EXPLAIN ANALYZE
• 実行計画がそれぞれどれくらい時間かかったか見るこ
とが可能
test=#EXPLAIN ANALYZE SELECT t1.a, t2.a FROM t1, t2 WHERE t1.a = t2.a and t1.a < 100;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.85..805.31 rows=95 width=8) (actual time=0.038..3.319 rows=99 loops=1)
-> Index Only Scan using t1_pkey on t1 (cost=0.42..10.09 rows=95 width=4) (actual
time=0.012..0.449 rows=99 loops=1)
Index Cond: (a < 100)
Heap Fetches: 99
-> Index Only Scan using idx_t2_a on t2 (cost=0.42..8.36 rows=1 width=4) (actual time=0.006..0.011
rows=1 loops=99)
Index Cond: (a = t1.a)
Heap Fetches: 99
プランノード
コスト
実行時間
Total runtime: 3.782 ms
(8 rows)
36.
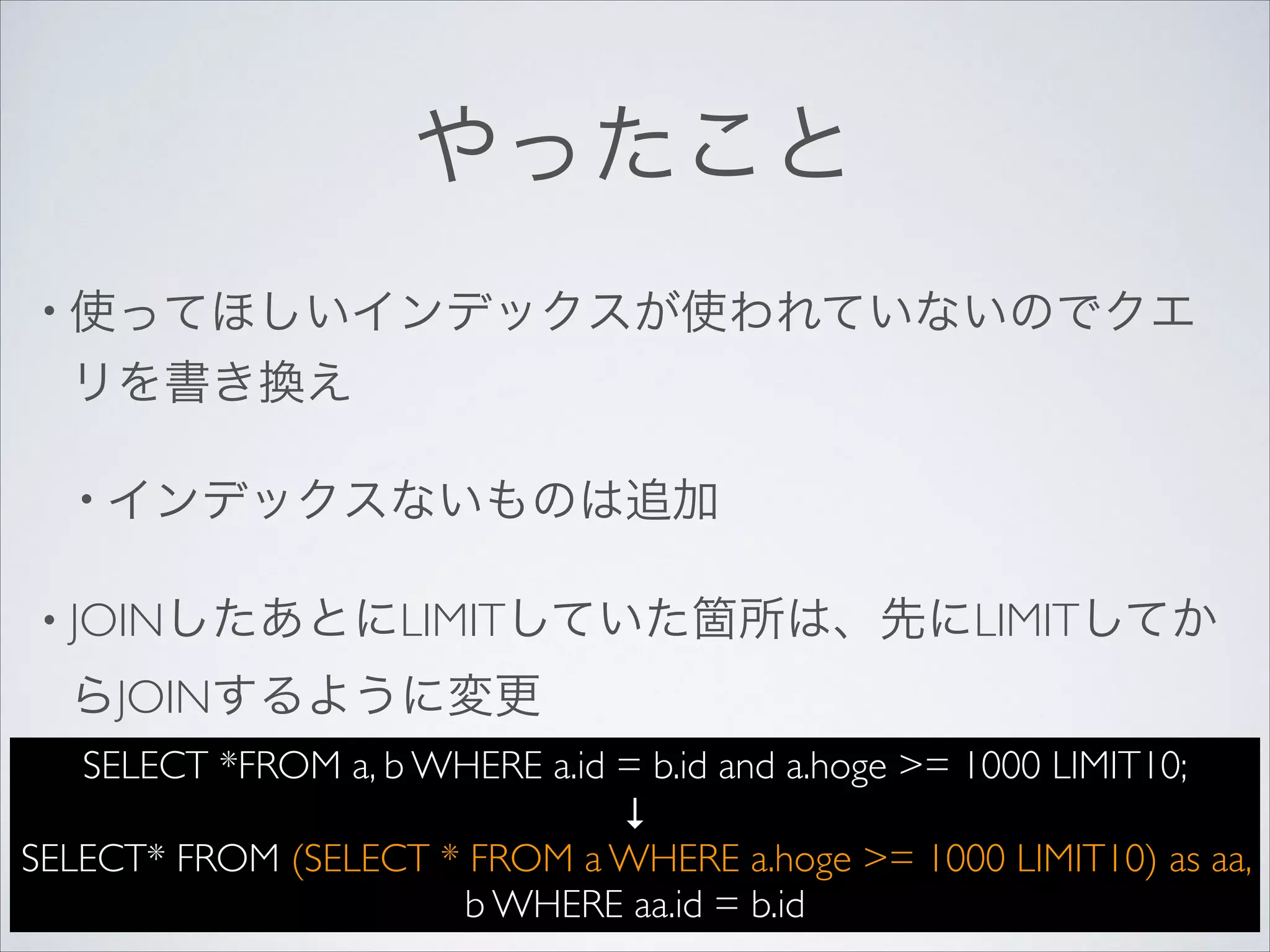
やったこと
• 使ってほしいインデックスが使われていないのでクエ
リを書き換え
• インデックスないものは追加
•JOINしたあとにLIMITしていた箇所は、先にLIMITしてか
らJOINするように変更
SELECT *FROM a, b WHERE a.id = b.id and a.hoge >= 1000 LIMIT10;
↓
SELECT* FROM (SELECT * FROM a WHERE a.hoge >= 1000 LIMIT10) as aa,
b WHERE aa.id = b.id
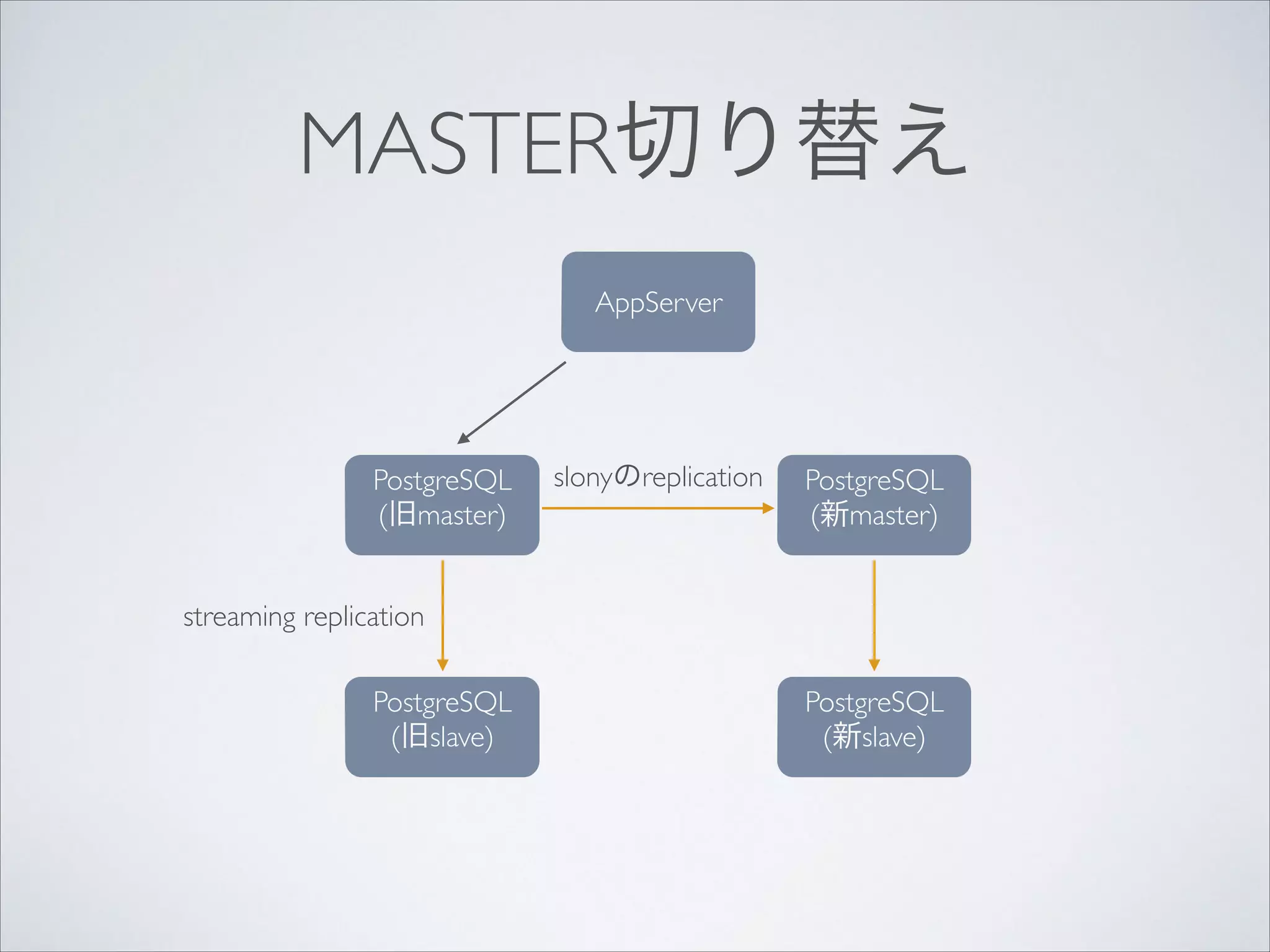
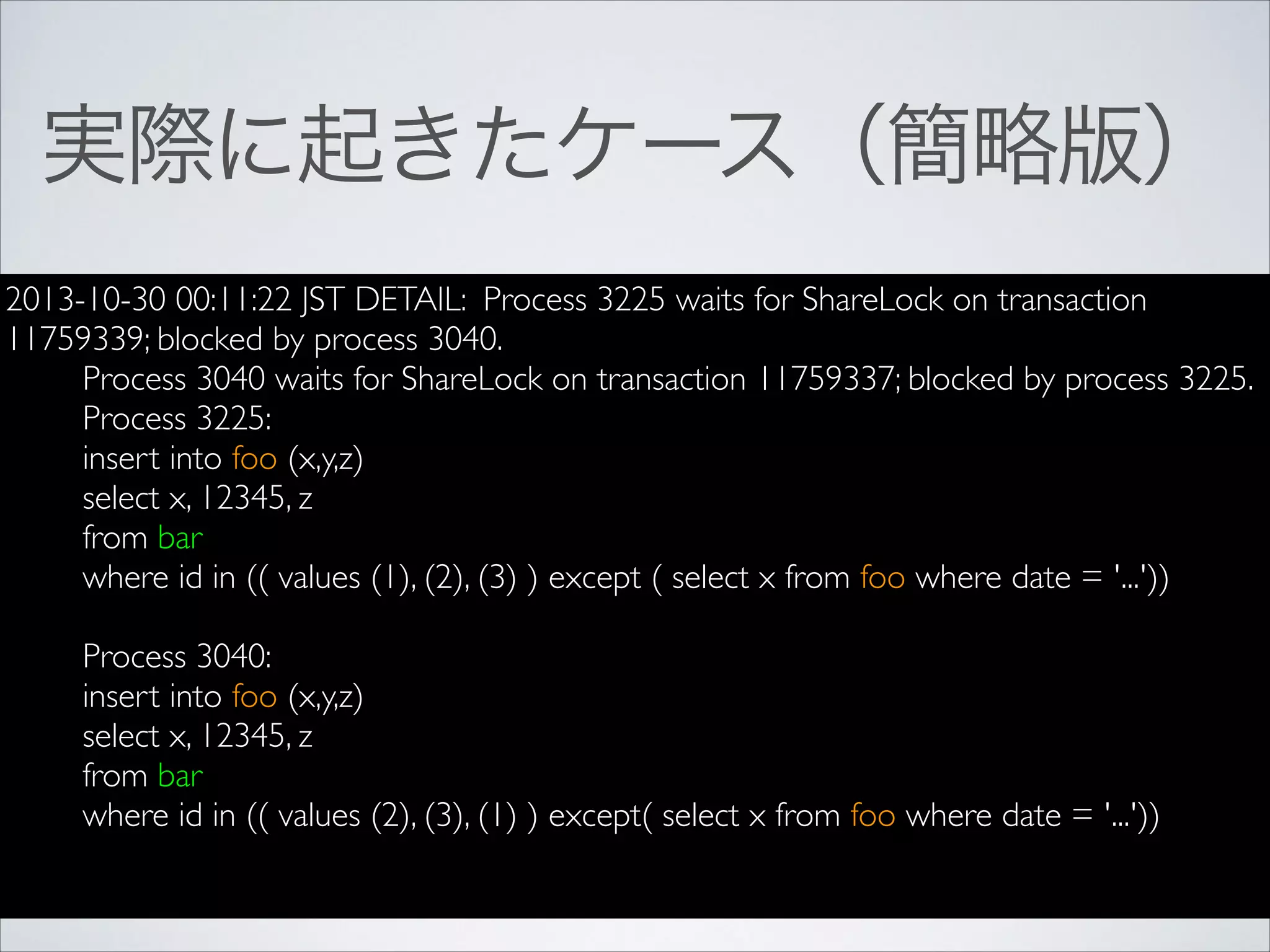
実際に起きたケース(簡略版)
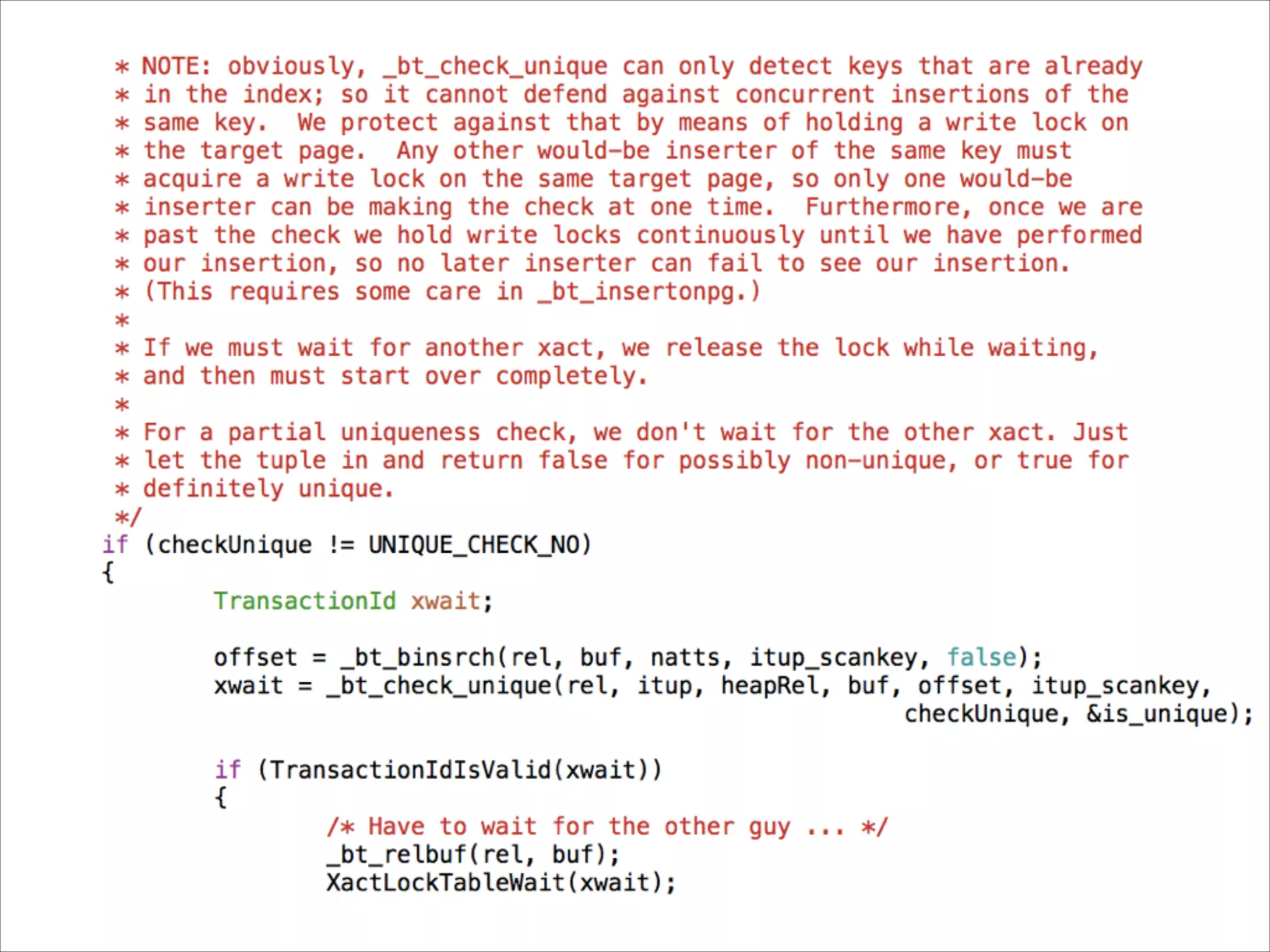
2013-10-30 00:11:22 JSTDETAIL: Process 3225 waits for ShareLock on transaction
11759339; blocked by process 3040.
Process 3040 waits for ShareLock on transaction 11759337; blocked by process 3225.
Process 3225:
insert into foo (x,y,z)
select x, 12345, z
from bar
where id in (( values (1), (2), (3) ) except ( select x from foo where date = '...'))
!
Process 3040:
insert into foo (x,y,z)
select x, 12345, z
from bar
where id in (( values (2), (3), (1) ) except( select x from foo where date = '...'))
!
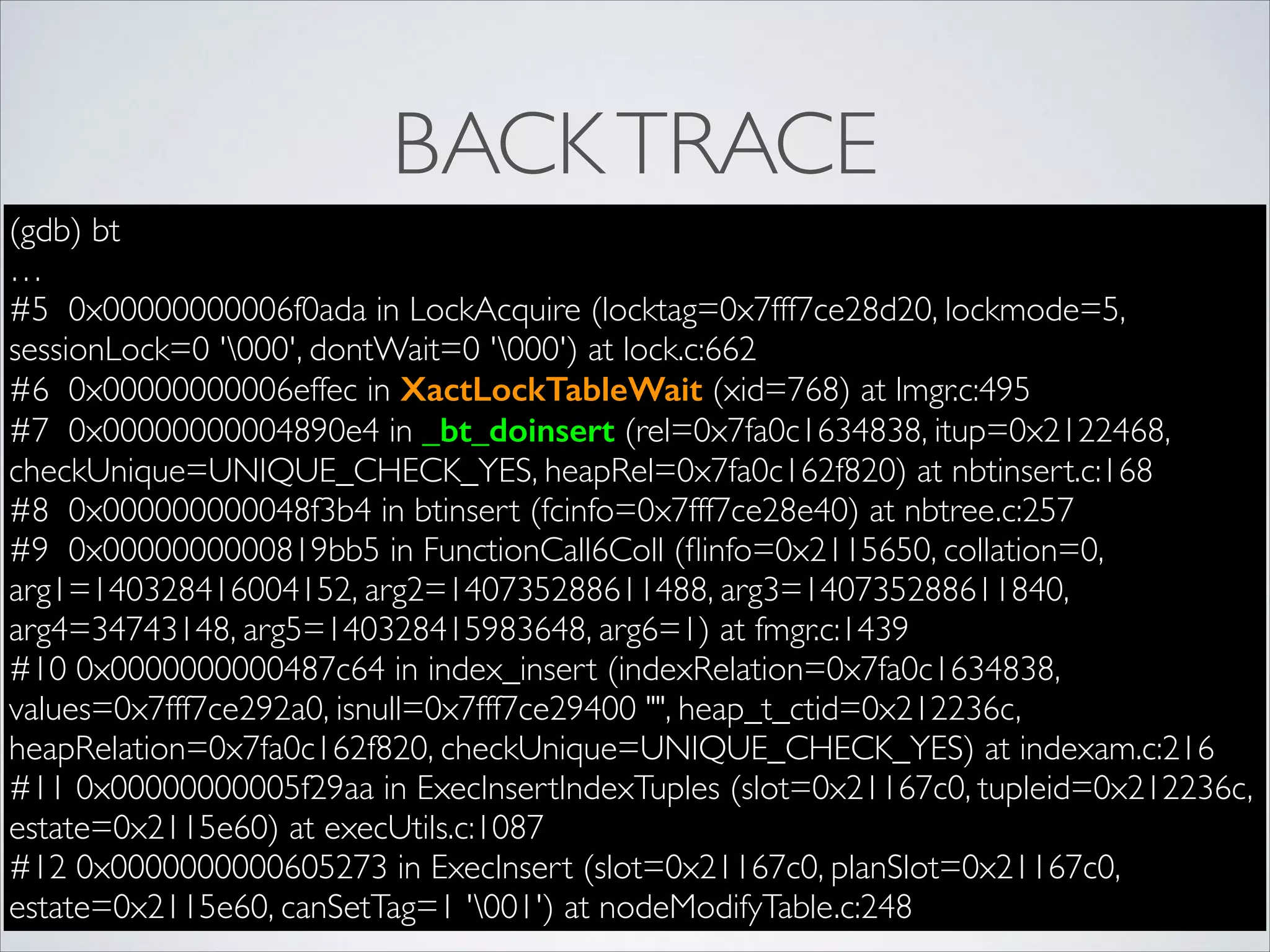
BACK TRACE
(gdb) bt
…
#50x00000000006f0ada in LockAcquire (locktag=0x7fff7ce28d20, lockmode=5,
sessionLock=0 '000', dontWait=0 '000') at lock.c:662
#6 0x00000000006effec in XactLockTableWait (xid=768) at lmgr.c:495
#7 0x00000000004890e4 in _bt_doinsert (rel=0x7fa0c1634838, itup=0x2122468,
checkUnique=UNIQUE_CHECK_YES, heapRel=0x7fa0c162f820) at nbtinsert.c:168
#8 0x000000000048f3b4 in btinsert (fcinfo=0x7fff7ce28e40) at nbtree.c:257
#9 0x0000000000819bb5 in FunctionCall6Coll (flinfo=0x2115650, collation=0,
arg1=140328416004152, arg2=140735288611488, arg3=140735288611840,
arg4=34743148, arg5=140328415983648, arg6=1) at fmgr.c:1439
#10 0x0000000000487c64 in index_insert (indexRelation=0x7fa0c1634838,
values=0x7fff7ce292a0, isnull=0x7fff7ce29400 "", heap_t_ctid=0x212236c,
heapRelation=0x7fa0c162f820, checkUnique=UNIQUE_CHECK_YES) at indexam.c:216
#11 0x00000000005f29aa in ExecInsertIndexTuples (slot=0x21167c0, tupleid=0x212236c,
estate=0x2115e60) at execUtils.c:1087
#12 0x0000000000605273 in ExecInsert (slot=0x21167c0, planSlot=0x21167c0,
estate=0x2115e60, canSetTag=1 '001') at nodeModifyTable.c:248
58.
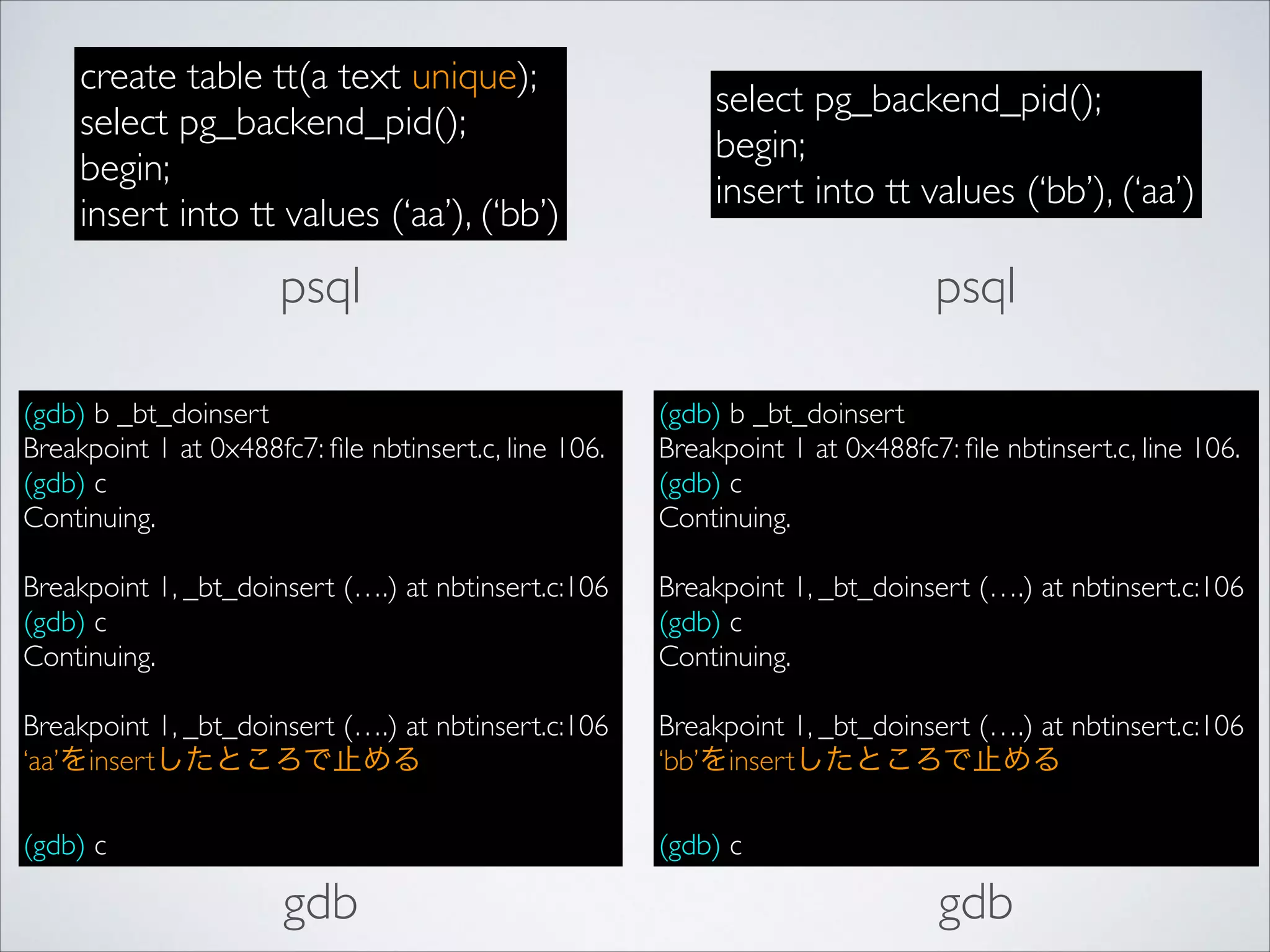
create table tt(atext unique);
select pg_backend_pid();
begin;
insert into tt values (‘aa’), (‘bb’)
select pg_backend_pid();
begin;
insert into tt values (‘bb’), (‘aa’)
psql
psql
(gdb) b _bt_doinsert
Breakpoint 1 at 0x488fc7: file nbtinsert.c, line 106.
(gdb) c
Continuing.
!
Breakpoint 1, _bt_doinsert (….) at nbtinsert.c:106
(gdb) c
Continuing.
!
Breakpoint 1, _bt_doinsert (….) at nbtinsert.c:106
‘aa’をinsertしたところで止める
(gdb) b _bt_doinsert
Breakpoint 1 at 0x488fc7: file nbtinsert.c, line 106.
(gdb) c
Continuing.
!
Breakpoint 1, _bt_doinsert (….) at nbtinsert.c:106
(gdb) c
Continuing.
!
Breakpoint 1, _bt_doinsert (….) at nbtinsert.c:106
‘bb’をinsertしたところで止める
!
(gdb) c
!
(gdb) c
gdb
gdb
59.
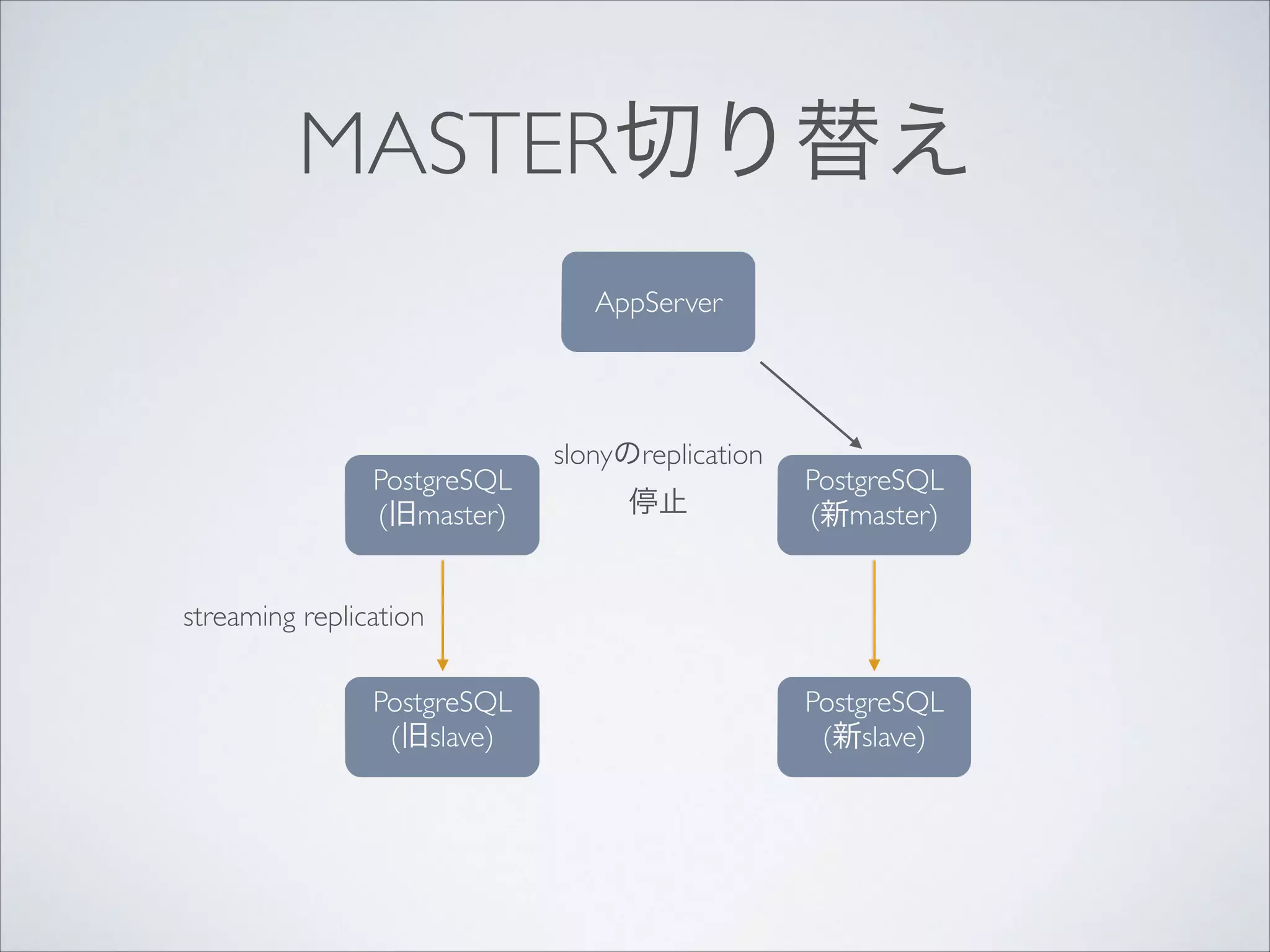
回避方法
2013-10-30 00:11:22 JSTDETAIL: Process 3225 waits for ShareLock on transaction
11759339; blocked by process 3040.
Process 3040 waits for ShareLock on transaction 11759337; blocked by process 3225.
Process 3225:
insert into foo (x,y,z)
select x, 12345, z
from bar
where x in (( values (1), (2), (3) ) except ( select x from foo where date = ‘…’))
ORDER BY x
!
Process 3040:
insert into foo (x,y,z)
select x, 12345, z
from bar
where x in (( values (2), (3), (1) ) except( select x from foo where date = ‘...'))
ORDER BY x
!

























































































































































































![[2025 Rakuten Technology Conference] Daybreak for AI Agents](https://cdn.slidesharecdn.com/ss_thumbnails/2025rakutentechnologyconferenceai-251119080407-027fe107-thumbnail.jpg?width=640&height=640&fit=bounds)




