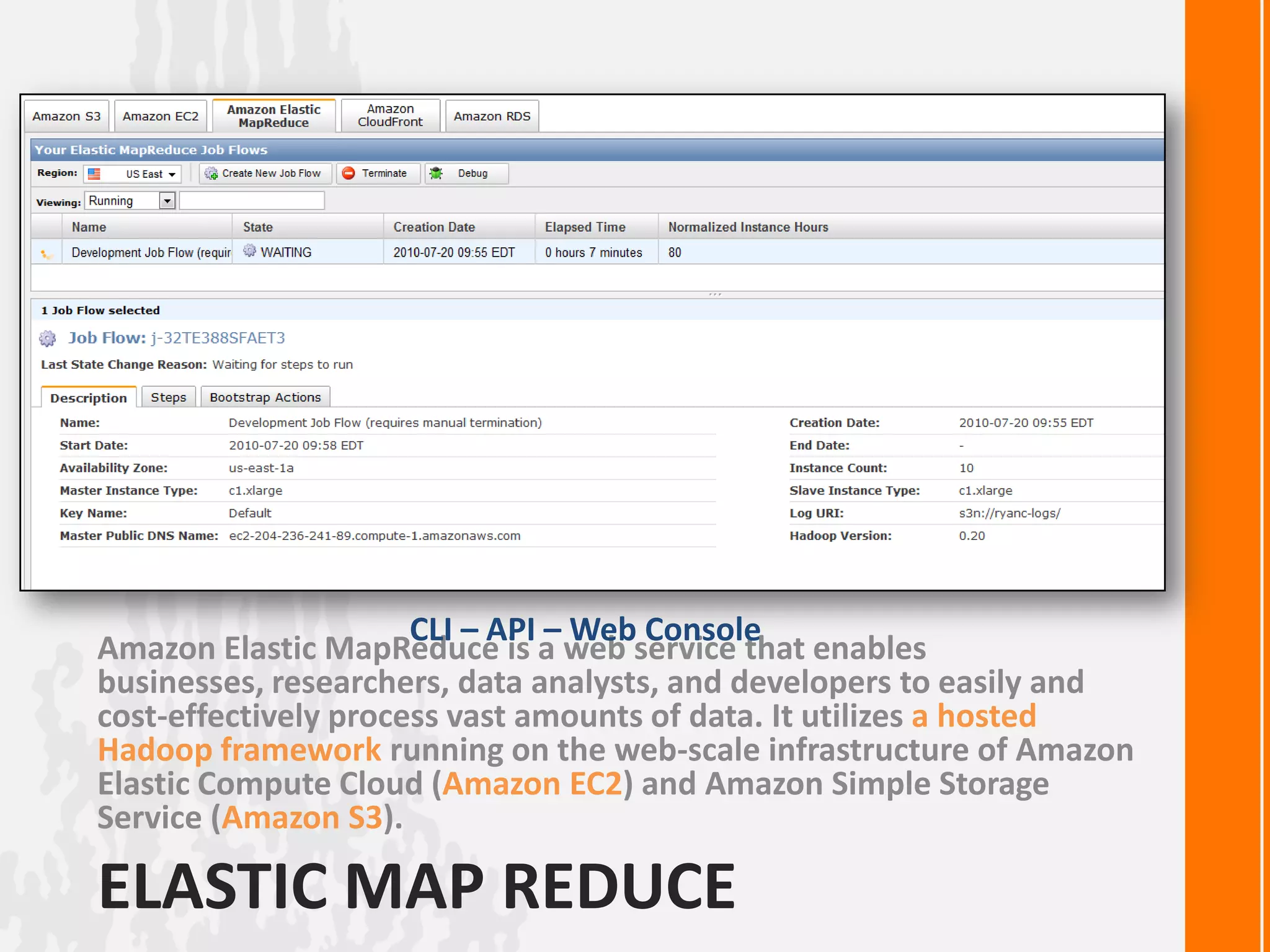
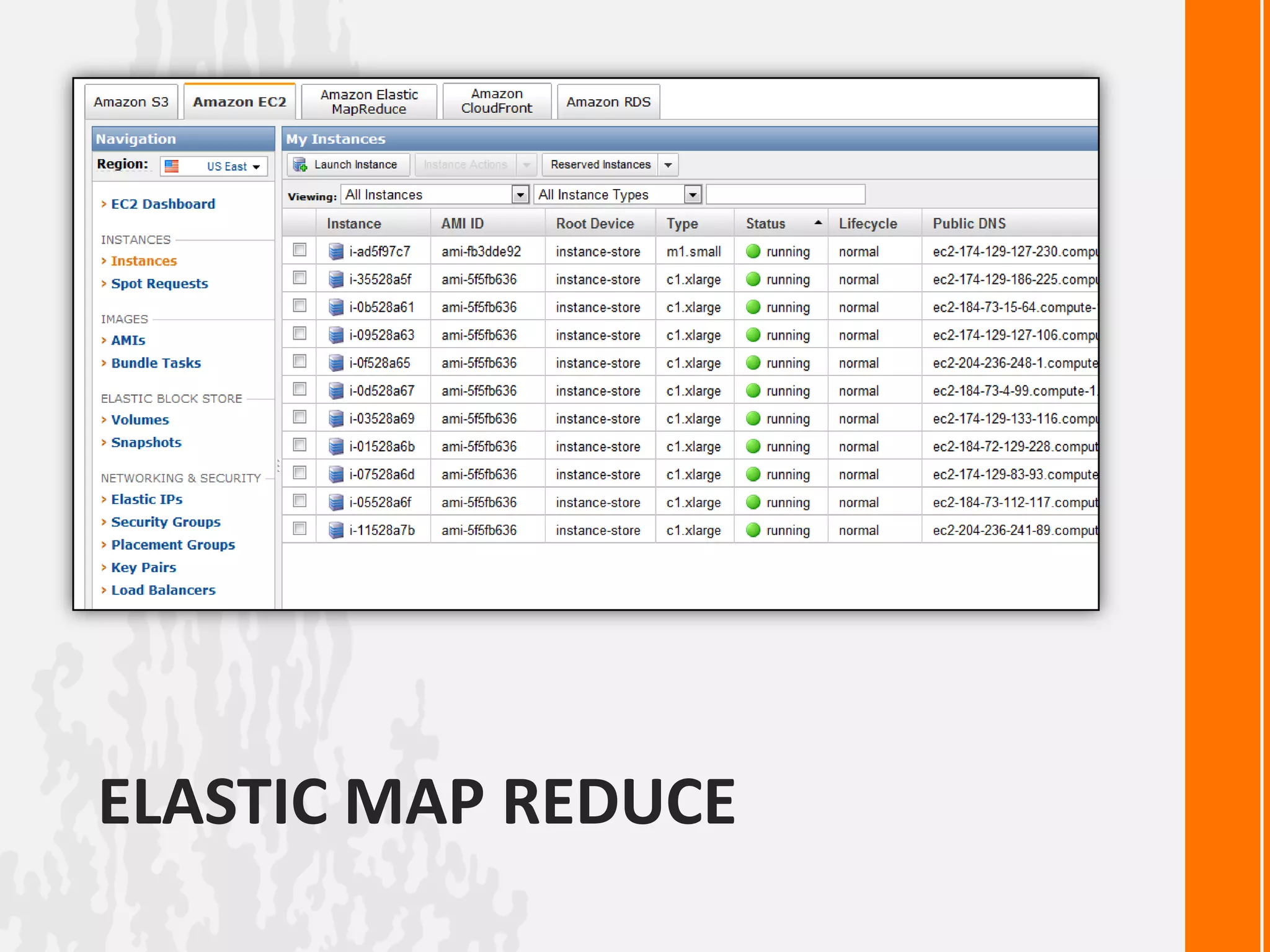
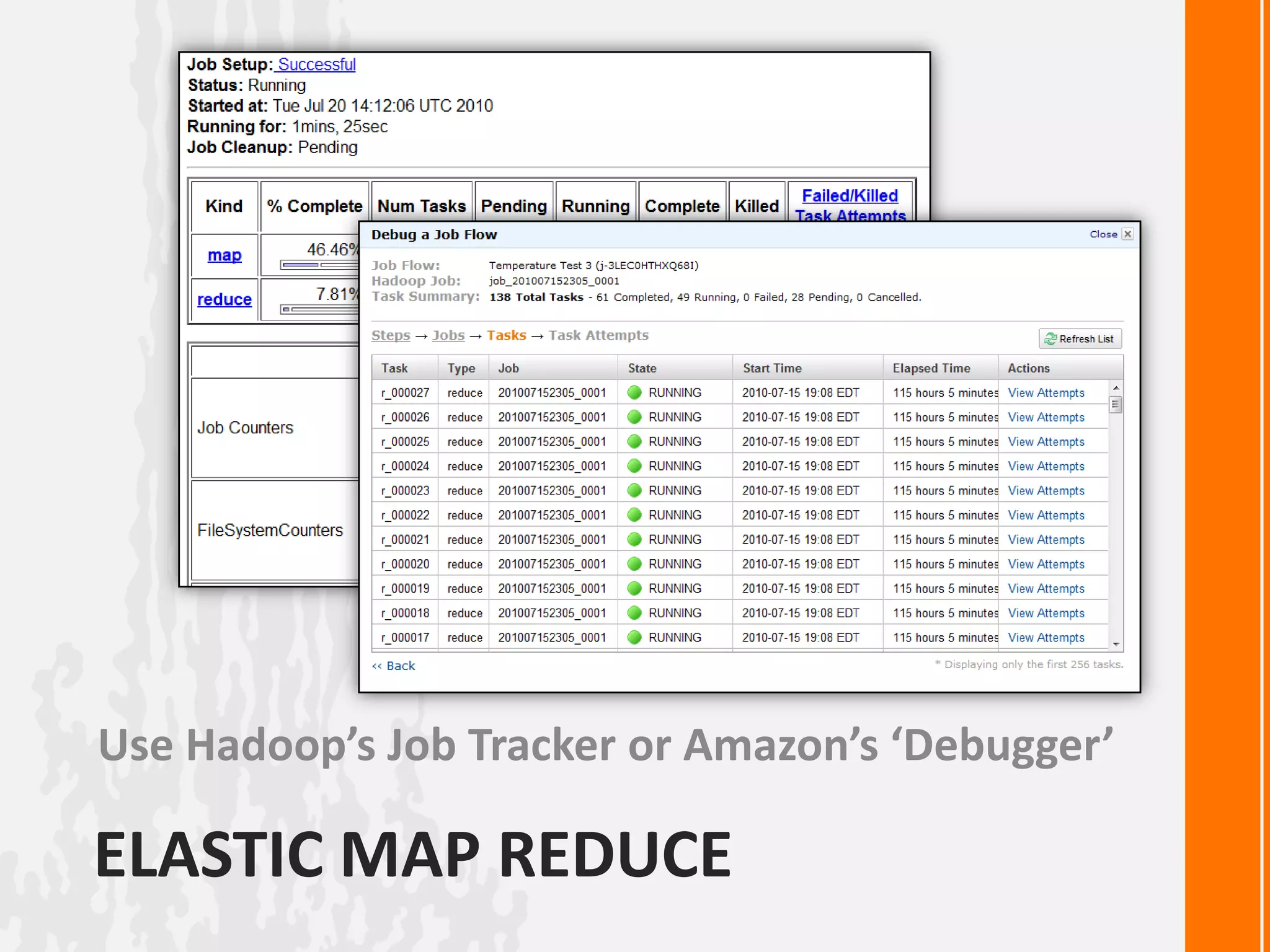
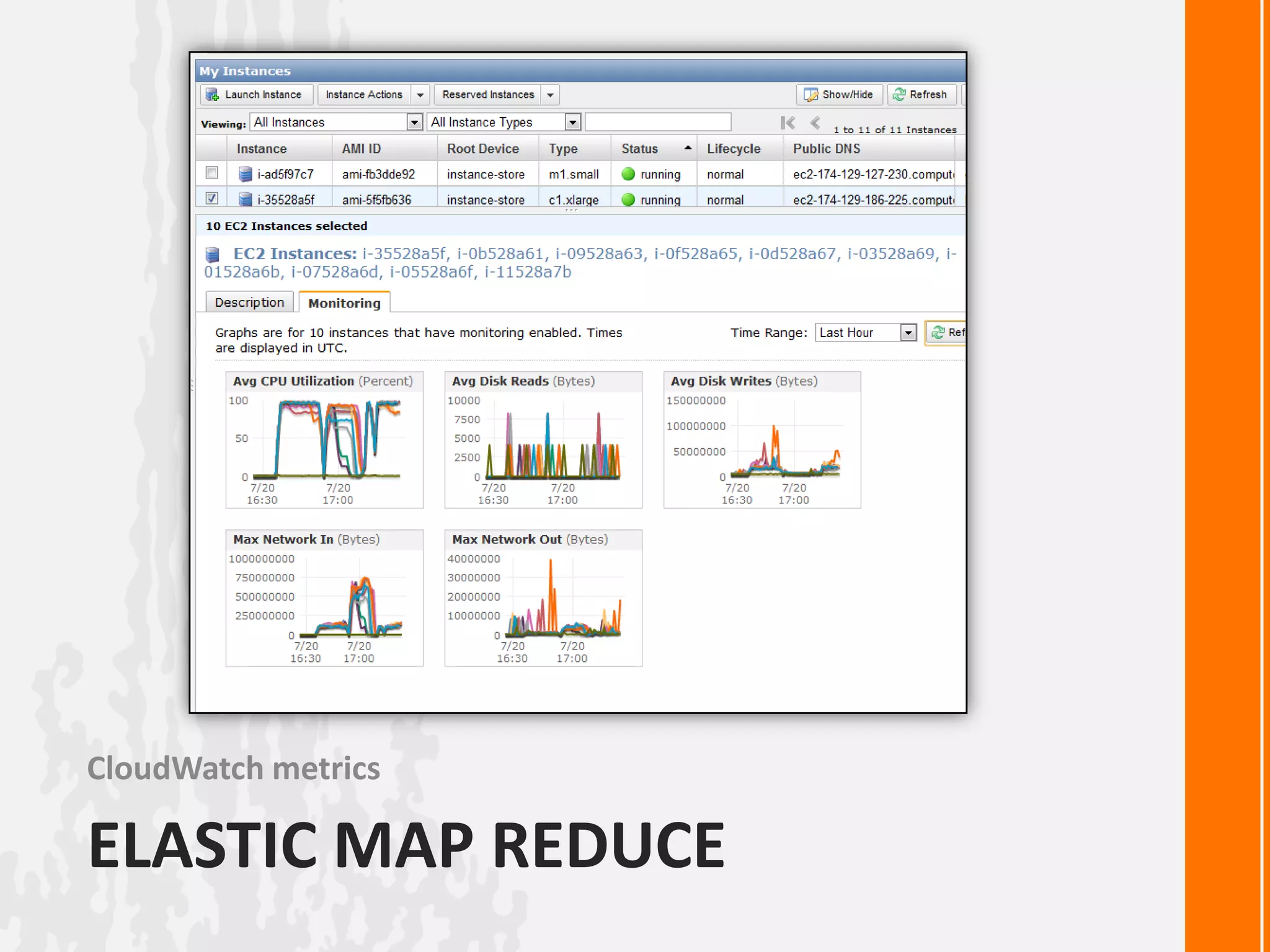
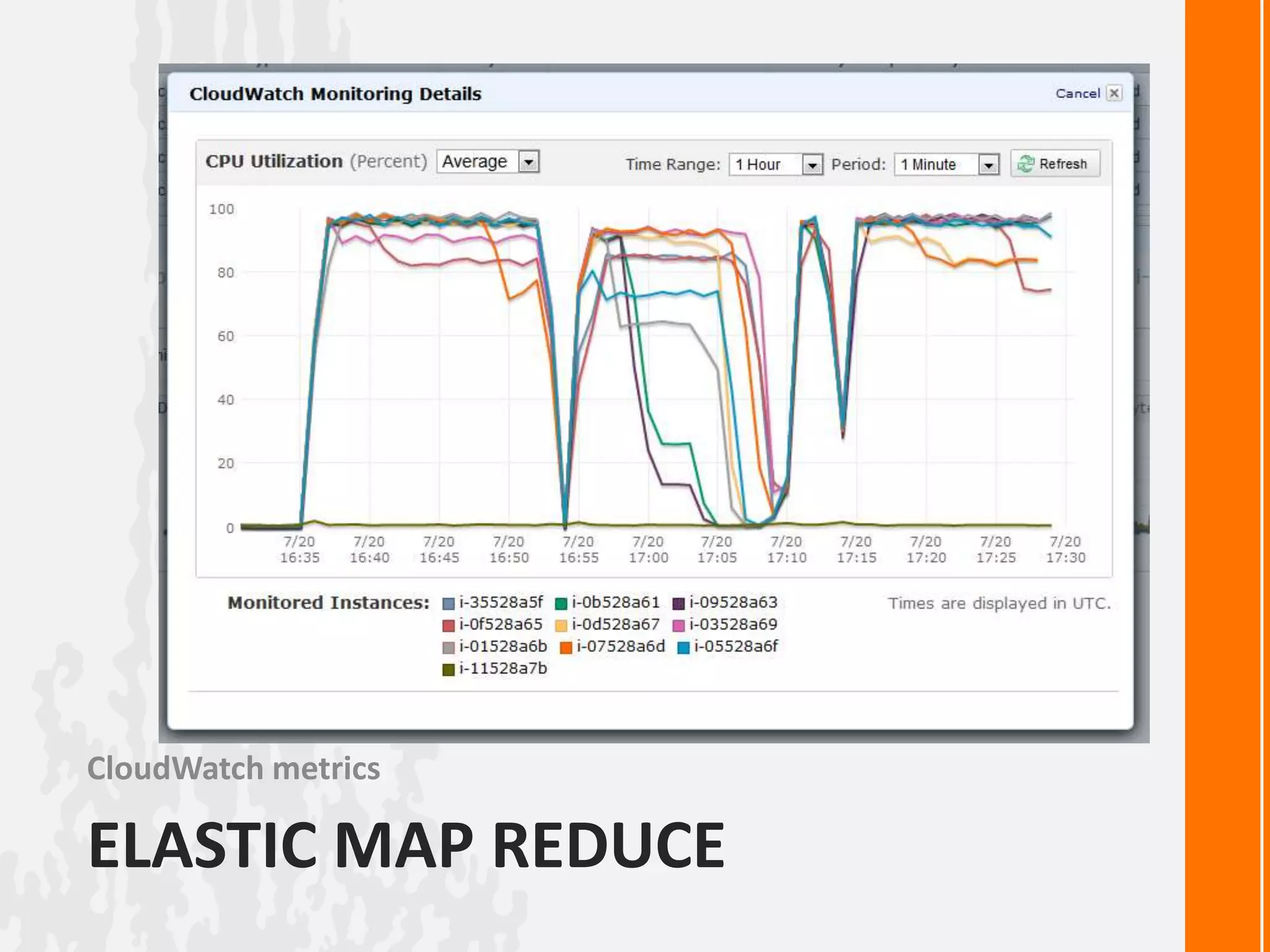
This document discusses processing large datasets with Python and Hadoop. It begins with an example of finding the highest temperature from a climate dataset using a map-reduce approach. Next, it provides code examples for implementing map-reduce in pure Python, with Hadoop Streaming, and with the Dumbo library. The document then discusses using Amazon Elastic MapReduce for running Hadoop jobs on AWS. It poses a question about how to implement breadth-first search as a map-reduce algorithm and ends with an example of using MongoDB's map-reduce functionality.

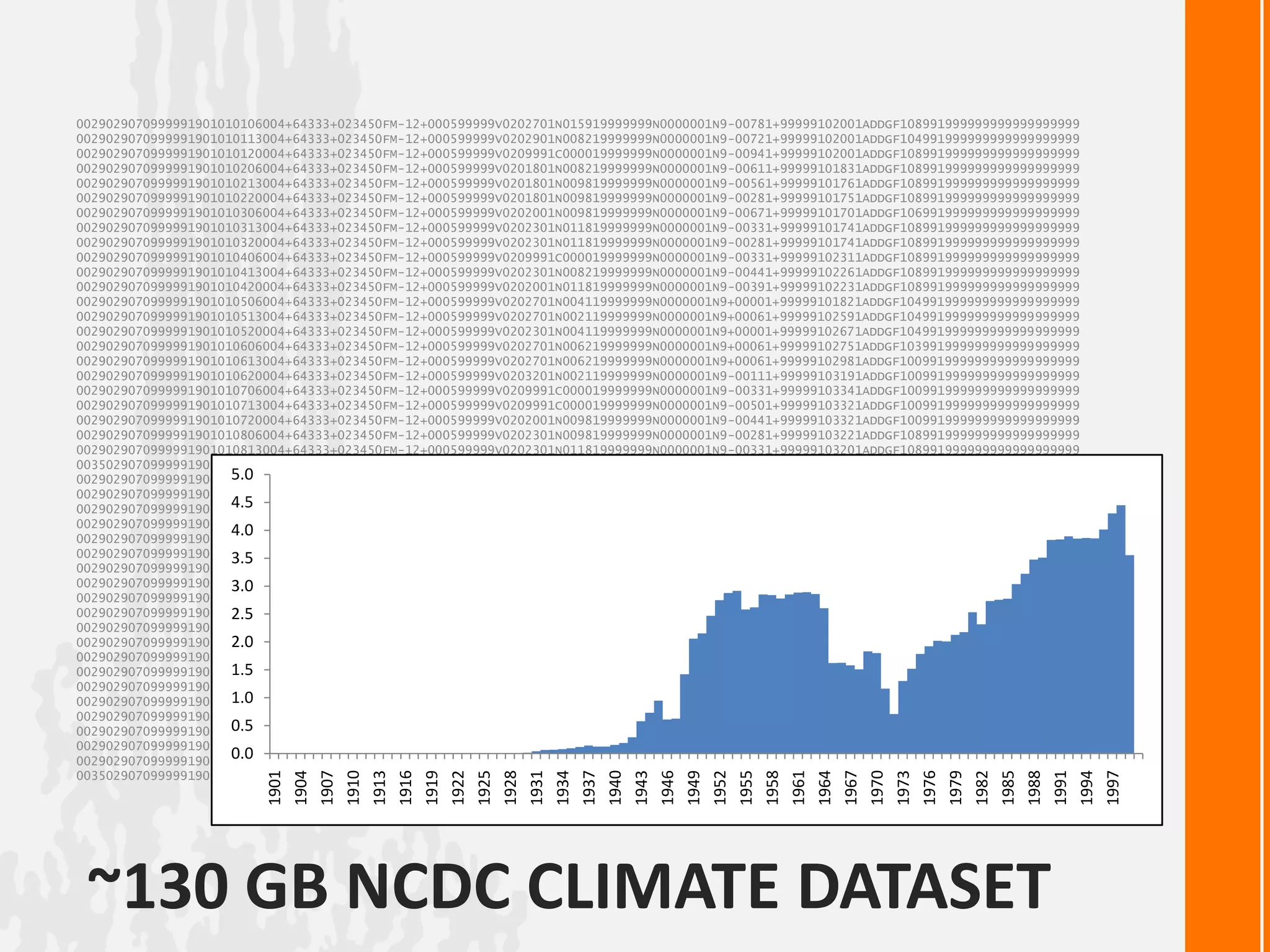
![high_temp=0forline inopen('1901'): line =line.strip() (year, temp, quality) = (line[15:19], line[87:92], line[92:93]) if(temp !="+9999"and quality in"01459"): high_temp=max(high_temp,float(temp)) printhigh_tempHow can we make this scale?( and do more interesting things )](https://image.slidesharecdn.com/pythonhadoopytrihug72010-100722182858-phpapp01/75/Megadata-With-Python-and-Hadoop-3-2048.jpg)



![defmapper(line): line =line.strip() (year, temp, quality) = (line[15:19], line[87:92], line[92:93]) if(temp !="+9999"and quality in"01459"): returnfloat(temp) returnNoneoutput =map(mapper,open('1901')) printreduce(max,output)Mapreduce in pure python](https://image.slidesharecdn.com/pythonhadoopytrihug72010-100722182858-phpapp01/75/Megadata-With-Python-and-Hadoop-7-2048.jpg)
![for line in sys.stdin:val = line.strip() (year, temp, q) = (val[15:19], val[87:92], val[92:93]) if (temp != "+9999" and re.match("[01459]", q)): print "%s\t%s" % (year, temp)mapper.py(last_key, max_val) = (None, 0)for line in sys.stdin: (key, val) = line.strip().split("\t") if last_key and last_key != key: print "%s\t%s" % (last_key, max_val) (last_key, max_val) = (key, int(val)) else: (last_key, max_val) = (key, max(max_val, int(val)))if last_key: print "%s\t%s" % (last_key, max_val)reduer.pycat dataFile | mapper.py | sort | reducer.pyHadoop Streaming](https://image.slidesharecdn.com/pythonhadoopytrihug72010-100722182858-phpapp01/75/Megadata-With-Python-and-Hadoop-8-2048.jpg)
![def mapper(key,value): line = value.strip() (year, temp, quality) = (line[15:19], line[87:92], line[92:93]) if (temp != "+9999" and quality in "01459"): yield year, int(temp)def reducer(key,values): yield key,max(values)if __name__ == "__main__": import dumbodumbo.run(mapper,reducer,reducer)Dumbo](https://image.slidesharecdn.com/pythonhadoopytrihug72010-100722182858-phpapp01/75/Megadata-With-Python-and-Hadoop-10-2048.jpg)







![high_temp=0forline inopen('1901'): line =line.strip() (year, temp, quality) = (line[15:19], line[87:92], line[92:93]) if(temp !="+9999"and quality in"01459"): high_temp=max(high_temp,float(temp)) printhigh_tempHow can we make this scale?( and do more interesting things )](https://crownmelresort.com/image.slidesharecdn.com/pythonhadoopytrihug72010-100722182858-phpapp01/75/Megadata-With-Python-and-Hadoop-3-2048.jpg)



![defmapper(line): line =line.strip() (year, temp, quality) = (line[15:19], line[87:92], line[92:93]) if(temp !="+9999"and quality in"01459"): returnfloat(temp) returnNoneoutput =map(mapper,open('1901')) printreduce(max,output)Mapreduce in pure python](https://crownmelresort.com/image.slidesharecdn.com/pythonhadoopytrihug72010-100722182858-phpapp01/75/Megadata-With-Python-and-Hadoop-7-2048.jpg)
![for line in sys.stdin:val = line.strip() (year, temp, q) = (val[15:19], val[87:92], val[92:93]) if (temp != "+9999" and re.match("[01459]", q)): print "%s\t%s" % (year, temp)mapper.py(last_key, max_val) = (None, 0)for line in sys.stdin: (key, val) = line.strip().split("\t") if last_key and last_key != key: print "%s\t%s" % (last_key, max_val) (last_key, max_val) = (key, int(val)) else: (last_key, max_val) = (key, max(max_val, int(val)))if last_key: print "%s\t%s" % (last_key, max_val)reduer.pycat dataFile | mapper.py | sort | reducer.pyHadoop Streaming](https://crownmelresort.com/image.slidesharecdn.com/pythonhadoopytrihug72010-100722182858-phpapp01/75/Megadata-With-Python-and-Hadoop-8-2048.jpg)

![def mapper(key,value): line = value.strip() (year, temp, quality) = (line[15:19], line[87:92], line[92:93]) if (temp != "+9999" and quality in "01459"): yield year, int(temp)def reducer(key,values): yield key,max(values)if __name__ == "__main__": import dumbodumbo.run(mapper,reducer,reducer)Dumbo](https://crownmelresort.com/image.slidesharecdn.com/pythonhadoopytrihug72010-100722182858-phpapp01/75/Megadata-With-Python-and-Hadoop-10-2048.jpg)