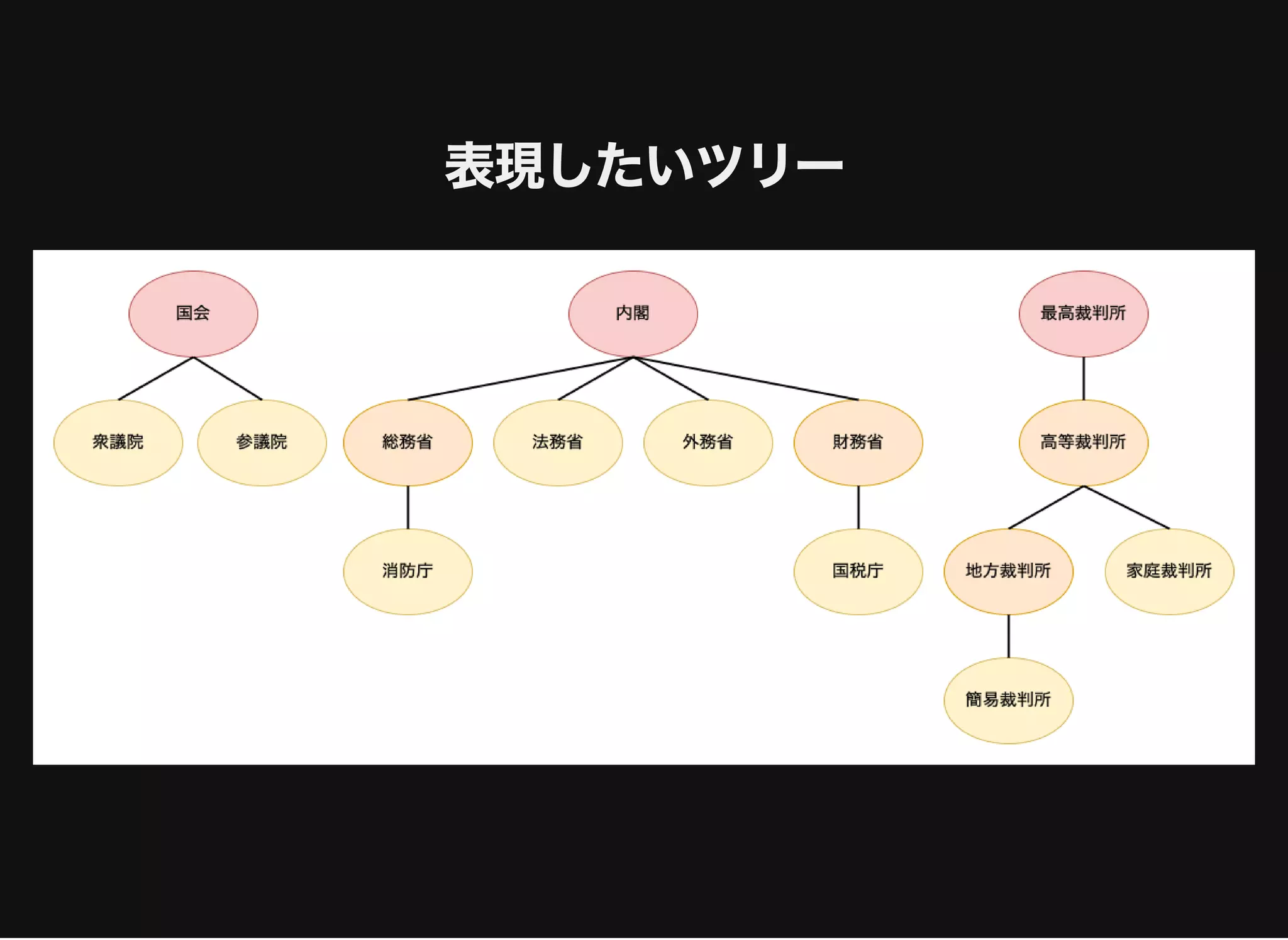
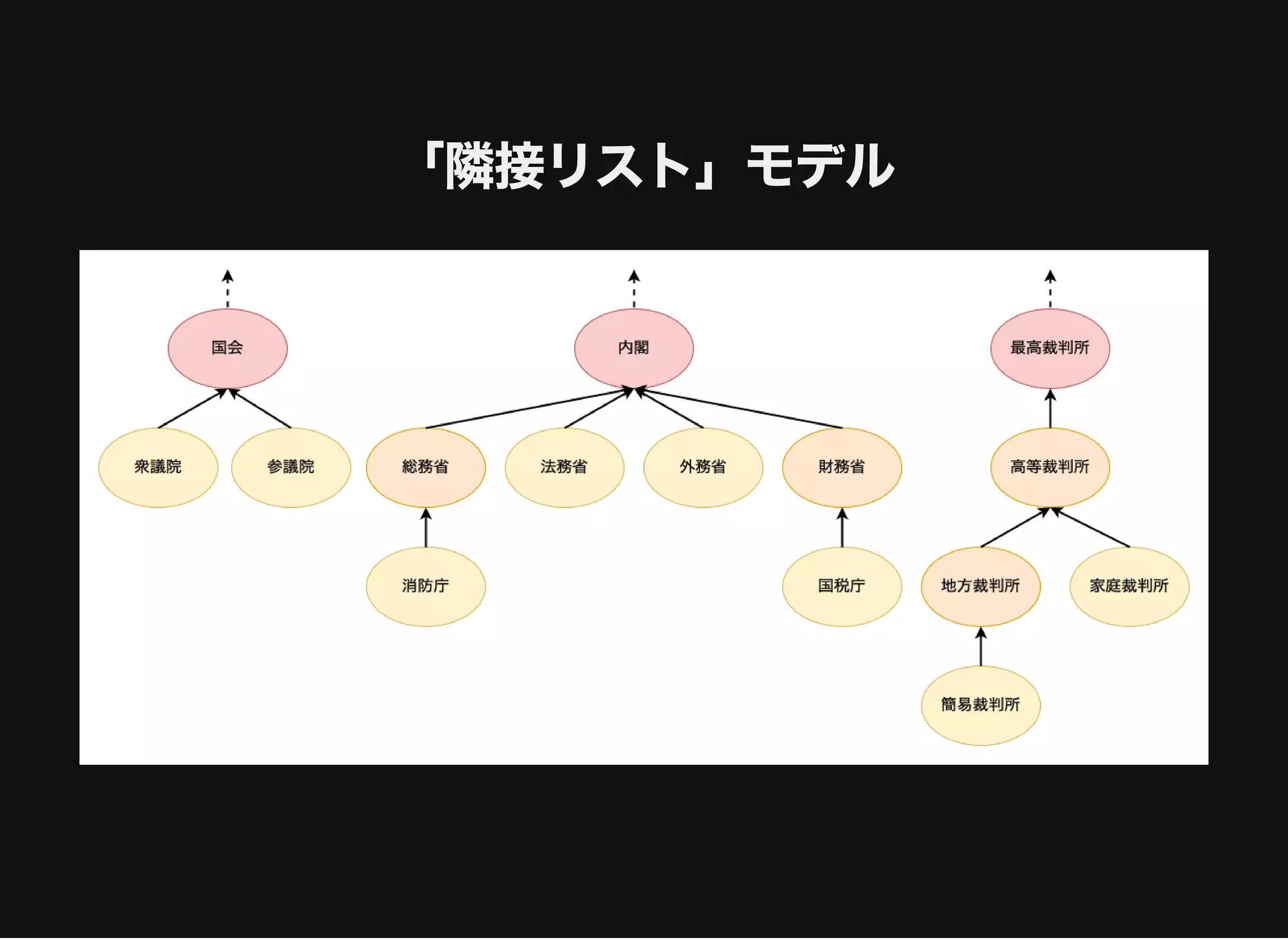
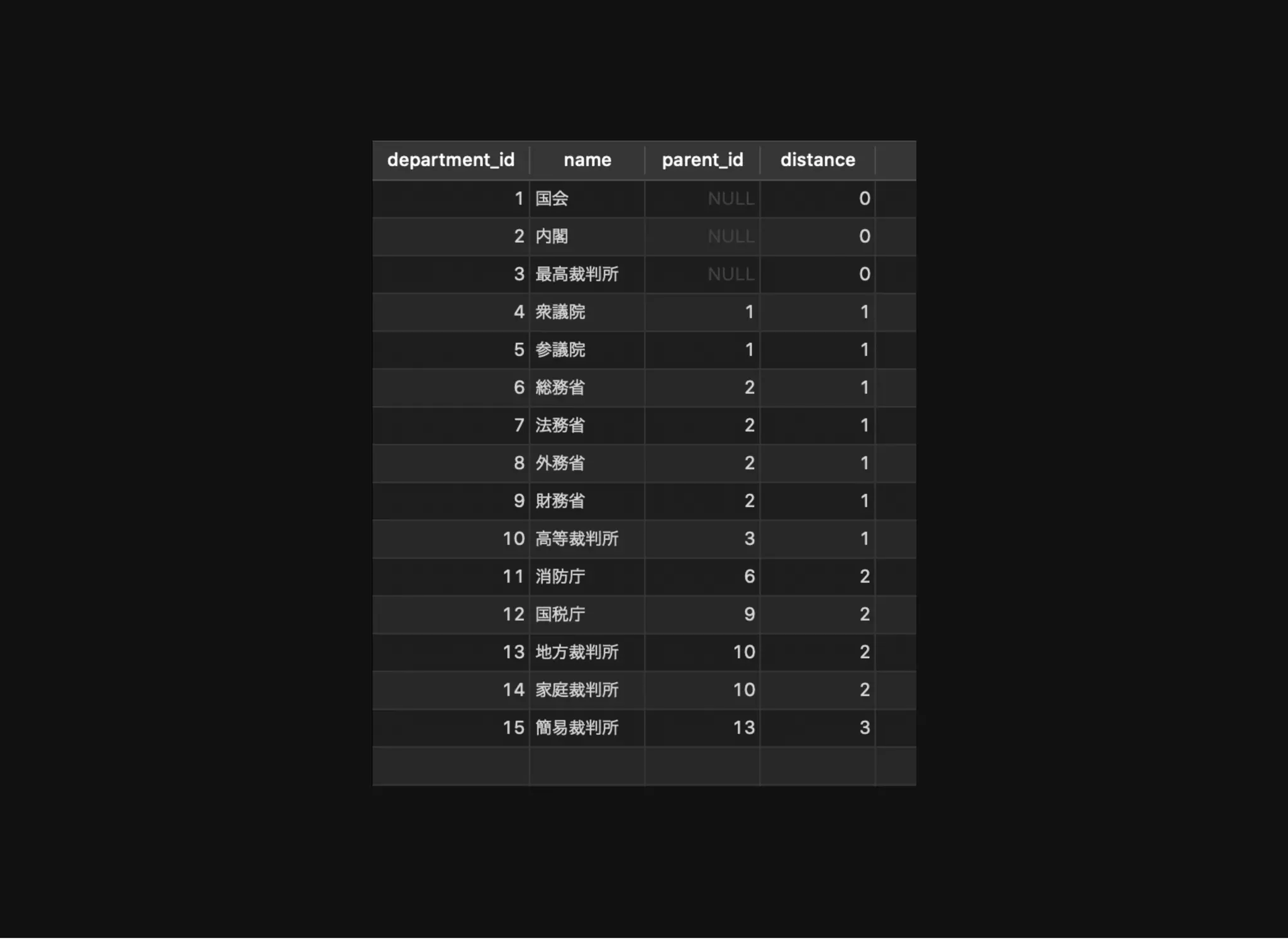
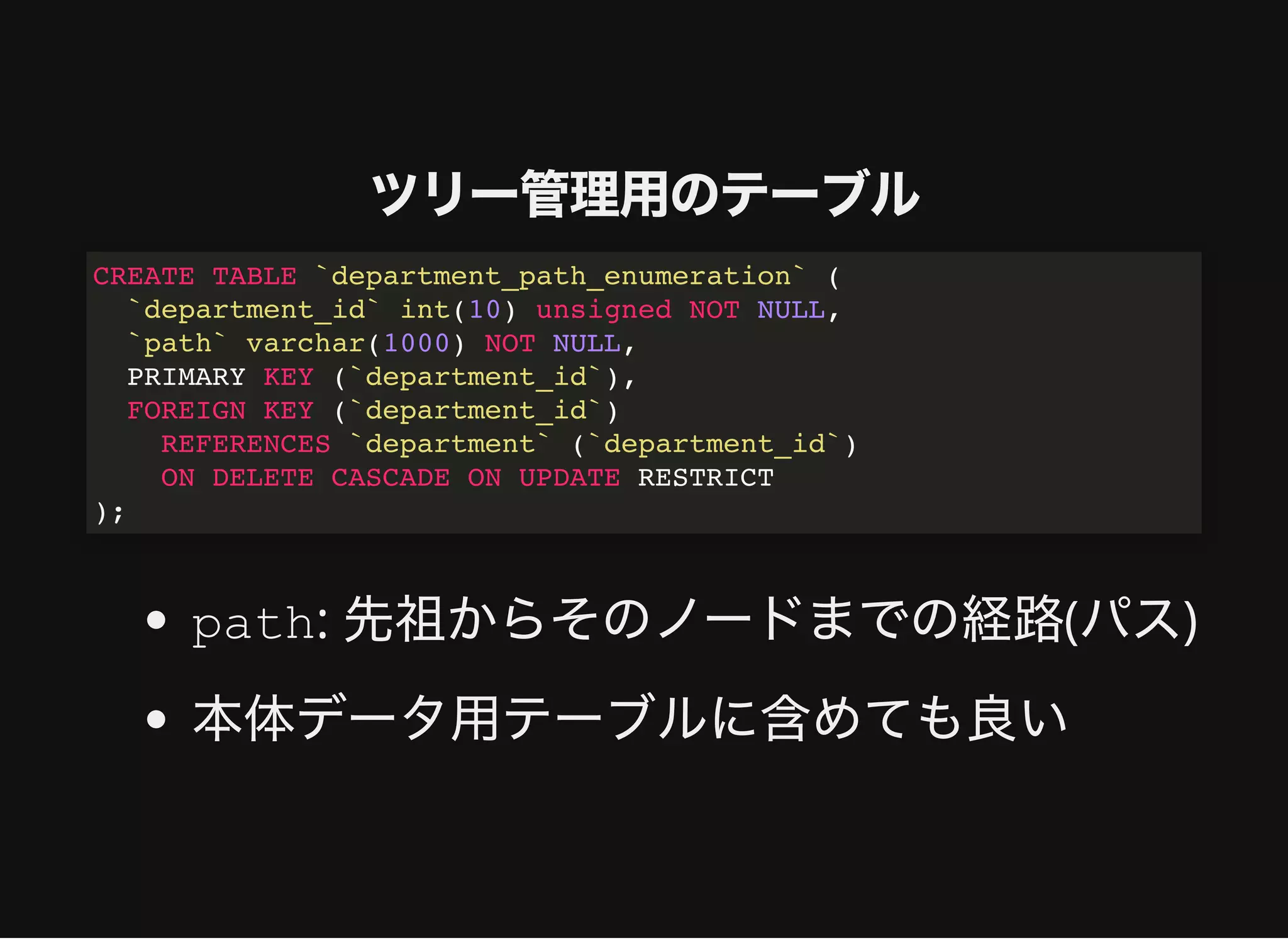
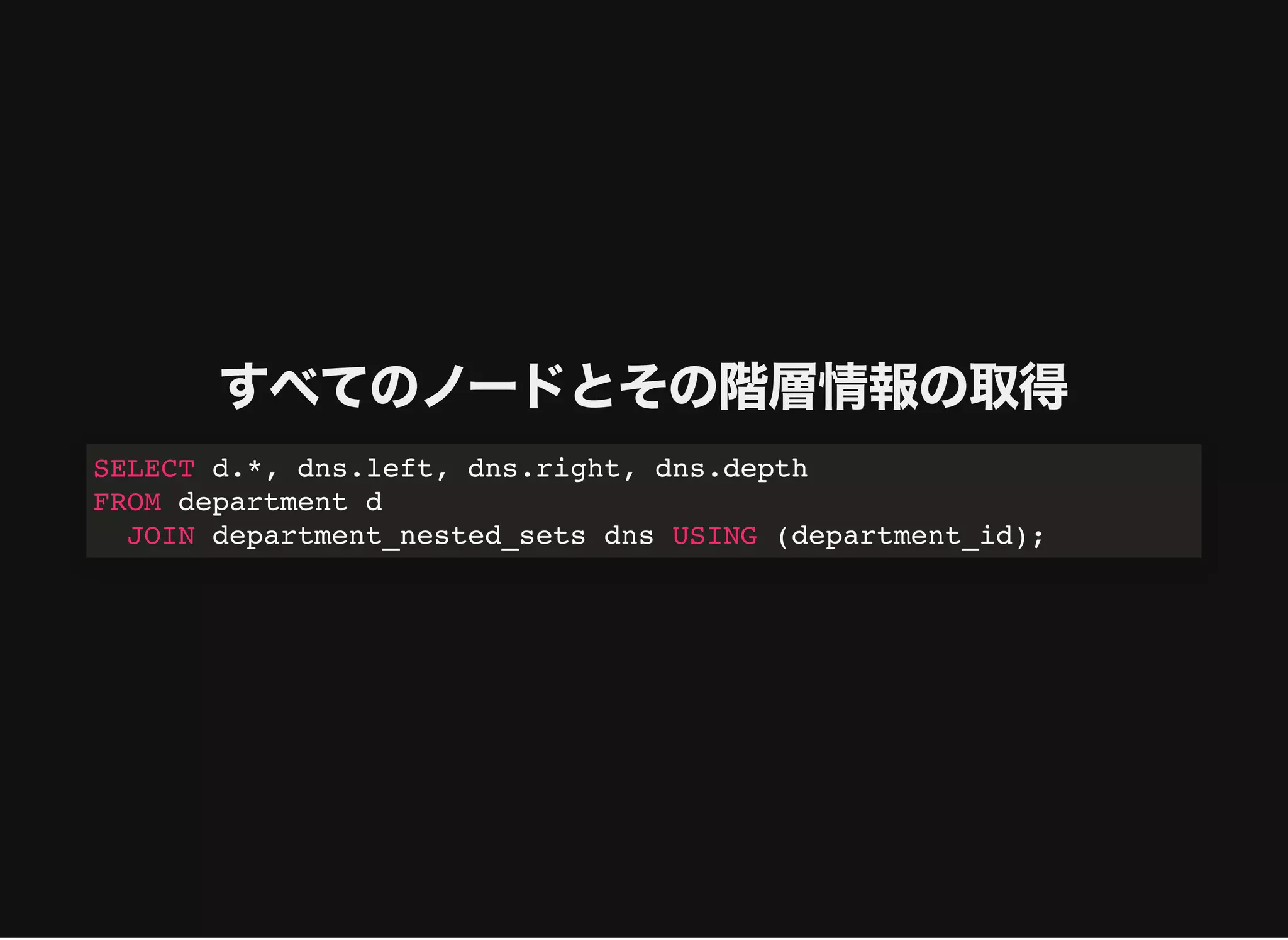
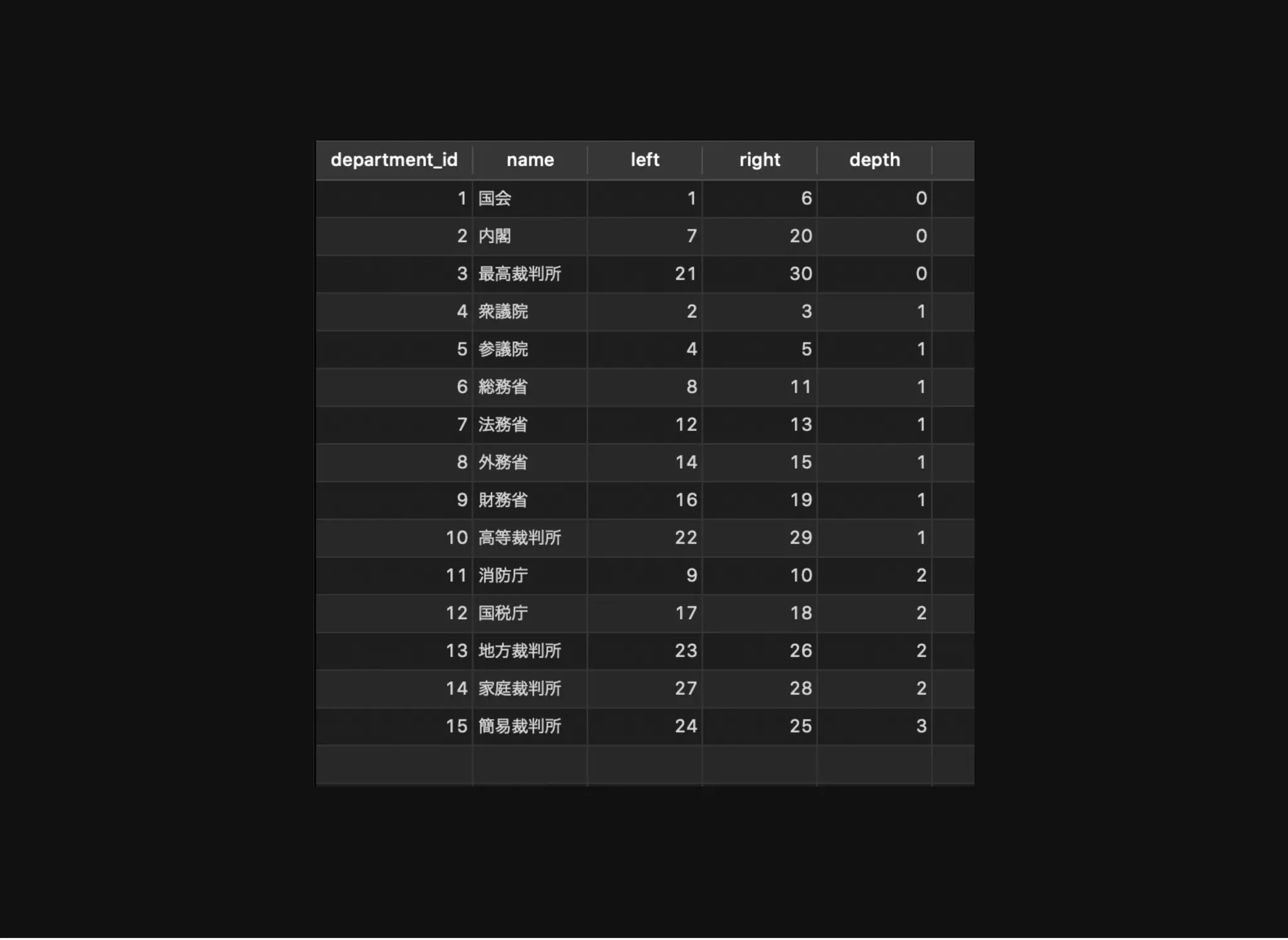
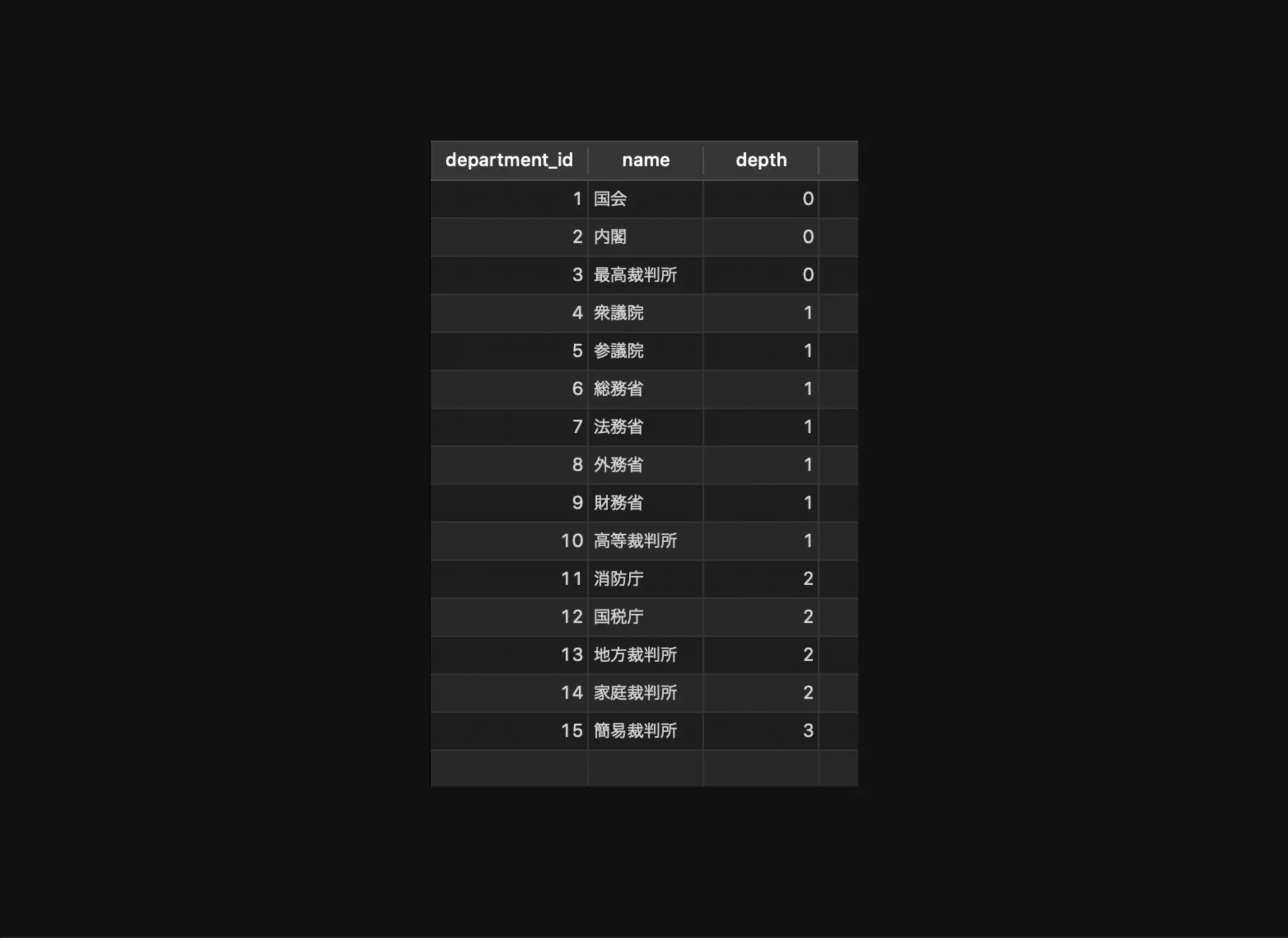
すべてのノードとその階層情報の取得
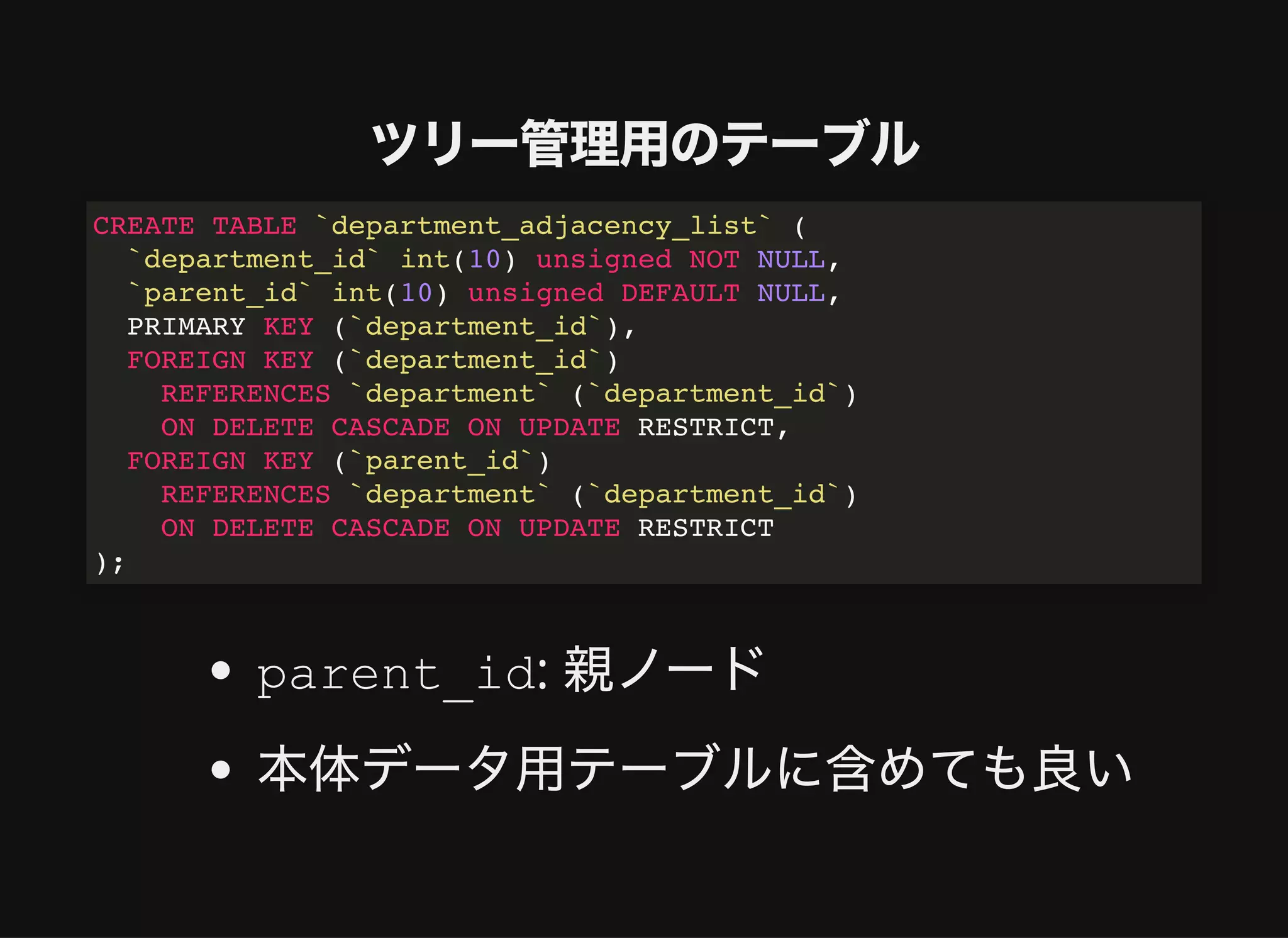
distance: ルートノードからの距離
cf.
WITH RECURSIVEdepartment_tree AS (
SELECT d.*, dal.parent_id, 0 distance
FROM department d
JOIN department_adjacency_list dal USING (department_id)
WHERE dal.parent_id IS NULL
UNION ALL
SELECT d.*, dal.parent_id, dt.distance + 1
FROM department d
JOIN department_adjacency_list dal USING (department_id)
JOIN department_tree dt ON dal.parent_id = dt.department_id
)
SELECT *
FROM department_tree;
WITH - MariaDB Knowledge Base
15.
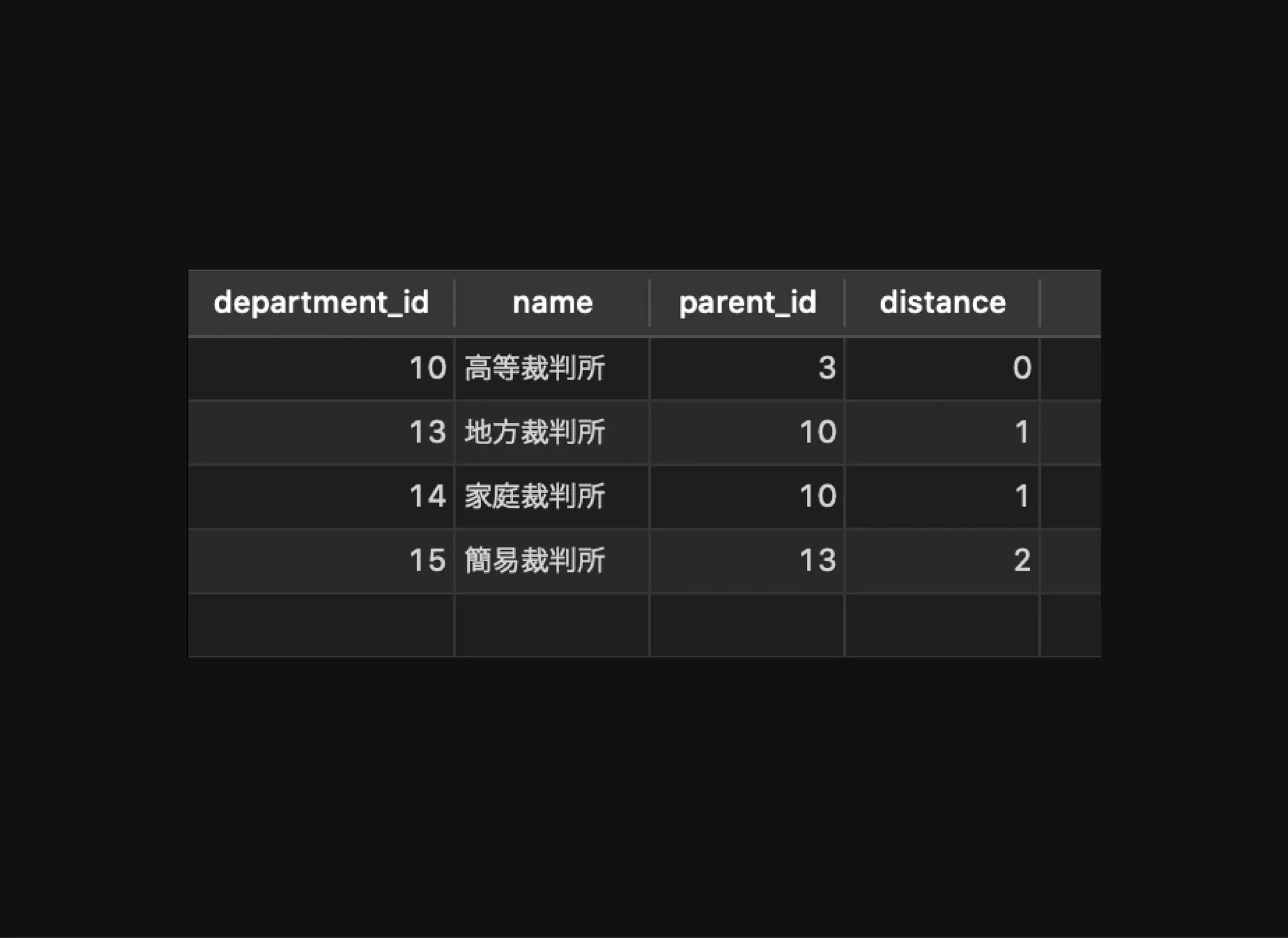
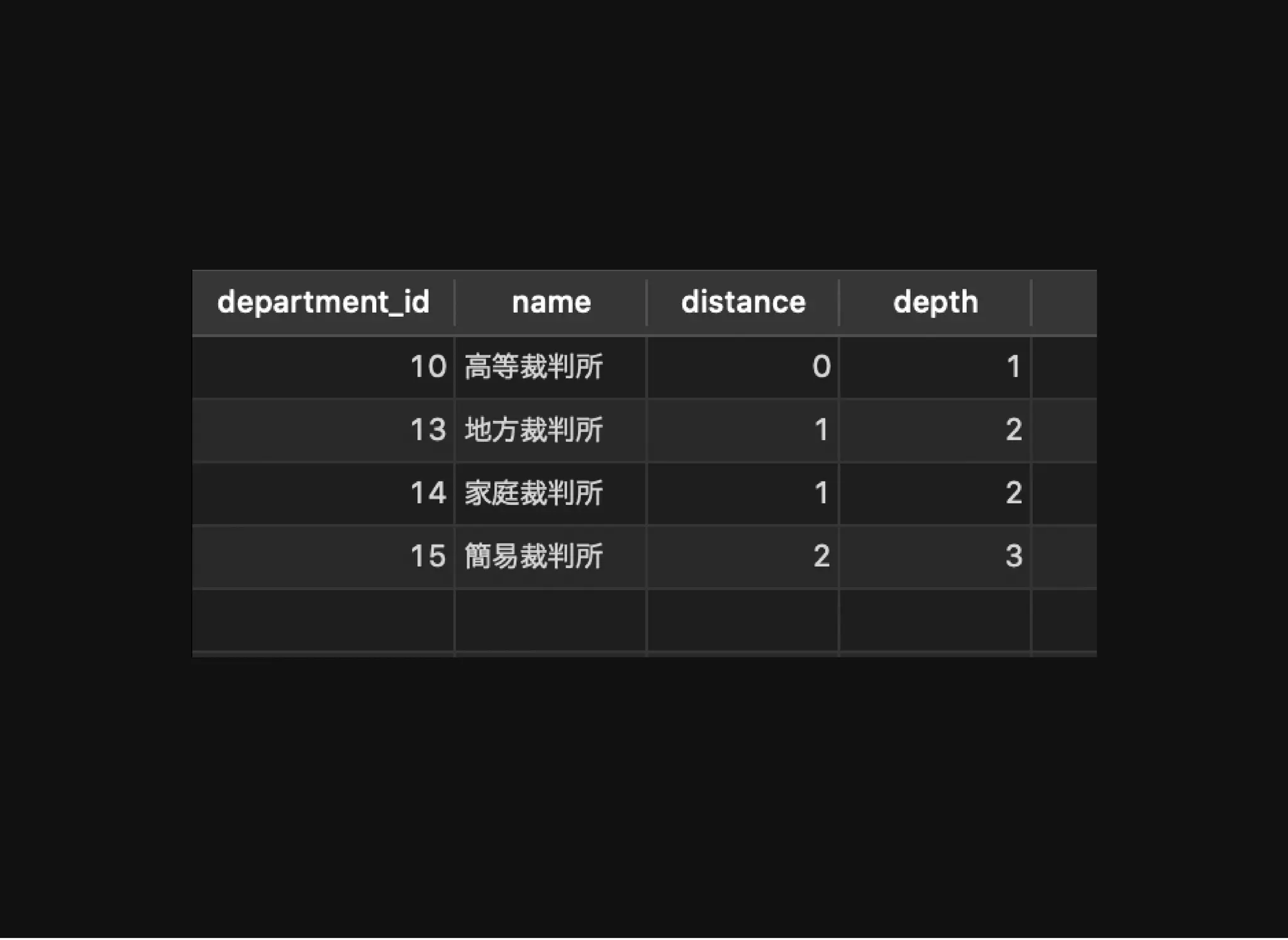
特定のノードからの⼦孫ノードの取得
distance: ノード10 からの距離
WITHRECURSIVE department_tree AS (
SELECT d.*, dal.parent_id, 0 distance
FROM department d
JOIN department_adjacency_list dal USING (department_id)
WHERE d.department_id = 10
UNION ALL
SELECT d.*, dal.parent_id, dt.distance + 1
FROM department d
JOIN department_adjacency_list dal USING (department_id)
JOIN department_tree dt ON dal.parent_id = dt.department_id
)
SELECT *
FROM department_tree;
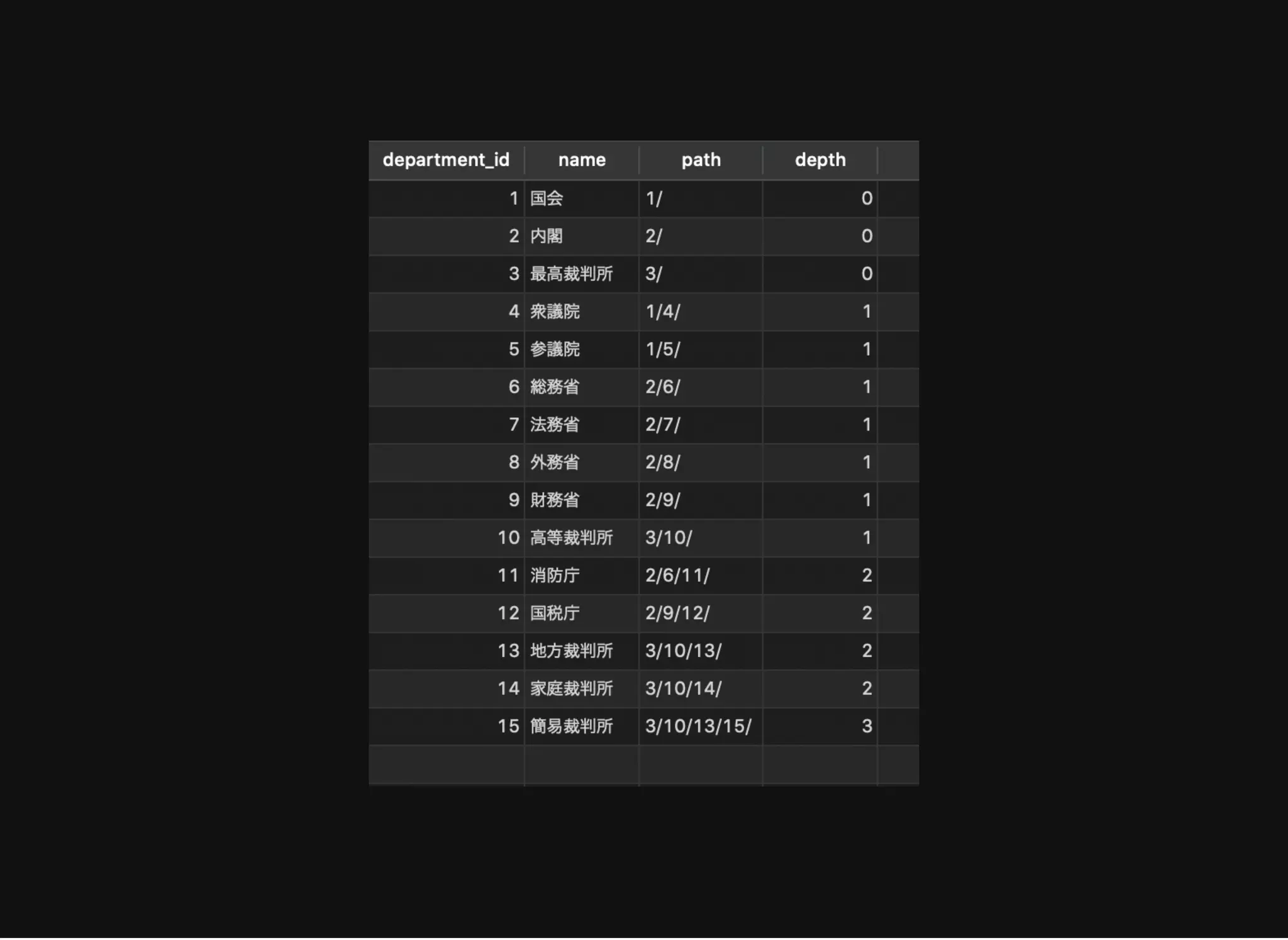
すべてのノードとその階層情報の取得
depth: ルートノードからの距離
SELECT d.*,dpe.path,
CHAR_LENGTH(dpe.path) - CHAR_LENGTH(REPLACE(dpe.path, '/', ''))
- 1 depth
FROM department d
JOIN department_path_enumeration dpe USING (department_id);
29.
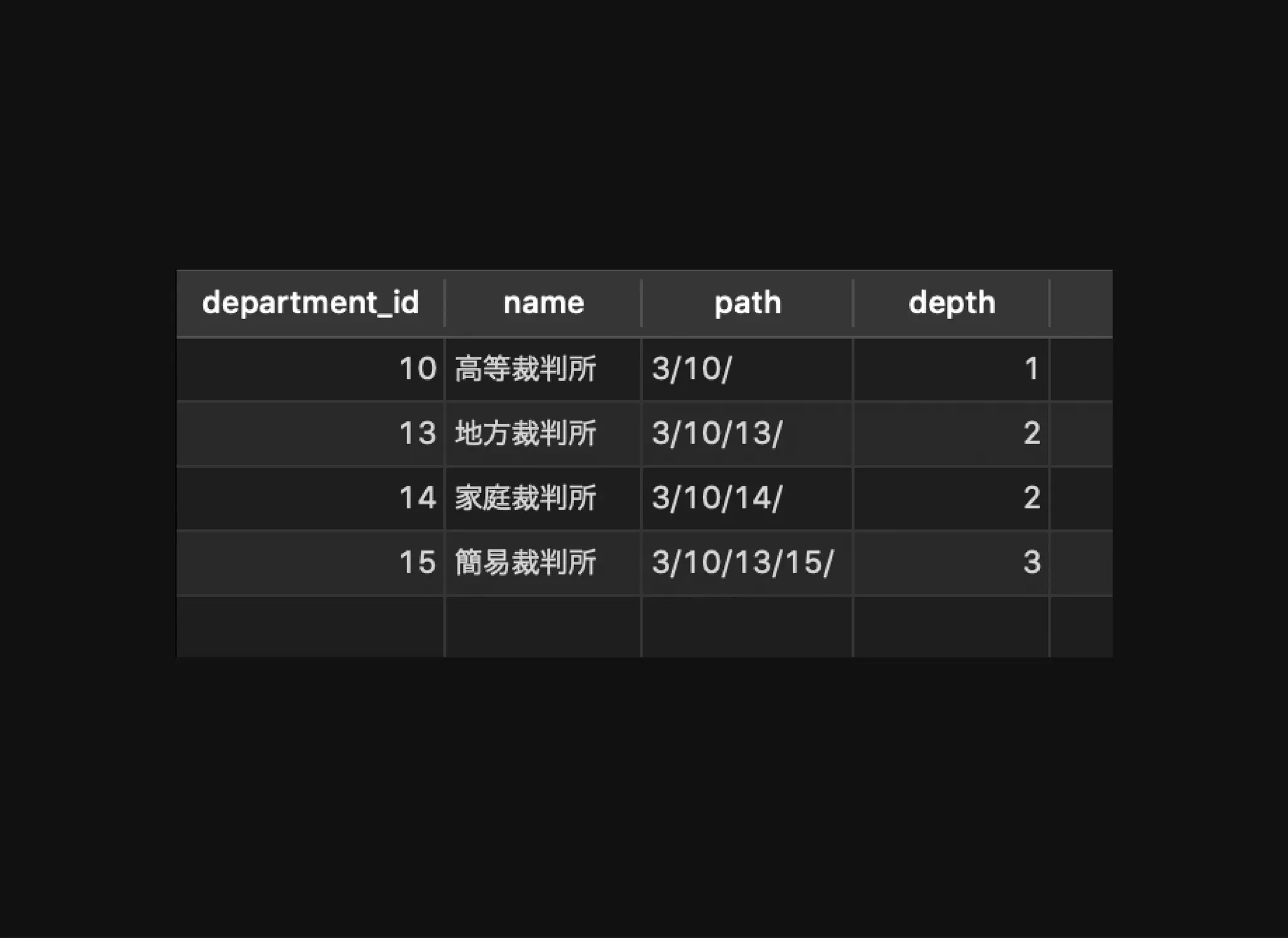
特定のノードからの⼦孫ノードの取得
depth: ルートノードからの距離
SELECT d.*,dpe.path,
CHAR_LENGTH(dpe.path) - CHAR_LENGTH(REPLACE(dpe.path, '/', ''))
- 1 depth
FROM department d
JOIN department_path_enumeration dpe USING (department_id)
WHERE dpe.path LIKE CONCAT((
SELECT path
FROM department_path_enumeration
WHERE department_id = 10
), '%');
31.
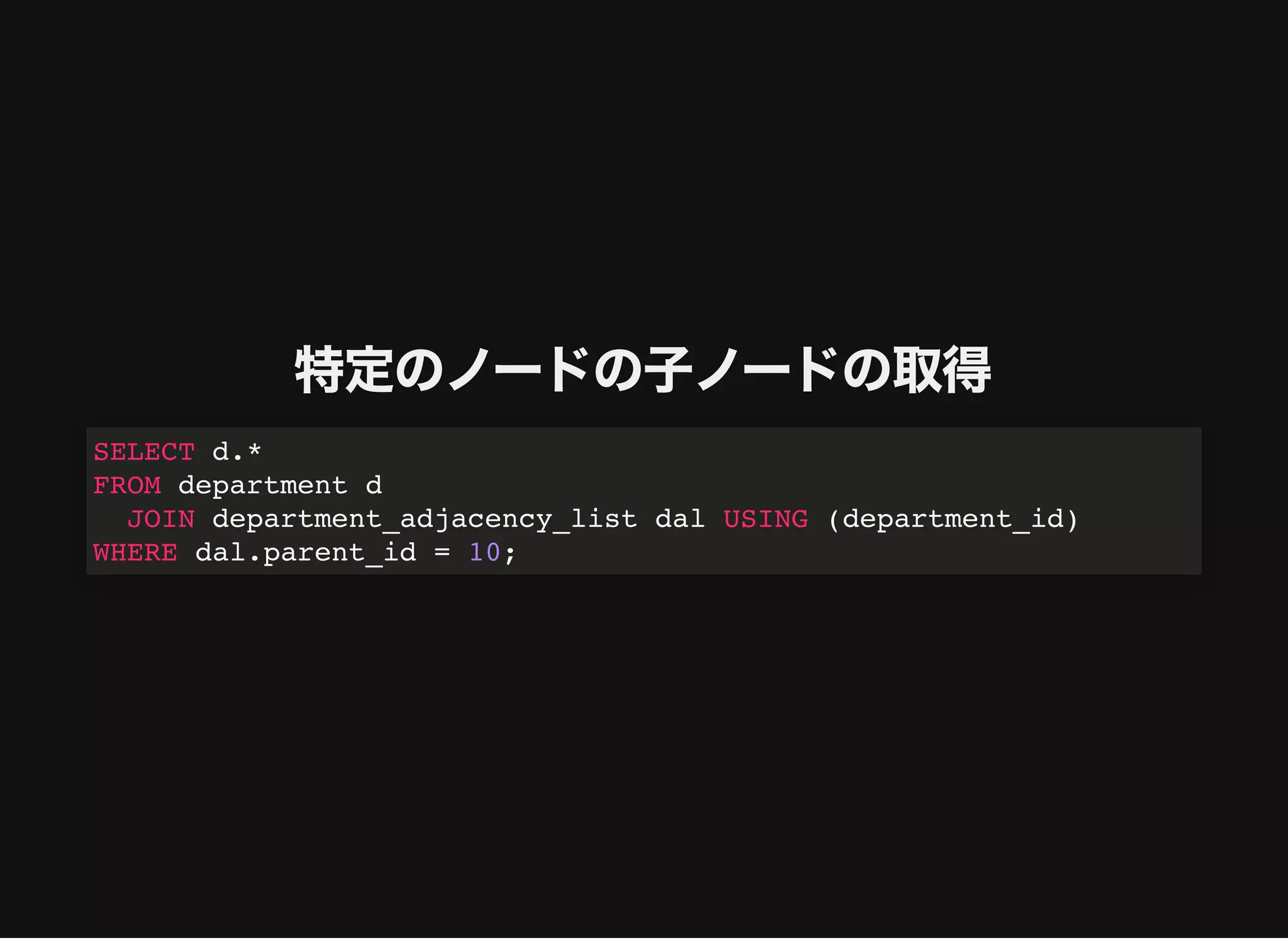
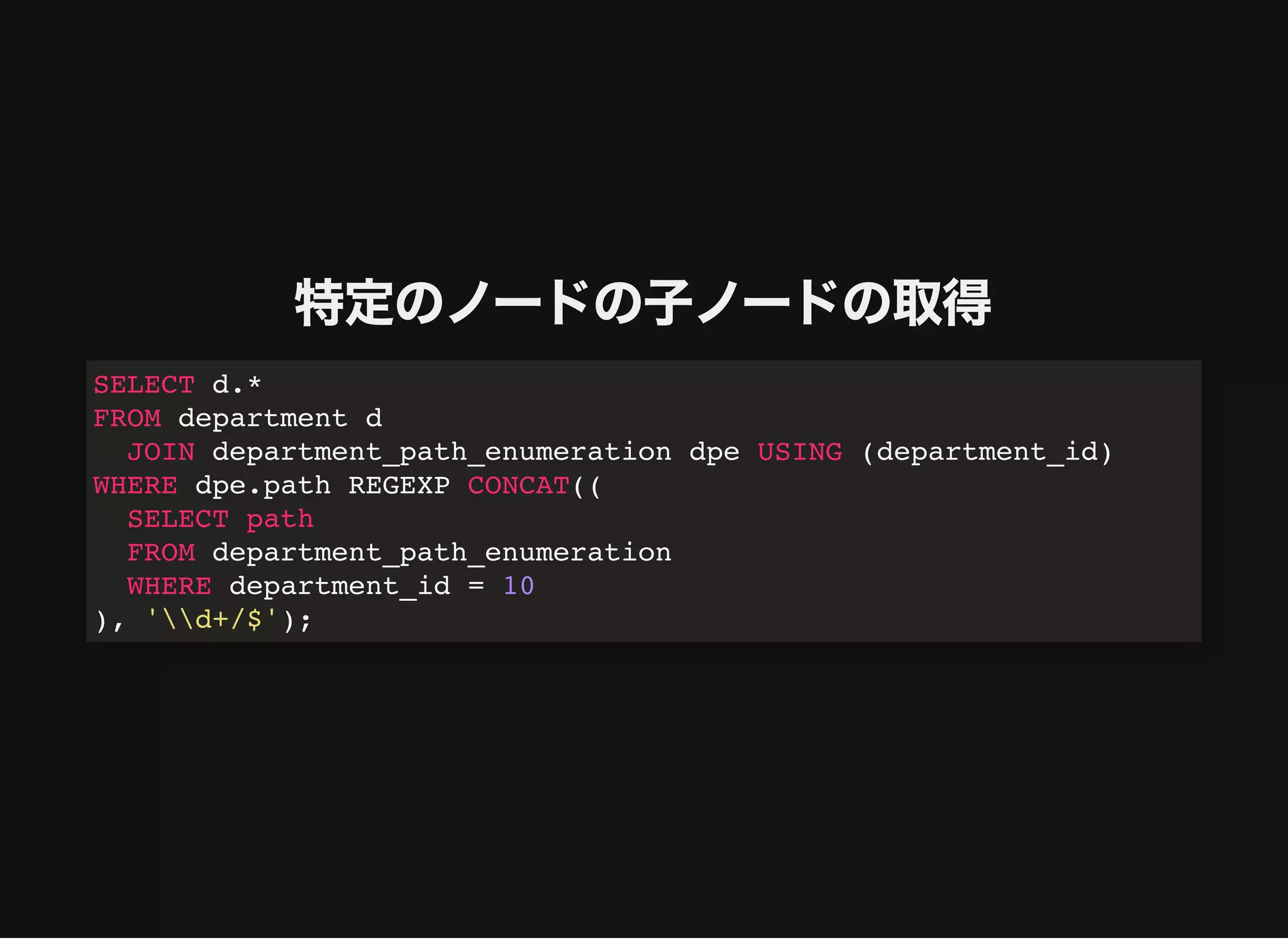
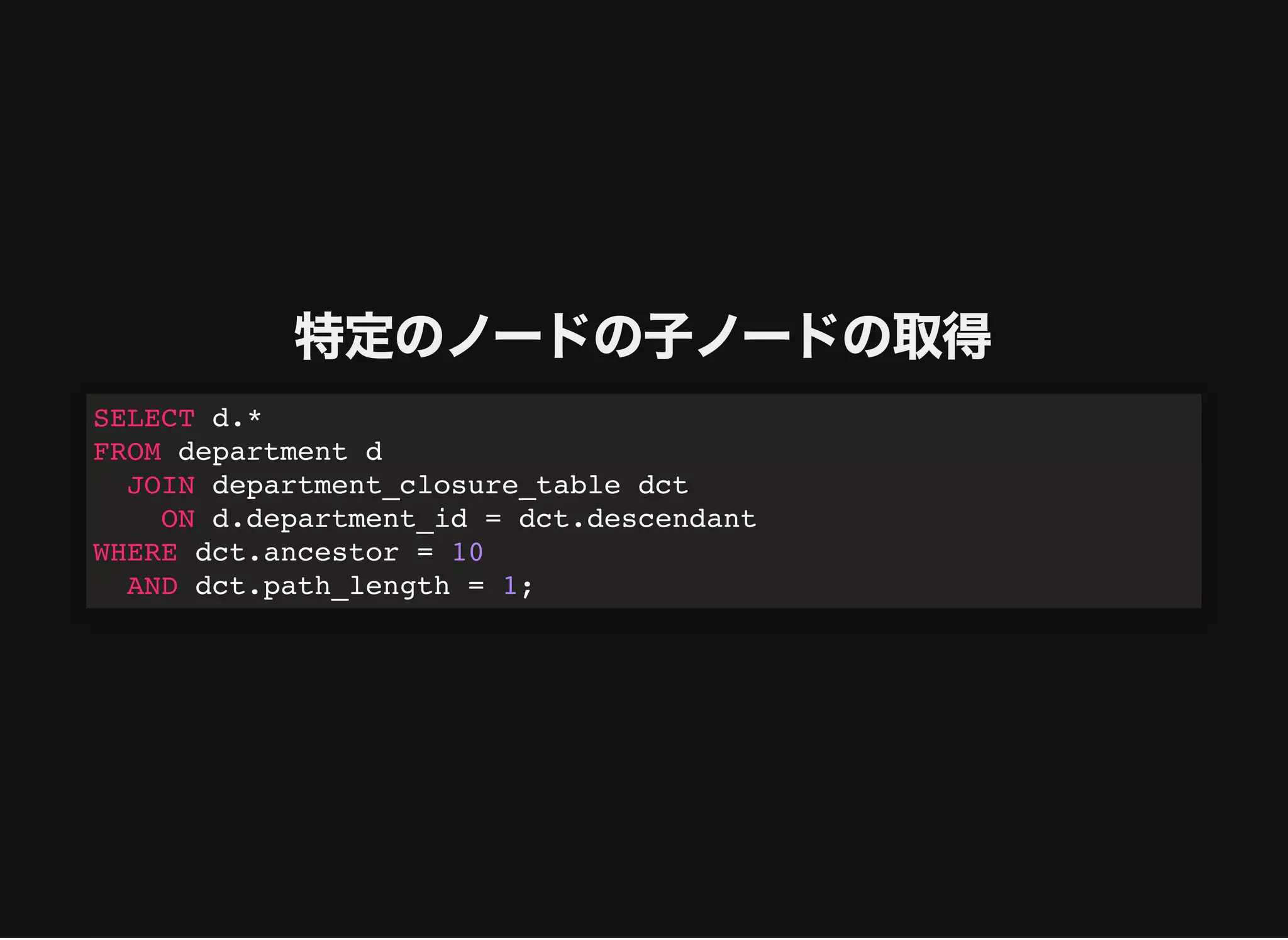
特定のノードの⼦ノードの取得
SELECT d.*
FROM departmentd
JOIN department_path_enumeration dpe USING (department_id)
WHERE dpe.path REGEXP CONCAT((
SELECT path
FROM department_path_enumeration
WHERE department_id = 10
), 'd+/$');
33.
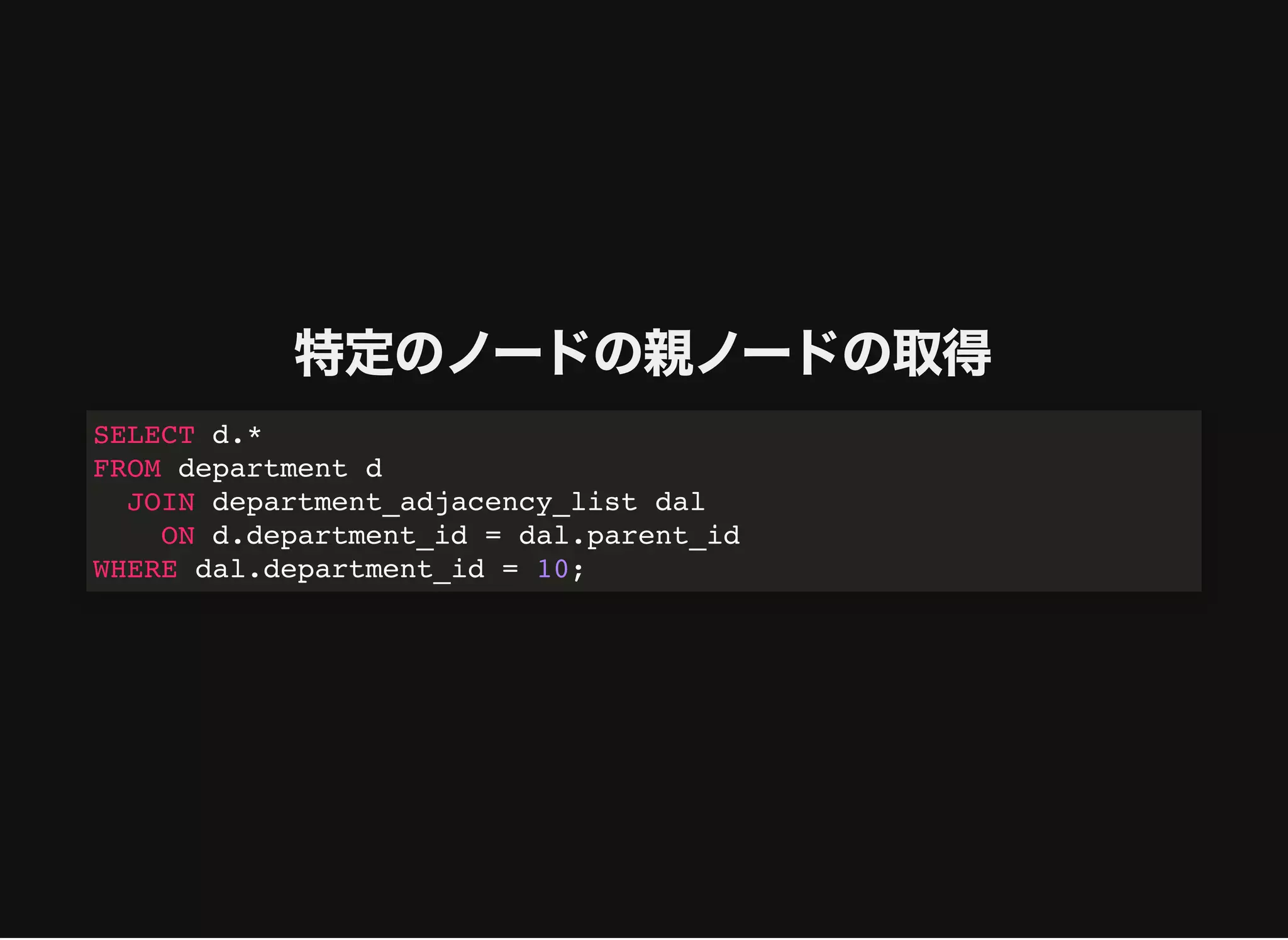
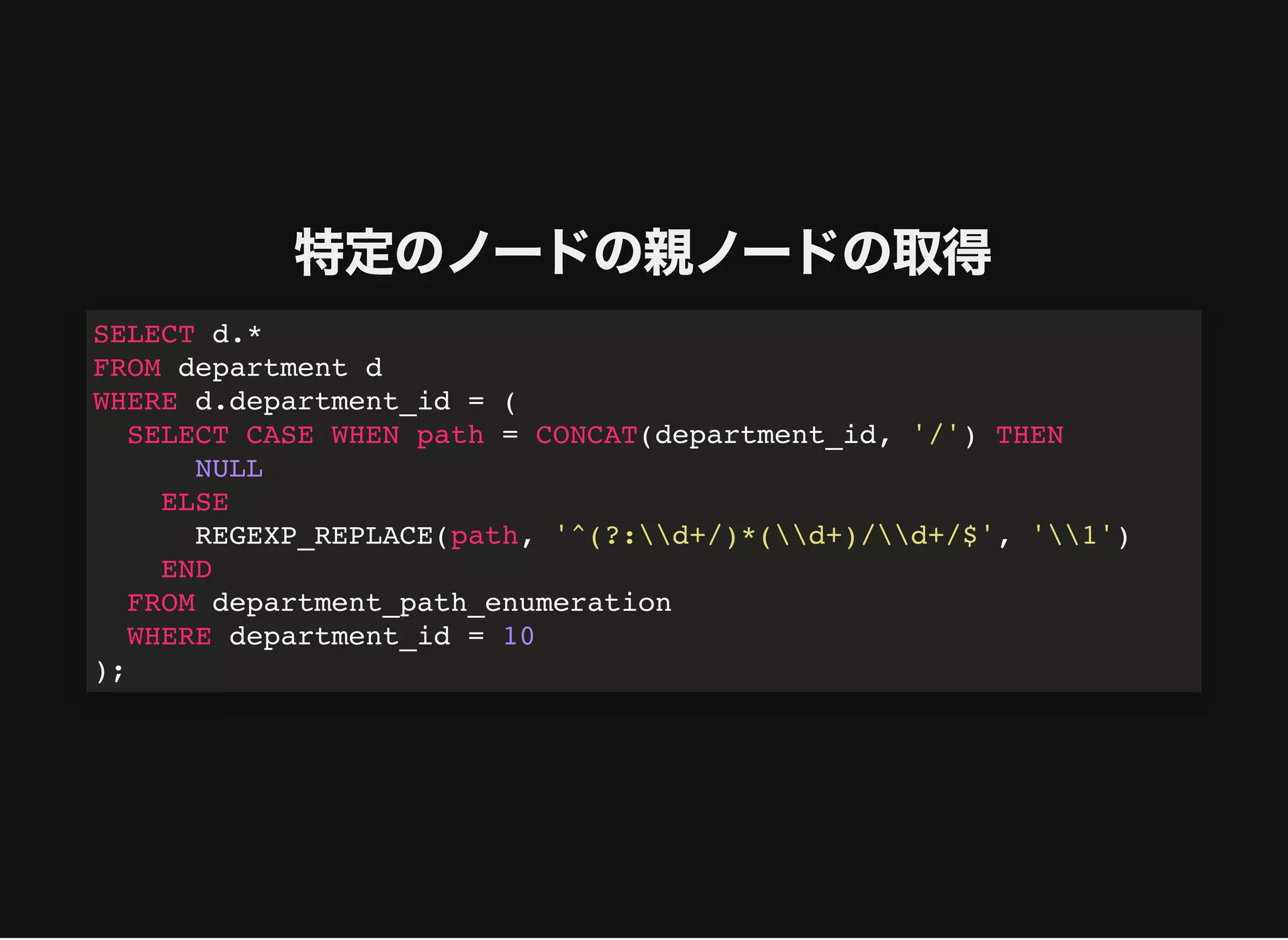
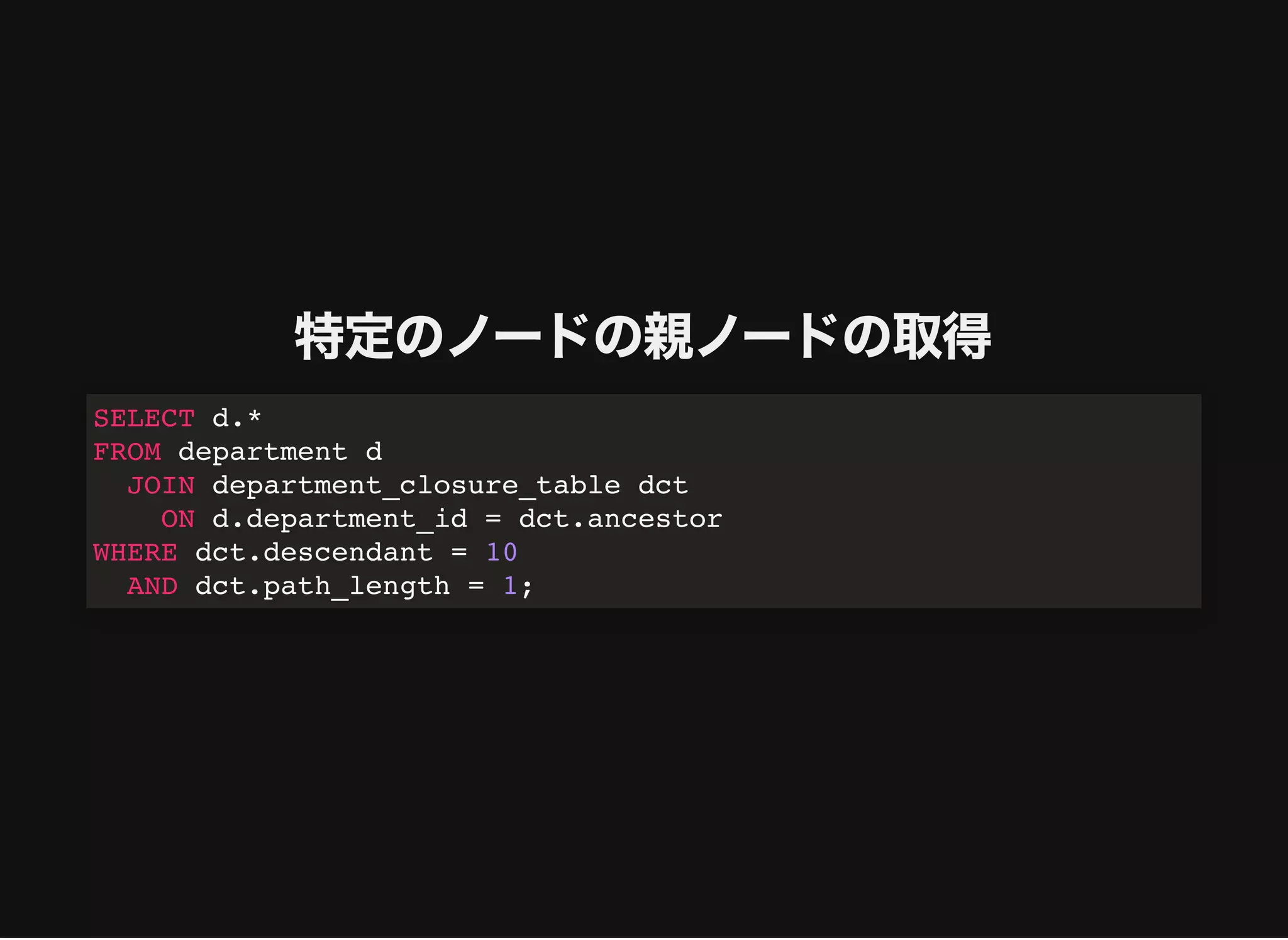
特定のノードの親ノードの取得
SELECT d.*
FROM departmentd
WHERE d.department_id = (
SELECT CASE WHEN path = CONCAT(department_id, '/') THEN
NULL
ELSE
REGEXP_REPLACE(path, '^(?:d+/)*(d+)/d+/$', '1')
END
FROM department_path_enumeration
WHERE department_id = 10
);
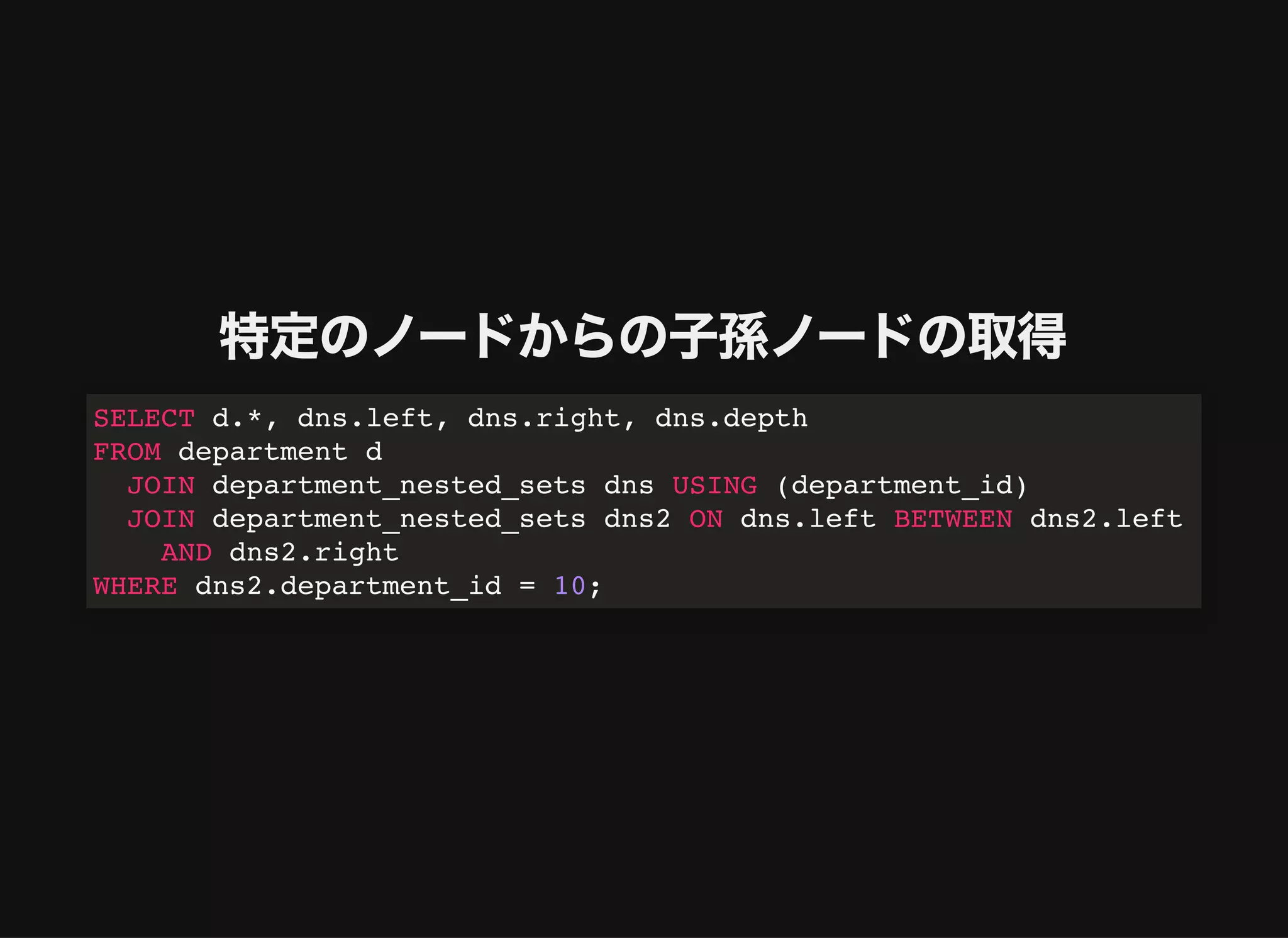
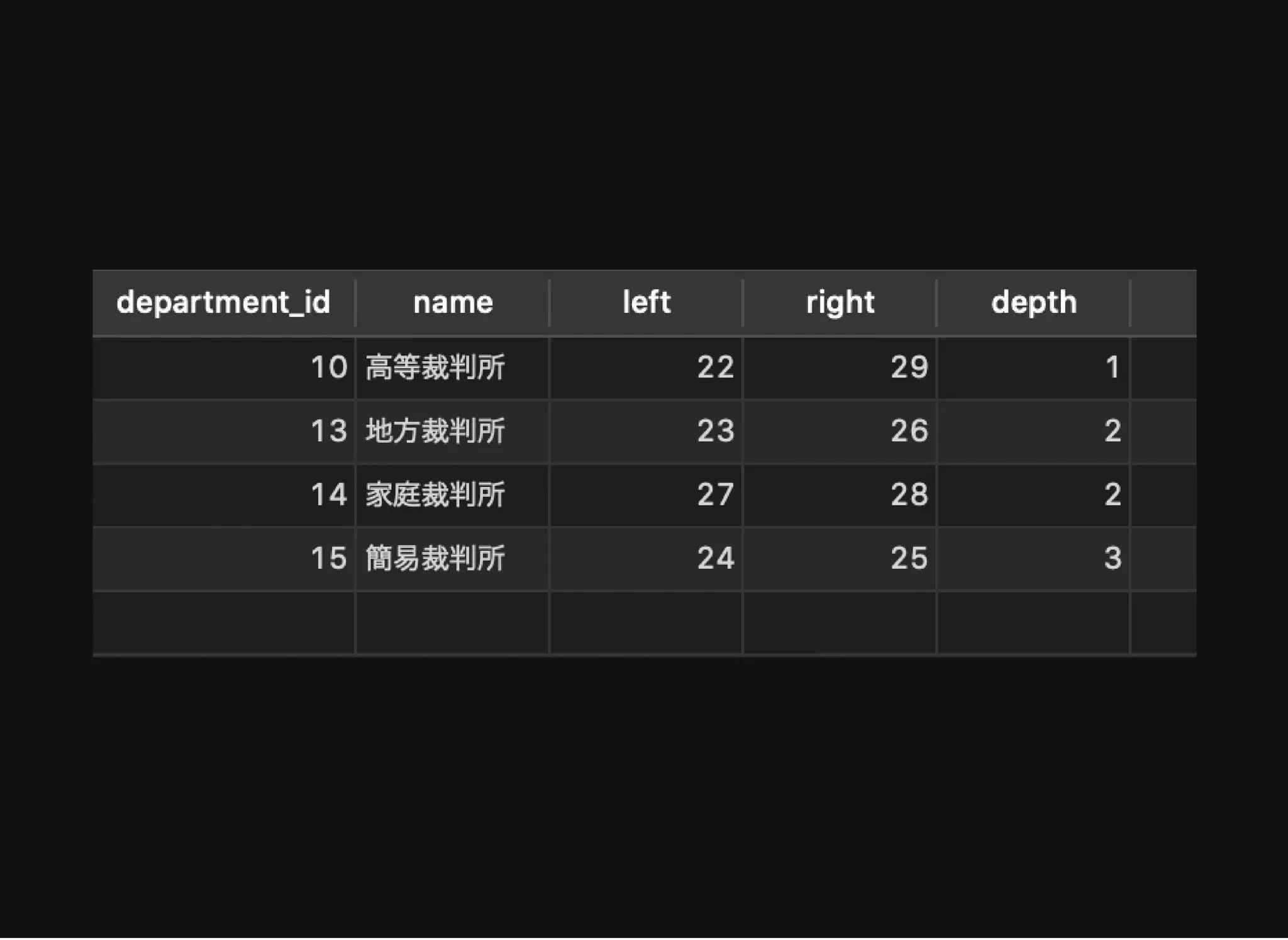
特定のノードからの⼦孫ノードの取得
SELECT d.*, dns.left,dns.right, dns.depth
FROM department d
JOIN department_nested_sets dns USING (department_id)
JOIN department_nested_sets dns2 ON dns.left BETWEEN dns2.left
AND dns2.right
WHERE dns2.department_id = 10;
45.
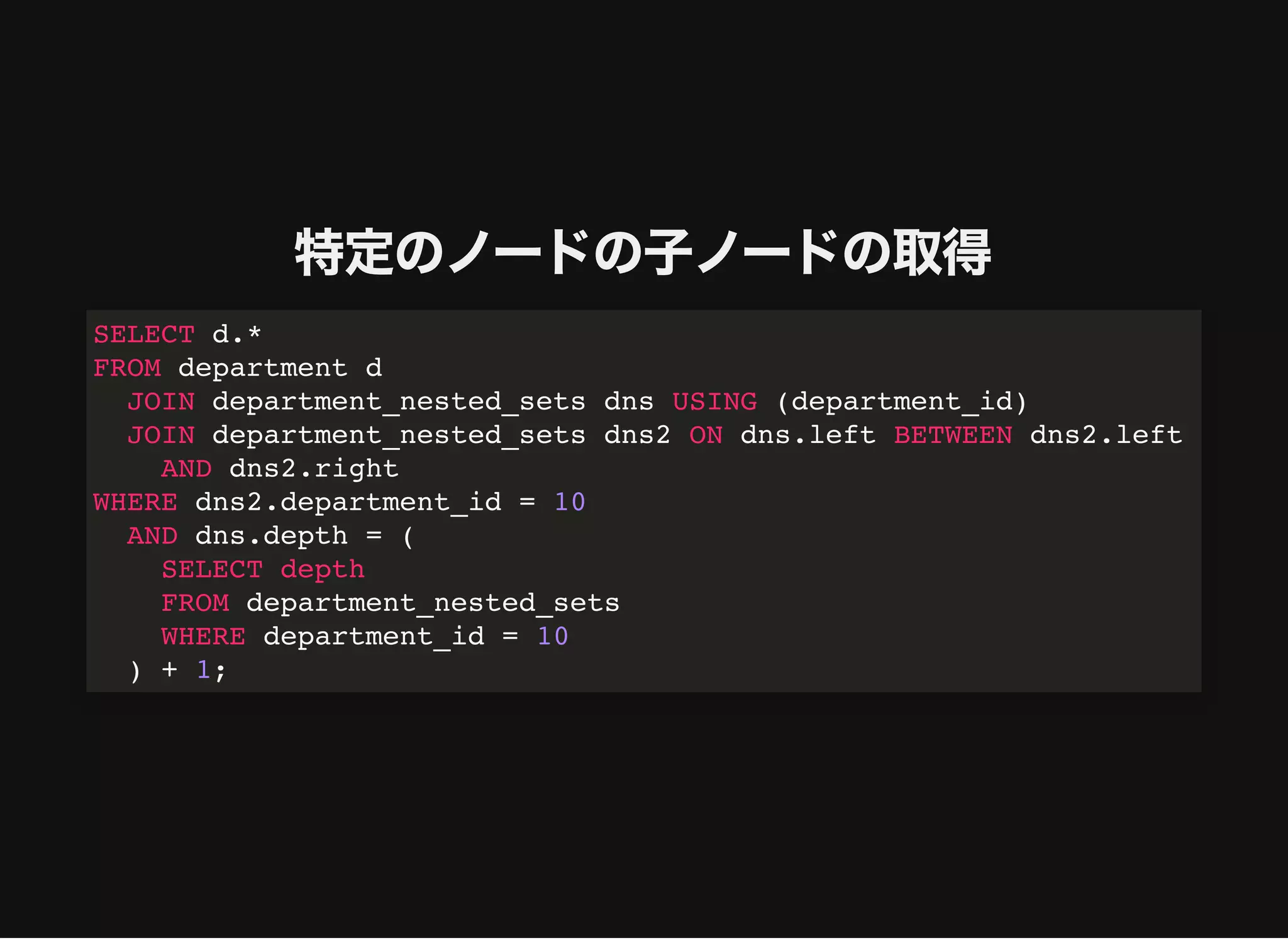
特定のノードの⼦ノードの取得
SELECT d.*
FROM departmentd
JOIN department_nested_sets dns USING (department_id)
JOIN department_nested_sets dns2 ON dns.left BETWEEN dns2.left
AND dns2.right
WHERE dns2.department_id = 10
AND dns.depth = (
SELECT depth
FROM department_nested_sets
WHERE department_id = 10
) + 1;
47.
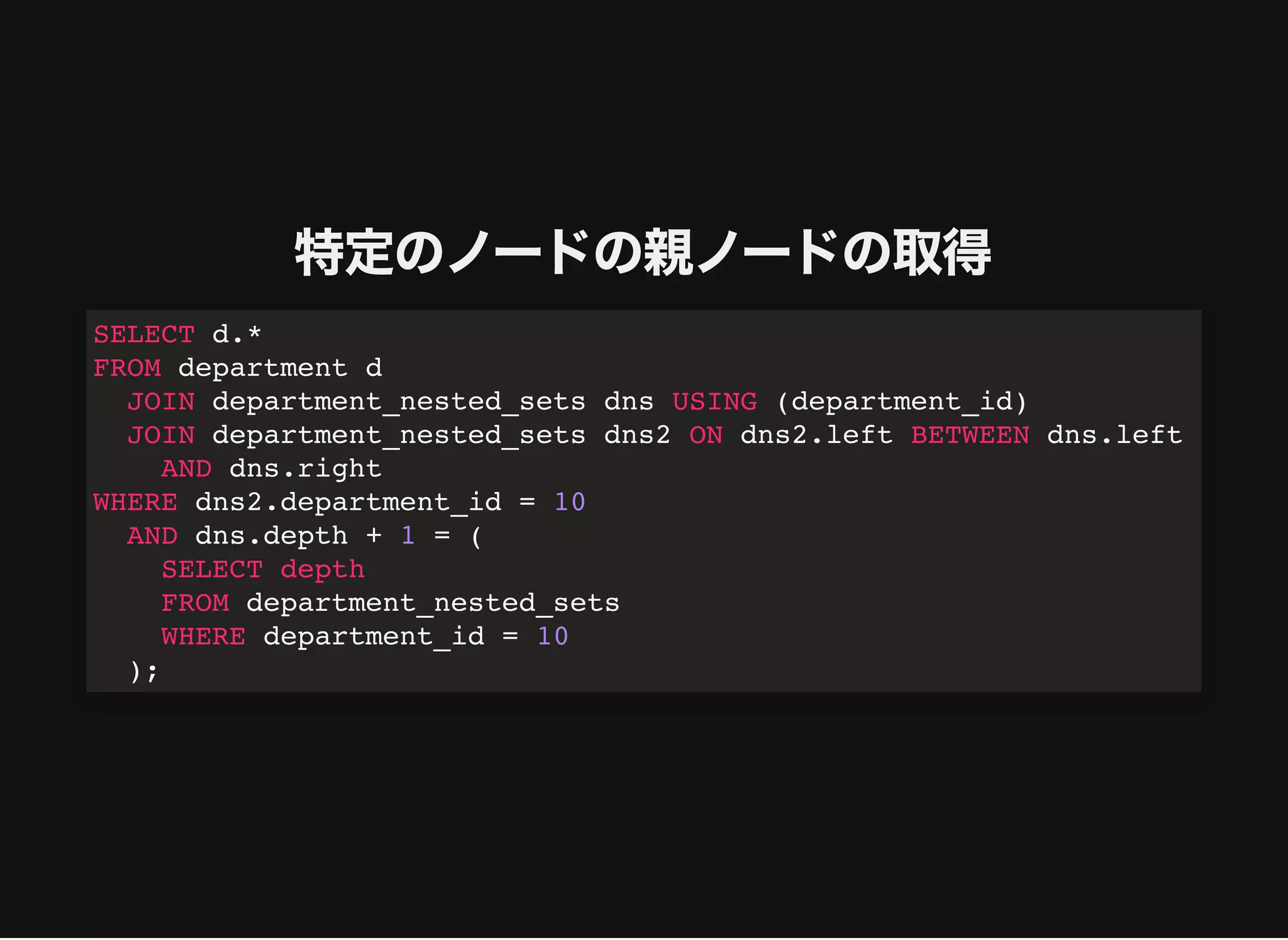
特定のノードの親ノードの取得
SELECT d.*
FROM departmentd
JOIN department_nested_sets dns USING (department_id)
JOIN department_nested_sets dns2 ON dns2.left BETWEEN dns.left
AND dns.right
WHERE dns2.department_id = 10
AND dns.depth + 1 = (
SELECT depth
FROM department_nested_sets
WHERE department_id = 10
);
特定のノードからの⼦孫ノードの取得
distance: ノード10 からの距離
depth:ルートノードからの距離
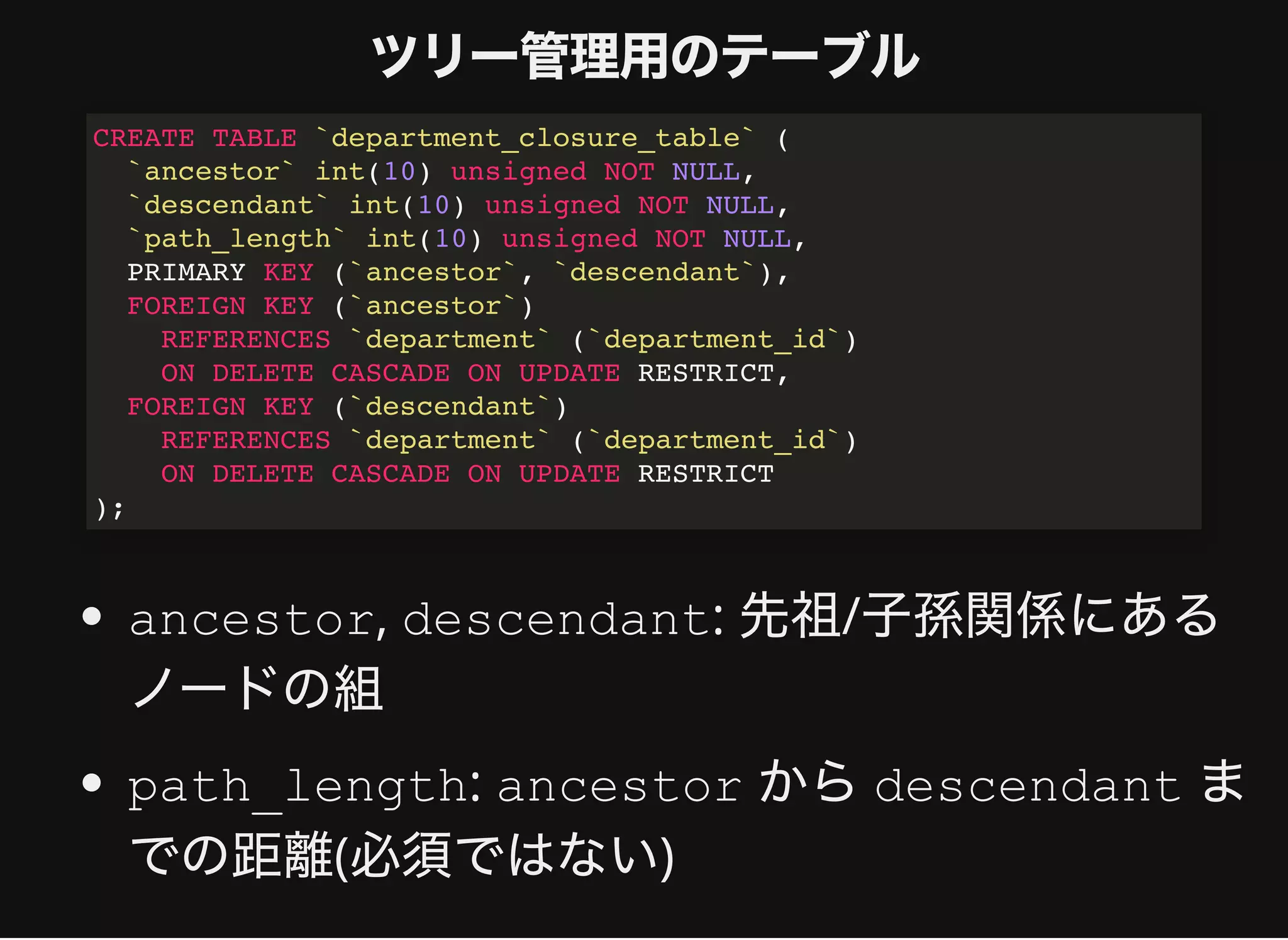
SELECT d.*, dct.path_length distance, dct2.depth
FROM department d
JOIN department_closure_table dct
ON d.department_id = dct.descendant
JOIN (
SELECT descendant, COUNT(*) - 1 depth
FROM department_closure_table
GROUP BY descendant
) dct2
ON d.department_id = dct2.descendant
WHERE dct.ancestor = 10;

![lagénorhynque
(defprofile lagénorhynque
:id @lagenorhynque
:reading "/laʒenɔʁɛ̃k/"
:aliases ["カマイルカ🐬 "]
:languages [Clojure Haskell English français]
:interests [programming language-learning law mathematics]
:commits ["github.com/lagenorhynque/duct.module.pedestal"
"github.com/lagenorhynque/duct.module.cambium"]
:contributes ["github.com/japan-clojurians/clojure-site-ja"])](https://image.slidesharecdn.com/introduction-to-tree-representations-in-rdb-200814072554/75/RDB-2-2048.jpg)






































![lagénorhynque
(defprofile lagénorhynque
:id @lagenorhynque
:reading "/laʒenɔʁɛ̃k/"
:aliases ["カマイルカ🐬 "]
:languages [Clojure Haskell English français]
:interests [programming language-learning law mathematics]
:commits ["github.com/lagenorhynque/duct.module.pedestal"
"github.com/lagenorhynque/duct.module.cambium"]
:contributes ["github.com/japan-clojurians/clojure-site-ja"])](https://crownmelresort.com/image.slidesharecdn.com/introduction-to-tree-representations-in-rdb-200814072554/75/RDB-2-2048.jpg)


























































































![[よくわかるクラウドデータベース] Amazon RDS for PostgreSQL検証報告](https://cdn.slidesharecdn.com/ss_thumbnails/20140117rdsforpgsqlbenchreport-140216194106-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










































