Big Data andHadoop
Module 1: Introduction to Big Data and Hadoop
2.
Slide 2
Session Objectives
ThisSession will help you to:
ᗍ Understand what is Big Data?
ᗍ List the challenges associated with Big Data
ᗍ Understand the difference between Real-time and Batch Processing
ᗍ Understand Hadoop capabilities
ᗍ Understand Hadoop ecosystem
3.
Slide 3
Definition ofBig Data
Big data is a buzzword, or catch-phrase, used to describe a massive volume of both structured and
unstructured data
that is so large that it's difficult to process using traditional database and software techniques
In most enterprise scenarios the data is too big or it moves too fast or it exceeds current processing capacity.
Big data has the potential to help companies improve operations and make faster, more intelligent decisions
Big Data is the term applied to data sets whose size is beyond the ability of the commonly used software
tools to capture, manage, and process
4.
Slide 4
Walmart
ᗍ US$485.651 Billion US Retailer
ᗍ Handles more than a million transactions every day, produces more 2.5 Petabytes on daily
basis
ᗍ Has dedicated data centers across the world to handle the above data (Has one in Bangalore
also)
5.
Slide 5
Facebook
ᗍ Ithas about a billion users as we speak
ᗍ Generates close to 500 TB of data per day
ᗍ Fires 70 thousand queries on that every
day
ᗍ Inventors and one of the biggest users to
hive
6.
Slide 6
Big DataContext with Case Studies
Cricket Telecast on Star
Sports
ᗍ Keys to success for a team
ᗍ Batsman’s strong or weak zone. Runs scoring graph
ᗍ Bowlers speed, Swing and Wicket Taking delivery
graph
7.
Slide 7
What isBig Data?
ᗍ Huge Amount of Data (Terabytes or Petabytes)
ᗍ Big data is the term for a collection of data sets
so large and complex that it becomes difficult
to process using on-hand database
management tools or traditional data
processing applications
ᗍ The challenges include capture, curation,
storage, search, sharing, transfer, analysis, and
visualization
8.
Three types ofdata can be identified:
ᗍ Unstructured Data
• Data which do not have a pre-defined data
model
• E.g. Text files, log files
ᗍ Semi-structured Data
• Data which do not have a formal data model
• E.g. XML files
ᗍ Structured Data
• Data which is represented in a tabular format
• E.g. Databases
Slide 8
Types of Data
Slide 10
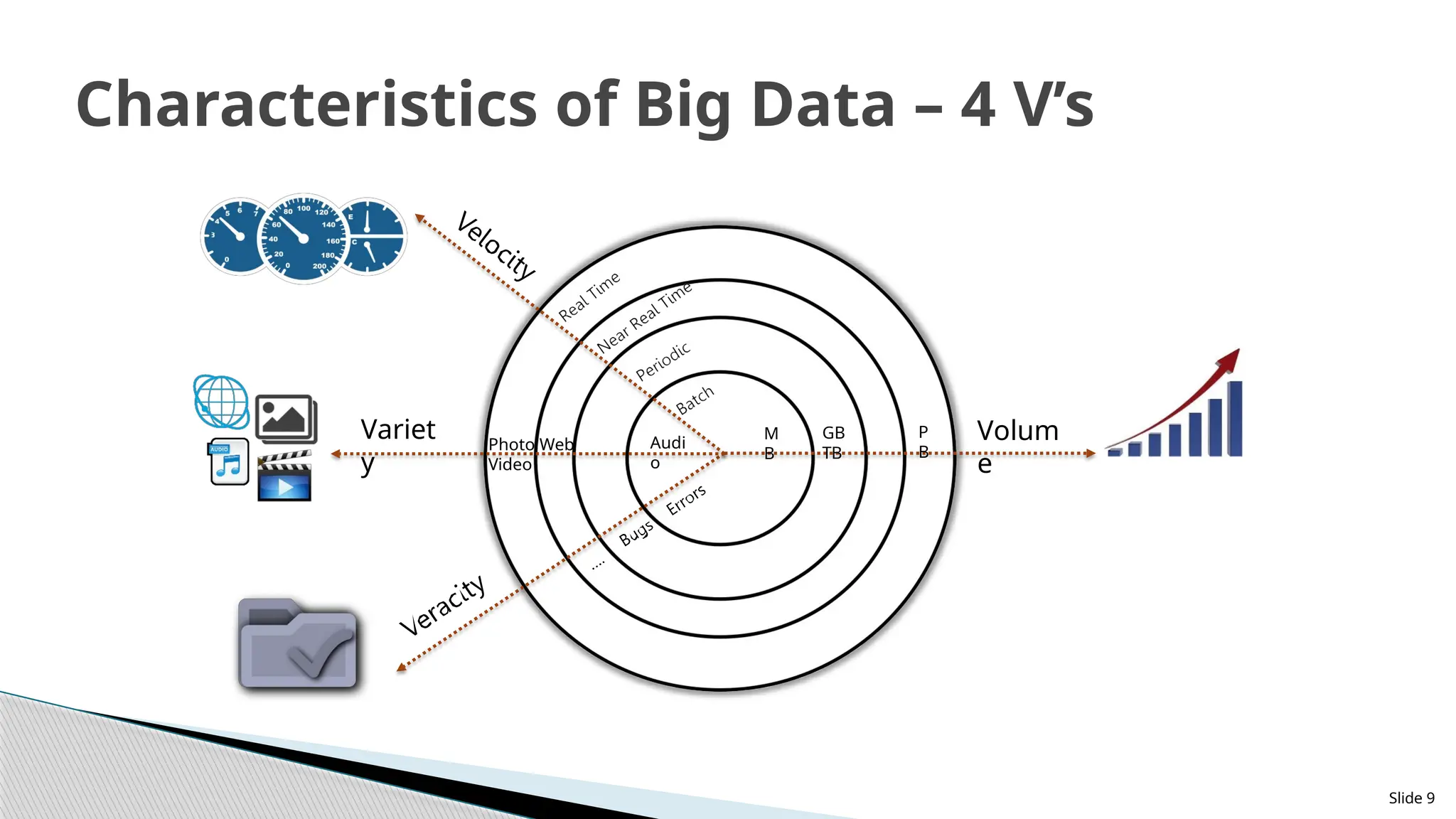
The V’sof Big Data
ᗍ Volume: 12 terabytes of Tweets created each day
ᗍ Velocity: Scrutinize 5 million trade events created each day to identify potential fraud
ᗍ Variety: Trade data, Sensor data, Audio, Video, Flight Tracking, R&D, Log files, Social media and more
ᗍ Veracity: The quality of the data being captured can vary greatly. Accuracy of analysis depends on the
veracity of the source data
11.
Slide 11
Limitations ofBig Data/Existing DWH
Solutions
ᗍ Two aspects: Storage of data and Analysis of data
ᗍ Limitation of existing IT infrastructure and resources
ᗍ Vertical Scalability is not always a solution: Upgrading server and
storage
ᗍ RDBMS is not designed to scale out
ᗍ Can not handle unstructured data
ᗍ Cost of commercially available solutions is significantly high
12.
Slide 12
Need forNew Approach
ᗍ A new approach to the problem is required:
ᗍ Process all types of data; Structured, Semi Structured and Unstructured
data
ᗍ Store and Process massive amount of data easily
ᗍ Cost of system; Process and Manage data economically
ᗍ Speed of processing
13.
Slide 13
What isHadoop?
Apache Hadoop is a framework that allows the distributed processing of large data sets
across clusters of commodity computers using a simple programming mode
It is an Open-source Data Management with scale-out storage and distributed
processing
14.
Slide 14
What isHadoop? (Cont’d)
ᗍ Apache Hadoop is a framework that allows for distributed processing of large data sets stored across
clusters of commodity computers using simple programming model
ᗍ A Free, Java-based programming framework that supports the processing of large data sets in a
distributed
computing environment
ᗍ Based on Google File System (GFS)
ᗍ Runs applications on distributed systems with thousands of nodes
15.
Slide 15
Hadoop KeyFeatures
ᗍ Simple architecture
ᗍ Scalability; Designed for Massive scale
ᗍ Availability; High degree of fault tolerance; Designed to recover from Failures; Robust
ᗍ Low Cost; Low software and hardware costs; Designed to run on commodity servers
ᗍ Speed of Operations; Distributed file system provides fast data transfers among nodes
ᗍ Parallel Programming Model; An easy to use programming paradigm that scales through 1000s of
nodes and petabytes of data
ᗍ Allows data analysis without first be modeled, cleansed and loaded
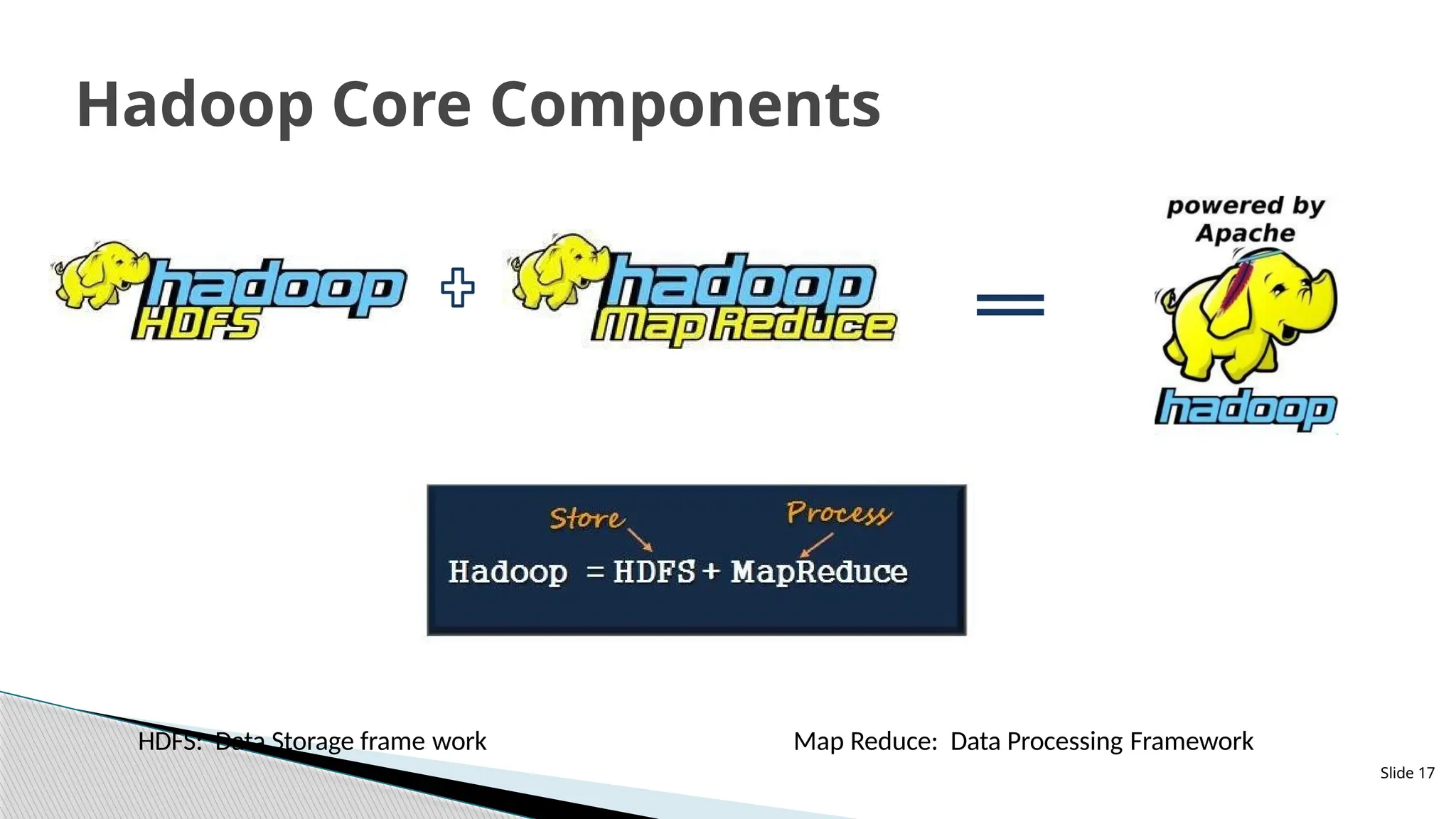
HDFS: Data Storageframe work
Slide 17
Hadoop Core Components
Map Reduce: Data Processing Framework
18.
Slide 18
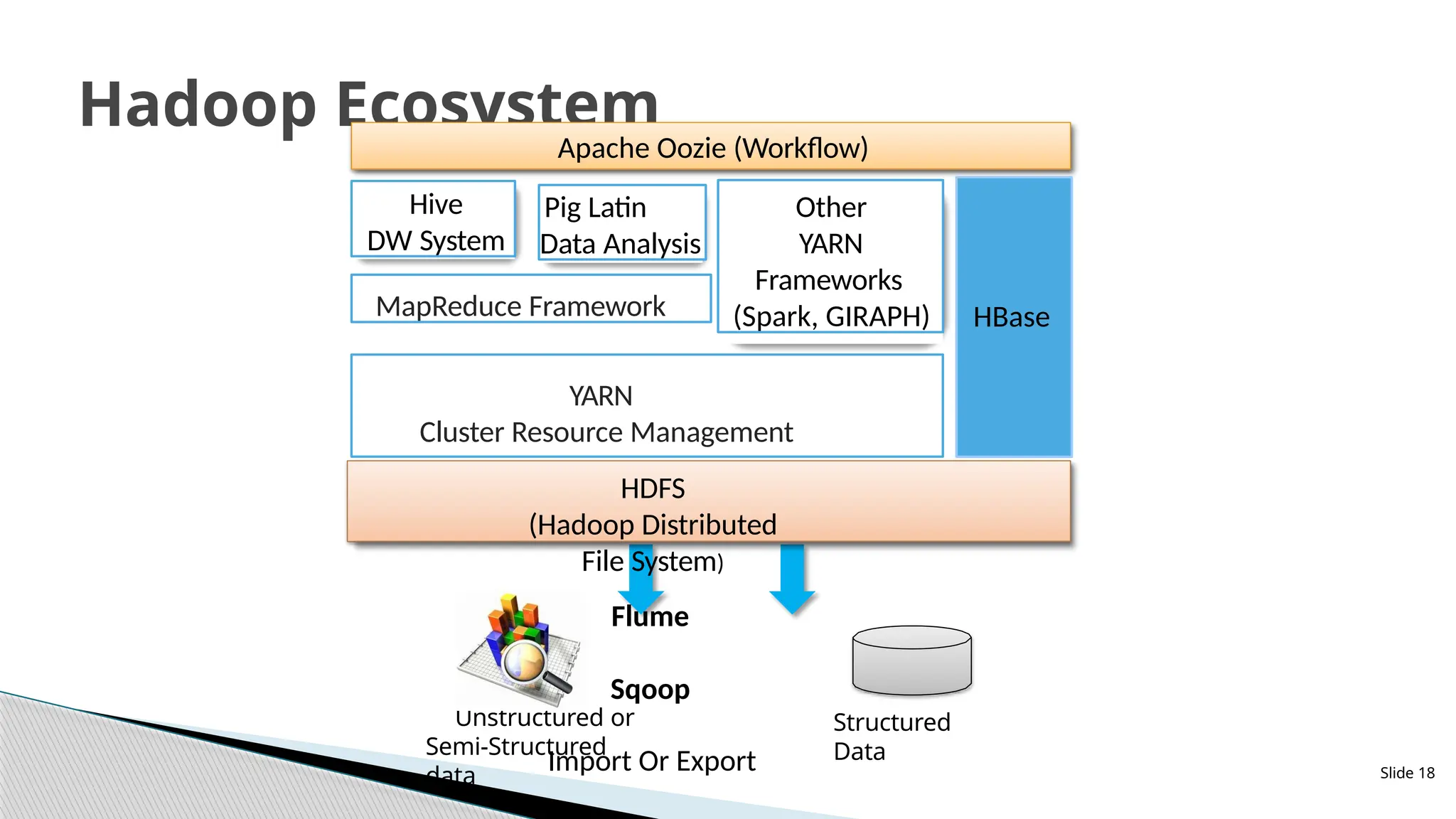
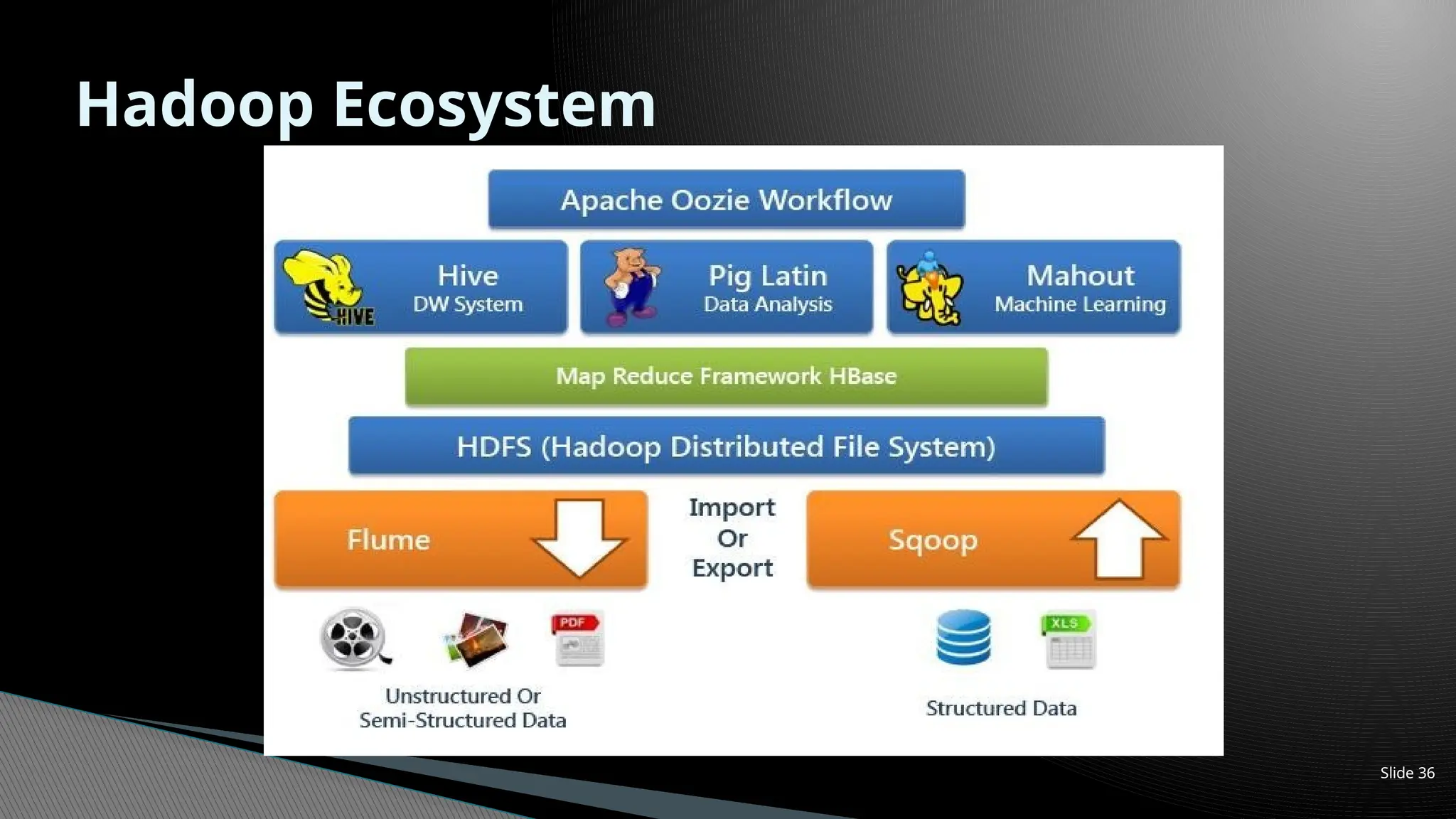
Hadoop Ecosystem
Unstructuredor
Semi-Structured
data
Structured
Data
Apache Oozie (Workflow)
Pig Latin
Data Analysis
Hive
DW System
MapReduce Framework HBase
Other
YARN
Frameworks
(Spark, GIRAPH)
YARN
Cluster Resource Management
HDFS
(Hadoop Distributed
File System)
Flume
Sqoop
Import Or Export
19.
Slide 19
Hadoop Services
Thecore services of Hadoop are:
ᗍ NameNode
ᗍ DataNode
ᗍ Resource Manager [Job Tracker in 1.0]
ᗍ Node Manager [TaskTracker in 1.0]
ᗍ Secondary NameNode
20.
You can useHadoop in following modes:
ᗍ Standalone (or Local) Mode
• No Hadoop daemons, entire process runs in a single JVM
• Suitable for running Hadoop programs during initial installation and Hadoop software
testing
• It doesn’t have any DFS available
ᗍ Pseudo-Distributed Mode
• Hadoop daemons up, but on a single machine
• Best suited for development
ᗍ Fully-Distributed/Clustered/Prod Mode
• Hadoop daemons run on a cluster of machines
• Best suited for production environments
Slide 20
Different Hadoop Modes
21.
Slide 21
Hadoop DeploymentModes
ᗍ Stand Standalone or Local mode
• Everything runs on single JVM
• Good for Development
ᗍ Pseudo-Distributed Mode
• All services running on single machine, a cluster simulation on one
machine
• Good For Test Environment
ᗍ Fully Distributed Mode
• Hadoop Services running on multiple machines on a cluster
• Production Environment
22.
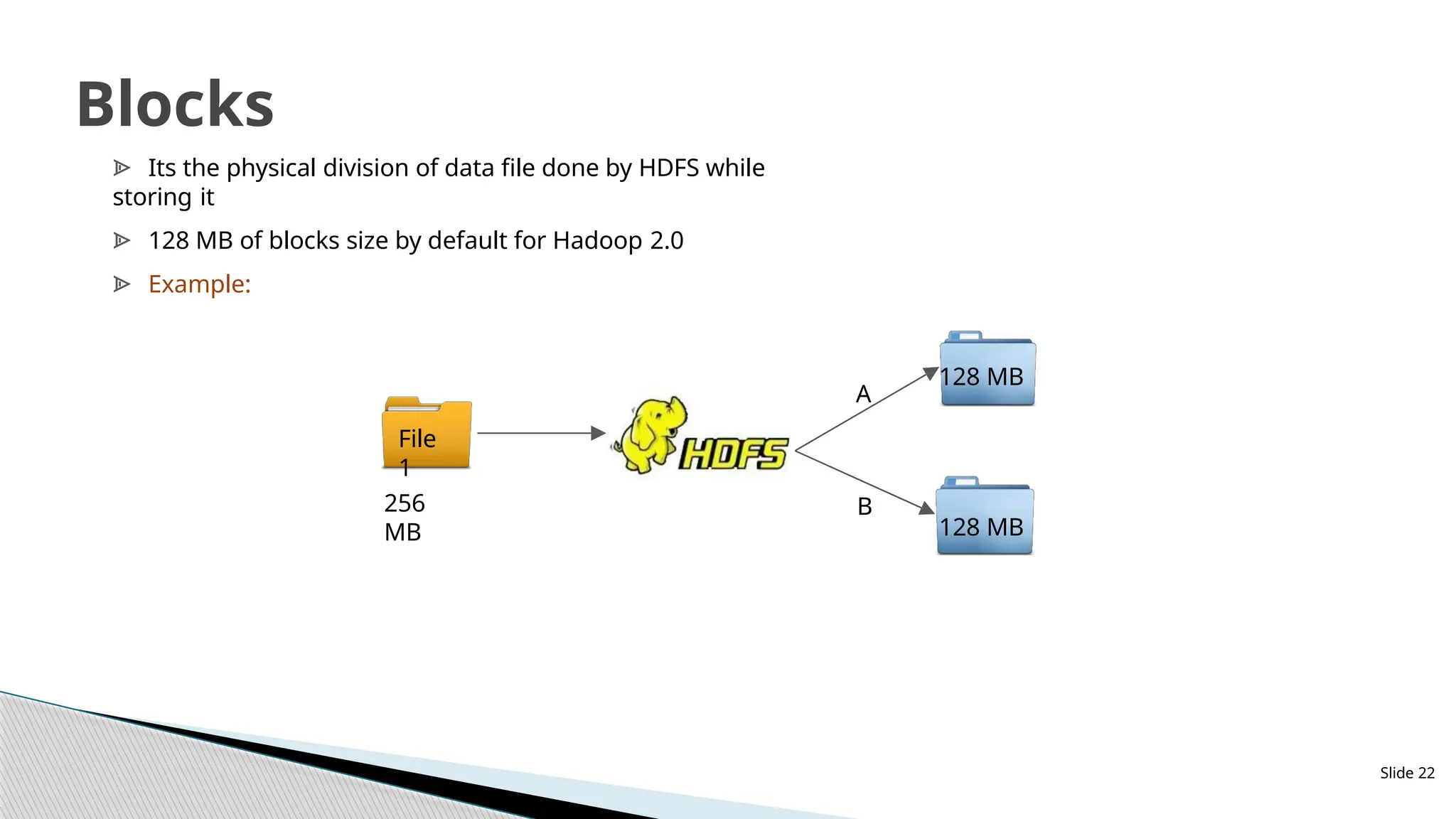
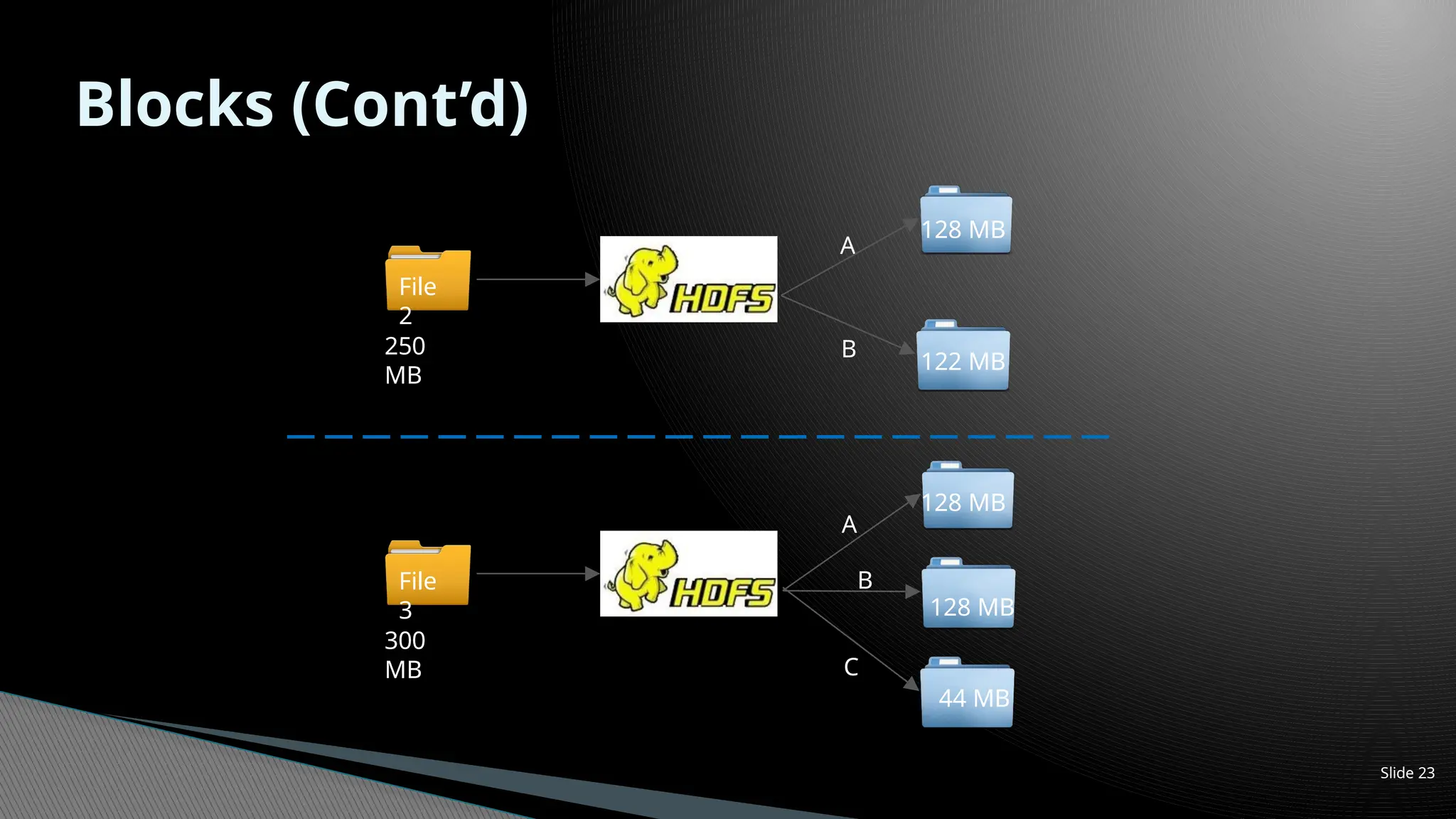
ᗍ Its thephysical division of data file done by HDFS while
storing it
ᗍ 128 MB of blocks size by default for Hadoop 2.0
ᗍ Example:
File
1
A
B
128 MB
256
MB 128 MB
Slide 22
Blocks
ᗍ Computer Racks
•Computer Rack is a physical chassis that can house multiple computers or servers simultaneously.
It is a
mounting rack that has the ability to install more than one computer
ᗍ Block Replication in HDFS
• Provides redundancy and fault tolerance to the data saved
• The default value is 3
Slide 24
Computer Racks & Block Replication
25.
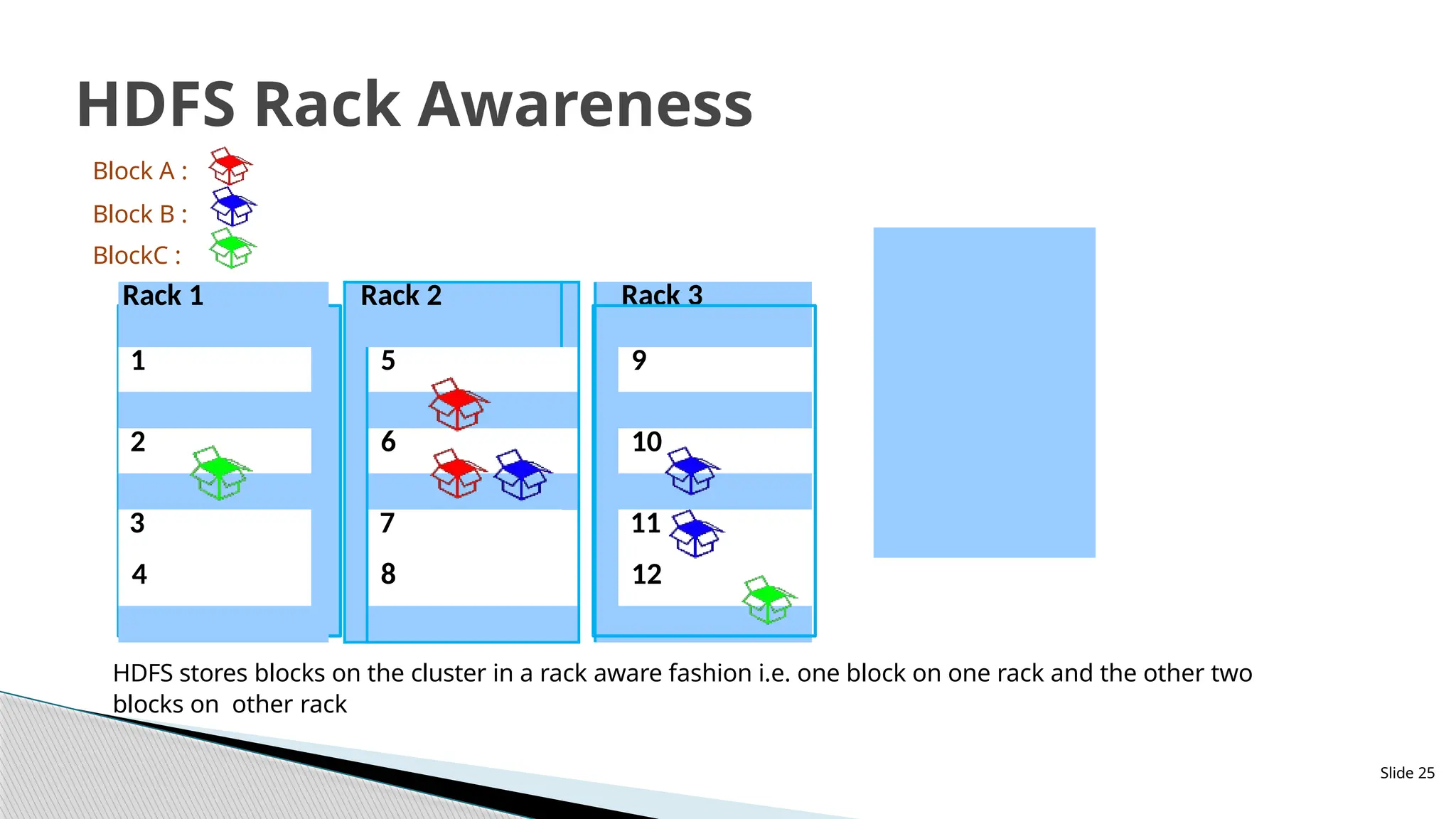
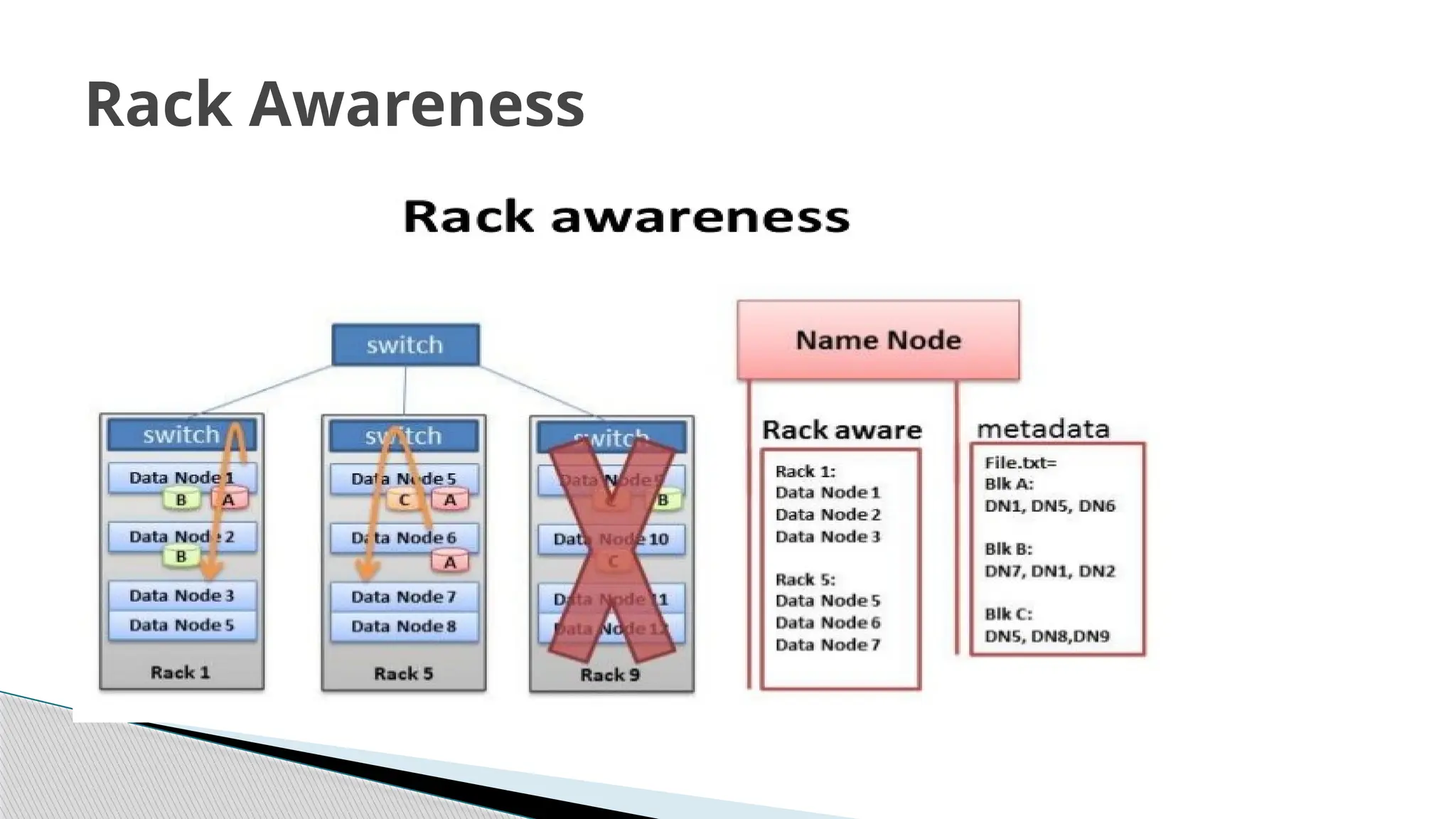
HDFS stores blockson the cluster in a rack aware fashion i.e. one block on one rack and the other two
blocks on other rack
Rack 1 Rack 2 Rack 3
1 5 9
2 6 10
3 7 11
4 8 12
Block A :
Block B :
BlockC :
Slide 25
HDFS Rack Awareness
26.
Slide 26
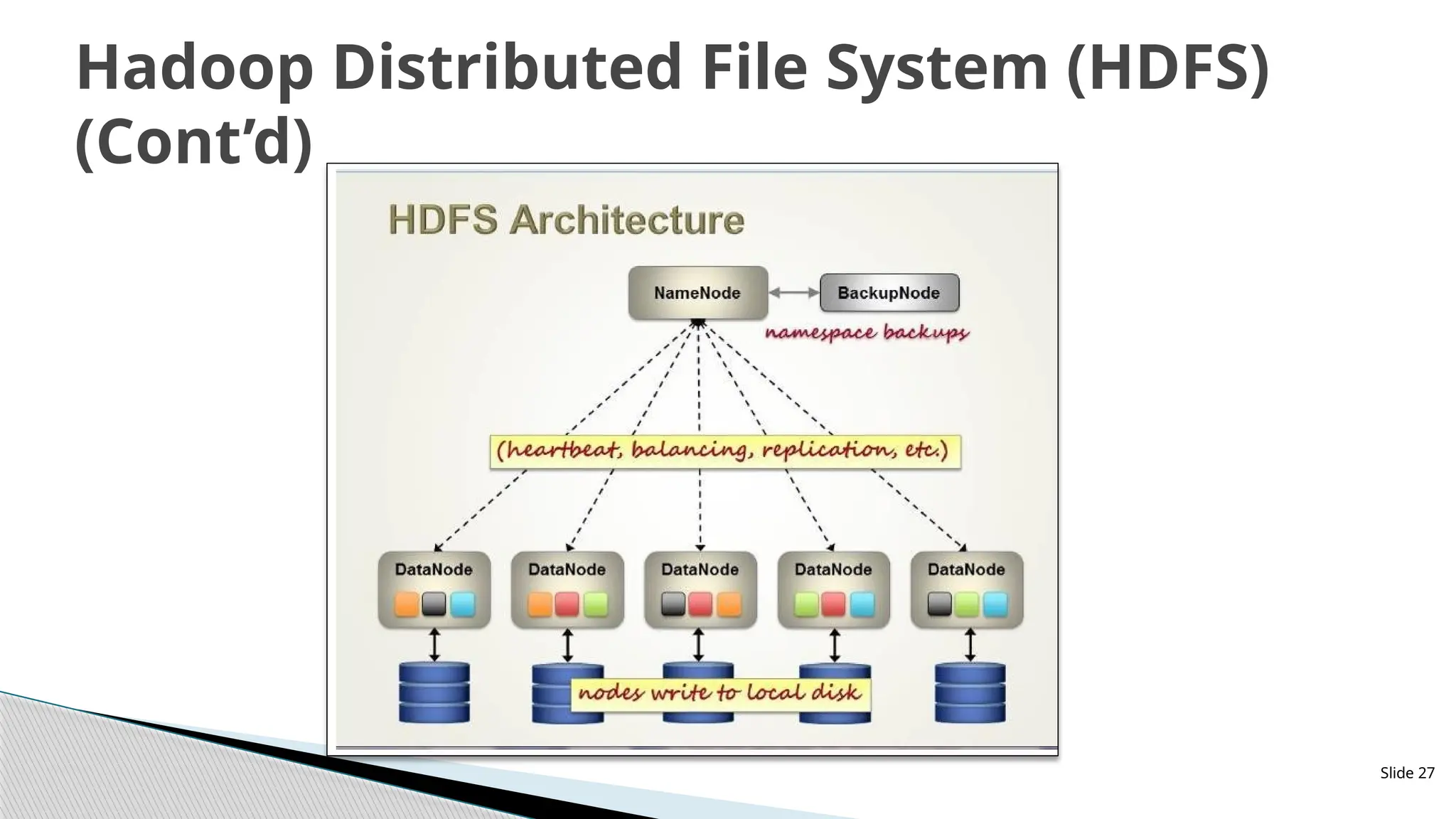
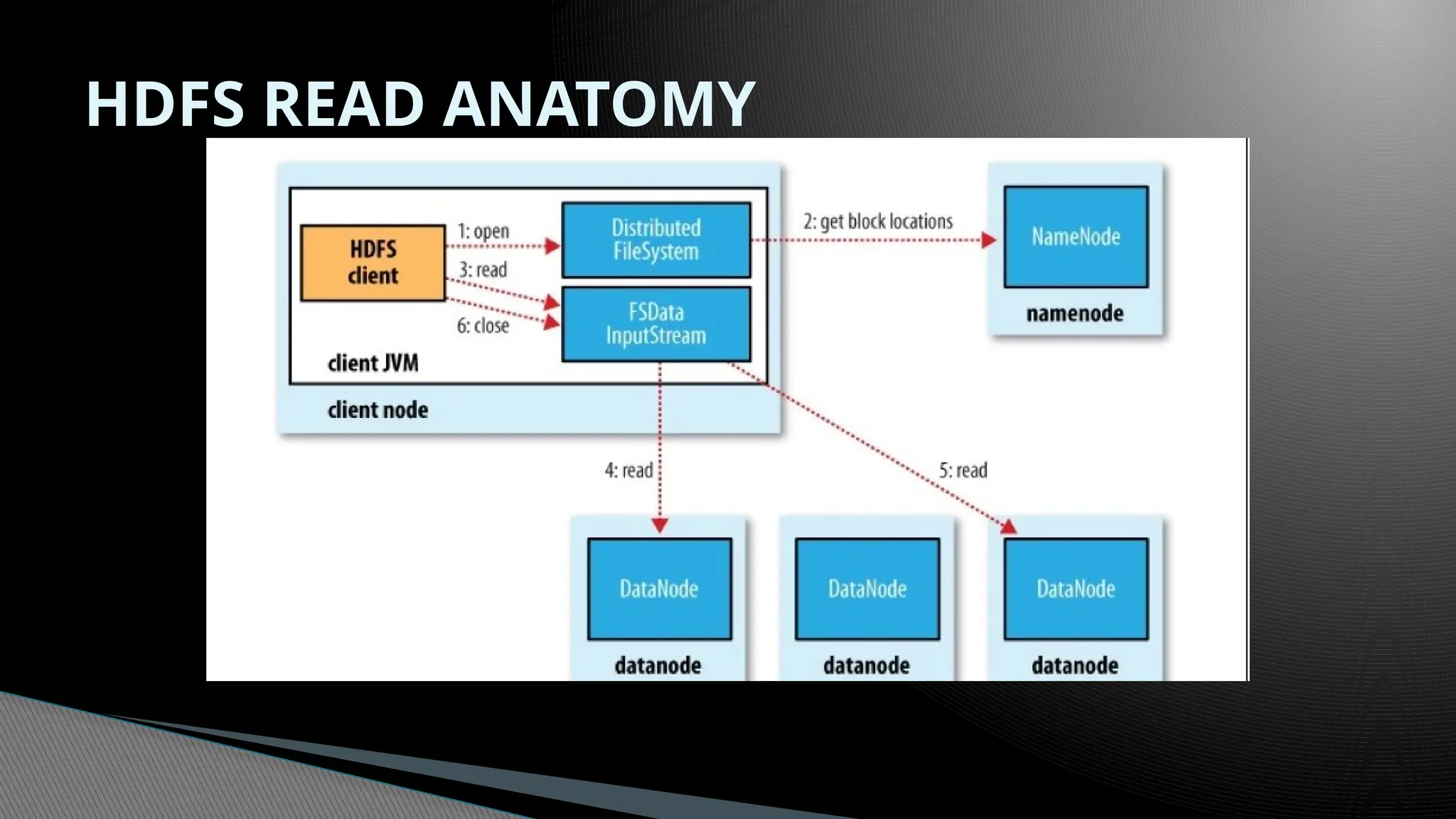
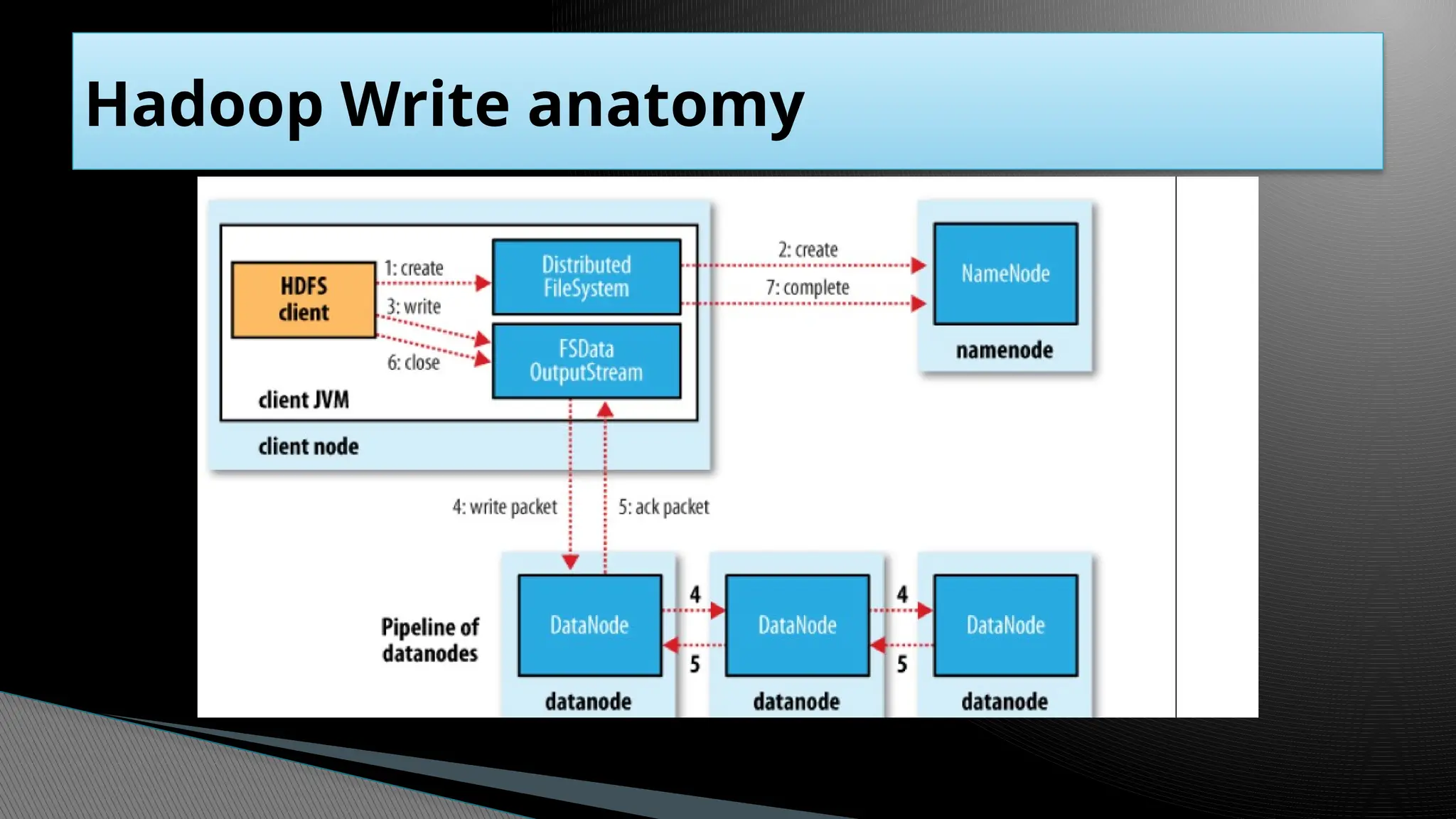
Hadoop DistributedFile System (HDFS)
The key features of Hadoop HDFS are:
ᗍ Storing large sets of data files (in TB/ PB)
ᗍ Distributed across multiple machines
ᗍ Inbuilt Fault tolerance & Reliability; Data replication
Creating multiple replicas of each data block and distributing them on computers throughout the cluster
to enable reliable and rapid data access
ᗍ Providing high-throughput access to data blocks; Low Latency data access
ᗍ Write once read many concept
Master/slave architecture
HDFS cluster consists of a single Namenode, a master server that manages the
file system namespace and regulates access to files by clients.
There are a number of DataNodes usually one per node in a cluster.
The DataNodes manage storage attached to the nodes that they run on.
HDFS exposes a file system namespace and allows user data to be stored in
files.
A file is split into one or more blocks and set of blocks are stored in
DataNodes.
DataNodes: serves read, write requests, performs block creation, deletion, and
replication upon instruction from Namenode
Slide 28
File system Namespace
Job Tracker andTaskTracker
The primary function of the job tracker is resource management
(managing the task trackers), tracking resource availability and task life
cycle management (tracking its progress, fault tolerance etc.)
The task tracker has a simple function of following the orders of the job
tracker and updating the job tracker with its progress status periodically
32.
HDFS is rackaware in the sense that the
namenode and the job tracker obtain a list
of rack ids corresponding to each of the
slave nodes (data nodes) and creates a
mapping between the IP address and the
rack id. HDFS uses this knowledge to
replicate data across different racks so that
data is not lost in the event of a complete
rack power outage or switch failure
ᗍ Mappers:
Mappers arejava programs confirming to Google’s Map Reduce algorithm framework. These programs
run on each of the blocks of big data file saved on the cluster
ᗍ Reducers:
Similar to Mappers, Reducers are also java programs confirming to Google’s Map Reduce algorithm
framework. They are aggregate functions which are supposed to run on the outputs coming out of
mappers
Slide 34
Mapper & Reduce – Basic Concepts
35.
Slide 35
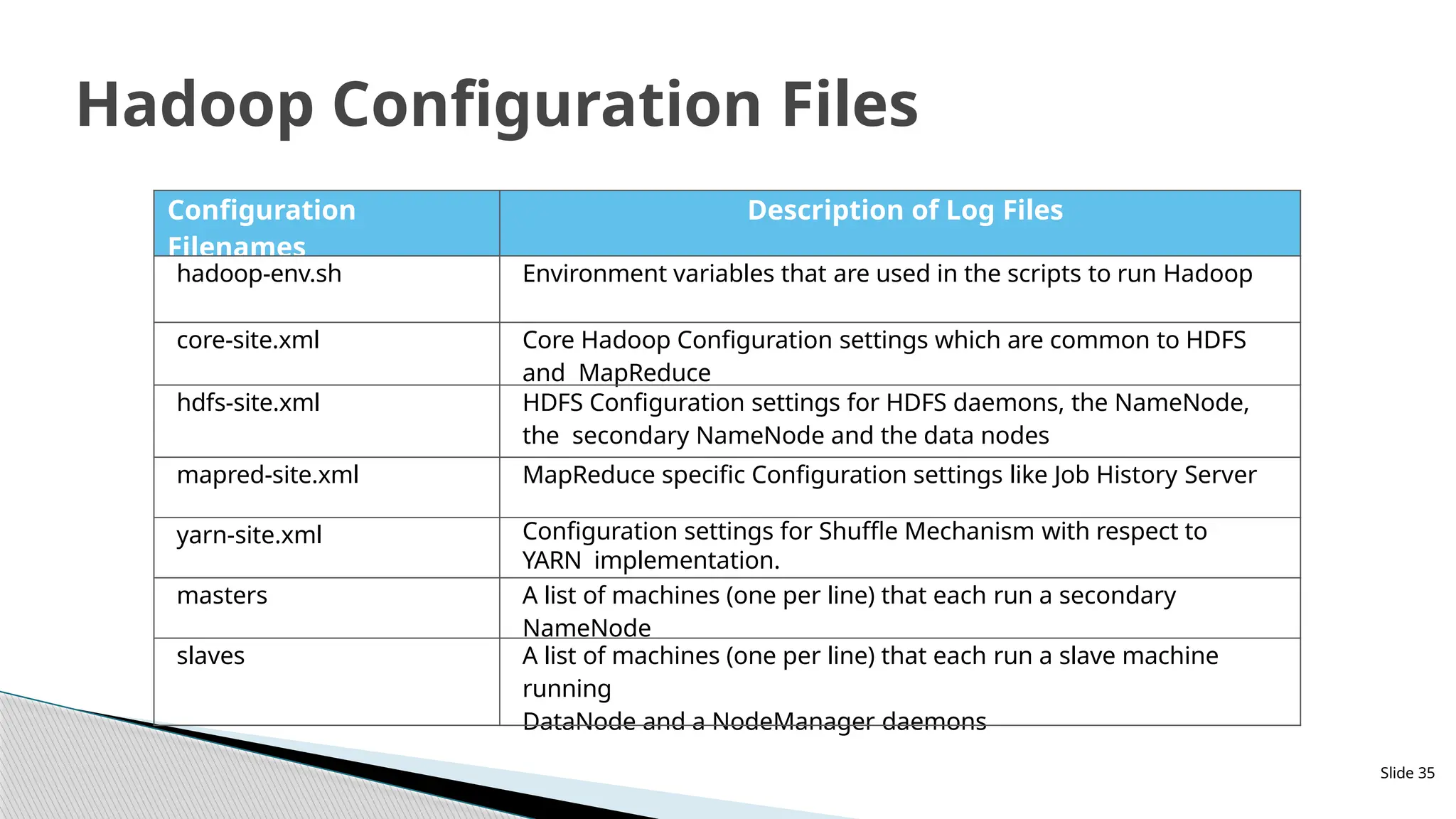
Hadoop ConfigurationFiles
Configuration
Filenames
Description of Log Files
hadoop-env.sh Environment variables that are used in the scripts to run Hadoop
core-site.xml Core Hadoop Configuration settings which are common to HDFS
and MapReduce
hdfs-site.xml HDFS Configuration settings for HDFS daemons, the NameNode,
the secondary NameNode and the data nodes
mapred-site.xml MapReduce specific Configuration settings like Job History Server
yarn-site.xml Configuration settings for Shuffle Mechanism with respect to
YARN implementation.
masters A list of machines (one per line) that each run a secondary
NameNode
slaves A list of machines (one per line) that each run a slave machine
running
DataNode and a NodeManager daemons
Copies singlesrc file from local file system to the Hadoop
Distributed File System.
hadoop fs -put <local-src> ... <HDFS_dest_path>
hadoop fs –put /home/cloudera/Desktop/Employee.csv /root/training
PUT Command
39.
Lists thecontents of a directory
# Usage: # hadoop fs -ls <args>
# Example: hadoop fs -ls /root/
Try Yourself: hadoop fs -lsr /root/
This –lsr is called recursive search
Ls command
40.
Copies/Downloads filesfrom HDFS to the local file system
hadoop fs -get <hdfs_src> <localdst>
Example: hadoop fs -get /user/root/employee.csv /home/cloudera/desktop/emloyee.csv
To Avoid this error give new name for file or diffrenet local path.
hadoop fs -get /user/root/employee.csv /home/cloudera/desktop/emloyee123.csv
Get Command
41.
To copyfile from one hdfs location to other.
Usage: hadoop fs -cp <source> <dest>
Example:
hadoop fs -cp /root/Employee.csv /root/training/Employee.csv
Please again try hadoop fs –lsr /root/
Cp command
42.
Same purposeas of put command
Usage:
hadoop fs -copyFromLocal <localsrc> URI
Example:
hadoop fs –put /home/cloudera/Desktop/Student.csv
/root/training
copyFromLocal
43.
Same purposeas that of get command
hadoop fs –copyToLocal <hdfs_src> <localdst>
Example: hadoop fs - copyToLocal /user/root/employee.csv
/home/cloudera/desktop/emloyee321.csv
copyToLocal
hadoop fsrm:
Removes the specified list of files and empty directories. An
example is shown below:
hadoop fs –rm /root/employee.csv
Try –rm –r option also and see differnce for /root/
Rm Command














![Slide 19
Hadoop Services
The core services of Hadoop are:
ᗍ NameNode
ᗍ DataNode
ᗍ Resource Manager [Job Tracker in 1.0]
ᗍ Node Manager [TaskTracker in 1.0]
ᗍ Secondary NameNode](https://image.slidesharecdn.com/module1-introductiontobigdataandhadoopv1-250429035233-45118b2e/75/Module-1-Introduction-to-Big-Data-and-Hadoop-19-2048.jpg)















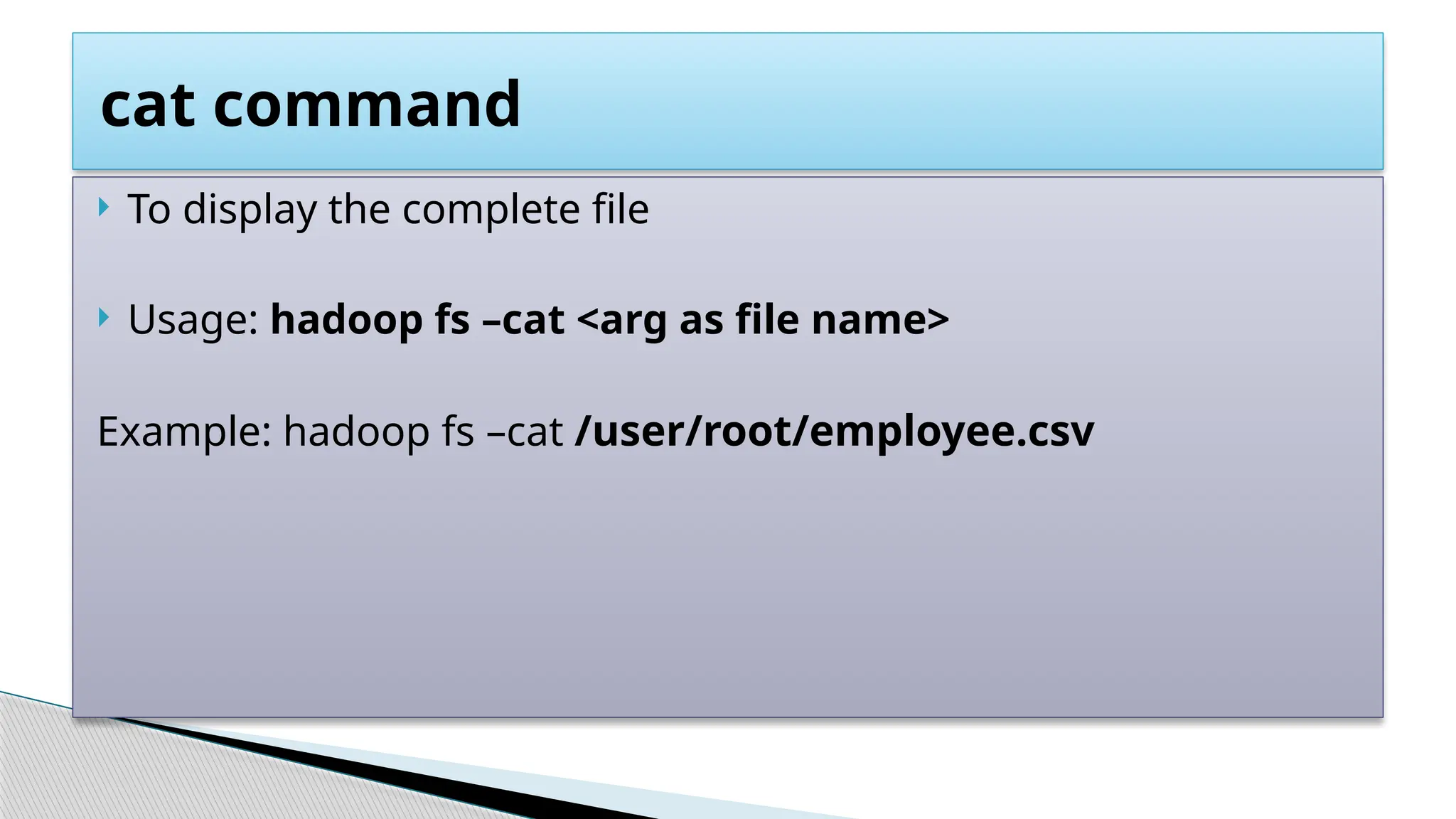
![ Display last few lines of a file.
Usage :
hadoop fs -tail <path[filename]>
Example:
hadoop fs -tail /user/root/employee.csv
Tail Command](https://image.slidesharecdn.com/module1-introductiontobigdataandhadoopv1-250429035233-45118b2e/75/Module-1-Introduction-to-Big-Data-and-Hadoop-44-2048.jpg)




















![Slide 19
Hadoop Services
The core services of Hadoop are:
ᗍ NameNode
ᗍ DataNode
ᗍ Resource Manager [Job Tracker in 1.0]
ᗍ Node Manager [TaskTracker in 1.0]
ᗍ Secondary NameNode](https://crownmelresort.com/image.slidesharecdn.com/module1-introductiontobigdataandhadoopv1-250429035233-45118b2e/75/Module-1-Introduction-to-Big-Data-and-Hadoop-19-2048.jpg)
























![ Display last few lines of a file.
Usage :
hadoop fs -tail <path[filename]>
Example:
hadoop fs -tail /user/root/employee.csv
Tail Command](https://crownmelresort.com/image.slidesharecdn.com/module1-introductiontobigdataandhadoopv1-250429035233-45118b2e/75/Module-1-Introduction-to-Big-Data-and-Hadoop-44-2048.jpg)





































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)











