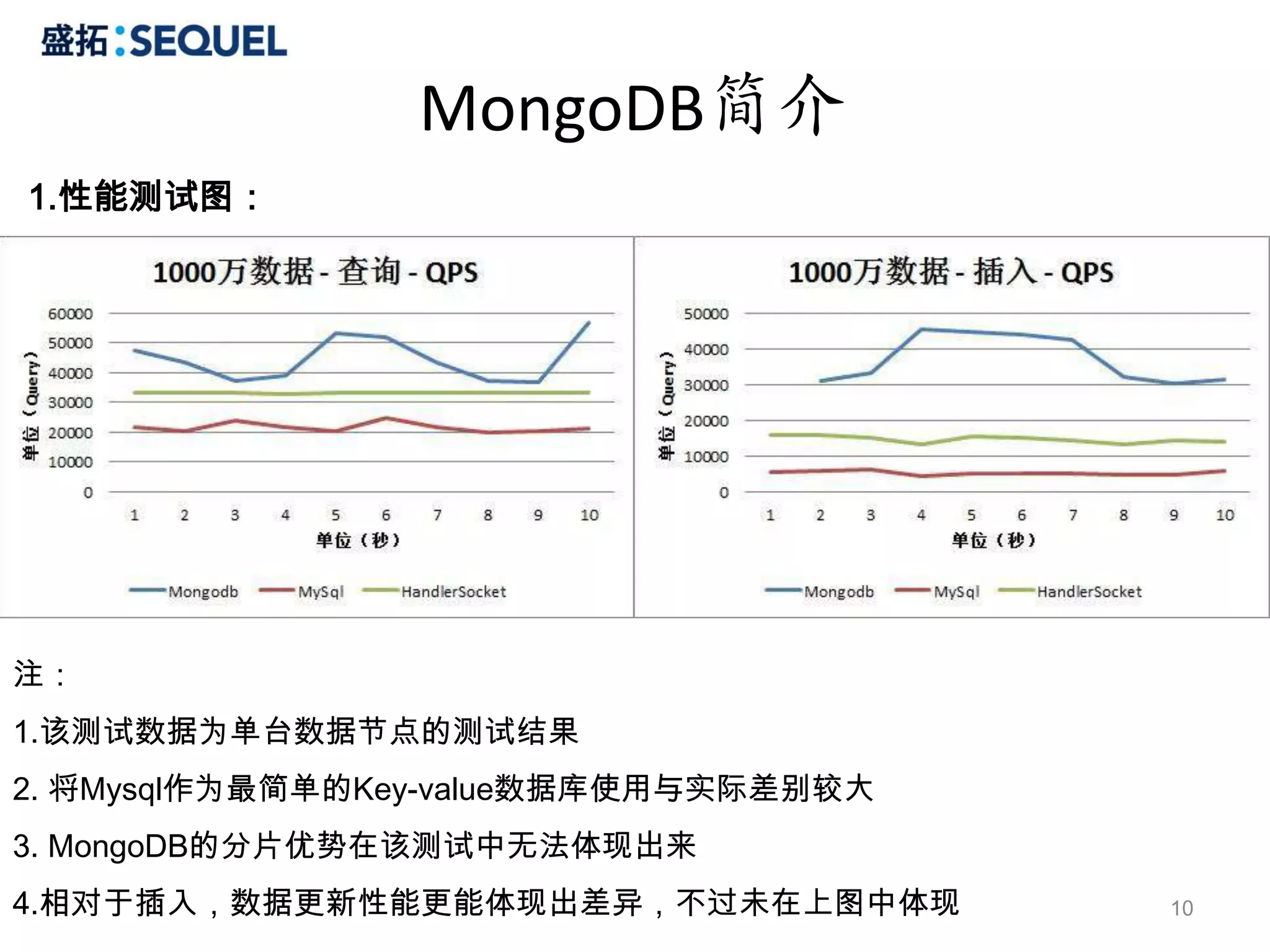
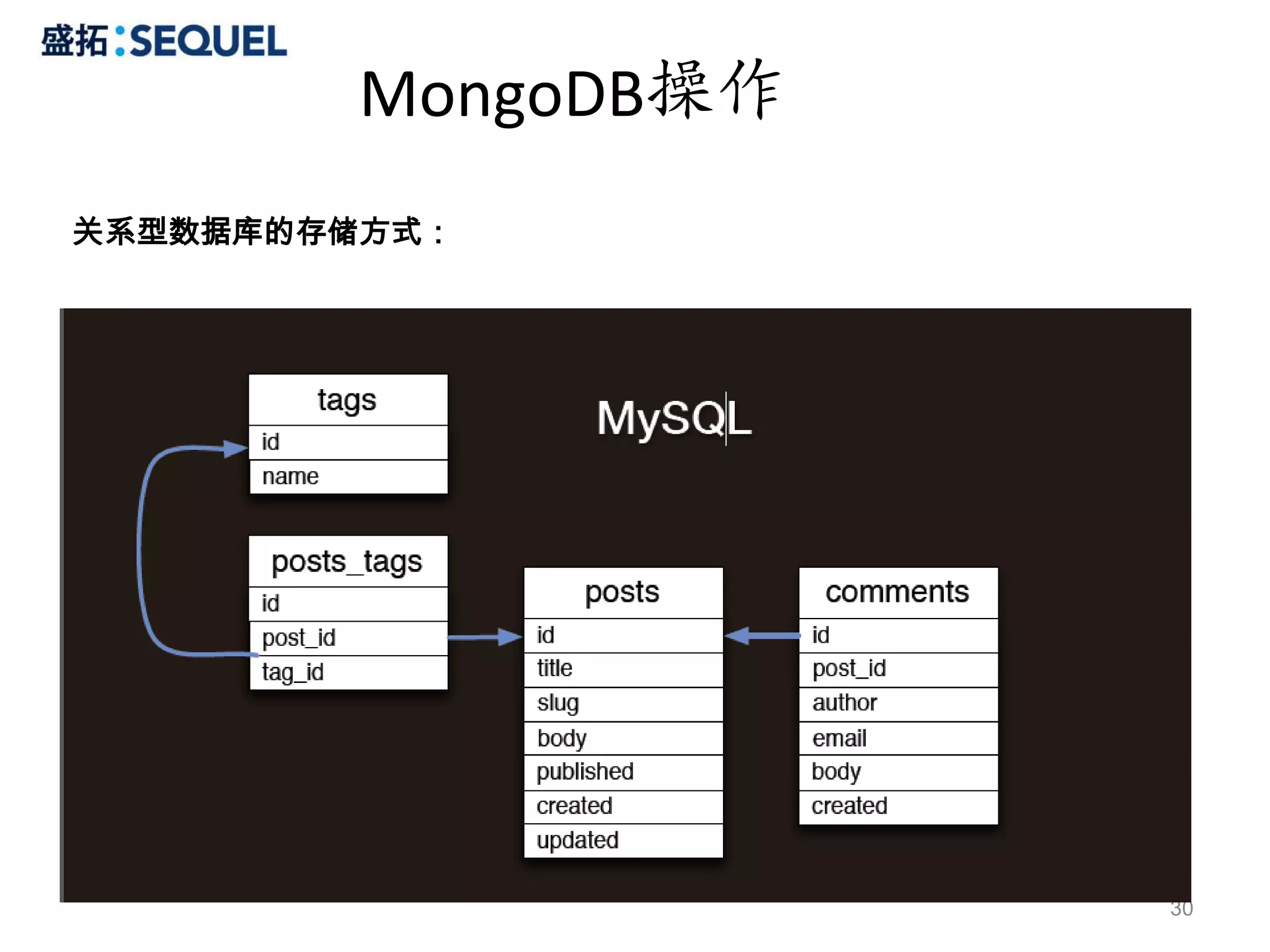
MongoDB操作
Query
1.WHERE
# select *from users where name = 'user1'
> db.users.find({name:"user1"})
{ "_id" : ObjectId("4c4528a0b55f2224d447e4b0"), "name" : "user1", "age" : 21, "sex" : 1}
# select * from users where name = 'user1' and age = 21
> db.users.find({name:"user1", age:21})
{ "_id" : ObjectId("4c4528a0b55f2224d447e4b0"), "name" : "user1", "age" : 21, "sex" : 1}
2.FIELDS
# select name, age from users where age = 21
> db.users.find({age:21}, {'name':1, 'age':1})
{ "_id" : ObjectId("4c452c343d48c8f284b388e0"), "name" : "user1", "age" : 21 }
# select name, age from users
> db.users.find({}, {'name':1, 'age':1})
3.SORT
# select * from users order by age
> db.users.find().sort({age:1})
# select * from users order by sex asce, age desc
> db.users.find().sort({sex:1, age:-1})
25
26.
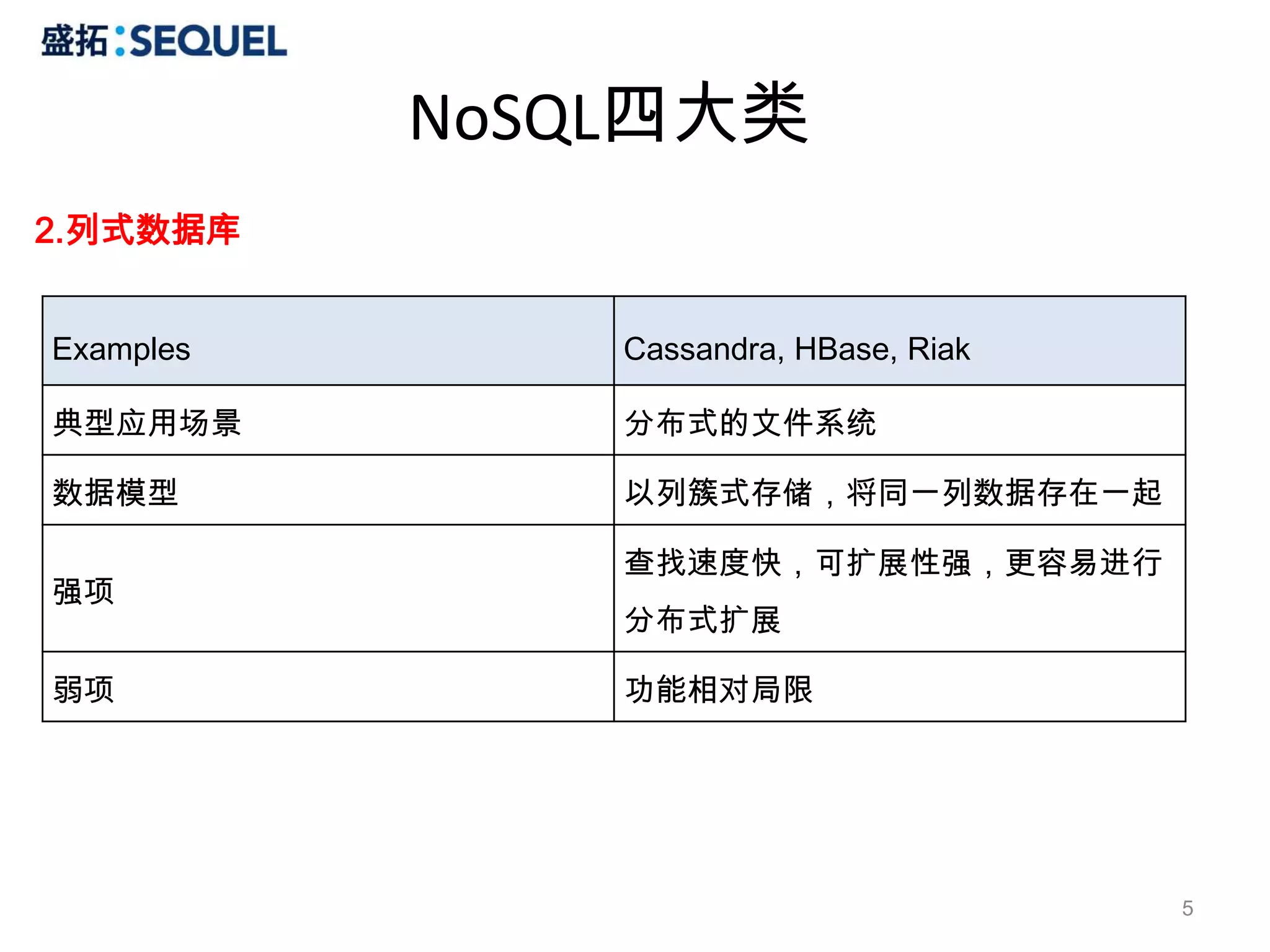
MongoDB操作
4.SLICE
# select *from users skip 2 limit 3
> db.users.find().skip(2).limit(3)
Conditional Operators
# select * from users where sex = 1 and age > 23 and age < 28
> db.users.find({sex:1, age:{$gt:23, $lt:28}})
比较操作包括:$gt (>)、$lt (<)、$gte (>=)、$lte(<=)、$ne (!=)
5. IN
# select * from users where age in (23, 26, 32)
> db.users.find({age:{$in:[23,26,32]}})
对应的操作符有 $nin (not in)。
6.COUNT
# select count(*) from users where age > 30
> db.users.find({age:{$gt:30}}).count()
7.OR
# select * from users where age = 25 or age = 28
> db.users.find({$or:[{age:25}, {age:28}]})
# select * from users where age <= 23 or age >= 33
db.users.find({$or:[{age:{$lte:23}}, {age:{$gte:33}}]})
26
27.
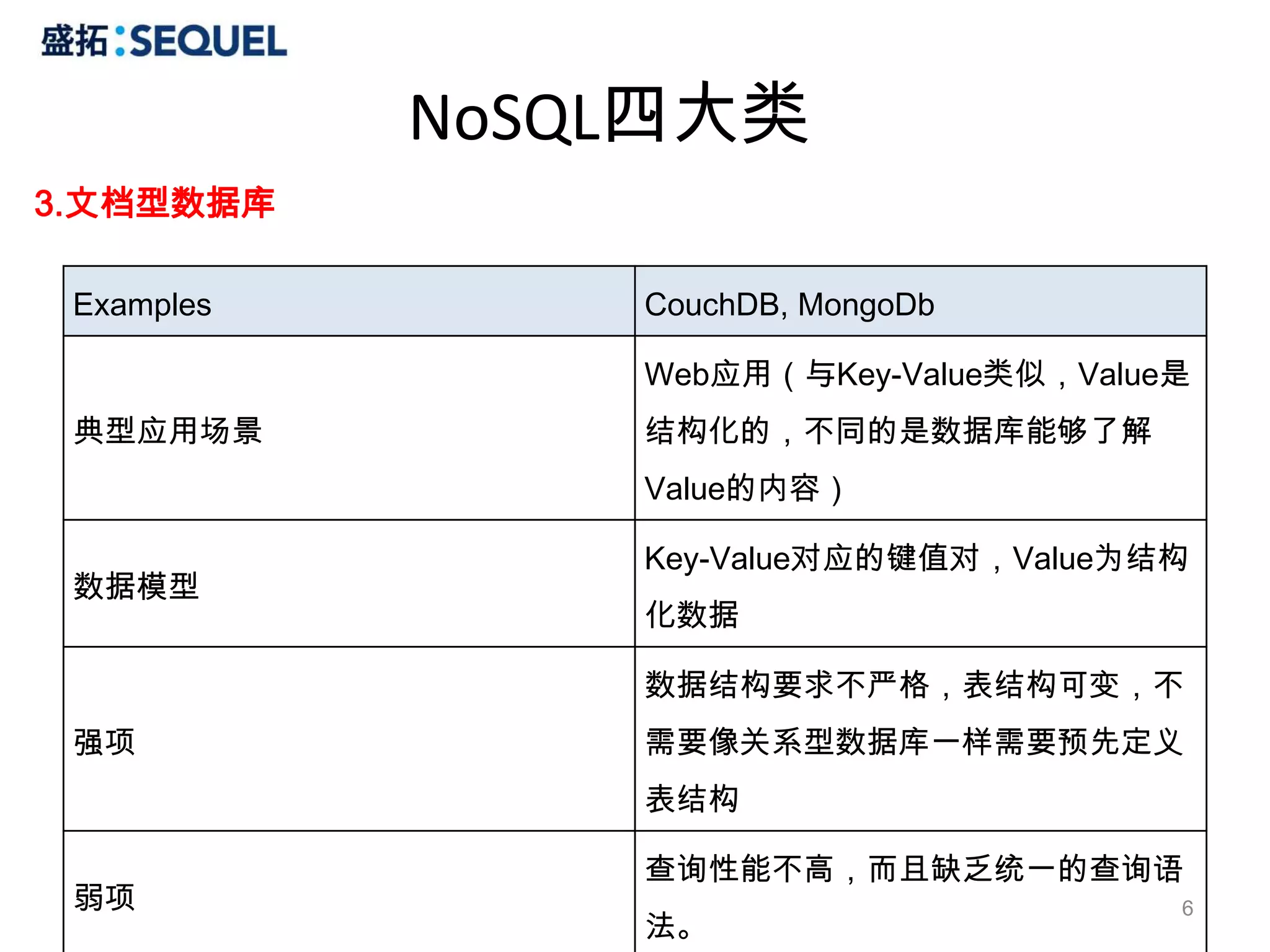
MongoDB操作
Update
可直接用类似 T-SQL 条件表达式更新,或用Save() 更新从数据库返回到文档对象。
# update users set age = 100, sex = 0 where name = 'user1‘
> db.users.update({name:"user1"}, {$set:{age:100, sex:0}})
update() 有几个参数需要注意。
db.collection.update(criteria, objNew, upsert, mult)
criteria: 需要被更新的条件表达式
objNew: 更新表达式
upsert: 如目标记录不存在,是否插入新文档。
multi: 是否更新多个文档。
# update users set age = age + 10
> db.users.update({}, {$inc:{age:10}}, false, true)
# update users set age = age + 10, sex = 1 where name = 'user1'
> db.users.update({name:"user1"}, {$inc:{age:10}, $set:{sex:1}})
Remove
remove() 用于删除单个或全部文档,删除后的文档无法恢复。
> id = db.users.findOne({name:"user2"})._id
ObjectId("4c4508818c4a1e0bf570460f")
> db.users.remove(id)
//移除name='use2'的行
> db.users.remove()//移除所有 27
28.
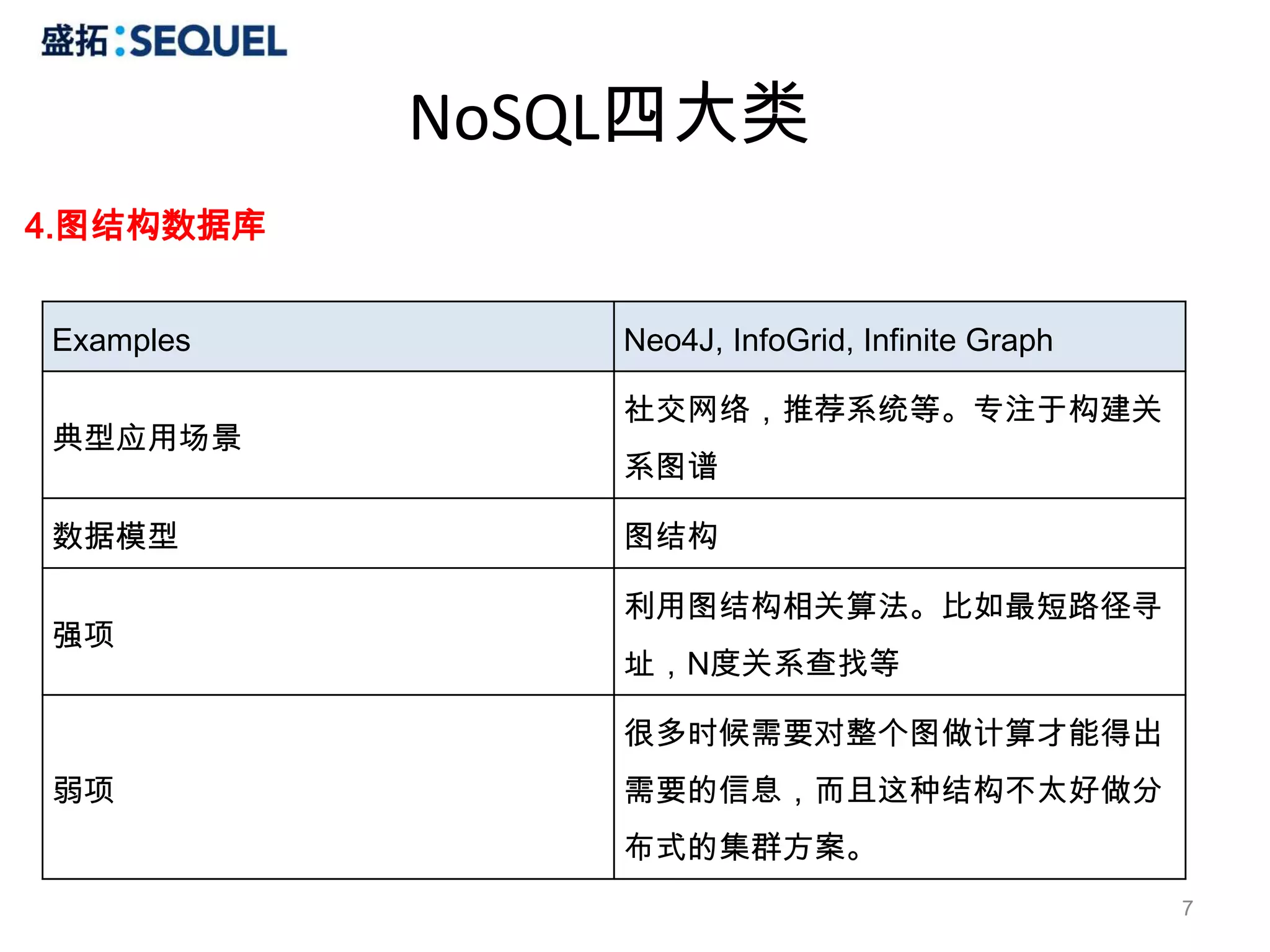
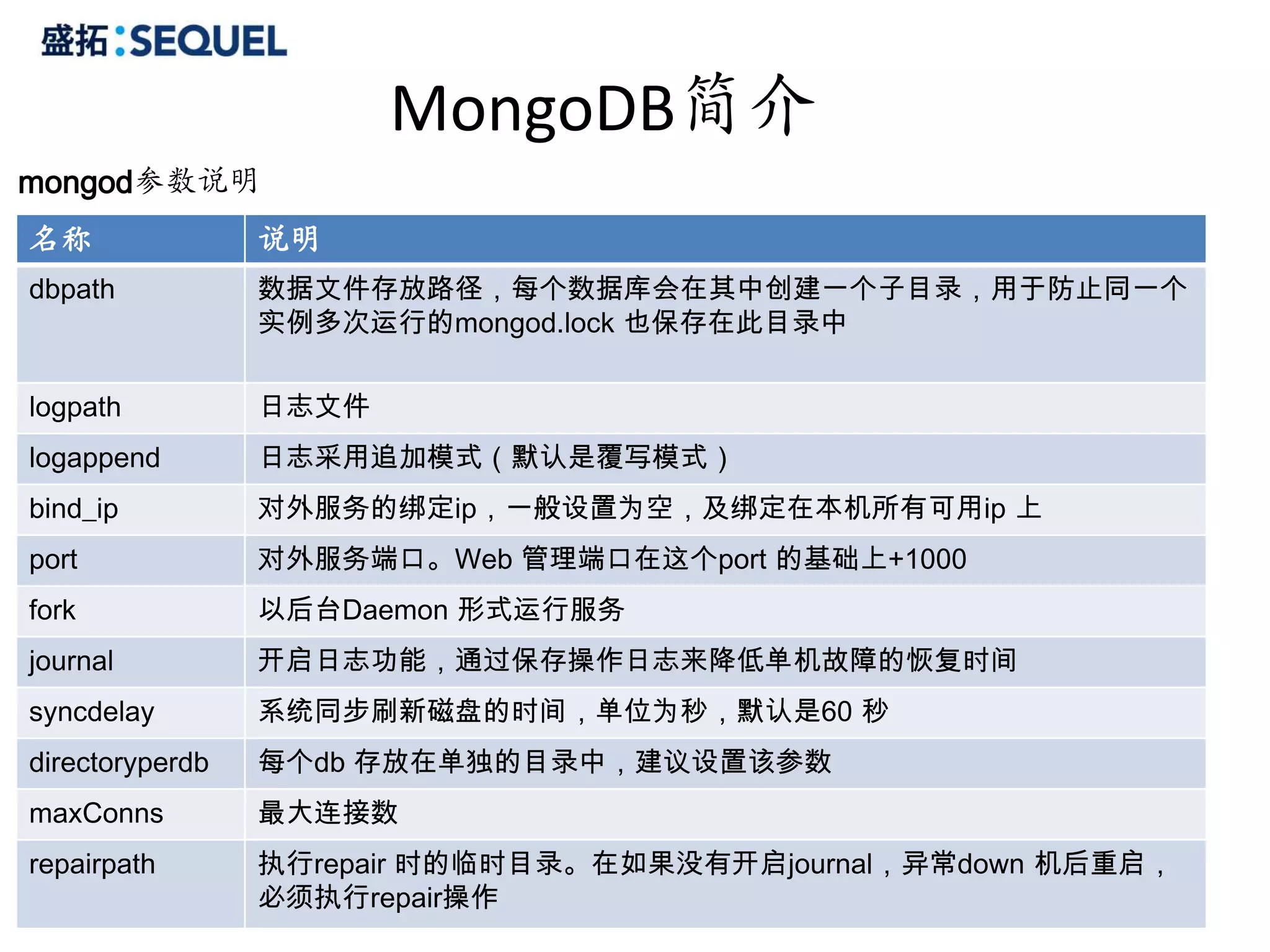
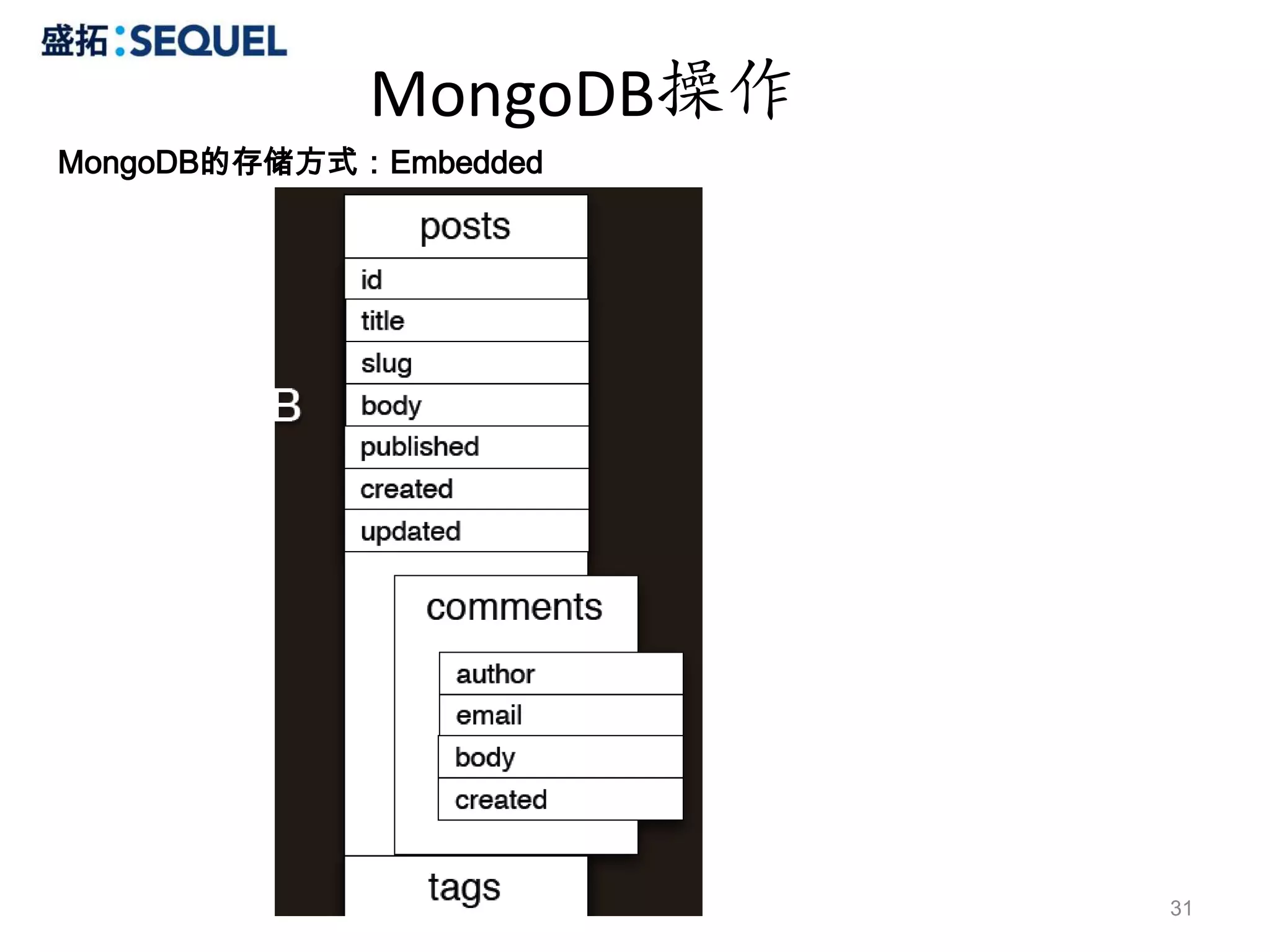
MongoDB操作
Distinct
> db.colors.distinct('name')
[ "blue","green", "orange", "purple", "red", "yellow" ]
Group
#SELECT name, sum(marks) FROM user where name='foo' GROUP BY name
>db.user.group({
key : {‘name’ : true},
cond: {‘name’ : ‘foo’},
reduce: function(obj,prev) { prev.msum += obj.marks; },
initial: {msum : 0}
});
Index
// single ascending
db.colors.ensureIndex({name: 1})
// unique
db.colors.ensureIndex({email: 1}, {unique: true})
// single descending
db.colors.ensureIndex({createdat: -1})
// compound
> db.colors.ensureIndex({name: 1, createdat: -1})
28



















![MongoDB操作
4.SLICE
# select * from users skip 2 limit 3
> db.users.find().skip(2).limit(3)
Conditional Operators
# select * from users where sex = 1 and age > 23 and age < 28
> db.users.find({sex:1, age:{$gt:23, $lt:28}})
比较操作包括:$gt (>)、$lt (<)、$gte (>=)、$lte(<=)、$ne (!=)
5. IN
# select * from users where age in (23, 26, 32)
> db.users.find({age:{$in:[23,26,32]}})
对应的操作符有 $nin (not in)。
6.COUNT
# select count(*) from users where age > 30
> db.users.find({age:{$gt:30}}).count()
7.OR
# select * from users where age = 25 or age = 28
> db.users.find({$or:[{age:25}, {age:28}]})
# select * from users where age <= 23 or age >= 33
db.users.find({$or:[{age:{$lte:23}}, {age:{$gte:33}}]})
26](https://image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-26-2048.jpg)

![MongoDB操作
Distinct
> db.colors.distinct('name')
[ "blue", "green", "orange", "purple", "red", "yellow" ]
Group
#SELECT name, sum(marks) FROM user where name='foo' GROUP BY name
>db.user.group({
key : {‘name’ : true},
cond: {‘name’ : ‘foo’},
reduce: function(obj,prev) { prev.msum += obj.marks; },
initial: {msum : 0}
});
Index
// single ascending
db.colors.ensureIndex({name: 1})
// unique
db.colors.ensureIndex({email: 1}, {unique: true})
// single descending
db.colors.ensureIndex({createdat: -1})
// compound
> db.colors.ensureIndex({name: 1, createdat: -1})
28](https://image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-28-2048.jpg)

![One to Many
>db.news.insert({
title:'油价上涨,伤不起啊~',
author:'zhangsan',
date:'2012-3-21',
uid:[1,2,3,4]
tag:["油价","中国","伤不起"]
});
32](https://image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-32-2048.jpg)
![>db.news.insert({
One to Many
"author" : "发改委",
"body" : "发改委于3月20日上调油价,国内汽柴油价格每吨上调600元!",
"comments" : [{
"author" : "犀利哥",
“body” : “幸亏哥没车,涨吧,涨吧,都来像我这样吧!",
"date" : "2012-3-20"
}, {
"author" : "凤姐",
"body" : "你妹的,伤不起啊 ~",
"date" : "2012-3-20"
}, {
"author" : "小崔",
"body" : "尼玛,坑爹啊!刚说话十块钱能买啥?你就上涨油价了~",
"date" : "2012-3-20"
}],
"date" : "2012-3-20",
"tags" : ["汽油", "油价", "发改委"],
"title" : "发改委于3月20日上调油价,国内汽柴油价格每吨上调600元!"
});
33](https://image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-33-2048.jpg)

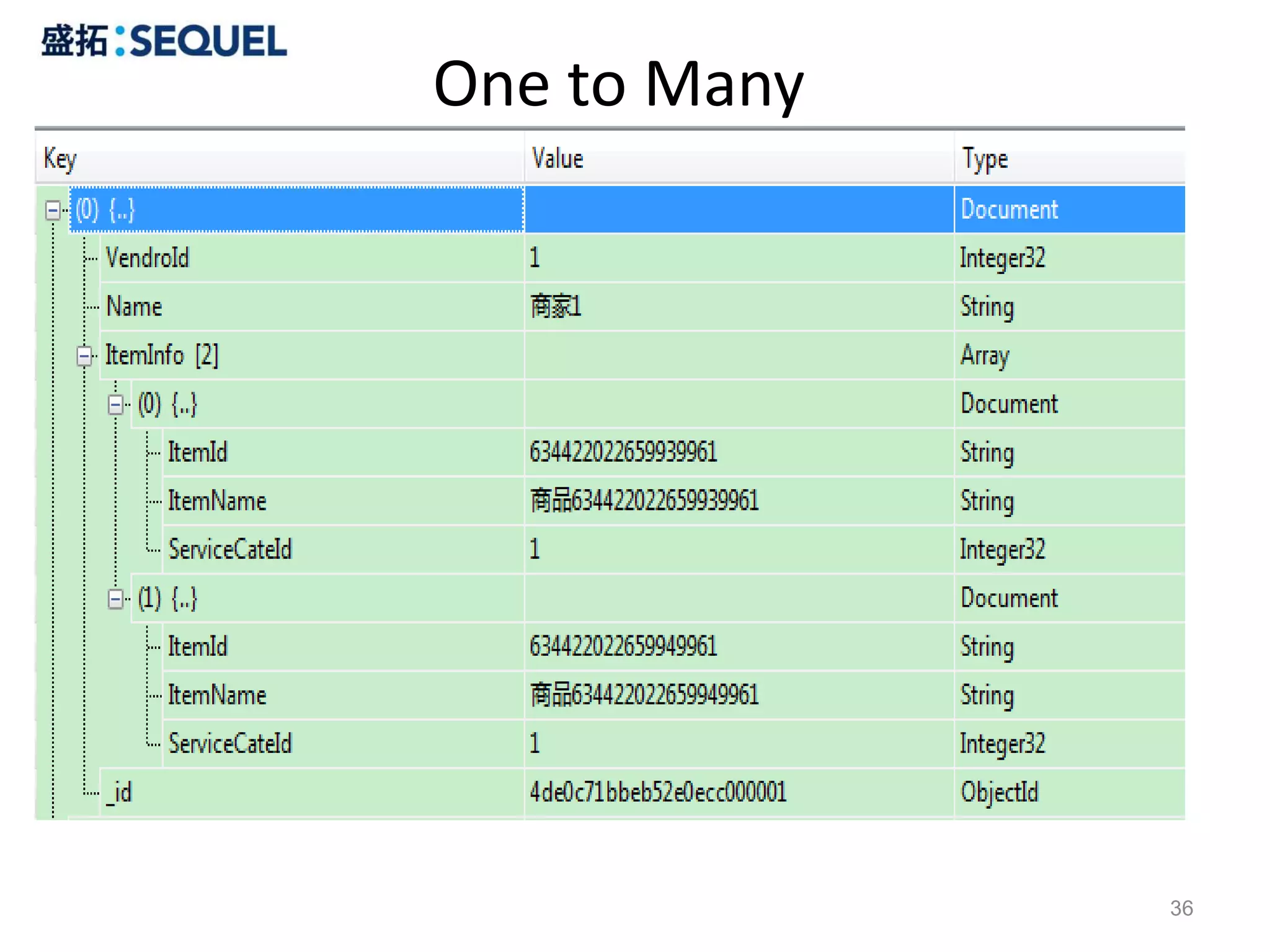
![One to Many
例如:
{
"VendroId": 1,
"Name": "商家1",
"ItemInfo": [
{
"ItemId": "634422022659939961",
"ItemName": "商品634422022659939961",
"ServiceCateId": 1
},
{
"ItemId": "634422022659949961",
"ItemName": "商品634422022659949961",
"ServiceCateId": 1
}
],
"_id": "4de0c71bbeb52e0ecc000001"
}
db.VendorInfo.find({“ItemInfo”:{“$elemMatch”:{"ItemId",
"634422022659949961"}}})
35](https://image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-35-2048.jpg)
![Many to Many
>db.sites.insert({domain: 'orderedlist.com'})
>db.sites.insert({domain: 'railstips.org'})
> db.users.insert({
name: 'John',
authorizations: [
ObjectId('4bee280f9e89db4e12bf78e2'),
ObjectId('4bee283c9e89db4e12bf78e3')
]
})
> db.users.insert({
name: 'Steve',
authorizations: [
ObjectId('4bee280f9e89db4e12bf78e2')
]
})
> var orderedlist = db.sites.findOne({domain:'orderedlist.com'})
db.users.find({authorizations:orderedlist._id})
> var railstips = db.sites.findOne({domain:'railstips.org'})
db.users.find({authorizations:railstips._id})
> var john = db.users.findOne({name:'John'})
> db.sites.find({_id:{$in: john.authorizations}})
37](https://image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-37-2048.jpg)


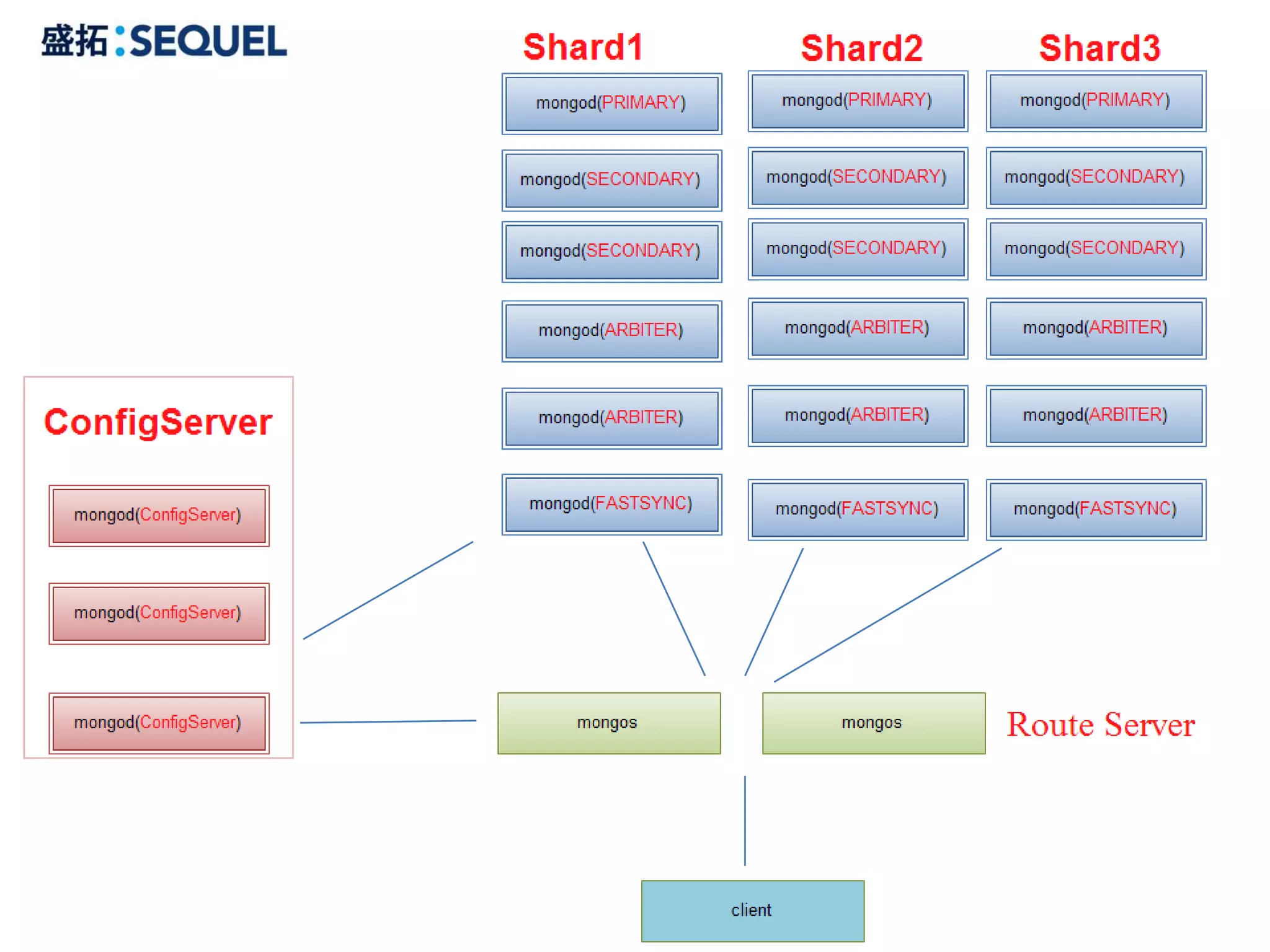
![分片(sharding)
[“a”,”f”] [“f”,”n”] [“n”,”t”] [“t”,”{”]
(Shard1) (Shard2) (Shard3) (Shard4)
42](https://image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-42-2048.jpg)
![分片(sharding)
[“a”,”c”] [“c”,”n”] [“n”,”t”] [“t”,”{”]
(Shard1) (Shard2) (Shard3) (Shard4)
[“a”,”c”] [“c”,”n”] [“n”,”t”] [“t”,”w”] [“w”,”{”]
(Shard1) (Shard2) (Shard3) (Shard4) (Shard5)
43](https://image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-43-2048.jpg)
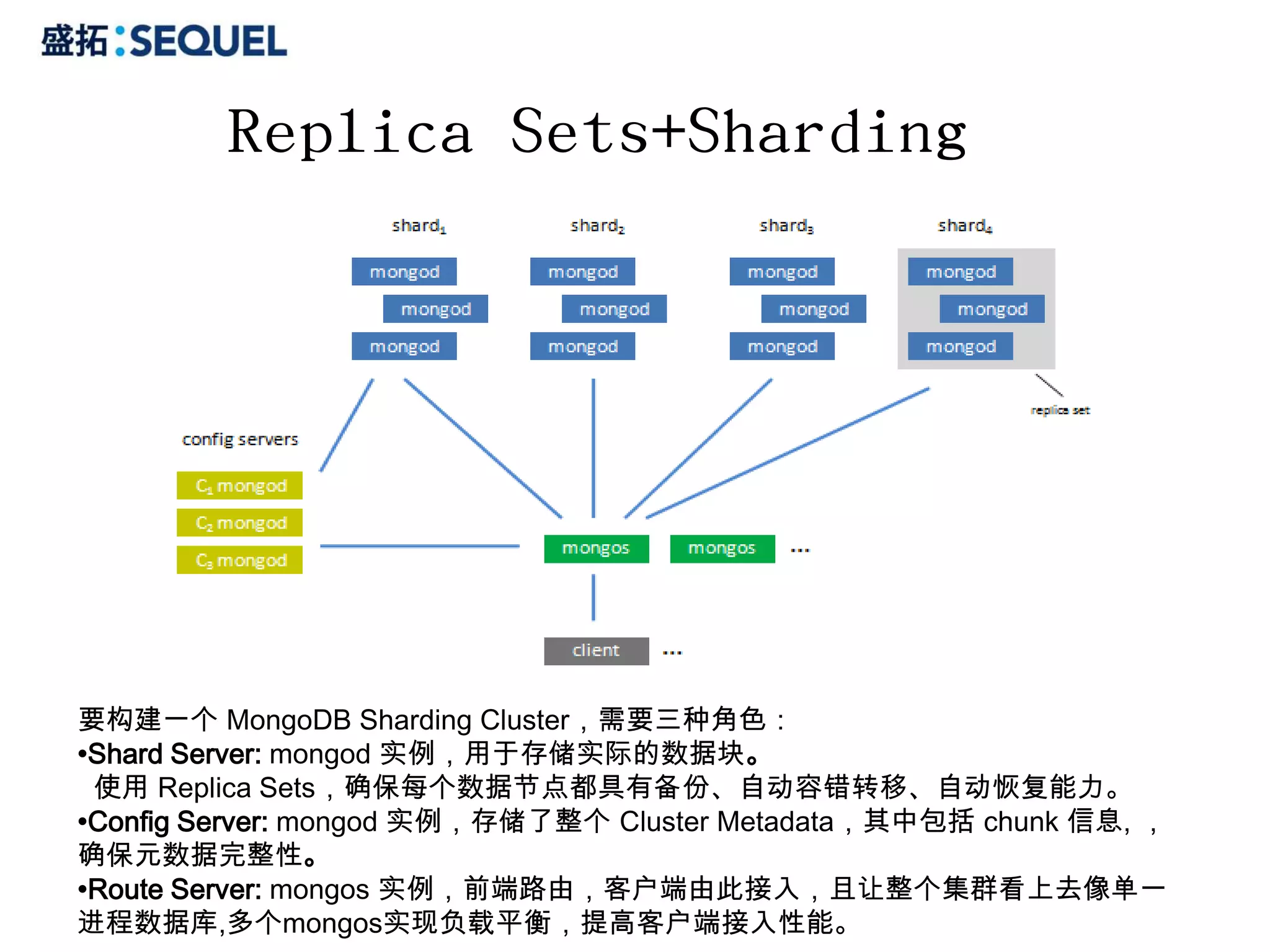
![分片(sharding)
1.一分片多区间
假设:把shard1的分片划分为二个区间([“a”,”d”],[“d”,“f”]),一个区间
的数据称为块(chunk),把一个块的区间一分为二时,一个块也就变成了二个块。
2.MongoDB的数据分配:当一个块变得越来越大时,MongoDB会自动将其分
割成二个较小的块。如果分片间比例失调,则MongoDB会通过迁移块来确保均衡。
3.块的创建取决你选择的片键(shrad key),片键可以是任意字段和字段的组合。
4.如果存在多个可用的分片,只要块的数量足够多,MongoDB就会把数据迁移到
其他分片上。这个迁移的过程叫做平衡(balancing),由均衡器(balancer)的进程负
责执行。
5.文件使用MMAP进行内存映射,会将所有数据文件映射到内存中,但是只是虚
拟内存,只有访问到这块数据时才会交换到物理内存。如果是读操作,内存中
的数据起到缓存的作用,如果是写操作,内存还可以把随机的写操作转换成顺
序的写操作。
6.对每一个块来说,其头部包含了一些块的元数据,比如自己的位置,上一个和下
一个块的位置以及块中第一条和最后一条记录的位置指针。剩下的部分用于存储 44
具体的数据,具体数据之间也是通过双向链接来进行连接。](https://image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-44-2048.jpg)





























![MongoDB操作
4.SLICE
# select * from users skip 2 limit 3
> db.users.find().skip(2).limit(3)
Conditional Operators
# select * from users where sex = 1 and age > 23 and age < 28
> db.users.find({sex:1, age:{$gt:23, $lt:28}})
比较操作包括:$gt (>)、$lt (<)、$gte (>=)、$lte(<=)、$ne (!=)
5. IN
# select * from users where age in (23, 26, 32)
> db.users.find({age:{$in:[23,26,32]}})
对应的操作符有 $nin (not in)。
6.COUNT
# select count(*) from users where age > 30
> db.users.find({age:{$gt:30}}).count()
7.OR
# select * from users where age = 25 or age = 28
> db.users.find({$or:[{age:25}, {age:28}]})
# select * from users where age <= 23 or age >= 33
db.users.find({$or:[{age:{$lte:23}}, {age:{$gte:33}}]})
26](https://crownmelresort.com/image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-26-2048.jpg)

![MongoDB操作
Distinct
> db.colors.distinct('name')
[ "blue", "green", "orange", "purple", "red", "yellow" ]
Group
#SELECT name, sum(marks) FROM user where name='foo' GROUP BY name
>db.user.group({
key : {‘name’ : true},
cond: {‘name’ : ‘foo’},
reduce: function(obj,prev) { prev.msum += obj.marks; },
initial: {msum : 0}
});
Index
// single ascending
db.colors.ensureIndex({name: 1})
// unique
db.colors.ensureIndex({email: 1}, {unique: true})
// single descending
db.colors.ensureIndex({createdat: -1})
// compound
> db.colors.ensureIndex({name: 1, createdat: -1})
28](https://crownmelresort.com/image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-28-2048.jpg)



![One to Many
>db.news.insert({
title:'油价上涨,伤不起啊~',
author:'zhangsan',
date:'2012-3-21',
uid:[1,2,3,4]
tag:["油价","中国","伤不起"]
});
32](https://crownmelresort.com/image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-32-2048.jpg)
![>db.news.insert({
One to Many
"author" : "发改委",
"body" : "发改委于3月20日上调油价,国内汽柴油价格每吨上调600元!",
"comments" : [{
"author" : "犀利哥",
“body” : “幸亏哥没车,涨吧,涨吧,都来像我这样吧!",
"date" : "2012-3-20"
}, {
"author" : "凤姐",
"body" : "你妹的,伤不起啊 ~",
"date" : "2012-3-20"
}, {
"author" : "小崔",
"body" : "尼玛,坑爹啊!刚说话十块钱能买啥?你就上涨油价了~",
"date" : "2012-3-20"
}],
"date" : "2012-3-20",
"tags" : ["汽油", "油价", "发改委"],
"title" : "发改委于3月20日上调油价,国内汽柴油价格每吨上调600元!"
});
33](https://crownmelresort.com/image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-33-2048.jpg)

![One to Many
例如:
{
"VendroId": 1,
"Name": "商家1",
"ItemInfo": [
{
"ItemId": "634422022659939961",
"ItemName": "商品634422022659939961",
"ServiceCateId": 1
},
{
"ItemId": "634422022659949961",
"ItemName": "商品634422022659949961",
"ServiceCateId": 1
}
],
"_id": "4de0c71bbeb52e0ecc000001"
}
db.VendorInfo.find({“ItemInfo”:{“$elemMatch”:{"ItemId",
"634422022659949961"}}})
35](https://crownmelresort.com/image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-35-2048.jpg)

![Many to Many
>db.sites.insert({domain: 'orderedlist.com'})
>db.sites.insert({domain: 'railstips.org'})
> db.users.insert({
name: 'John',
authorizations: [
ObjectId('4bee280f9e89db4e12bf78e2'),
ObjectId('4bee283c9e89db4e12bf78e3')
]
})
> db.users.insert({
name: 'Steve',
authorizations: [
ObjectId('4bee280f9e89db4e12bf78e2')
]
})
> var orderedlist = db.sites.findOne({domain:'orderedlist.com'})
db.users.find({authorizations:orderedlist._id})
> var railstips = db.sites.findOne({domain:'railstips.org'})
db.users.find({authorizations:railstips._id})
> var john = db.users.findOne({name:'John'})
> db.sites.find({_id:{$in: john.authorizations}})
37](https://crownmelresort.com/image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-37-2048.jpg)




![分片(sharding)
[“a”,”f”] [“f”,”n”] [“n”,”t”] [“t”,”{”]
(Shard1) (Shard2) (Shard3) (Shard4)
42](https://crownmelresort.com/image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-42-2048.jpg)
![分片(sharding)
[“a”,”c”] [“c”,”n”] [“n”,”t”] [“t”,”{”]
(Shard1) (Shard2) (Shard3) (Shard4)
[“a”,”c”] [“c”,”n”] [“n”,”t”] [“t”,”w”] [“w”,”{”]
(Shard1) (Shard2) (Shard3) (Shard4) (Shard5)
43](https://crownmelresort.com/image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-43-2048.jpg)
![分片(sharding)
1.一分片多区间
假设:把shard1的分片划分为二个区间([“a”,”d”],[“d”,“f”]),一个区间
的数据称为块(chunk),把一个块的区间一分为二时,一个块也就变成了二个块。
2.MongoDB的数据分配:当一个块变得越来越大时,MongoDB会自动将其分
割成二个较小的块。如果分片间比例失调,则MongoDB会通过迁移块来确保均衡。
3.块的创建取决你选择的片键(shrad key),片键可以是任意字段和字段的组合。
4.如果存在多个可用的分片,只要块的数量足够多,MongoDB就会把数据迁移到
其他分片上。这个迁移的过程叫做平衡(balancing),由均衡器(balancer)的进程负
责执行。
5.文件使用MMAP进行内存映射,会将所有数据文件映射到内存中,但是只是虚
拟内存,只有访问到这块数据时才会交换到物理内存。如果是读操作,内存中
的数据起到缓存的作用,如果是写操作,内存还可以把随机的写操作转换成顺
序的写操作。
6.对每一个块来说,其头部包含了一些块的元数据,比如自己的位置,上一个和下
一个块的位置以及块中第一条和最后一条记录的位置指针。剩下的部分用于存储 44
具体的数据,具体数据之间也是通过双向链接来进行连接。](https://crownmelresort.com/image.slidesharecdn.com/mongodb-120330073959-phpapp02/75/Mongo-db-44-2048.jpg)




















![[Black Belt Online Seminar] AWS上でのログ管理](https://cdn.slidesharecdn.com/ss_thumbnails/aws-log-mgmt-161201043056-thumbnail.jpg?width=640&height=640&fit=bounds)

![[AWSマイスターシリーズ] Amazon CloudFront / Amazon Elastic Transcoderによるコンテンツ配信](https://cdn.slidesharecdn.com/ss_thumbnails/20131120aws-medister-regenerate-cloudfrontetspublic-131120181553-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























































