What is NLP?
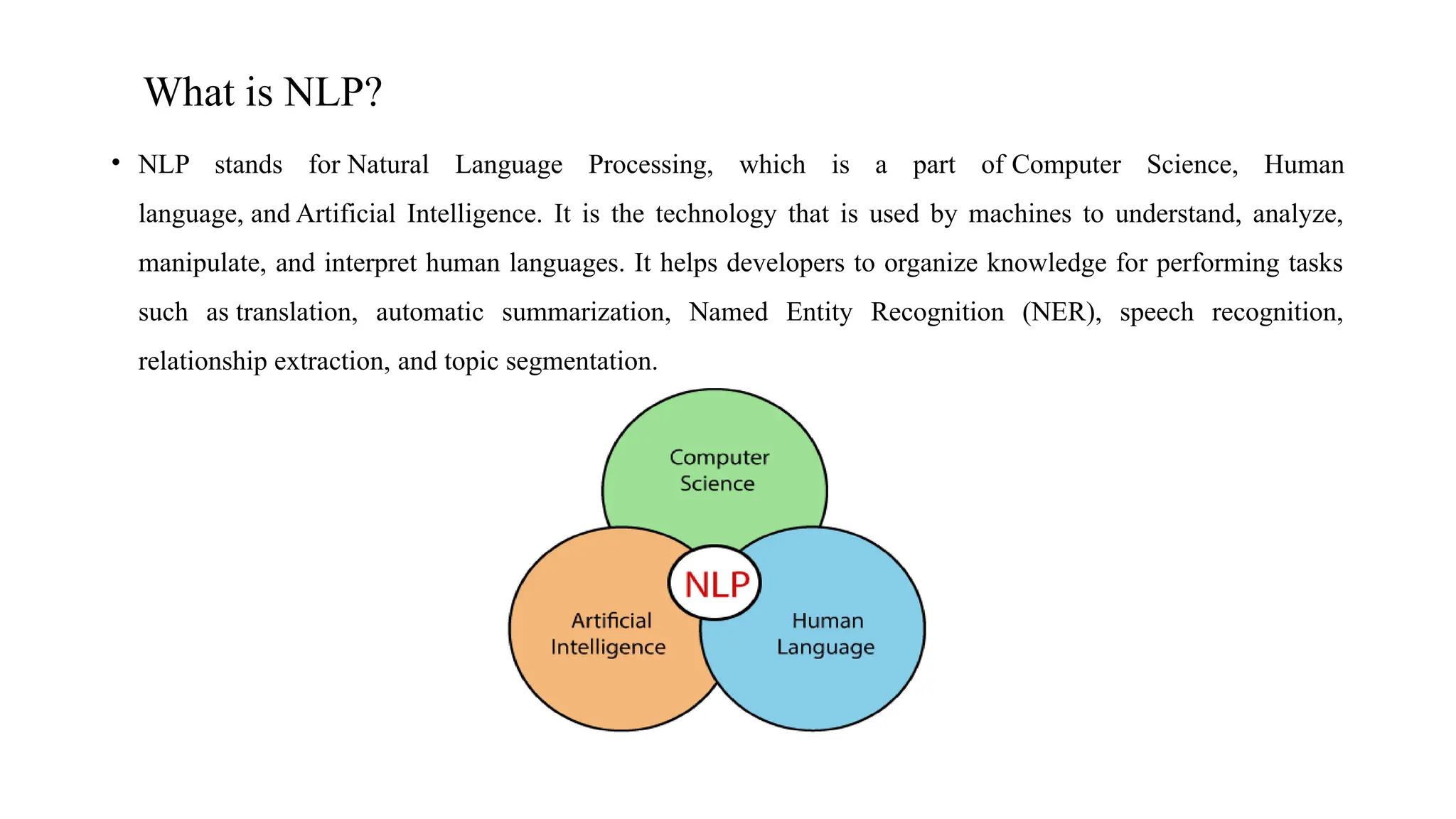
•NLP stands for Natural Language Processing, which is a part of Computer Science, Human
language, and Artificial Intelligence. It is the technology that is used by machines to understand, analyze,
manipulate, and interpret human languages. It helps developers to organize knowledge for performing tasks
such as translation, automatic summarization, Named Entity Recognition (NER), speech recognition,
relationship extraction, and topic segmentation.
3.
Advantages of NLP
•NLP helps users to ask questions about any subject and get a direct response within seconds.
• NLP offers exact answers to the question means it does not offer unnecessary and unwanted
information.
• NLP helps computers to communicate with humans in their languages.
• It is very time efficient.
• Most of companies use NLP to improve the efficiency of documentation processes, accuracy
of documentation, and identify the information from large databases.
4.
Components of NLP
NaturalLanguage Understanding (NLU)
• Natural Language Understanding (NLU) helps the machine to understand and analyse human language by
extracting the metadata from content such as concepts, entities, keywords, emotions, relations, and semantic
roles.
• NLU is mainly used in Business applications to understand the customer's problem in both spoken and
written language.
5.
Natural Language Generation(NLG)
• Natural Language Generation (NLG) acts as a translator that converts the computerized data into natural
language representation.
• It mainly involves Text planning, Sentence planning, and Text Realization.
6.
Applications of NLP
1.Question Answering
• Question Answering focuses on building systems that automatically answer the questions asked by humans in a natural language.
2. Spam Detection
• Spam detection is used to detect unwanted e-mails getting to a user's inbox.
3. Sentiment Analysis
• Sentiment Analysis is also known as opinion mining. It is used on the web to analyze the attitude, behaviour, and emotional state of
the sender.
• This application is implemented through a combination of NLP (Natural Language Processing) and statistics by assigning the values
to the text (positive, negative, or natural), identifying the mood of the context (happy, sad, angry, etc.)
4. Machine Translation
• Machine translation is used to translate text or speech from one natural language to another natural language.
7.
5. Spelling correction
•Microsoft Corporation provides word processor software like MS-word and PowerPoint for spelling
correction.
6. Chatbot
• Implementing the Chatbot is one of the important applications of NLP. It is used by many companies to
provide customer chat services.
8.
Natural language processingand its neighbors
• Computational Linguistics
Computational linguistics (CL) is the application of computer science to the analysis and comprehension
of written and spoken language.
As an interdisciplinary field, CL combines linguistics with computer science and artificial intelligence (
AI) and is concerned with understanding language from a computational perspective. Computers that are
linguistically competent help facilitate human interaction with machines and software.
9.
Machine learning
• Machinelearning (ML) for natural language processing (NLP) and text analytics involves using machine
learning algorithms and “narrow” artificial intelligence (AI) to understand the meaning of text documents.
• Narrow AI, also known as Weak AI, refers to artificial intelligence systems that are designed to perform
specific tasks or functions within a limited domain.
• These documents can be just about anything that contains the text: social media comments, online reviews,
survey responses, and even financial, medical, legal and regulatory documents.
• In essence, the role of machine learning and AI in natural language processing and text analytics is to
improve, accelerate and automate the underlying text analytics functions and NLP features that turn
this unstructured text into useable data and insights.
10.
Natural language processinghas characteristics that distinguish it from many of machine learning’s other application
domains.
• Unlike images or audio, text data is fundamentally discrete, with meaning created by combinatorial arrangements
of symbolic units.
• “Discrete" refers to a variable or data that can only take on distinct values or specific points on a scale. Discrete
data is characterized by being countable and having gaps or intervals between the possible values. E.g.: No of
students in a class.
• Although the set of words is discrete, new words are always being created. Furthermore, the distribution over
words (and other linguistic elements) resembles that of power law (there will be a few very frequent words and a
long tail of rare words).
• In statistics, a power law is a functional relationship between two quantities, where a relative change in one
quantity results in a proportional relative change in the other quantity, independent of the initial size of those
quantities: one quantity varies as a power of another.
11.
• For example,if we analyze a large text corpus and rank the words based on their frequency, we would
typically find that the most frequent word occurs much more often than the second most frequent word, and
so on. The relationship between word frequency and rank follows a power law distribution.
12.
• Language iscompositional: units such as words can combine to create phrases, which can combine by the
very same principles to create larger phrases.
• For example, a noun phrase can be created by combining a smaller noun phrase with a prepositional
phrase.
• Eg: Priya caught the bus on time. "On time" is the prepositional phrase.
13.
Artificial Intelligence
• AIor Artificial Intelligence is a branch of computing that’s dedicated to designing and implementing systems
capable of ingesting information, drawing inferences from data, and then performing actions in a manner
similar to or superior to the way that human beings react.
• Natural Language Processing or NLP in AI is the sub-branch of artificial intelligence whose focus uses
natural language as the medium of interaction between humans and machines.
• The goal of artificial intelligence is to build software and robots with the same range of abilities as humans.
14.
Computer Science
• Thediscrete and recursive nature of natural language invites the application of theoretical ideas from
computer science.
• Linguists such as Chomsky and Montague have shown how formal language theory can help explain the natural
language's syntax and semantics. Formal language theory is concerned with the purely syntactical(structure) aspects,
rather than the semantics or meaning of the strings. Formal language theory is a branch of computer science and
mathematics that deals with the study of formal languages and their properties. It provides a theoretical framework
for understanding and analyzing formal languages, which are used in areas such as programming languages,
compiler design, artificial intelligence, and computational linguistics.
• Theoretical models such as finite-state and pushdown automata(Mathematical models of computation) are the
basis for many practical natural language processing systems.
15.
• Algorithms forsearching the combinatorial space of analyses of natural language utterances can be analyzed
in terms of their computational complexity, and theoretically motivated approximations can sometimes be
applied.
• The combinatorial space of analyses in natural language refers to the vast number of possible interpretations
or structures that can be generated when analyzing and processing natural language data.
16.
Speech processing
• Naturallanguage is often communicated in spoken form, and speech recognition is the task of converting
an audio signal to text.
• From one perspective, this is a signal processing problem, which might be viewed as a preprocessing step
before natural language processing can be applied.
• However, context plays a critical role in speech recognition by human listeners: knowledge of the
surrounding words influences perception and helps to correct for noise.
17.
Ethics
Ethics in NaturalLanguage Processing (NLP) refers to the responsible and ethical considerations surrounding
the development, deployment, and use of NLP technologies. As NLP systems become more sophisticated and
pervasive, it is essential to address ethical concerns to ensure that these technologies are developed and used in
a manner that respects societal values, fairness, privacy, and human rights. Here are some key ethical
considerations in NLP:
• Bias and Fairness: NLP models can be influenced by biases present in the training data, leading to biased
outcomes and unfair treatment of individuals or groups. It is crucial to address and mitigate biases to ensure
fairness, and equality, and avoid reinforcing discriminatory practices.
18.
Does language technologylearn to replicate social biases from text corpora(A corpus is a large and structured
set of machine-readable texts that have been produced in a natural communicative setting), and does it support
these biases?
The algorithms are often based on stereotypes, as in this example. These kinds of systems are created using
large amounts of language data – and this naturally occurring language data contains biases: systematic and
unfair discrimination against certain individuals or groups of individuals in favour of others.
19.
• Privacy andData Protection: NLP systems often require access to personal and sensitive data. Safeguarding
privacy and implementing robust data protection measures are essential to prevent unauthorized access,
misuse, or disclosure of sensitive information.
• Accountability: NLP models should be accountable for their decisions and actions. Establishing mechanisms
for auditing, testing, and validating models, as well as providing avenues for recourse and redress in the event
of errors or harm, is important.
20.
Three themes innatural language processing
Natural language processing covers a diverse range of tasks, methods, and linguistic phenomena.
• Learning and Knowledge
• Search and Learning
• Relational, compositional, and distributional perspectives
21.
Learning and Knowledge
•Learning in NLP refers to the process of acquiring knowledge or skills from data in order to improve the
performance of natural language processing systems. This can involve training machine learning models, neural
networks, or other statistical models using labelled or unlabeled data to extract patterns, relationships, and
structures in natural language.
• Knowledge in NLP refers to the information, facts, and rules that are acquired and represented by NLP systems.
This knowledge can be explicit, such as linguistic rules or lexical resources, or implicit, derived from patterns
learned from data. Knowledge in NLP is used to understand, analyze, generate, and process natural language text.
22.
• There area number of ways in which knowledge and learning can be combined in natural language
processing. Many supervised learning systems make use of carefully engineered features, which transform
the data into a representation that can facilitate learning.
• For example, in a task like a search, it may be useful to identify each word’s stem(basic word), so that a
system can more easily generalize across related terms such as whale, whales, whalers, and whaling. (This
issue is relatively benign in English(having no significant effect), as compared to the many other languages
which include much more elaborate systems of prefixes and suffixes.) Such features could be obtained from a
hand-crafted resource, like a dictionary that maps each word to a single root form.
23.
In NLP, stemmingis the process of reducing words to their base or root form, called the stem. The stem
represents the core meaning of the word and is typically obtained by removing prefixes, suffixes, and other
affixes from the word.
The purpose of stemming is to reduce the dimensionality of text data and bring related words to a common base
form. Stemming helps in capturing the essence of words and simplifies text analysis tasks such as information
retrieval, text mining, and sentiment analysis.
Here's an example to illustrate stemming:
Original Words: running, runner, runs
Stemmed Words: run, run, run
24.
• Another synthesisof learning and knowledge is in model structure: building machine learning models whose
architectures are inspired by linguistic theories.
• For example, the organization of sentences is often described as compositional, with the meaning of larger
units gradually constructed from the meaning of their smaller constituents. This idea can be built into the
architecture of a deep neural network, which is then trained using contemporary deep learning techniques
• The mathematicalformula ŷ = argmax Ψ(x, y; θ) represents a common notation used in machine learning and statistical
modelling, specifically in the context of structured prediction tasks in natural language processing (NLP).
• ŷ: It represents the predicted output or label for a given input x. In NLP, this can refer to various tasks such as part-of-
speech tagging, named entity recognition, or syntactic parsing. The goal is to predict the most suitable output given the
input.
• argmax: The argmax function returns the argument (in this case, y) that maximizes the function Ψ(x, y; θ). It finds the
value of y that maximizes the score or probability assigned to it by the model.
• Ψ(x, y; θ): Ψ is a scoring or feature function that takes as input (the input-output pair (x, y) and model parameters θ). It
calculates a score or measure of compatibility between the input x and the output y, guided by the model parameters θ. The
scoring function Ψ can be defined in various ways depending on the specific task and modelling approach used in NLP.
• θ: It represents the model parameters or weights that are learned during the training process. These parameters are
optimized to maximize the performance of the model on the given task.
28.
The basic structurementioned previously can be applied to a huge range of problems.
For example, the input x might be a social media post, and the output y might be the labelling of the emotional sentiment or
x could be a sentence in French, and the output y could be a sentence in Tamil or x might be a sentence in English, and y
might be a representation of the syntactic structure of the sentence or x might be a news article and y might be a structured
record of the events.
• This formulation reflects an implicit decision that language processing algorithms will have two distinct modules:
29.
• Search
The searchmodule is responsible for computing the argmax of the function ψ. It finds the output ŷ
that gets the best score with respect to the input x. This is easy when the search space Y(x) is small
enough to enumerate, or when the scoring function ψ has a convenient decomposition into parts.
30.
Learning
The learning moduleis responsible for finding the parameters. This is typically (but not always) done by
processing a large dataset of labelled examples,
Like search, learning is also approached through the framework of optimization, Because the parameters are
usually continuous, learning algorithms generally rely on numerical optimization(minimizing/maximizing an
evaluation measure)to identify vectors of real-valued parameters that optimize some function of the model and
the labelled data.
31.
• The divisionof natural language processing into separate modules for search and learning makes it possible
to reuse generic algorithms across many tasks and models.
• Much of the work of natural language processing can be focused on the design of the model — identifying
and formalizing the linguistic phenomena that are relevant to the task at hand — while reaping the benefits of
decades of progress in search, optimization, and learning.
32.
• When amodel is capable of making subtle linguistic distinctions, it is said to be expressive. Expressiveness is
often traded off against efficiency of search and learning.
• For example, a word-to-word translation model makes search and learning easy, but it is not expressive
enough to distinguish good translations from bad ones.
• Many of the most important problems in natural language processing seem to require expressive models, in
which the complexity of search grows exponentially with the size of the input.
33.
Relational, compositional, anddistributional perspectives
Any element of language — a word, a phrase, a sentence, or even a sound — can be described from at least three
perspectives. Consider the word journalist.
A journalist is a subcategory of a profession, and an anchorwoman is a subcategory of a journalist; furthermore, a
journalist performs journalism, which is often, but not always, a subcategory of writing. This relational perspective on
meaning is the basis for semantic ontologies(Ontology is the branch of metaphysics) such as WORDNET(a large
lexical database of English), which enumerate the relations that hold between words and other elementary semantic
units. The power of the relational perspective is illustrated by the following example:
34.
Uma Shanthi interviewedAna. She works for the college newspaper.
Who works for the college newspaper?
The word journalist, while not stated in the example, implicitly links the interview to the newspaper, making
Uma Shanthi the most likely referent for the pronoun.
35.
Yet despite theinferential power of the relational perspective, it is not easy to formalize computationally.
Exactly which elements are to be related? Are journalists and reporters distinct, or should we group them into a
single unit? Is the kind of interview performed by a journalist the same as the kind that one undergoes when
applying for a job?
Difficulties in ontology construction have led some linguists to argue that there is no task-independent way(not
influenced by a specific task or goal) to partition up word meanings.
36.
Some problems areeasier. Each member in a group of journalists is a journalist: the –s suffix distinguishes the
plural meaning from the singular in most of the nouns in English.
Similarly, a journalist can be thought of, perhaps colloquially, as someone who produces or works on a journal.
(Taking this approach even further, the word journal derives from the French jour+nal, or day+ly = daily.)
In this way, the meaning of a word is constructed from the constituent parts — the principle of compositionality.
This principle can be applied to larger units: phrases, sentences, and beyond.
Indeed, one of the great strengths of the compositional view of meaning is that it provides a roadmap for
understanding entire texts and dialogues through a single analytic lens, grounding out in the smallest parts of
individual words.
37.
But alongside journalistsand anti-parliamentarians, there are many words that seem to be linguistic atoms:
think, for example, of whale, blubber, and Nantucket. Idiomatic phrases like kick the bucket(die or to pass
away) and shoot the breeze(small talk) have meanings that are quite different from the sum of their parts.
Composition is of little help for such words and expressions, but their meanings can be ascertained—or at least
approximated—from the contexts in which they appear. Take, for example, blubber, which appears in such
contexts as (1.4) The blubber served them as fuel.
In this sentence, "blubber" refers to the thick layer of fat found under the skin of marine mammals, such as
whales or seals. Here, it is mentioned that the blubber was used as fuel, implying that it was burned or utilized
for heat or energy.
38.
b. . .. extracting it from the blubber of the large fish . . .
In this sentence, "blubber" is again referring to the fatty layer found in marine mammals. Here, it suggests that
the process involves extracting the fat from the blubber of large fish, possibly for some specific purpose or use.
c. Amongst oily substances, blubber has been employed as manure.
In this sentence, "blubber" is used to denote the fatty tissue of animals. Here, it states that blubber has been used
as manure, indicating that it has been utilized as a fertilizer or organic material to enrich the soil for agricultural
purposes.
39.
These contexts formthe distributional properties of the word blubber, and they link it to words which can
appear in similar constructions: fat, pelts, and barnacles. This distributional perspective makes it possible to
learn about meaning from unlabeled data alone; unlike relational and compositional semantics, no manual
annotation or expert knowledge is required. Distributional semantics is thus capable of covering a huge range of
linguistic phenomena. However, it lacks precision: blubber is similar to fat in one sense, to pelts in another
sense, and to barnacles in still another. The question of why all these words tend to appear in the same contexts
is left unanswered.
40.
The relational, compositional,and distributional perspectives all contribute to our understanding of
linguistic meaning, and all three appear to be critical to natural language processing. Yet they are uneasy
collaborators, requiring seemingly incompatible representations and algorithmic approaches


















































































![Intro to AI of [chapter 6-7- 8 ] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/introtoaichapter6-7-81-250124165251-b71db41b-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


















