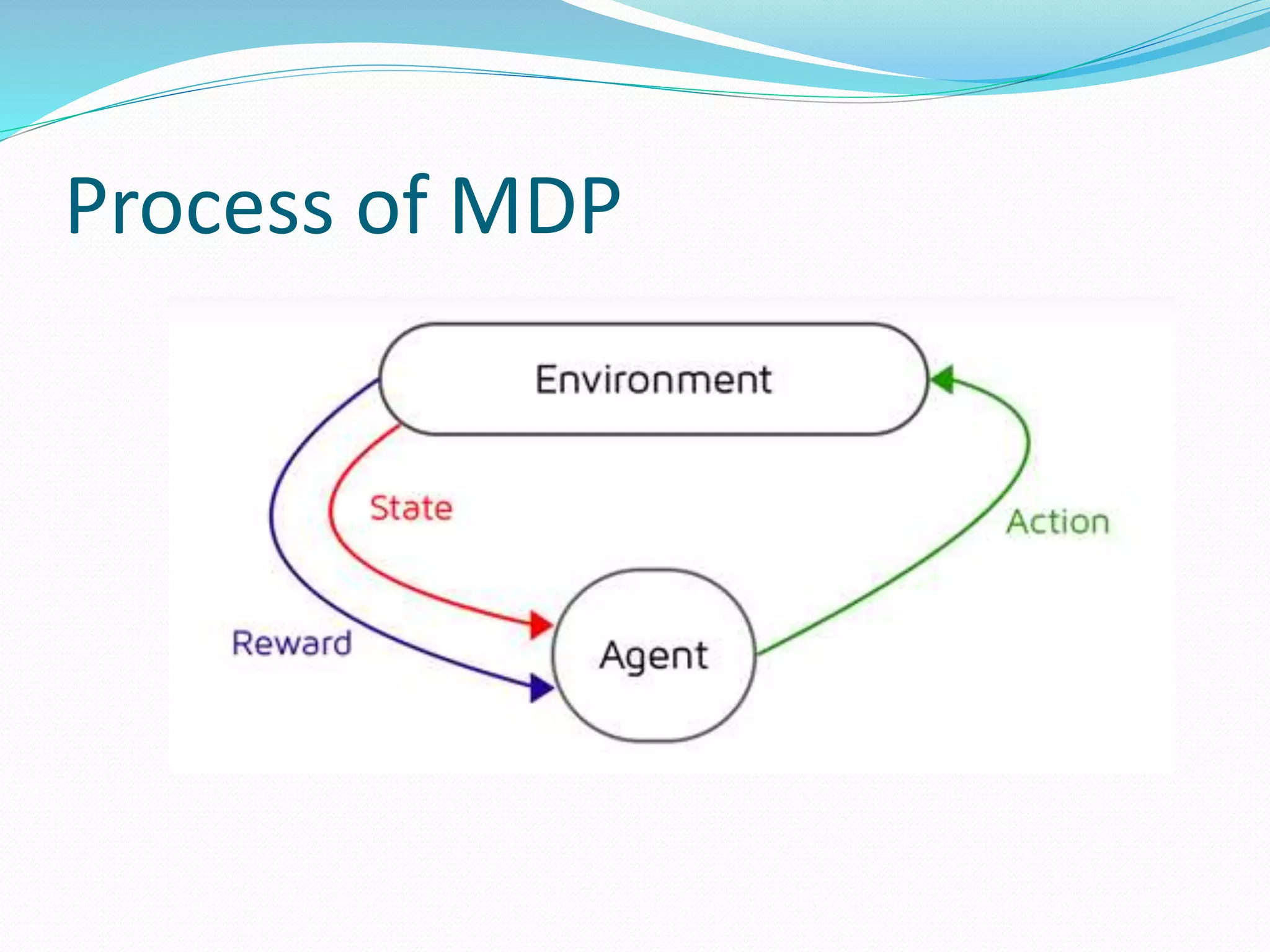
Markov Decision Process (MDP) is a reinforcement learning model that consists of: (1) states, (2) actions, (3) transition models, and (4) rewards. The goal is to find the optimal policy, which maps states to the best actions, in order to maximize long-term rewards. In an MDP, an agent takes an action in a state, then transitions to a new state based on the transition model, and receives an immediate reward.